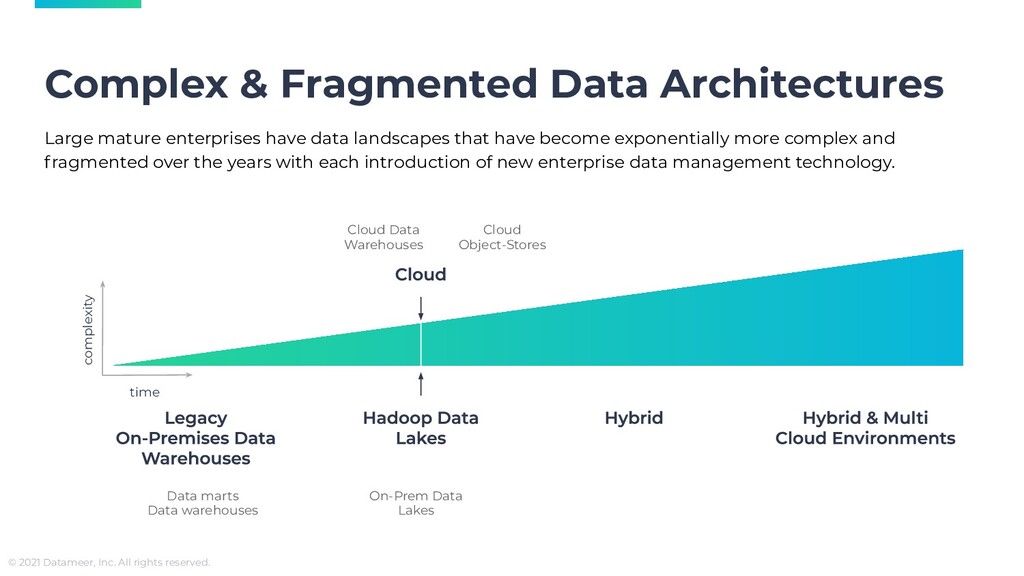
10 million data centers have been built over the last decade, according to IDC. Now, data centers have the same carbon footprint as the entire aviation industry pre-pandemic. Lengthy & Unwieldy Business users need instant access to data to make real-time business decisions. Current batch ETL processes for moving data don’t give users the instant access they need. Making matters worse, it takes days, weeks, and sometimes months to initially set up a data pipeline. Data pipelines’ specifications can also get lost in translation between the business domain experts and the data engineers who build them, complicating things further. What’s more, business users don’t always know what transformations, cleansing, and manipulation they’ll want to apply to the data, and having to go back and forth with data engineers makes the discovery process very cumbersome. Hadoop was designed to solve this issue with schema on read. But the complexity of the technology combined with the still monolithic data lake model doomed this ecosystem. Governance & Security Risks Replicating data via data pipelines comes with its own regulatory, compliance, and security risks. The centralized data approach gave IT teams the illusion of tighter control and data governance. However, this approach backfired. With data sets never exactly meeting business needs, different teams began to set up their own data marts, and the proliferation of these only exacerbated data governance issues. Sunk Costs & Throwing Good Money after Bad Over the years, organizations have made significant investments to build their version of the enterprise data warehouse. And despite these projects falling short of their promises, organizations have been committing what economists call the sunk cost fallacy by throwing more money at them, in an attempt to fix them, e.g., recruiting more specialized engineers and buying more tools vs. looking for alternative approaches and starting anew. Enterprises will, for example, move some of their data to the cloud on AWS, Azure, Google, or Snowflake on the promise of faster, cheaper, more user-friendly analytics. Migration projects are rarely 100% successful and often result in more fragmented data architectures that make it harder to perform analytics in hybrid or multi-cloud environments. Businesses might purchase Alteryx, for example, to enable domain experts to transform data locally on their laptop, contributing to more data chaos and the proliferation of ungoverned data sets. After that, they’ll purchase a data catalog, to index that data and help business users find it. On top of that, the IT team will want to
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}