Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Elasticsearch Education
Search
Akira Morikawa
April 10, 2018
Technology
110
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Elasticsearch Education
初心者向けに実施したElasticsearch社内勉強会の資料です。
Akira Morikawa
April 10, 2018
More Decks by Akira Morikawa
See All by Akira Morikawa
コロナ禍だからこそ考えるオフラインコミュニティの意義 / significance of community
ariaki
0
2.2k
アウトプットの始め方/start output 20230121
ariaki
0
360
web-secure-phpcon2020
ariaki
3
3.7k
オブジェクトライフサイクルとメモリ管理を学ぼう / OOC 2020
ariaki
8
4.1k
エンジニアはアウトプットによって成長できるのか? / Grow with your output
ariaki
24
6.8k
アウトプットを始めよう / How to begin output jawsug-bgnr
ariaki
2
4.1k
参加者の安全を守れていますか? / Protecting community safety
ariaki
1
7.7k
タピオカに学ぶ二段階認証 / tapioca-mfa
ariaki
5
1.4k
古に学ぶ個人開発のススメ / My recommendation of personal development
ariaki
1
1.6k
Other Decks in Technology
See All in Technology
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.5k
Aurora MySQL 8.4リリース! Rubyistが備えること / what-rubyist-should-prepare-for-aurora-mysql-8-4
fkmy
0
1.1k
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
220
発表と総括 / Presentations and Summary
ks91
PRO
0
200
「守りたい体験」を渡すだけで E2E を生成させられるようになった話
hinac0
2
1.1k
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
330
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
460
kaonavi Tech Night#1
kaonavi
0
160
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
170
壊して学ぶAWS CDK: そのcdk deployで消えるもの、残るもの
k_adachi_01
1
490
アップデートで何が変わった?デモで学んで使いこなすIBM Bob2.0
muehara
0
250
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
6
1.3k
Featured
See All Featured
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Paper Plane
katiecoart
PRO
2
52k
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
Chasing Engaging Ingredients in Design
codingconduct
0
240
Bash Introduction
62gerente
615
220k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
230
Faster Mobile Websites
deanohume
310
32k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
The Invisible Side of Design
smashingmag
301
52k
RailsConf 2023
tenderlove
30
1.5k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Transcript
Elasticsearch 勉強会 #1 株式会社メディアドゥ プロダクト開発部 この資料は、Creative Commons 4.0 国際ライセンスに基づいて配布されます https://creativecommons.org/licenses/by/4.0/
ver. 1.0.1
の回し者ではありません Disclaimer Elasticsearchを始めてみよう https://www.elastic.co/jp/videos/getting-started-elasticsearch
全文検索システムはなぜ必要? ・既存のRDBMSで主に使われているインデックスはB-Tree →先頭一致検索を主目的としている為、部分一致検索に弱い ・SQL言語の仕様では全文検索に対する適切解がない →転置インデックスをSQL仕様外で実装する必要がある 2つのアプローチ ①既存のRDBMSに組み込む ②全文検索システムを構築する
2つのアプローチ ①既存のRDBMSに組み込む ②全文検索システムを構築する Oracle Oracle Text MySQL Mroonga(Groonga) PostgreSQL PGroonga(Groonga)
・SQLがそのまま使える ・既存リレーションを流用できる ・複雑な結合検索が可能 Lucene http://lucene.apache.org/ Solr http://lucene.apache.org/solr/ Elasticsearch https://www.elastic.co/ ・より洗練された高速システム ・ファセット等の高度検索が使える ・システムの拡張性が高い
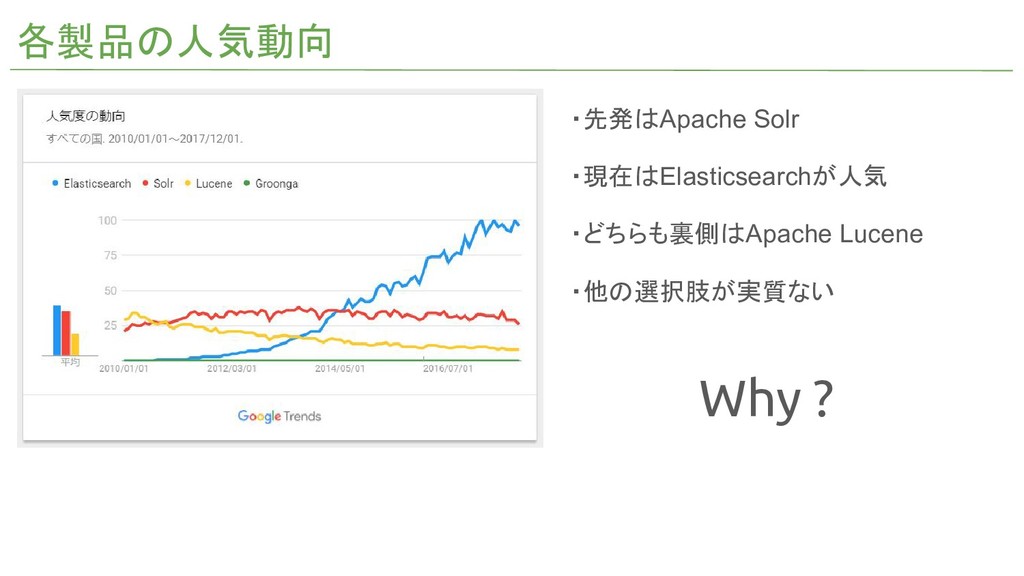
各製品の人気動向 ・先発はApache Solr ・現在はElasticsearchが人気 ・どちらも裏側はApache Lucene ・他の選択肢が実質ない Why ?
各製品の比較 ぶっちゃけ検索機能とクラスタ構築のしやすさが選定条件です。 あとはサポート体制とか、クラウド対応状況とか、見た目のかっこよさとか。 機能面ではほぼ遜色ないので、流行にのる方が楽に開発できます。 ※ただしElasticsearchの公式ドキュメントは英語だし割と雑です。 ※詳細は以下の記事を読んでください https://www.slideshare.net/shinsuke/solr-vses2014 http://solr-vs-elasticsearch.com/ http://mojavy.com/blog/2014/02/10/search-engine-comparison/
Elasticsearchの特徴 ①RDBMSではないのでSQLは使えない(REST+JSON) ②分散処理を基本とした高可用性スケーラブルシステム ③マルチテナント型 ④スキーマレス・ドキュメント指向 ⑤シングルドキュメントタイプ(Flat mapping) ⑥強力なAggregation機能 ⑦Kibanaによる可視化が容易
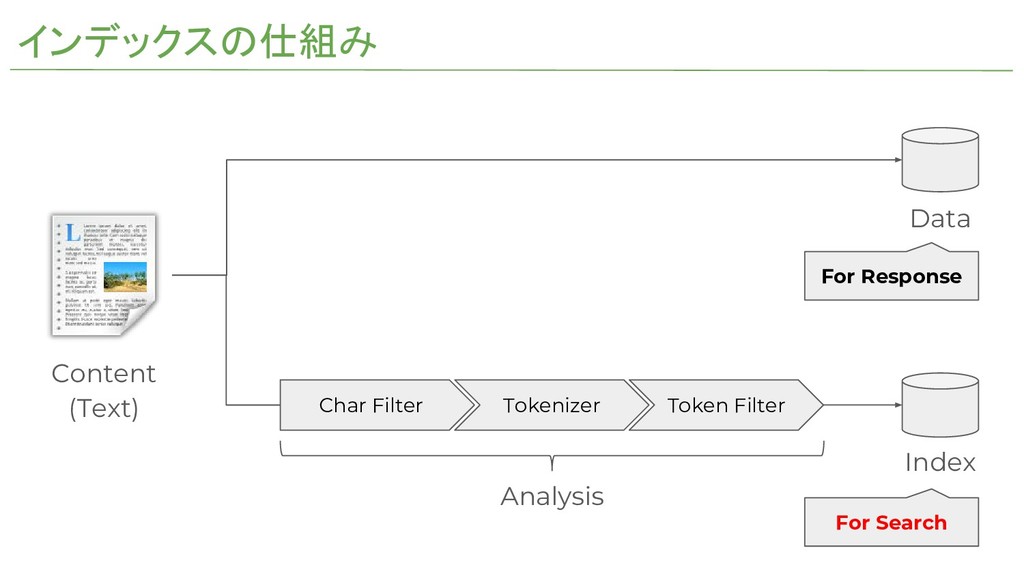
インデックスの仕組み Char Filter Tokenizer Token Filter Content (Text) Data Index
Analysis For Response For Search
インデックスの仕組み ①Char Filter テキストに対して事前処理をする。 例)HTMLタグ削除、カナ→かな、LowerCase、等 ②Tokenizer テキストをアルゴリズムに基づき単語(トークン)に分割する。 ③Token Filter 単語ごとに事後処理をする。
例)動詞を原形に統一する、名詞を単数形に統一する、長音除去、等 Elasticsearchでは、それぞれがプラグイン(拡張機能)として提供されている。 https://www.elastic.co/guide/en/elasticsearch/plugins/current/index.html
インデックスの仕組み - Tokenizer ①形態素解析 英文は単語ごとにスペースで区切る(わかち書き)仕組みの為に単語を検索するのは容易 だが、日本語は区切らず続けて書くために単語単位での検索が難しい。 これを解消し、ワード単位の検索を実現するため、文章を「形態素」という単位で区切ってイ ンデックスする。 この仕組みではワード検索は高速になるが、その反面で予め準備されている単語辞書にな いもの(ひらがな等)の分割解釈が難しく、検索漏れが発生する。
インデックスの仕組み - Tokenizer ①形態素解析 例)今日はいい天気です 今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー は 助詞,係助詞,*,*,*,*,は,ハ,ワ いい
形容詞,自立,*,*,形容詞・イイ,基本形,いい,イイ,イイ 天気 名詞,一般,*,*,*,*,天気,テンキ,テンキ です 助動詞,*,*,*,特殊・デス,基本形,です,デス,デス ※この例だと「はい」等で検索してもヒットしない
インデックスの仕組み - Tokenizer ②N-Gram 予め指定したN文字単位で文字を分割してインデックスする手法。 ・Uni-gram (1グラム) → 1文字ずつインデックスを作成する。 ・Bi-gram(2グラム)
→ 2文字ずつインデックスを作成する。 : この仕組みでは検索漏れが発生せず辞書も必要ないが、辞書肥大化と検索ノイズ発生が 懸念される。 ※検索ノイズ … たとえば「京都」を検索する場合、「東京都庁」の中間文字がヒットする。
インデックスの仕組み - Tokenizer ②N-Gram 例)今日はいい天気です 今日 / 日は / はい
/ いい / い天 / 天気 / 気で / です ・この仕組みでは検索漏れが発生せず、単語辞書も必要ない。 ・形態素解析と比べインデックスサイズが大きい。 ・検索ノイズが発生する。 ※たとえば「京都」を検索する場合、「東京都庁」の中間がヒットする。
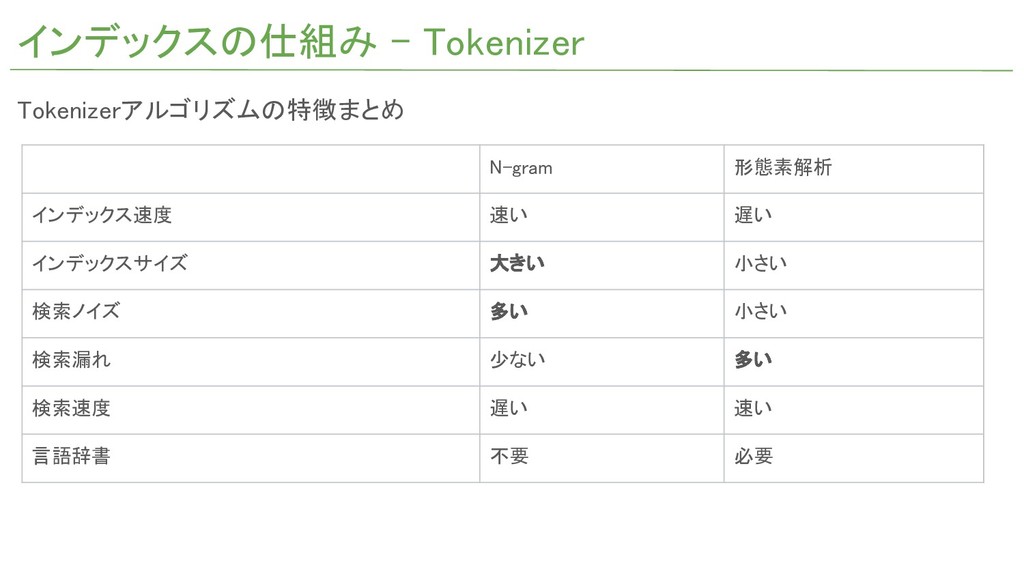
インデックスの仕組み - Tokenizer N-gram 形態素解析 インデックス速度 速い 遅い インデックスサイズ 大きい
小さい 検索ノイズ 多い 小さい 検索漏れ 少ない 多い 検索速度 遅い 速い 言語辞書 不要 必要 Tokenizerアルゴリズムの特徴まとめ
検索精度 全文検索はその仕組み上、入力されたキーワードに対して完全一致検索を行わないため、 取得データが完璧な精度にならない。 用語 英名 説明 正しい結果 True Positive 検索結果として返していて、ユーザが求めていた情報。
検索ノイズ False Positive 検索結果として返していて、ユーザが求めていない情報。 検索漏れ False Negative ユーザが求めているのに、検索結果に含ませない情報。 ※不正確なデータは防ぎようがなく、一方を減らすともう一方が増えてしまう。 →検索ノイズは我慢できるけど、検索漏れは防ぎたいよね?
検索精度 TF/IDF 検索結果にはTF/IDFによるスコアが設定される。 文書内におけるワードの出現頻度に基づき、頻度が高い順でスコアリングされる。 またワードの短さも評価対象となり、長文よりも短文上に出現した方が高くなる。 TF … ある文書の中に出現する索引語の頻度です。 文書中にその単語が何回現れたか(Term
Frequency)を表します。 DF … 文書全体でその単語が何回現れたか(Document Frequency)を表します。 ※IDFはDFの対数(Inverse Document Frequency) Wikipedia - TF/IDF https://ja.wikipedia.org/wiki/Tf-idf
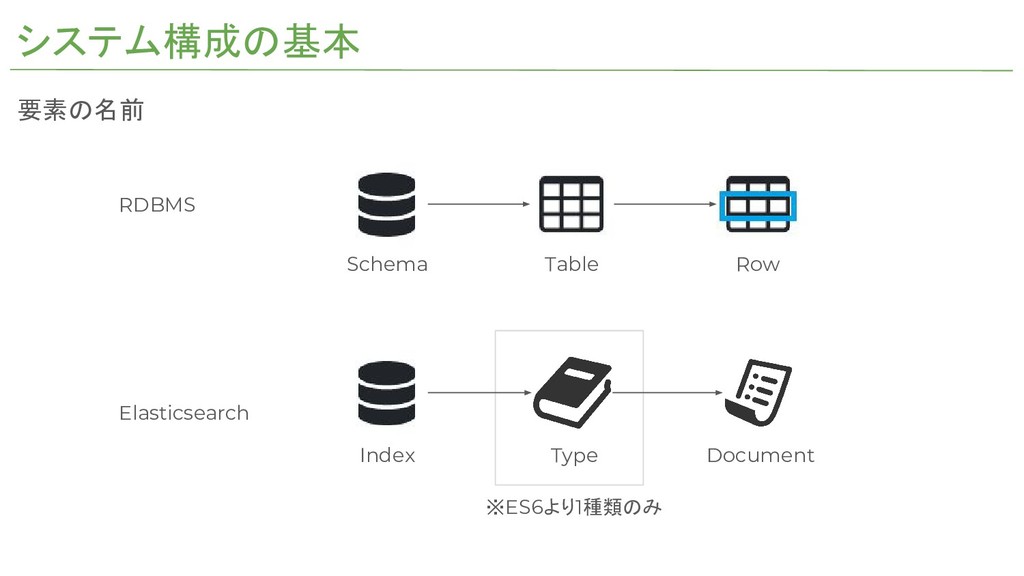
システム構成の基本 Schema Table Row RDBMS Elasticsearch Index Type Document ※ES6より1種類のみ
要素の名前
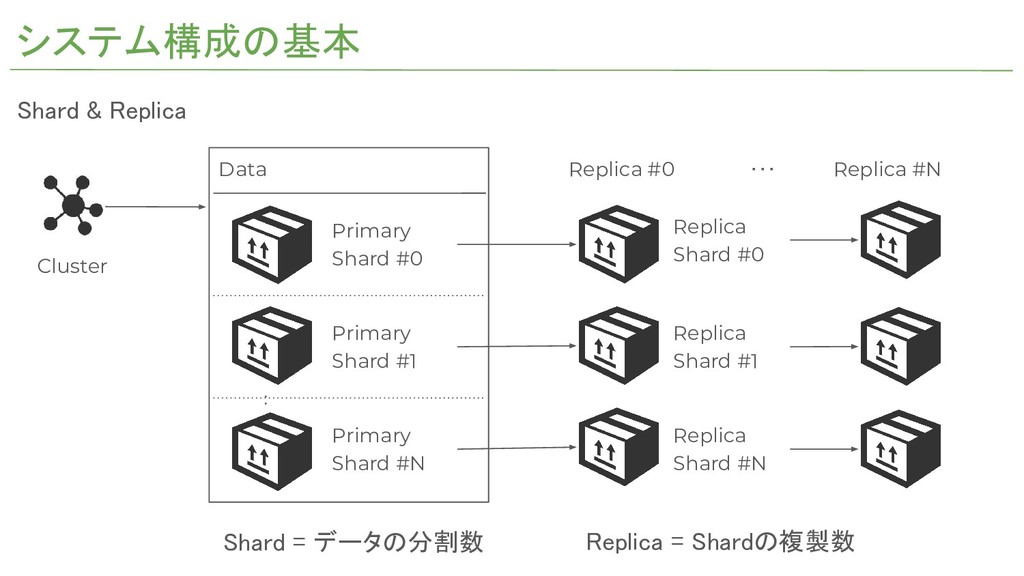
Shard = データの分割数 システム構成の基本 Cluster Data Primary Shard #0 Primary
Shard #1 Primary Shard #N : Replica Shard #0 Replica Shard #1 Replica Shard #N Replica #0 Replica #N ・・・ Shard & Replica Replica = Shardの複製数
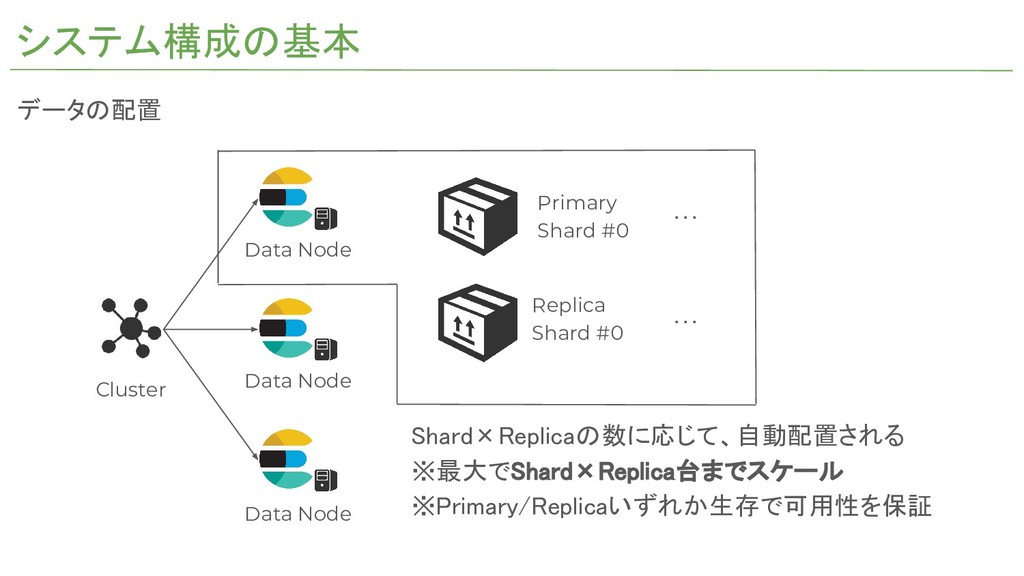
システム構成の基本 Cluster Data Node Data Node Data Node Primary Shard
#0 Replica Shard #0 ・・・ ・・・ データの配置 Shard×Replicaの数に応じて、自動配置される ※最大でShard×Replica台までスケール ※Primary/Replicaいずれか生存で可用性を保証
システム構成の基本 ノードの種類 ①Master-eligible Node シャードを管理する機能を有するMaster Nodeの候補となる。 この中からMaster Nodeが自動選出される。 ※Split Brain対策として台数は2n-1台とする必要がある。
②Data Node データを保持・操作(CRUD)する為のノード。 ※マスターノードと兼務する事が可能。 ③Ingest Node… データのパイプライン処理(自動変換)を行う為のノード。 ④Tribe Node … 複数クラスタを接続して横断検索する場合に必要なノード。
システム構成の基本 クラスタ構成の検討方法 ①シャード数の算出 シャードあたりのデータサイズを30GB以下にするよう推奨されている。 ②レプリカ数の検討 可用性と保全性をあげるため、レプリカを1つ以上作成する事が推奨される。 ③ノード辺りのシャード数の検討 ノード内に複数のシャードを配置可能だが、クラスタ速度はシャード数が 一番大きいノードに引きずられるため、均等に分散されることが好ましい。 ※Node数=PrimaryShard数ができれば最高
Elasticsearchの歴史 ネットの古い記事はやばい ・これまでバージョン1→2→5→6と変遷してきた ・リリース頻度は年1回程度(のはず) ・他に類を見ない Breaking Changes のバーゲンセール ・2→5では仕様変更のせいで大量のプラグインがDISCONになった ・5→6ではTypeが廃止になった
・今後も仕様変更がいっぱいあると思うのでバージョンアップは相当やばい ・数年前の記事は割と使えない事が多い ・機能が追加されまくってるんできっと幸せになれる事もあるはず ↓阿鼻叫喚レベルの仕様変更たち https://www.elastic.co/guide/en/elasticsearch/reference/5.0/breaking-changes-5.0.html https://www.elastic.co/guide/en/elasticsearch/reference/6.0/breaking-changes-6.0.html
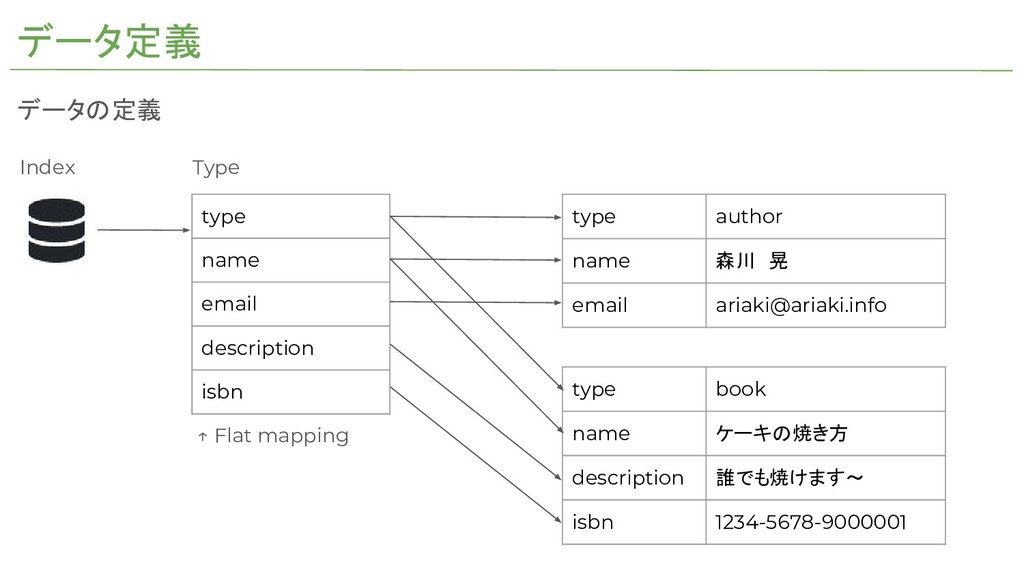
データ定義 Index データの定義 type name email description isbn type author
name 森川 晃 email
[email protected]
type book name ケーキの焼き方 description 誰でも焼けます~ isbn 1234-5678-9000001 ↑ Flat mapping Type
データ定義 GET http://localhost:9200/_search { "query": { "bool": { "must": {
← 検索条件設定(重み付けに影響 する) "match": { "name": "森川 晃" } }, "filter": { ← フィルタ設定(重み付けに影響 しない) "match": { "type": "author" } } } } } データの検索方法 独自のQueryDSLというJSONを記述して、検索する。
データ定義 データ型 通常のRDBMSと同様の型が存在する。 テキスト型 text, keyword 数値型 long, integer, short,
byte, double, float, half_float, scaled_float 日付型 date 真理値型 boolean バイナリ型 binary 範囲型 integer_range, float_range, long_range, double_range, date_range その他 Array, Object, Nested, … etc.
データ定義 2種類のテキスト型 ① text 全文検索を使用するためのテキスト型。 ② keyword 全文検索を使用しない(完全一致検索のみの)テキスト型。
データ定義 マッピング定義 Elasticsearchに予めマッピング情報を定義する事ができる。 ・settings … index, analysis 等の基本情報を設定する。 ・mappings …
フィールドマッピングを設定する。 ドキュメント登録時に同名のフィールドが存在する場合、マッピング定義に基づいてインデッ クス処理される。 ※同一フィールド名が存在しない場合もエラーとならない為、注意が必要。
データ定義 マッピング定義 マッピング時に利用できるオプションでよく使うものは以下の通り。 analyzer settings.analysis.analyzer定義名 index インデックスし、検索対象とするか( true/false) ※ES6から仕様変更になったので注意 store
オリジナルデータを”store”リストに保持するか( true/false) ※設定しなくても”_source”リストからとれるが、こちらのほうが高速 fielddata データをメモリキャッシュしソート対象とするか( true/false) ※text型はデフォルトfalseとなるため、利用する場合には設定が必要
データ定義 マッピング変更 Elasticsearchによって提供されているマッピング変更コマンドを使用した場合、 既存データには影響しません。 全データの再構築が必要な場合はreindexコマンドを使用します。 これは仕様変更を適用して新しいindexにコピーするコマンドになります。 このような処理が頻発するので、aliasを設定しそちらを参照するのが一般的です。 ・旧index→新indexを作成(reindex) ・aliasを使って参照先を新indexに張り替え ・問題なければ折をみて旧indexを削除
データ定義 親子関係の構築 Type内のデータ同士に親子関係を持たせるためにJoin Data Typeがある。 { "mappings": { "doc": {
"properties": { "parent_or_child": { ← 結合キー名(名前はなんでもいい) "type": "join", “relations”: { “target”: “child” ← 親子識別キーワード(名前はなんでもいい) } } } } } } Elasticsearch 6.1 - Join Data Type https://www.elastic.co/guide/en/elasticsearch/reference/current/parent-join.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}