Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] Pay Attention to MLPs
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
July 19, 2021
Technology
1.5k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] Pay Attention to MLPs
Semantic Machine Intelligence Lab., Keio Univ.
PRO
July 19, 2021
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
85
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
370
「顧客の声を聞かなければ何も始まらない」 ── 顧客の声から生まれた『AI返信補助機能』の開発プロセス / AICon2026_shikata_imai
rakus_dev
1
270
設計レビューとAIハーネスで向き合う AIが生み出した新しいボトルネックの対処法 / Design Reviews and AI Harnesses Against New Bottlenecks Created by AI
nstock
4
430
変更し続けられるシステムをどう保つか — AI時代のSSoTという設計原則
kawauso
1
1.1k
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
5
1.2k
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
610
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
230
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
3
520
StepFunctionsとGraphRAGを活用した暗黙知活用のためのRAG基盤
yakumo
0
140
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.3k
AIとハーネスで育てるトランスコンパイラ / 20260722 Yasushi Katayama
shift_evolve
PRO
3
780
2年前に削除したPHPクラスが、 ある日突然決済をエラーにした
ykagano
1
780
Featured
See All Featured
Fashionably flexible responsive web design (full day workshop)
malarkey
408
67k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
Optimizing for Happiness
mojombo
378
71k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
810
So, you think you're a good person
axbom
PRO
2
2.1k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
How STYLIGHT went responsive
nonsquared
100
6.2k
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
340
Transcript
Hanxiao Liu, Zihang Dai, David R. So, Quoc V. Le
(Google Research, Brain Team) Pay Attention to MLPs Liu, Hanxiao, et al. "Pay Attention to MLPs." arXiv preprint arXiv:2105.08050 (2021). 慶應義塾大学 杉浦孔明研究室 畑中駿平
2 • Attention-free transformer の一種である「gMLP」の提案 • Transformer の構造を変更した gate 付き
Multi Layer Perceptron ( MLP ) のみで設計 概要 ✓ gMLP が現在の Transformer よりも優れた性能、または同等の性能を発揮 ✓ self-attention がさほど重要な要素ではない
3 • Transformer [Vaswani+, NIPS2017] の出現 − Natural Language Processing
( NLP ) … LSTM・RNN → BERT [Devlin+, NAACL2018] − Computer Vision ( CV ) … CNN → ViT [Dosovitskiy+, ICLR2020] • self-attention の特徴 1. 再帰的ではない ( = 並列処理 ) 2. token 間の空間情報を取得 背景:Transformer の出現による NLP, CV の発展
• Attention 機構のメリット [Bahdanau+, ICLR2015] − 入力データの表現に基づいた動的なパラメータの 決定により、より有効な帰納バイアスを導入可能 − 帰納バイアスが顕著に有効かどうか未解決
• MLP のメリット[Hornik+, 1989] − 静的なパラメータで任意の関数を近似可能 問題提起:MLP での代替案・Attention の必要性 • MLP で self-attention の特徴を表現可能か • self-attention を用いる必要性の是非 4
5 • 2021年以降に MLPs が再評価されている − ただし、MLP よりも Transformer のほうが依然として精度がよい
既存手法:MLPs が再評価されている ( 2021年以降 ) 既存手法 特徴 Transformer BERT [Devlin+, NAACL2018] • TransformerのEncoderを使ったモデル • 事前学習としてMLMとNSPを学習 ViT [Dosovitskiy, ICLR2020] DeiT [Hugo+, 2020] • 画像パッチを単語のように扱う • DeiT は ViT の学習データやパラメータを減らしたモデル MLP MLP-Mixer [Tolstikhin+, 2021] • 画像パッチをチャンネル方向および空間方向に関して MLPで変換 ResMLP [Touvron+, 2021] • 画像パッチをMLPのみでできた残差ブロックに複数回 通して、分類ヘッドに入力
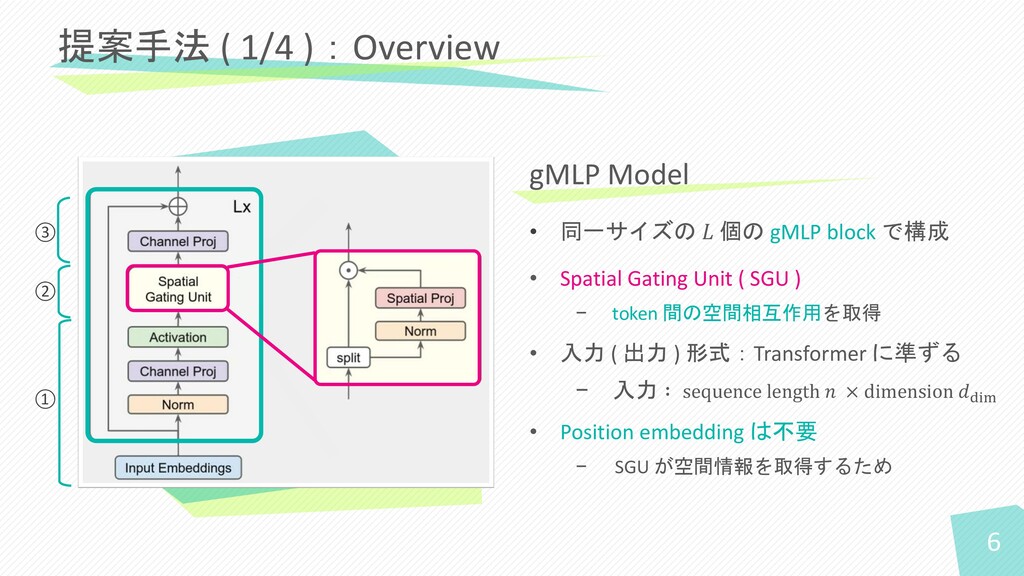
• 同一サイズの 𝐿 個の gMLP block で構成 • Spatial Gating
Unit ( SGU ) − token 間の空間相互作用を取得 • 入力 ( 出力 ) 形式:Transformer に準ずる − 入力 ∶ sequence length 𝑛 × dimension 𝑑dim • Position embedding は不要 − SGU が空間情報を取得するため 提案手法 ( 1/4 ):Overview gMLP Model 6 ① ② ③
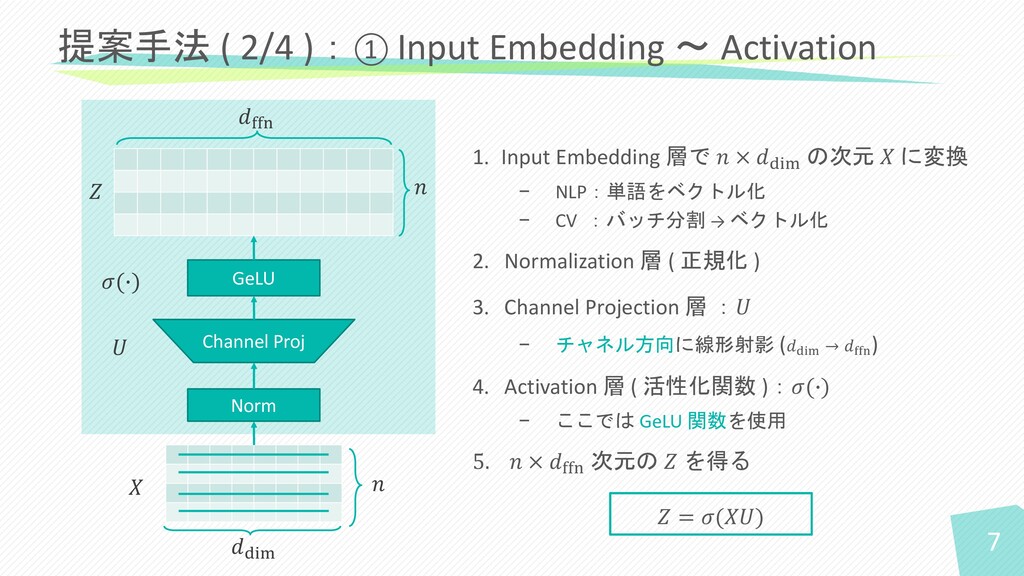
1. Input Embedding 層で 𝑛 × 𝑑dim の次元 𝑋 に変換
− NLP:単語をベクトル化 − CV :バッチ分割 → ベクトル化 2. Normalization 層 ( 正規化 ) 3. Channel Projection 層 :𝑈 − チャネル方向に線形射影 (𝑑dim → 𝑑ffn ) 4. Activation 層 ( 活性化関数 ):𝜎(∙) − ここでは GeLU 関数を使用 5. 𝑛 × 𝑑ffn 次元の 𝑍 を得る 提案手法 ( 2/4 ):① Input Embedding ~ Activation Norm Channel Proj GeLU 𝑛 𝑑dim 𝑑ffn 𝑈 𝜎(∙) 𝑍 𝑍 = 𝜎(𝑋𝑈) 𝑋 𝑛 7
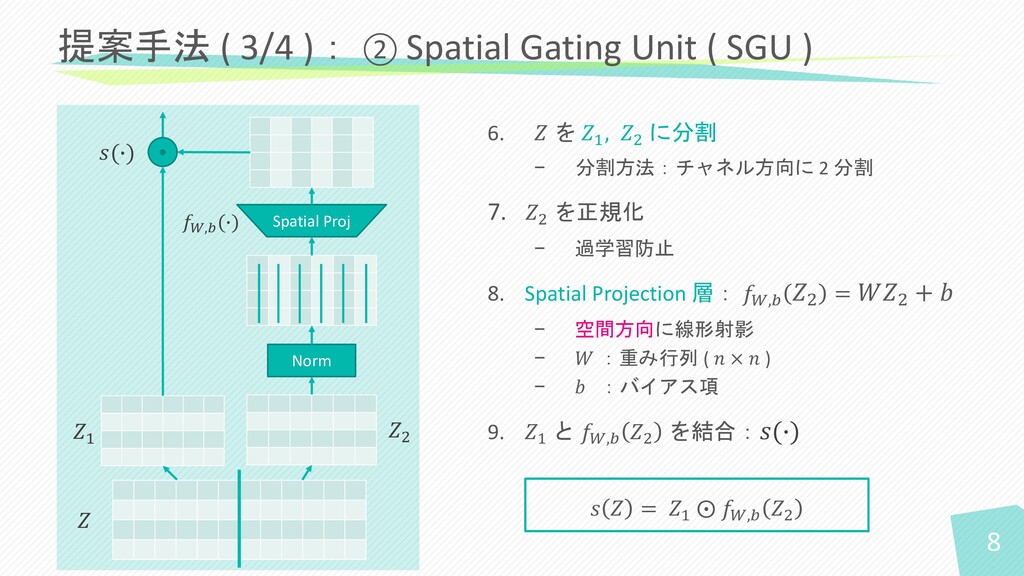
6. 𝑍 を 𝑍1 , 𝑍2 に分割 − 分割方法:チャネル方向に 2
分割 7. 𝑍2 を正規化 − 過学習防止 8. Spatial Projection 層: 𝑓𝑊,𝑏 𝑍2 = 𝑊𝑍2 + 𝑏 − 空間方向に線形射影 − 𝑊 :重み行列 ( 𝑛 × 𝑛 ) − 𝑏 :バイアス項 9. 𝑍1 と 𝑓𝑊,𝑏 𝑍2 を結合:𝑠(∙) 提案手法 ( 3/4 ): ② Spatial Gating Unit ( SGU ) 𝑠 𝑍 = 𝑍1 ⨀ 𝑓𝑊,𝑏 𝑍2 8 𝑍 Norm Spatial Proj 𝑍1 𝑍2 𝑓𝑊,𝑏 (∙) 𝑠(∙)
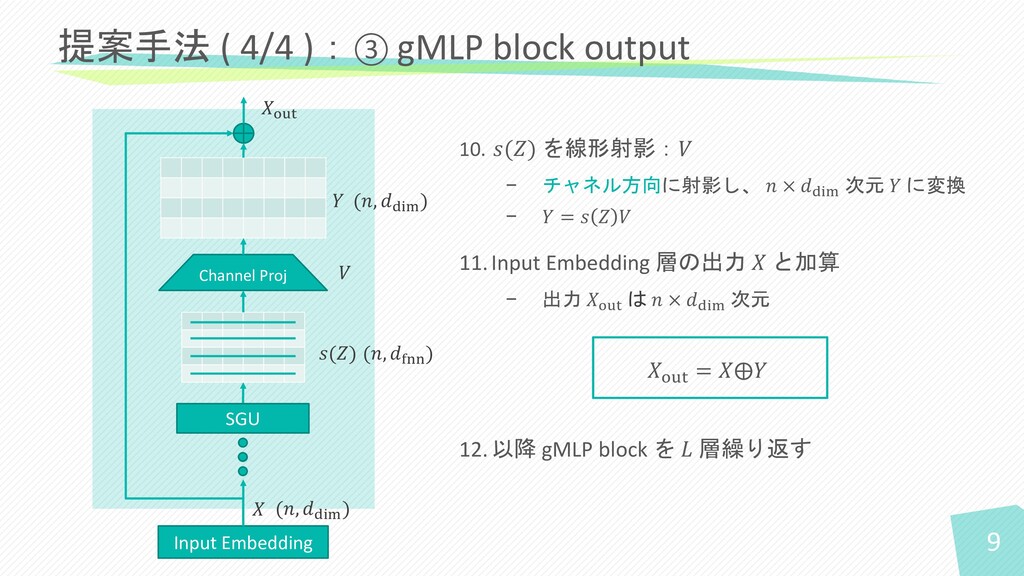
10. 𝑠(𝑍) を線形射影:𝑉 − チャネル方向に射影し、 𝑛 × 𝑑dim 次元 𝑌
に変換 − 𝑌 = 𝑠 𝑍 𝑉 11.Input Embedding 層の出力 𝑋 と加算 − 出力 𝑋out は 𝑛 × 𝑑dim 次元 12.以降 gMLP block を 𝐿 層繰り返す 提案手法 ( 4/4 ):③ gMLP block output 𝑠(𝑍) 𝑋out = 𝑋⨁𝑌 Channel Proj SGU Input Embedding 𝑉 (𝑛, 𝑑dim ) (𝑛, 𝑑dim ) 𝑋out 𝑌 𝑋 (𝑛, 𝑑fnn ) 9
• ImageNet で画像分類タスクの性能比較 − gMLP は3つのサイズのモデルを用意 ✓ DeiT と同等な性能 −
self-attention は CV において不要 ✓ 他の MLP 系列の中で最も精度が高い − SGU の有効性の確認 ✓ CNN モデルのほうがよい精度 − EfficientNet [Tan+, ICML2019] − NFNet [Brock+, 2021] 結果 ( 1/3 ):画像分類タスクで DeiT と同等な性能を獲得 10 Model ImageNet Top1 ( % ) ConvNets EfficientNet-B0 77.1 EfficientNet-B3 81.6 EfficientNet-B7 84.3 NFNet-F0 84.3 Transformer DeiT-Ti 72.2 DeiT-S 79.8 DeiT-B 81.8 MLP-like Mixer-B/16 76.4 Mixer-L/16 71.8 ResMLP-12 76.6 ResMLP-24 79.4 ResMLP-36 79.7 gMLP-Ti ( ours ) 72.0 gMLP-S ( ours ) 79.4 gMLP-B ( ours ) 81.6
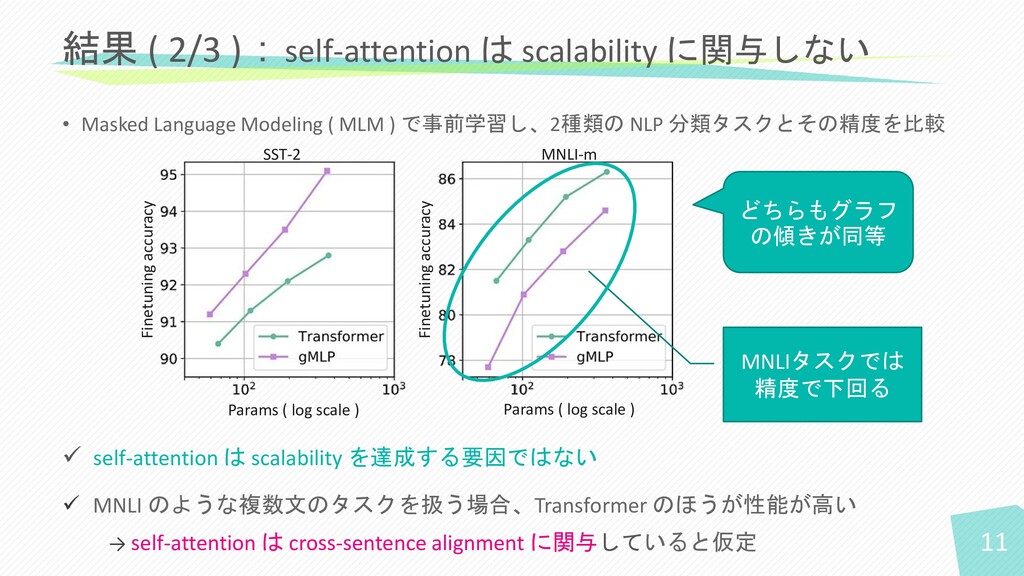
• Masked Language Modeling ( MLM ) で事前学習し、2種類の NLP 分類タスクとその精度を比較
MNLI-m ✓ self-attention は scalability を達成する要因ではない ✓ MNLI のような複数文のタスクを扱う場合、Transformer のほうが性能が高い → self-attention は cross-sentence alignment に関与していると仮定 結果 ( 2/3 ):self-attention は scalability に関与しない どちらもグラフ の傾きが同等 11 MNLIタスクでは 精度で下回る SST-2 Finetuning accuracy Finetuning accuracy Params ( log scale ) Params ( log scale )
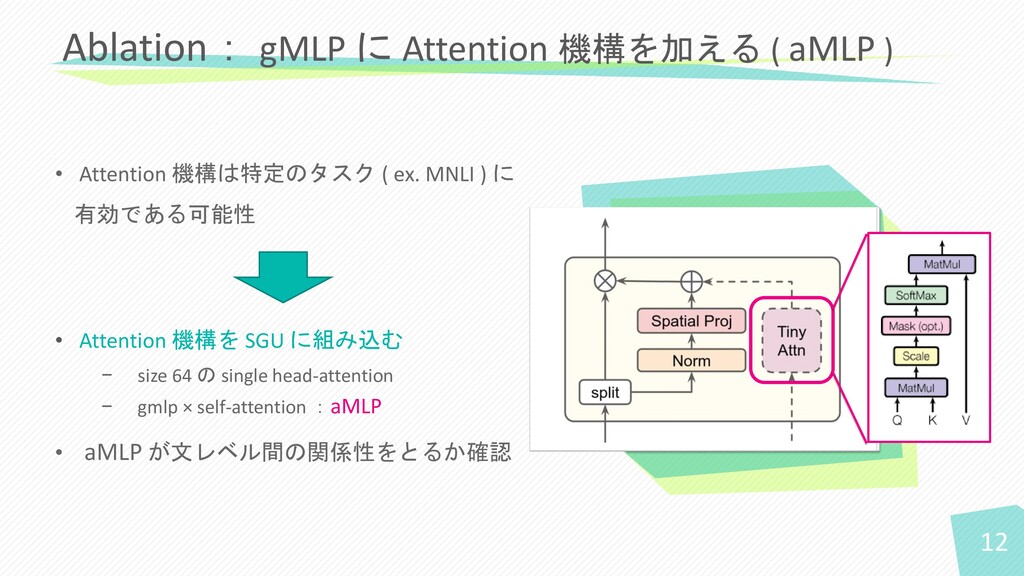
• Attention 機構は特定のタスク ( ex. MNLI ) に 有効である可能性 •
Attention 機構を SGU に組み込む − size 64 の single head-attention − gmlp × self-attention :aMLP • aMLP が文レベル間の関係性をとるか確認 Ablation: gMLP に Attention 機構を加える ( aMLP ) 12
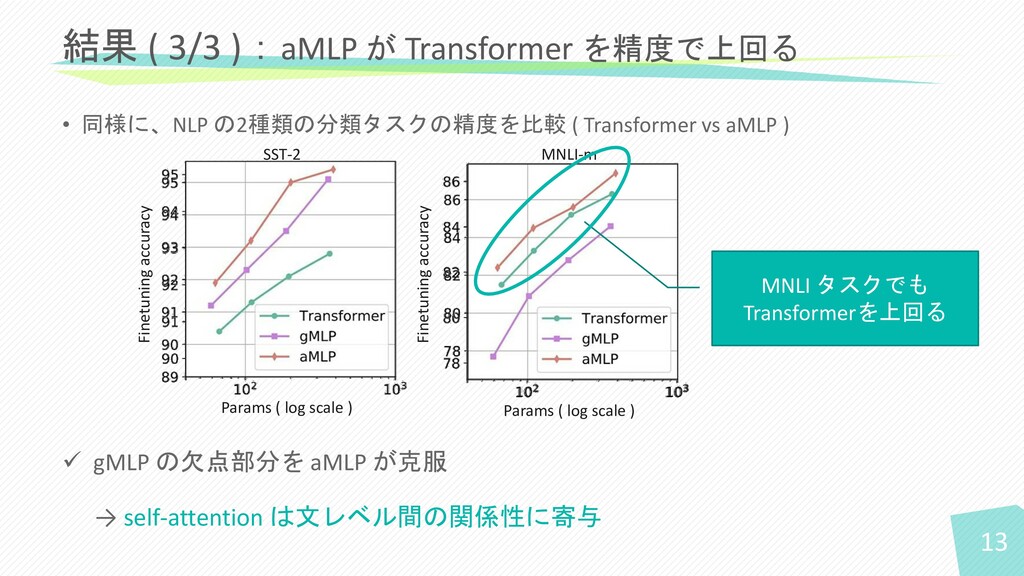
• 同様に、NLP の2種類の分類タスクの精度を比較 ( Transformer vs aMLP ) MNLI-m SST-2
✓ gMLP の欠点部分を aMLP が克服 → self-attention は文レベル間の関係性に寄与 結果 ( 3/3 ):aMLP が Transformer を精度で上回る 13 MNLI タスクでも Transformerを上回る Finetuning accuracy Finetuning accuracy Params ( log scale ) Params ( log scale )
14 • timm ライブラリの ImageNet 学習済みモデルを使用 • gMLP が正しく認識・EfficientNet が誤認識した例
✓ gMLP は局所的な認識、 Efficient Net は全体的な認識をしている gMLP と EfficientNet を実際に動かしてみた① ( 定性的結果 ) https://github.com/rwightman/pytorch-image-models.git 正解:アイスキャンディ 正解:瓶のキャップ EfficientNet の誤認識例 × ザリガニ × 水筒 EfficientNet の誤認識例 × トラック × 芝刈り機
15 • gMLP が誤認識・EfficientNet が正しく認識した例 ✓ gMLP は 物体が見切れている or
端に位置している 画像に対して認識が弱い → CV 分野にも aMLP を用いることで、画像バッチ間の関係性に注目し改善されるのではないか gMLP と EfficientNet を実際に動かしてみた② ( 定性的結果 ) https://github.com/rwightman/pytorch-image-models.git 正解:公園のベンチ 正解:テニスボール gMLP の誤認識例 × 斧 × カタツムリ gMLP の誤認識例 × タランチュラ × 注射器
16 • Attention-free transformer の一種である「gMLP」の提案 • self-attention 機構は CV ではほぼ必要性がない
• NLP でも特定のタスク以外では必要性が低い まとめ SLIDE 16 ✓ self-attention は文横断的な alignment を必要とするタスクに有効 ✓ gMLP のモデルを大きくする or aMLP でTransformer との差を縮小
{kind=link}
{kind=link}
![3 • Transformer [Vaswani+, NIPS2017] の出現 − Natural Language Processing](https://files.speakerdeck.com/presentations/cebb0498b73c4f73b87e2efd5b3f1bb2/slide_2.jpg){kind=link}
![• Attention 機構のメリット [Bahdanau+, ICLR2015] − 入力データの表現に基づいた動的なパラメータの 決定により、より有効な帰納バイアスを導入可能 − 帰納バイアスが顕著に有効かどうか未解決](https://files.speakerdeck.com/presentations/cebb0498b73c4f73b87e2efd5b3f1bb2/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}