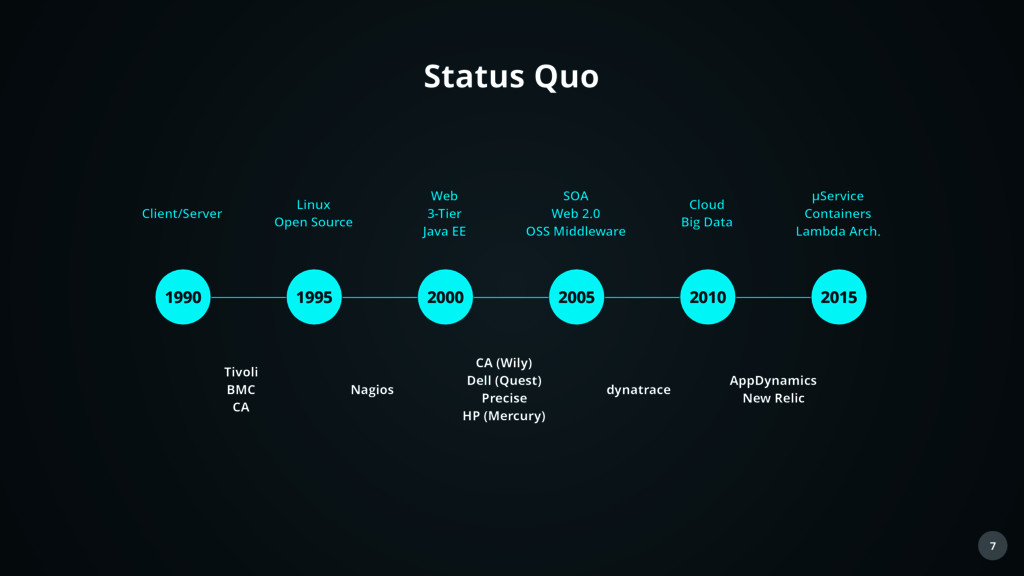
Linux Open Source Web 3-Tier Java EE SOA Web 2.0 OSS Middleware Cloud Big Data µService Containers Lambda Arch. Tivoli BMC CA Nagios CA (Wily) Dell (Quest) Precise HP (Mercury) dynatrace AppDynamics New Relic
schwer zu ermitteln oder ungenau. • “Korrelation” zwischen Technologien fragil oder unmöglich. • In asynchronen, reaktiven, eventually consistent Anwendungen nicht mehr existent. • Beantworten keine Fragen von Betrieb oder Entwicklung.
• Zusammenhänge müssen mühsam herausgefunden werden. • Aussagekraft wird durch falsche Konfiguration reduziert. • Kleine Graphen produzieren Datenmatsch.
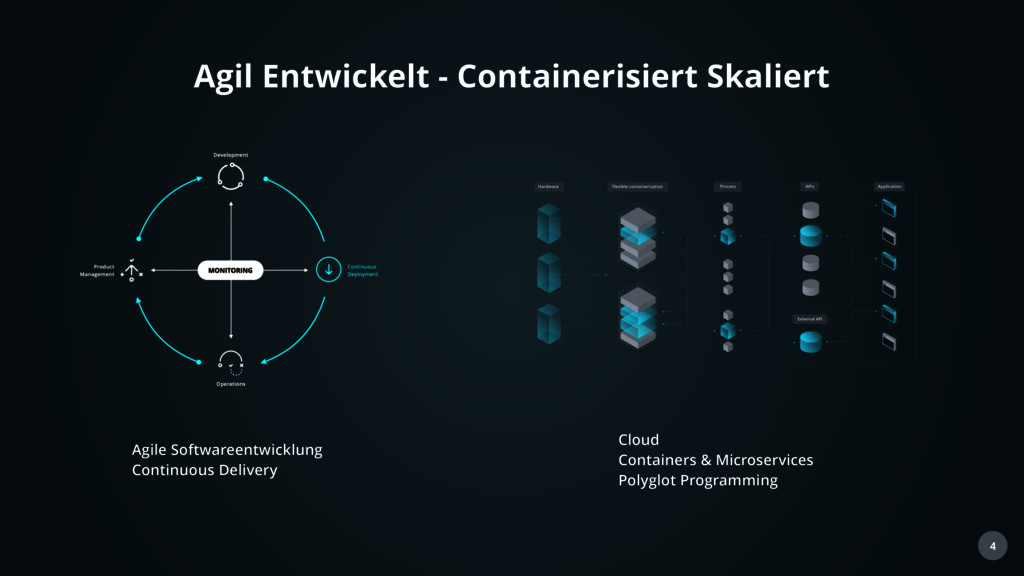
die Funktionsweise der Anwendung höher. • Benötigen auch: • Übersicht über das Gesamtsystem • Verlässliche Zustandsmeldung • Optimierungsvorschläge • Kapazitätsplanung
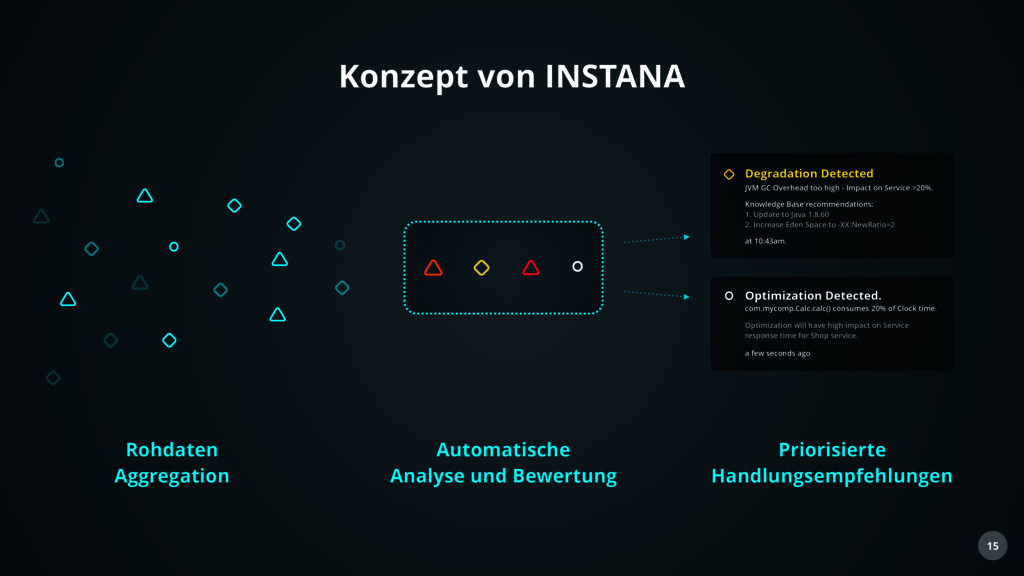
Detected JVM GC Overhead too high - Impact on Service >20%. Knowledge Base recommendations: 1. Update to Java 1.8.60 2. Increase Eden Space to -XX:NewRatio=2 at 10:43am. Optimization Detected. com.mycomp.Calc.calc() consumes 20% of Clock time. Optimization will have high impact on Service response time for Shop service. a few seconds ago Konzept von INSTANA
hoch oder niedrig gut? • Was für ein Typ ist der Wert? • Gauge: Ein aktueller Wert. • Counter: Aktueller Wert der nur inkrementiert. • Histogram: Wertevereilung über Zeit. • Meter: Wert pro Zeit (Rate). • Wie häufig ändert sich der Wert? • Gibt es Grenzwerte (Minimum, Maximum)?
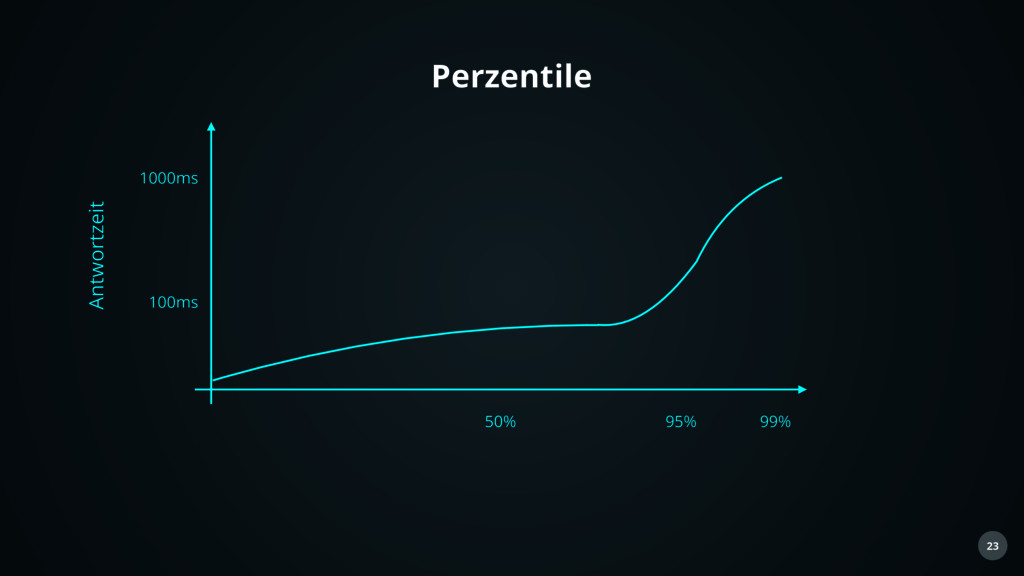
sinnvolle Aggregate wählen: • Average / Mean: selten sinnvoll. • Maximum, Minimum: Für Best/Worst Case Analysen. • 99th Percentile: “In der Regel Wert”. • Outlier bewahren. • Neue Grafentypen verstehen.
Load auf 2 von 8 Servern ist 4.3. • Cache Hit Ratio des EJBs ist 0. • Bandbreitennutzung auf dem Switch 8.3 GBit/s. • Disk /dev/sda 80% voll. • Willkürliche Korrelation macht keinen Sinn. • Fachliche Aussagekraft wünschenswert.
schwer. • Viele Unternehmen haben eine handvoll überlasteter Experten. • Viele Zusammenhänge sind aber überall gleich. • Ein Monitoringsystem sollte über eine Wissensbasis verfügen. • Problemlösungsdatenbanken funktionieren nicht. • Weil sie das Problem nicht kennen.
the status of all of our systems. … it is critical for us to have exceptional tools coupled with intelligent analysis to proactively detect and communicate system faults and identify areas of improvement 33 33
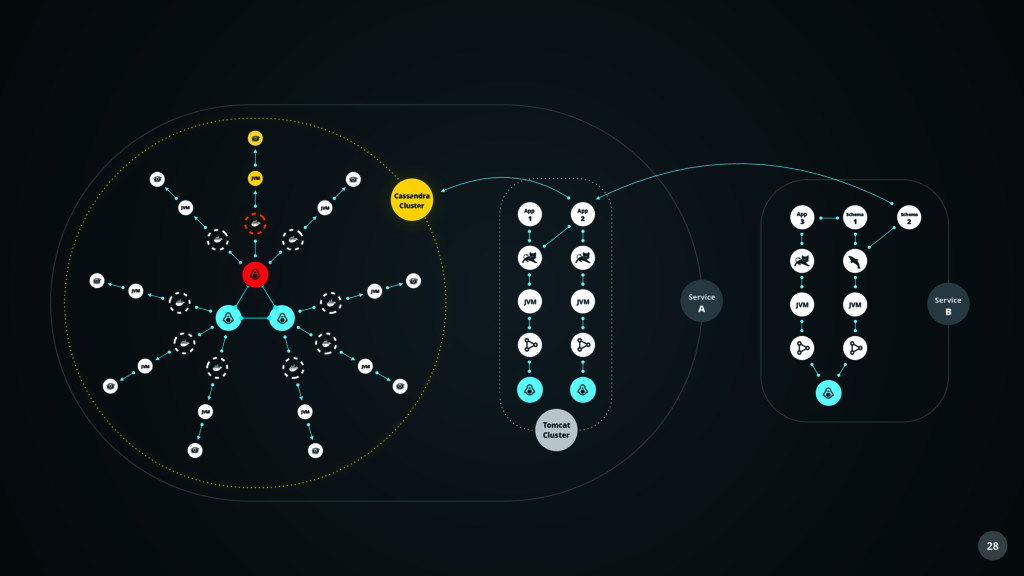
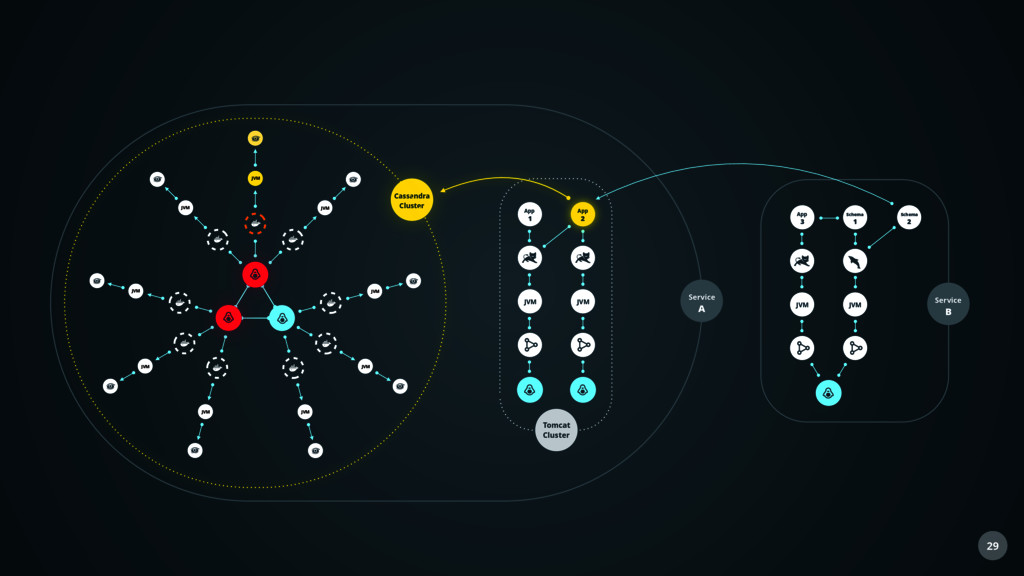
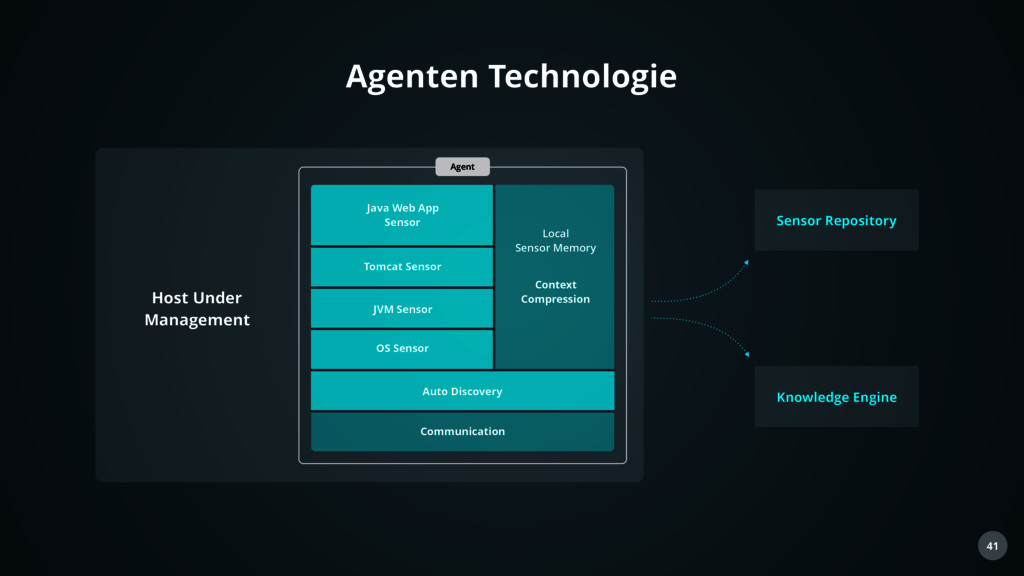
Sensor Auto Discovery Communication Local Sensor Memory Context Compression Host Under Management Sensor Repository Agent Knowledge Engine Agenten Technologie
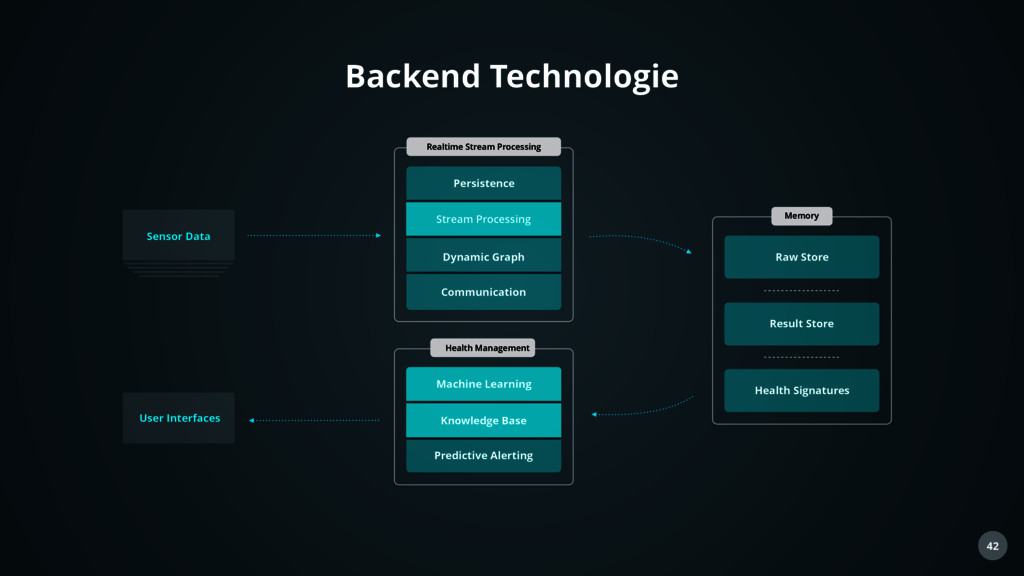
Stream Processing Machine Learning Knowledge Base Predictive Alerting Health Management Raw Store Memory Result Store Health Signatures User Interfaces Backend Technologie
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![43 @CodingFabian [email protected] lj speakerdeck.com/CodingFabian github.com/CodingFabian Noch Fragen?](https://files.speakerdeck.com/presentations/658d6c67f9d042bd9c8d9a0d8c5c4e35/slide_42.jpg){kind=link}