当⽇、会場で演者や司会のお⼆⼈も話されていたのが「減点されにくい曲」のスコアが今回⾼い、という印 象 ( ex : コード進⾏に合わない⾳、無⾳、単調なロングトーン等) • 絵やテキストと違って、⾳の場合は半⾳ずれるだけで違和感がmaxになることもあるので、独⾃の難しさは ありそう (絵のAI⽣成は指が多少おかしくても全体としては通⽤する) • また⾳楽データの場合は学習データも集めるのが難しそう (波形データの場合はノイズの問題、またミック スされた⾳の分離の問題。⼀⽅で⽣のMIDIデータは通常あまり⼤量には流通していない。また楽譜データの 場合は書き起こす必要がある) • ⾳声のテキスト化より、研究の優先度が低い可能性もあるのではないか ( ⾳声解析はビジネスインパクトが⼤きいが、⾳楽⽣成の場合は⼀部のユースケースに限定される? ) • Google謹製のMagentaでもまだ⼈間には及ばない状況なので、研究分野としてはまだまだ発展の余地があり そう • 「⾳楽のドメイン知識を⼊れる」 vs「理論を⼊れない他のアプローチ」の可能性を感じることができました • 以下、妄想ですがそのうちこの分野の進化が進むとゲームの曲とかも作曲指⽰でサクッと作れるようになる とゲーム開発なども捗るかもしれませんね・・!!
{kind=link}
{kind=link}
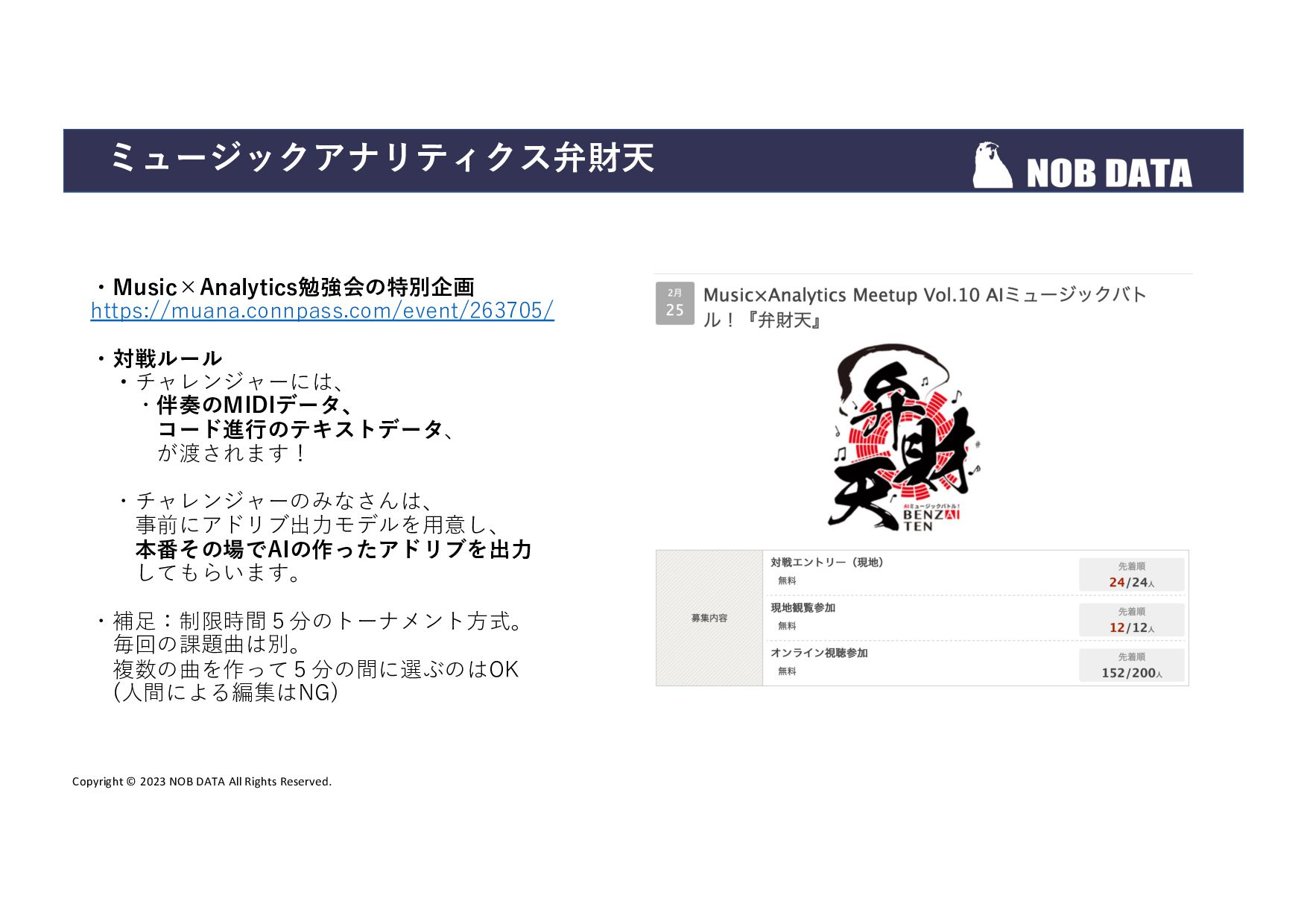{kind=link}
{kind=link}
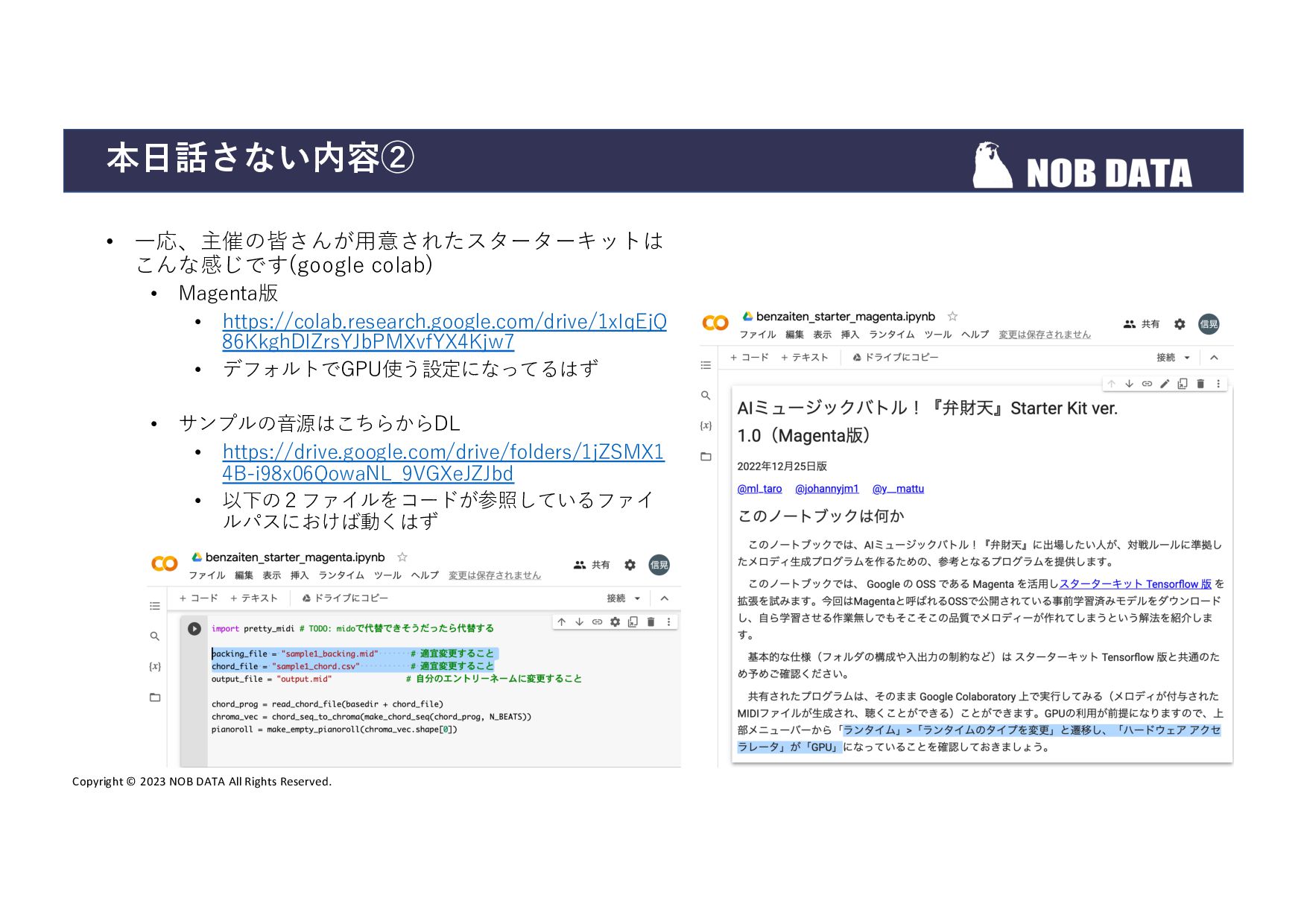{kind=link}
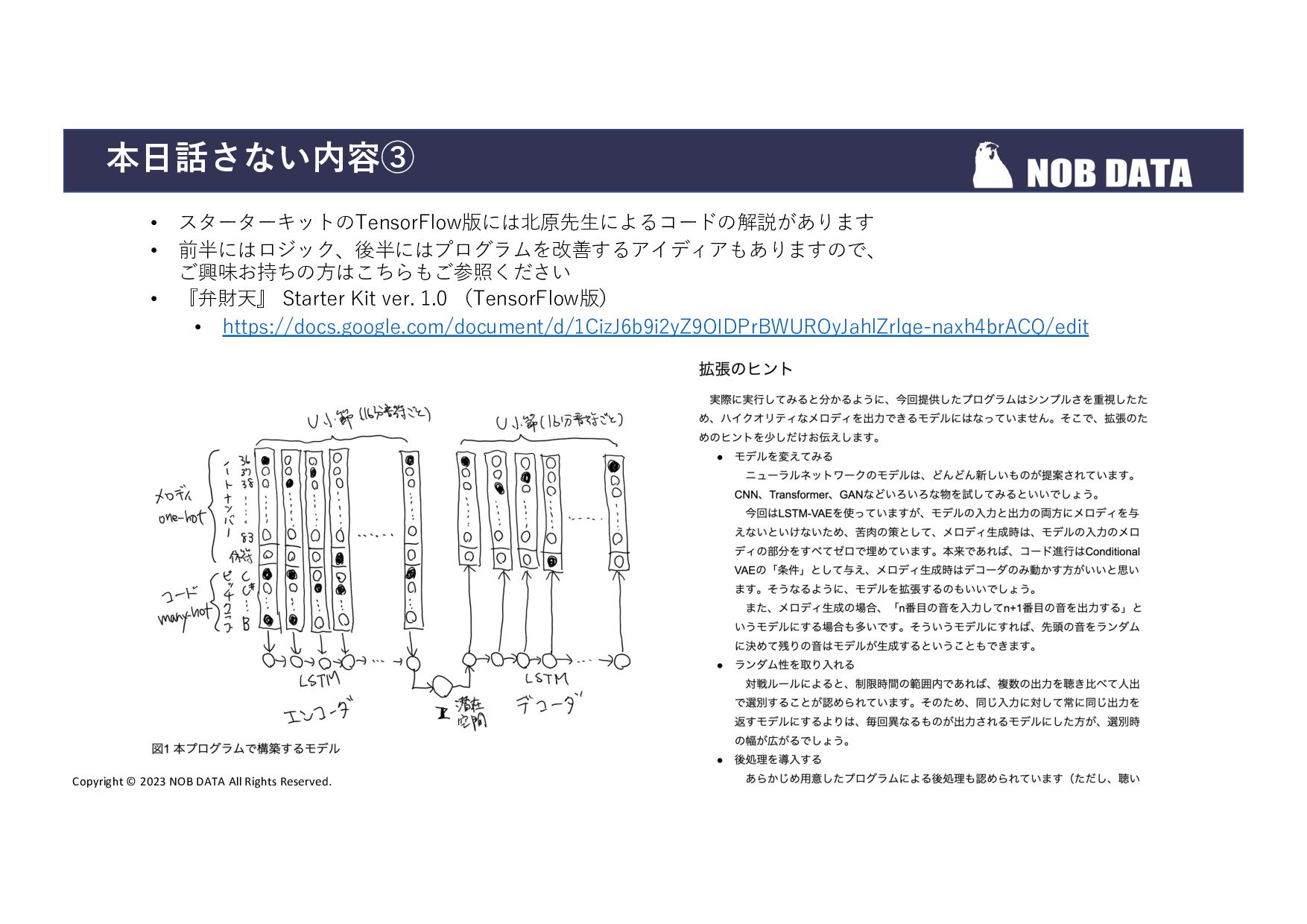{kind=link}
{kind=link}
{kind=link}
{kind=link}
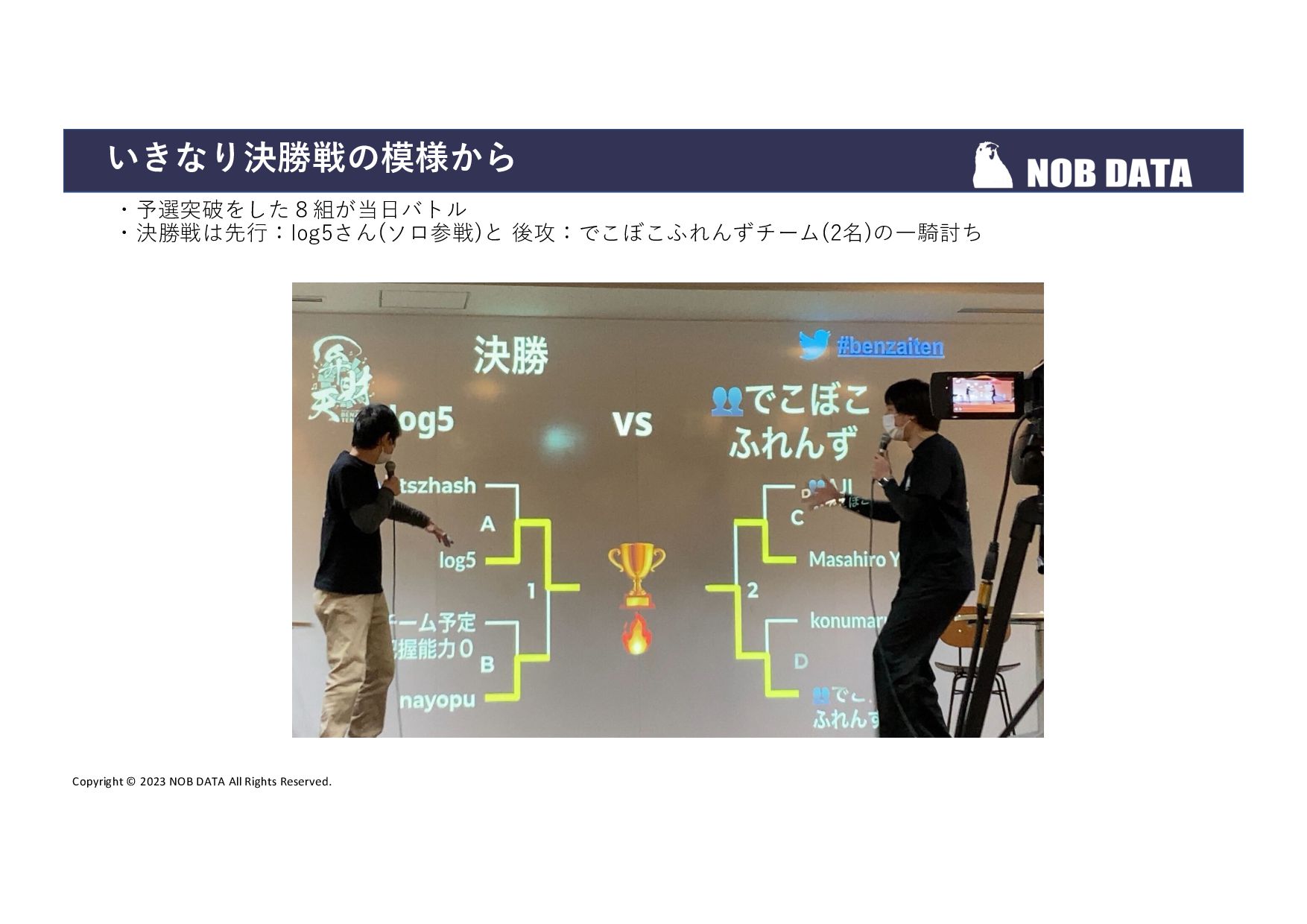{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}