Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
共起要素のクラスタリングを用いた分布類似度計算
Search
自然言語処理研究室
March 31, 2011
Research
160
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
共起要素のクラスタリングを用いた分布類似度計算
大平 真一, 山本 和英. 共起要素のクラスタリングを用いた分布類似度計算. 言語処理学会第17回年次大会, pp.292-295 (2011.3)
自然言語処理研究室
March 31, 2011
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
420
データサイエンス13_解析.pdf
jnlp
0
530
データサイエンス12_分類.pdf
jnlp
0
370
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Research
See All in Research
セマンティック通信勉強会 6Gに向けたデバイス間効率的な通信の技術紹介・課題・今後展望
satai
3
200
「なんとなく」の顧客理解から脱却する ──顧客の解像度を武器にするインサイトマネジメント
tajima_kaho
10
7.7k
世界モデルにおける分布外データ対応の方法論
koukyo1994
7
2.2k
コーディングエージェントとABNを再考
hf149
2
750
PGDM: Physically Guided Diffusion Model for L Downscaling
satai
3
320
【ローカルAIに向き合う展示会vol.2】液体時間定数型モジュールを用いた オリジナルの双方向エンコーダーモデルNexteraBERT 推論速度向上検討並びにダウンストリーム評価
rikkabotan7
0
100
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
3
350
LINEヤフー データサイエンス Meetup「三井物産コモディティ予測チャレンジ」の舞台裏-AlpacaTechパート
gamella
1
590
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
330
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
150
衛星×エッジAI勉強会 衛星上におけるAI処理制約とそ取組について
satai
4
590
敵対生成プロンプト同時探索による内省型プロンプト最適化
kinoue_smarthr
0
280
Featured
See All Featured
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
Navigating Weather and Climate Data
rabernat
0
270
Ethics towards AI in product and experience design
skipperchong
2
320
BBQ
matthewcrist
89
10k
30 Presentation Tips
portentint
PRO
1
340
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
430
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
State of Search Keynote: SEO is Dead Long Live SEO
ryanjones
0
220
Marketing to machines
jonoalderson
1
5.5k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
Transcript
共起要素の クラスタリングを用いた 分布類似度計算 長岡技術科学大学 電気系 山本研究室 大平 真一,山本 和英
単語類似度とは 意味が近い語同士を類似する単語とする 『そば』 と 『うどん』 は共通点が多い→類似度が高い 『そば』
と 『缶』 は性質など全く異なる→類似度が低い コーパスを用いた類似度計算 類似した文脈の語同士は似ている:分布仮説 コーパス内での単語の使われ方を比較 →分布類似度 ①
分布類似度とは 単語と素性の例 (共起要素を素性とした場合) 『そば』 「を,打つ」 「を,食べる」 「の,原料」 『うどん』
「を,打つ」 「を,食べる」 「の,原料」 『缶』 「を,蹴る」 「を,あける」 「の,ふた」 共通する素性が多い → 類似度が高い 共通する素性が少ない → 類似度が低い ②
既存研究 [相澤, 08] - 特徴を強く表す素性のみを使用 [柴田ら, 09] -
類似度計算に用いる式の検討 [Maayan Zhitomirsky-Geffet and Dagan, 09] - ブートストラップ法を用いての素性選択 [朝倉ら, 10] - 重みの相対性を用いた素性選択 ③
提案手法 計算に用いる共起要素をクラスタリングする 人名などの単語に依存する素性が有効となる 『単語 w』 : 「共起要素」 =
「格要素r,係り先の語w’」 『ドイツ』 : 「の,ビール」 「の,首相」 「の,州」 『フランス』 : 「の,人々」 「の,大統領」 「の,地域圏」 等価な意味の共起要素が 有効な素性となる 例 ④
システム全体の流れ 1. 共起要素の自動獲得 単語と共起要素の対を獲得[Lin, 98] 2. 共起要素のクラスタリング クラスタリングツールbayonを用いる
3. 関数を用いた類似度計算 Weight 関数によるノイズ低減と Measure 関数による類似度計算 [柴田ら, 09] ⑤
クラスタリング 『ドイツ』 : 「の,ビール」 「の,首相」 「の,州」 『フランス』 : 「の,人々」 「の,大統領」
「の,地域圏」 ↓ 『ドイツ』 : 「クラスタa」 「クラスタx」 「クラスタy」 『フランス』 : 「クラスタb」 「クラスタx」 「クラスタy」 例 共起要素をクラスタリング結果に置き換える ⑥
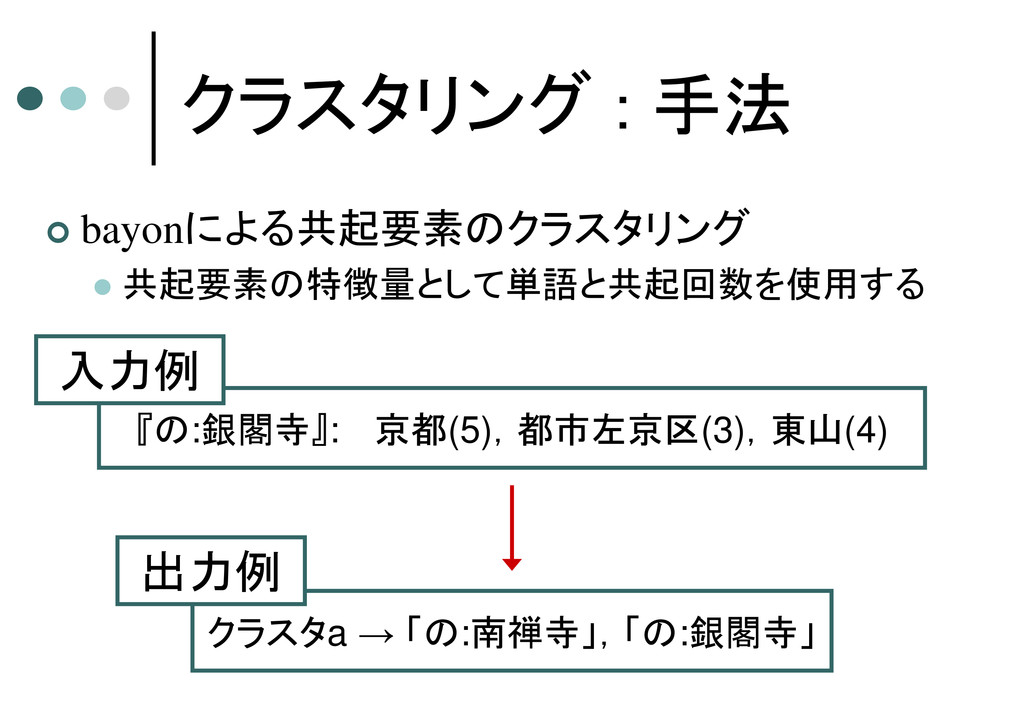
クラスタリング : 手法 bayonによる共起要素のクラスタリング 共起要素の特徴量として単語と共起回数を使用する 『の:銀閣寺』: 京都(5),都市左京区(3),東山(4) クラスタa
→ 「の:南禅寺」,「の:銀閣寺」 出力例 入力例
『強』類義語ペア→フランス:ドイツ 『中』類義語ペア→フランス:欧州 『弱』類義語ペア→フランス:日本人 『非』類義語ペア→フランス:建物 評価手法
シソーラスから類義語ペアを自動生成 『強』や『弱』など段階を設定する[朝倉ら, 10] 各段階ごとに800セットをランダムで使用 例 ⑦
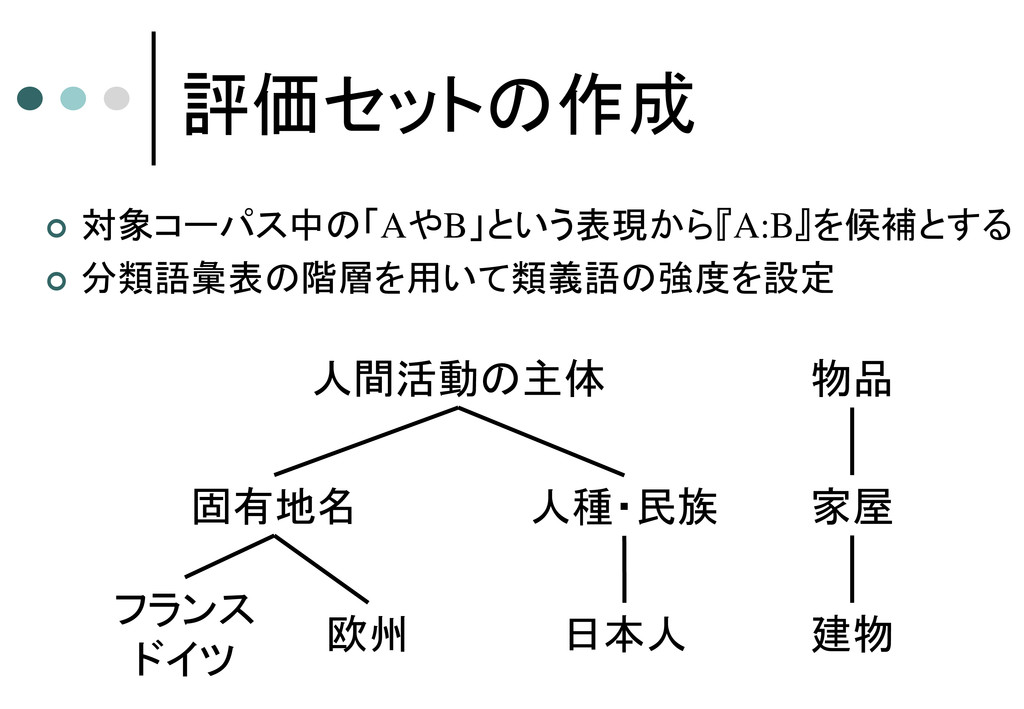
対象コーパス中の「AやB」という表現から『A:B』を候補とする 分類語彙表の階層を用いて類義語の強度を設定 物品 人間活動の主体 家屋 建物 固有地名 人種・民族
フランス ドイツ 欧州 日本人 評価セットの作成
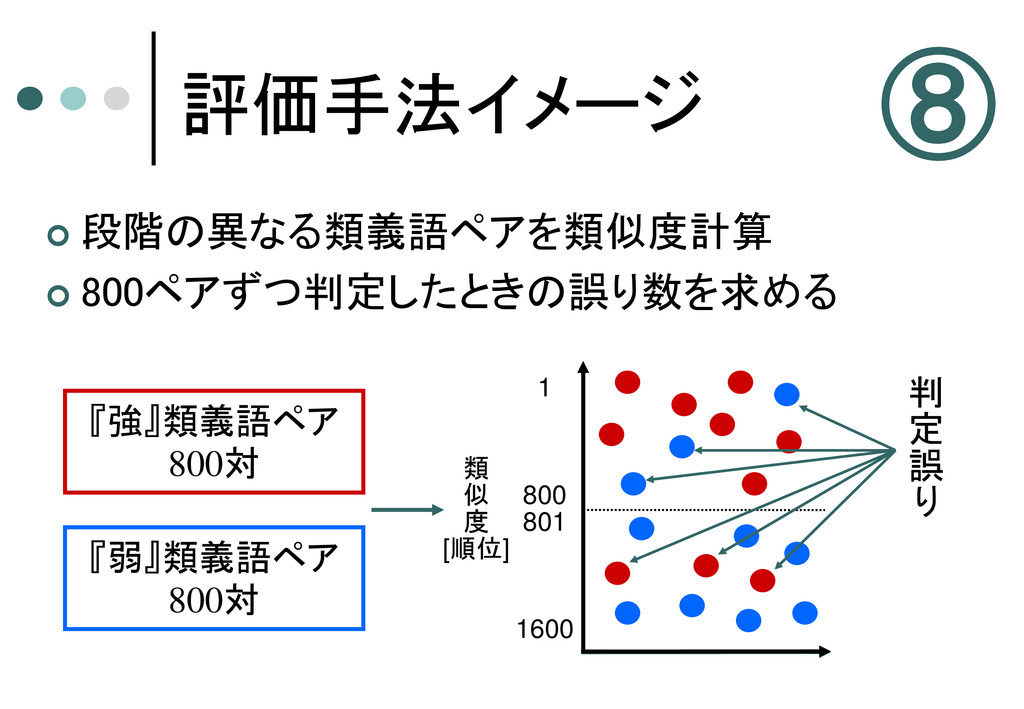
評価手法イメージ 段階の異なる類義語ペアを類似度計算 800ペアずつ判定したときの誤り数を求める 『強』類義語ペア 800対 『弱』類義語ペア 800対 1
800 801 1600 類 似 度 [順位] 判 定 誤 り ⑧
実験条件 使用したコーパス 日本経済新聞全記事データベース 1990~2004年度版 単語のユニーク数 : 145,057
個 共起要素のユニーク数 : 158,057 個 クラスタ数 12,500,2万5千,5万,7万5千,10万,12万5千 ⑨
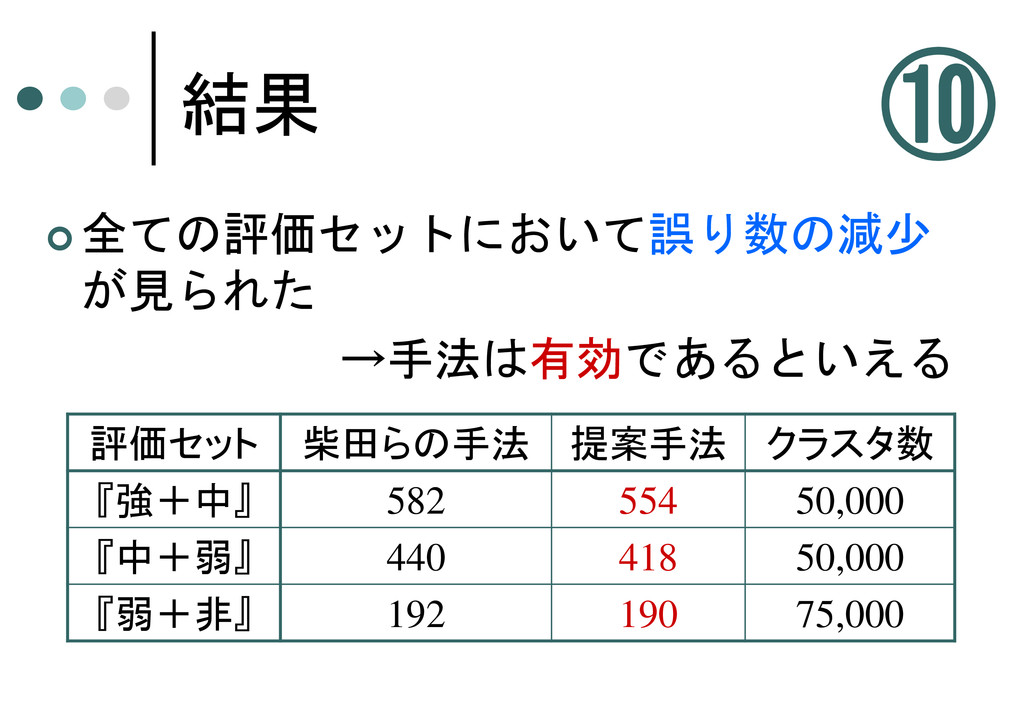
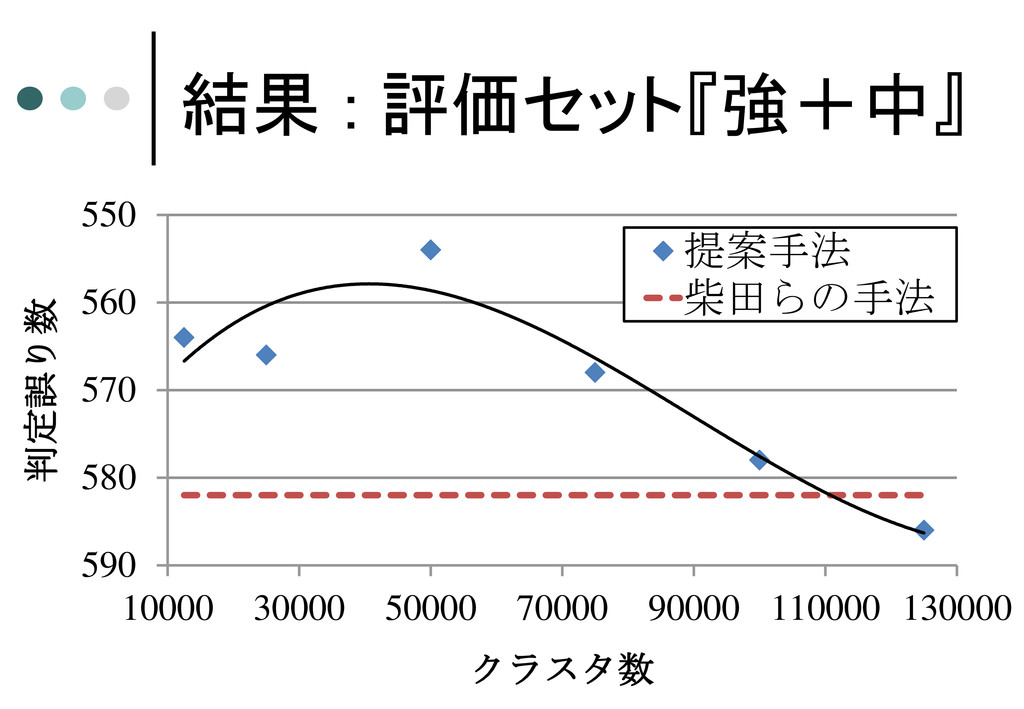
結果 全ての評価セットにおいて誤り数の減少 が見られた →手法は有効であるといえる 評価セット 柴田らの手法 提案手法 クラスタ数 『強+中』
582 554 50,000 『中+弱』 440 418 50,000 『弱+非』 192 190 75,000 ⑩
結果 : 評価セット『強+中』 550 560 570 580 590 10000 30000
50000 70000 90000 110000 130000 判定誤り数 クラスタ数 提案手法 柴田らの手法
考察 クラスタリングが原因の判定誤りがあった →精度向上に寄与するクラスタを選択する手法が 求められる 改善例には国名・地域名が多く見られた 特に『強+中』のセットにおいては39%を占めた →人名などのクラスタリングの効果が強く表れた
⑪
まとめ クラスタリングを行うことで等価な意味を持つ 共起要素をまとめることを狙った 既存手法に対して誤り数の減少を確認し、 有効性を示した 国名・地域名に対して特に効果が確認された ⑫
{kind=link}
{kind=link}
{kind=link}
![既存研究 [相澤, 08] - 特徴を強く表す素性のみを使用 [柴田ら, 09] -](https://files.speakerdeck.com/presentations/427f0780c5bf013037e12a36d8f42a9e/slide_3.jpg){kind=link}
{kind=link}
![システム全体の流れ 1. 共起要素の自動獲得 単語と共起要素の対を獲得[Lin, 98] 2. 共起要素のクラスタリング クラスタリングツールbayonを用いる](https://files.speakerdeck.com/presentations/427f0780c5bf013037e12a36d8f42a9e/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}