Alexander Kolesnikov, Lucas Beyer⋆ Google DeepMind 慶應義塾大学 杉浦孔明研究室 小槻誠太郎 X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer, “Sigmoid Loss for Language Image Pre-Training,” in ICCV, 2023, pp. 11975–11986. ICCV’23 Oral
[embedding dimension of the text model] 2つの行列を用意して一度低次元空間に写像してから戻すことで 必要なパラメータ数を削減😄 23 Bottlenecked token embedding F2 : RK à RW F1 : RN à RK Vocab size: N Embedding dim.: W
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![前提: 多クラス分類を複数の2値分類の集合として扱い, sigmoid関数を 使うと, ラベルのノイズに頑健になることが知られている [Beyer+, ‘20] 実際にわざとラベルを確率pで破壊した時, 従来のCLIPのような損失関数を使用するよりも提案手法の方が頑健 17](https://files.speakerdeck.com/presentations/add5548186ba4ad0bc13645b1ff040db/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
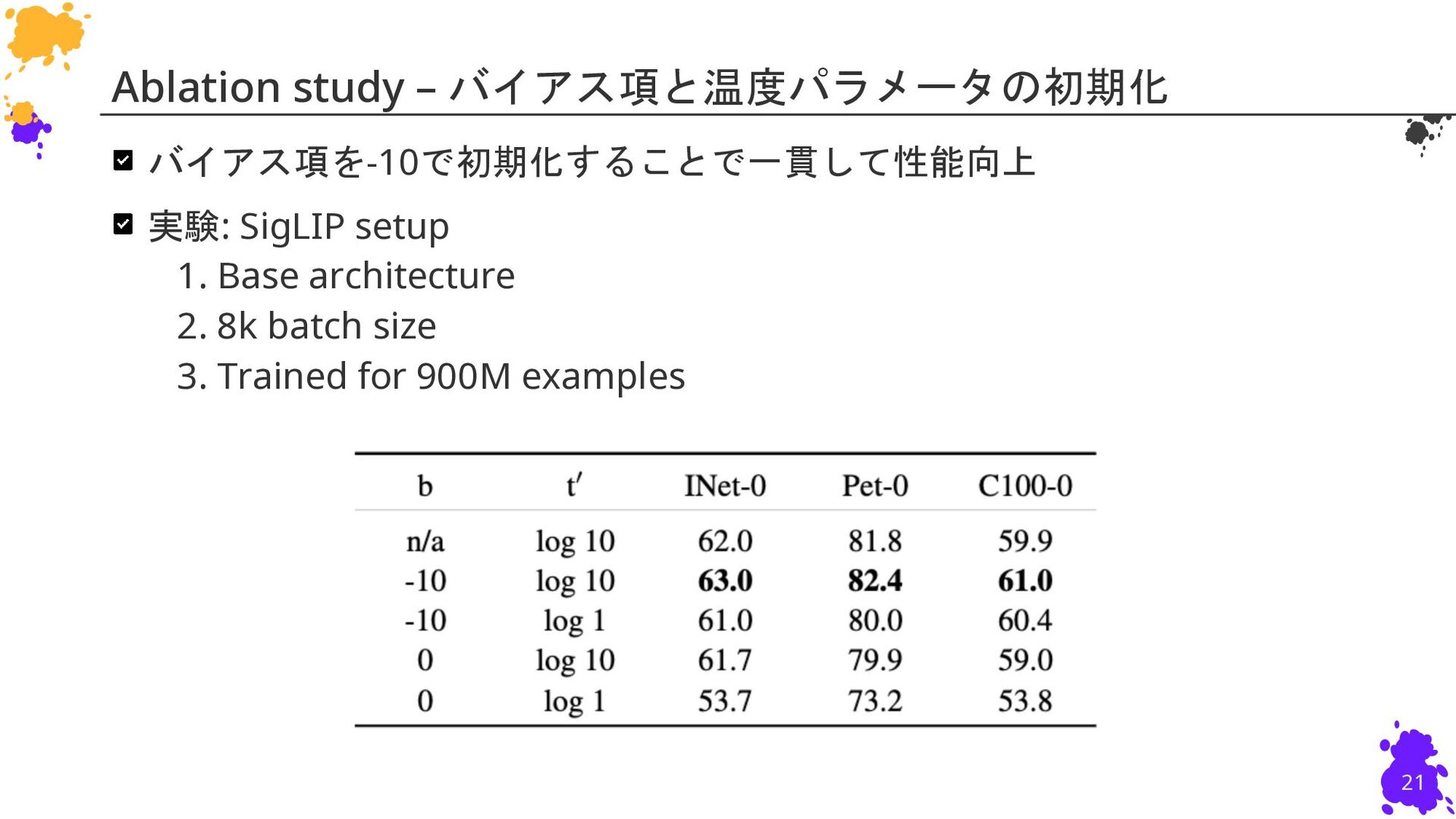{kind=link}
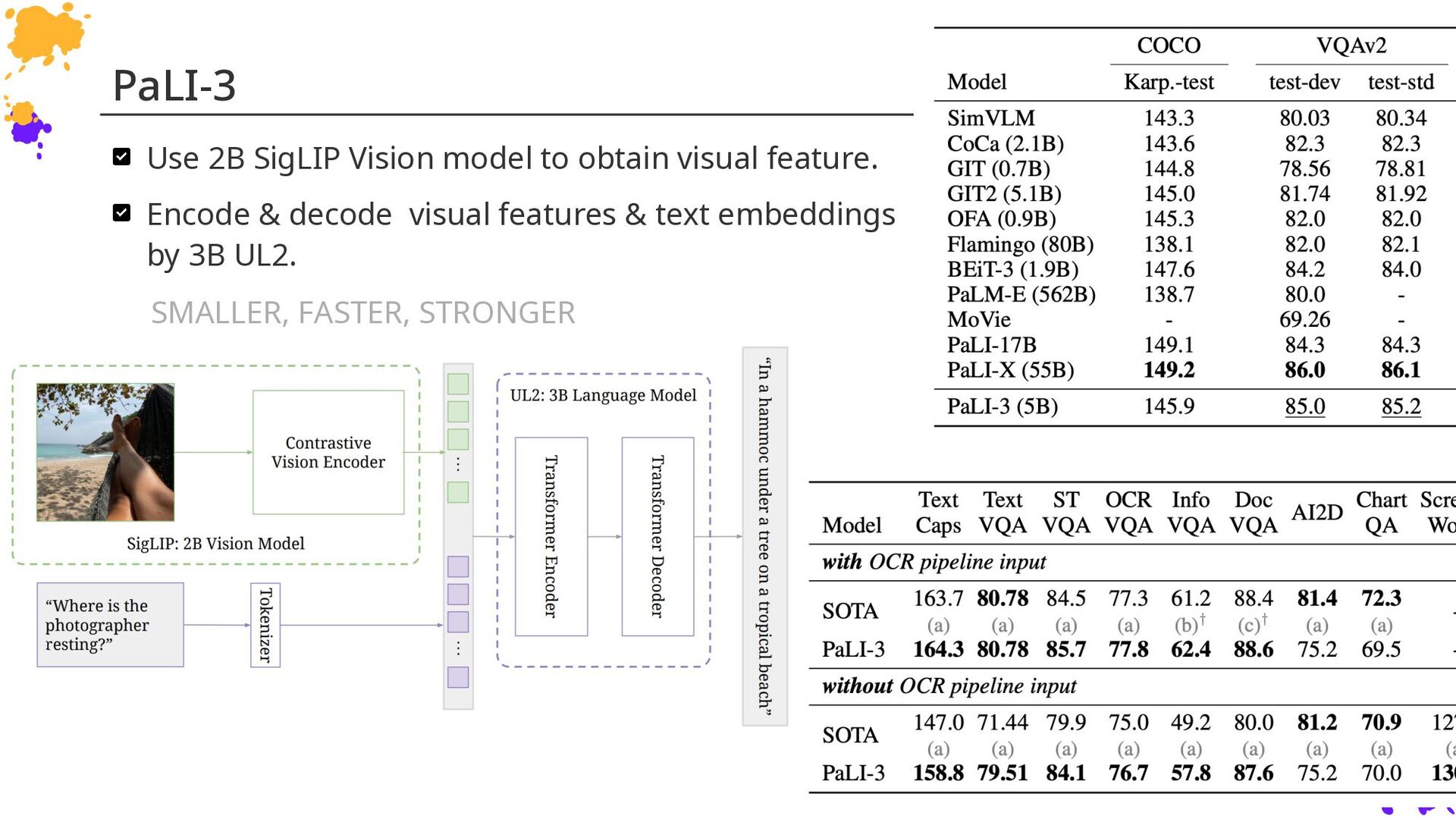{kind=link}
![Vocab. sizeが大きいと単語埋め込みに必要な行列が巨大化🤮 ( 特に multilingual 設定など ) [Vocab. size] x](https://files.speakerdeck.com/presentations/add5548186ba4ad0bc13645b1ff040db/slide_22.jpg){kind=link}
{kind=link}