4.0 International Public License ( CC BY-NC-SA 4.0 ) 問題設定: 目標領域を予測する移動指示理解タスク ▪ 対象タスク:Referring Navigable Regions (RNR) タスク ▪ モビリティに対して、移動指示文が 指している目標領域を予測 ▪ 入力 ▪ 画像 ▪ 移動指示文 ▪ 出力 ▪ 目標領域のセグメンテーションマスク “pull in behind the blue van on the left side.” - 4 - the blue van
{kind=link}
{kind=link}
![関連研究: 移動指示理解タスクにおいて、目標位置や領域 予測モデルとして広く研究が行われている 代表的手法 概要 [Rufus+, IROS21] 目標領域のセグメンテーションマスク を生成するモデル PDPC](https://files.speakerdeck.com/presentations/1212fbb2321a4c76979abc4e0239780a/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
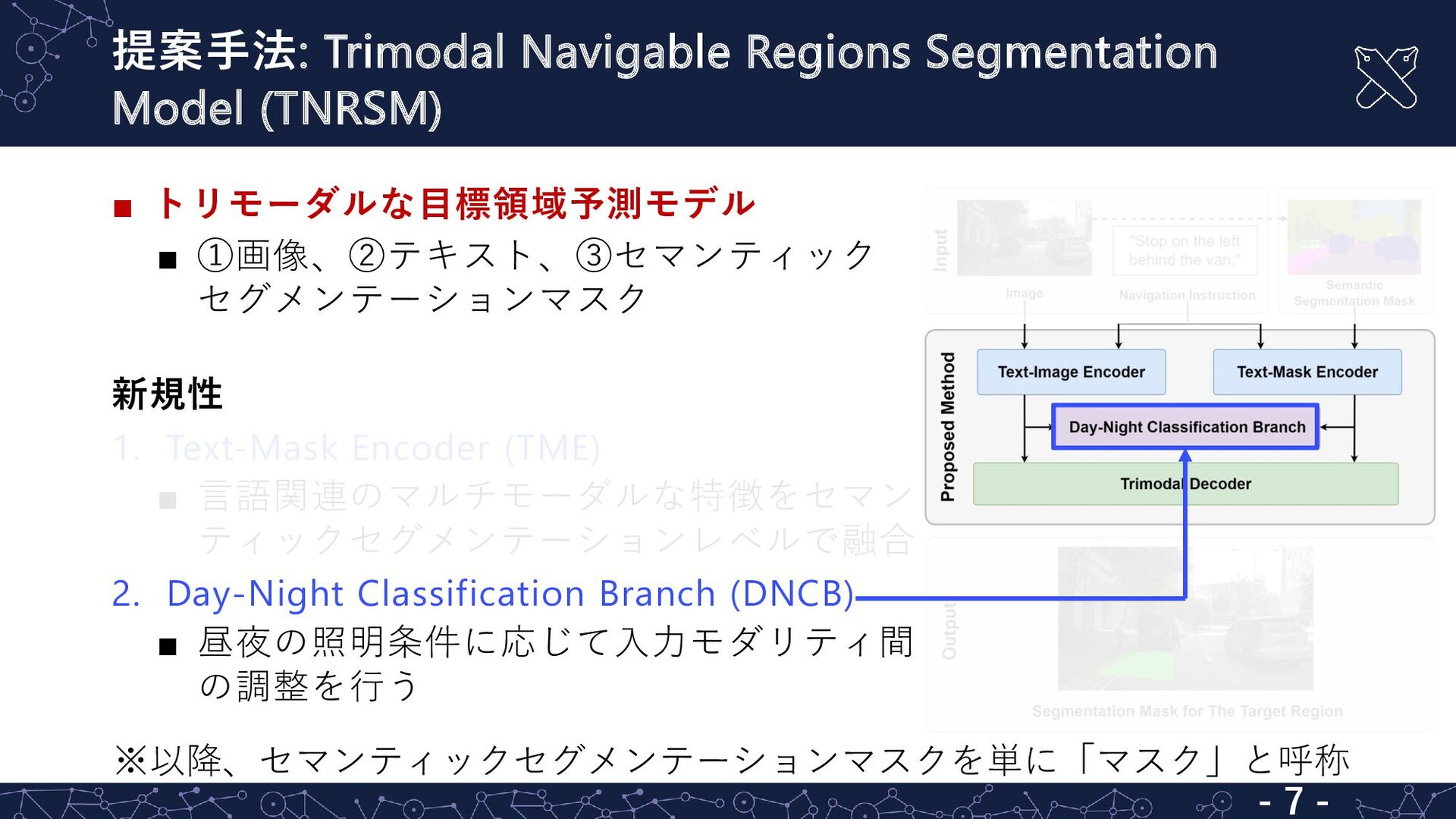{kind=link}
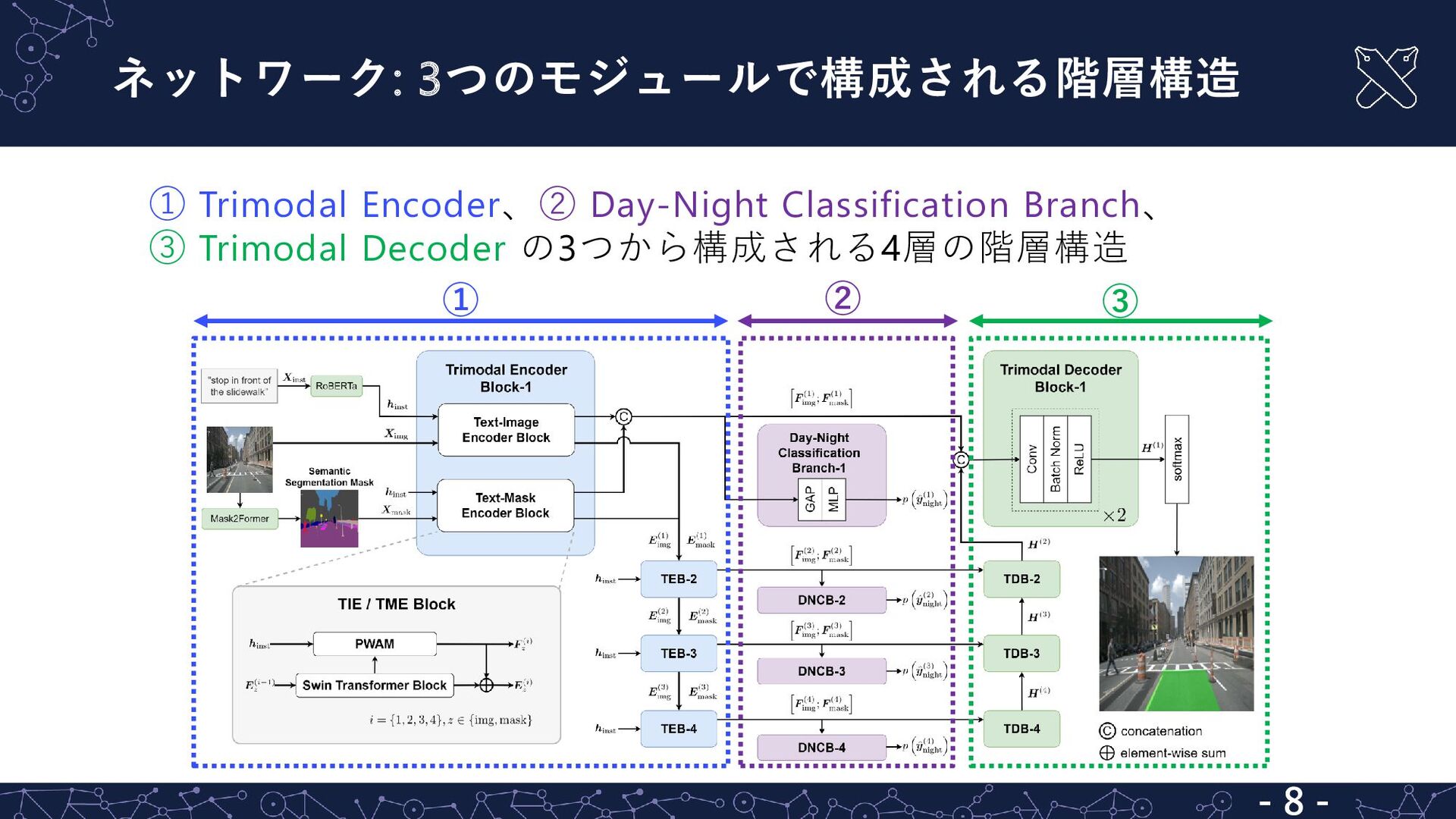{kind=link}
![Mask2Formerを用いて、画像からゼロショットで セマンティックセグメンテーションマスクを生成 セマンティック セグメンテーションマスク Mask2Former [Cheng+, CVPR22] RGB画像 ▪ Mask2Former](https://files.speakerdeck.com/presentations/1212fbb2321a4c76979abc4e0239780a/slide_8.jpg){kind=link}
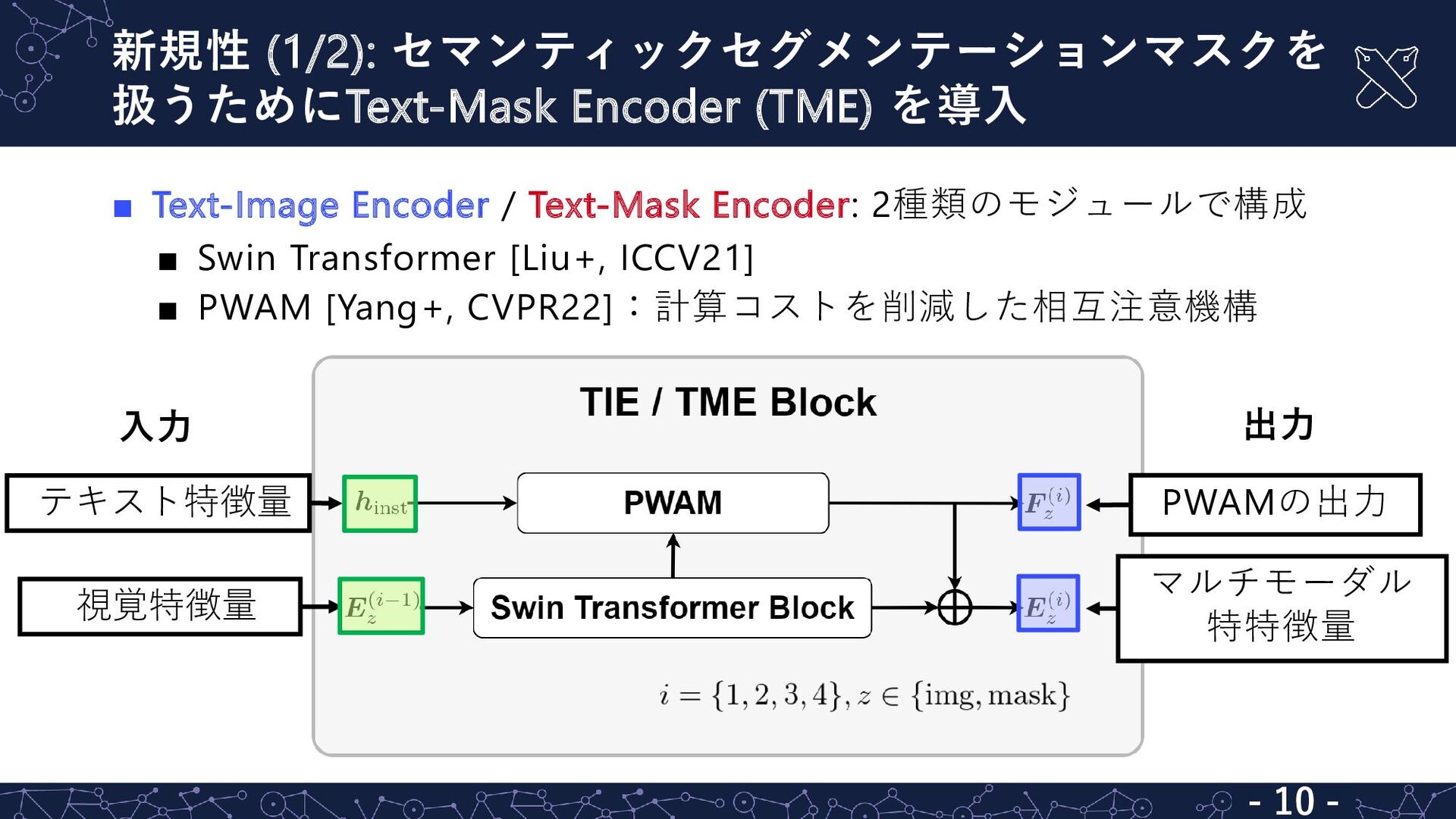{kind=link}
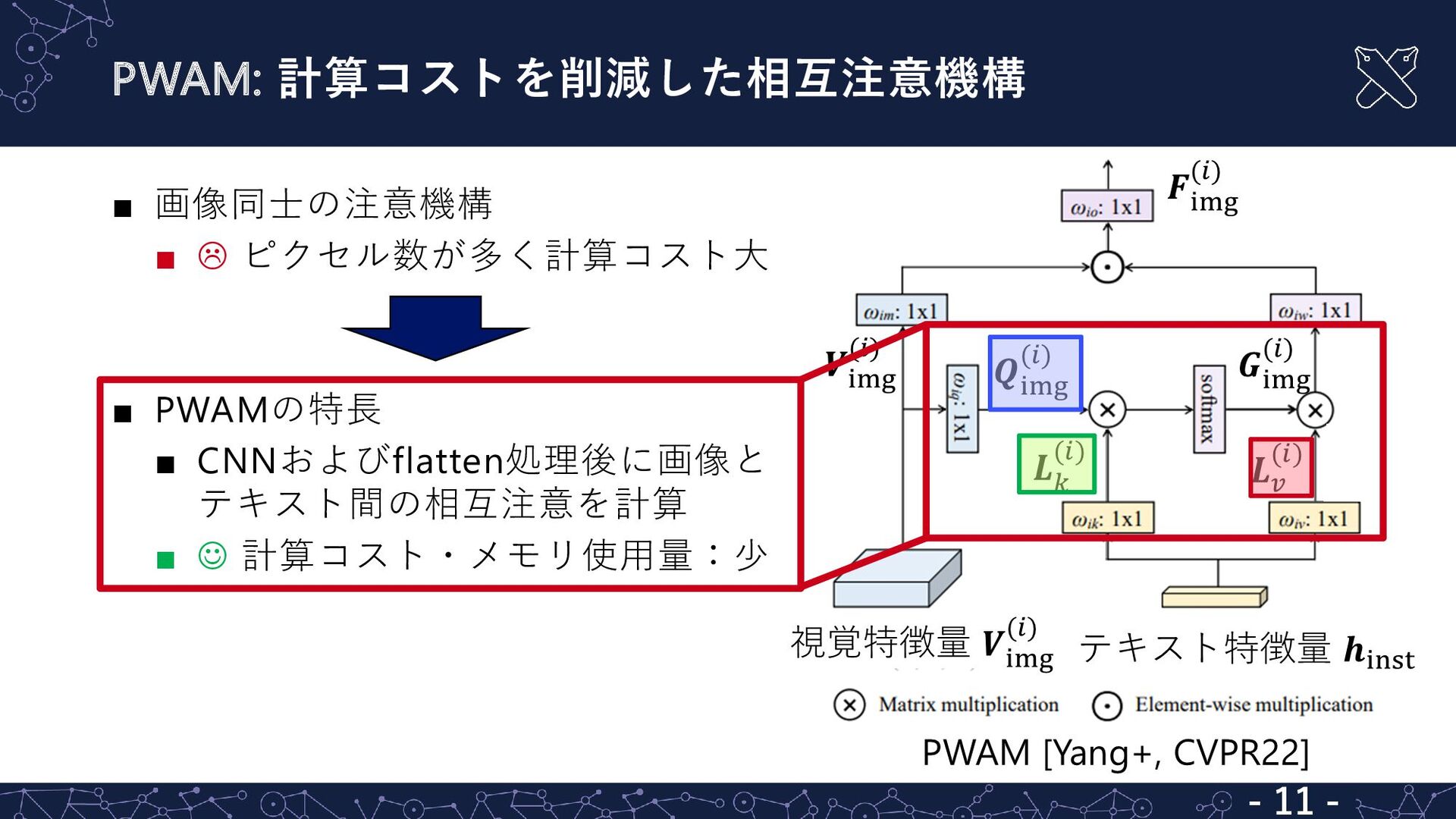{kind=link}
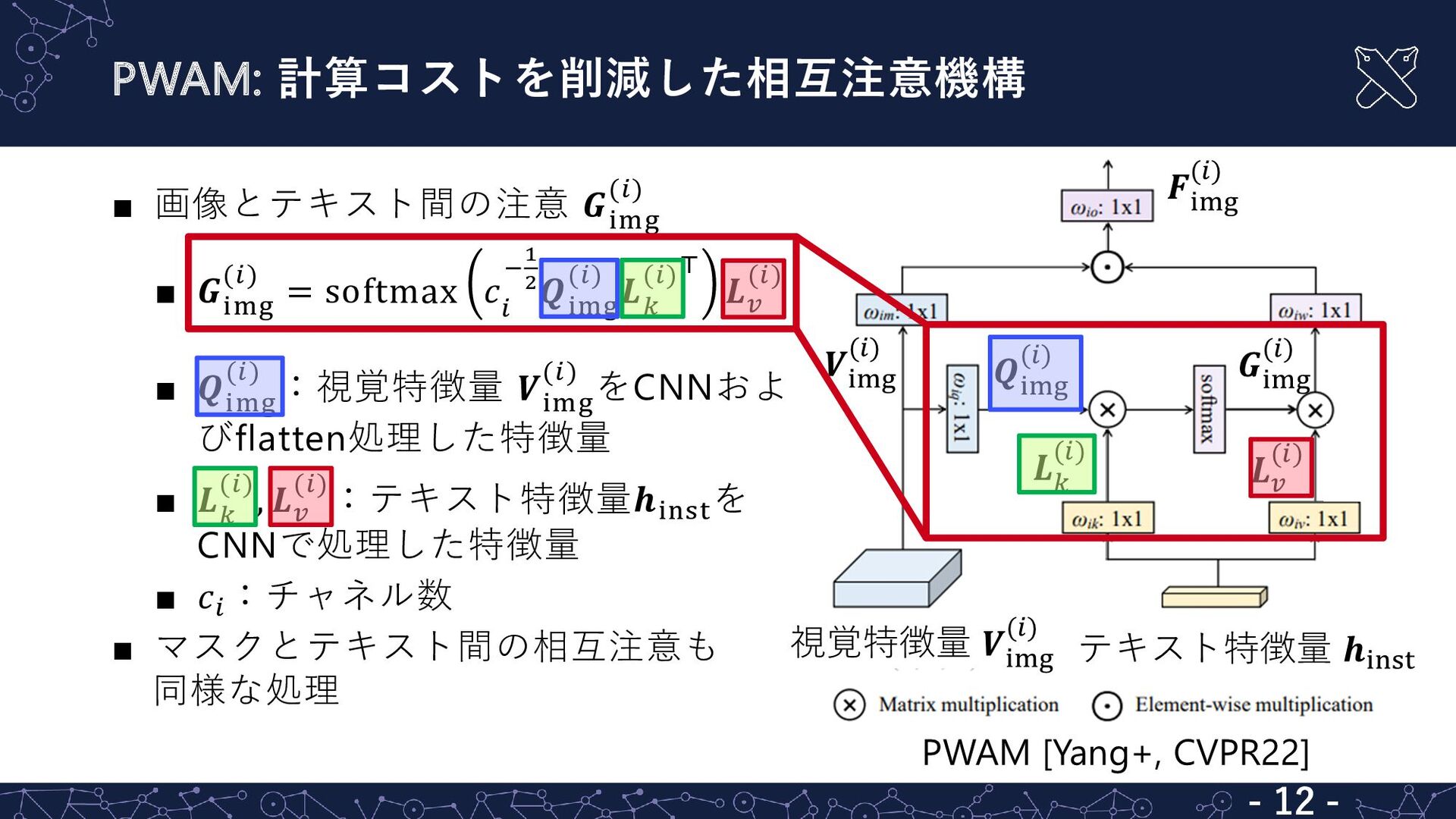{kind=link}
{kind=link}
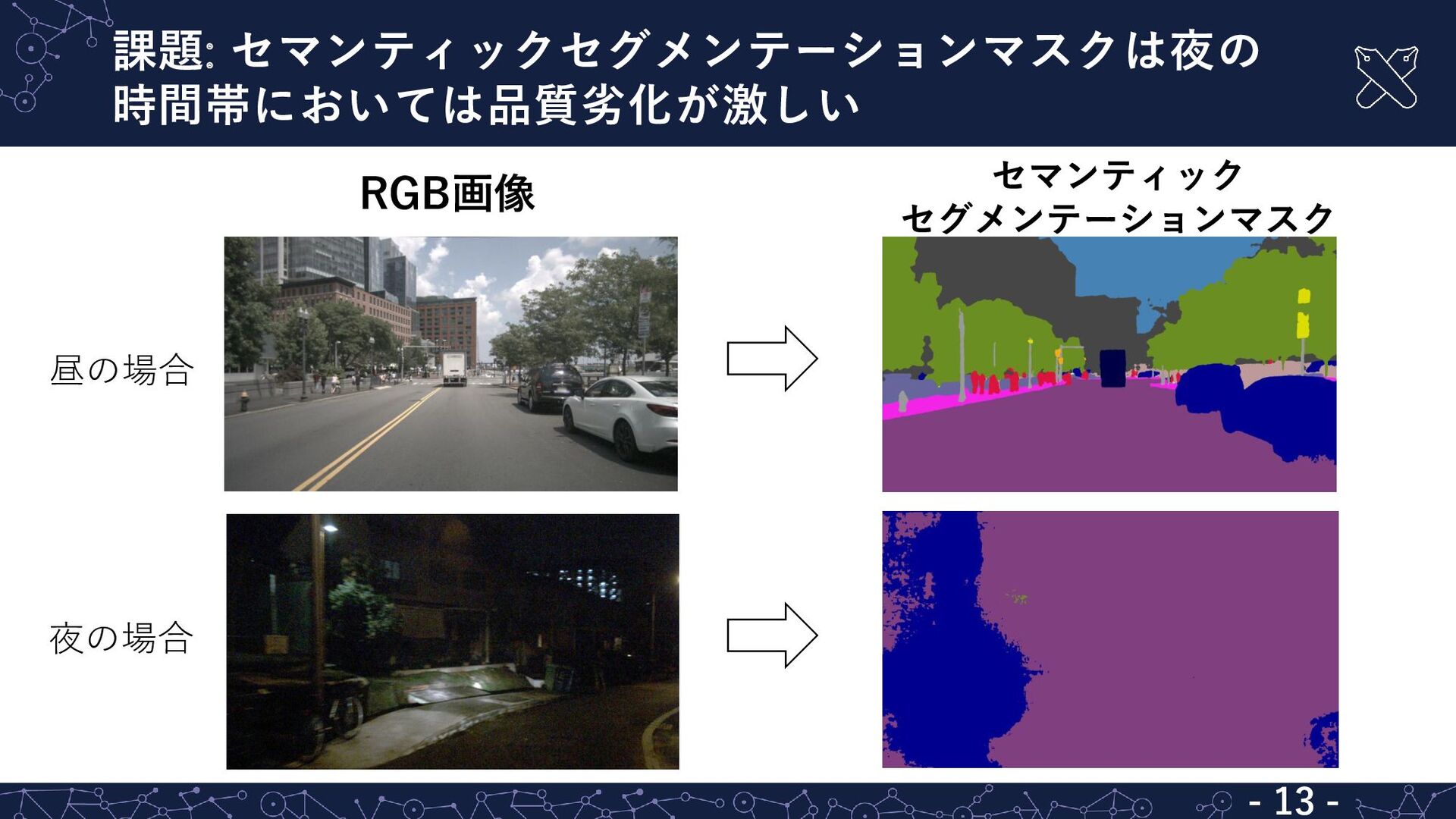
{kind=link}
{kind=link}
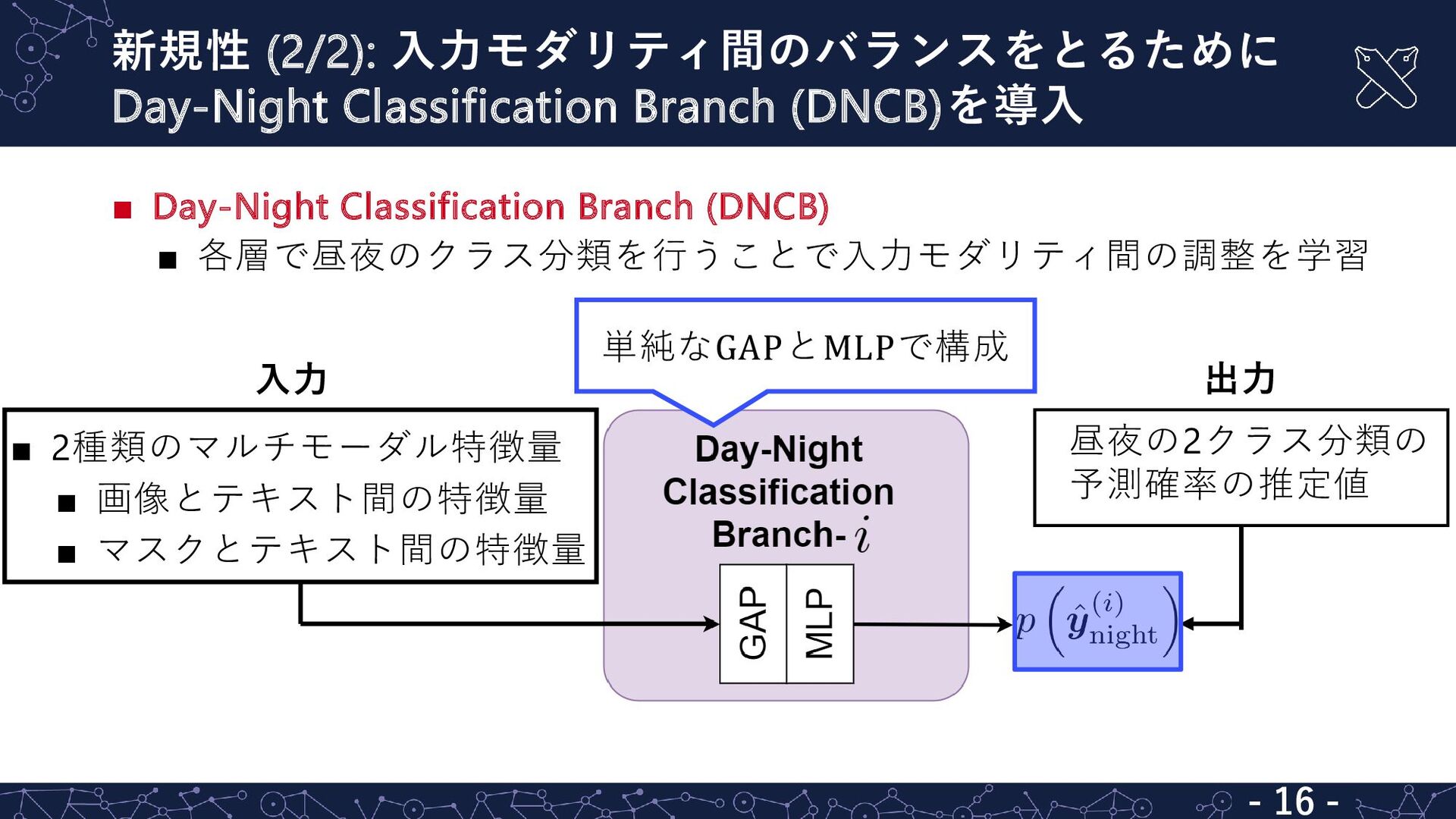{kind=link}
{kind=link}
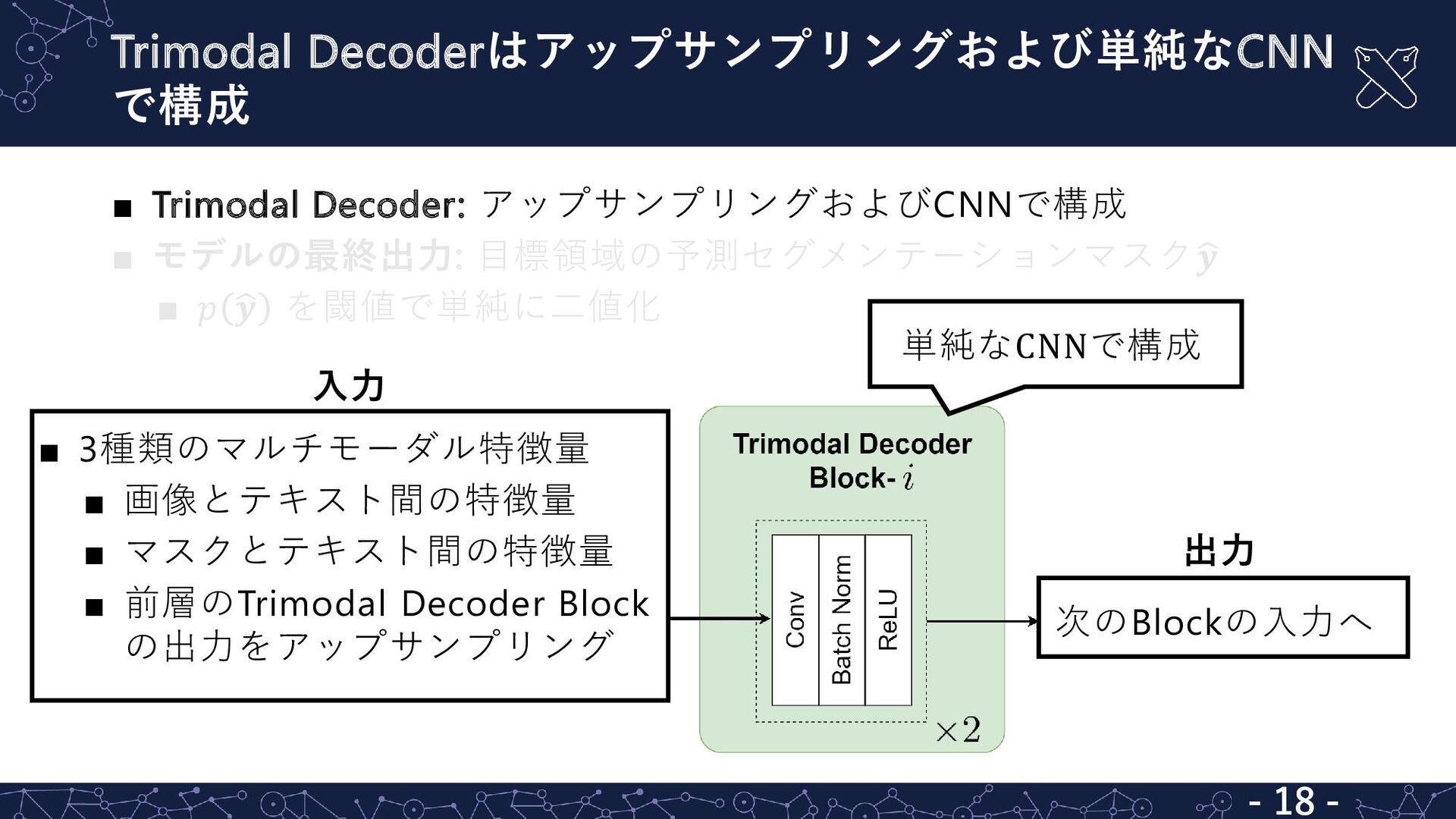{kind=link}
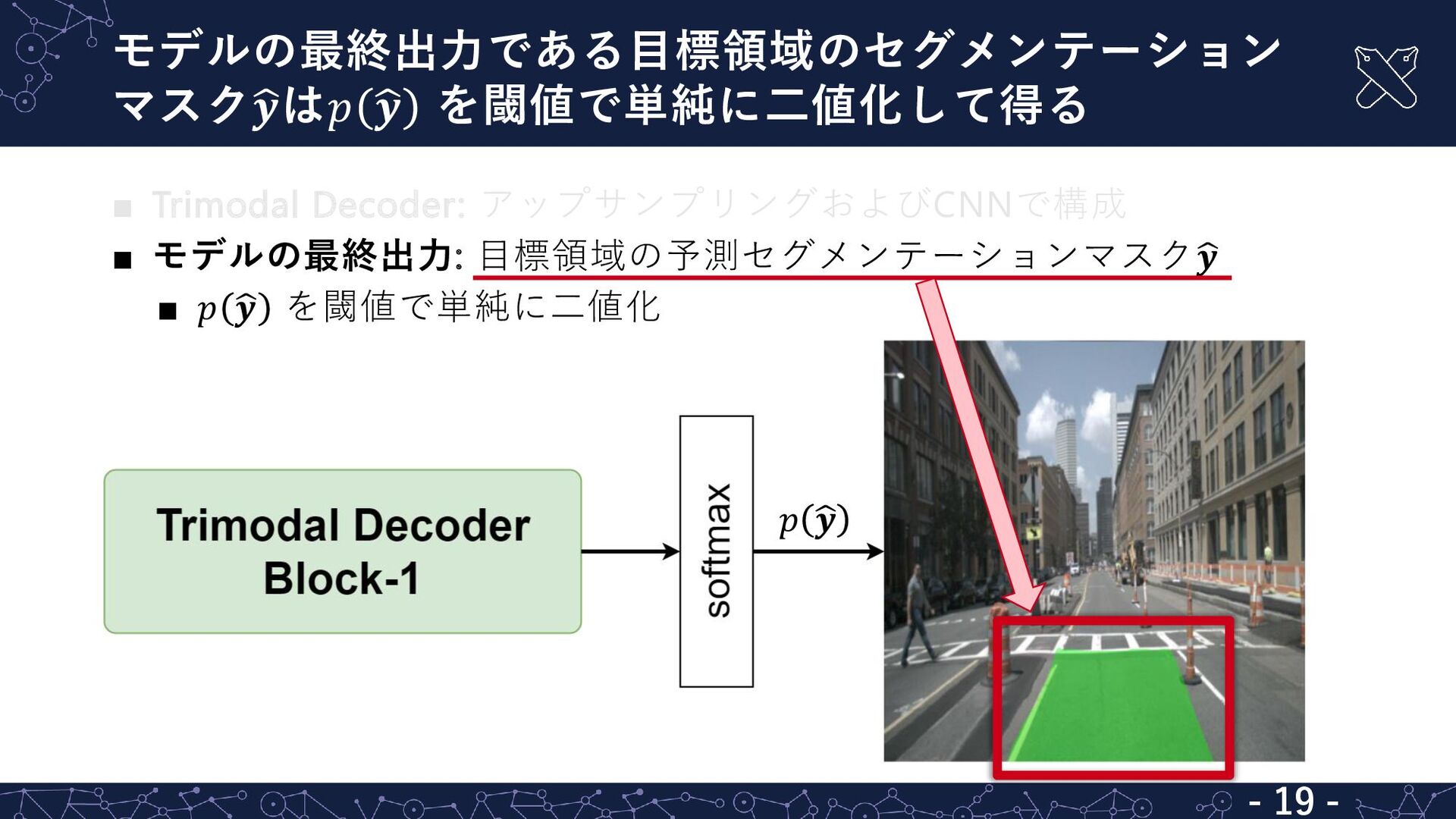{kind=link}
{kind=link}
![実験設定: nuScenesデータセットで提供されている 昼夜情報をTalk2Car-RegSegデータセットに適用 ▪ Talk2Car-RegSeg [Rufus+, IROS21] ▪ 画像と移動指示文から目標領域の セグメンテーションマスクを生成](https://files.speakerdeck.com/presentations/1212fbb2321a4c76979abc4e0239780a/slide_20.jpg){kind=link}
![定量的結果: 既存手法を上回る性能を獲得 ▪ 評価尺度:3種類 ▪ Mean IoU、Overall IoU、[email protected] ▪ ☺](https://files.speakerdeck.com/presentations/1212fbb2321a4c76979abc4e0239780a/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
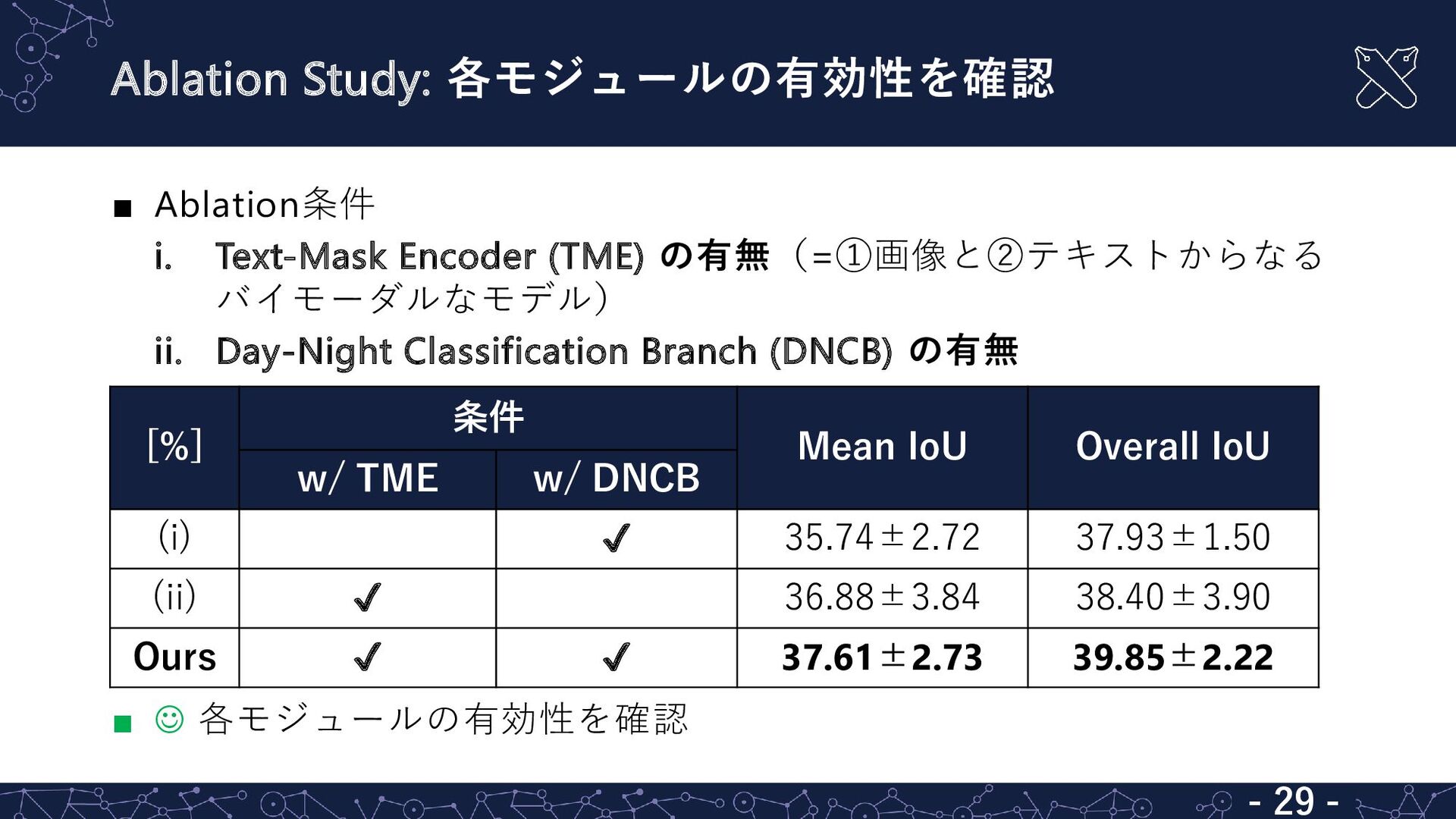{kind=link}
{kind=link}
{kind=link}
{kind=link}