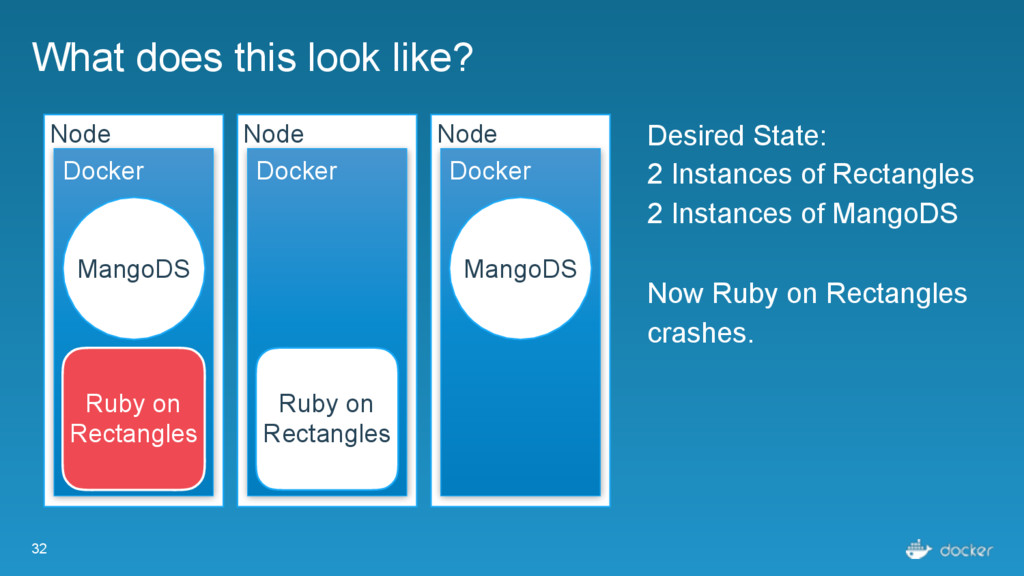
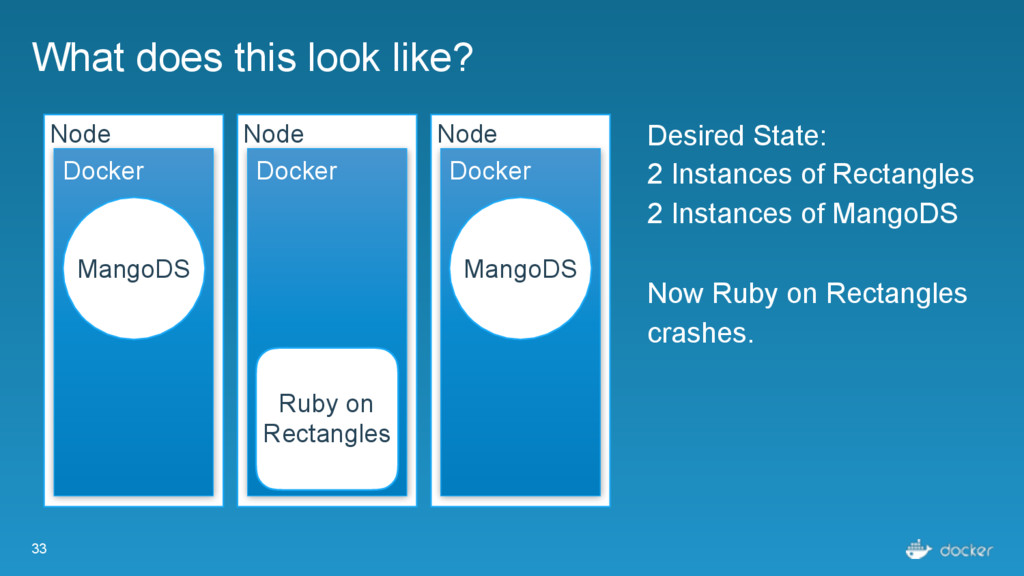
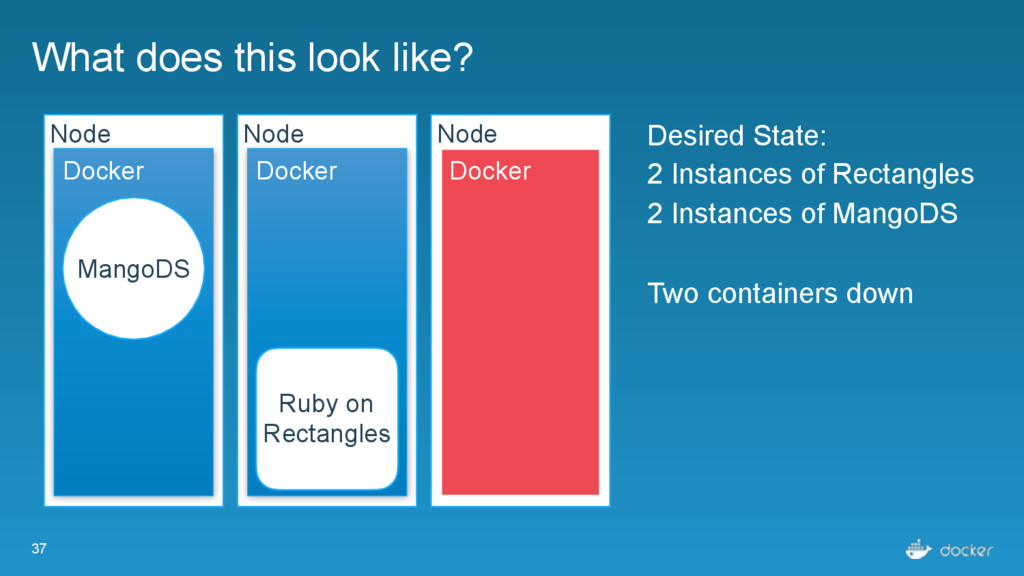
Rectangles Node Docker Ruby on Rectangles Node Docker Desired State: 2 Instances of Rectangles 2 Instances of MangoDS Now Ruby on Rectangles crashes. MangoDS MangoDS
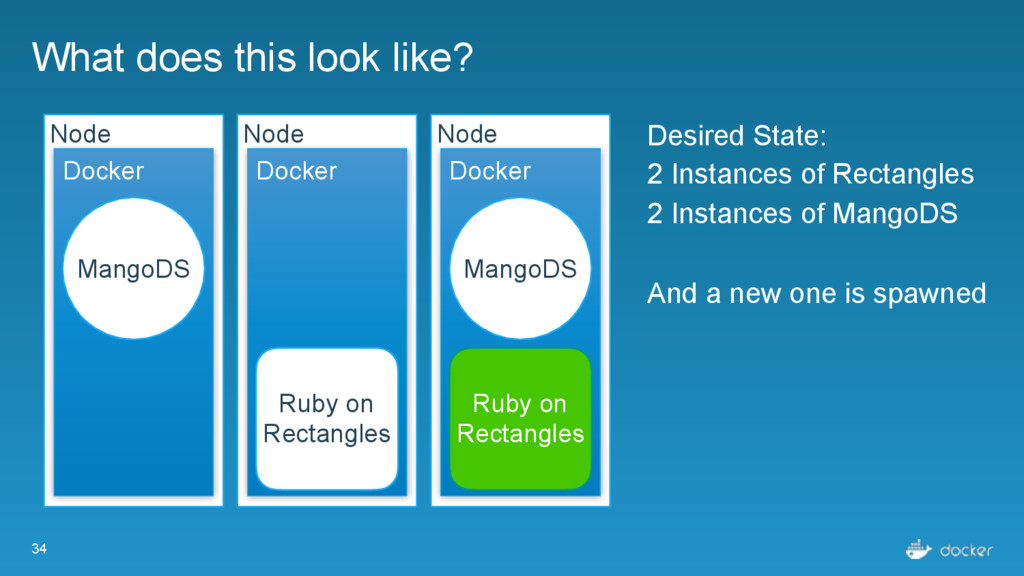
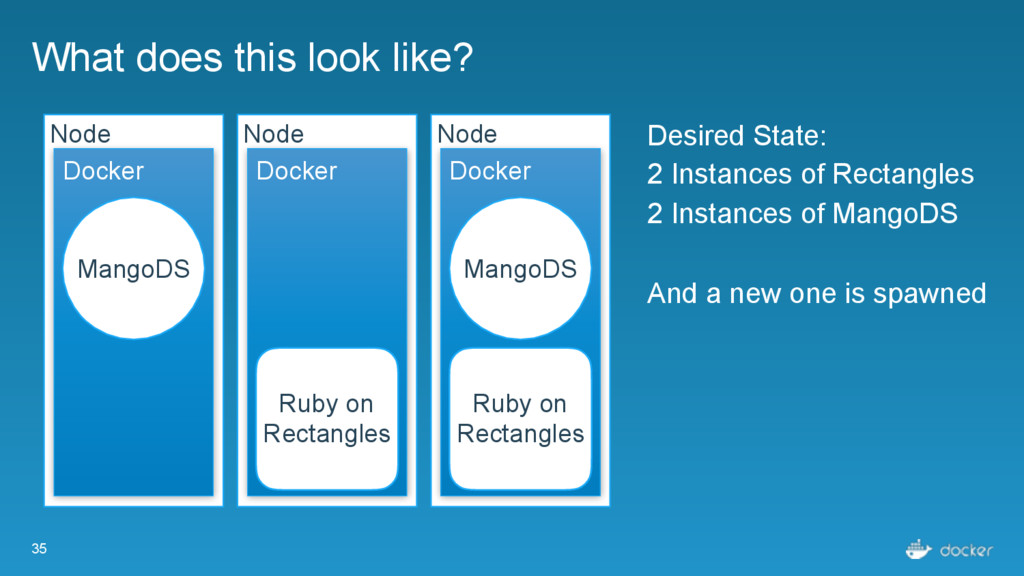
Ruby on Rectangles Node Docker Desired State: 2 Instances of Rectangles 2 Instances of MangoDS And a new one is spawned MangoDS MangoDS Ruby on Rectangles
Ruby on Rectangles Node Docker Desired State: 2 Instances of Rectangles 2 Instances of MangoDS And a new one is spawned MangoDS MangoDS Ruby on Rectangles
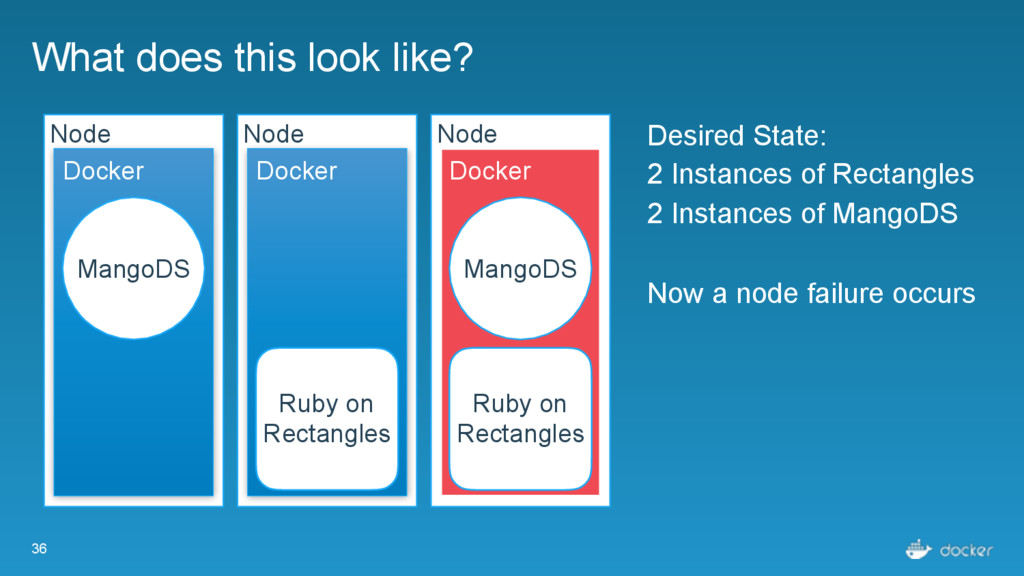
Ruby on Rectangles Node Docker Desired State: 2 Instances of Rectangles 2 Instances of MangoDS Now a node failure occurs MangoDS MangoDS Ruby on Rectangles
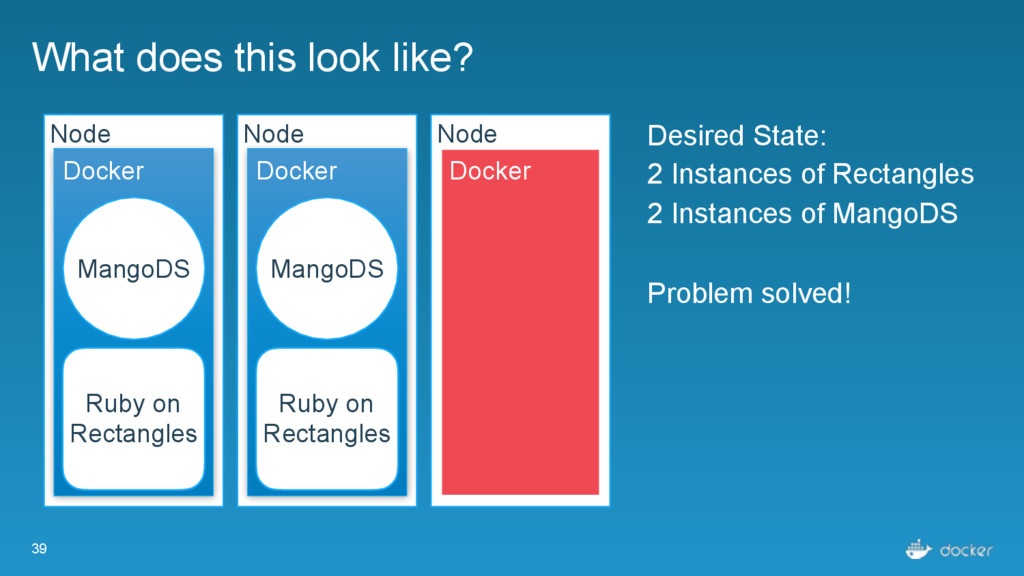
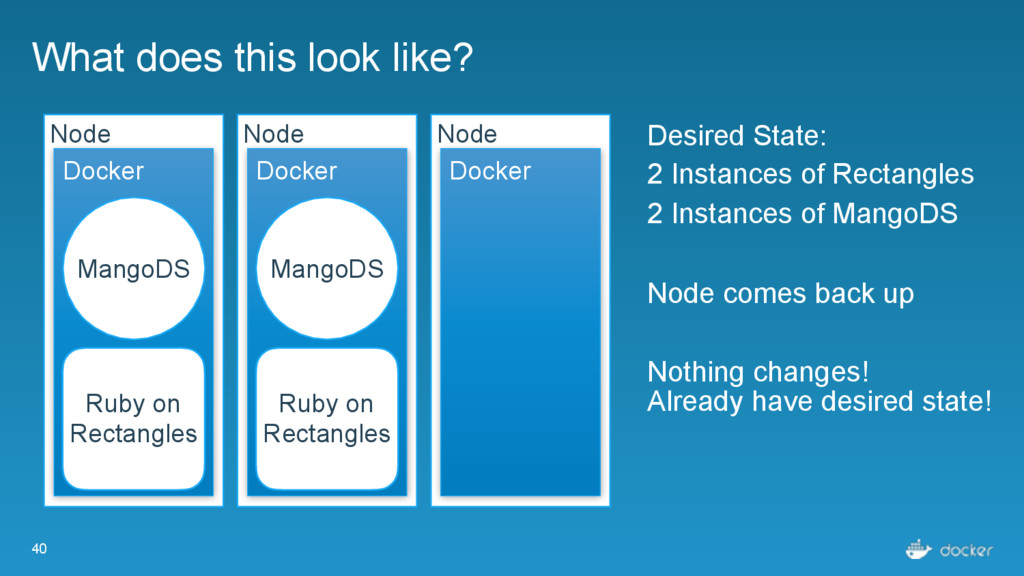
Rectangles Node Docker Ruby on Rectangles Node Docker Desired State: 2 Instances of Rectangles 2 Instances of MangoDS Node comes back up Nothing changes! Already have desired state! MangoDS MangoDS
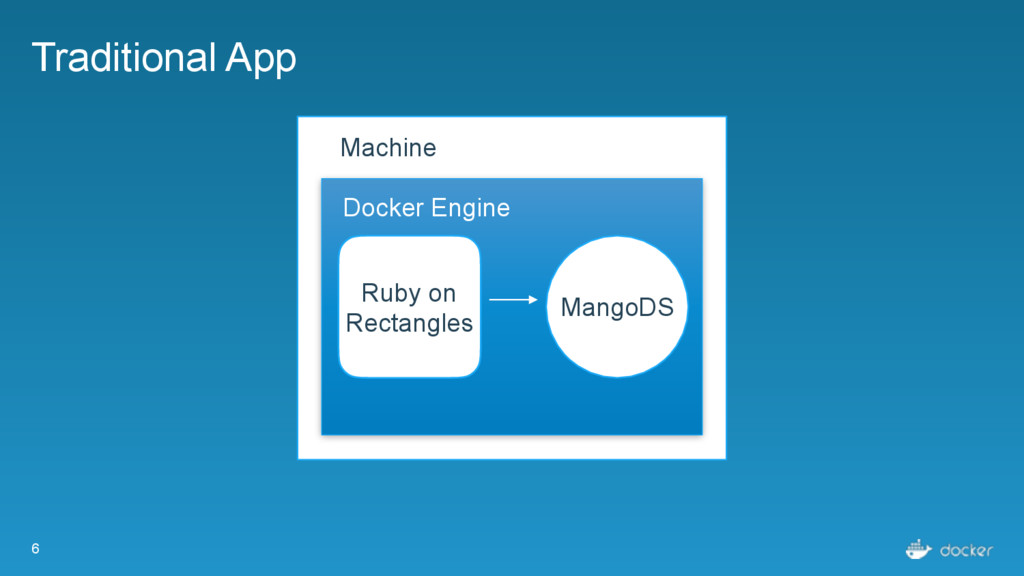
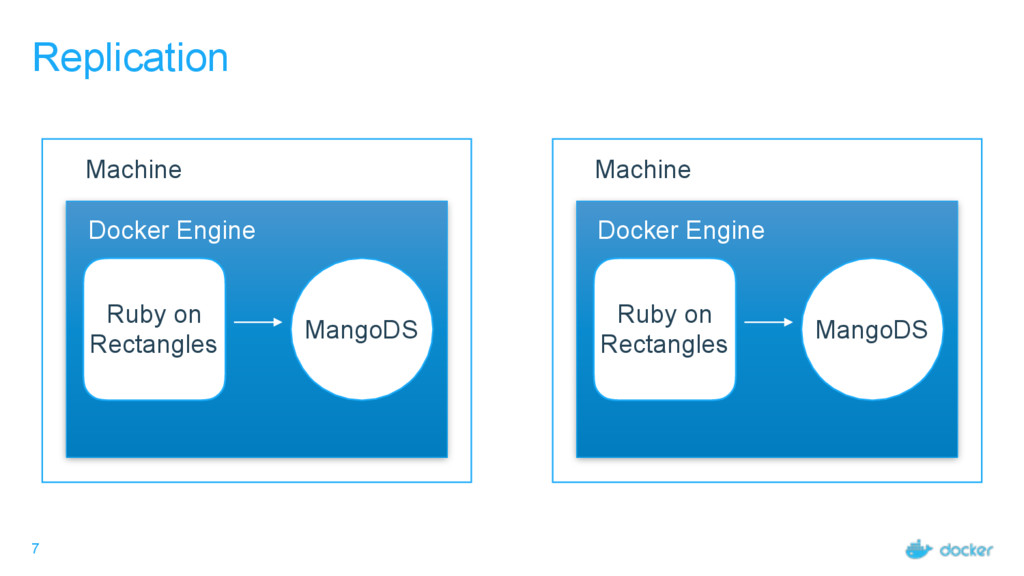
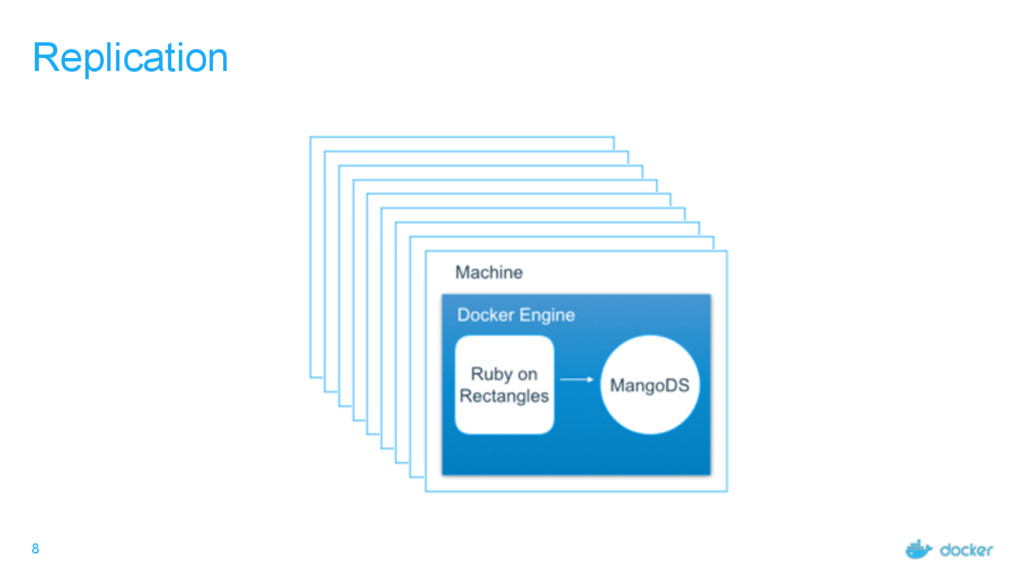
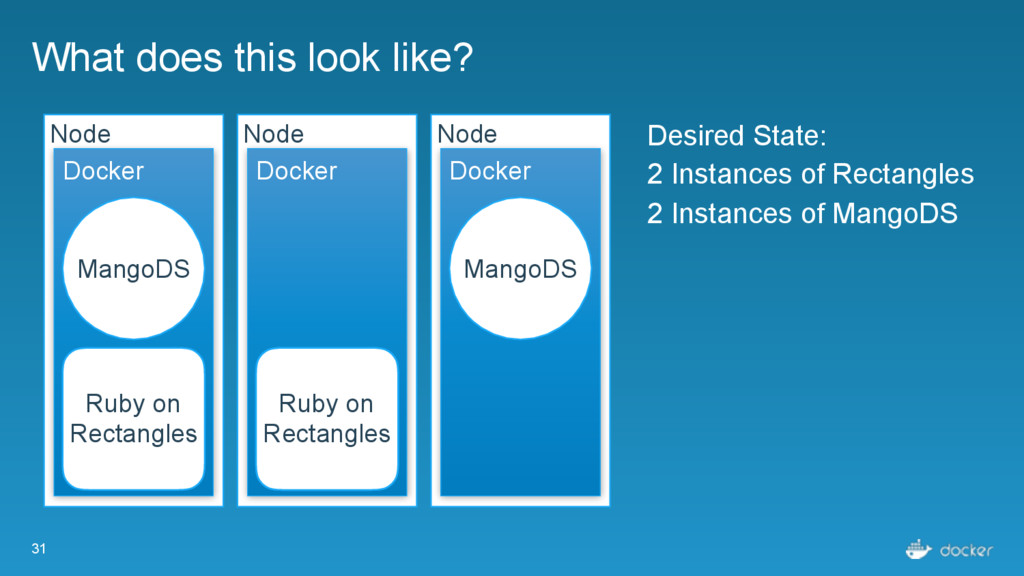
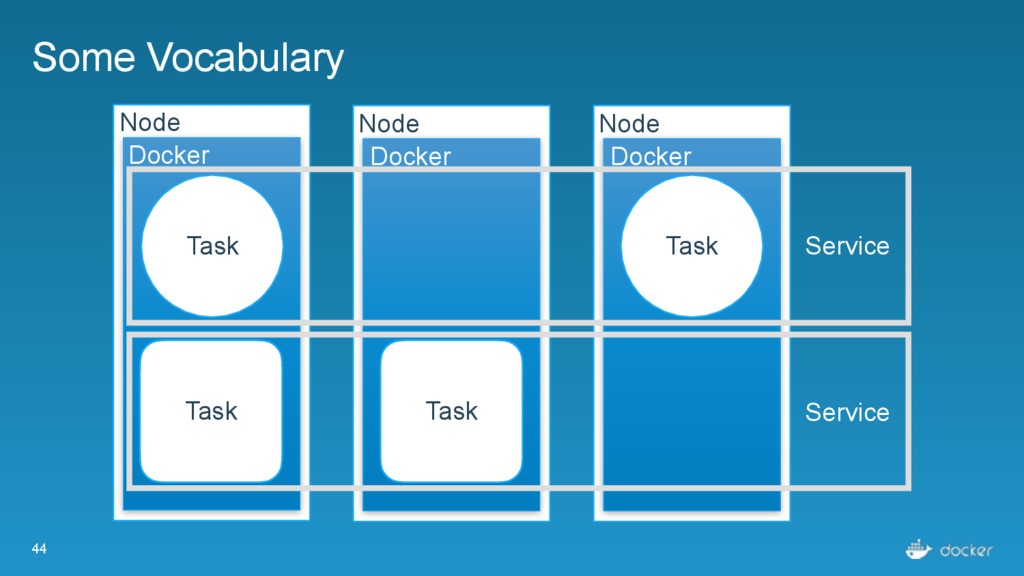
computing resources. One node is generally one Docker Engine Task - an individual atomic scheduling unit, belonging to a service. One task is generally one container. Service - Individual unit of desired state. Defines what application and how many replicas.
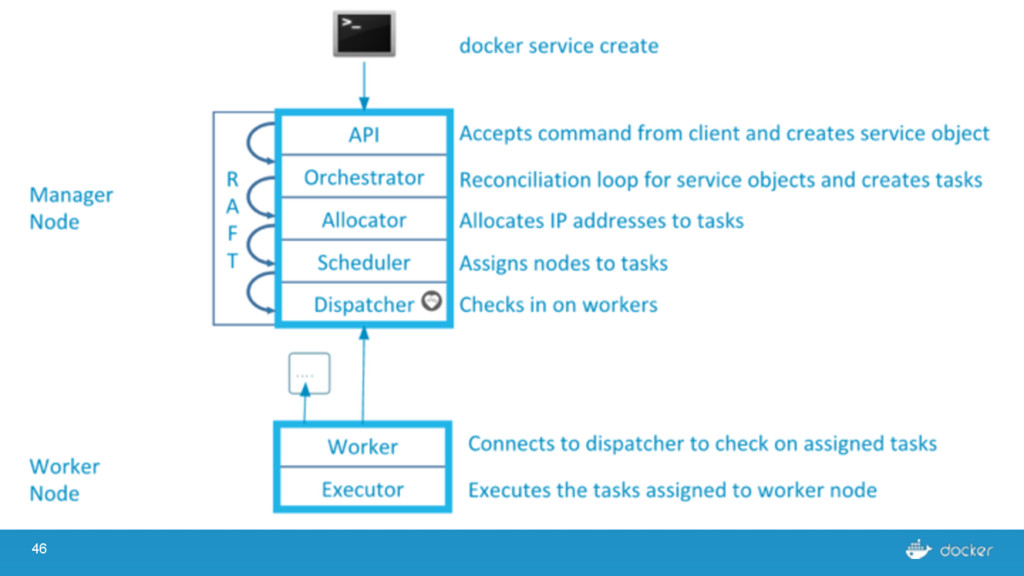
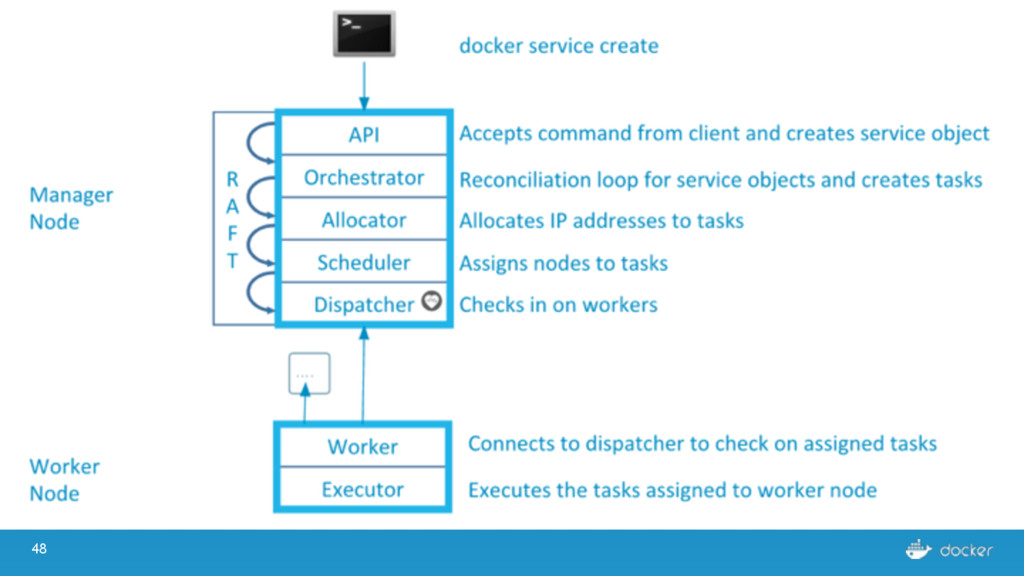
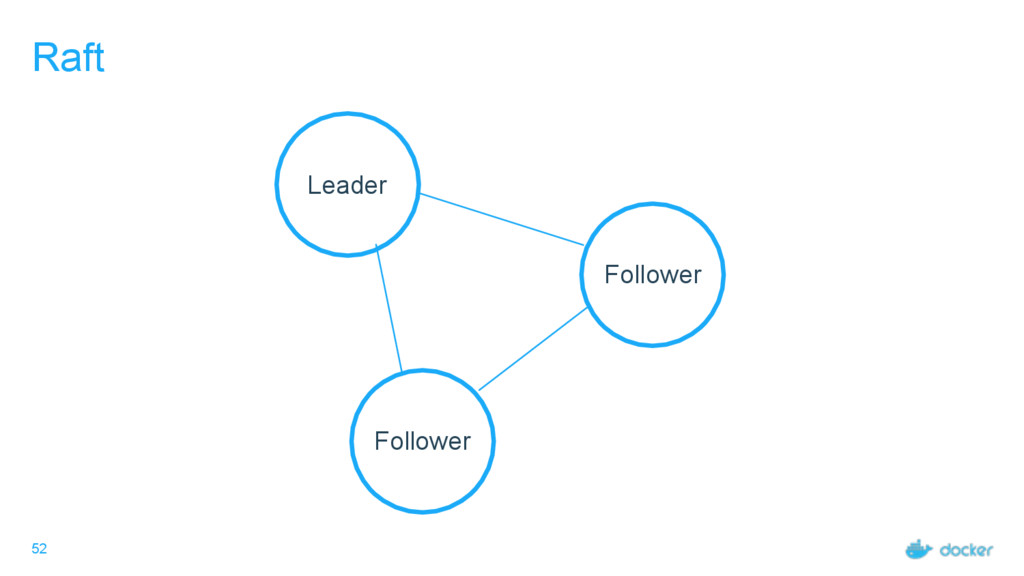
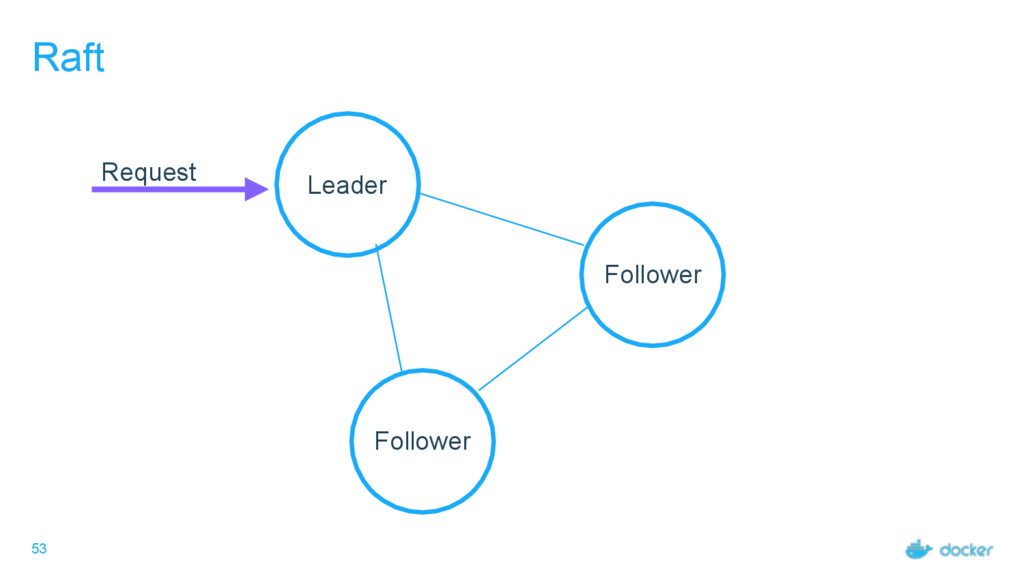
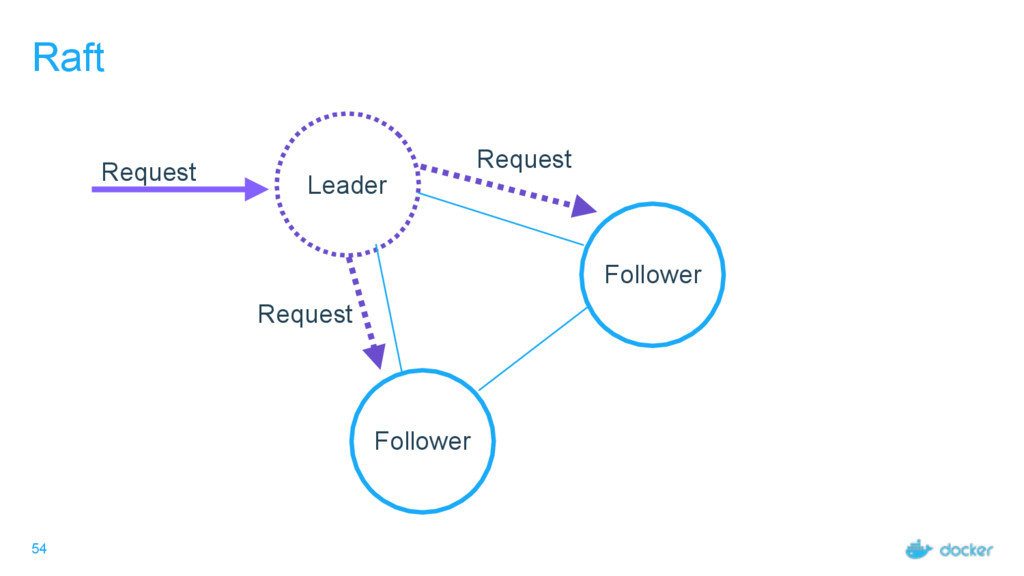
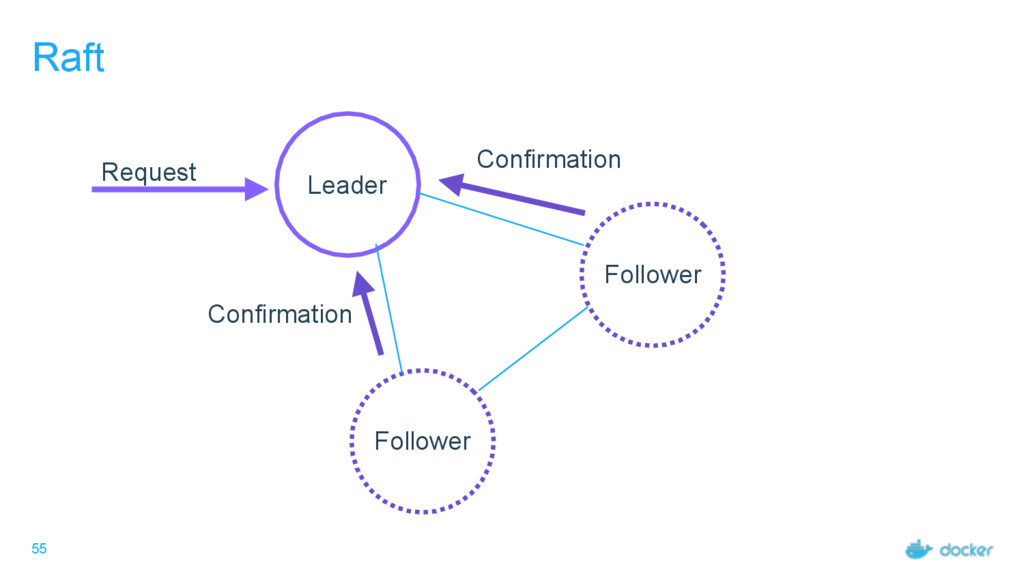
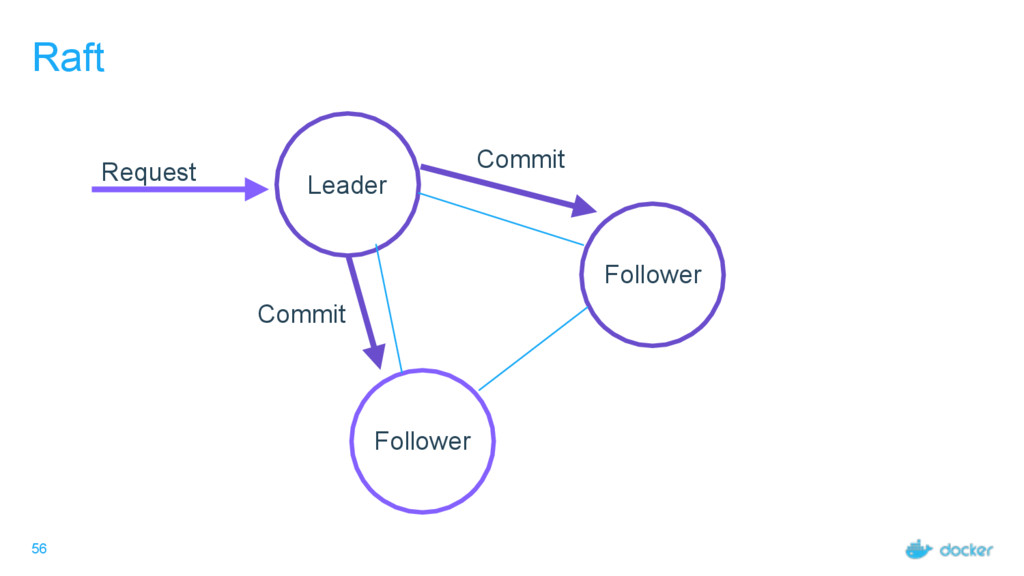
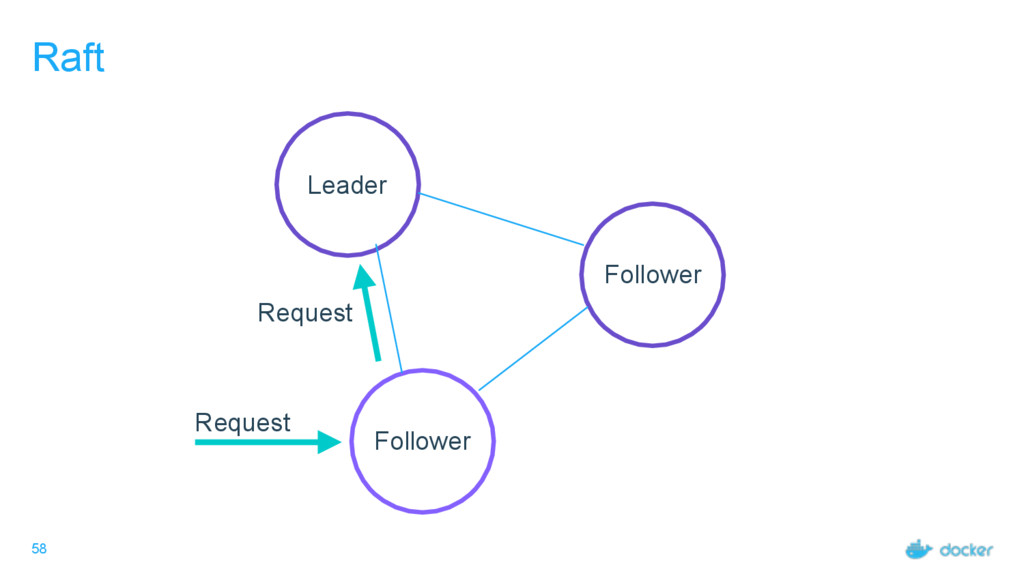
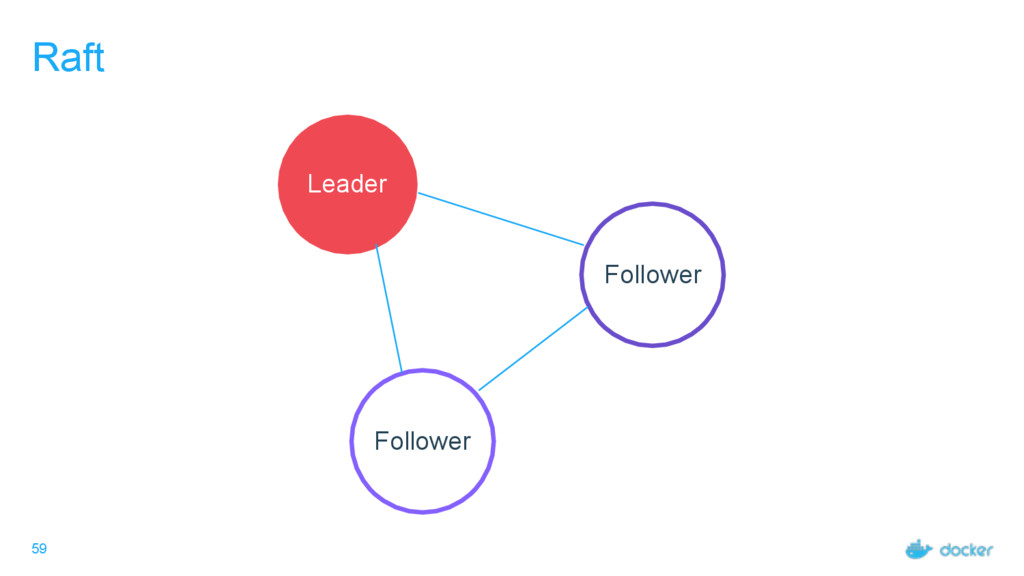
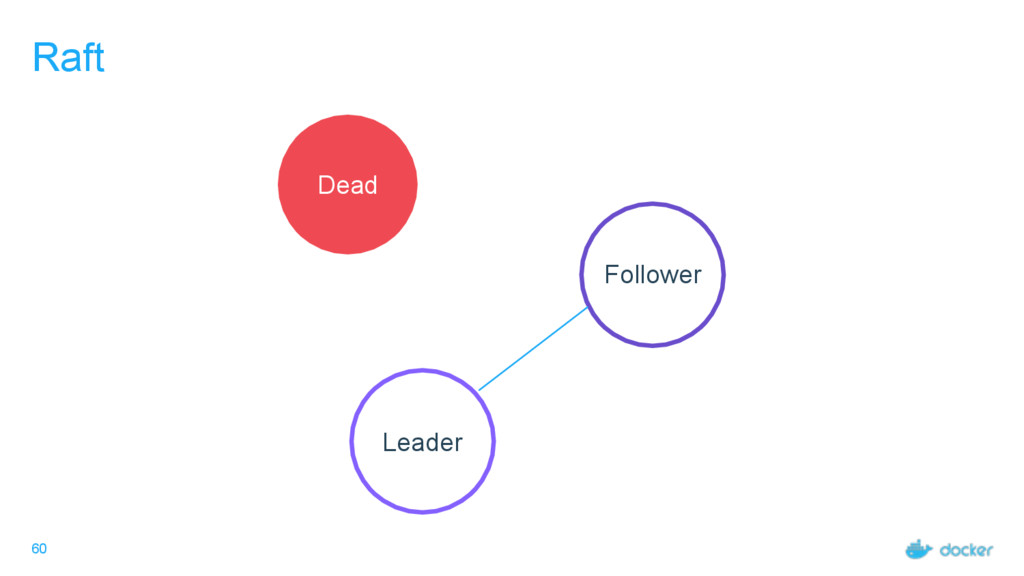
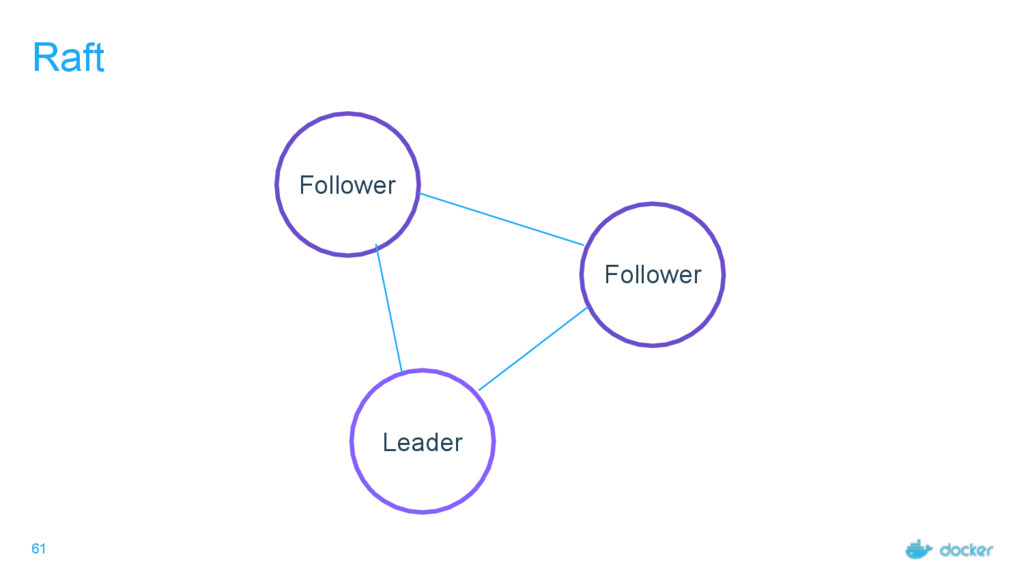
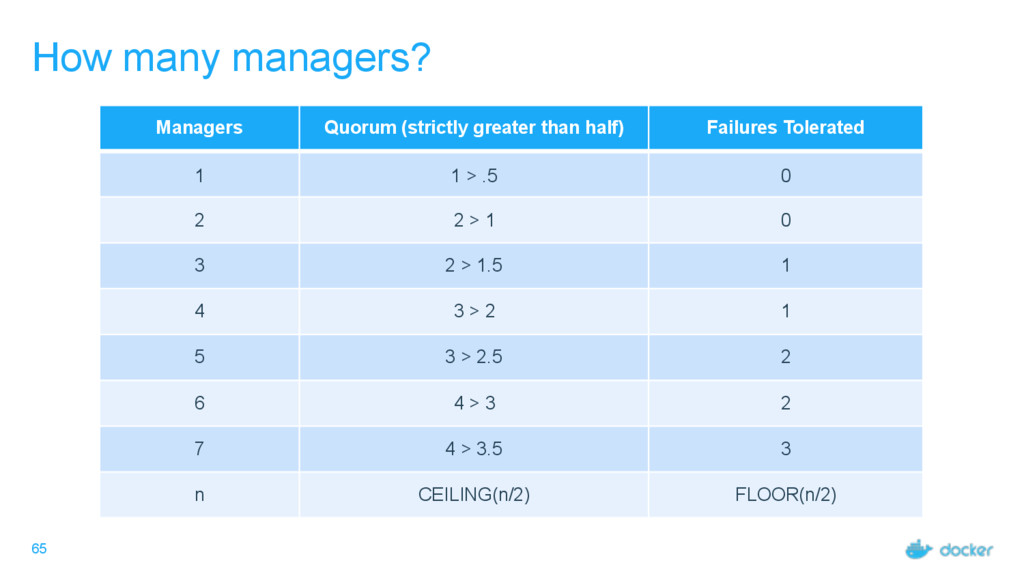
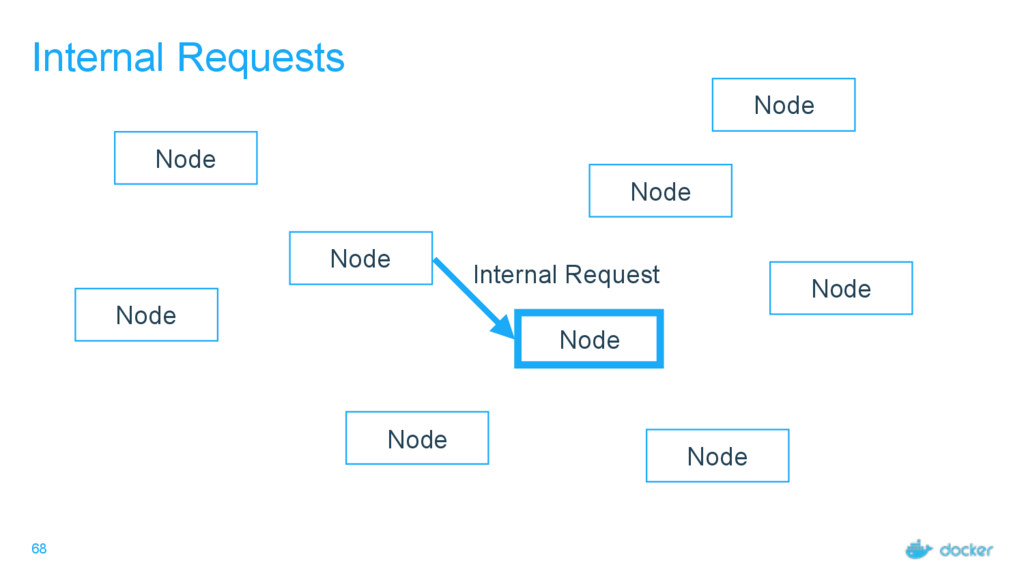
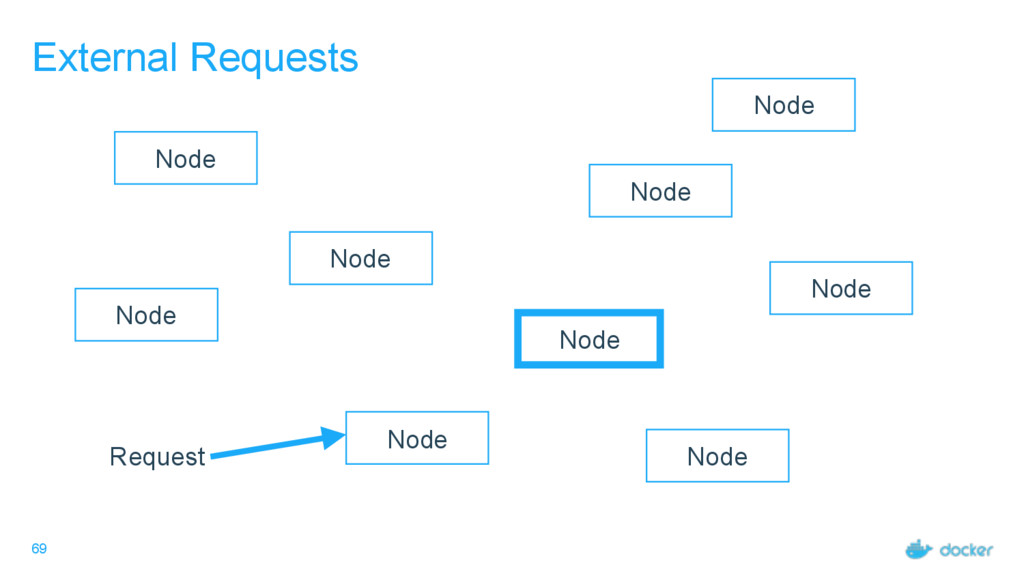
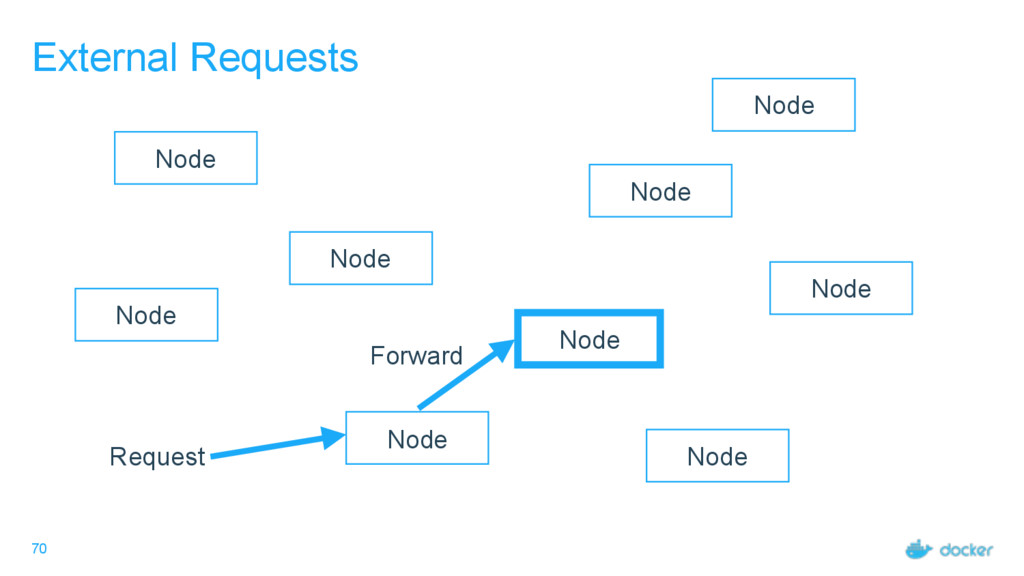
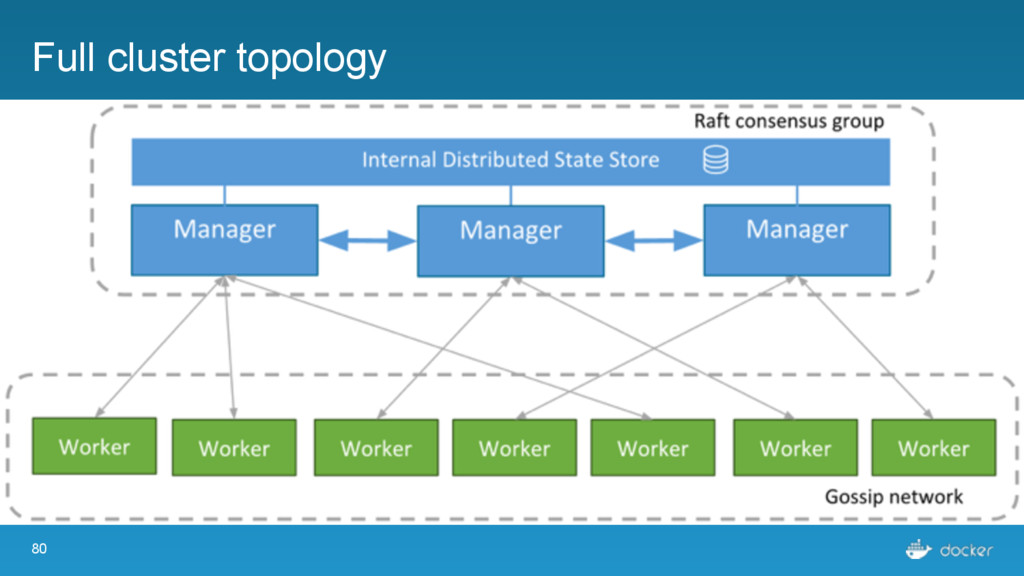
others Followers Leader is the ultimate endpoint for all requests Leader informs all Followers about log changes, waits for acknowledgement from a quorum (more than half) of Followers before committing Followers proxy requests to the leader (all are valid endpoints) If Leader dies or goes missing from the quorum, a new one is elected
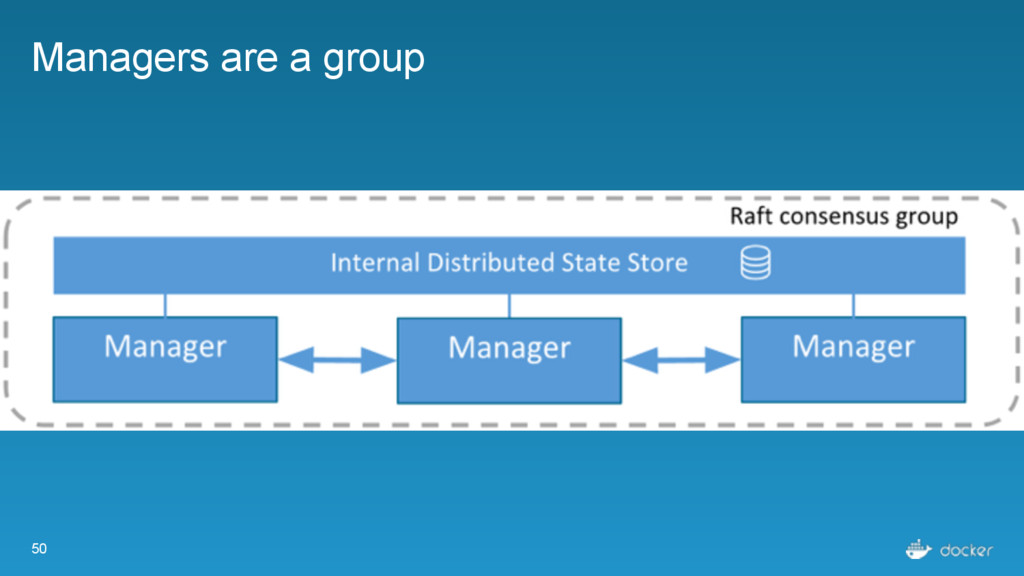
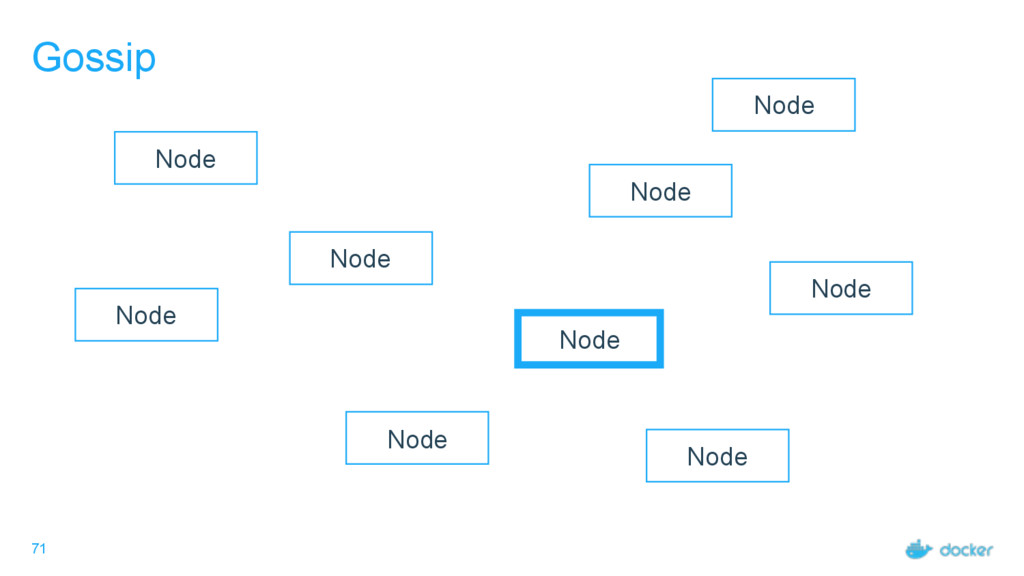
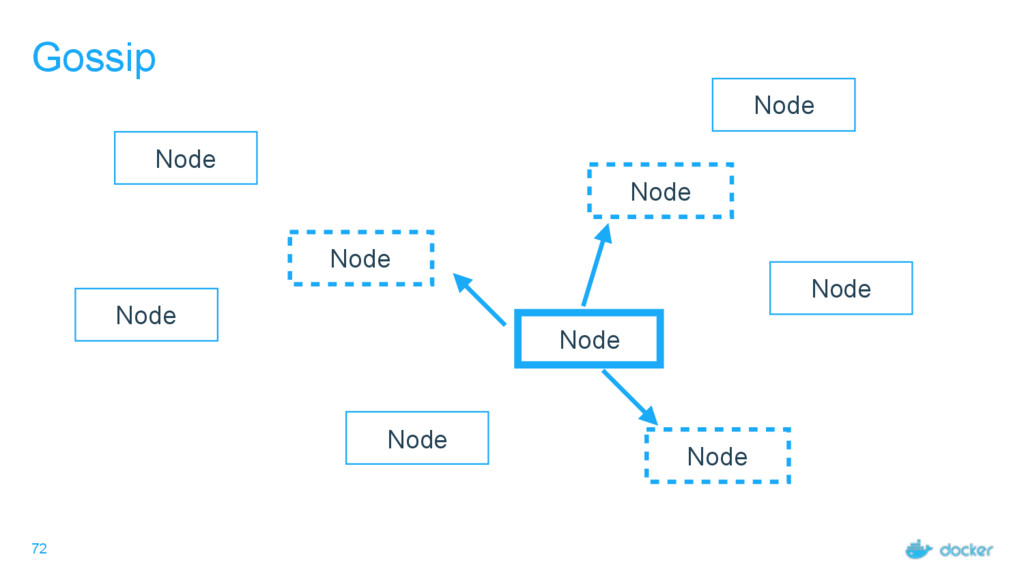
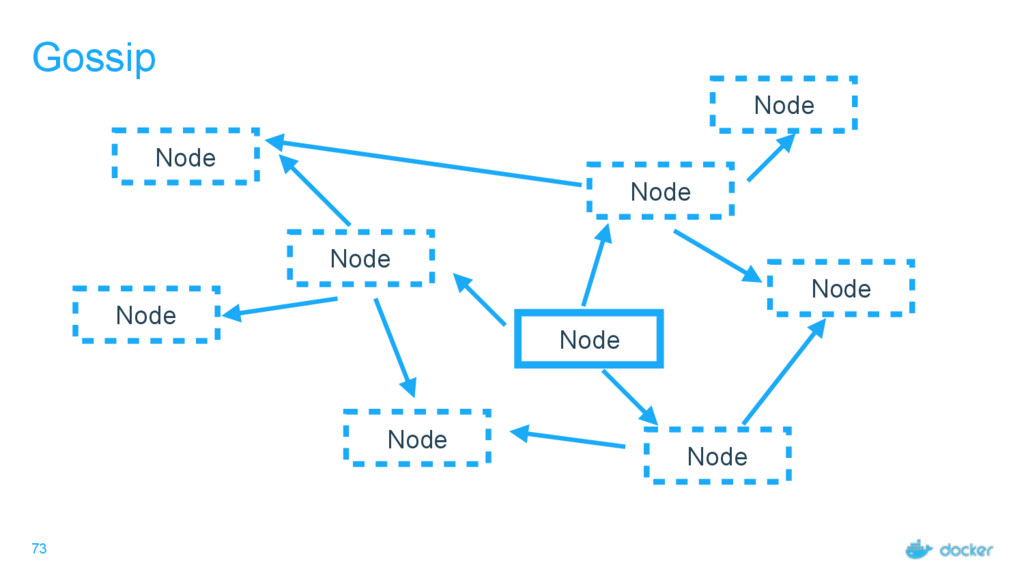
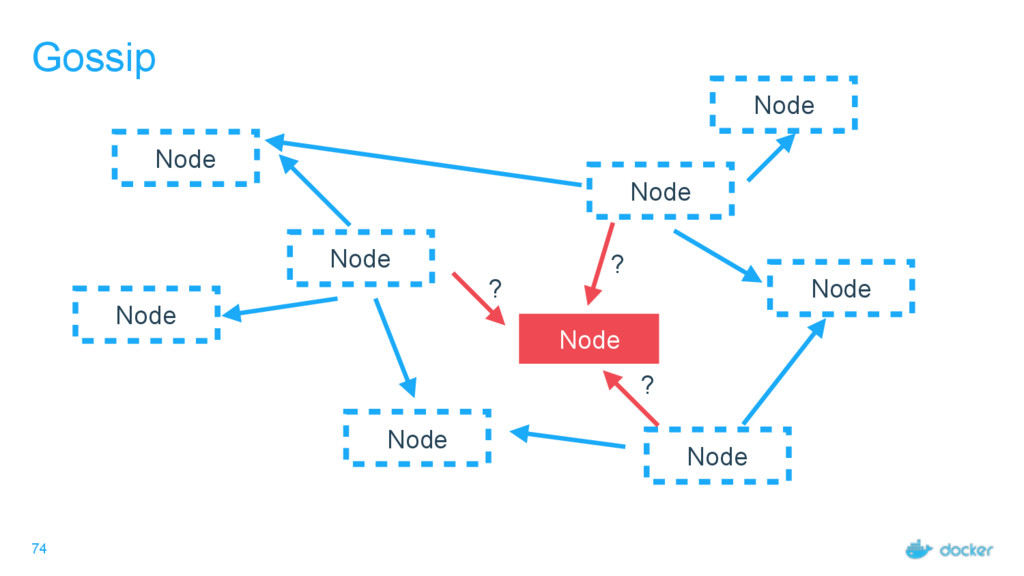
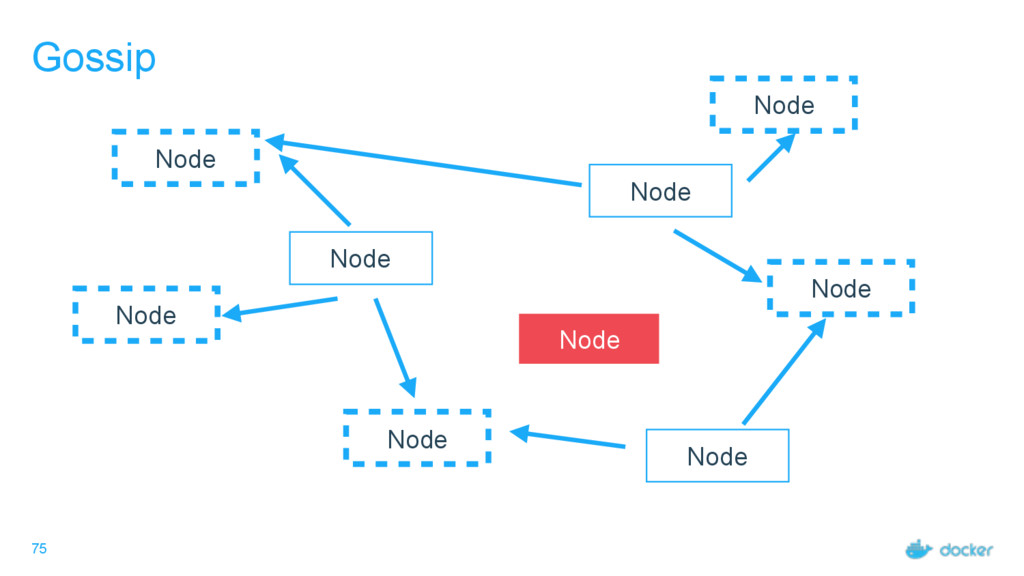
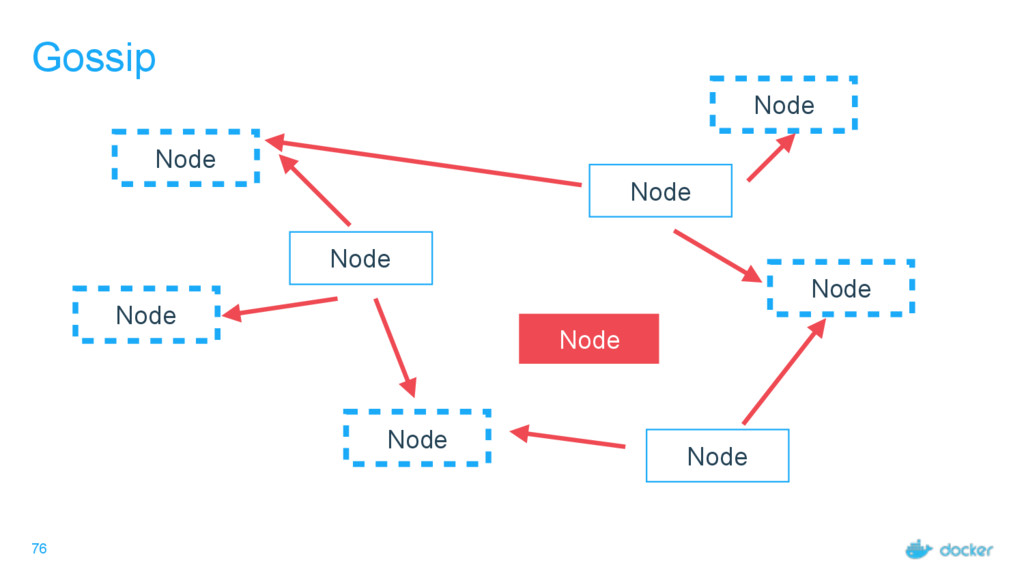
what services Every node must maintain a record of the services on every other node Done outside of Raft Eventually consistent, not guaranteed consistent
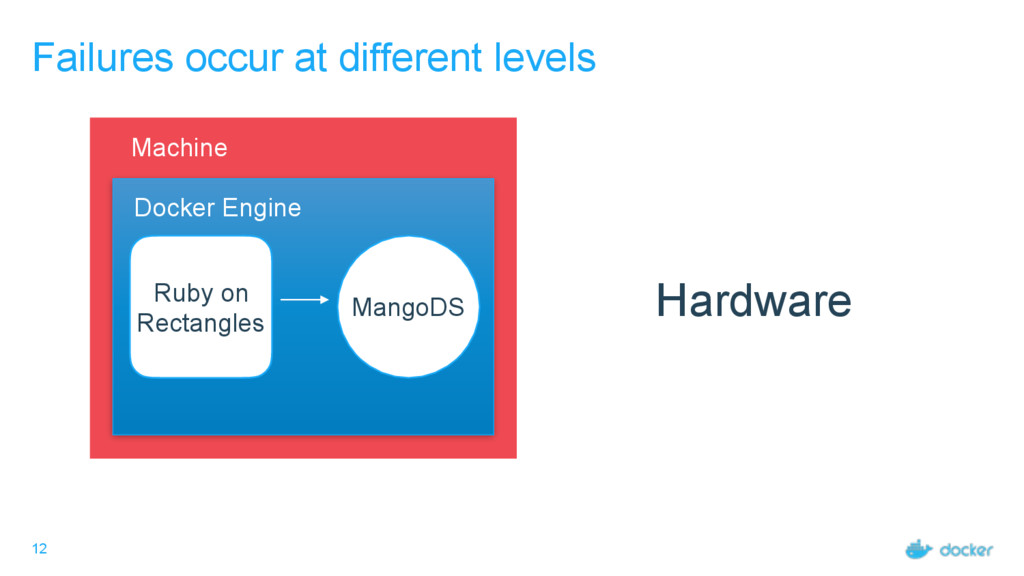
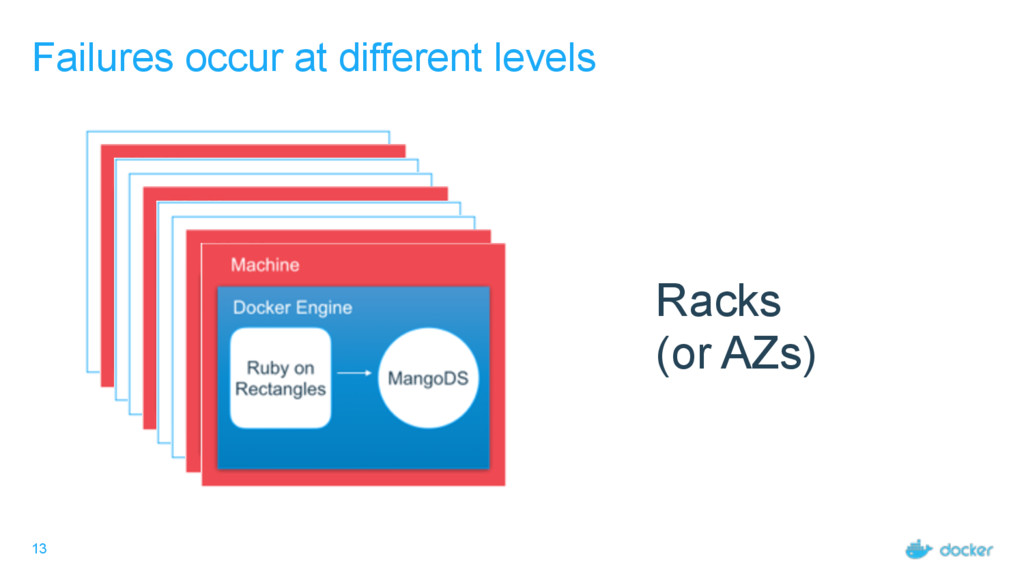
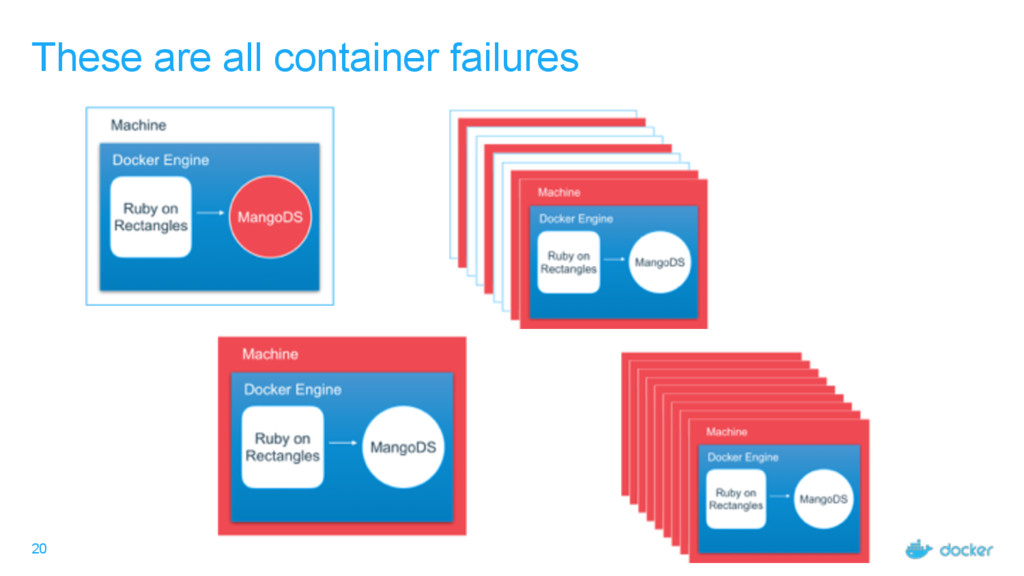
• If we focus on container failures, we narrow the problem. • Orchestration does the heavy lifting for us. • Swarmkit uses lots of tricks to make orchestration itself failure-tolerant.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Drew Erny [email protected] @dperny on every social network](https://files.speakerdeck.com/presentations/de3f9c3d206a4f4a9afc49b49afe7243/slide_81.jpg){kind=link}