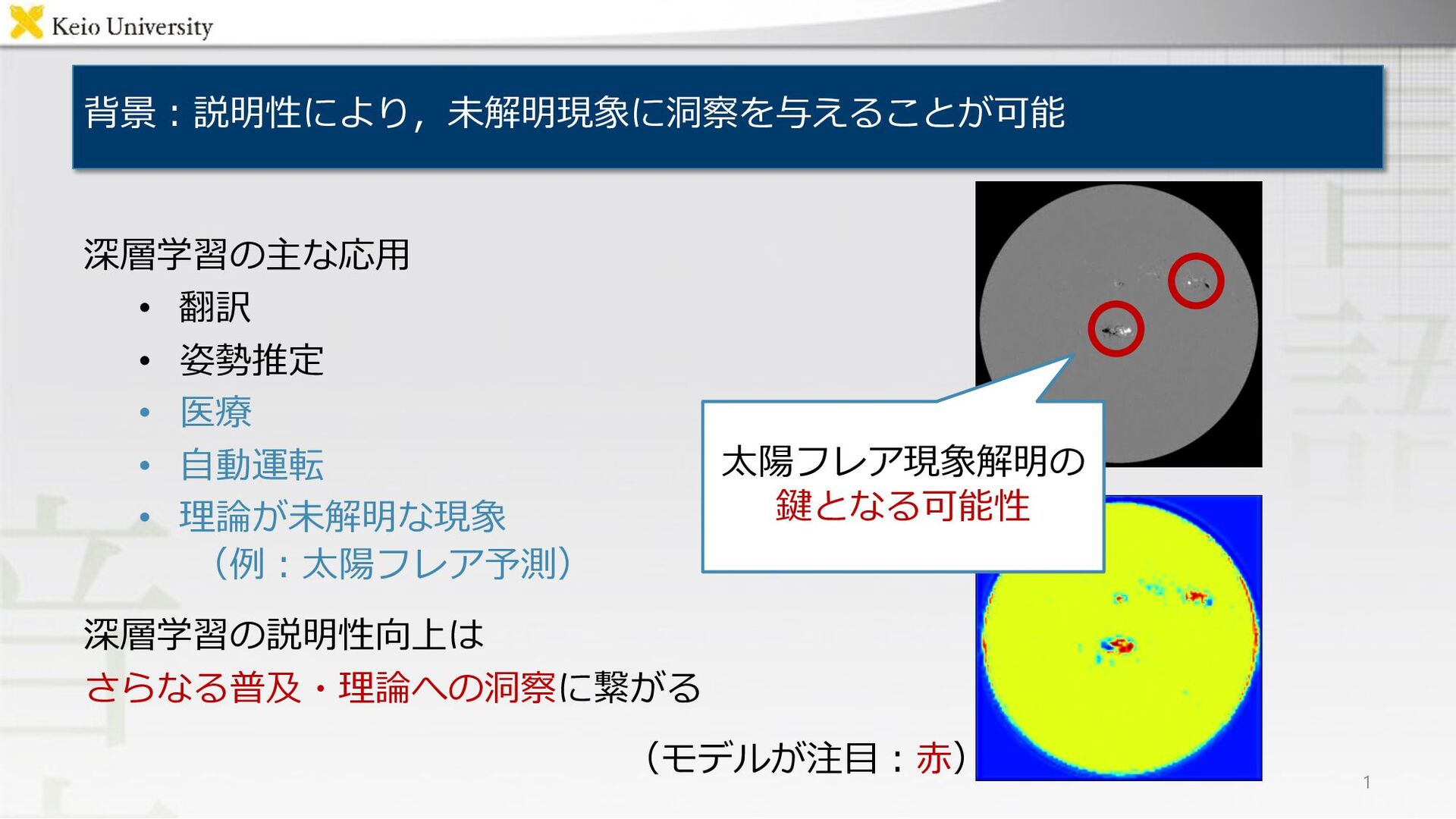
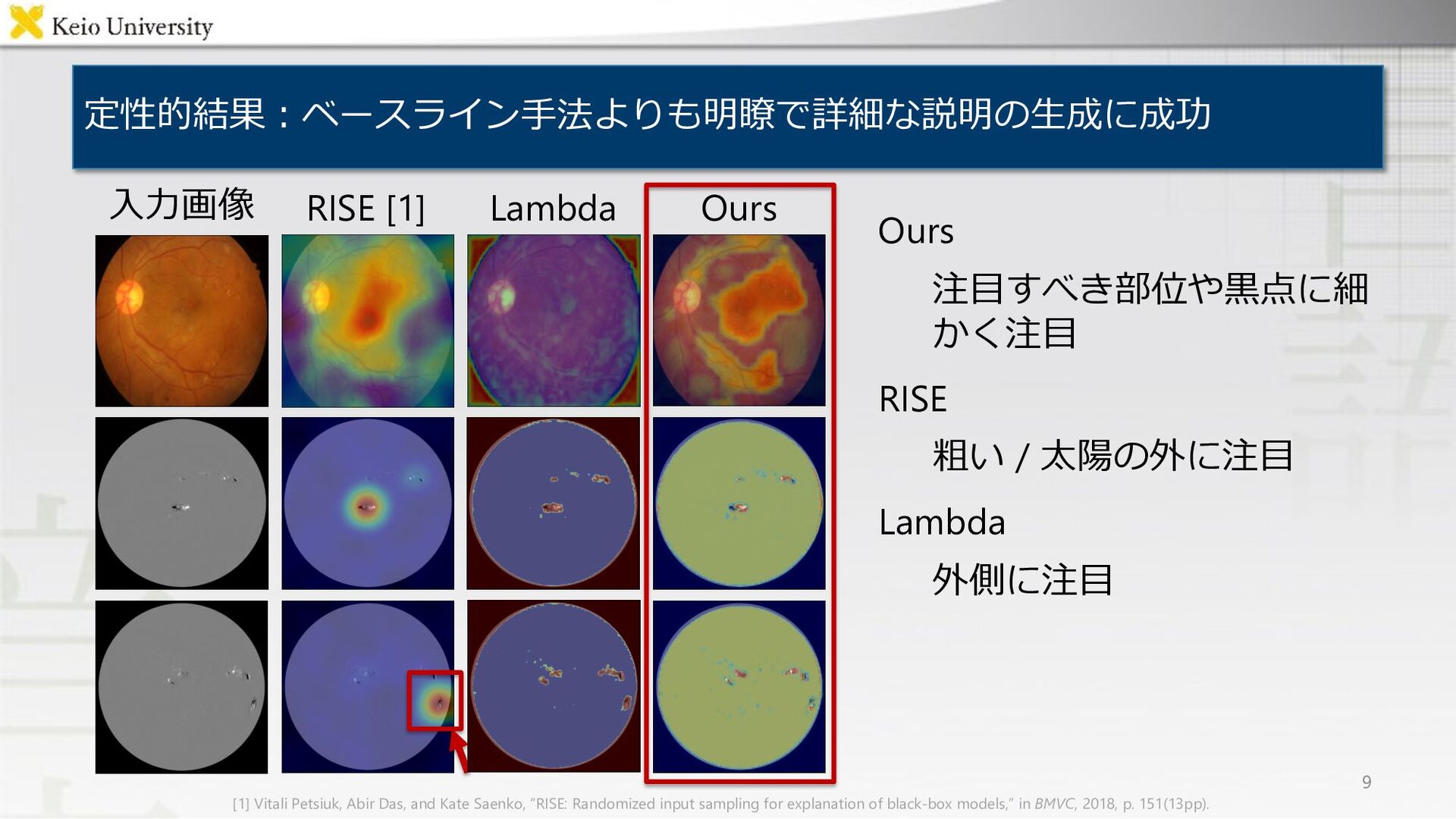
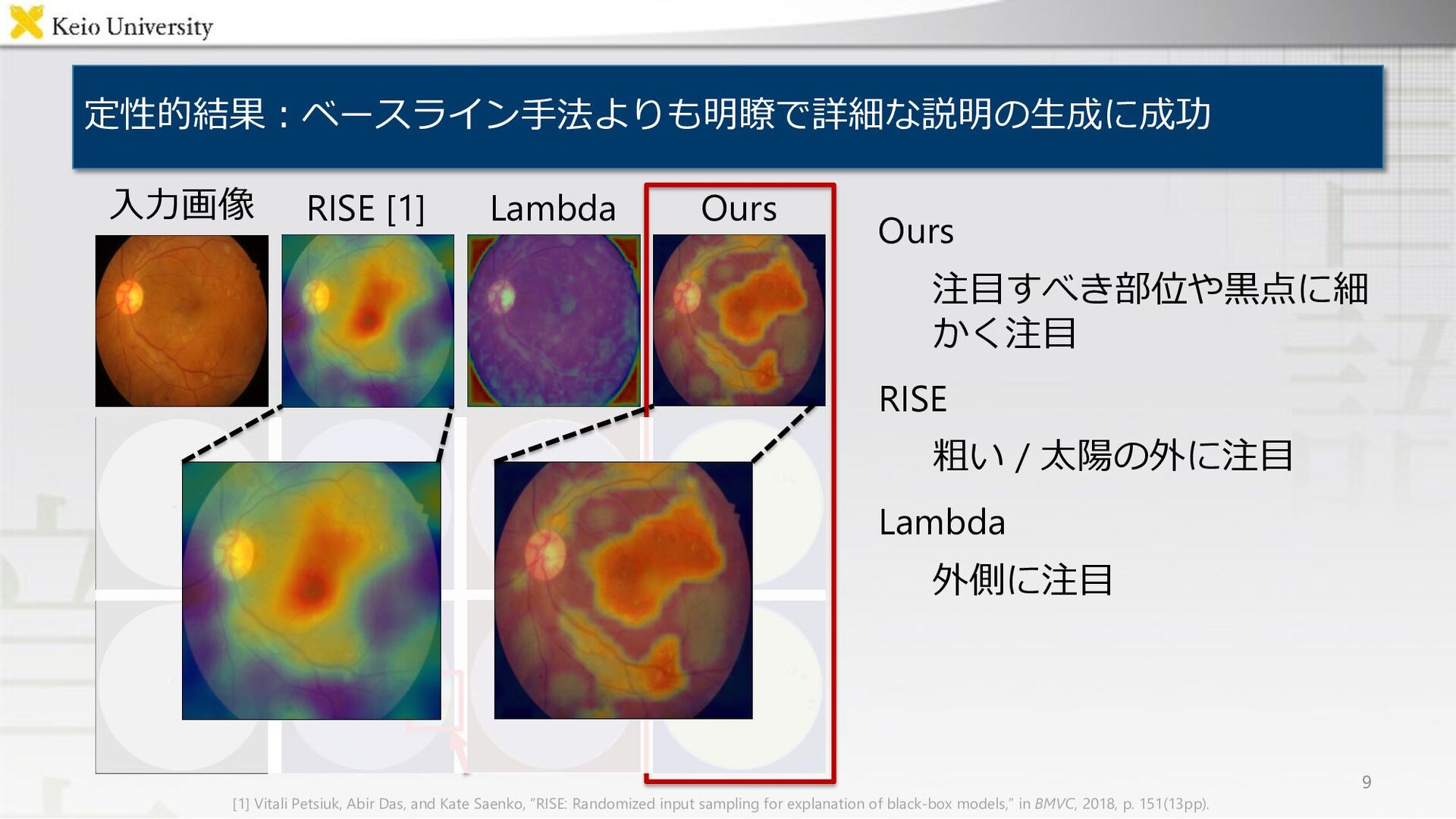
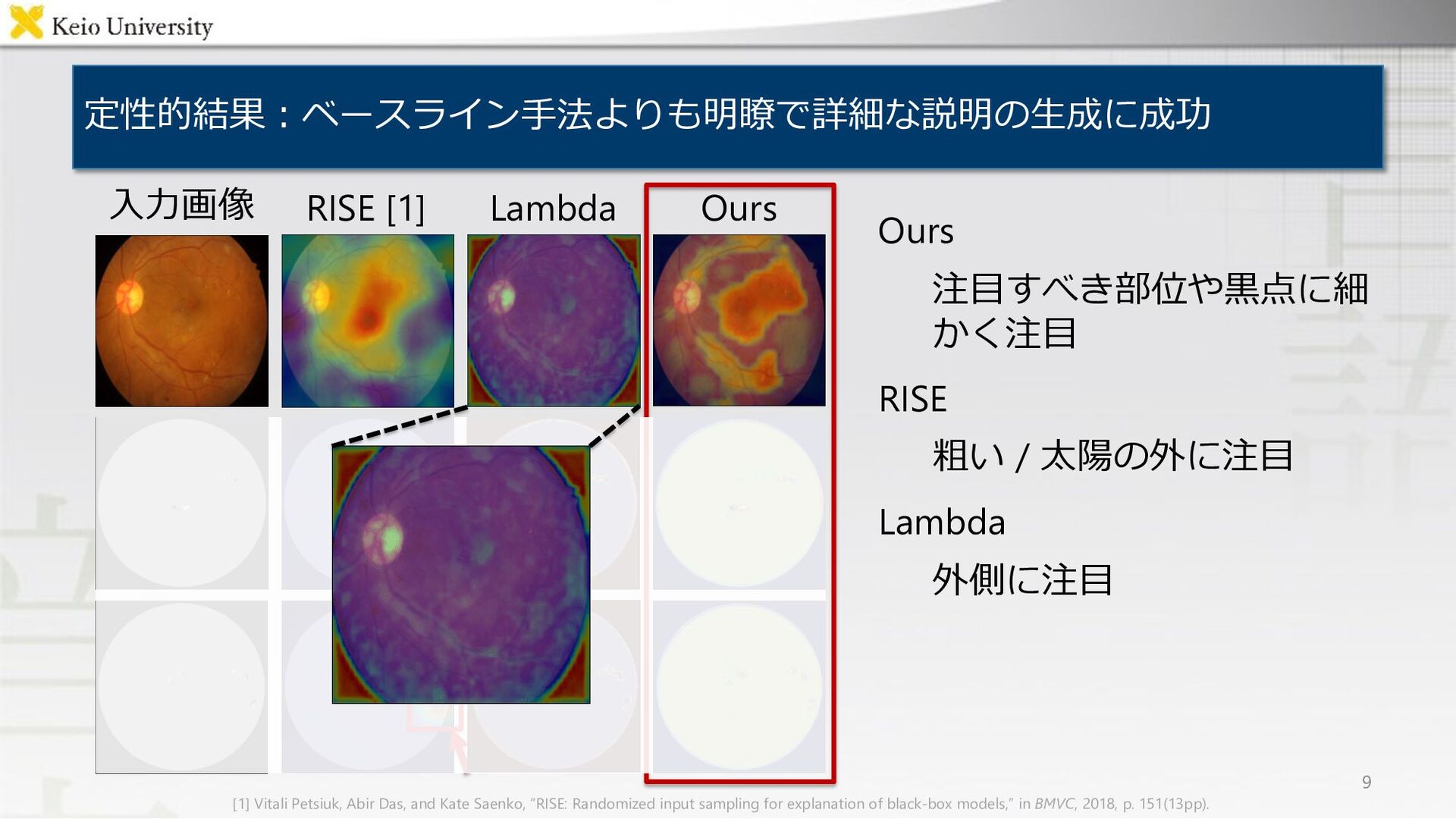
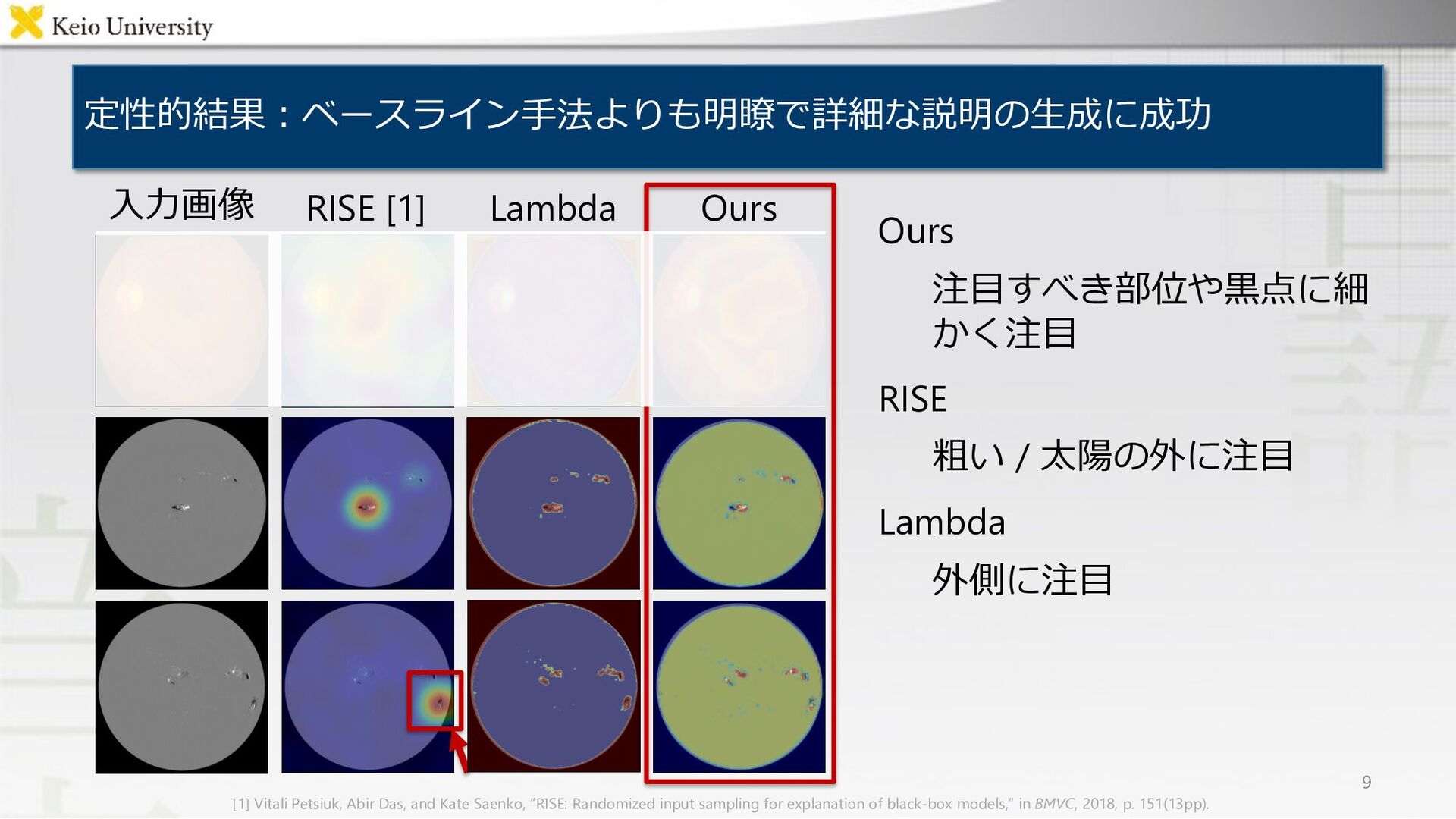
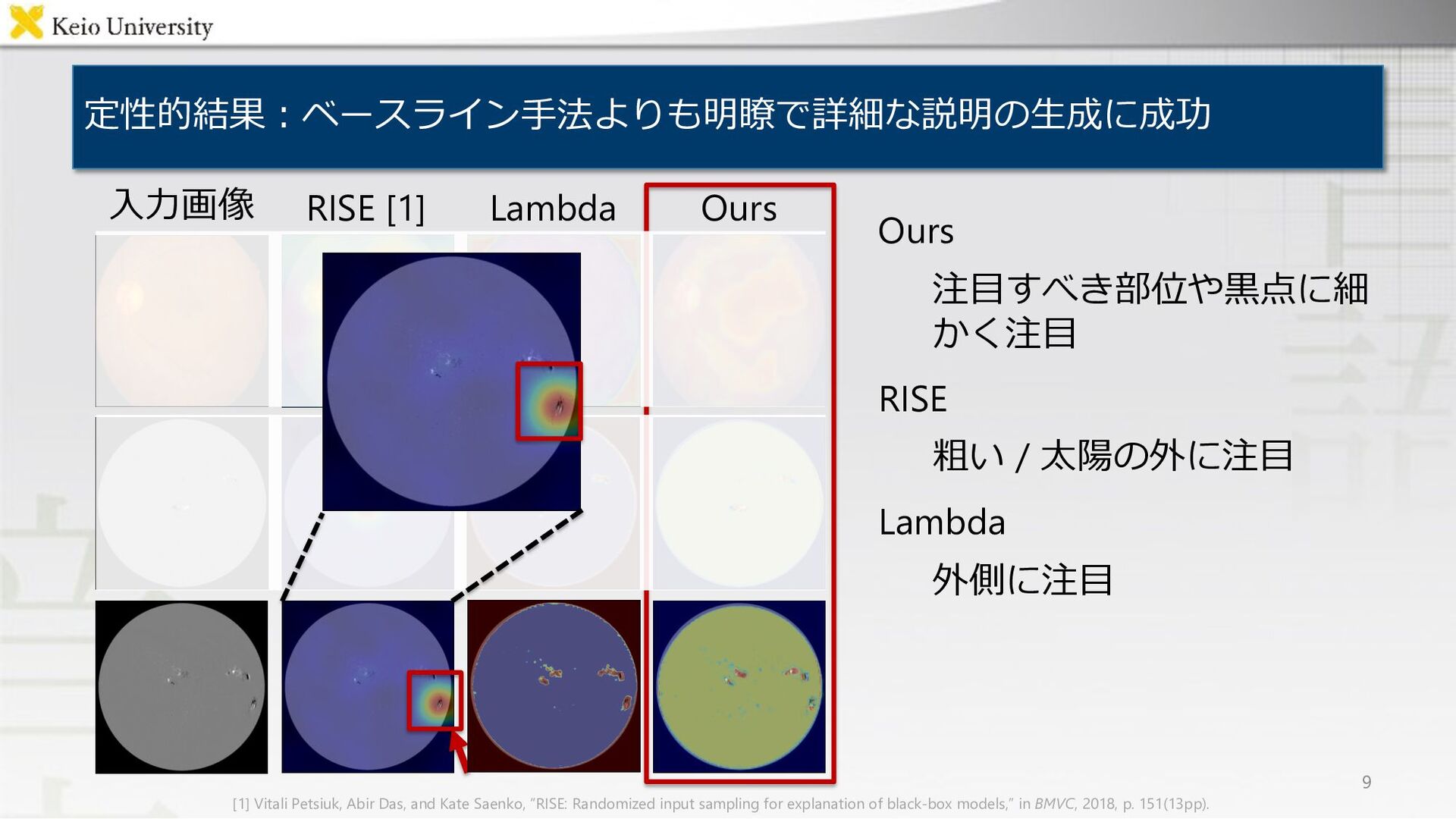
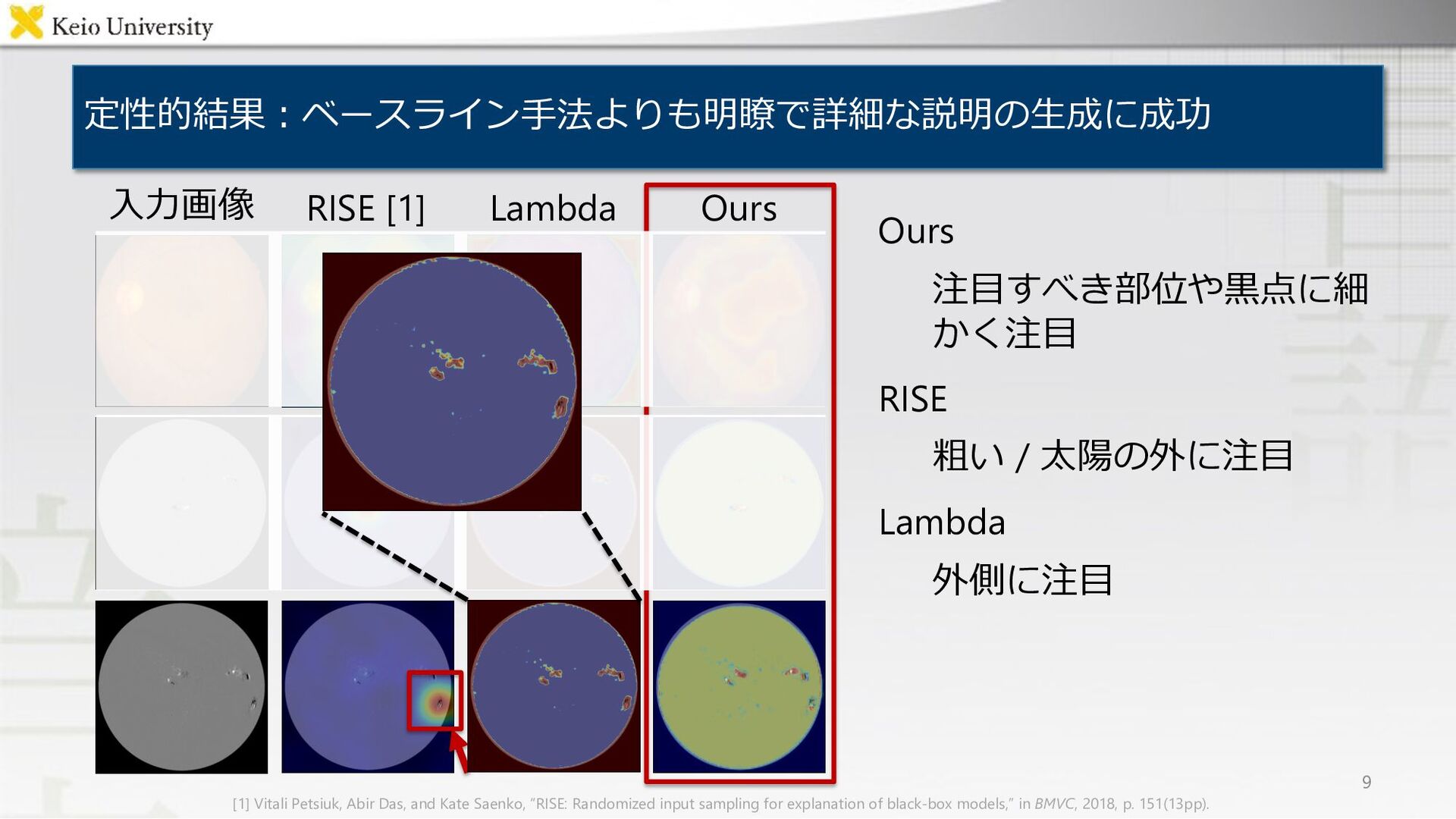
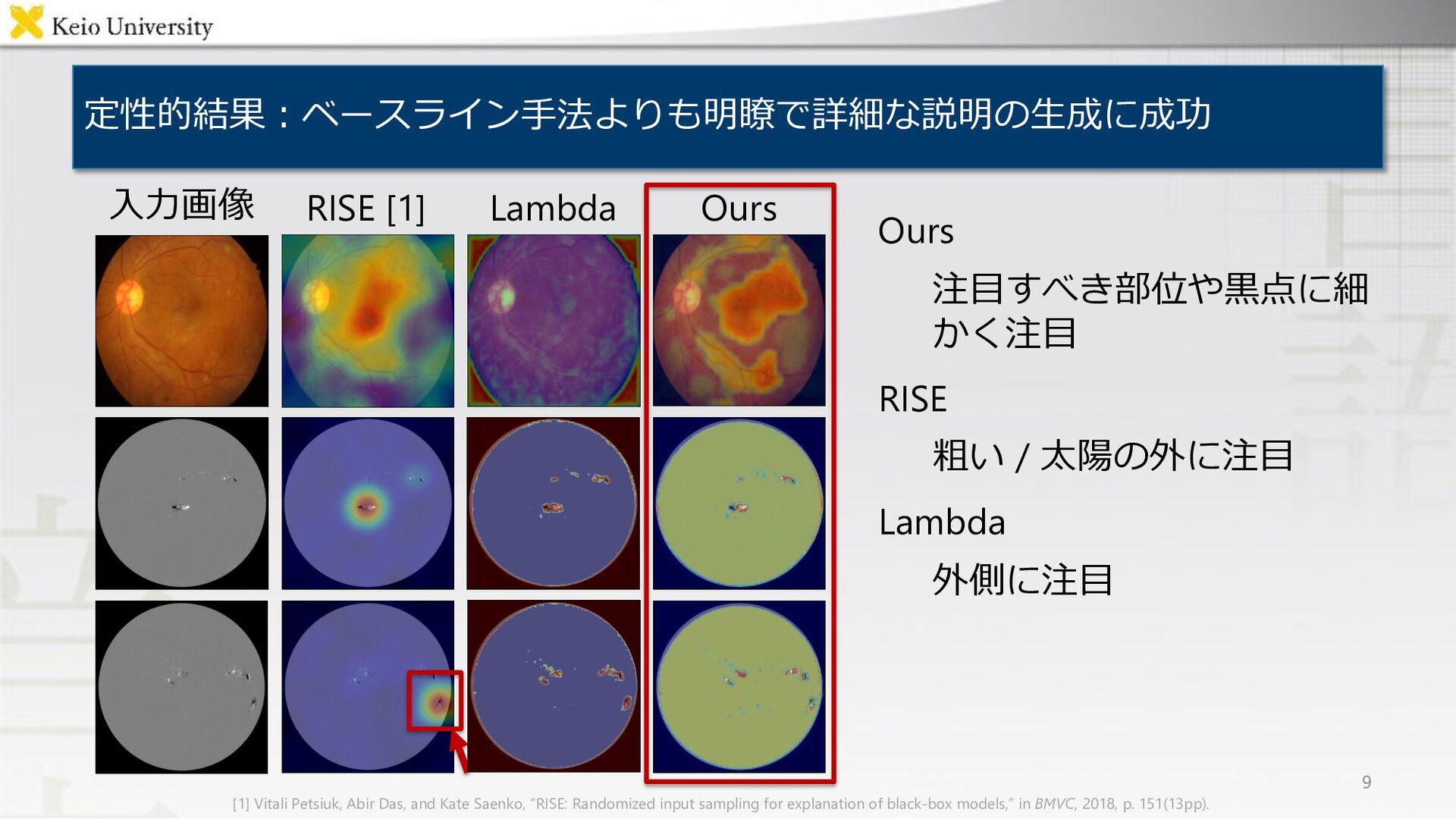
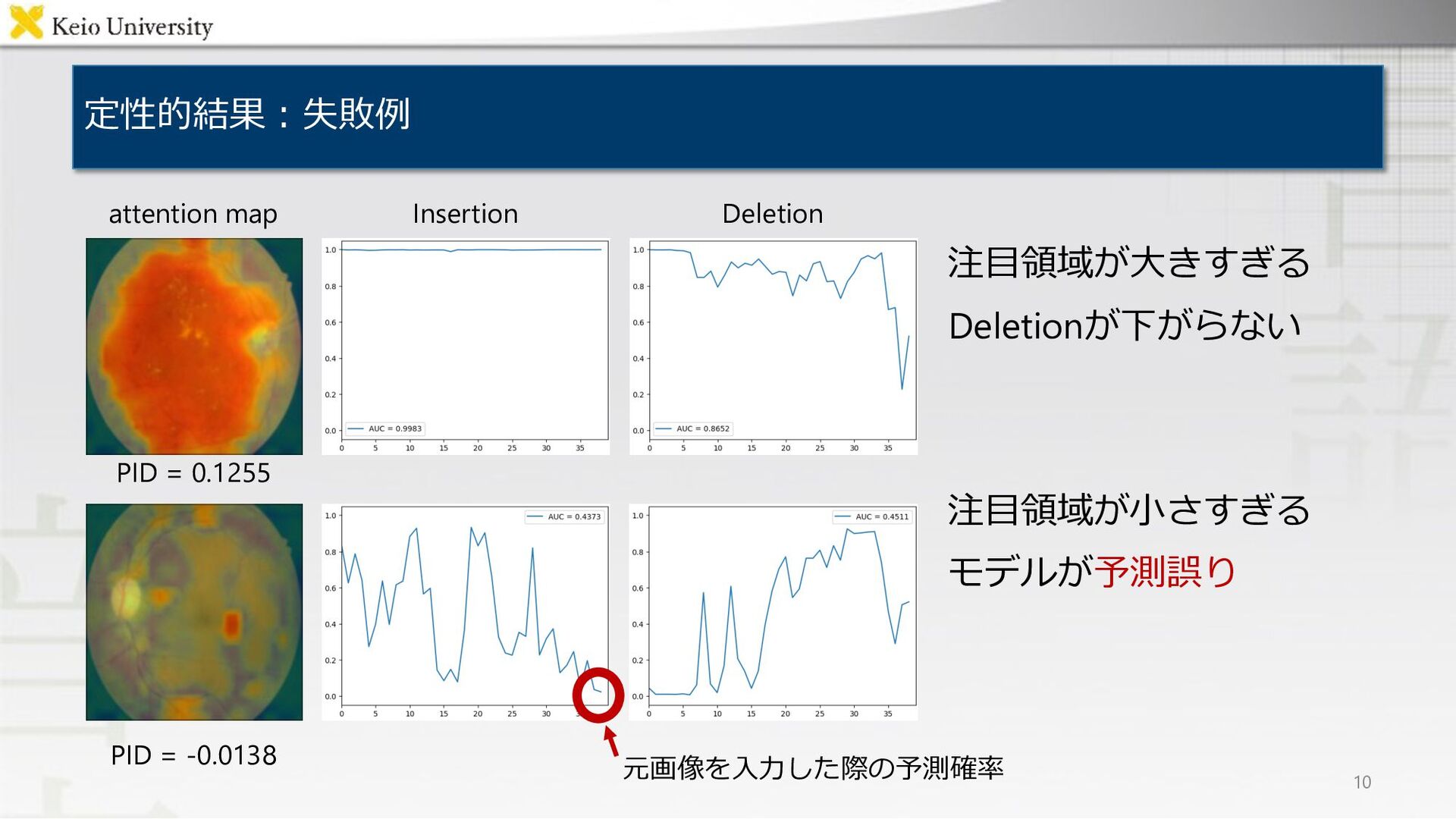
RISE [1] Lambda Ours 9 ⼊⼒画像 [1] Vitali Petsiuk, Abir Das, and Kate Saenko, “RISE: Randomized input sampling for explanation of black-box models,” in BMVC, 2018, p. 151(13pp).
RISE [1] Lambda Ours 9 ⼊⼒画像 [1] Vitali Petsiuk, Abir Das, and Kate Saenko, “RISE: Randomized input sampling for explanation of black-box models,” in BMVC, 2018, p. 151(13pp).
RISE [1] Lambda Ours 9 ⼊⼒画像 [1] Vitali Petsiuk, Abir Das, and Kate Saenko, “RISE: Randomized input sampling for explanation of black-box models,” in BMVC, 2018, p. 151(13pp).
RISE [1] Lambda Ours 9 ⼊⼒画像 [1] Vitali Petsiuk, Abir Das, and Kate Saenko, “RISE: Randomized input sampling for explanation of black-box models,” in BMVC, 2018, p. 151(13pp).
RISE [1] Lambda Ours 9 ⼊⼒画像 [1] Vitali Petsiuk, Abir Das, and Kate Saenko, “RISE: Randomized input sampling for explanation of black-box models,” in BMVC, 2018, p. 151(13pp).
RISE [1] Lambda Ours 9 ⼊⼒画像 [1] Vitali Petsiuk, Abir Das, and Kate Saenko, “RISE: Randomized input sampling for explanation of black-box models,” in BMVC, 2018, p. 151(13pp).
RISE [1] Lambda Ours 9 ⼊⼒画像 [1] Vitali Petsiuk, Abir Das, and Kate Saenko, “RISE: Randomized input sampling for explanation of black-box models,” in BMVC, 2018, p. 151(13pp).
RISE [1] Lambda Ours 9 ⼊⼒画像 [1] Vitali Petsiuk, Abir Das, and Kate Saenko, “RISE: Randomized input sampling for explanation of black-box models,” in BMVC, 2018, p. 151(13pp).
RISE [1] Lambda Ours 9 ⼊⼒画像 [1] Vitali Petsiuk, Abir Das, and Kate Saenko, “RISE: Randomized input sampling for explanation of black-box models,” in BMVC, 2018, p. 151(13pp).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![関連研究︓transformerの説明⽣成や応⽤先を考慮した説明の研究は少ない 3 Attention Branch Network [Fukui+, CVPR19] ブランチ構造によりCNNの説明を⽣成 Attention Rollout](https://files.speakerdeck.com/presentations/11b971d803064a66b8617b18f7b8f333/slide_5.jpg){kind=link}
![関連研究︓Lambda Networks [Bello+, ICLR21] 4 Lambda Layer CNNとの親和性が⾼いtransformer層 ViTより少ない計算量で 広範囲の関係を捉えることが可能](https://files.speakerdeck.com/presentations/11b971d803064a66b8617b18f7b8f333/slide_6.jpg){kind=link}
![関連研究︓Lambda Networks [Bello+, ICLR21] 4 Lambda Layer 画像特化したtransformer ViTより少ない計算量で 全ピクセル間の関係を取得可能](https://files.speakerdeck.com/presentations/11b971d803064a66b8617b18f7b8f333/slide_7.jpg){kind=link}
![関連研究︓Lambda Networks [Bello+, ICLR21] 4 Lambda Layer 画像特化したtransformer ViTより少ない計算量で 全ピクセル間の関係を取得可能](https://files.speakerdeck.com/presentations/11b971d803064a66b8617b18f7b8f333/slide_8.jpg){kind=link}
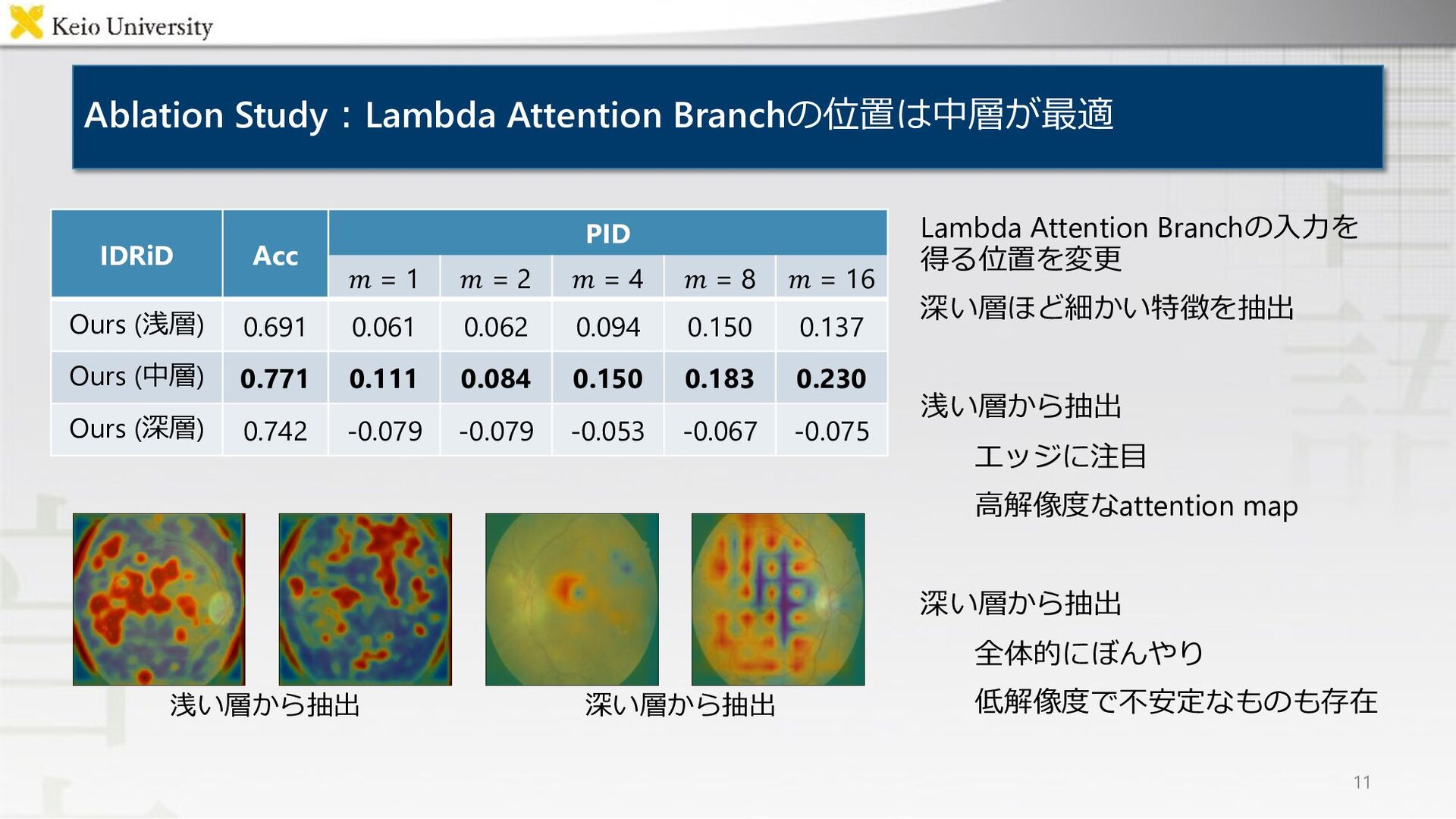
![提案⼿法①︓Lambda Attention Branch Networks 5 Lambda [Bello+, ICLR21]を基にしたtransformerの説明⽣成 Lambda Attention](https://files.speakerdeck.com/presentations/11b971d803064a66b8617b18f7b8f333/slide_9.jpg){kind=link}
![提案⼿法①︓Lambda Attention Branch Networks 5 Lambda [Bello+, ICLR21]を基にしたtransformerの説明⽣成 Lambda Attention](https://files.speakerdeck.com/presentations/11b971d803064a66b8617b18f7b8f333/slide_10.jpg){kind=link}
![提案⼿法①︓Lambda Attention Branch Networks 5 Lambda [Bello+, ICLR21]を基にしたtransformerの説明⽣成 Lambda Attention](https://files.speakerdeck.com/presentations/11b971d803064a66b8617b18f7b8f333/slide_11.jpg){kind=link}
![提案⼿法①︓Lambda Attention Branch Networks 5 Lambda [Bello+, ICLR21]を基にしたtransformerの説明⽣成 Lambda Attention](https://files.speakerdeck.com/presentations/11b971d803064a66b8617b18f7b8f333/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}