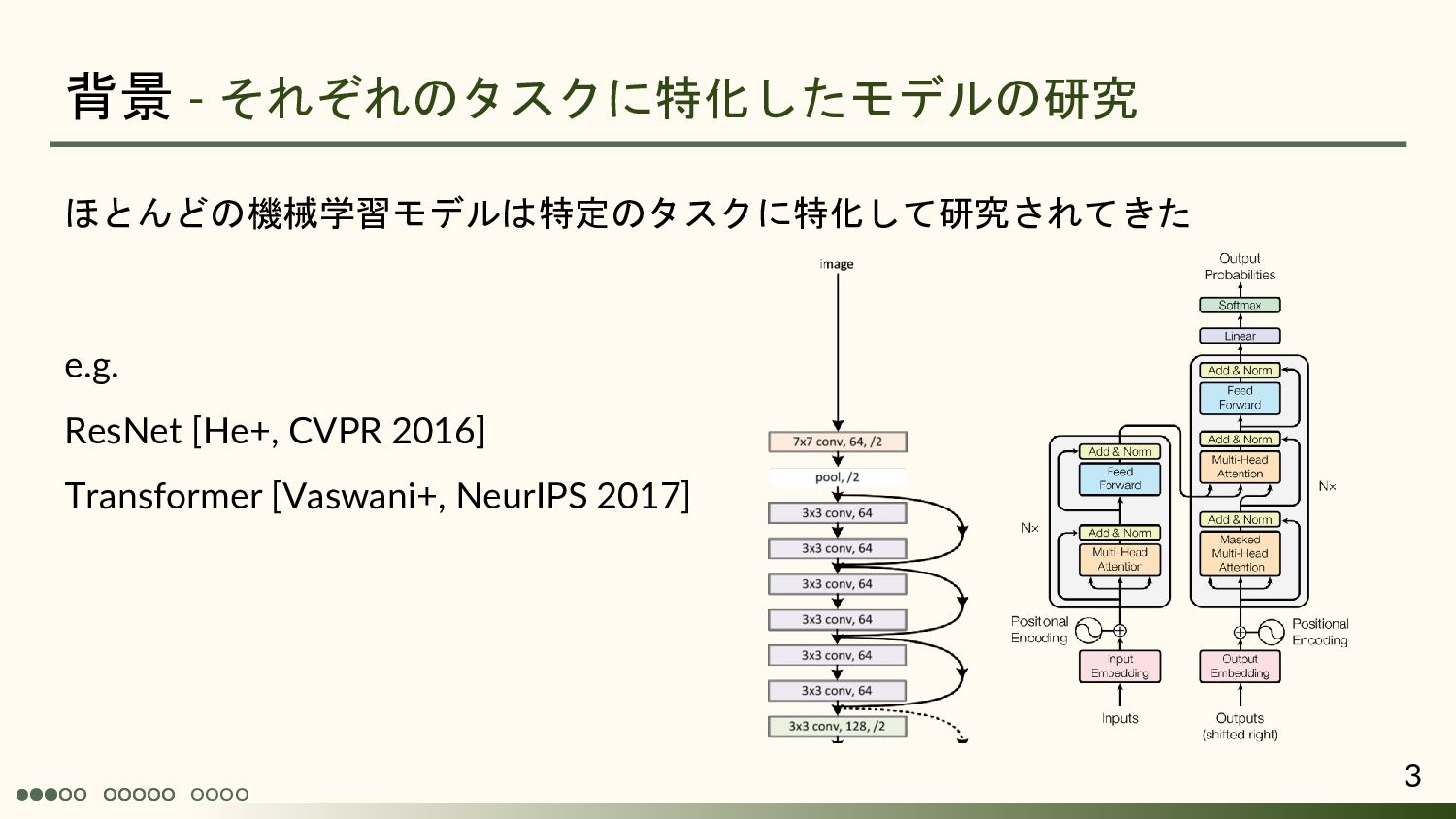
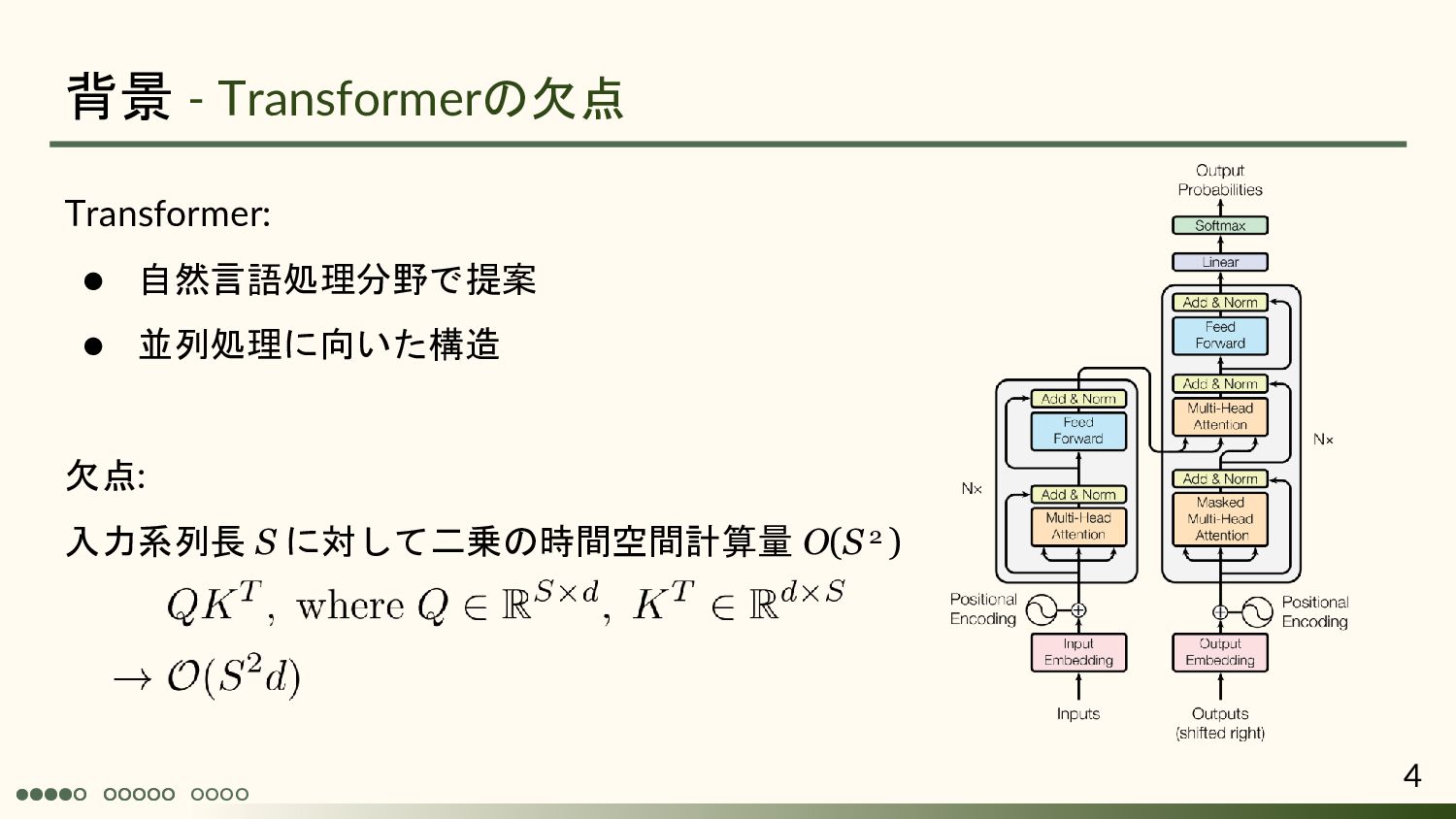
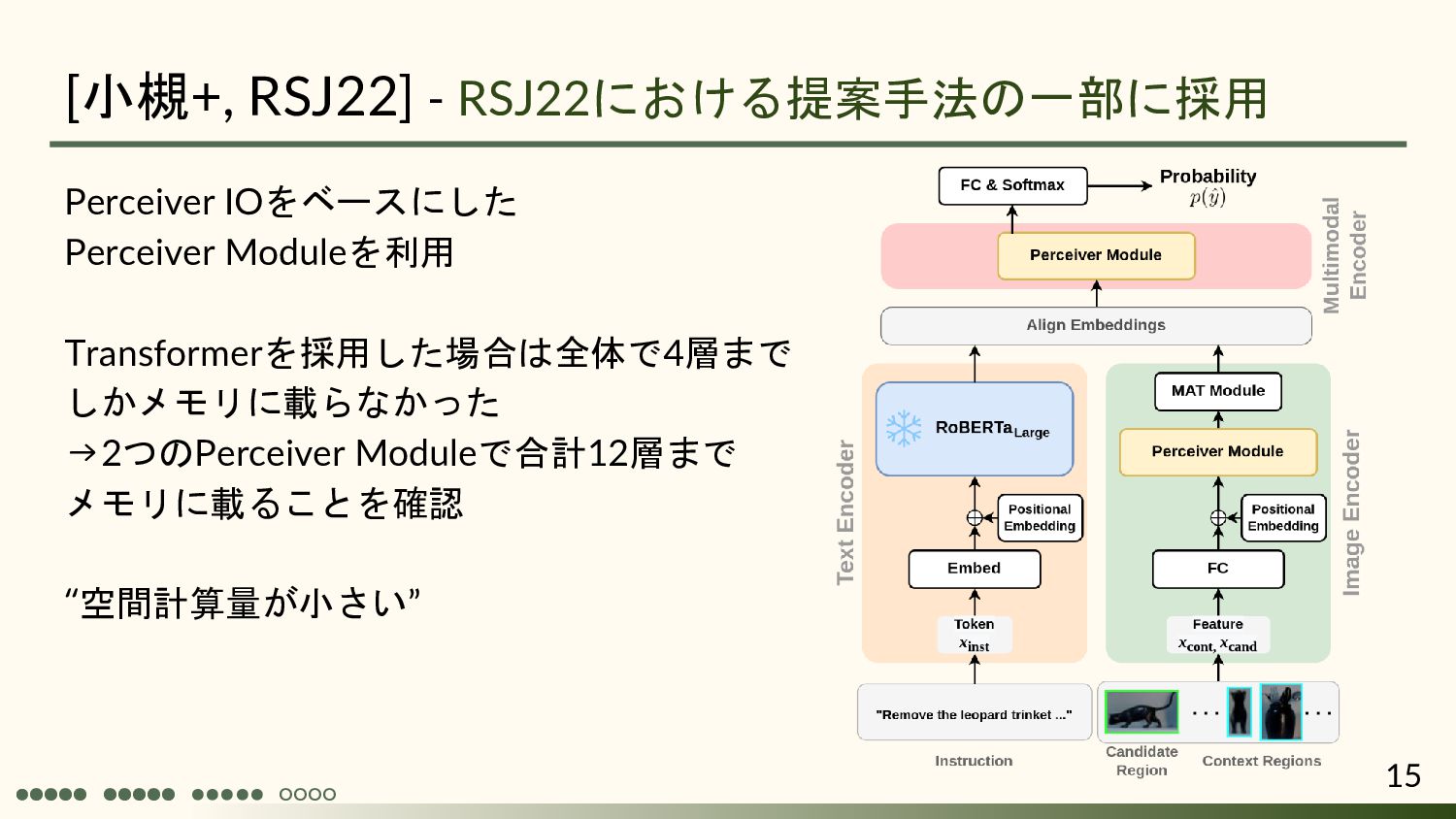
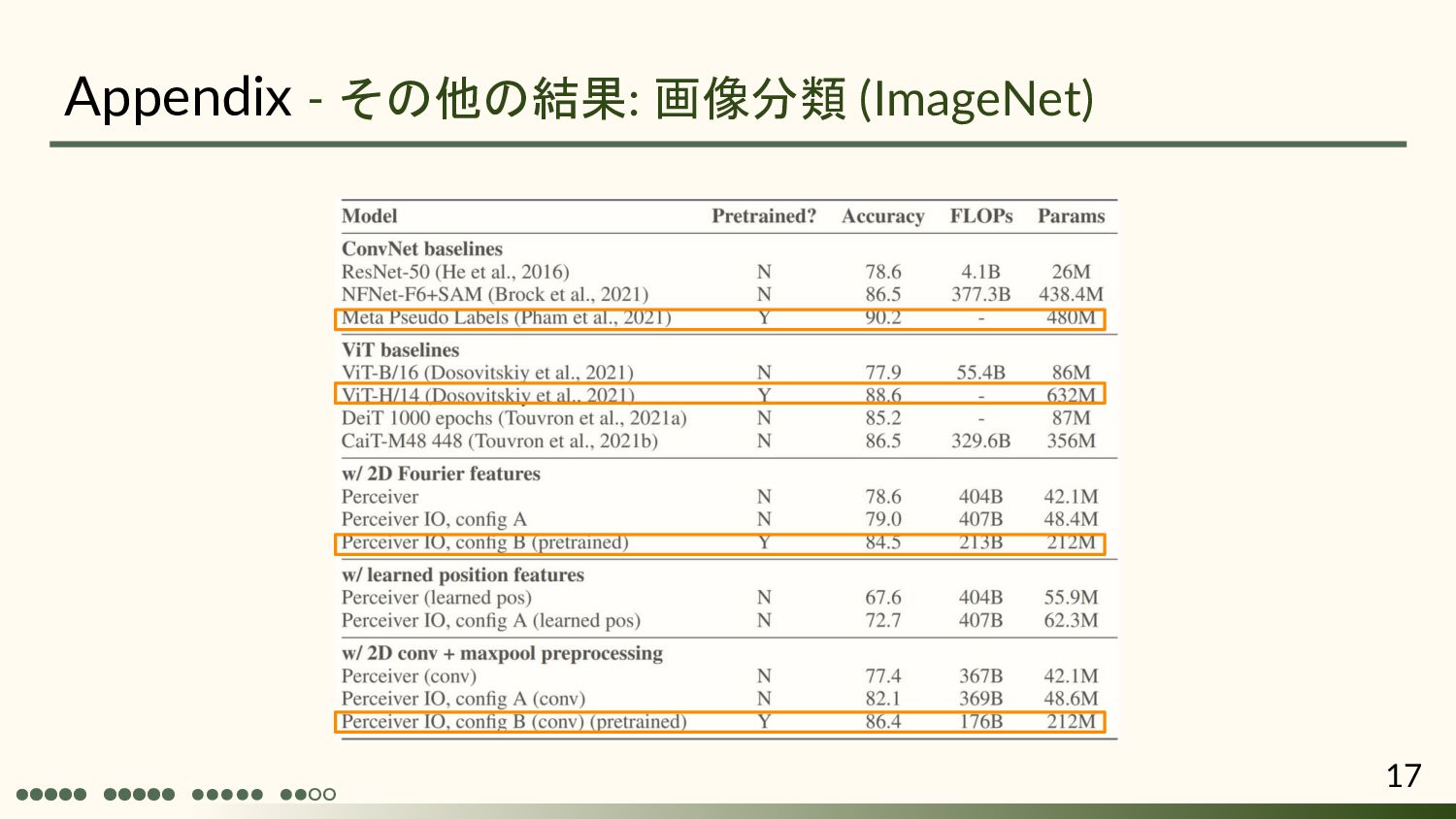
Andrew Jaegle 1, Sebastian Borgeaud 1, Jean-Baptiste Alayrac 1, Carl Doersch1, Catalin Ionescu1, David Ding 1, Skanda Koppula 1, Daniel Zoran 1, Andrew Brock 1, Evan Shelhamer 1, Olivier Hénaff 1, Matthew M. Botvinick 1, Andrew Zisserman1, Oriol Vinyals 1, João Carreira 1 1: DeepMind ICLR2022 Spotlight 慶応義塾大学 杉浦孔明研究室 小槻誠太郎 A. Jaegle, S. Borgeaud, J.-B. Alayrac, C. Doersch, C. Ionescu, D. Ding, S. Koppula, D. Zoran, A. Brock, E. Shelhamer, O.J. Henaff, M. Botvinick, A. Zisserman, O. Vinyals, and J. Carreira, “Perceiver IO: A general architecture for structured inputs & outputs,” ICLR, 2022.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
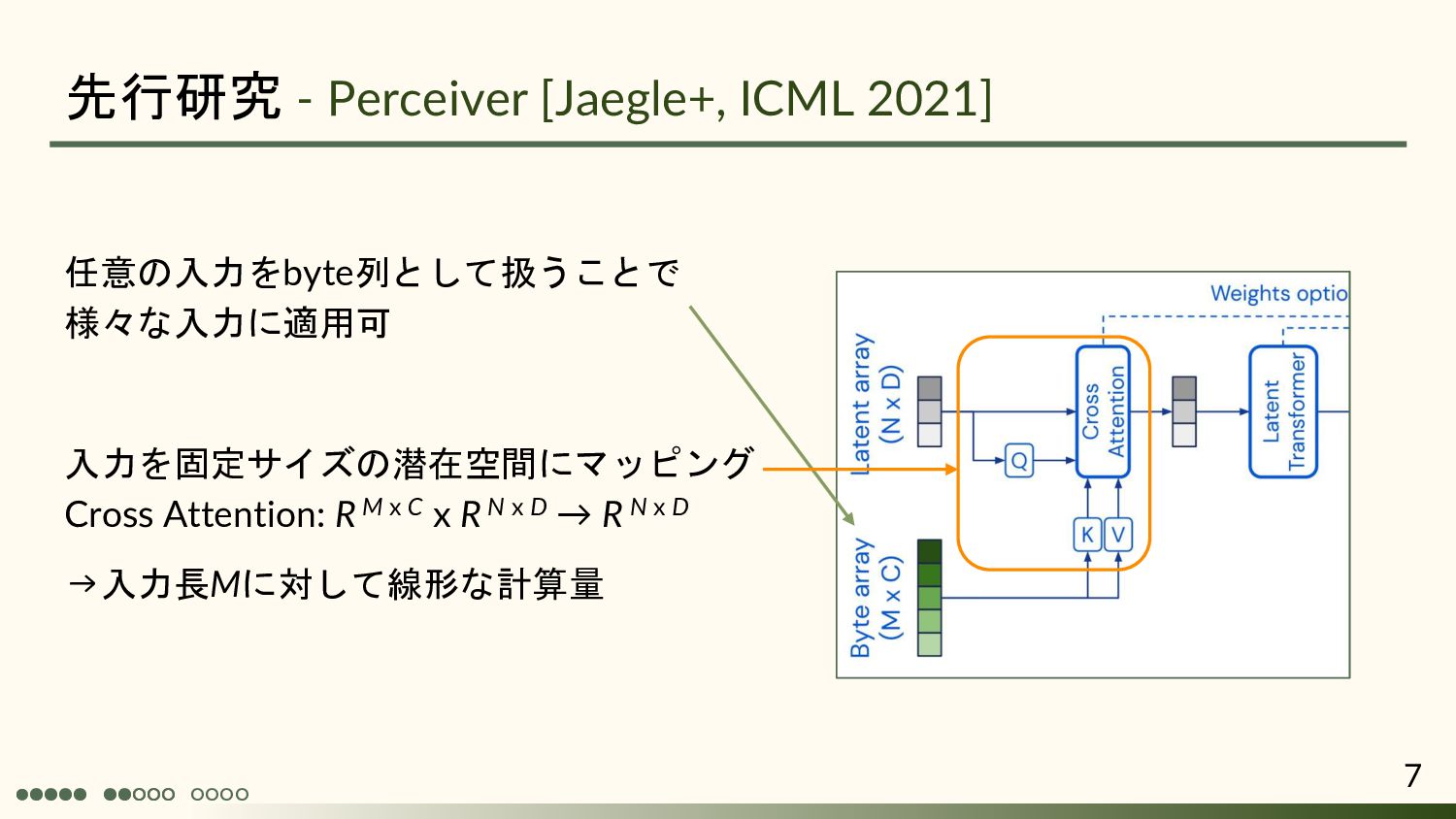
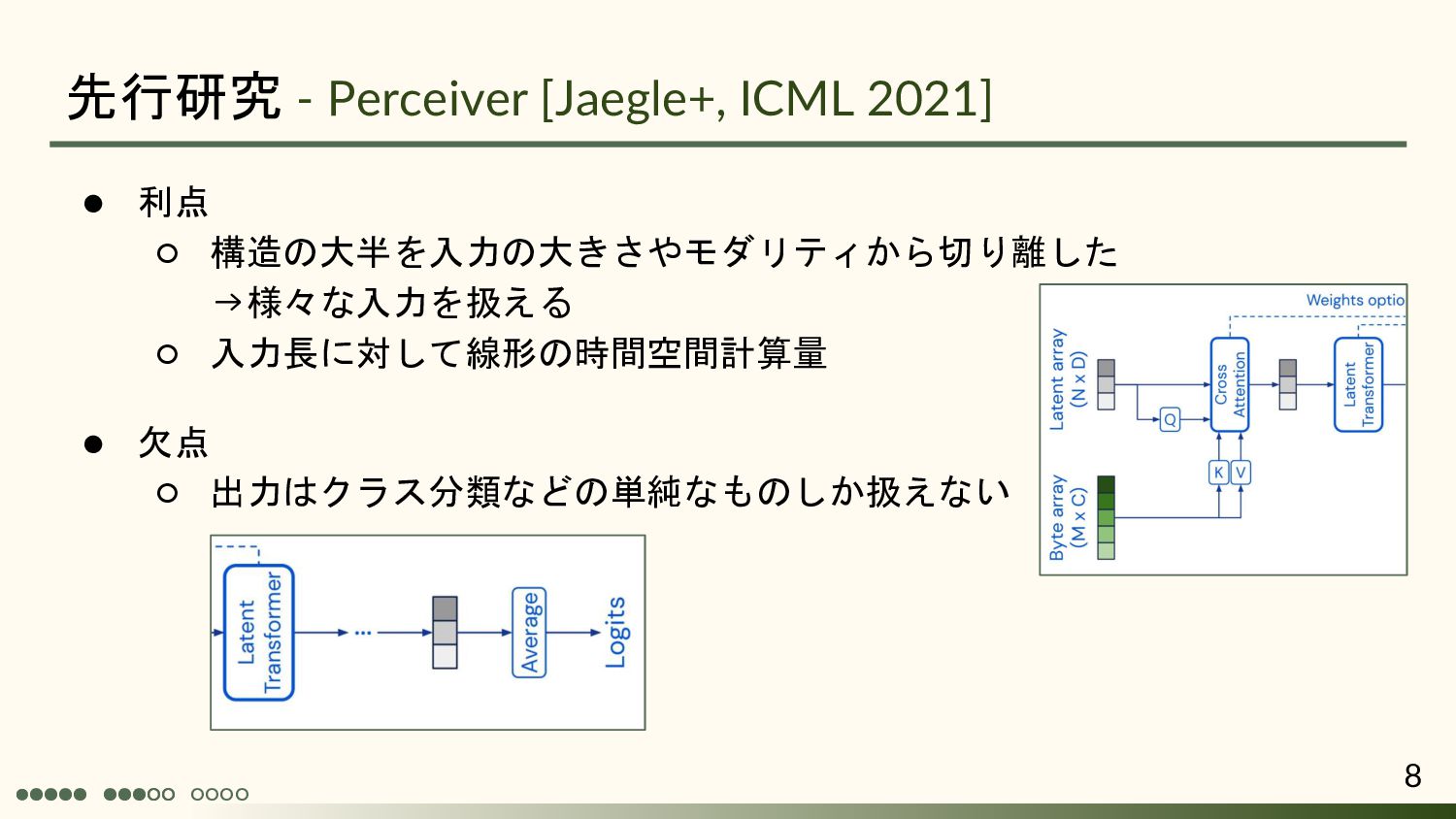
![•◦◦◦◦ ◦◦◦◦◦ 先行研究 - Perceiver [Jaegle+, ICML 2021] • 入力をbyte列と見做して統一的に処理](https://files.speakerdeck.com/presentations/49801693165444dbb997252a7ef6aaac/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
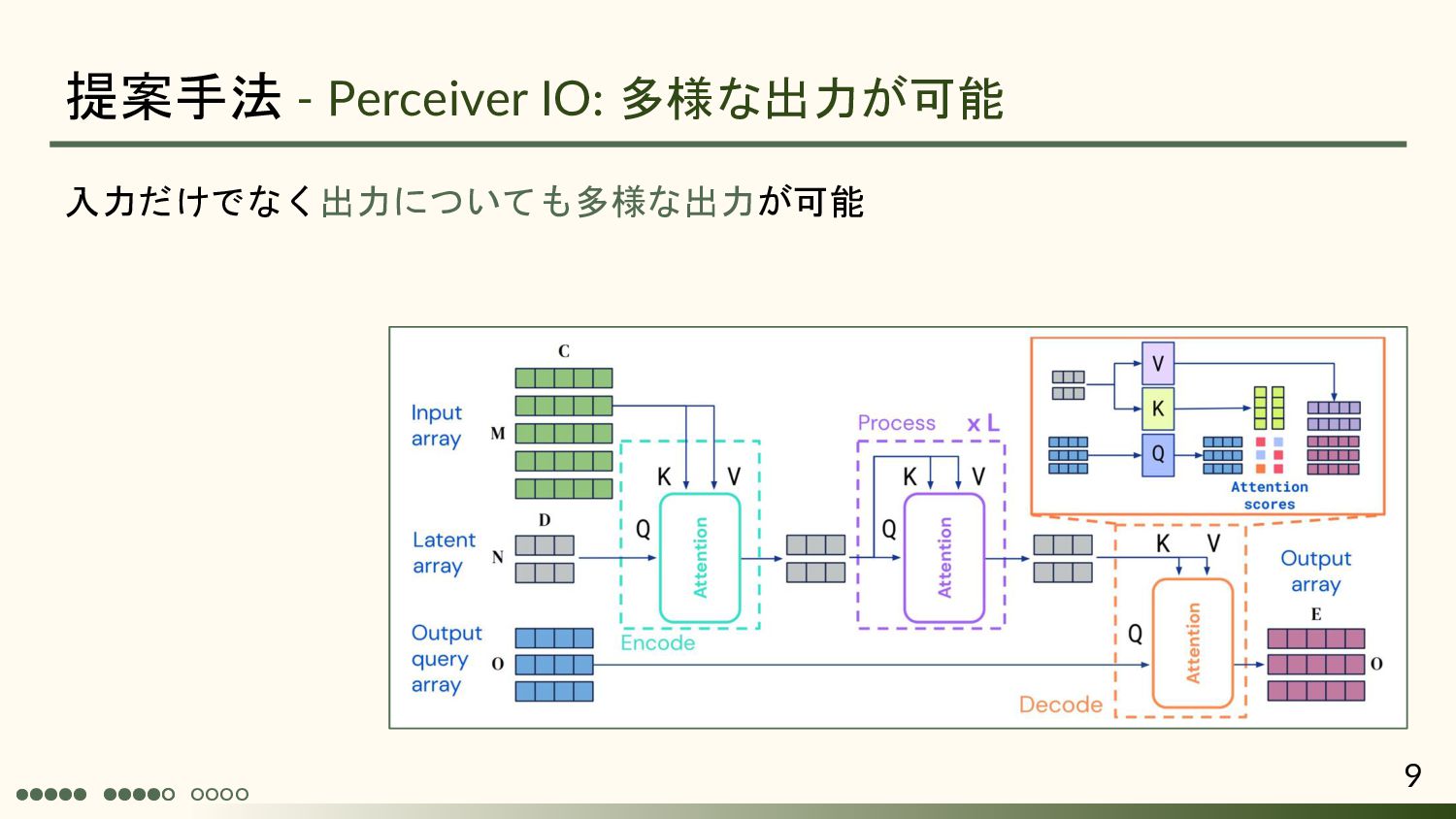{kind=link}
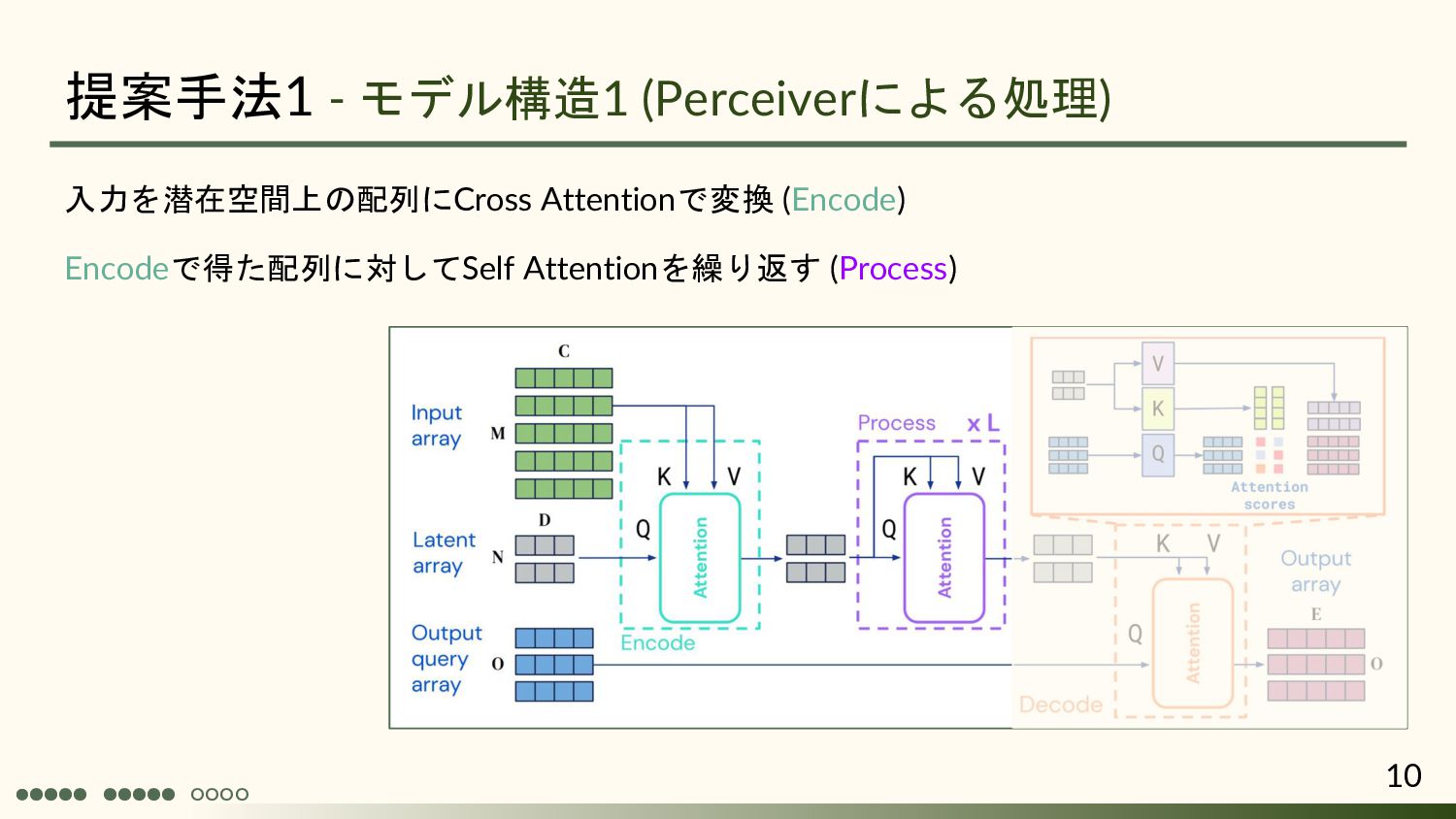{kind=link}
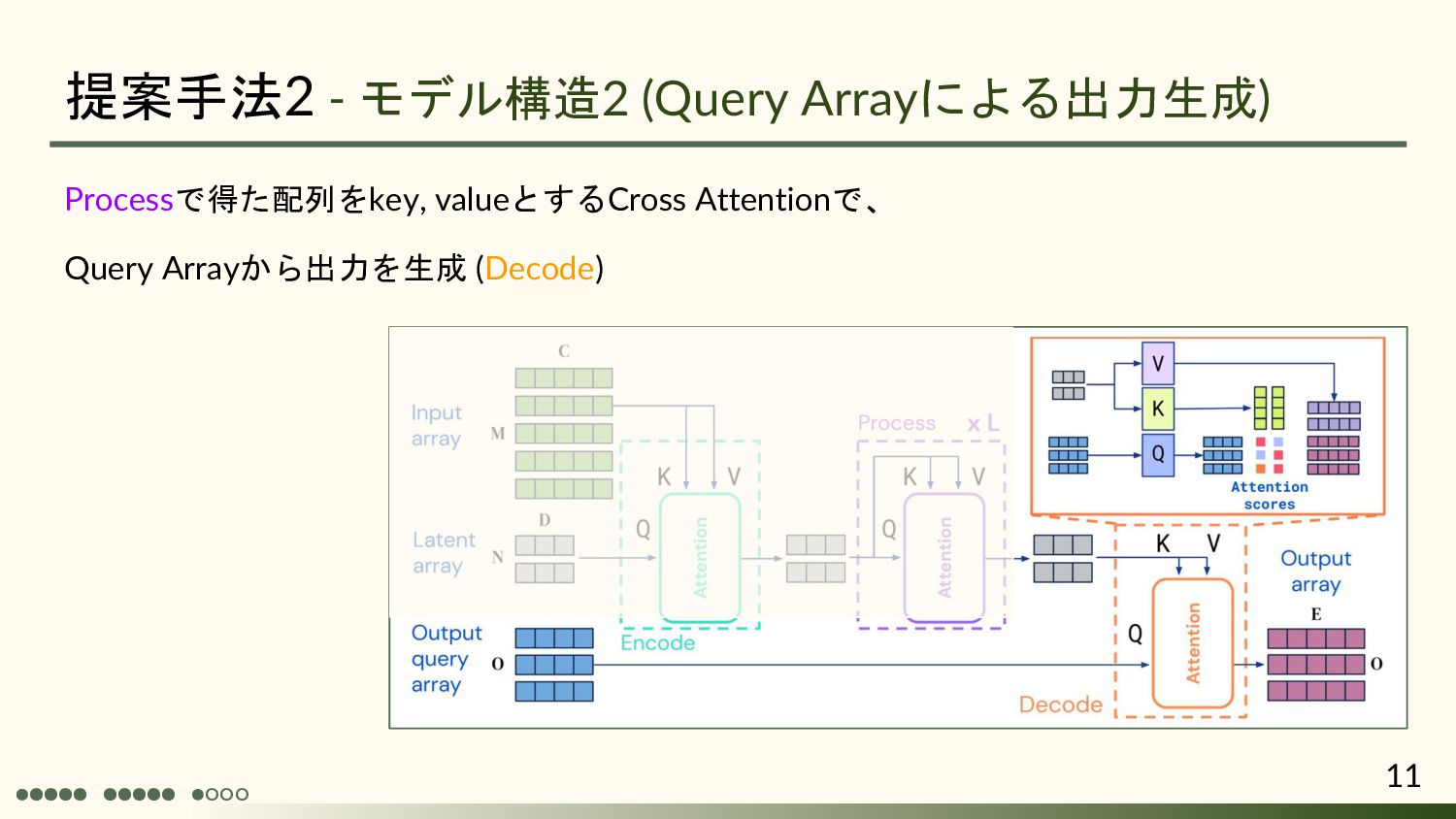{kind=link}
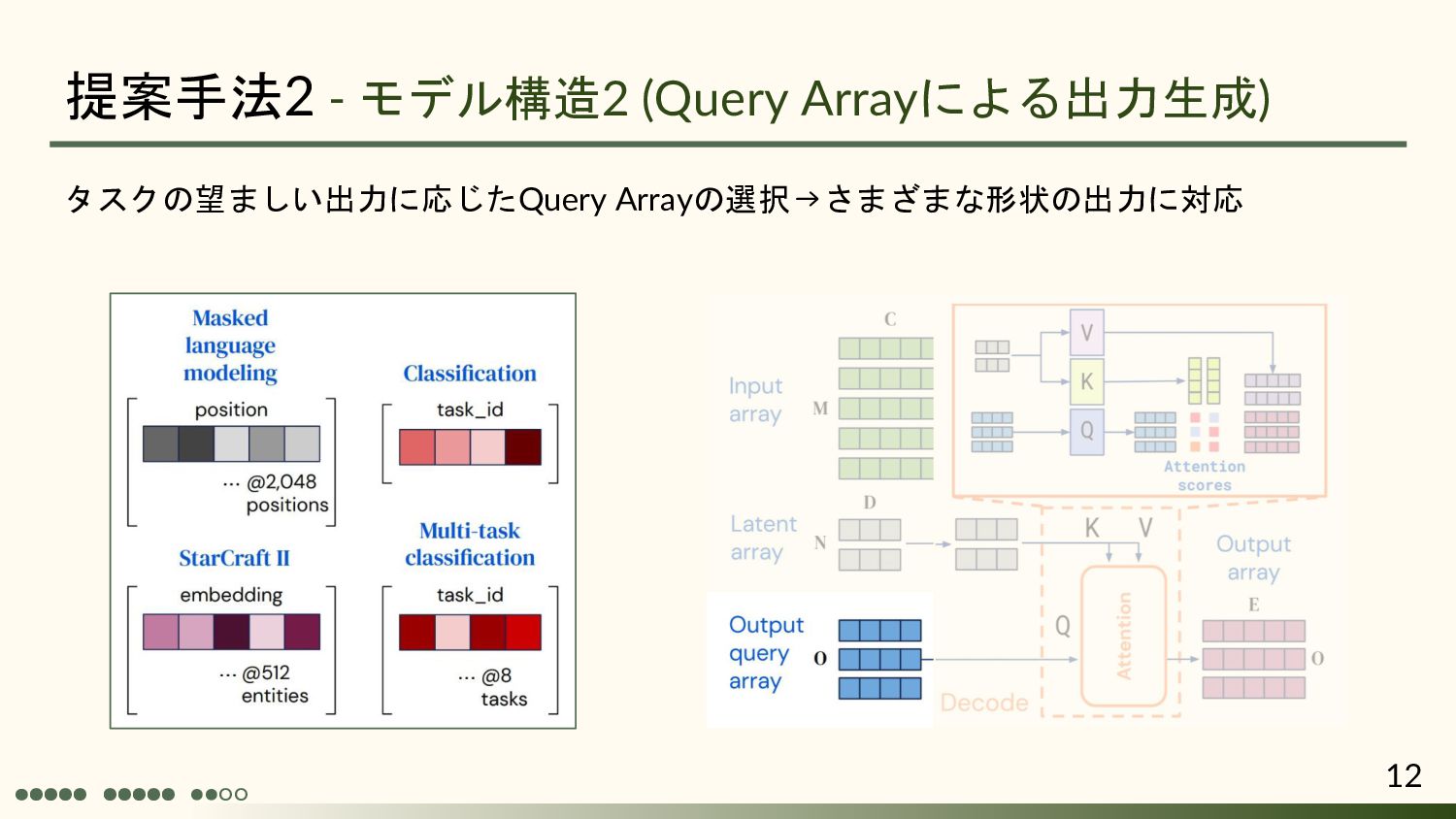{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}