Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club]PolyFormer: Referring Image Segme...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
April 28, 2023
Technology
1.5k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club]PolyFormer: Referring Image Segmentation as Sequential Polygon Generation
Semantic Machine Intelligence Lab., Keio Univ.
PRO
April 28, 2023
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
81
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
AmplifyHostingConstructからSSRフレームワークのためのホスティング設計を考察する/amplify-hosting-construct
fossamagna
1
300
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
320
Amazon Quick 入門!
ysuzuki
2
130
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
510
凡エンジニアがこの先生きのこるためには。〜TypeScript完全に理解したい〜
alchemy1115
2
410
Jitera Company Deck
jitera
0
270
GoでCコンパイラを作った話
repunit
0
150
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
210
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
420
AI_Dev_Day_製造業領域でのAI活用から見た活用の罠と成功に導く実践知.pdf
kintotechdev
0
160
Network Firewallやっていき!
news_it_enj
0
260
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
13
4.3k
Featured
See All Featured
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
220
Un-Boring Meetings
codingconduct
0
350
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.6k
The Pragmatic Product Professional
lauravandoore
37
7.4k
Fireside Chat
paigeccino
42
4k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Docker and Python
trallard
47
4k
A Soul's Torment
seathinner
6
3.1k
Product Roadmaps are Hard
iamctodd
55
12k
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Producing Creativity
orderedlist
PRO
348
40k
Transcript
PolyFormer: Referring Image Segmentation as Sequential Polygon Generation 慶應義塾大学 杉浦孔明研究室
畑中駿平 Liu, Jiang, et al. "PolyFormer: Referring image segmentation as sequential polygon generation.“, arXiv preprint arXiv:2302.07387, 2023. Jiang Liu1*☨ , Hui Ding2*, Zhaowei Cai2, Yuting Zhang2, Ravi Kumar Satzoda2, Vijay Mahadevan2, R. Manmatha2 1 Johns Hopkins University, 2 AWS AI Labs * Equal Contribution, ☨ Work done during internship at AWS AI Labs Accepted for CVPR2023
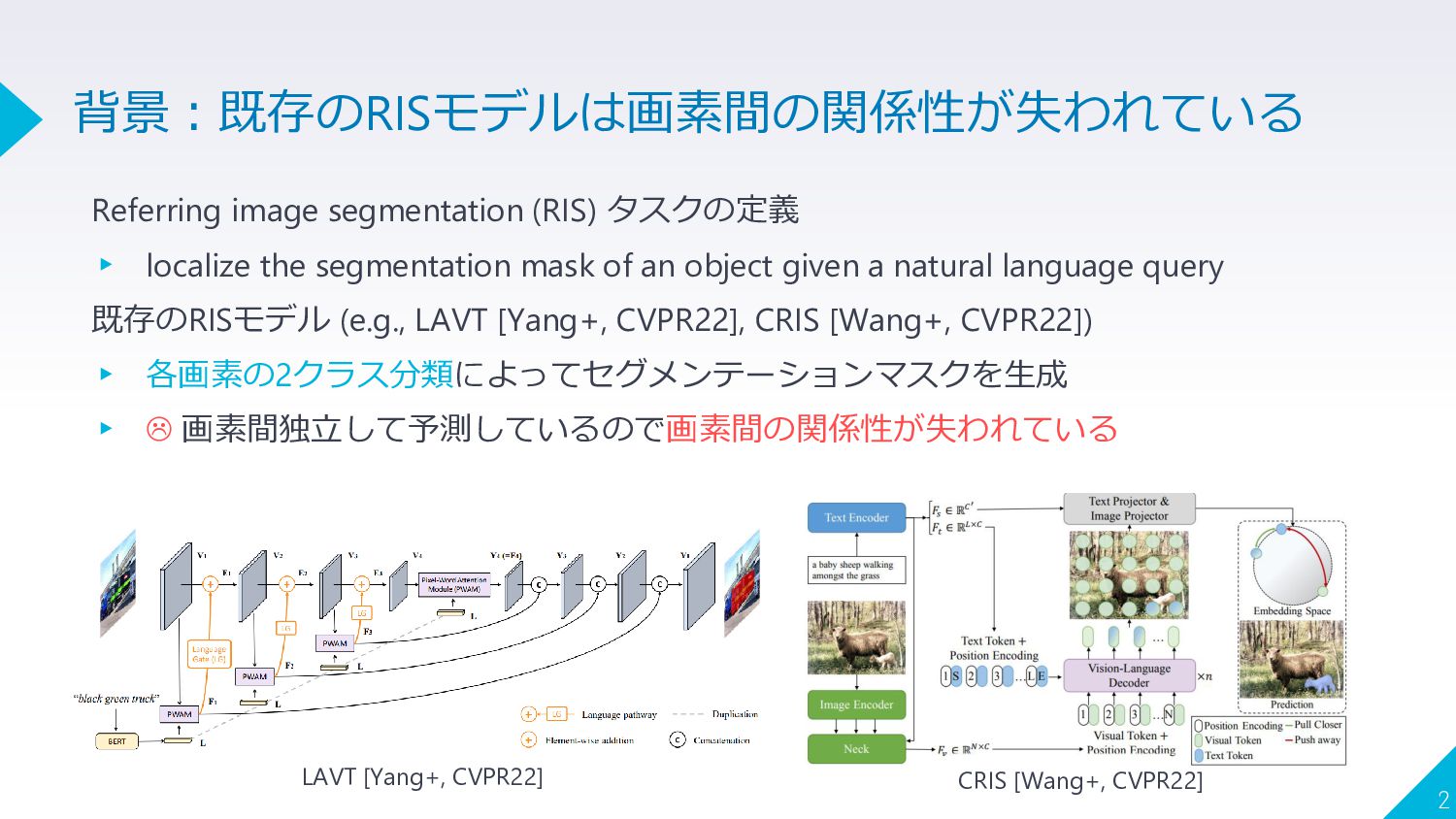
Referring image segmentation (RIS) タスクの定義 ▸ localize the segmentation mask
of an object given a natural language query 既存のRISモデル (e.g., LAVT [Yang+, CVPR22], CRIS [Wang+, CVPR22]) ▸ 各画素の2クラス分類によってセグメンテーションマスクを生成 ▸ 画素間独立して予測しているので画素間の関係性が失われている 2 背景:既存のRISモデルは画素間の関係性が失われている LAVT [Yang+, CVPR22] CRIS [Wang+, CVPR22]
近年のセグメンテーションマスクのアノテーション方法 ▸ 物体の輪郭を描く形で構造化されたポリゴン形式で表現 ([Acuna+, CVPR18]) ▸ ☺ べた塗のマスクよりも安価で好まれるアノテーション形式 構造化されたポリゴンを直接予測するCNNベースモデル ▸
E.g., BoundaryFormer [Lazarow+, CVPR22], PolyTransform [Liang+, CVPR22], PolarMask [Xie+, CVPR22] ▸ CNNベースで直接ポリゴンを予測するのは困難であり性能が低い 3 既存手法:CNNベースのポリゴン予測モデルは依然として 性能が低い PolygonRNN++ [Acuna+, CVPR18] PolyTransform [Liang+, CVPR22]
Vision系おけるseq2seqフレームワーク:座標を量子化して分類タスクとして定式化 ▸ E.g., Pix2Seq [Chen+, ICLR22], Unified-IO [Lu+, 2022], OFA
[Wang+, ICML22] ▸ [0,1)に正規化した座標値を整数倍して離散トークンとして扱う Cf. https://speakerdeck.com/keio_smilab/journal-club-pix2seq-a-language-modeling- framework-for-object-detection?slide=8 ▸ 分類タスクとして扱うことは位置特定タスクにとっては最適ではない ▹ 回帰タスクとして直接ポリゴンの座標値を予測したい 4 既存手法:既存のseq2seqフレームワークでは座標を量子化 した分類タスクとして扱っており最適ではない Pix2Seq [Chen+, ICLR21] Unified-IO [Lu+, 22] OFA [Wang+, ICML22]
SeqTR [Zhu+, ECCV22]:seq2seqフレームワークのRISモデル ▸ ☺ ポリゴンの頂点を逐次的に生成可能 SeqTRの問題点 ▸ 座標値を量子化してRISを分類タスクとして定式化している
▸ 18頂点の単一ポリゴンしか生成できず、複雑な形状やオクルージョンをもつ物体 に対して正しい輪郭を描くことができない 5 SeqTRも既存手法同様に座標値を量子化してポリゴン座標値 を分類タスクとして予測 SeqTR [Zhu+, ECCV22]
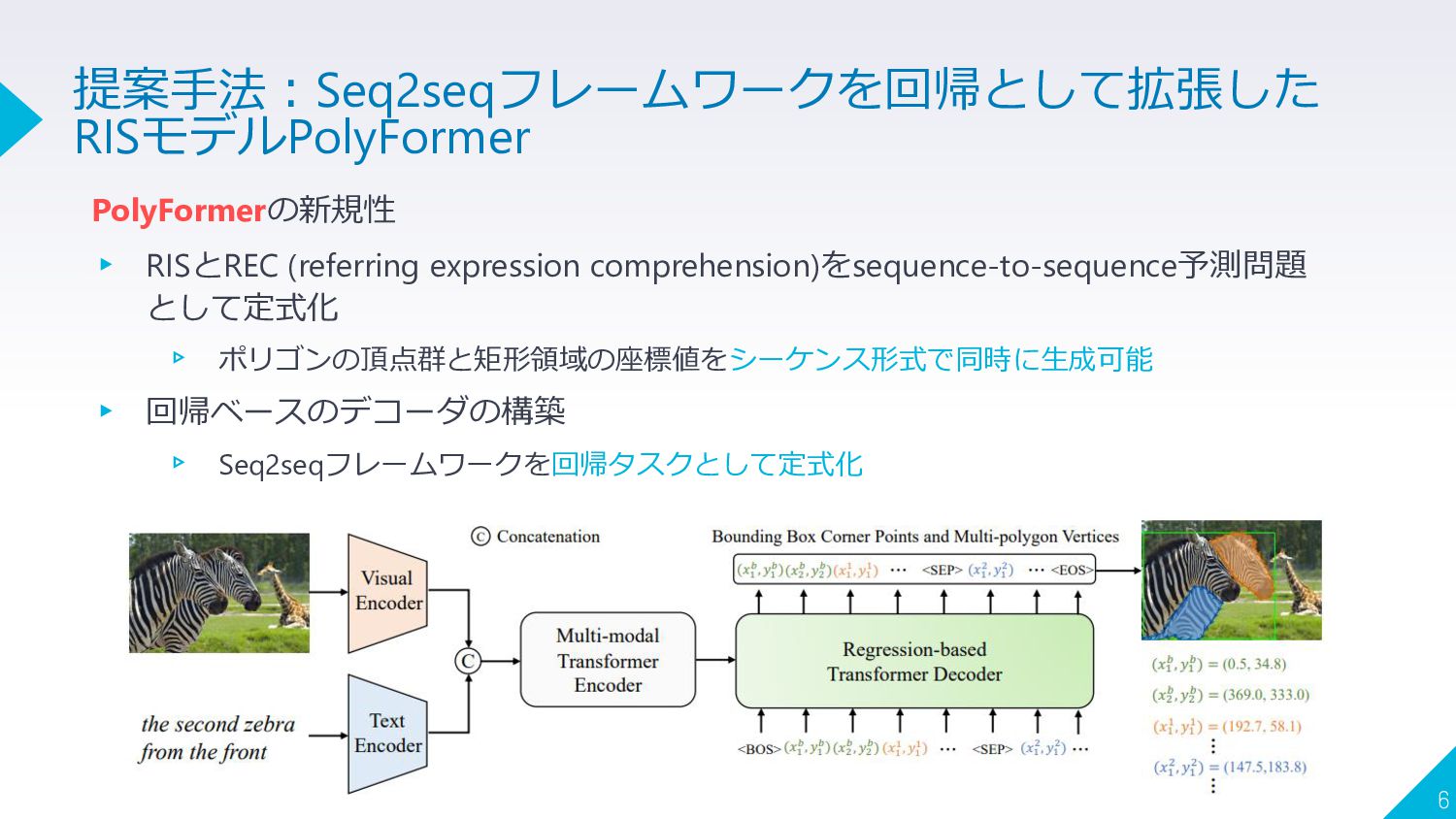
PolyFormerの新規性 ▸ RISとREC (referring expression comprehension)をsequence-to-sequence予測問題 として定式化 ▹ ポリゴンの頂点群と矩形領域の座標値をシーケンス形式で同時に生成可能 ▸
回帰ベースのデコーダの構築 ▹ Seq2seqフレームワークを回帰タスクとして定式化 6 提案手法:Seq2seqフレームワークを回帰として拡張した RISモデルPolyFormer
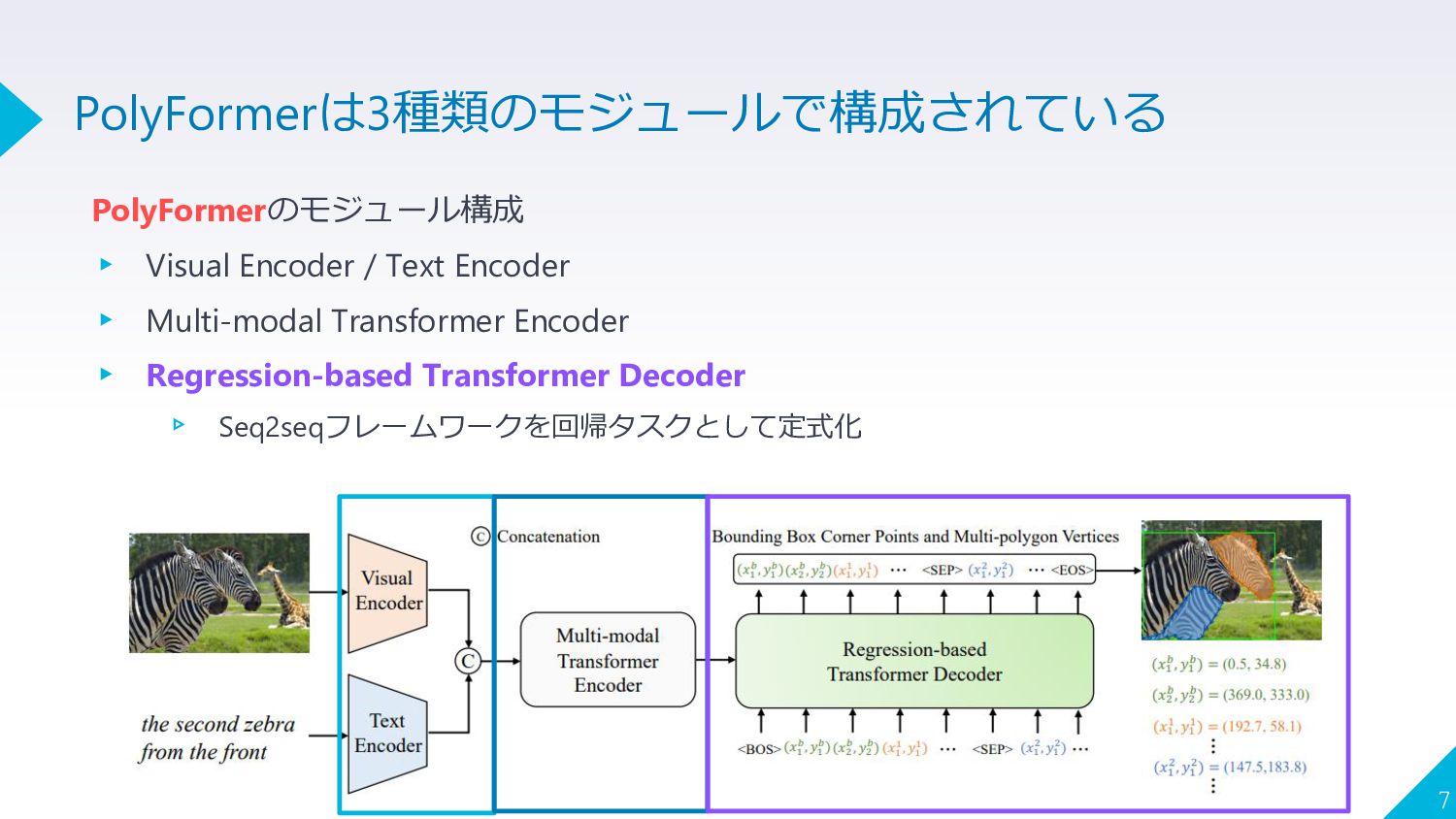
PolyFormerのモジュール構成 ▸ Visual Encoder / Text Encoder ▸ Multi-modal Transformer
Encoder ▸ Regression-based Transformer Decoder ▹ Seq2seqフレームワークを回帰タスクとして定式化 7 PolyFormerは3種類のモジュールで構成されている
Visual Encoder:Swin transformer [Liu+, ICCV21] ▸ 入力:𝐼 ∈ ℝ𝐻×𝑊×3 ▸
出力: 𝐹 𝑣 ∈ ℝ 𝐻 32 ×𝑊 32 ×𝐶𝑣 Text Encoder:BERT [Devlin+, NAACL-HLT18] ▸ 入力: 𝑇 ∈ ℝ𝐿 ▸ 出力: 𝐹𝑙 ∈ ℝ𝐿×𝐶𝑙 Multi-modal Transformer Encoder: 𝑵層のtransformer layer ▸ 入力:𝐹𝑀 = [MLP 𝐹 𝑣 ; MLP 𝐹𝑙 ] ▹ 画像とテキストの位置情報を保持するために、絶対位置エンコーディング ([Ke+, ICLR21]) と 相対位置バイアス (T5[Raffel+, JMLR21], CoAtNet [Dai+, NeurIPS21], SimVLM [Wang+, ICLR22]) を付加 ▸ 出力:𝐹𝑀 𝑁 8 Transformerベースの構造でマルチモーダルな特徴量を獲得
既存のseq2seqフレームワーク (Pix2Seq, Unified-IO, OFA, SeqTR) ▸ 1次元空間における座標コードブックで位置座標の埋め込み表現を獲得 ▸ 2次元座標
𝑥, 𝑦 に対する座標表現を獲得することが難しい 2次元座標のコードブックを適用 ▸ ☺ 任意の座標 𝑥, 𝑦 に対してより正確な座標埋め込みを獲得 ▸ 4種類の離散的なビンを生成し、埋め込み表現𝑒(𝑥,𝑦) を獲得 ▹ 例: 𝑒 ҧ 𝑥, ത 𝑦 = 𝒟 ҧ 𝑥, ത 𝑦 ∈ ℝ𝐵𝐻×𝐵𝑊×𝐶𝑒 9 2次元座標のコードブックを使用して 𝑥, 𝑦 に対する 座標埋め込み表現を獲得 𝑒(𝑥,𝑦) = ҧ 𝑥 − 𝑥 ത 𝑦 − 𝑦 ∙ 𝑒 𝑥,𝑦 + 𝑥 − 𝑥 𝑦 − 𝑦 ∙ 𝑒 ҧ 𝑥,𝑦 + 𝑥 − 𝑥 𝑦 − 𝑦 ∙ 𝑒 𝑥, ത 𝑦 + 𝑥 − 𝑥 𝑦 − 𝑦 ∙ 𝑒 ҧ 𝑥, ത 𝑦
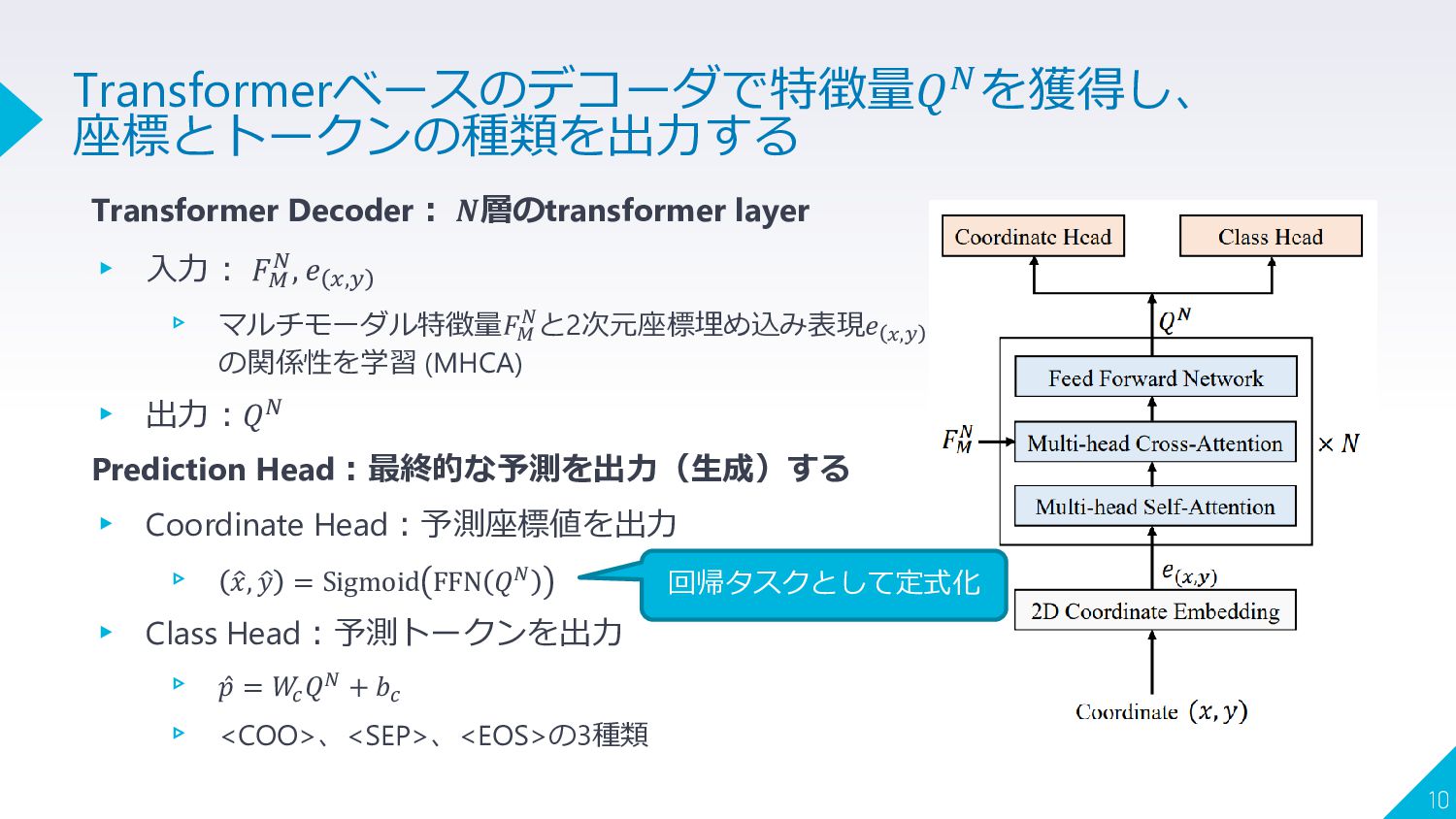
Transformer Decoder: 𝑵層のtransformer layer ▸ 入力: 𝐹𝑀 𝑁, 𝑒 𝑥,𝑦
▹ マルチモーダル特徴量𝐹𝑀 𝑁と2次元座標埋め込み表現𝑒 𝑥,𝑦 の関係性を学習 (MHCA) ▸ 出力:𝑄𝑁 Prediction Head:最終的な予測を出力(生成)する ▸ Coordinate Head:予測座標値を出力 ▹ ො 𝑥, ො 𝑦 = Sigmoid FFN 𝑄𝑁 ▸ Class Head:予測トークンを出力 ▹ Ƹ 𝑝 = 𝑊 𝑐 𝑄𝑁 + 𝑏𝑐 ▹ <COO>、<SEP>、<EOS>の3種類 10 Transformerベースのデコーダで特徴量𝑄𝑁を獲得し、 座標とトークンの種類を出力する 回帰タスクとして定式化
1. <BOS>トークンを入力することで生成を開始 2. クラスヘッドからトークンの種類を取得する ◼ <COO>:先行する予測を前提条件としてcoordinate headから2次元座標予測を取得 ◼ <SEP>:ポリゴンの終わりを示すので、<SEP>トークンを出力シーケンスに追加 3.
<EOS>が出力された時点で停止 ◼ 最初の2つのトークンは矩形領域の座標 ◼ 残りはポリゴンの頂点群 ◼ 最終的なセグメンテーションマスクは、ポリゴンの予測値から得られる 11 推論方法:トークンを取得したのちポリゴンを順次生成 SeqTRの問題点を解消
データセット:RISタスクとして4種類で評価 ▸ RefCOCO [Yu+, ECCV16] ▸ RefCOCO+ [Yu+, ECCV16] ▸
RefCOCOg [Mao+, CVPR16] ▸ ReferIt [Kazemzadeh+ EMNLP14] 評価尺度:3種類 ▸ Mean IoU、
[email protected]
、Overall IoU 学習時間に関して ▸ 学習時間・ハードウェア構成:ともに記載なし ▸ 参考:バッチサイズ128のエポック数100で学習 12 実験設定:4種類のデータセットで実験
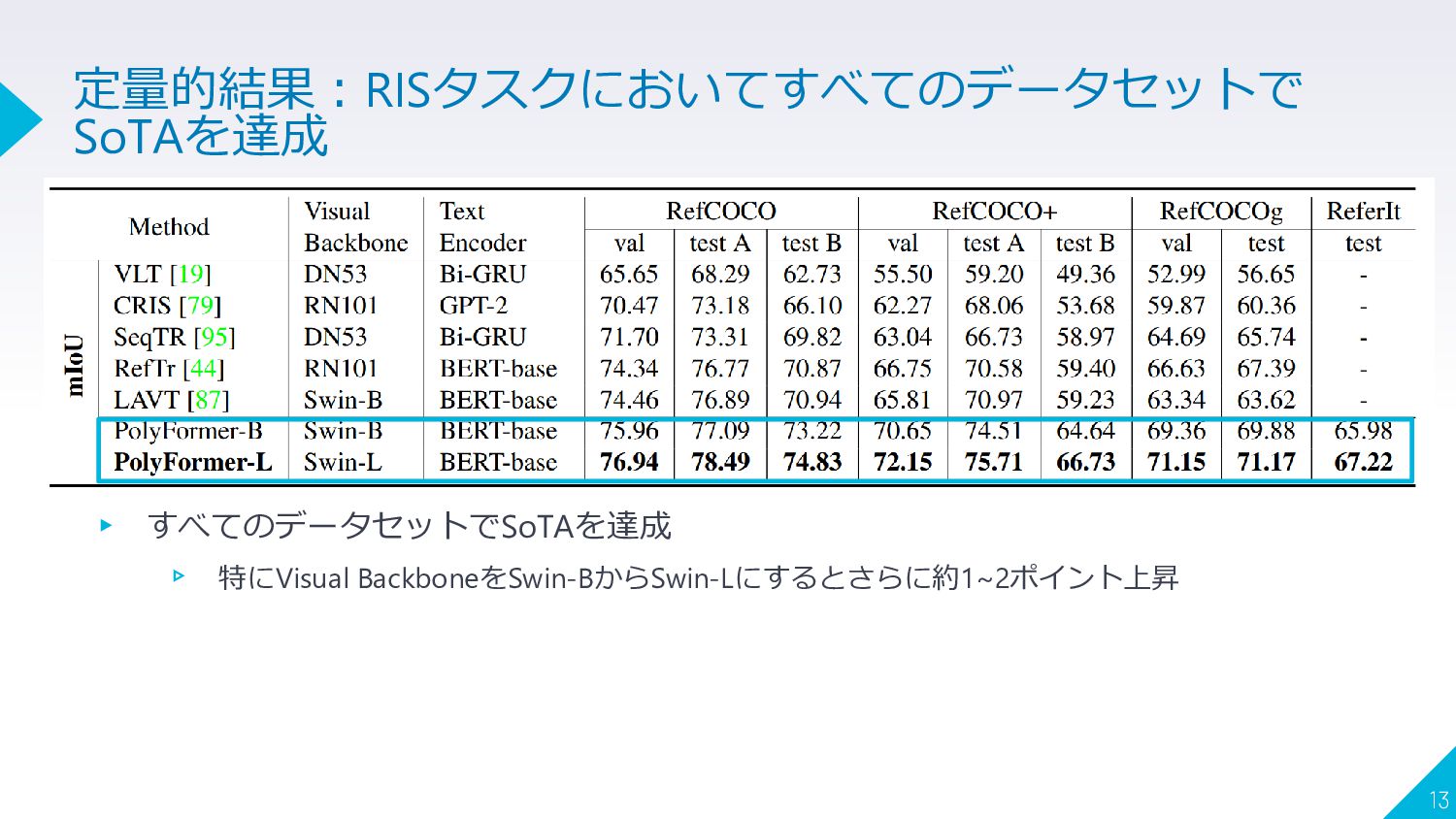
▸ すべてのデータセットでSoTAを達成 ▹ 特にVisual BackboneをSwin-BからSwin-Lにするとさらに約1~2ポイント上昇 13 定量的結果:RISタスクにおいてすべてのデータセットで SoTAを達成
14 定性的結果:オクルージョンな物体でも既存手法より正確 にセグメンテーションマスクを生成可能
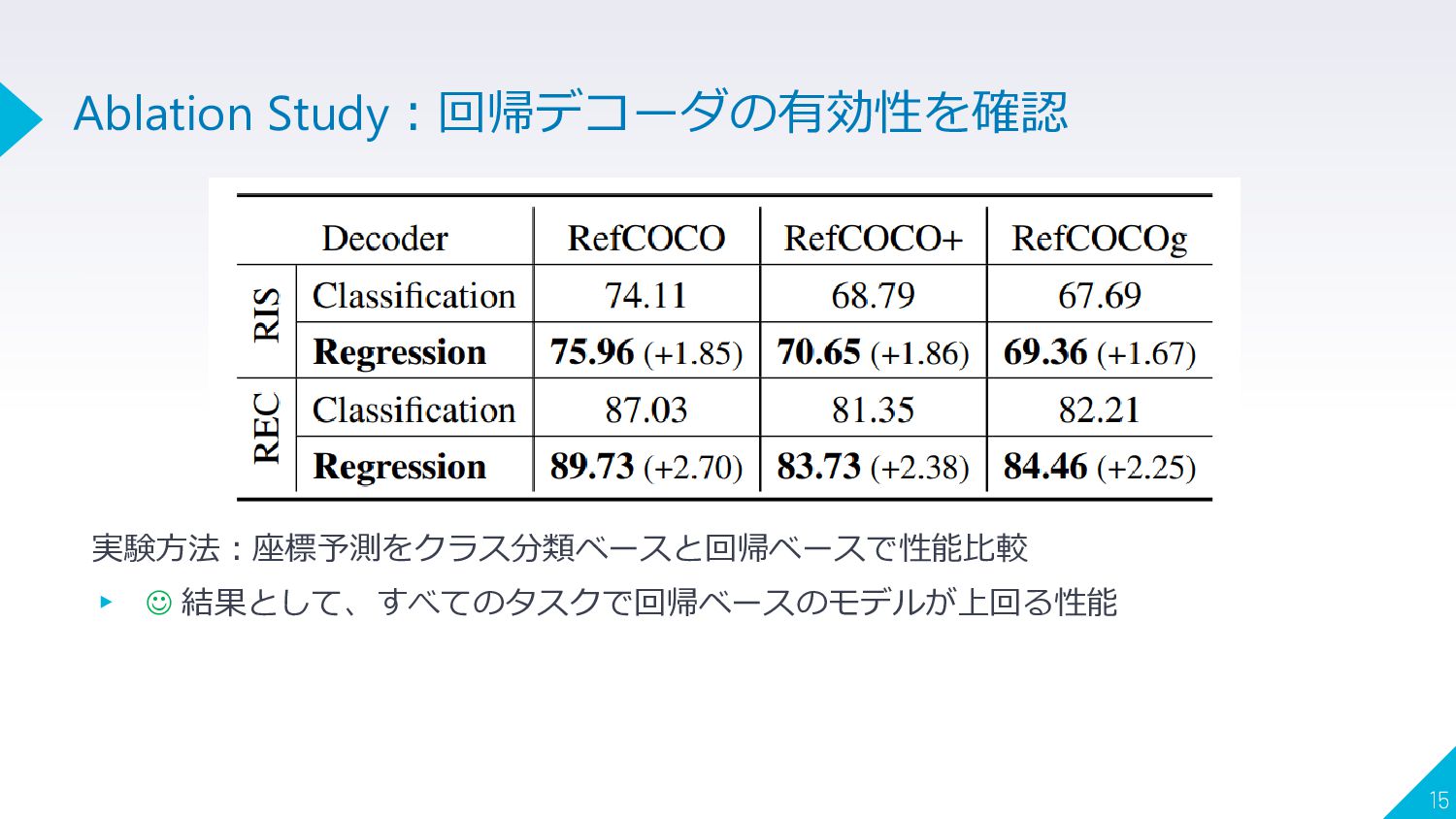
実験方法:座標予測をクラス分類ベースと回帰ベースで性能比較 ▸ ☺ 結果として、すべてのタスクで回帰ベースのモデルが上回る性能 15 Ablation Study:回帰デコーダの有効性を確認
Strengths ▸ 既存手法の調査の網羅性の高さと提案手法との差別化が明確である ▸ Seq2seqフレームワークを回帰タスクとして定式化したことで、性能向上を実現 Weaknesses ▸ SeqTRの改良版という位置づけなので新規性としてはSeqTRのほうがインパクトが大きい印象 ▸ 失敗例の定性的結果やエラー分析がない
Others ▸ LAVT [Yang+, CVPR22] のスコアが実際の論文値よりもなぜか高くなっている ▸ 第1著者(おそらく博士課程の学生)がAWS AI Labのインターン中にCVPRにアクセプトされる 実績を得ることに驚き ▸ コードの公開が待たれる ▹ Project page: https://polyformer.github.io 16 所感
背景 ▸ 既存手法のseq2seqフレームワークは座標を量子化しており、予測は分類タスク として定式化されている 提案 ▸ Seq2seqフレームワークを回帰タスクとして定式化したPolyFormerの提案 結果 ▸ RISタスクの主要なベンチマークでSoTAを達成
17 まとめ
Appendix 18
▸ Coordinate Head:L1ノルム損失関数 ▹ 最初の2トークン分は矩形領域の座標値を予測 ▸ Class Head:交差エントロピー損失関数 19 損失関数:2種類の損失関数を適用
▸ SeqTRの問題点:ポリゴンの頂点数を固定(デフォルト値18点)になっている ▹ 生成されたセグメンテーションマスクが粗くなる ▸ ポリゴンのデータ拡張 ▹ GTのポリゴン情報から密な輪郭を補間しサンプリング ▹
密な輪郭からランダムに粒度の異なるポリゴンを生成 ▹ ☺ モデルがより柔軟なポリゴン表現を学習可能 20 ポリゴンのデータ拡張
学習方法:RECタスクとして事前学習→RISタスクとしてファインチューニング ▸ データセットは4種類 ▹ Visual Genome, RefCOCO, RefCOCO+, RefCOCOg, Flickr30k-entities
▹ バッチサイズは160、エポック数は20で学習 ハイパーパラメータなどの設定 ▸ 𝜆𝑏𝑜𝑥 , 𝜆𝑝𝑜𝑙𝑦 , 𝜆𝑐𝑙𝑠 = 0.1, 1, 5 × 10−5 ▸ ポリゴンのデータ拡張:50%の確率で適用 ▸ 2次元座標埋め込みコードブック: 𝐵𝐻 , 𝐵𝑊 = 64, 64 21 学習方法:RECタスクを事前学習したのちRISタスクとして ファインチューニングを行う
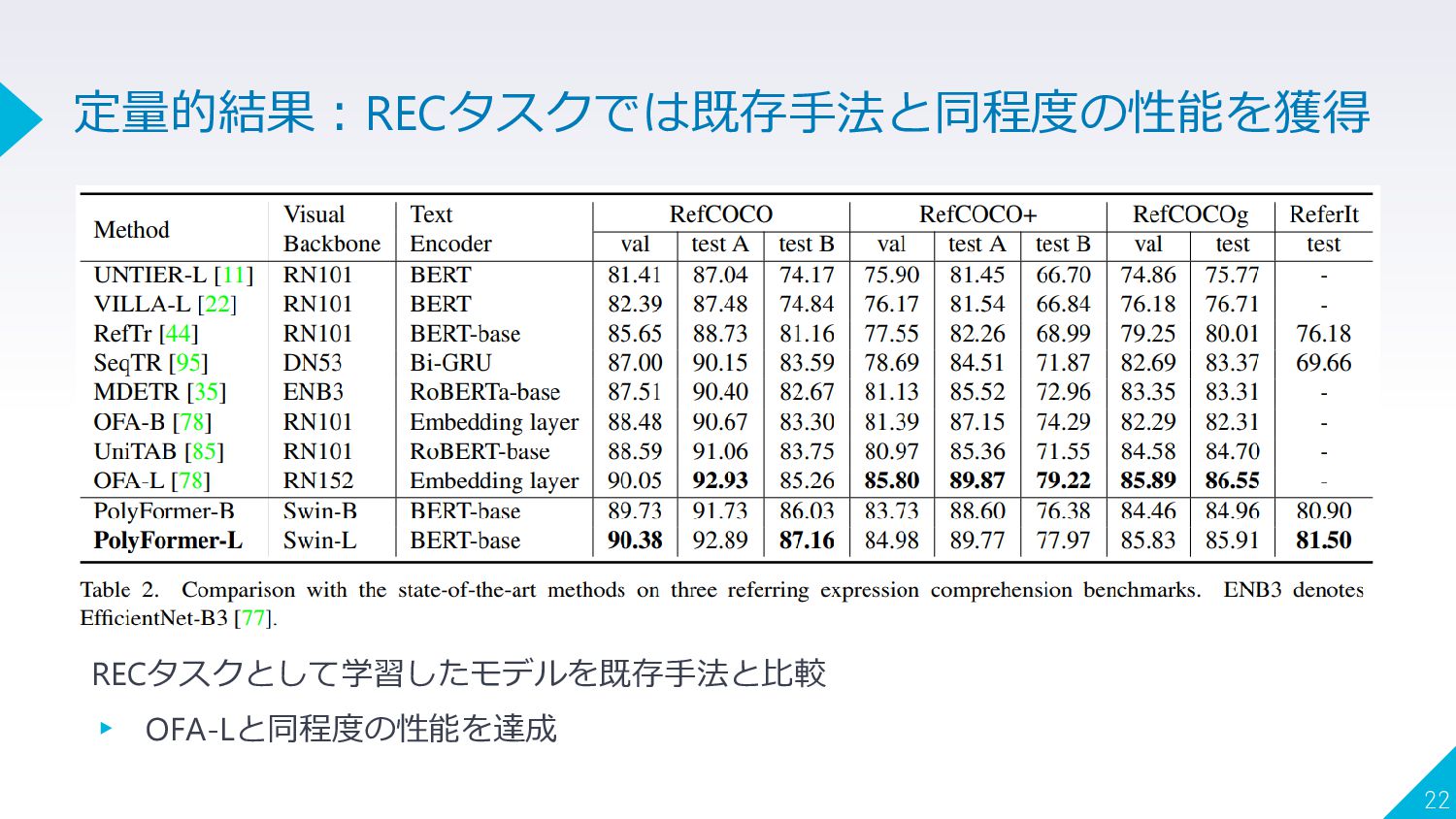
RECタスクとして学習したモデルを既存手法と比較 ▸ OFA-Lと同程度の性能を達成 22 定量的結果:RECタスクでは既存手法と同程度の性能を獲得
23 相互注意機構のアテンションの可視化結果
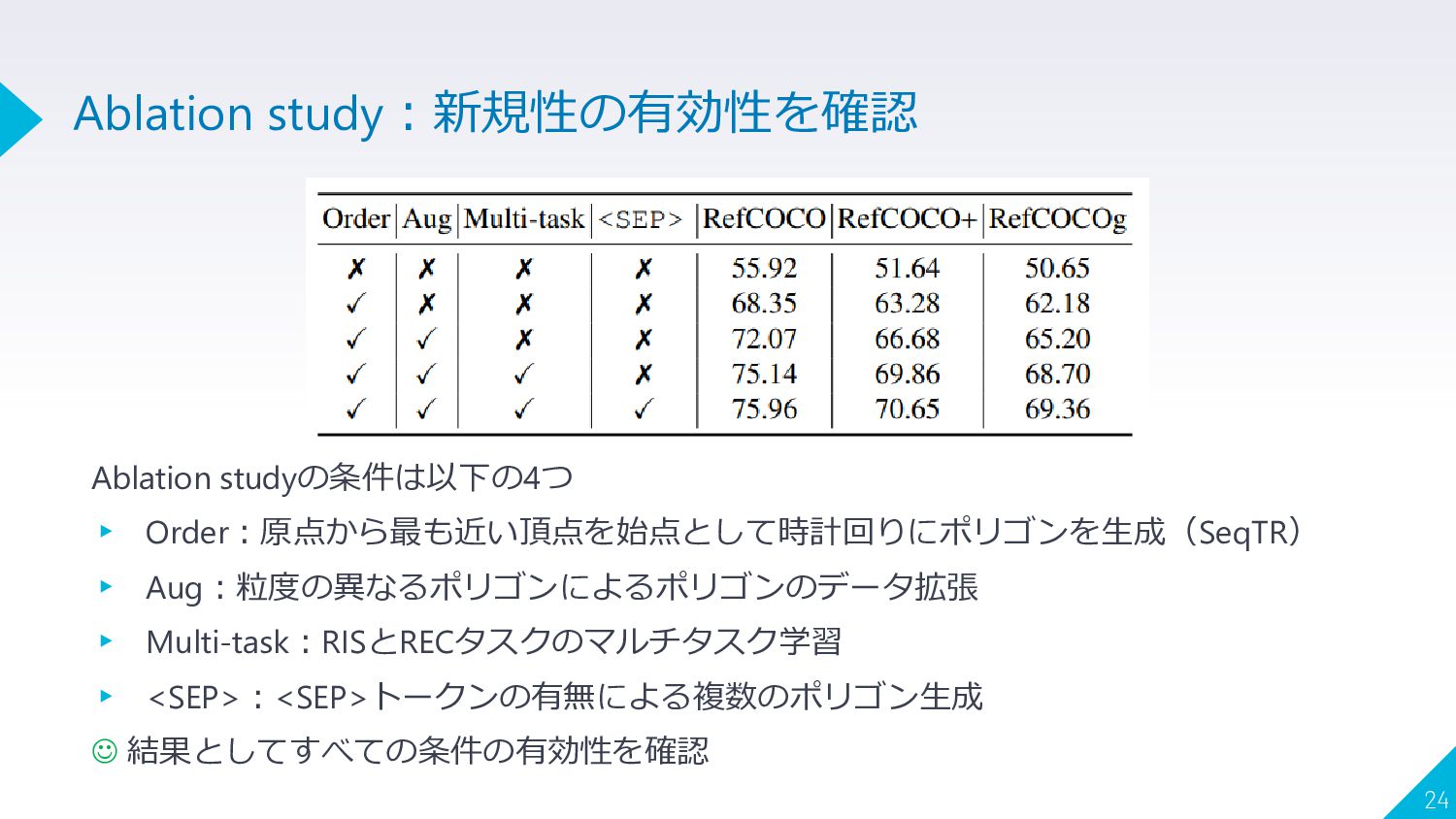
Ablation studyの条件は以下の4つ ▸ Order:原点から最も近い頂点を始点として時計回りにポリゴンを生成(SeqTR) ▸ Aug:粒度の異なるポリゴンによるポリゴンのデータ拡張 ▸ Multi-task:RISとRECタスクのマルチタスク学習 ▸ <SEP>:<SEP>トークンの有無による複数のポリゴン生成
☺ 結果としてすべての条件の有効性を確認 24 Ablation study:新規性の有効性を確認
Ablation studyの条件:PolyFormer-Bにおいてコードブックのサイズを変更 ☺ 結果として、サイズが64のときに最良であることを確認 25 Ablation study:2次元の座標埋め込みコードブックは64の サイズが最良
{kind=link}
{kind=link}
![近年のセグメンテーションマスクのアノテーション方法 ▸ 物体の輪郭を描く形で構造化されたポリゴン形式で表現 ([Acuna+, CVPR18]) ▸ ☺ べた塗のマスクよりも安価で好まれるアノテーション形式 構造化されたポリゴンを直接予測するCNNベースモデル ▸](https://files.speakerdeck.com/presentations/5256a485917d41fe85e845852f2cd84c/slide_2.jpg){kind=link}
![Vision系おけるseq2seqフレームワーク:座標を量子化して分類タスクとして定式化 ▸ E.g., Pix2Seq [Chen+, ICLR22], Unified-IO [Lu+, 2022], OFA](https://files.speakerdeck.com/presentations/5256a485917d41fe85e845852f2cd84c/slide_3.jpg){kind=link}
![SeqTR [Zhu+, ECCV22]:seq2seqフレームワークのRISモデル ▸ ☺ ポリゴンの頂点を逐次的に生成可能 SeqTRの問題点 ▸ 座標値を量子化してRISを分類タスクとして定式化している](https://files.speakerdeck.com/presentations/5256a485917d41fe85e845852f2cd84c/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
![Visual Encoder:Swin transformer [Liu+, ICCV21] ▸ 入力:𝐼 ∈ ℝ𝐻×𝑊×3 ▸](https://files.speakerdeck.com/presentations/5256a485917d41fe85e845852f2cd84c/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![データセット:RISタスクとして4種類で評価 ▸ RefCOCO [Yu+, ECCV16] ▸ RefCOCO+ [Yu+, ECCV16] ▸](https://files.speakerdeck.com/presentations/5256a485917d41fe85e845852f2cd84c/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}