Dinh, L., Krueger, D., and Bengio, Y. (2014). NICE: Non-linear independent components estimation. International Conference on Learning Representations Workshop. Ø [Dinh et al., 2017.] Dinh, L., Sohl-Dickstein, J., and Bengio, S. (2017). Density estimation using Real NVP. International Conference on Learning Representations. Ø [Kingma & Dhariwal., 2018.] Kingma, D. P. and Dhariwal, P. (2018). Glow: Generative flow with invertible 1x1 convolutions. In Advances in Neural Information Processing Systems, pages 10236–10245. Ø [Rezende & Mohamed., 2015.] Rezende, D. and Mohamed, S. (2015). Variational inference with normalizing flows. In Proceedings of The 32nd International Conference on Machine Learning, pages 1530–1538. ü [Kobyzev et al., 2019.] Kobyzev, I., Prince, S., and Brubaker, M. (2019). Normalizing Flows: An Introduction and Review of Current Methods. arXiv: 1908.09257 [stat.ML] ü [Papamakarios et la., 2019.] Papamakarios, G., Nalisnick, E., Rezende, D., Mohamed, S., and Lakshminarayanan, B. (2019). Normalizing Flows for Probabilistic Modeling and Inference. arXiv: 1912.02762 [stat.ML] n ブログ Ø [Weng., 2018.] LilʼLog: Flow-based Deep Generative Models. https://lilianweng.github.io/lil-log/2018/10/13/flow-based-deep-generative-models.html n スライド Ø [Suzuki., 2019.] DL輪読会のスライド: Flow-based Deep Generative Models https://www.slideshare.net/DeepLearningJP2016/dlflowbased-deep-generative-models 28 参考⽂献
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
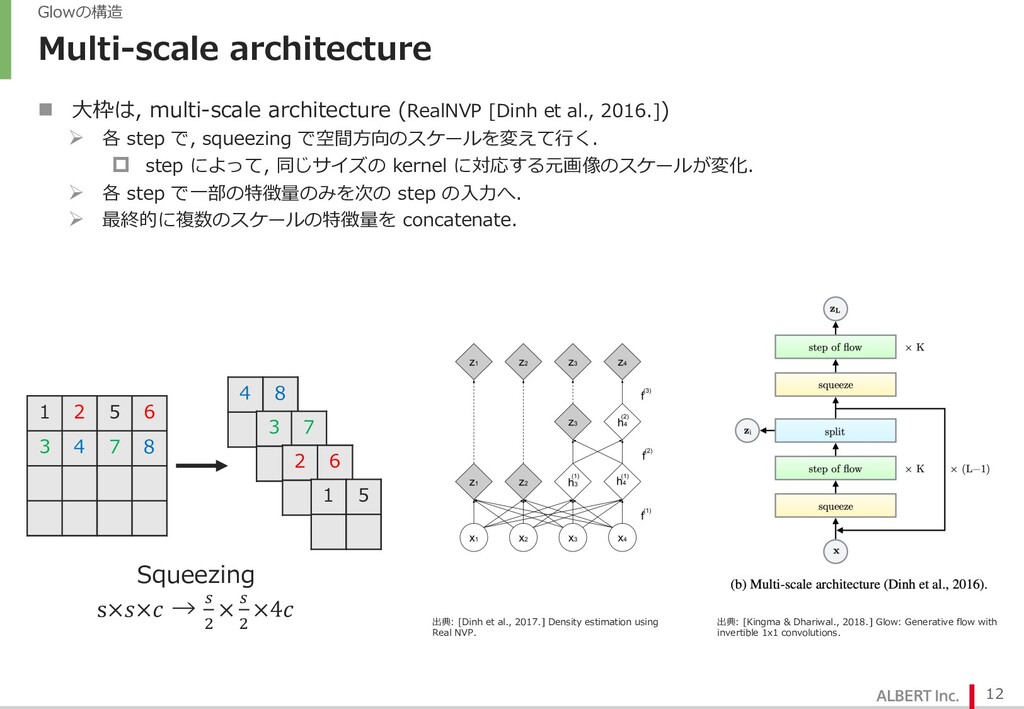{kind=link}
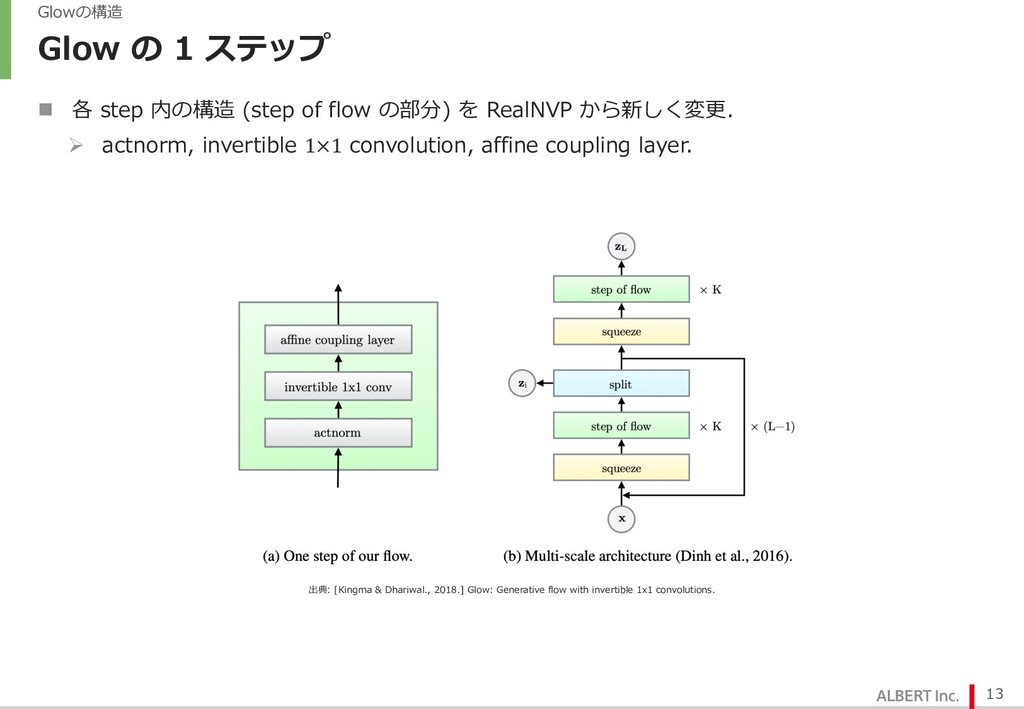{kind=link}
{kind=link}
![Actnorm 15 Glowの構造 出典: [Kingma & Dhariwal., 2018.] Glow: Generative](https://files.speakerdeck.com/presentations/2c7ee557d2cd4d309bb045611b9d4797/slide_14.jpg){kind=link}
{kind=link}
![Invertible 1×1 convolution 17 Glowの構造 出典: [Kingma & Dhariwal., 2018.]](https://files.speakerdeck.com/presentations/2c7ee557d2cd4d309bb045611b9d4797/slide_16.jpg){kind=link}
{kind=link}
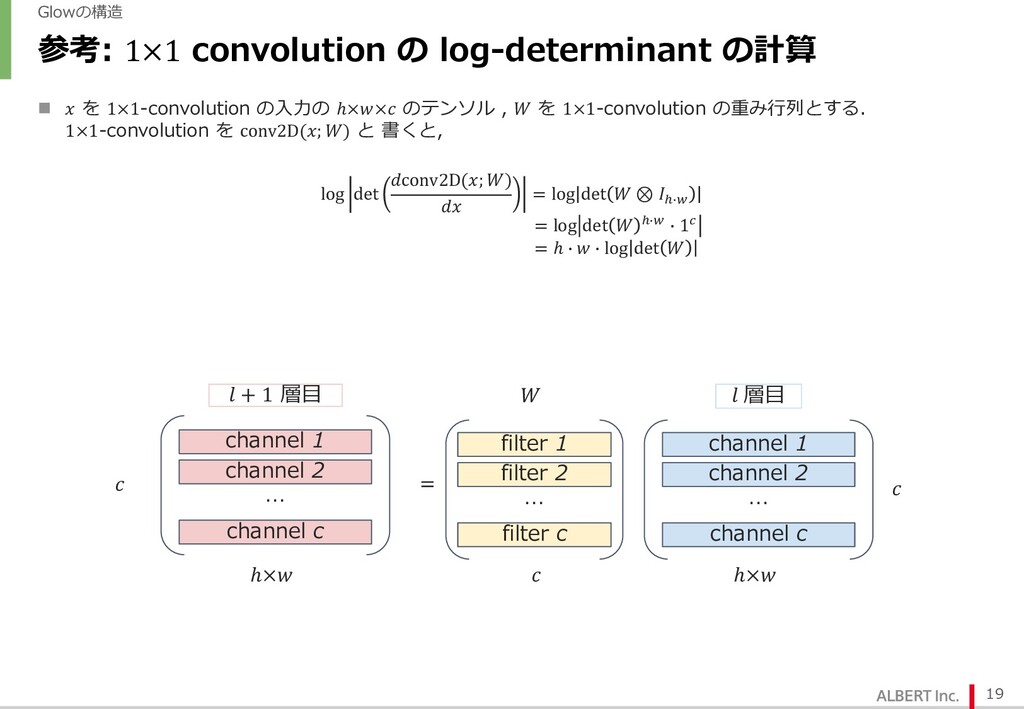{kind=link}
![Affine coupling layers 20 Glowの構造 出典: [Kingma & Dhariwal., 2018.]](https://files.speakerdeck.com/presentations/2c7ee557d2cd4d309bb045611b9d4797/slide_19.jpg){kind=link}
{kind=link}
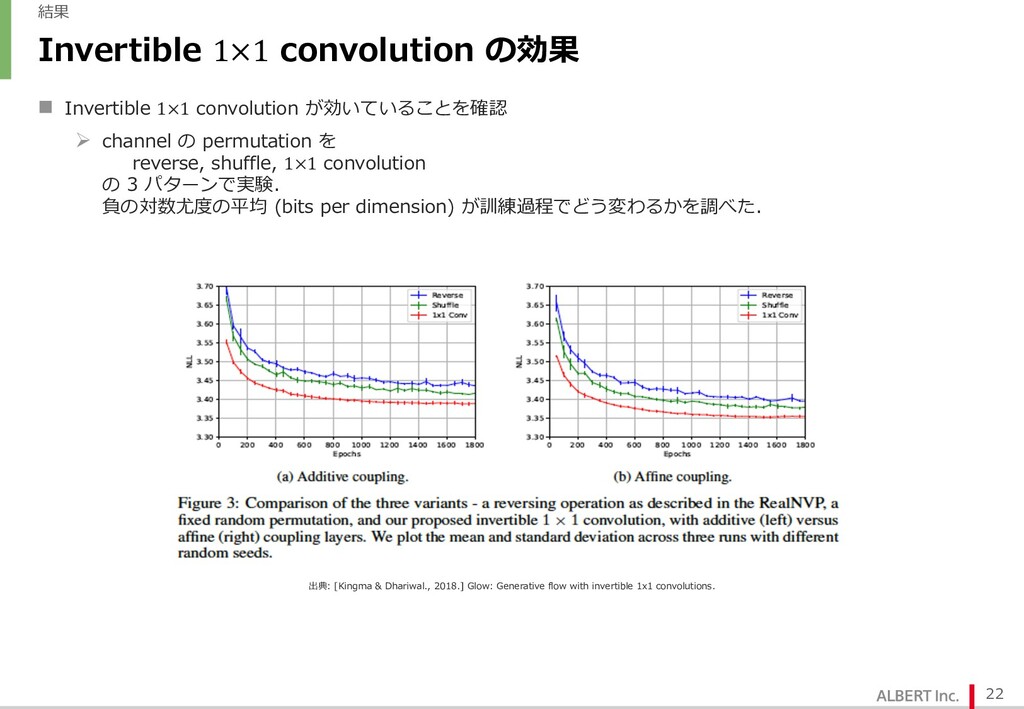{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考⽂献 n 論⽂ (✔ はサーベイ) Ø [Dinh et al., 2014.]](https://files.speakerdeck.com/presentations/2c7ee557d2cd4d309bb045611b9d4797/slide_27.jpg){kind=link}
{kind=link}