Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データの民主化 〜Chatworkのデータ活用の取り組み〜
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Ikuya Murasato
May 29, 2020
Business
9.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データの民主化 〜Chatworkのデータ活用の取り組み〜
2020/5/29(金)に開催したExploratory データサイエンス勉強会#13のChatwork株式会社様のご登壇資料です。
Ikuya Murasato
May 29, 2020
More Decks by Ikuya Murasato
See All by Ikuya Murasato
トピックモデル分析を活用した問合せ業務の効率化
ikuyam
1
310
回帰分析の活用による新商品の販売力予測
ikuyam
1
210
生存分析モデルを利用したLineのブロック要因分析
ikuyam
0
140
自動車トラブルと気象条件などの探索的データ分析
ikuyam
0
130
データサイエンス「も」使えるチェンジメーカー輩出への挑戦
ikuyam
0
490
ExploratoryとRによる全学データサイエンス教育
ikuyam
0
730
エンゲージメント向上のための人事制度改革 - 管理部門におけるExploratoryの活用
ikuyam
0
2.2k
「学ぶ」分析技術から「使う」分析技術へ - Exploratoryによるドリル演習
ikuyam
0
540
データサイエンス入門教育の現場から - 46歳新任教員2年間の苦闘
ikuyam
0
670
Other Decks in Business
See All in Business
WDB株式会社エウレカ社会社説明資料
eureka01
0
3.6k
SimpleForm 会社紹介資料
simpleform
2
56k
5年間コードを書かなかったVPoEが なぜ現場に戻ったのか?
gessy0129
1
270
unname_会社概要資料 2026.06.25 update
unnameinc
PRO
1
4.1k
FABRIC TOKYO会社紹介資料 / We are hiring(2026年06月17日更新)
yuichirom
39
410k
Miroom Company Deck
miroom
0
220
会社紹介資料/Idein株式会社 ※URLが変わりました
ideininc
0
63k
2026.7_中途採用資料.pdf
superstudio
PRO
5
120k
PMMから始まる経営 PMM→CMO/CPOの5年から導いた、 PMMの役割
kazuotanaka
1
250
エムスリーキャリア Work Support採用資料 / M3C Work Support
m3c
0
14k
余白を生むセルフマネジメント/Self-Management That Creates Breathing Room
ikuodanaka
2
2.8k
AI時代のリスク管理は どうあるべきか考えてみる
0air
0
220
Featured
See All Featured
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
390
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.1k
Six Lessons from altMBA
skipperchong
29
4.3k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
Discover your Explorer Soul
emna__ayadi
2
1.2k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
220
The Mindset for Success: Future Career Progression
greggifford
PRO
0
410
The SEO identity crisis: Don't let AI make you average
varn
0
510
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
170
Creating an realtime collaboration tool: Agile Flush - .NET Oxford
marcduiker
35
2.5k
Transcript
2020.05.29 Exploratory様 データサイエンス勉強会 #13 Chatwork株式会社 プロダクトマネジメント室 プロダクトマネージャー 田中 亜希 データの民主化 〜Chatworkのデータ活用の取り組み〜
目次 2 • 自己紹介 • テーマ「データの民主化」 • SQLの民主化 • BIツール
自己紹介 3 田中 亜希 • Chatworkのグロース施策担当 ◦ ユーザーのアクティベーション ◦ フリープランユーザー有料化 •
Exploratoryの導入など、社内のデータ活用の普及活動 Chatwork 株式会社 プロダクトマネージャー室
01 テーマ「データの民主化」 属人化することの課題 4
データが属人化している状態とは 5 • 例えば ◦ エンジニア(データを記録してくれている・SQL書ける) ◦ データサイエンティスト、データアナリスト(専門家) • 他のメンバーはどんなデータがあるか知らない、知っていても使い方がわからない状態
データをみられるのは社内の一部メンバーのみ
ここでいう「データ」とは 6 • 本来このようなデータを最も活用できる立場にあるのは ◦ プロダクトの企画運営者(プロダクトマネージャー) ◦ カスタマーサクセス ◦ マーケター、セールスなど
• 彼らが自分でデータを使えない状態=データの属人化 プロダクト利用状況 ユーザー属性 セールスリード・商談 各機能がどれくらい 使われているか 登録時期、言語、利 用プラン、業種など 見込み顧客の状況 誰が活用できるか
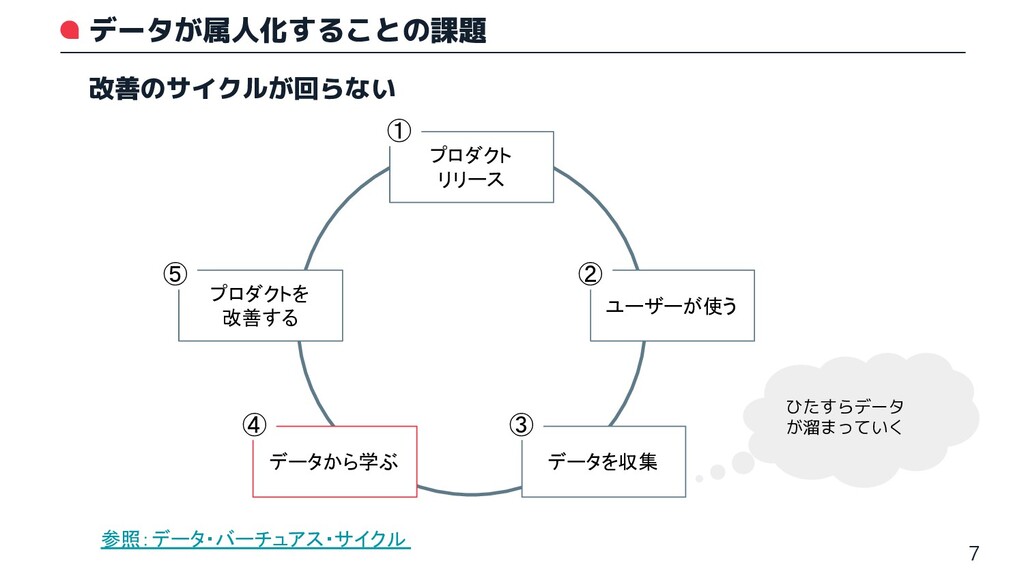
データが属人化することの課題 7 改善のサイクルが回らない プロダクト リリース ユーザーが使う データを収集 データから学ぶ プロダクトを 改善する
参照:データ・バーチュアス・サイクル ひたすらデータ が溜まっていく ① ② ③ ④ ⑤
誰かに依頼して必要なデータを取得してもらうことはできる。でも・・・ 8 • 一部メンバーに依頼が集中 ◦ 専業のメンバーがいない場合、依頼先のメンバーは本来の業務に集中できない • 例:エンジニアは実装が本務。データ抽出依頼は自然と後回しに・・ 時間がかかってしまう →誰もが自分でデータを使えるようにしたい(データの民主化)
そもそもどんなデータがあるかがわからない • イメージしているものが取得できる・できないを判断できない ◦ 非現実的な依頼になってしまう
02 SQLの民主化 教えて広める 9
Chatworkでの取り組み例 10 • 元々は社内唯一のデータアナリスト(ただし専業ではない)が始めた取り組み ◦ 参加もレクチャーも任意 • カリキュラム(30分4コマくらい) ◦ 社内のデータ分析環境(データベースアーキテクチャ)
◦ 記録されているデータについて(どんなテーブルがあるのか) ◦ SQL概要(サブクエリくらいまで) • 疑問点はチャットでも随時サポート(チャットの会社なので・・) 非エンジニアを対象にしたSQLのレクチャー会の実施
職種で選べる2つのコース 11 コース プロダクトコース セールス・マーケコース 参加者 プロダクトマネージャー デザイナー マーケター インサイドセールス
内容 プロダクトやユーザーのデータ中心 リード(Salesforce、Marketo)の データ中心 • 職種によってよく使うデータが違う • レクチャーのゴール ◦ 実際にSQLをガッツリ書けるようになるよりも、どんなデータが使えて、SQLでどん な抽出ができるのかを理解することがまず重要
03 BIツール ツールを使って簡単に 12
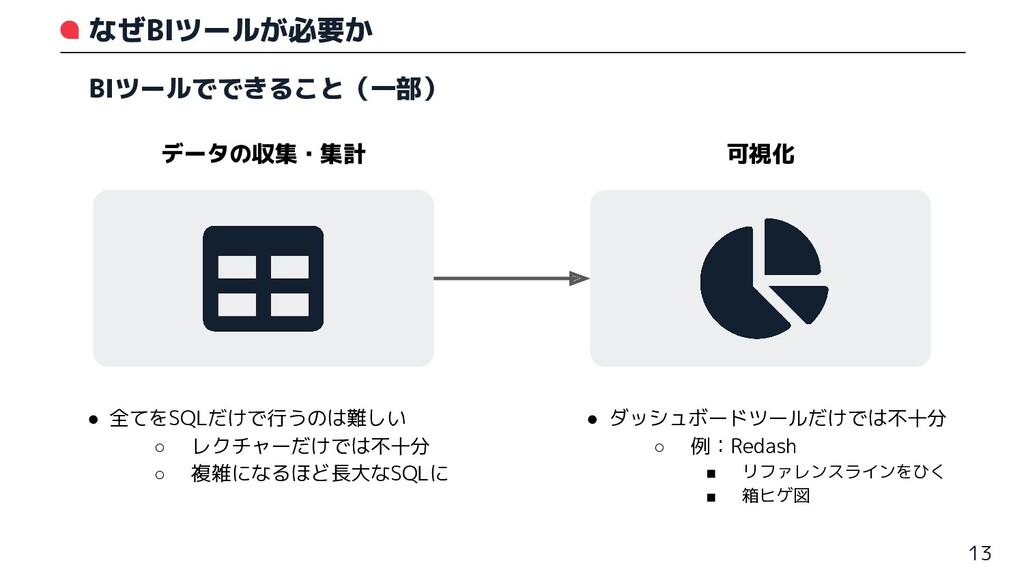
なぜBIツールが必要か 13 データの収集・集計 可視化 • 全てをSQLだけで行うのは難しい ◦ レクチャーだけでは不十分 ◦ 複雑になるほど長大なSQLに
• ダッシュボードツールだけでは不十分 ◦ 例:Redash ▪ リファレンスラインをひく ▪ 箱ヒゲ図 BIツールでできること(一部)
• 某大手BIツールを導入してみた(2019年) ◦ 減っていく利用者 ▪ 定常的に使われていたのは10ライセンス中2ライセンス・・ • 使われなかった要因 ◦ 全てをGUIで操作できるが、最初のデータ読み込みに時間がかかりつまづく
▪ 効率的にデータを読み込むには結局SQLを書く必要がある ◦ メンバー間で協力しづらい ◦ サポート体制 ▪ 上記のような状態を改善できず ChatworkではBIツールも活用しています 14 しかし導入すればよいというものではなかった・・
15 • 当初はデータをSQLで抽出する時点で導入難しいと思った • しかし、全員がゼロからデータ分析しなくても運用できる方法がある ◦ 同じ職種であれば使うデータは似通っている ▪ 誰かがデータ抽出のテンプレートを作り、他の人はそれを使ってほぼ可 視化だけをすればいい
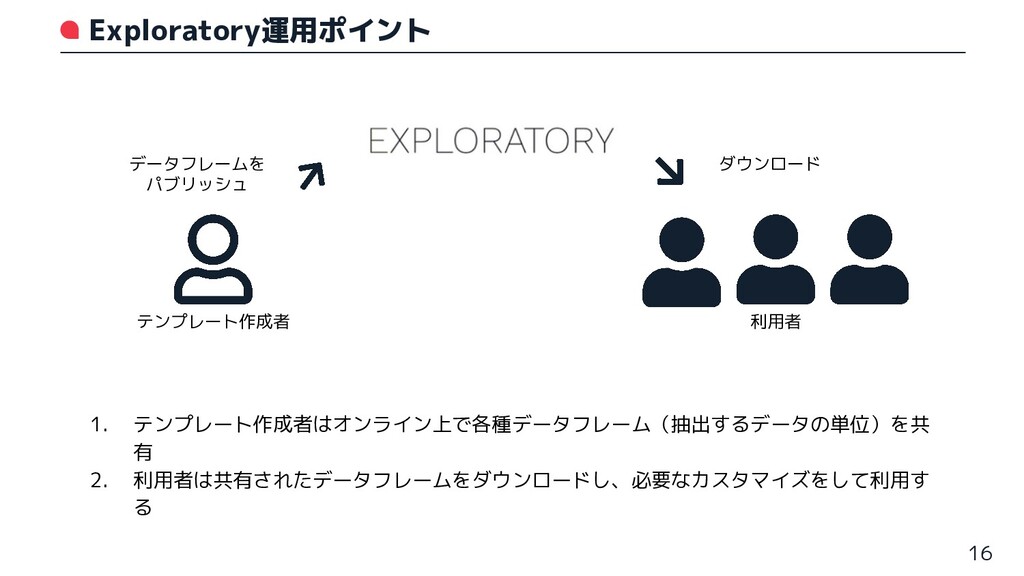
• これがうまくはまった ◦ Exploratory導入へ(2020年) Exploratory導入のポイント 全員がゼロからデータ分析しなくてもいい
1. テンプレート作成者はオンライン上で各種データフレーム(抽出するデータの単位)を共 有 2. 利用者は共有されたデータフレームをダウンロードし、必要なカスタマイズをして利用す る Exploratory運用ポイント 16 データフレームを パブリッシュ
ダウンロード テンプレート作成者 利用者
1. データフレーム作成時に、データの「取得期間」や「対象のカテゴリー」など、利用者が 変更する可能性のある箇所はパラメーター(変数)にしておく a. 「@{パラメーター名}」の部分 1.テンプレート作成(作成者) 17 パラメーターの利用
1. データフレームごとにタグをつけたり概要説明も書いてわかりやすくしておく 2.データフレームの共有(作成者) 18 パブリッシュ
1. 利用者はデータカタログ(Exploraotryでのパブリッシュされたデータのこと)からEDFで データをダウンロード 3.データフレームのダウンロード(利用者) 19 データカタログ
4.データをカスタマイズ(利用者) 20 パラメーターの編集 1. EDFファイルをExploratoryのデスクトップアプリで開く 2. データの加工のステップやパラメータの設定が残っているので必要に応じてカスタマイズ 3. 可視化をするなどして分析(すぐ分析できてカンタン)
まとめ 21 データの属人化の課題 • 社内にどんなデータがあるのか、データ抽出の基本としてのSQLを広めていく • データ集計・可視化を自分で簡単に行うためにBIツールを導入 • 誰もがデータを自分で扱えるようになり、データの属人化が解消される データの民主化へ
• サービス運営・企画、マーケティングなどデータを活用できる職種のメンバーが自分で データを活用できない • 誰かに依頼するとしてもどんな依頼ができるかわからない・時間がかかってしまう • データがただ溜まっていくだけでデータから学ぶサイクルが回らない
04 最後に お知らせ 22
グロース担当プロダクトマネージャー募集中 23 https://www.wantedly.com/projects/429264 ご入社でもれなく Exploratoryライセンス進呈!
働くをもっと楽しく、創造的に 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}