Development of a Japanese-English Software Manual Paralell Corpus
Tatsuya Ishisaka, Masao Utiyama, Eiichiro Sumita and Kazuhide Yamamoto. Development of a Japanese-English Software Manual Paralell Corpus. Proceedings of the Twelfth Machine Translation Summit ( MT Summit XII), no page numbers (2009.8)
Ishisaka1 , Masao Utiyama2 Eiichiro Sumita2 , and Kazuhide Yamamoto1 1 Nagaoka University of Technology (Japan) 2 National Institute of Information and Communications Tehnology MASTAR Project (Japan)
Japanese-English parallel corpora are scarce. Domains of current corpora are limited. Patent has 18 million parallel sentences. Newspaper has 180 thousand parallel sentences. Goal We develop and publish Large-scale open source parallel corpus. Background
Web has many translated documents volunteer translators have made them We collected translated documents on the Web Open source software manuals z Large scale z The quality of translation is high
ex.) Command name Format differs from English to Japanese ex.) HTML files and Text file Manuals are being updated The latest original document version may be newer than the translated document version.
Web search engines manually to search for open source software manuals. We searched for Japanese Web pages containing phrases such as ༁ ϓϩδΣΫτ (translation project). If the Web pages are found, we downloaded manuals.
Following example licenses allow redistribution and modification. • MIT License • GNU Free Documentation License • FreeBSD Documentation License • Creative Commons We limited manuals to which such licenses were applied. Target license
1. We deleted HTML tags 2. We deleted newlines which break sentences One line has one sentence We checked sentences by using simple pattern match rules
We used Utiyama and Isahara’s (2007) alignment method. Overview of the algorithm 1. We translate words, using dictionary. 2. We calculate the similarity based on word overlap. 3. We calculate the maximum similarity sentences, using DP matching.
how errors are handled. ৽͍͠ϑΝΠϧ͕XMLΤσΟλͰ։͖·͢ɻ ˱The new file opens in the XML editor. ϝοηʔδͷHTTPϓϩτίϧόʔδϣϯΛઃఆ͠·͢ɻ ˱ Set the HTTP Protocol version of the message. ը૾ͷϚοτνϟωϧΛઃఆ͠·͢ɻ ˱ Sets the image matte channel. ͜ΕΒͦΕͧΕ௨ৗϢʔβʔͱroot ͷσϑΥϧτύεͰ͢ɻ ˱ That will be a default path for normal and root users respectively.
were precisely aligned. The further improvements are possible, since we have failed to clean up some noisy sentences. The alignment accuracy would improve if we remove such noisy sentences.
We simulated a situation where SMT systems helps translators. We only translated from English. Test data is 500 sentences. We extracted from the aligned JF sentences. The highest BLEU score was 44.36.
Japanese- English corpus. But we have to be careful about our experimental result. Reason: Our test sentences might not be representative samples. Sentences were relatively short. Our Japanese word segmenter segmented ASCII words into characters. ex.) “word” was segmented into “w o r d”
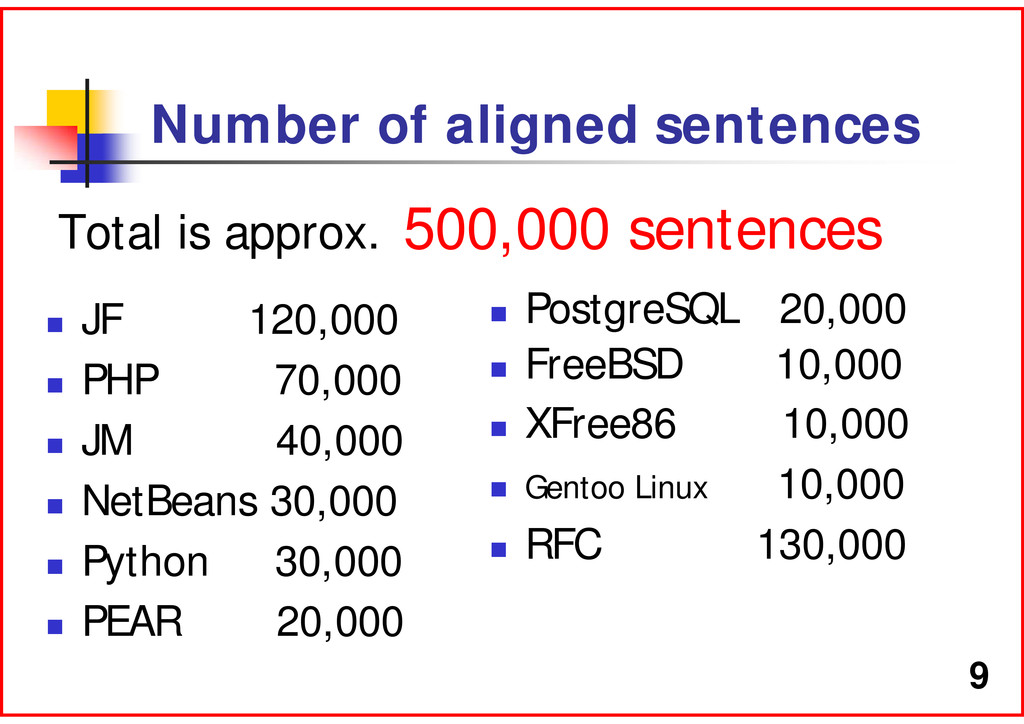
software manuals. The corpus has approx. 500,000 sentence pairs. The corpus will be available at: http://www2.nict.go.jp/x/x161/members/mutiyama / .
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}