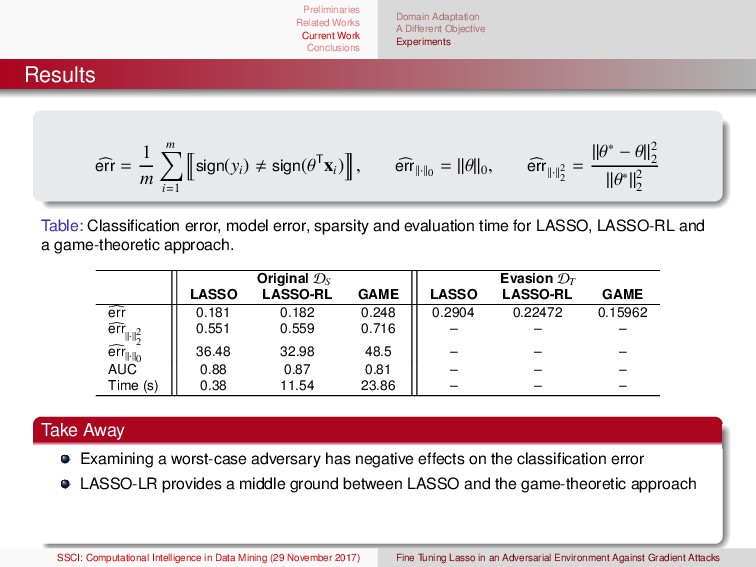
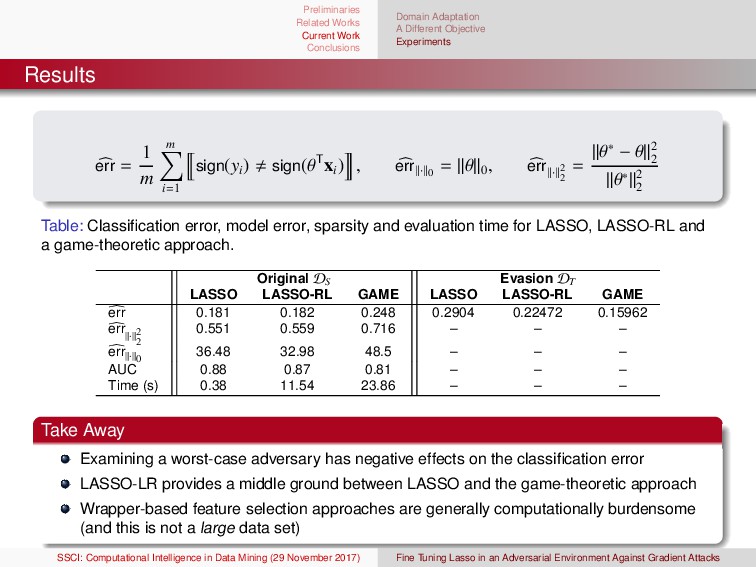
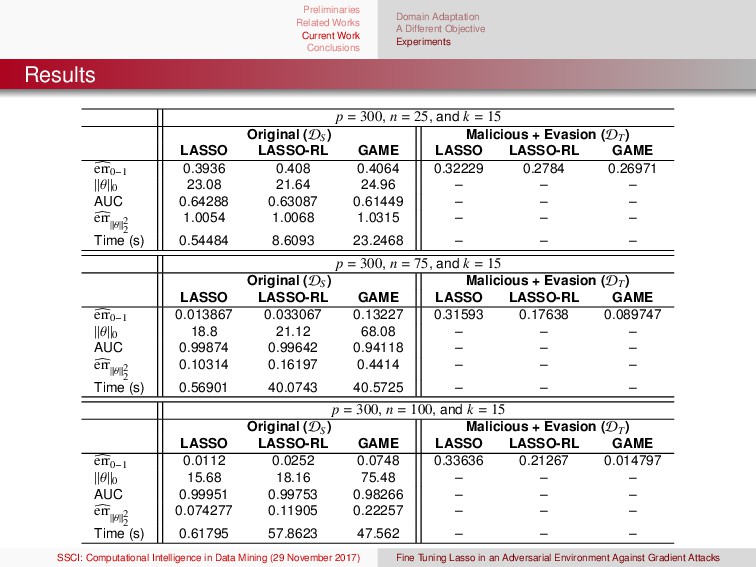
Learning in Nonstationary Environments Concept drift Concept drift can be modeled as a change in a probability distribution, P(X, Ω). The change can be in P(X), P(X|Ω), P(Ω), or joint changes in P(Ω|X). P(Ω|X) = P(X|Ω)P(Ω) P(X) We generally reserve names for specific types of drift (e.g., real and virtual) Drift types: sudden, gradual, incremental, & reoccurring General Examples: electricity demand, financial, climate, epidemiological, and spam (to name a few) NSE and Traditional Classification Algorithms Many traditional learning algorithms assume that data are sampled i.i.d. (CART, Adaboost, etc); however, rarely is that the case Learning in NSE generally requires that the drift in the stream is “structured”. E.g., there is some common information between the different data sets in the stream 1G. Ditzler, M. Roveri, C. Alippi, and R. Polikar, “Adaptive strategies for learning in nonstationary environments: a survey,” IEEE Computational Intelligence Magazine, 2015, vol. 10, no. 4, pp. 12–25. 2G. Ditzler, G. Rosen, and R. Polikar, “Domain Adaptation Bounds for Multiple Expert Systems Under Concept Drift,” International Joint Conference on Neural Networks, 2014. (best student paper award) SSCI: Computational Intelligence in Data Mining (29 November 2017) Fine Tuning Lasso in an Adversarial Environment Against Gradient Attacks
{kind=link}
{kind=link}
{kind=link}
{kind=link}
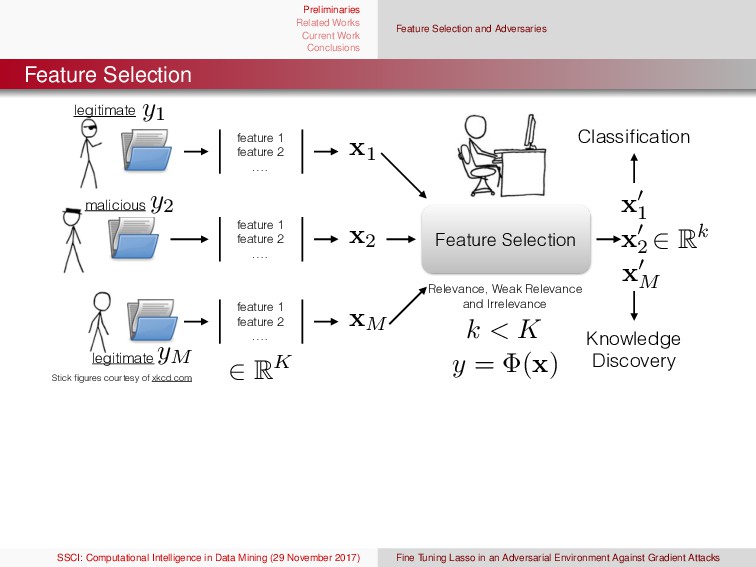{kind=link}
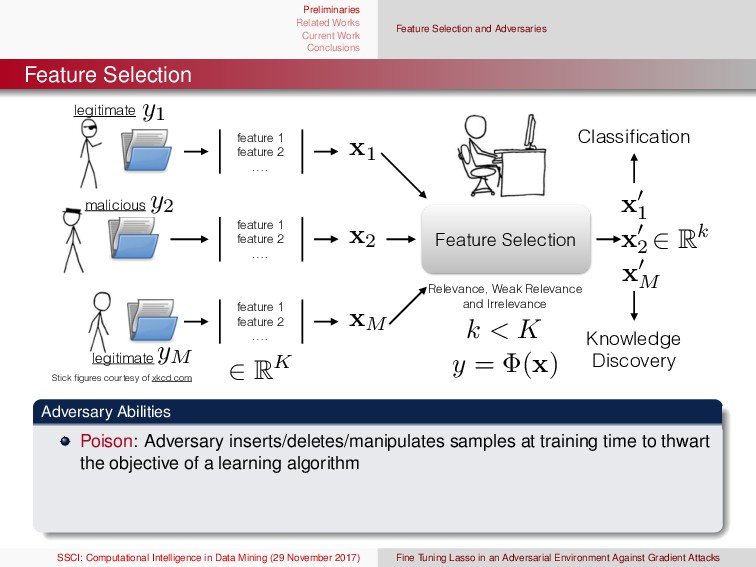{kind=link}
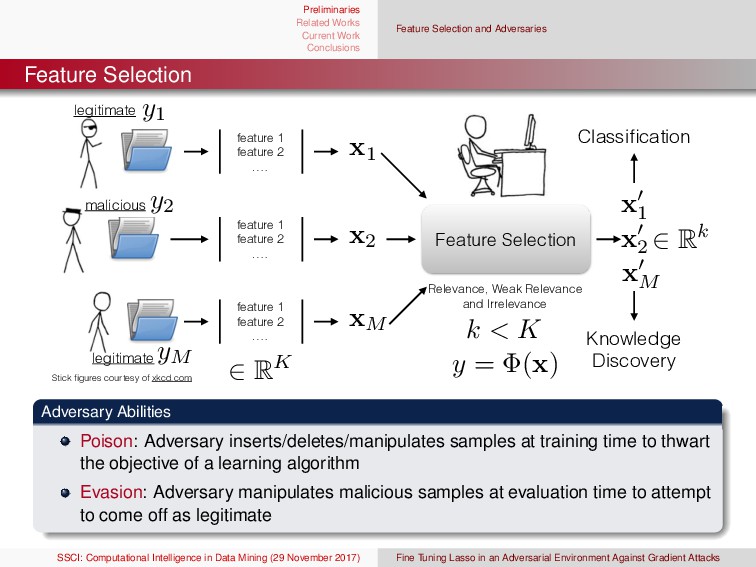{kind=link}
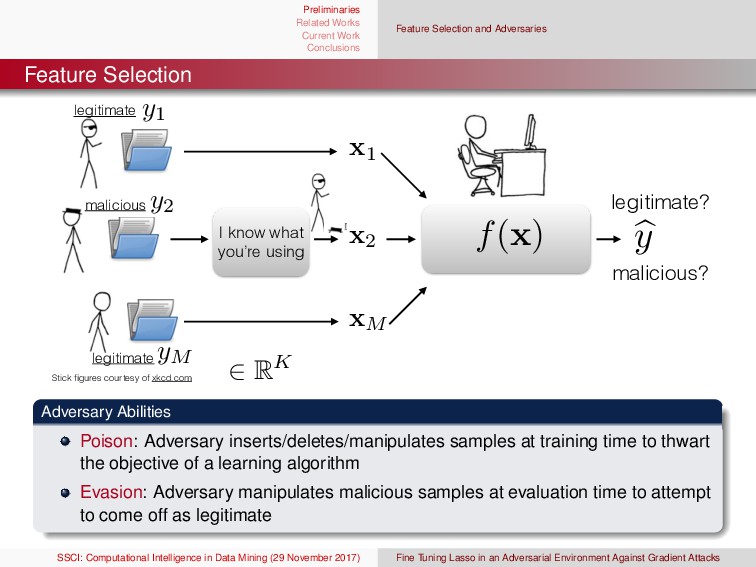{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}