Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
tidymodelsによるtidyな機械学習 / Japan.R 2019
Search
森下光之助
December 07, 2019
Programming
6.1k
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
tidymodelsによるtidyな機械学習 / Japan.R 2019
2019年12月7日に行われたJapan.R 2019での発表資料です
https://japanr.connpass.com/event/154070/
森下光之助
December 07, 2019
More Decks by 森下光之助
See All by 森下光之助
『ビジネス課題を解決する技術』を出版しました / CA DATA Night #7
dropout009
1
83
baseballrによるMLBデータの抽出と階層ベイズモデルによる打率の推定 / TokyoR118
dropout009
2
950
tidymodelsによるtidyな生存時間解析 / Japan.R2024
dropout009
2
1.4k
データ不足に数理モデルで立ち向かう / Japan.R 2023
dropout009
12
6.3k
回帰分析ではlm()ではなくestimatr::lm_robust()を使おう / TokyoR100
dropout009
67
11k
Counterfactual Explanationsで機械学習モデルを解釈する / TokyoR99
dropout009
3
3.2k
『機械学習を解釈する技術』の紹介 / Devsumi2022
dropout009
4
4.1k
シンプルな数理モデルでビジネス課題を解決する / Japan.R 2021
dropout009
2
7.1k
テレビCMのユニークリーチを最適化する / PyData.Tokyo24
dropout009
0
1.9k
Other Decks in Programming
See All in Programming
Apache Hive: そしてCloud Native Lakehouseへ
okumin
1
110
『コードを書く以外の』エンジニアリング〜課金基盤移行プロジェクト推進のためのTips4選
yuriko1211
0
490
技術記事、 専門家としてのプログラマ、 言語化
mizchi
14
7.5k
Even G2とAWSで推しのエージェントを召喚しよう!
har1101
1
170
AI がコードを書く時代における新卒エンジニアの仕事風景 (2026) / New Graduate Engineers in the Era of AI Coding (2026)
sushichan044
0
220
Performance Engineering for Everyone
elenatanasoiu
0
270
PHP Application における Kubernetes 内 gRPC 通信
ganchiku
0
420
Haskell/Servantを通してWebミドルウェアを捉え直す
pizzacat83
1
580
エンジニアにデザインハーネスを 〜デザインプロセスを規定するためのハーネス〜 / Design harness from an engineer's perspective
rkaga
2
1.5k
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
360k
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
920
琵琶湖の水は止められてもNet--HTTPのリトライは止められない / You might be able to stop the water flow of Lake Biwa but you can't stop Net::HTTP retries
luccafort
PRO
0
380
Featured
See All Featured
Practical Orchestrator
shlominoach
191
11k
Evolution of real-time – Irina Nazarova, EuRuKo, 2024
irinanazarova
9
1.4k
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Balancing Empowerment & Direction
lara
6
1.2k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
360
Documentation Writing (for coders)
carmenintech
77
5.4k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
340
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
200
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
Ruling the World: When Life Gets Gamed
codingconduct
0
280
Designing for Performance
lara
611
70k
Transcript
tidymodelsによる tidyな機械学習 2019/12/7 Japan.R 2019 森下光之助(@dropout009)
tidymodels︓tidyなやり⽅で機械学習が⾏えるパッケージ群 ü rsample︓Train/Test、Cross Validationなどのデータ分割 ü recipe︓データの前処理、特徴量エンジニアリング ü parsnip︓モデル構築と学習 ü tune︓ハイパーパラメータのチューニング
ü yardstic :モデルの精度評価
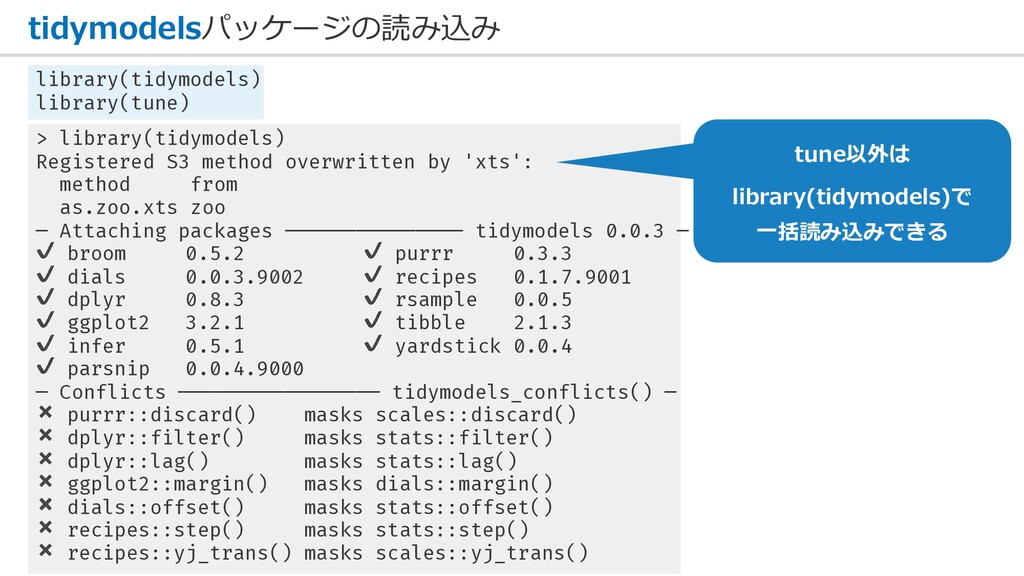
tidymodelsパッケージの読み込み library(tidymodels) library(tune) > library(tidymodels) Registered S3 method overwritten by
'xts': method from as.zoo.xts zoo ─ Attaching packages ─────────────── tidymodels 0.0.3 ─ ✔ broom 0.5.2 ✔ purrr 0.3.3 ✔ dials 0.0.3.9002 ✔ recipes 0.1.7.9001 ✔ dplyr 0.8.3 ✔ rsample 0.0.5 ✔ ggplot2 3.2.1 ✔ tibble 2.1.3 ✔ infer 0.5.1 ✔ yardstick 0.0.4 ✔ parsnip 0.0.4.9000 ─ Conflicts ───────────────── tidymodels_conflicts() ─ ✖ purrr::discard() masks scales::discard() ✖ dplyr::filter() masks stats::filter() ✖ dplyr::lag() masks stats::lag() ✖ ggplot2::margin() masks dials::margin() ✖ dials::offset() masks stats::offset() ✖ recipes::step() masks stats::step() ✖ recipes::yj_trans() masks scales::yj_trans() tune以外は library(tidymodels)で ⼀括読み込みできる
今回はサンプルデータとしてAmesHousingを使⽤ df = AmesHousing::make_ames() > df %>% + select(Sale_Price, everything())
# A tibble: 2,930 x 81 Sale_Price MS_SubClass MS_Zoning Lot_Frontage Lot_Area Street Alley <int> <fct> <fct> <dbl> <int> <fct> <fct> 1 215000 One_Story_… Resident… 141 31770 Pave No_A… 2 105000 One_Story_… Resident… 80 11622 Pave No_A… 3 172000 One_Story_… Resident… 81 14267 Pave No_A… 4 244000 One_Story_… Resident… 93 11160 Pave No_A… 5 189900 Two_Story_… Resident… 74 13830 Pave No_A… 6 195500 Two_Story_… Resident… 78 9978 Pave No_A… 7 213500 One_Story_… Resident… 41 4920 Pave No_A… 8 191500 One_Story_… Resident… 43 5005 Pave No_A… 9 236500 One_Story_… Resident… 39 5389 Pave No_A… 10 189000 Two_Story_… Resident… 60 7500 Pave No_A… # … with 2,920 more rows, and 74 more variables: Sale Priceを予測したい
rsampleでデータを分割 split = initial_split(df, prop = 0.8) df_train = training(split)
df_test = testing(split) df_cv = vfold_cv(df_train, v = 5) > df_cv # 5-fold cross-validation # A tibble: 5 x 2 splits id <named list> <chr> 1 <split [1.9K/469]> Fold1 2 <split [1.9K/469]> Fold2 3 <split [1.9K/469]> Fold3 4 <split [1.9K/469]> Fold4 5 <split [1.9K/469]> Fold5 Train/Testの分割 Trainをさらに CVとして5分割
recipeでデータの前処理 rec = recipe(Sale_Price ~ ., data = df_train) %>%
step_log(Sale_Price) > rec Data Recipe Inputs: role #variables outcome 1 predictor 80 Operations: Log transformation on Sale_Price recipeで前処理⾏う 今回はターゲットの対数をとった
parsnipでモデルを作成 model = rand_forest(mode = "regression", trees = 500, min_n
= tune(), mtry = tune()) %>% set_engine(engine = "ranger", num.threads = parallel::detectCores(), seed = 42) > model Random Forest Model Specification (regression) Main Arguments: mtry = tune() trees = 500 min_n = tune() Engine-Specific Arguments: num.threads = parallel::detectCores() seed = 42 Computational engine: ranger parsnipでモデルを指定する 今回はRF 探索したいハイパーパラメータ はtune()としておく どのRFパッケージを使うかは set_engine()で指定 パッケージ固有のパラメータ もここで指定
tuneで探索するハイパーパラメータとその範囲を指定 params = list(min_n = min_n(range = c(1, 20)), mtry
= mtry(range(5, 20))) %>% parameters() > params Collection of 2 parameters for tuning id parameter type object class min_n min_n nparam[+] mtry mtry nparam[+] 探索したいハイパーパラメータと その範囲をリストに
tuneでハイパーパラメータを探索 df_tuned = tune_bayes( rec, model = model, resamples =
df_cv, param_info = params, initial = 5, iter = 50, metrics = metric_set(rsq), control = control_bayes(no_improve = 10, verbose = TRUE)) > df_tuned # 5-fold cross-validation # A tibble: 90 x 5 splits id .metrics .notes .iter * <list> <chr> <list> <list> <dbl> 1 <split [1.8K/440]> Fold1 <tibble [4 × 5]> <tibble [0 × 1]> 0 2 <split [1.8K/440]> Fold2 <tibble [5 × 5]> <tibble [0 × 1]> 0 3 <split [1.8K/440]> Fold3 <tibble [5 × 5]> <tibble [0 × 1]> 0 4 <split [1.8K/439]> Fold4 <tibble [5 × 5]> <tibble [0 × 1]> 0 5 <split [1.8K/439]> Fold5 <tibble [5 × 5]> <tibble [0 × 1]> 0 # … with 80 more rows ハイパーパラメータの探索 今回はベイズ最適化で探す
ハイパーパラメータの探索結果を確認(tune) df_best_result = df_tuned %>% show_best(metric = "rsq", n_top =
3, maximize = TRUE) > df_best_result # A tibble: 3 x 8 mtry min_n .iter .metric .estimator mean n std_err <int> <int> <dbl> <chr> <chr> <dbl> <int> <dbl> 1 14 1 4 rsq standard 0.896 5 0.00356 2 20 1 10 rsq standard 0.896 5 0.00324 3 20 4 0 rsq standard 0.896 5 0.00325 特に精度の良かった ハイパーパラメータを確認 mtry=14, min_n=1 で最⾼の精度
最も精度の良かったハイパーパラメータをモデルにセット(parsnip) df_best_param = df_tuned %>% select_best(metric = "rsq", maximize =
TRUE) model_best = model %>% update(df_best_param) > model_best Random Forest Model Specification (regression) Main Arguments: mtry = 14 trees = 500 min_n = 1 Engine-Specific Arguments: num.threads = parallel::detectCores() seed = 42 Computational engine: ranger 特に精度の良かった ハイパーパラメータを モデルにセット
全Trainデータで再学習し、Testデータで予測(recipe, parsnip) preped_rec = rec %>% prep() df_train_baked = preped_rec
%>% juice() df_test_baked = preped_rec %>% bake(df_test) fitted_model = model_best %>% fit(Sale_Price ~ ., data = df_train_baked) df_pred = df_test_baked %>% bind_cols(fitted_model %>% predict(new_data = df_test_baked)) レシピをTrainに適⽤ レシピをTestに適⽤ Trainで学習 Testで予測
yardsticでTestデータでの精度を確認 df_eval = df_pred %>% metrics(Sale_Price, .pred) > df_eval #
A tibble: 3 x 3 .metric .estimator .estimate <chr> <chr> <dbl> 1 rmse standard 0.120 2 rsq standard 0.903 3 mae standard 0.0816 Testデータでの予測精度を計算 モデルの予測値と実際のSale Price
まとめ︓tidymodels使うとtidyなやり⽅で機械学習が⾏える ü rsample︓Train/Test、Cross Validationなどのデータ分割 ü recipe︓データの前処理、特徴量エンジニアリング ü parsnip︓モデル構築と学習 ü tune︓ハイパーパラメータのチューニング
ü yardstic :モデルの精度評価
参考⽂献 • tidymodelsによるモデル構築と運⽤ / tidymodels https://speakerdeck.com/s_uryu/tidymodels • tidymodelsによるtidyな機械学習(その1︓データ分割と前処理から学習と性能評価まで) https://dropout009.hatenablog.com/entry/2019/01/06/124932 •
tidymodelsによるtidyな機械学習(その3︓ハイパーパラメータのチューニング) https://dropout009.hatenablog.com/entry/2019/11/10/125650 • General Resampling Infrastructure • rsample https://tidymodels.github.io/rsample/ • Preprocessing Tools to Create Design Matrices • recipes https://tidymodels.github.io/recipes/ • A Common API to Modeling and Analysis Functions • parsnip https://tidymodels.github.io/parsnip/ • Tidy Characterizations of Model Performance • yardstick https://tidymodels.github.io/yardstick/ • Tidy Tuning Tools • tune https://tidymodels.github.io/tune/index.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}