Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[Journal club] Prototypical Contrastive Learnin...
Search
Semantic Machine Intelligence Lab., Keio Univ.
PRO
August 01, 2022
Technology
1.2k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[Journal club] Prototypical Contrastive Learning of Unsupervised Representations
慶應義塾⼤学 杉浦孔明研究室 B4 和田唯我 / Yuiga Wada
Semantic Machine Intelligence Lab., Keio Univ.
PRO
August 01, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
61
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
74
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
110
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
90
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
6.9k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
Text-to-SQLをAgentCoreで実現し、生成されるSQLの精度を定量的に評価する
yakumo
2
680
Kotlin 開発のツラミを爆破した話! / Explode the difficulty of Kotlin dev!
eller86
0
150
ループエンジニアリングでE2Eテストを実践
noriyukitakei
0
310
金融の未来を考える / Thinking About the Future of Finance
ks91
PRO
0
180
完全自律ロボットを作りたくて、先に開発を自律させた話(ROS Japan UG #63 LT)
rryz09
0
420
テスト設計の本質を改めて考えてみる~生成AIを活用する時代だからこそ、作ったテストの説明性を高めよう~
yamasaki696
1
390
オブザーバビリティ、本当に活用できてる? 〜API連携×生成AIで成熟度を自動評価〜
dmmsre
1
2.2k
20260702_生成AIはどこまで成長するのか_チャットだけじゃない世界
doradora09
PRO
0
110
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
12
1.8k
ローカルLLMとLINE Botの組み合わせ その3 / LINE DC Generative AI Meetup #8
you
PRO
0
120
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
140
AIに「使われる」時代のSaaS戦略 〜既存WebAPIのMCPサーバー化における開発ノウハウ〜
ekispert_api
0
300
Featured
See All Featured
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
Exploring anti-patterns in Rails
aemeredith
3
440
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
44k
Design in an AI World
tapps
1
260
New Earth Scene 8
popppiees
3
2.4k
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
330
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
Prompt Engineering for Job Search
mfonobong
0
370
Statistics for Hackers
jakevdp
799
230k
Transcript
Prototypical Contrastive Learning of Unsupervised Representations Junnan Li, Pan Zhou,
Caiming Xiong, Steven C.H. Hoi (Salesforce Research) Li, Pan Zhou, Caiming Xiong and Steven C. H. Hoi. Prototypical Contrastive Learning of Unsupervised Representations, ICLR2021 慶應義塾⼤学 杉浦孔明研究室 和⽥唯我 ICLR 2021
和田唯我 / Yuiga Wada
概要 2 ü 教師なし表現学習⼿法 Prototypical Contrastive Learning (PCL) を提案 ü
EM-algorithmに基づき, プロトタイプを基準とした損失 ProtoNCE Loss を提案 ü 様々な画像認識タスクで既存⼿法を超える結果を記録
背景: Instance-wiseな対照学習は, 本質的な意味情報を獲得できない 3 o Instance-wiseな教師なし表現学習 • 加⼯された画像(instance)のペアが同じ元画像に由来するかを識別 o Instance-wiseな⼿法における2つの問題点
1. 低次元の特徴だけで識別できるため,識別はNNにとって簡単なタスク ⇒ ⾼密度な情報をエンコードしているとは⾔い難い 2. ペア間の類似度が⾼くても, 負例は負例として扱う ⇒ 負例ペアにおける類似性についての 意味情報は獲得できない
既存⼿法: 対照学習⼿法には改善の余地がある 4 既存⼿法 種類 問題点 • SimCLR[Chen+, ICML20] •
MoCo[He+, CVPR20] Instance-wise Instance-wiseな⼿法であり, 前述の問題点有り • DeepCluster[Caron+, ECCV18] prototype-wise PCAによる次元削減処理を挟む ⇒クラスタリングによる最適化が 直接的でない DeepCluster[Caron+, ECCV18] PCA not good
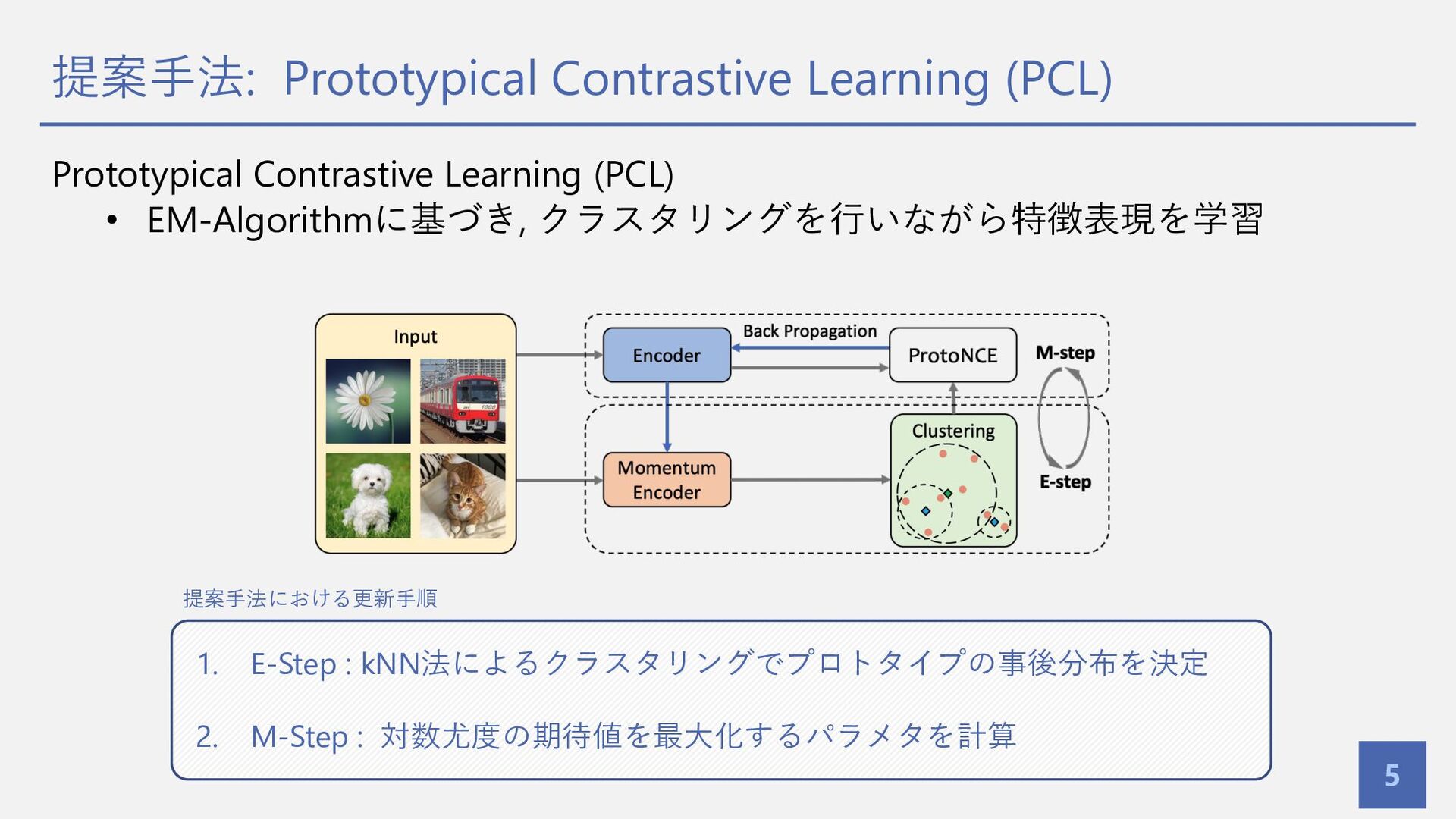
提案⼿法: Prototypical Contrastive Learning (PCL) 5 Prototypical Contrastive Learning (PCL)
• EM-Algorithmに基づき, クラスタリングを⾏いながら特徴表現を学習 1. E-Step : kNN法によるクラスタリングでプロトタイプの事後分布を決定 2. M-Step : 対数尤度の期待値を最⼤化するパラメタを計算 提案⼿法における更新⼿順
EM-Algorithm: PCLでは対数尤度最⼤化のためEMを⽤いる 6 1. E-Step : kNN法によるクラスタリングでプロトタイプの事後分布を決定 2. M-Step :
対数尤度の期待値を最⼤化するパラメタを計算 提案⼿法における更新⼿順 プロトタイプ 𝒄𝒊 を潜在変数として, 対数尤度を最⼤化するモデルのパラメタ 𝜃 を獲得したい (プロトタイプ : クラスタの重⼼のこと) 提案⼿法の⽬標
前準備: 最適化における⽬的関数の整理 7 上式を直接求めるのは困難なので, Jensenの不等式より, 最右辺を最⼤化すれば良いので,最右辺からパラメタ 𝜃 依存部だけ取り出した下式 を⽬的関数とする. ただし,
𝑄 𝐜𝐢 ≔ 𝑝 𝒄𝒊 ; 𝒙𝒊 , 𝜽 (∵ ∑𝑄 𝐜𝐢 = 1 ⇒ − ∑ ∑𝑄 𝐜𝐢 𝑙𝑜𝑔𝑄 𝐜𝐢 は定数)
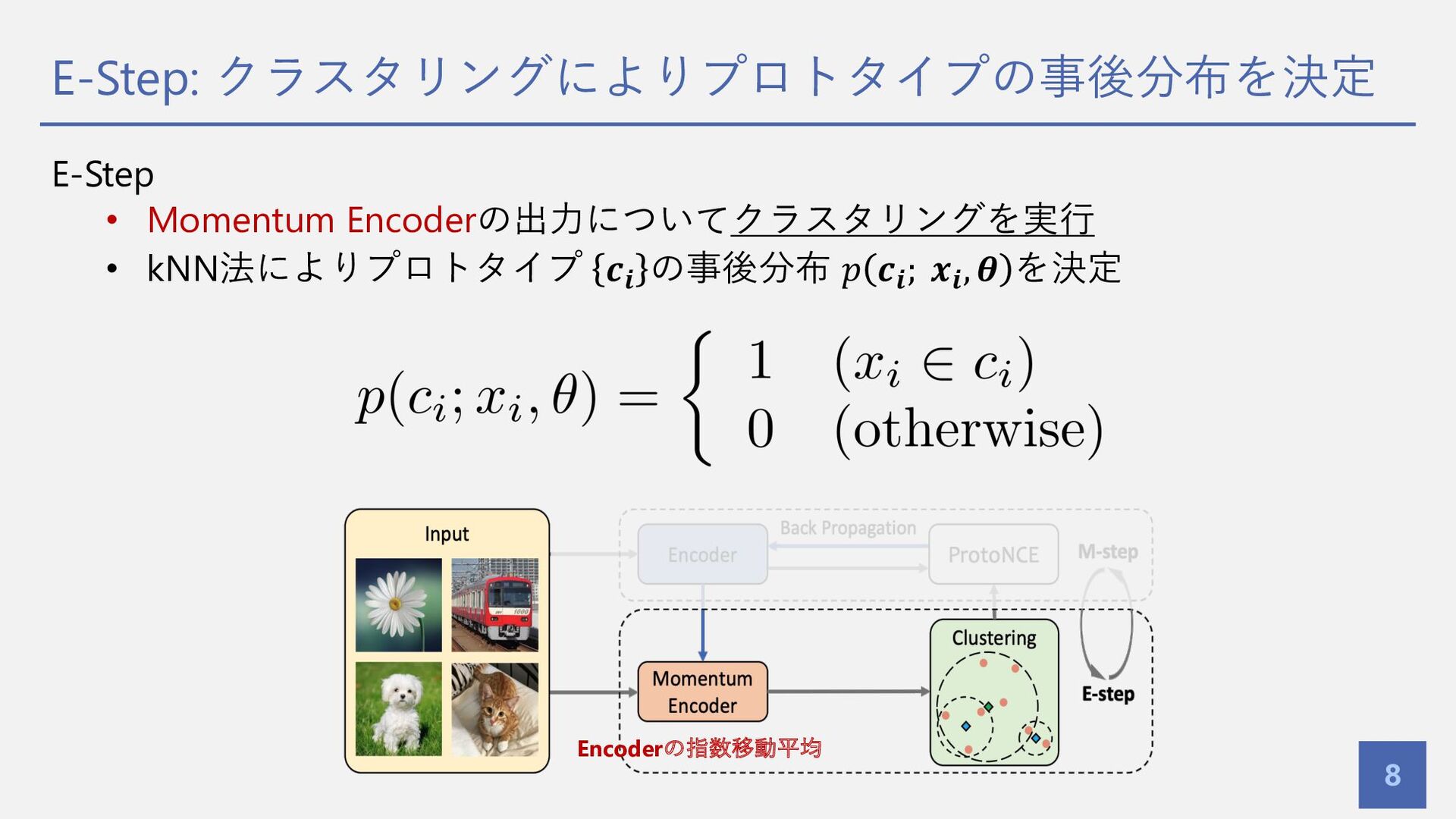
E-Step: クラスタリングによりプロトタイプの事後分布を決定 8 E-Step • Momentum Encoderの出⼒についてクラスタリングを実⾏ • kNN法によりプロトタイプ 𝒄𝒊
の事後分布 𝑝 𝒄𝒊; 𝒙𝒊, 𝜽 を決定 Encoderの指数移動平均
M-Step (1/3): 対数尤度を最⼤化するパラメタ 𝜃 を求める 9 M-Step • 対数尤度を最⼤化するパラメタ 𝜃
を求める • 事前分布を 1/𝑘 とすると, • ⼊⼒ {𝒙𝒊 } がプロトタイプを中⼼に等⽅的に分布してると仮定すると, 𝑝 𝒙𝒊; 𝒄𝒊, 𝜽 は
M-Step (2/3): 対数尤度を最⼤化するパラメタ 𝜃 を求める 10 以上より, 対数尤度を最⼤化するパラメタ 𝜃 は
(具体的な計算過程は省略) ・ ・ ・
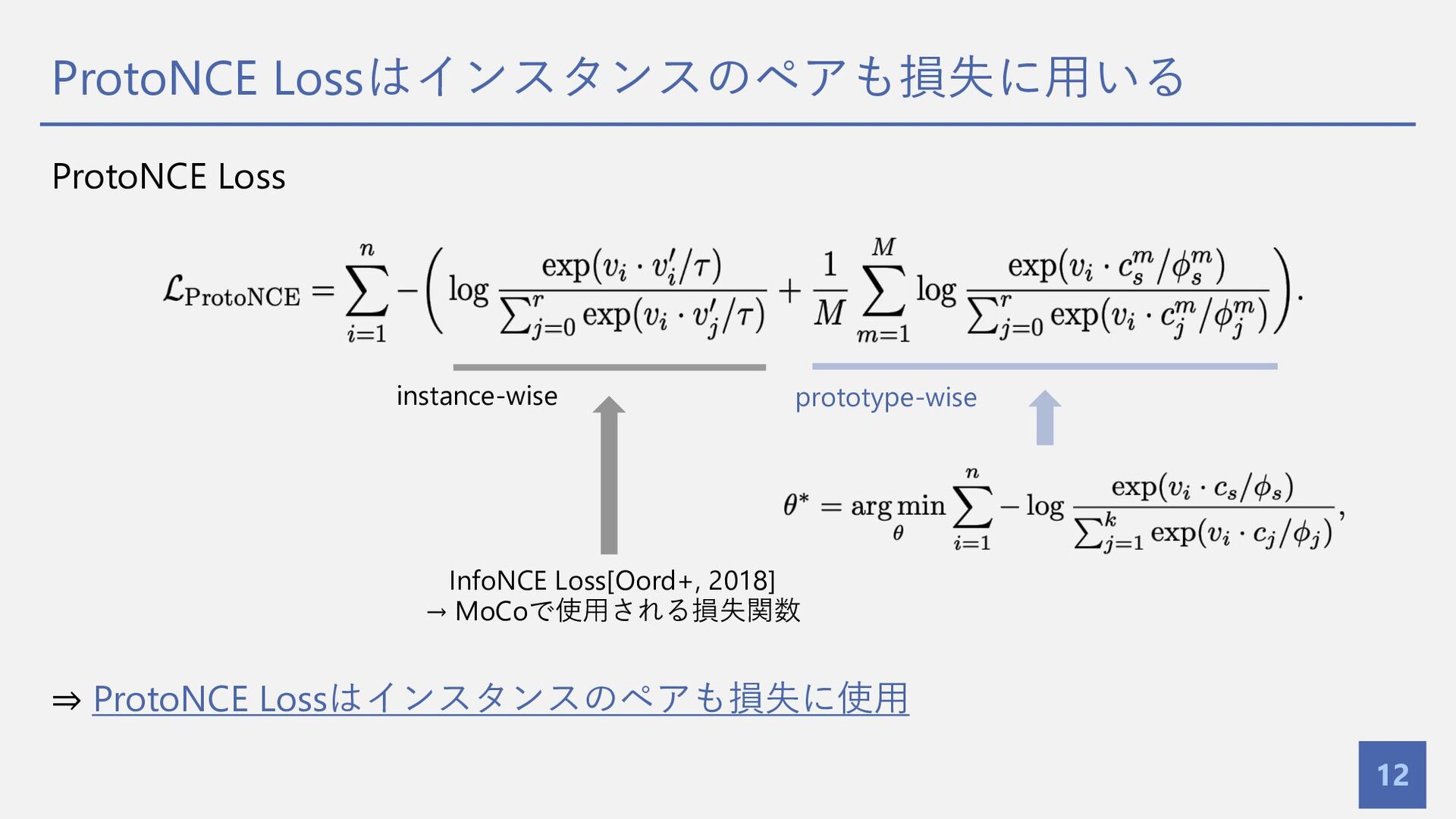
M-Step (3/3): 対数尤度を最⼤化する損失関数を提案 11 M-Step • 対数尤度を最⼤化するパラメタ 𝜃 は 損失に組み込む
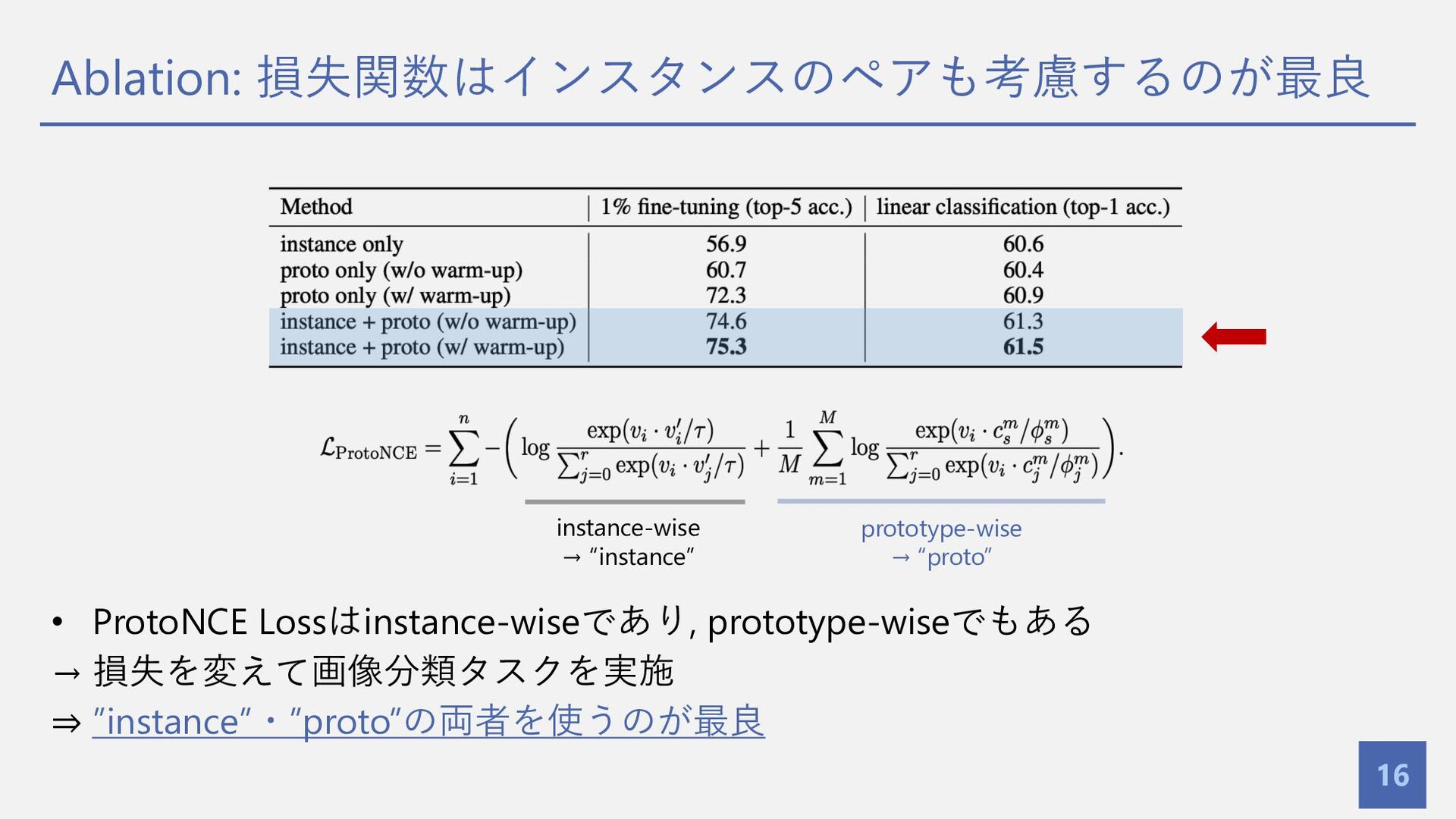
損失関数 ProtoNCE Loss (提案⼿法)
ProtoNCE Lossはインスタンスのペアも損失に⽤いる 12 ProtoNCE Loss ⇒ ProtoNCE Lossはインスタンスのペアも損失に使⽤ InfoNCE Loss[Oord+,
2018] → MoCoで使⽤される損失関数 instance-wise prototype-wise
定性的結果: 特徴ごとに適切なクラスタが形成 13 • 各クラスタに属する画像をランダムに選択 ⇒ 教師なし学習にも拘らず, 特徴ごとに適切なクラスタが形成 Cluster X
Cluster Y
定量的結果: 画像分類タスクにおいて既存⼿法を上回る結果 14 • ResNet + 線形分類器による画像分類 ⇒ MoCoやSimCLRといった既存⼿法を上回る結果を記録
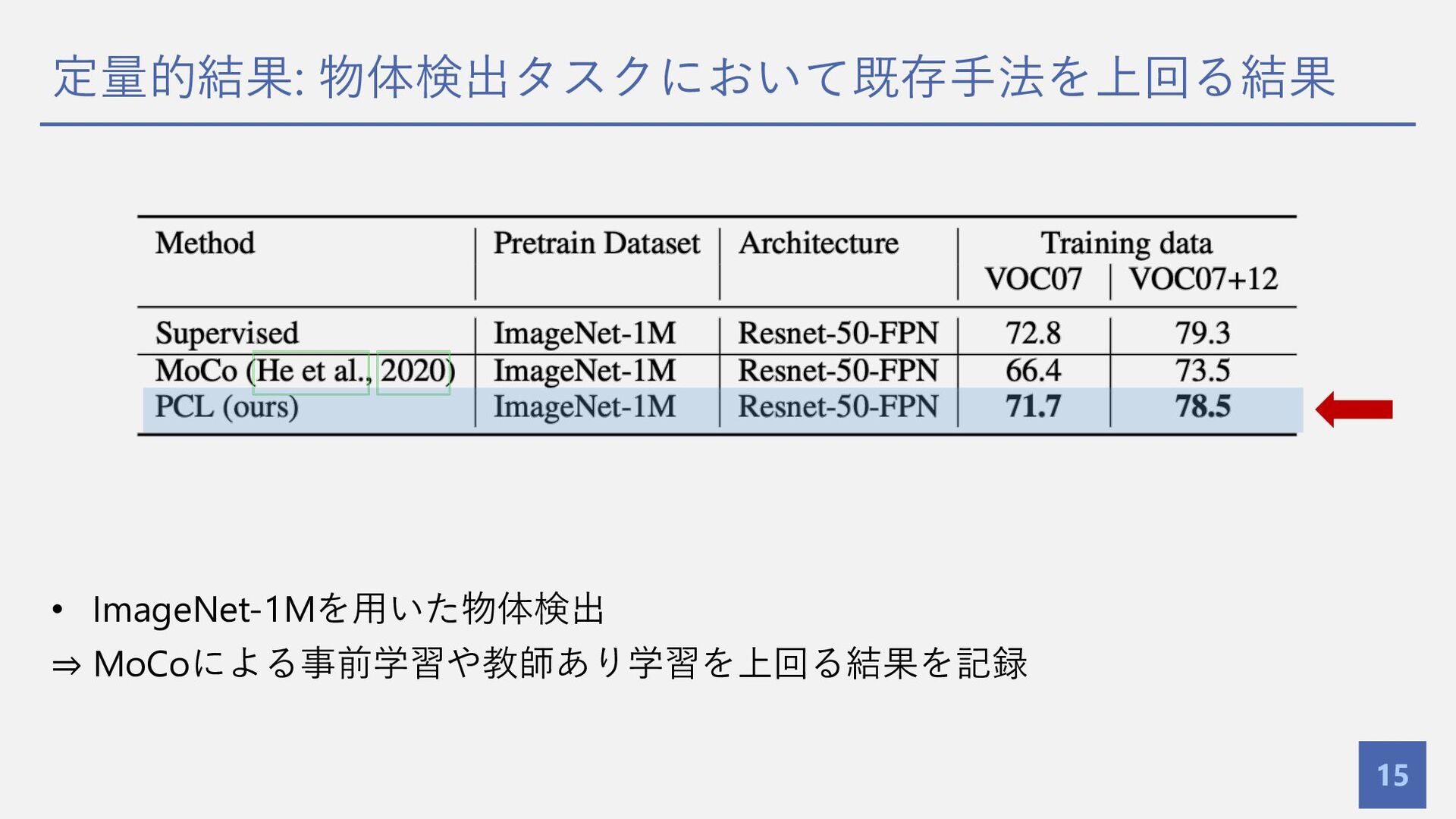
定量的結果: 物体検出タスクにおいて既存⼿法を上回る結果 15 • ImageNet-1Mを⽤いた物体検出 ⇒ MoCoによる事前学習や教師あり学習を上回る結果を記録
Ablation: 損失関数はインスタンスのペアも考慮するのが最良 16 • ProtoNCE Lossはinstance-wiseであり, prototype-wiseでもある → 損失を変えて画像分類タスクを実施 ⇒
”instance”・”proto”の両者を使うのが最良 instance-wise → “instance” prototype-wise → “proto”
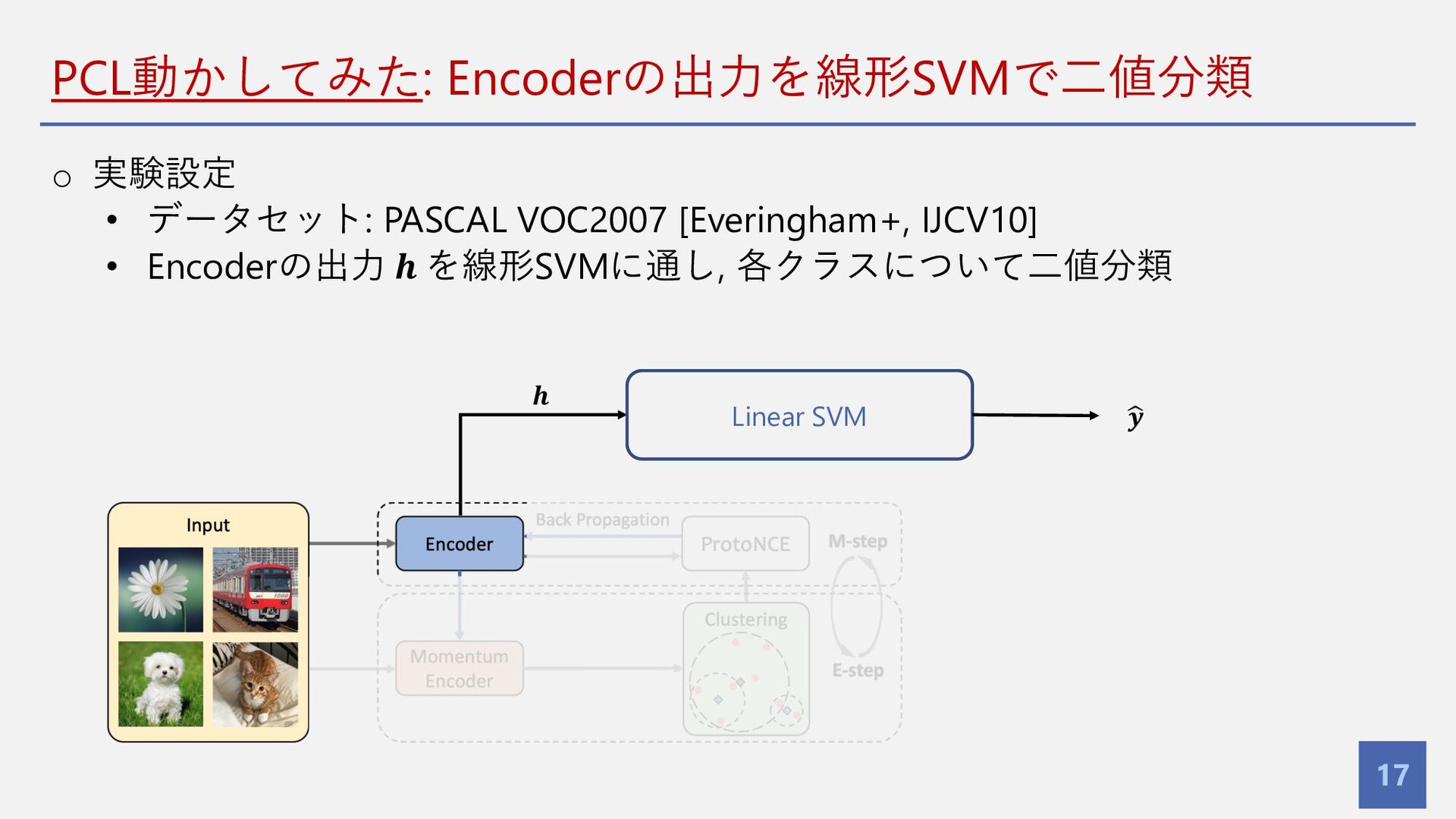
PCL動かしてみた: Encoderの出⼒を線形SVMで⼆値分類 17 o 実験設定 • データセット: PASCAL VOC2007 [Everingham+,
IJCV10] • Encoderの出⼒ 𝒉 を線形SVMに通し, 各クラスについて⼆値分類 Linear SVM 𝒉 5 𝒚
PCL動かしてみた: 極めて単純なモデルでも⾼精度で画像分類可能に 18 • 全クラスにおいて mAP = 85.45を記録 • 例:
“airplain”の⼆値分類結果 (全クラスの画像を⼊⼒) → 線形SVMという⾮常に単純なモデルで極めて良い性能を記録 True Positive False Positive
まとめ 19 ü 教師なし表現学習⼿法 Prototypical Contrastive Learning (PCL) を提案 ü
EM-algorithmに基づき, プロトタイプを基準とした損失 ProtoNCE Loss を提案 • ただし, 純粋にprototype-wiseな損失にすると精度が落ちる ü 様々な画像認識タスクで既存⼿法を超える結果を記録
Appendix: 擬似コード 20
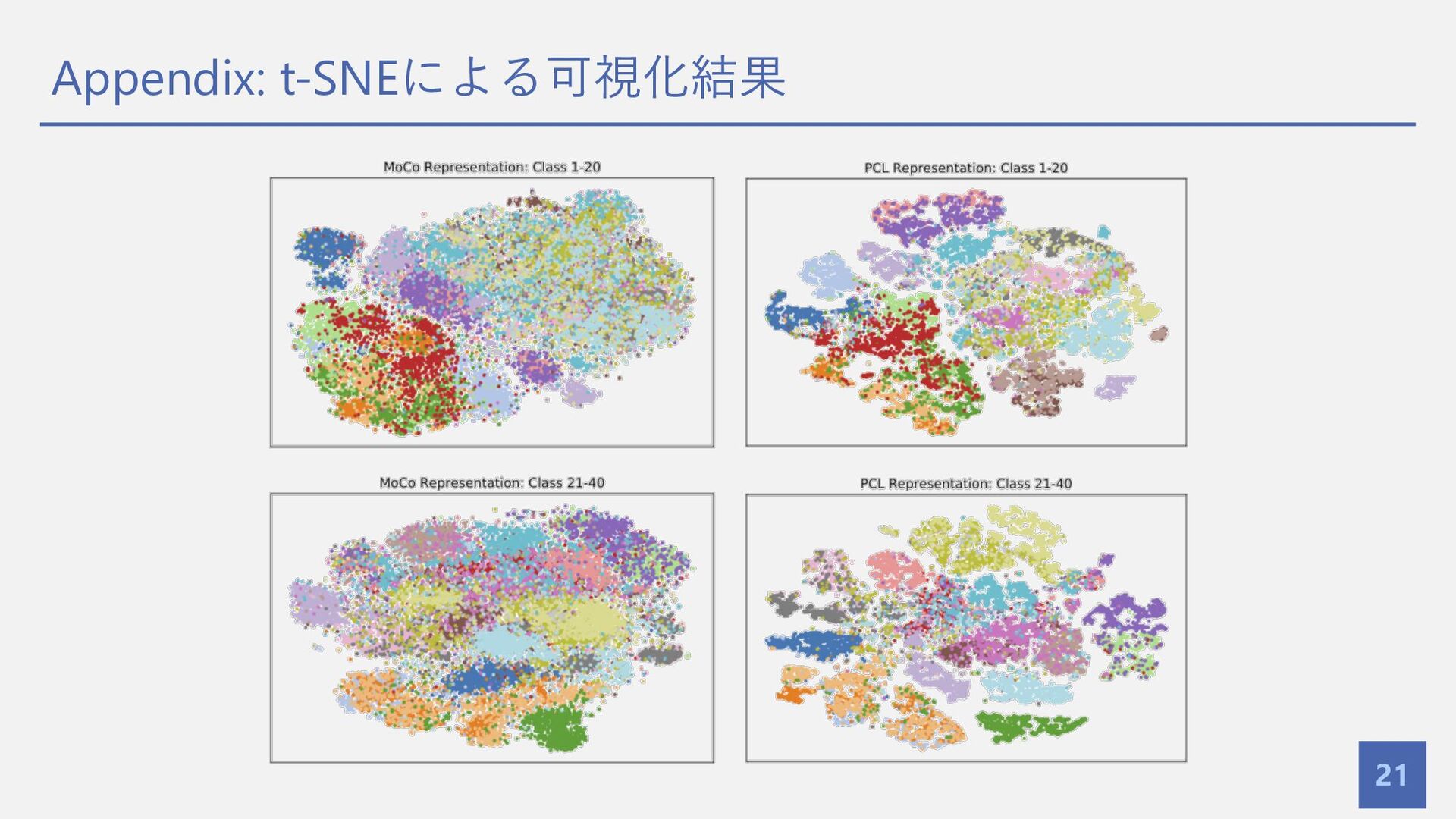
Appendix: t-SNEによる可視化結果 21
Appendix: プロトタイプの種類 22 • クラスタは包含関係を許容する (fine-grained / coarse-grained)
{kind=link}
{kind=link}
{kind=link}
![既存⼿法: 対照学習⼿法には改善の余地がある 4 既存⼿法 種類 問題点 • SimCLR[Chen+, ICML20] •](https://files.speakerdeck.com/presentations/dcc804dab29a4236a0ccc0b06d276805/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}