From proof of concept to implementation in a minimal amount of time, here is a story of how a small team of engineers at the University of Washington introduced Elasticsearch in its development stack to replace the Oracle WebCenter content search engine, how it made their life easier, and how it improved the user experience.
Maxime Deravet | Elastic{ON} Tour Seattle | December 3, 2015
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
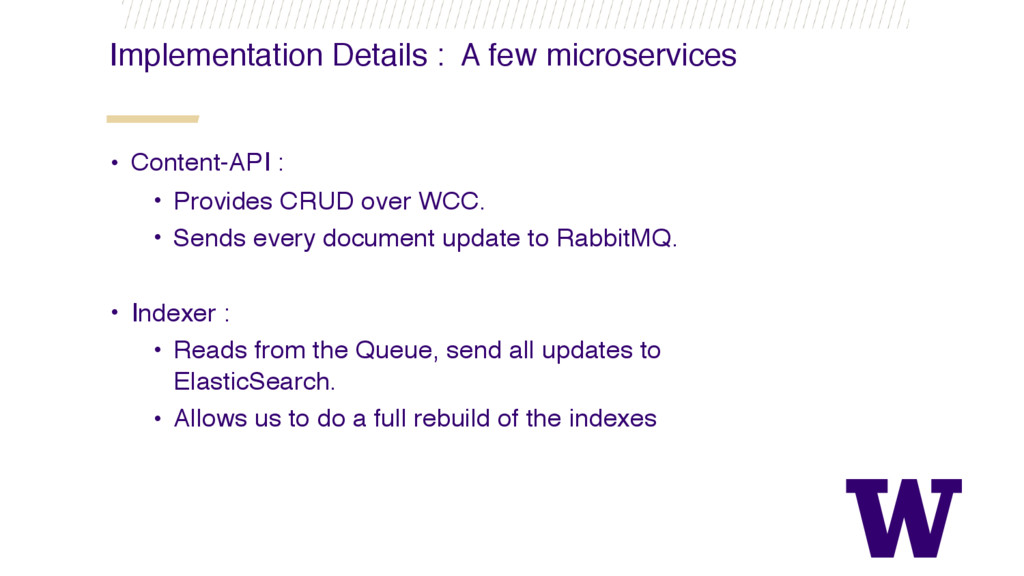{kind=link}
{kind=link}
{kind=link}
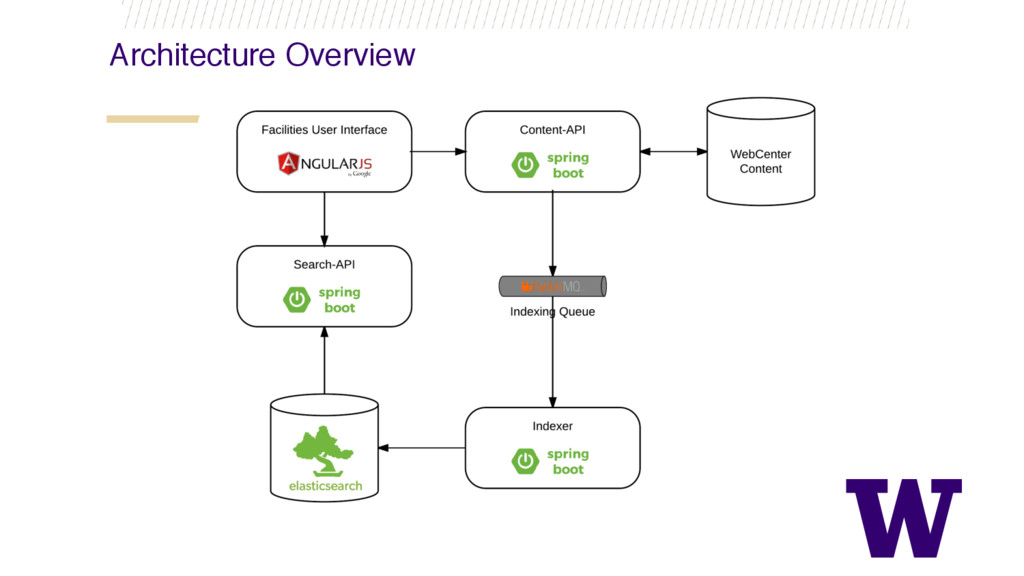{kind=link}
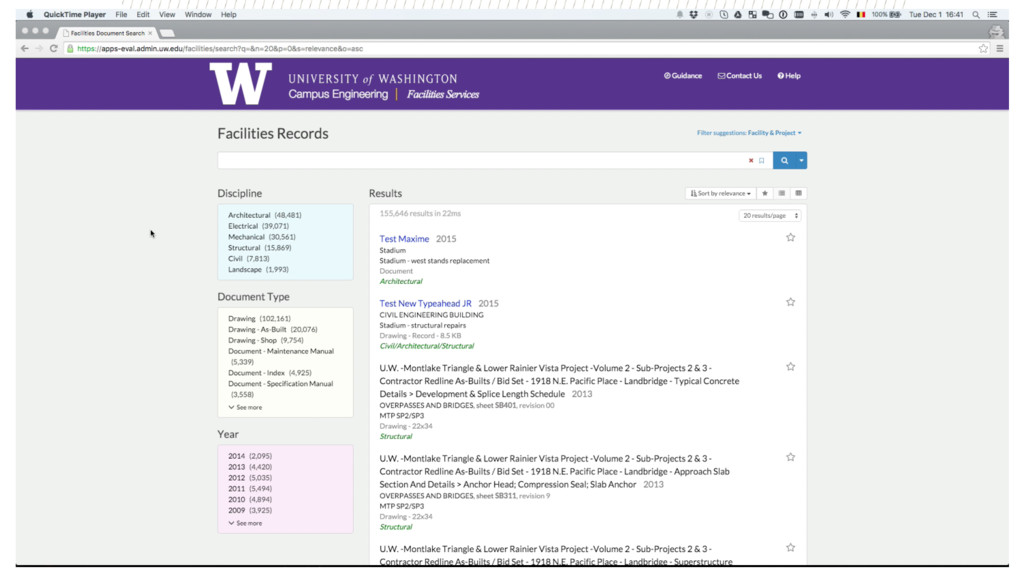{kind=link}
{kind=link}
![Questions ? Maxime Deravet : • [email protected] • @maximeder](https://files.speakerdeck.com/presentations/4c3c8dbbd4dd4141b15925bca1252364/slide_20.jpg){kind=link}