degree of Information Science at Kyoto University Sun Microsystems K.K. → Founded own startup at Kyoto → Established Kyoto Branch of Nulab Inc. → Current
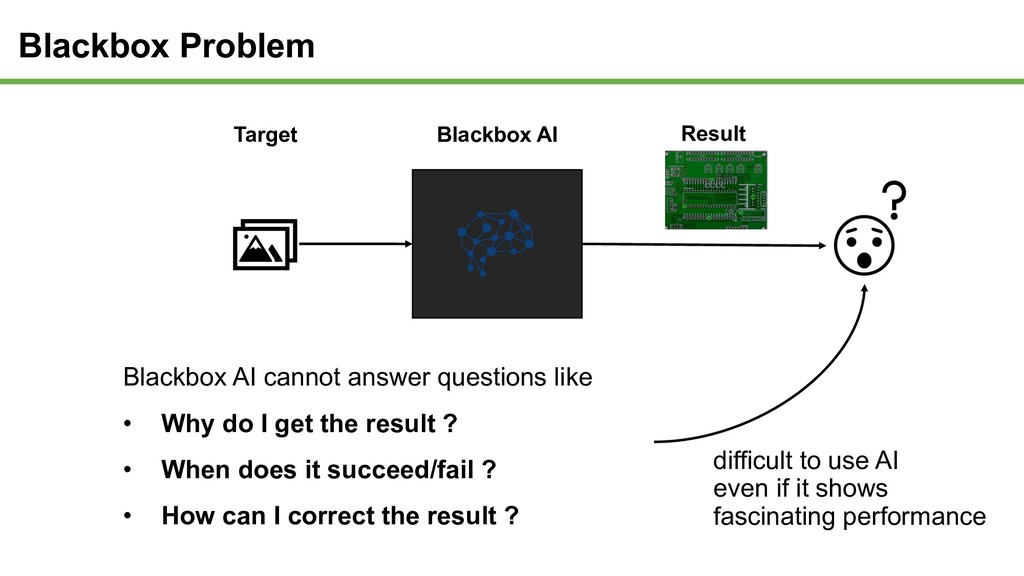
questions like • Why do I get the result ? • When does it succeed/fail ? • How can I correct the result ? difficult to use AI even if it shows fascinating performance
model • Individual prediction explanations • Global prediction explanations • Build an interpretable model • Logistic regression, Decision trees and so on For more details, refer to Explainable AI in Industry (KDD 2019 Tutorial)
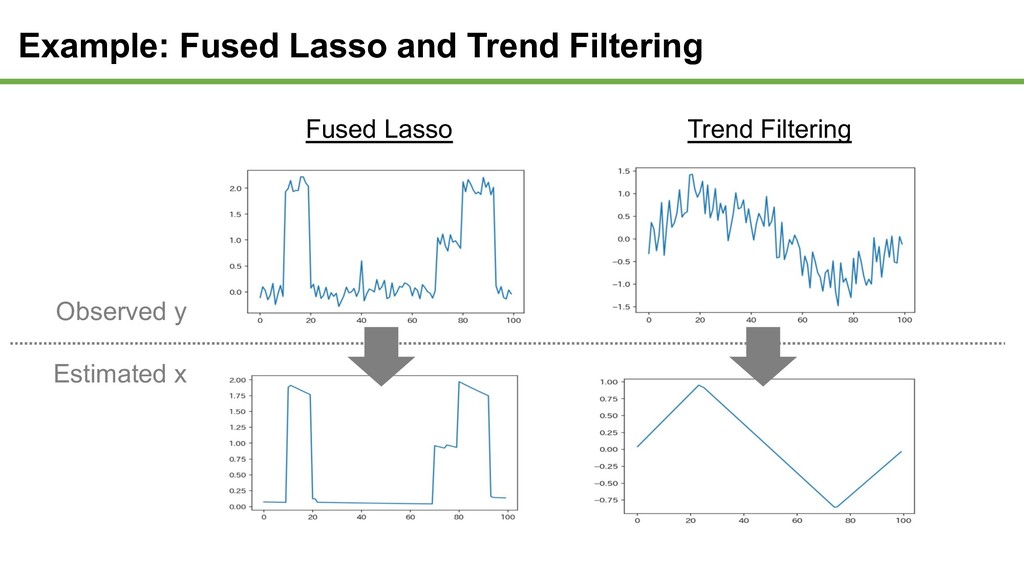
and Selection via Lasso R. Tibshirani 1996 Sparse Coding B. Olshausen 2006 Compressed Sensing D.L. Donoho 2018 Multi-Layer Convolutional Sparse Modeling M. Elad
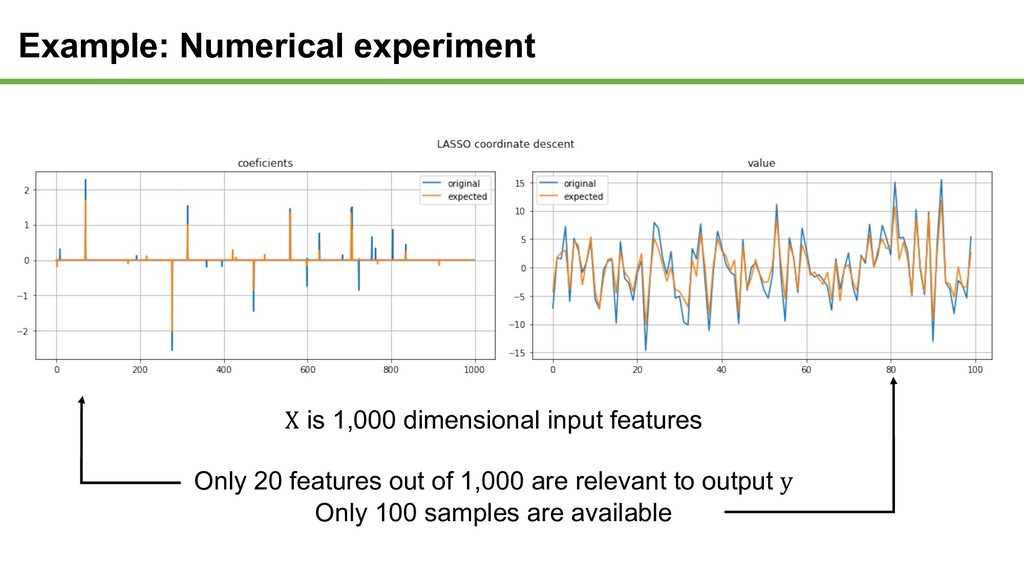
linear combination of x with observation noise ε where x is m dimensional and sample size of y is n = $ $ + ⋯ + ( ( + Basic approach to the problem • Least squares method • Minimize least square errors of y and multipliers of x and estimated w min 1 2 − 0
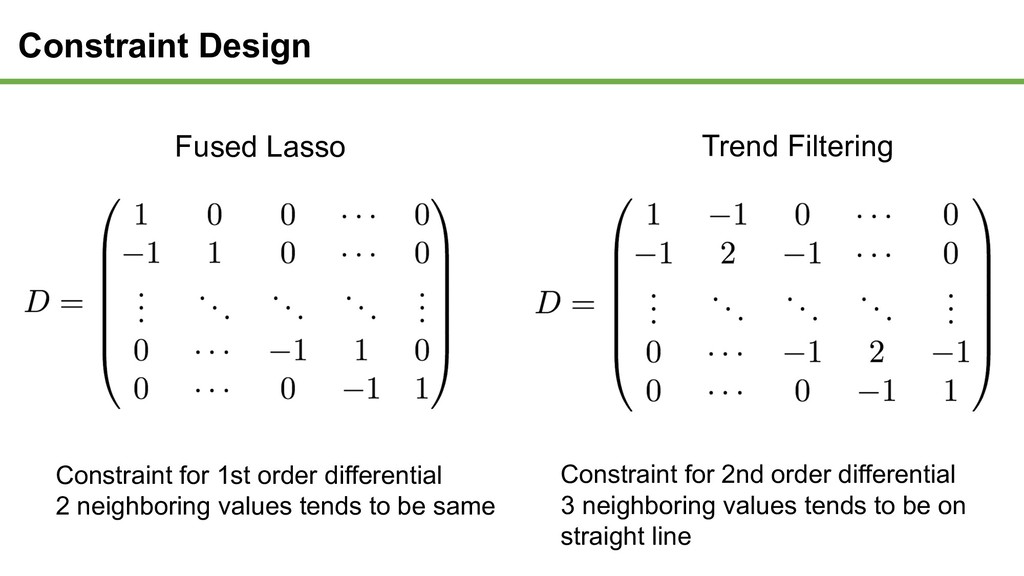
not all input features won’t be used to express y • Additional constraint will be introduced as regularization term • Objective function can be changed to the following form min 1 2 − 0 + 3 ⇒ Regularization parameter λ controls effectiveness of regularization Introduce Regularization
to satisfy equation • Find w to minimize number of non-zero elements • Combinational optimization • NP-hard and not feasible L L0 and L1 norm optimization • L1 norm optimization • Find w to minimize sum of its absolute values • Global solution can (still) be reached • Solved within practical time Relax constraint Least Absolute Shrinkage and Selection Operator
• scikit-learn compliant interface • supported algorithms and planned works • generalized Lasso (4 variants) • k-svd and more… • total variation, more lasso (planned) • more examples (planned)
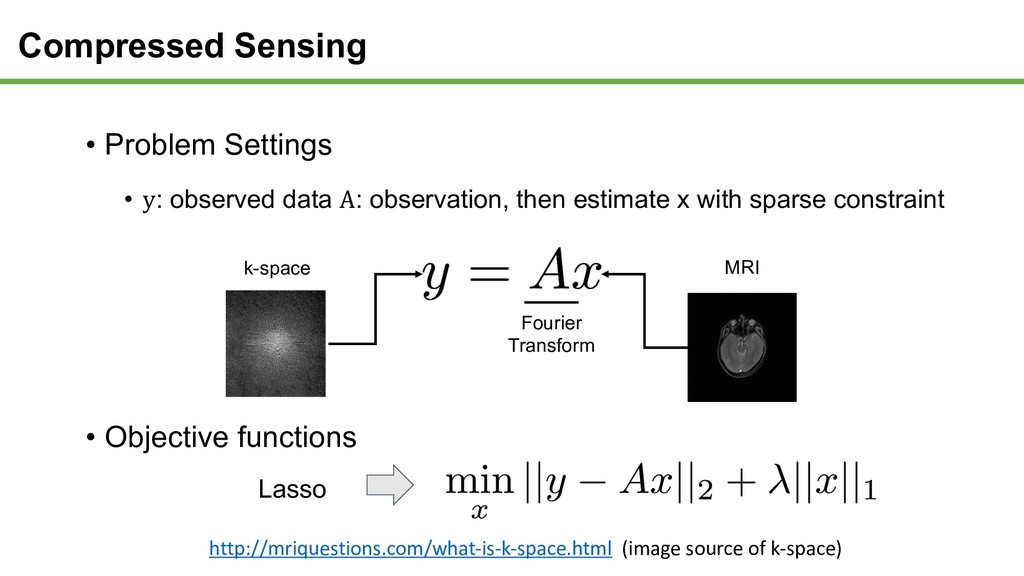
observation, then estimate x with sparse constraint Lasso • Objective functions http://mriquestions.com/what-is-k-space.html (image source of k-space) k-space MRI Fourier Transform
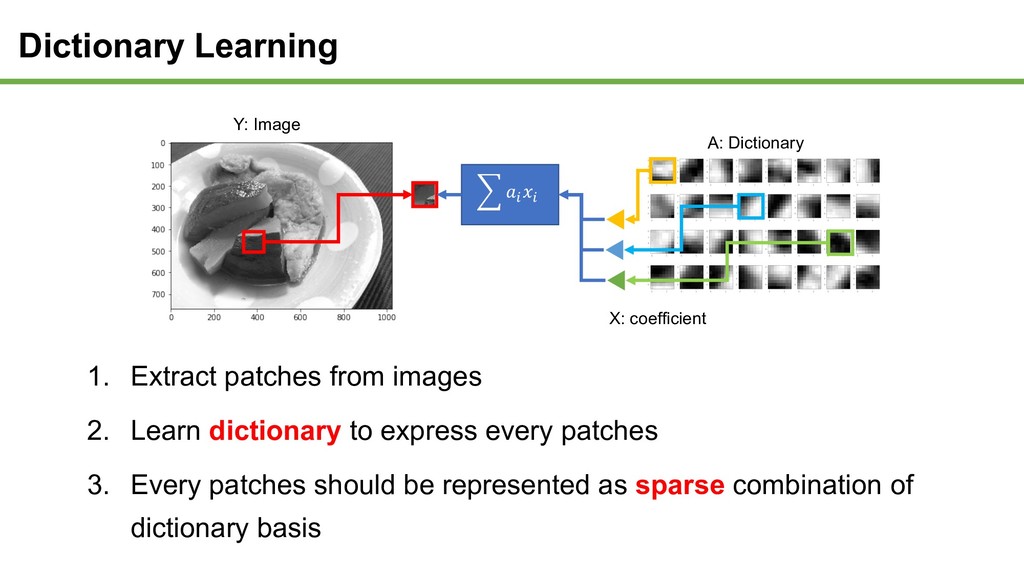
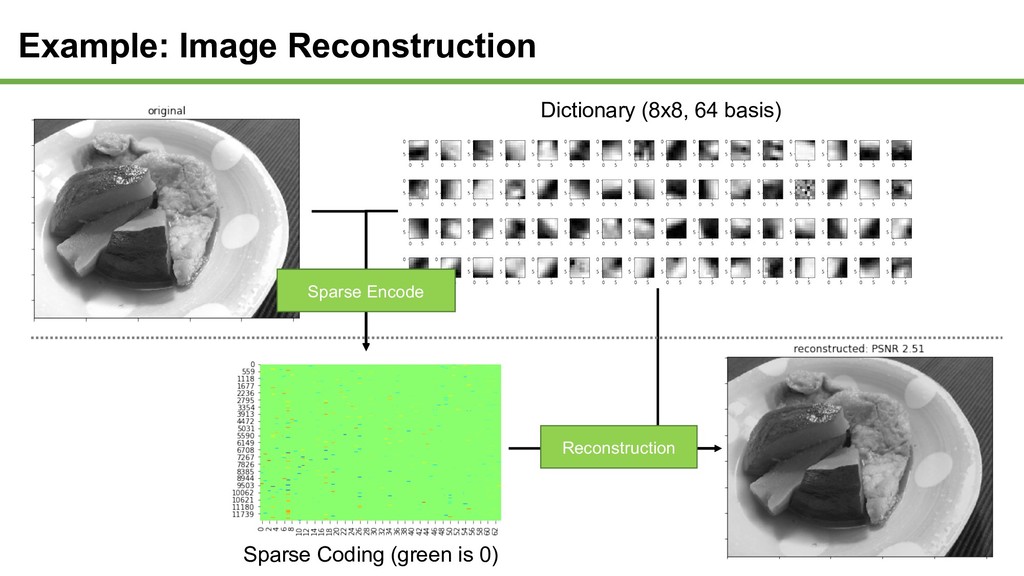
every patches 3. Every patches should be represented as sparse combination of dictionary basis Y: Image A: Dictionary : < < X: coefficient Dictionary Learning
SOTA ML methods Makes rule from data and prior information, i.e. sparsity Makes rule (basically) only from data Can start with small dataset and both training and inference is fast Requires big dataset with a lot of time for training Focus on specific use cases Can support very wide range of problem
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}