Mordvintsev2 Andrey Zhmoginov2 Max Vladymyrov2 1. ETH Zurich, 2. Google Research 杉浦孔明研究室 小槻誠太郎 ICML23 OralPoster J. von Oswald, E. Niklasson, E. Randazzo, J. Sacramento, A. Mordvintsev, A. Zhmoginov, and M. Vladymyrov, “Transformers Learn In-Context by Gradient Descent,” in ICML, 2023, pp. 35151–35174.
{kind=link}
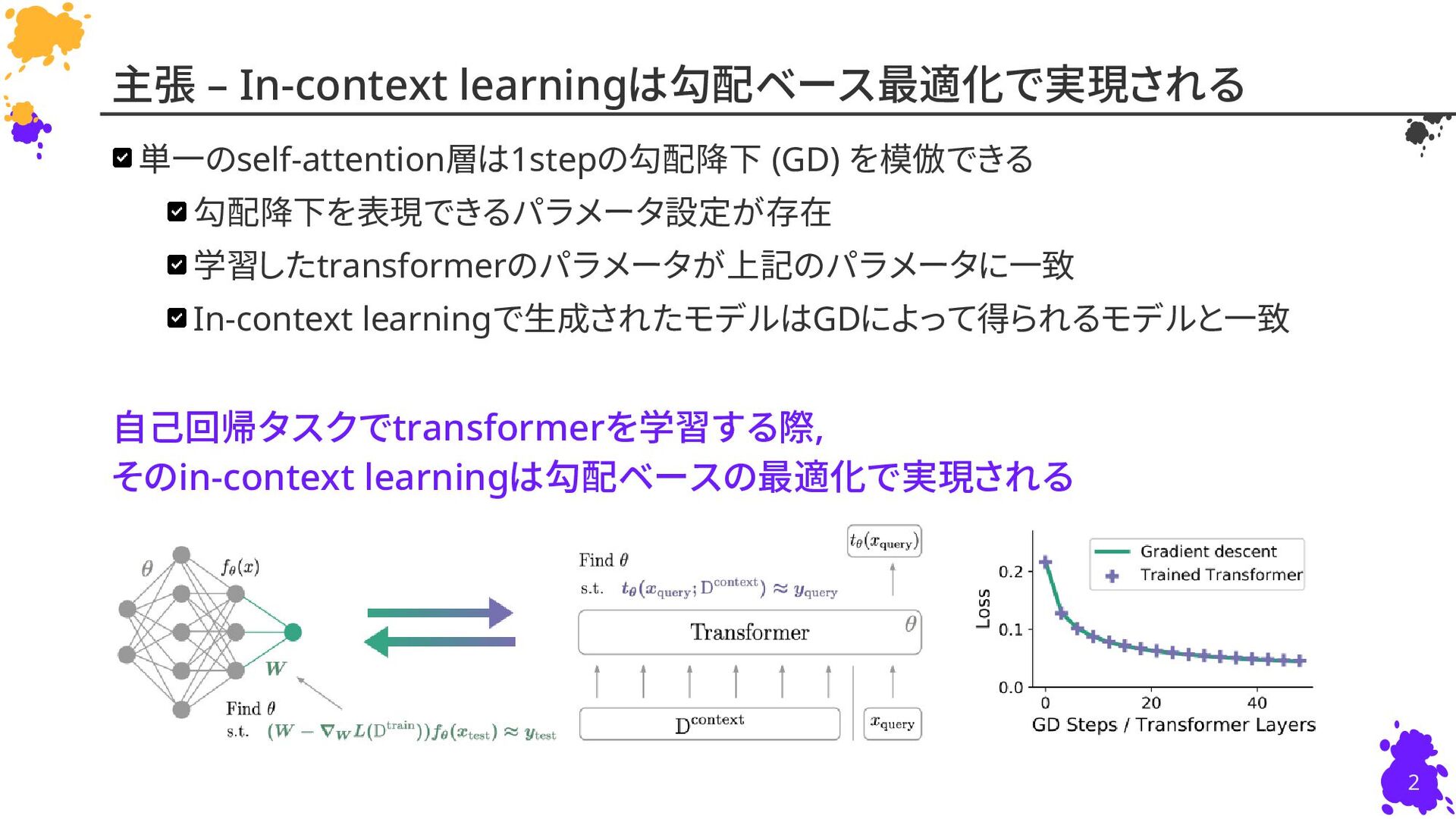{kind=link}
![多様な分野でtransformer architectureが採用されている 3 背景 – Transformerがデファクトに ViT [Dosovitskiy+, ICLR21] Graphormer](https://files.speakerdeck.com/presentations/e137bf9d652e42a3892f6986f38b25f4/slide_2.jpg){kind=link}
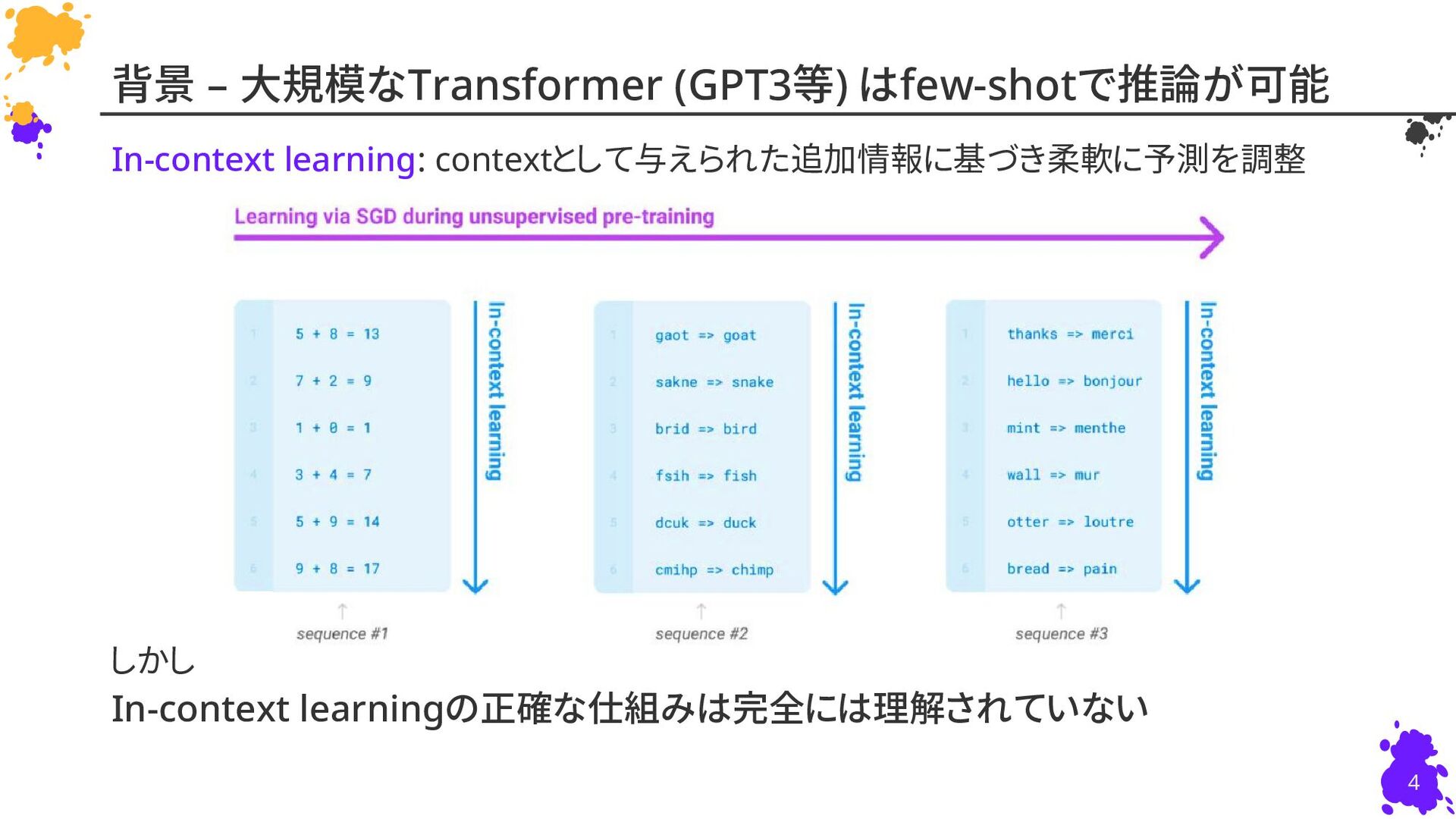{kind=link}
![Induction heads [Olsson+, 22]: Input: [A], [B], …, [A] →](https://files.speakerdeck.com/presentations/e137bf9d652e42a3892f6986f38b25f4/slide_4.jpg){kind=link}
{kind=link}
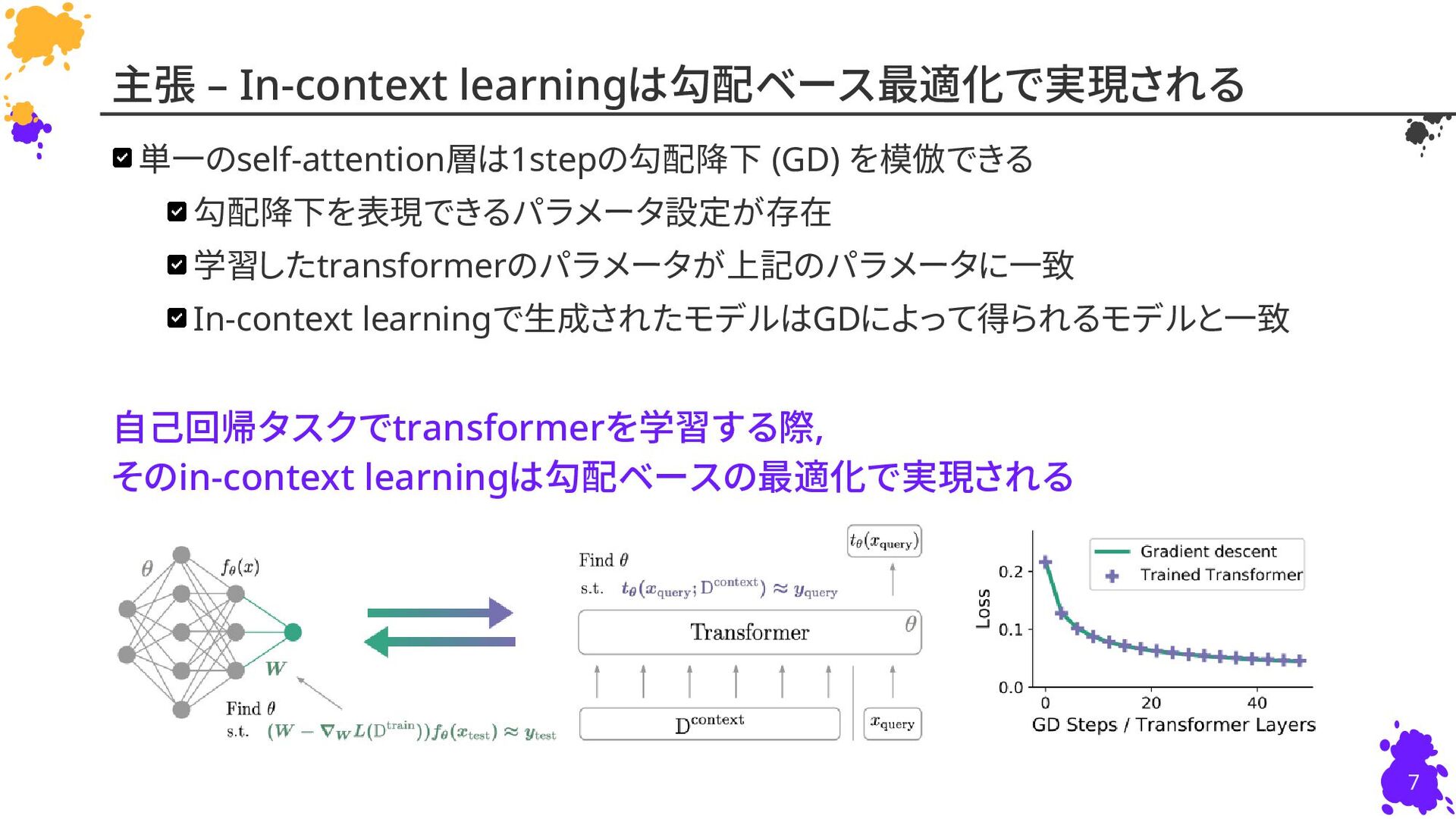{kind=link}
![Recap: Self-attention ↓ Linear self-attention [Schlag+, ICML21] 8 準備1/2 –](https://files.speakerdeck.com/presentations/e137bf9d652e42a3892f6986f38b25f4/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
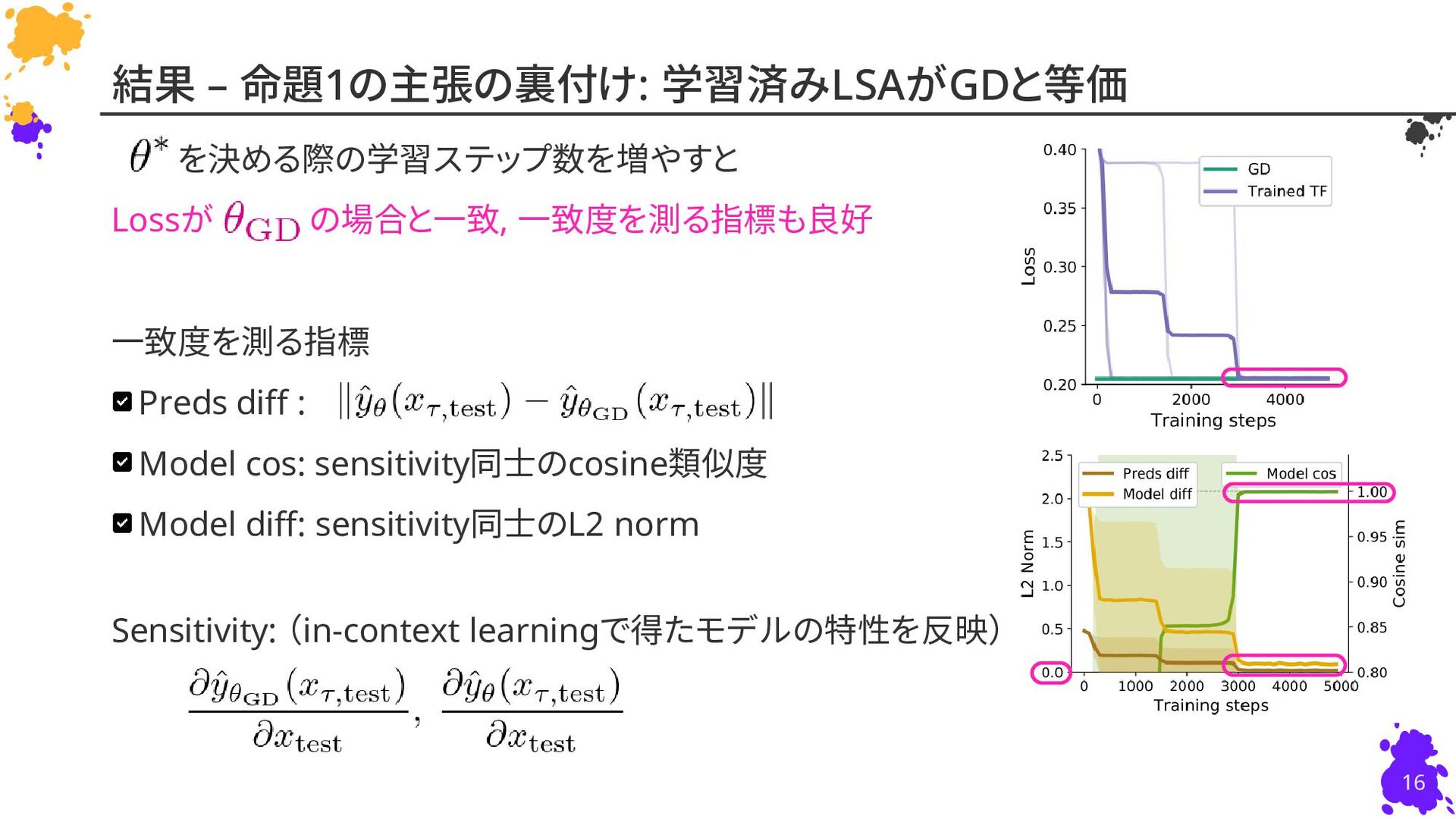{kind=link}
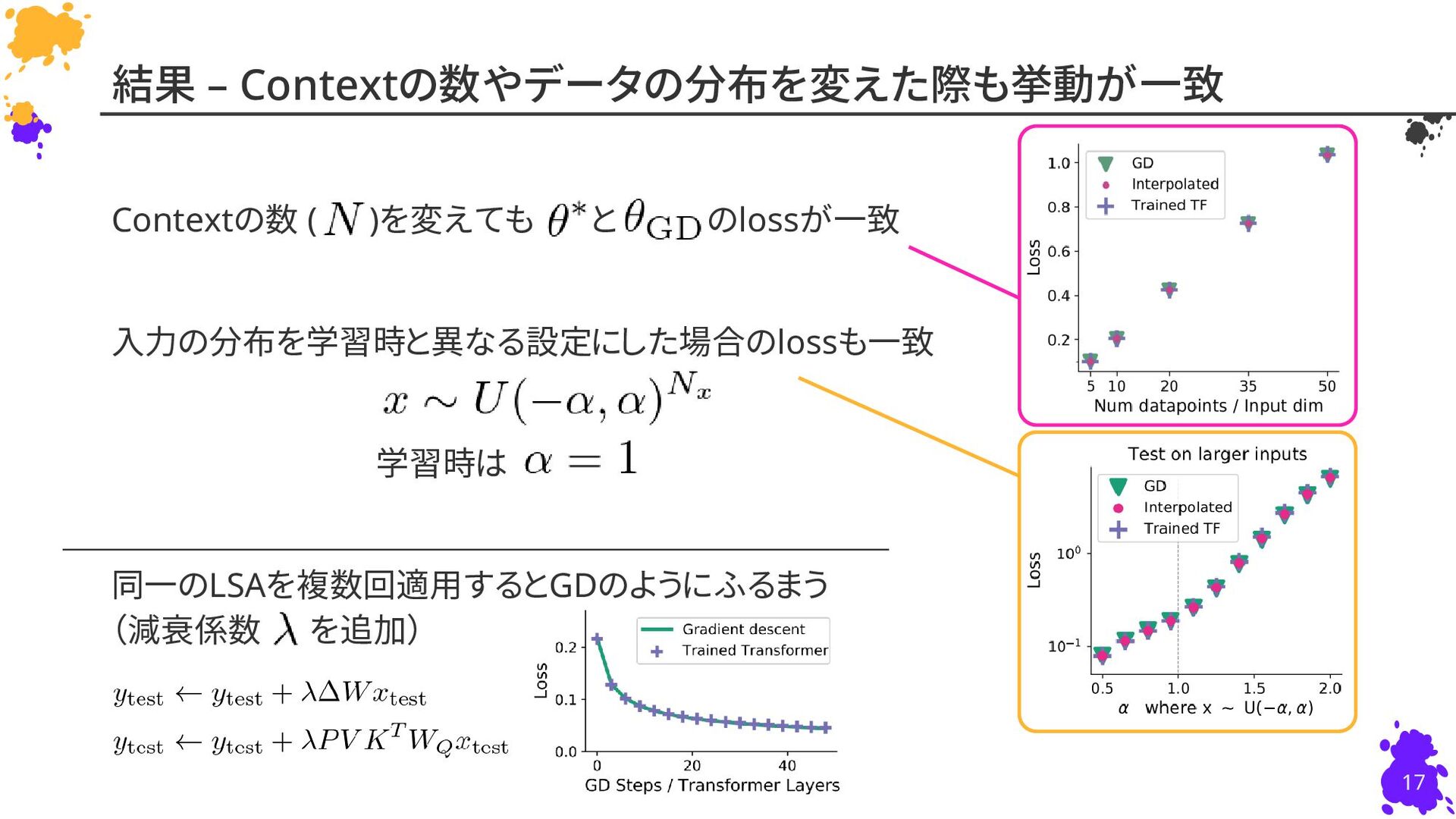{kind=link}
{kind=link}
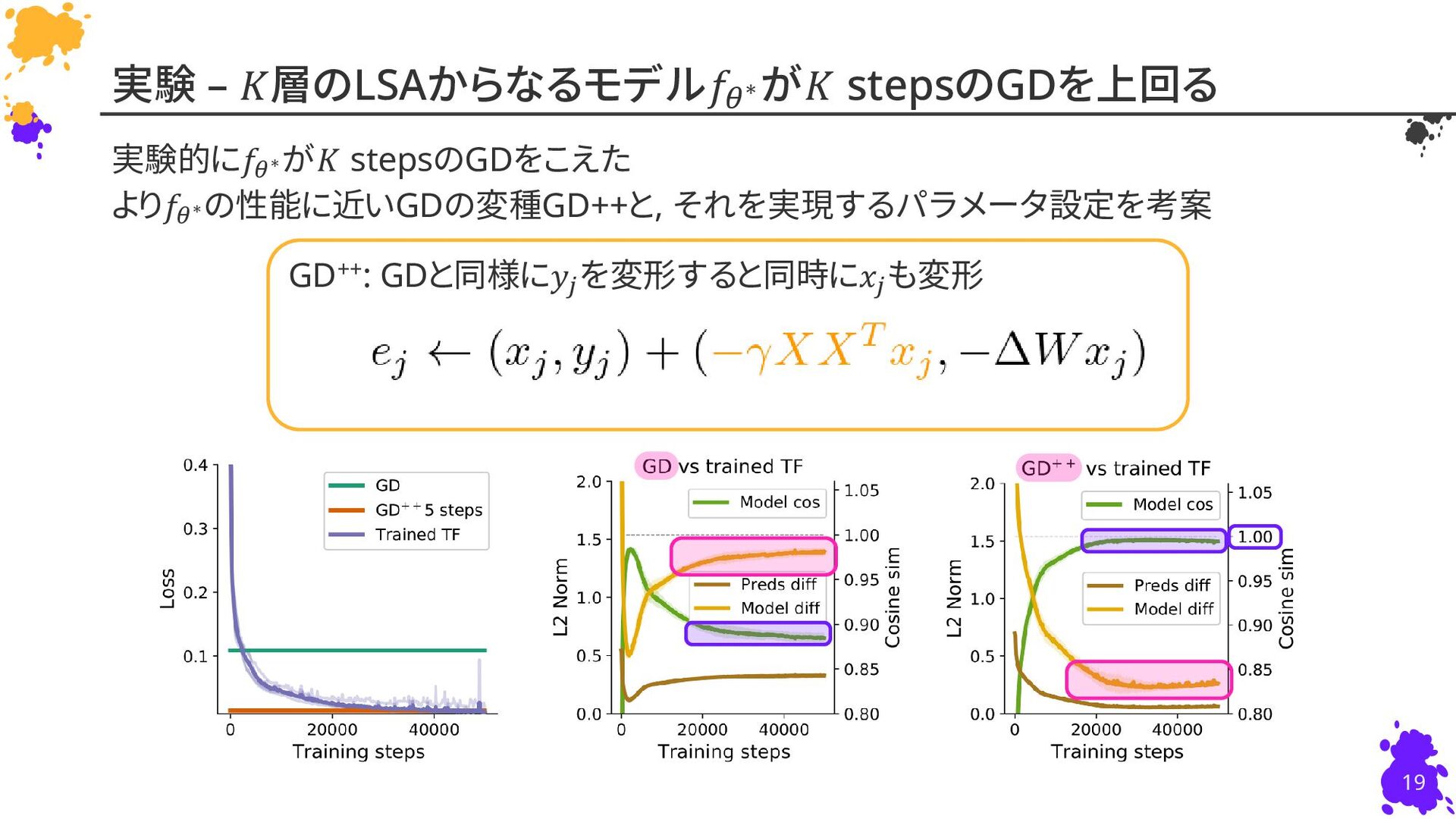{kind=link}
{kind=link}
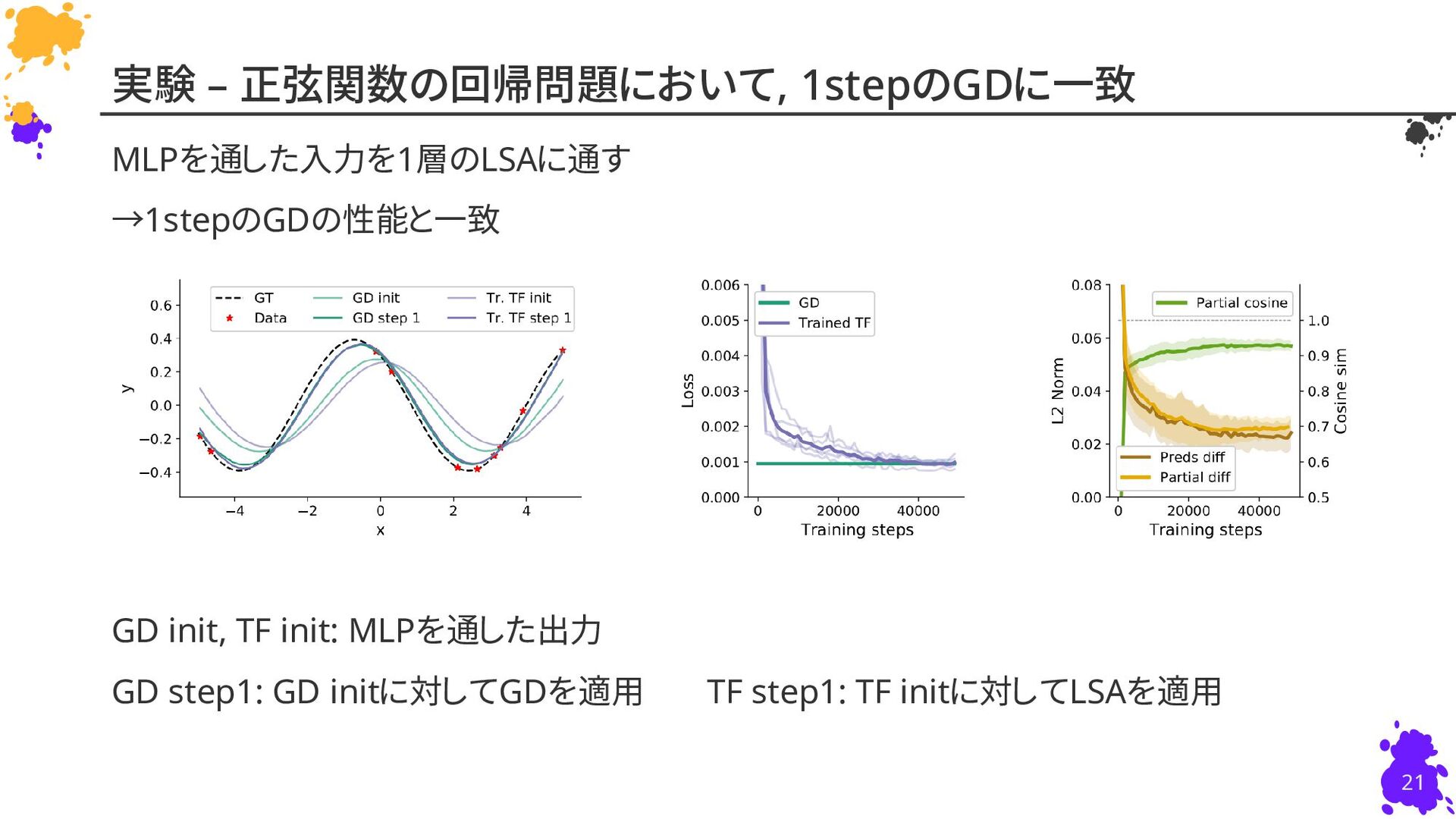{kind=link}
{kind=link}
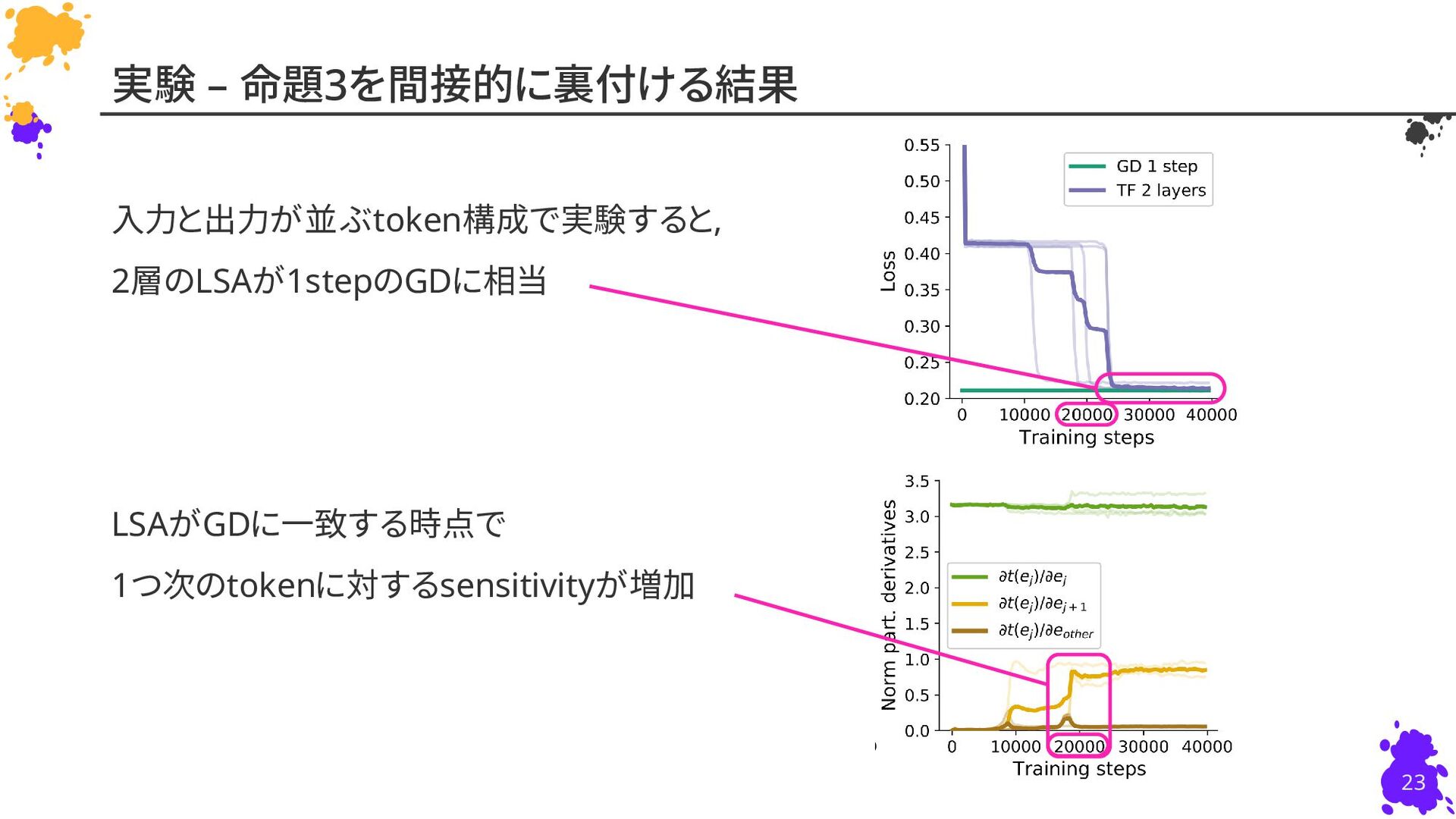{kind=link}
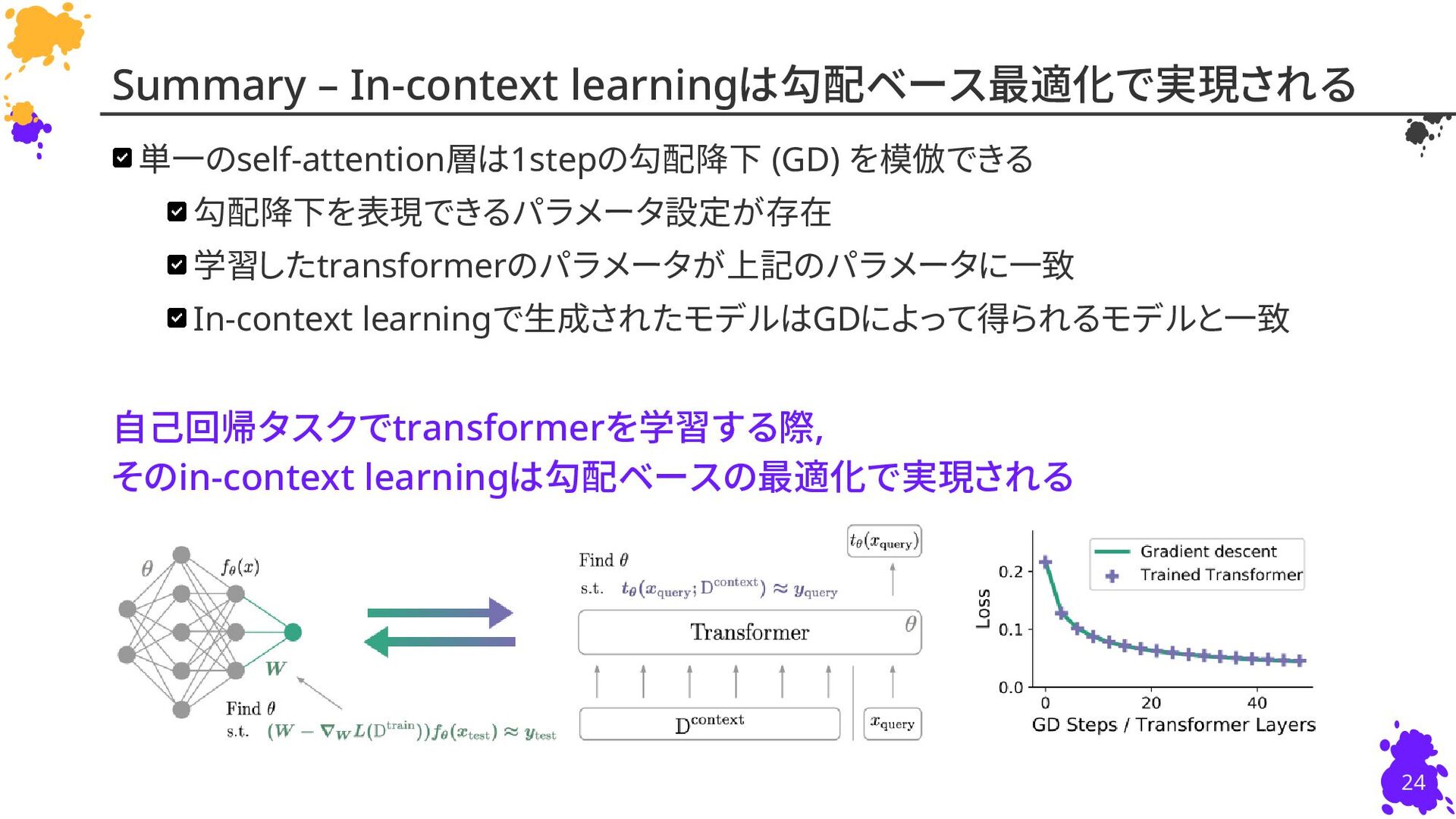{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
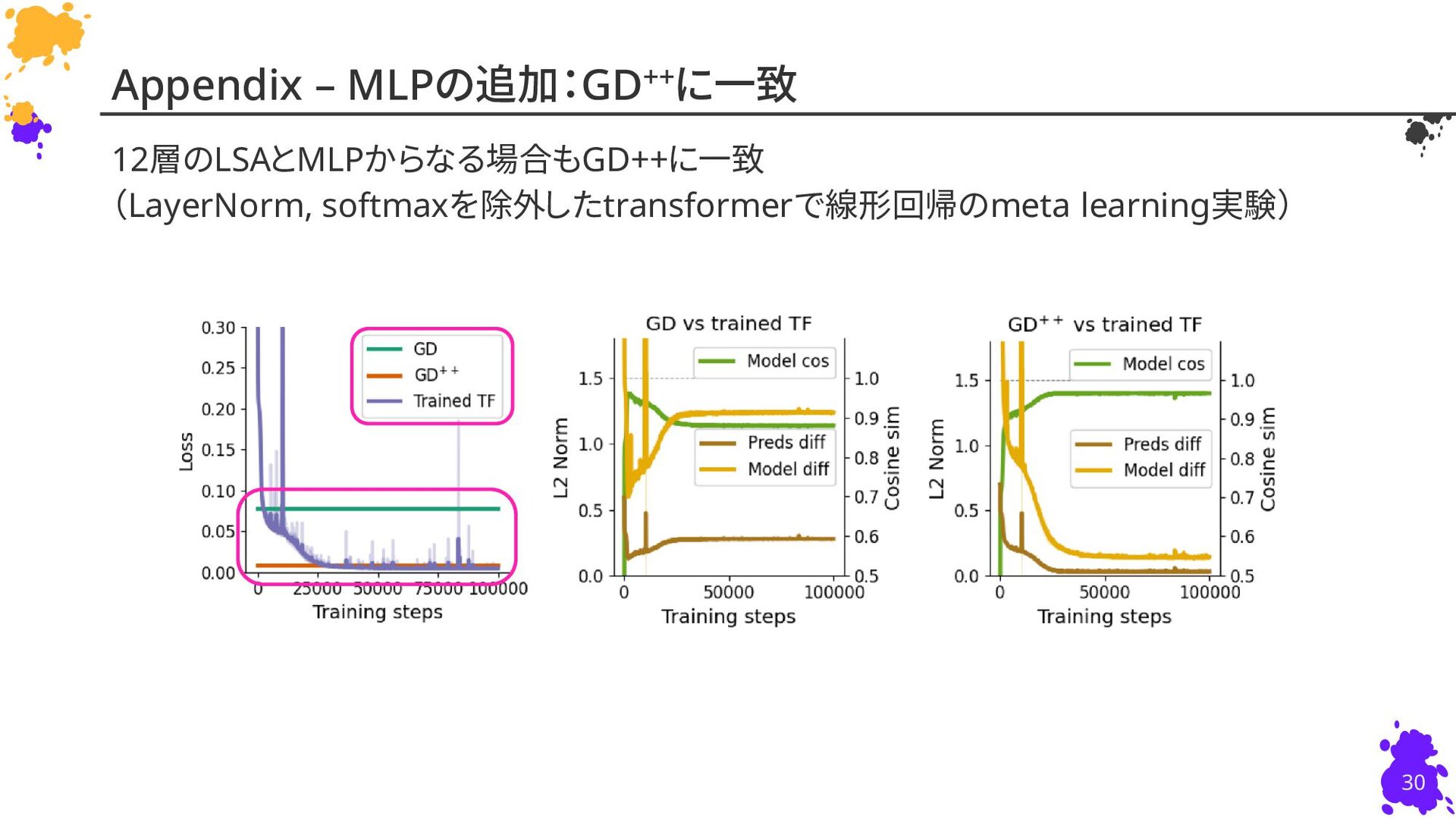{kind=link}
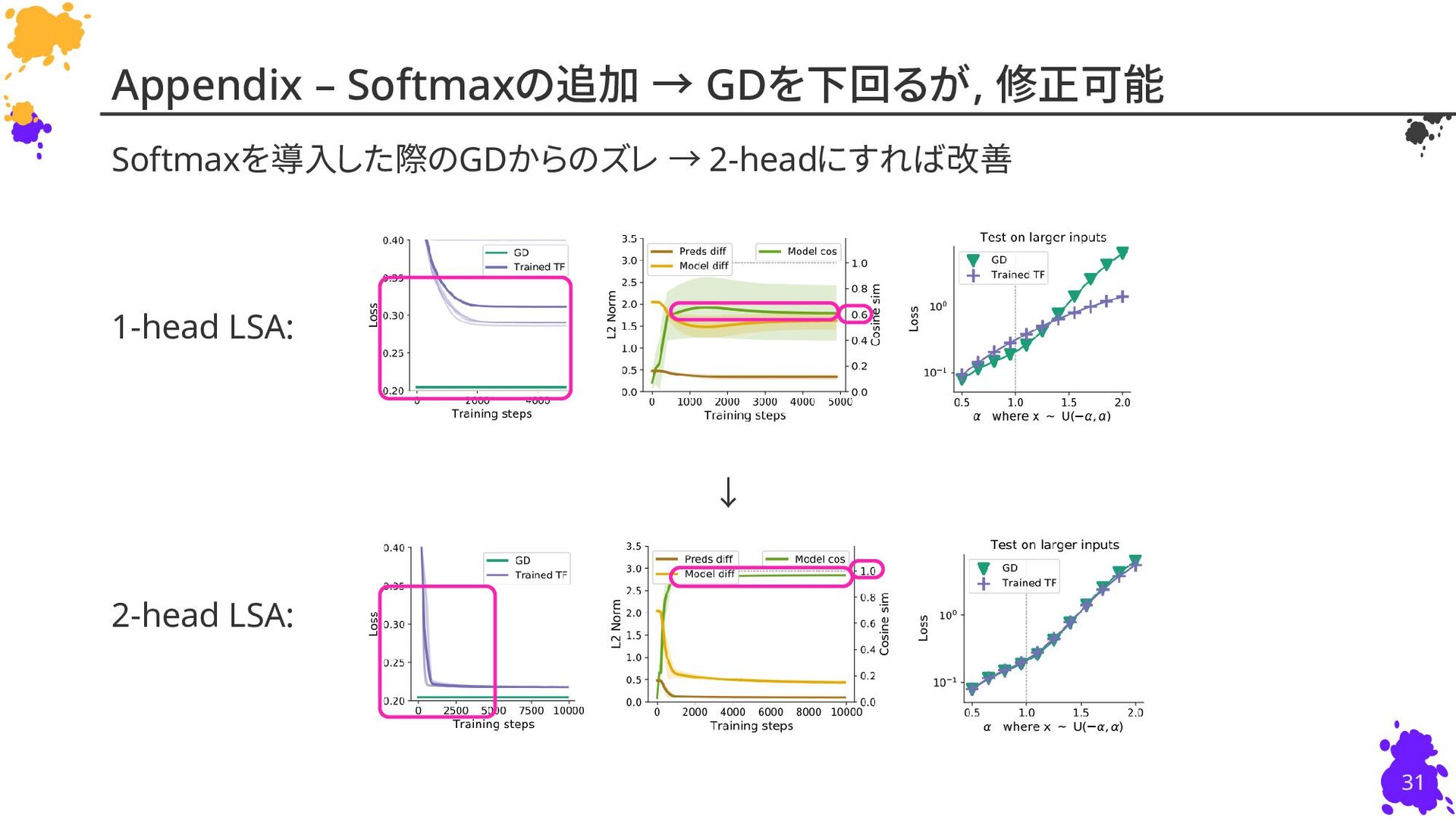{kind=link}
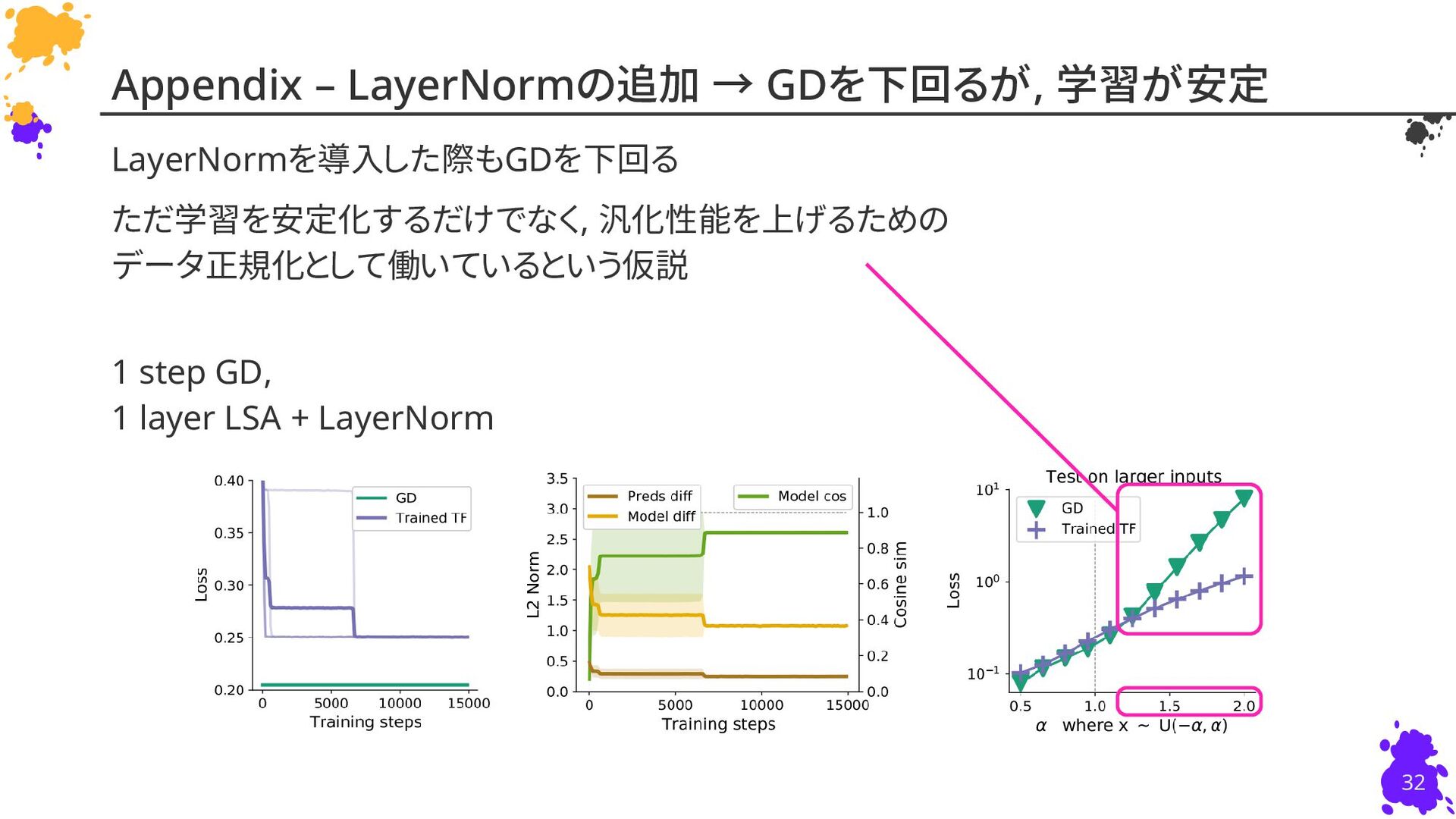{kind=link}
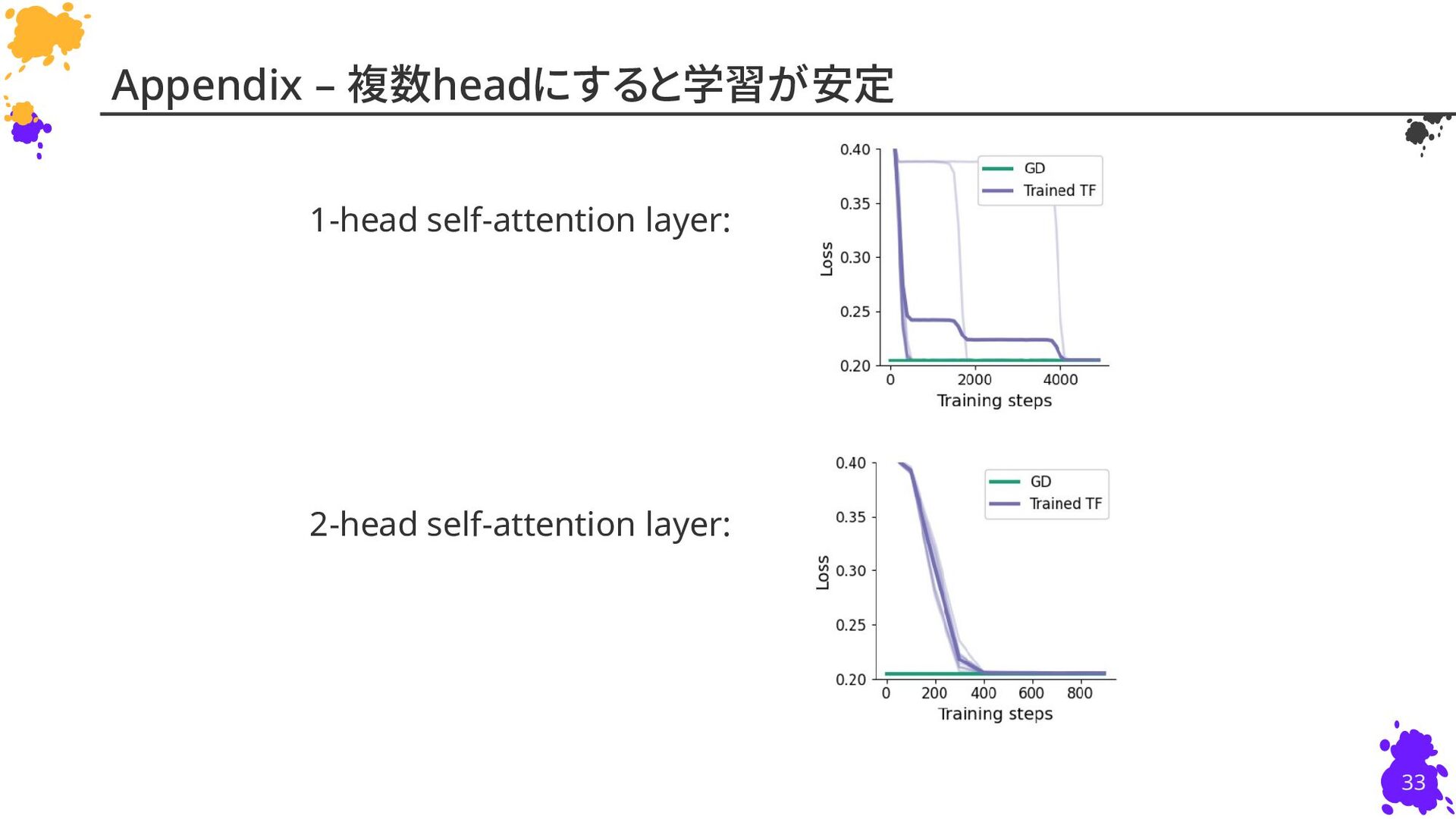{kind=link}
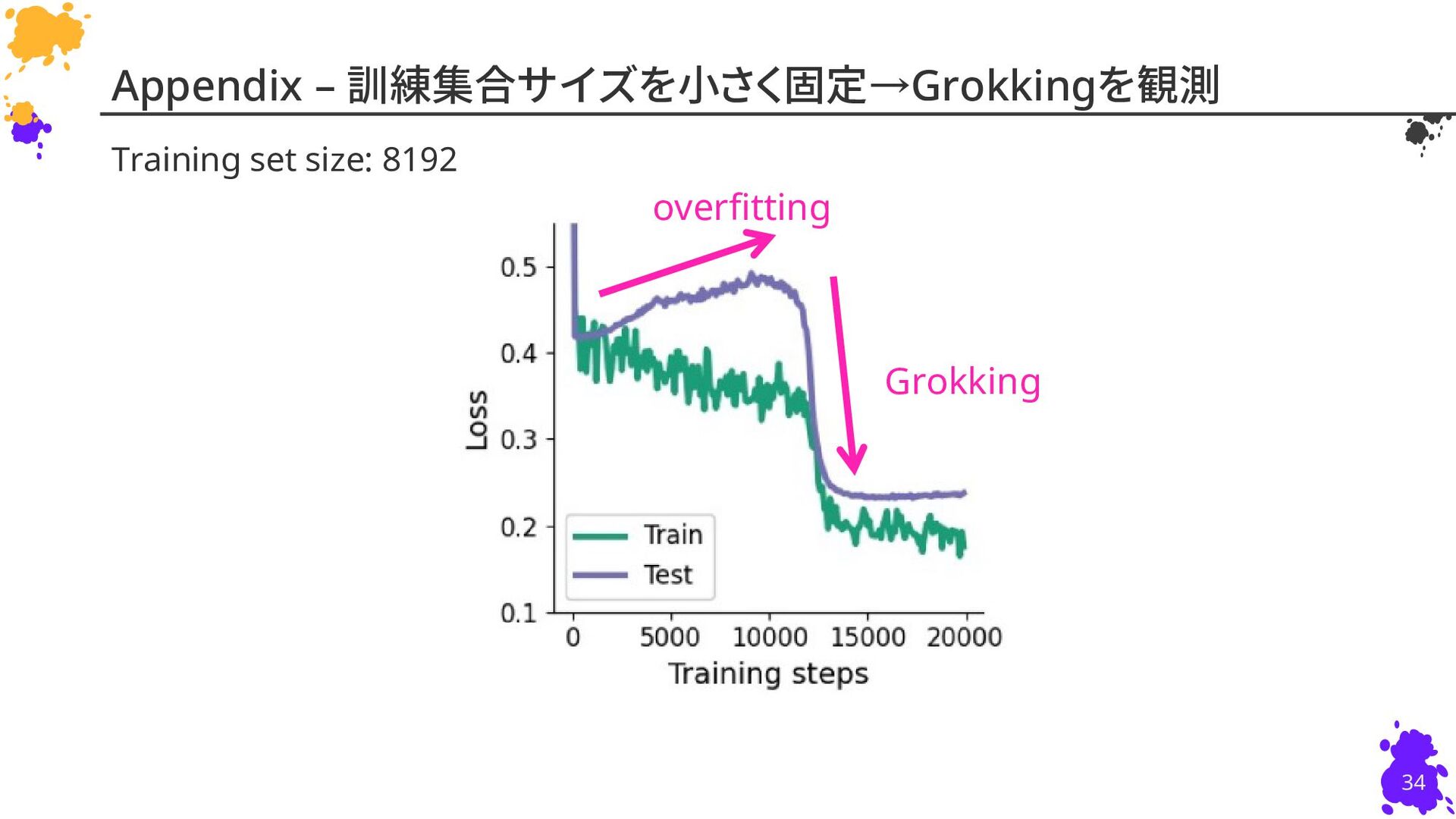{kind=link}
{kind=link}