estimating regression. Theory of Probability & Its Applications, 9(1), 141–142. 2. Watson, G. S. (1964). Smooth regression analysis. Sankhyā: The Indian Journal of Statistics, Series A, pp. 359–372. 3. Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., ... & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929. 4. Fukui, H., Hirakawa, T., Yamashita, T., & Fujiyoshi, H. (2019). Attention branch network: Learning of attention mechanism for visual explanation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 10705-10714). 5. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
![情報工学科 教授 杉浦孔明 [email protected] 慶應義塾大学理工学部 機械学習基礎 第11回 注意機構とトランスフォーマー](https://files.speakerdeck.com/presentations/7f88bb8c5b1e475bbe637e6b6dc754aa/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
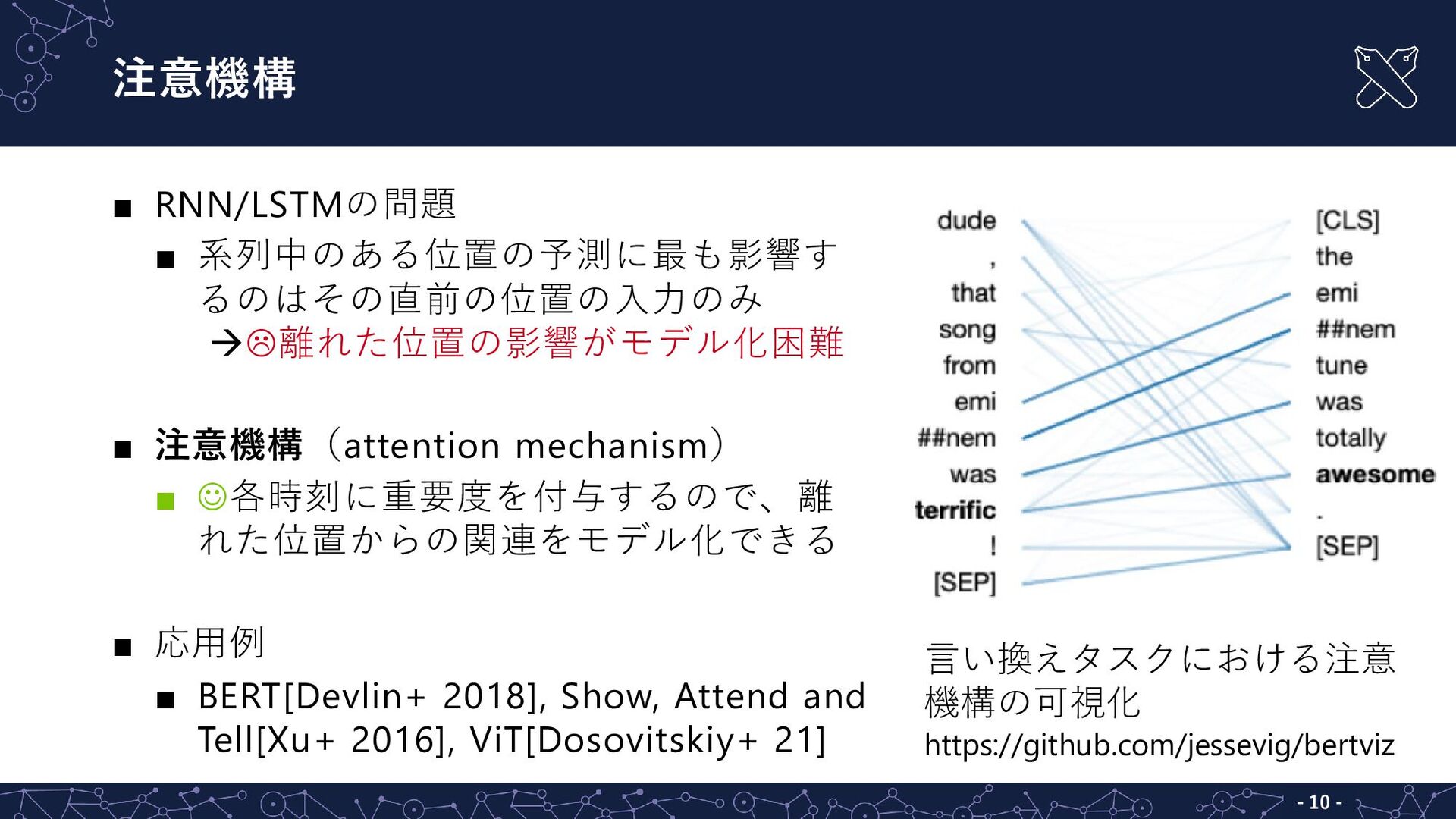{kind=link}
![注意機構の例 - - 11 ▪ BERTにおける単語予測 https://github.com/jessevig/bertviz ▪ 画像キャプショニング[Xu+ 2016]](https://files.speakerdeck.com/presentations/7f88bb8c5b1e475bbe637e6b6dc754aa/slide_5.jpg){kind=link}
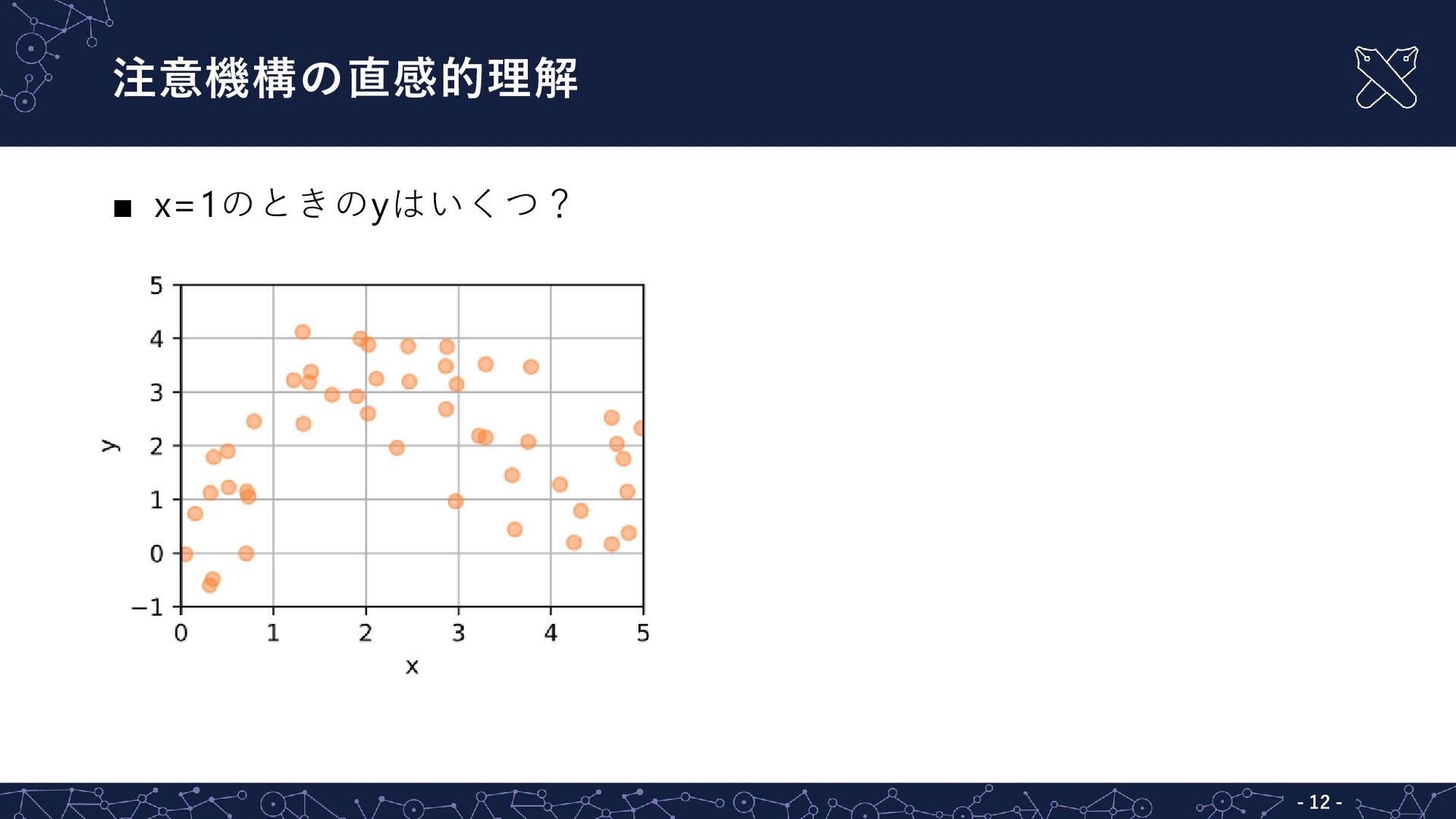{kind=link}
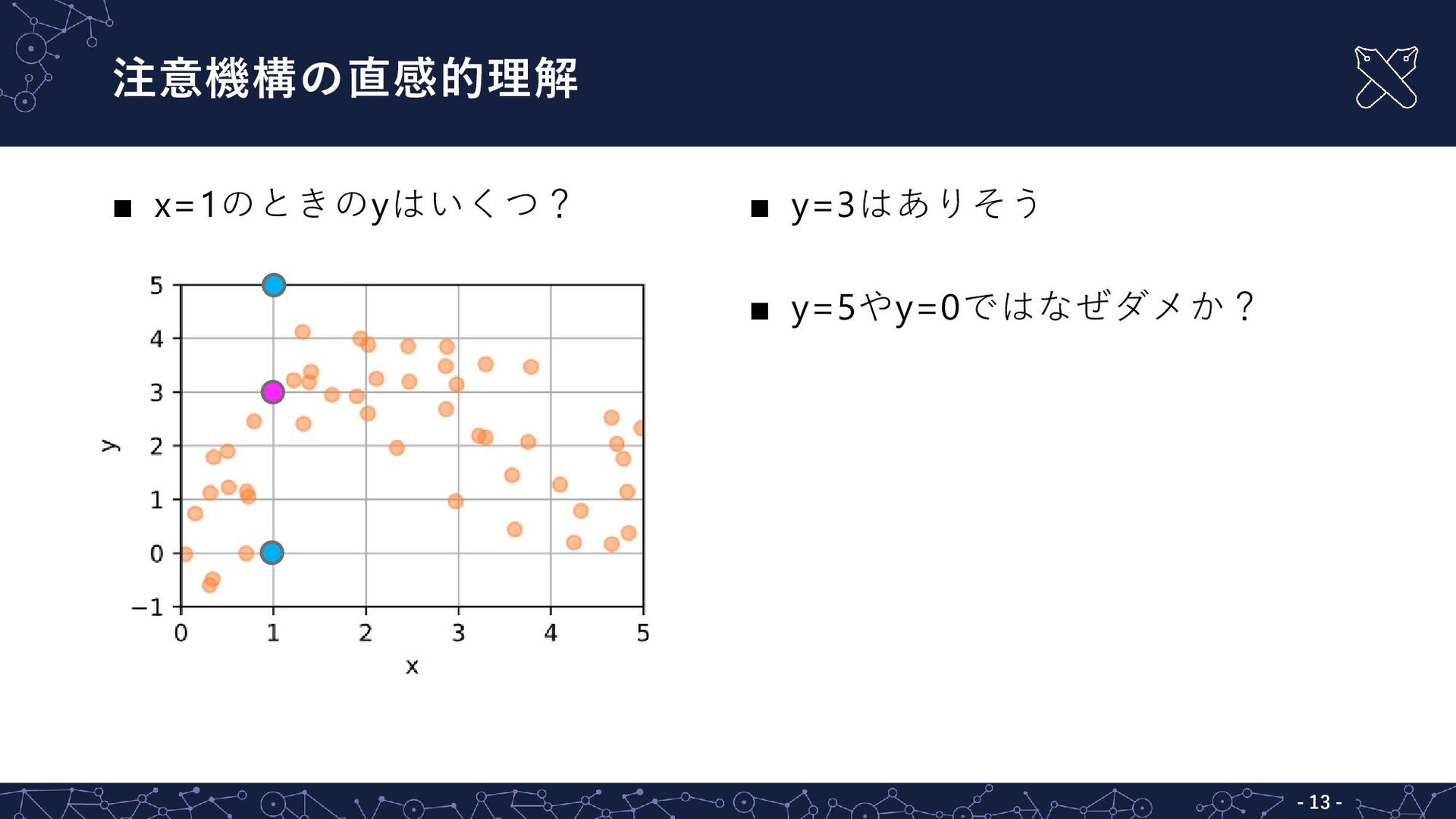{kind=link}
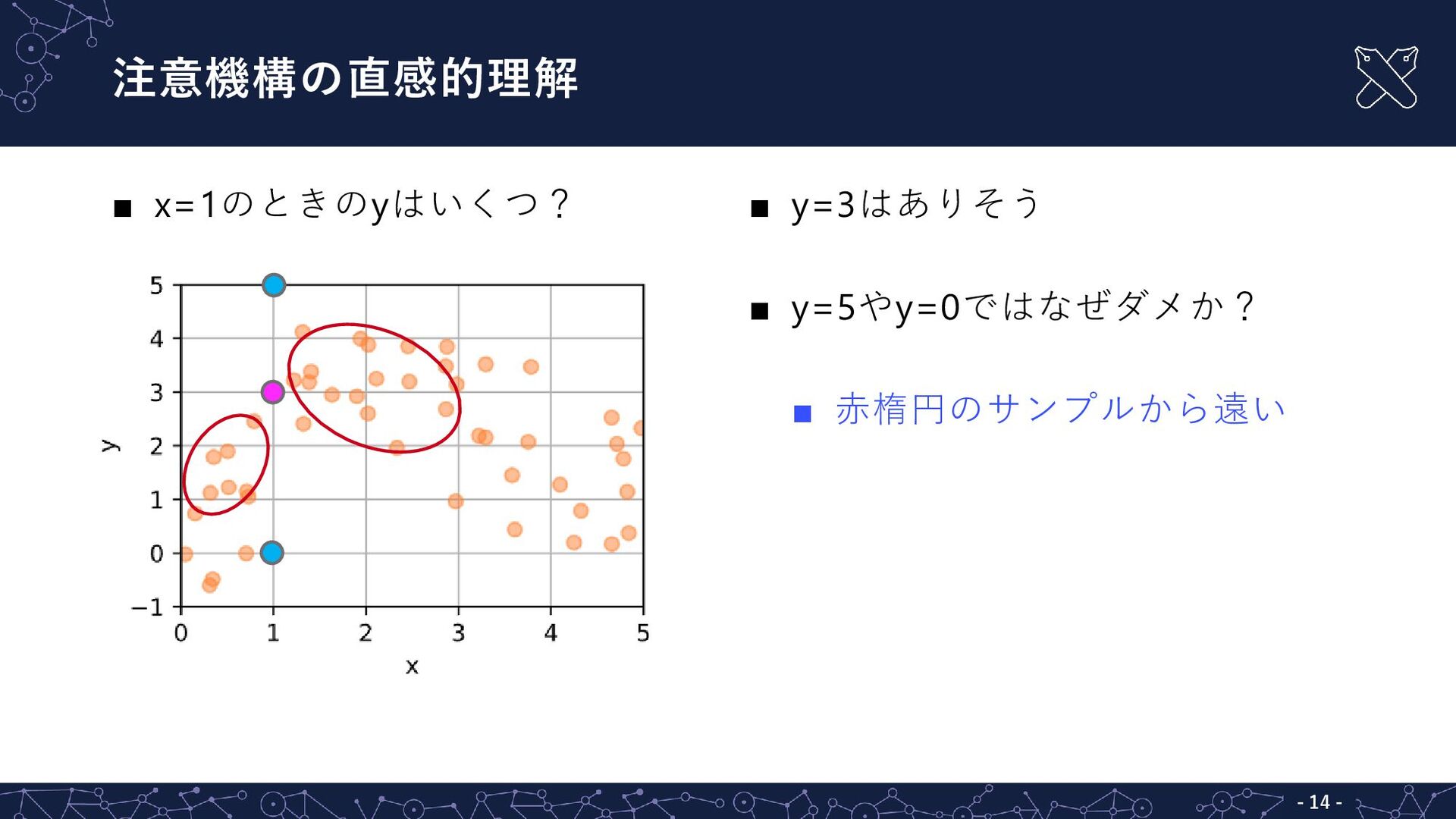{kind=link}
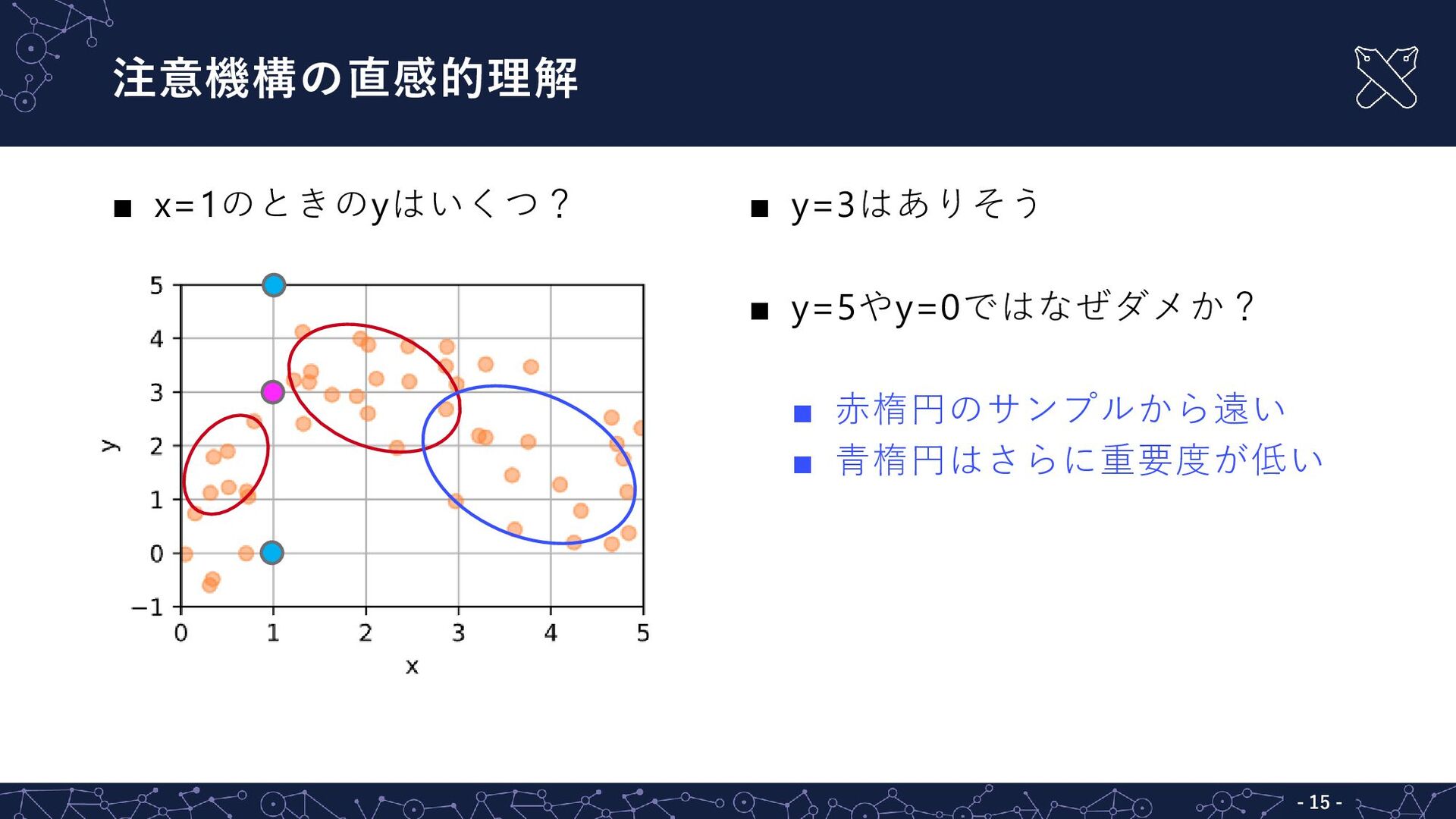{kind=link}
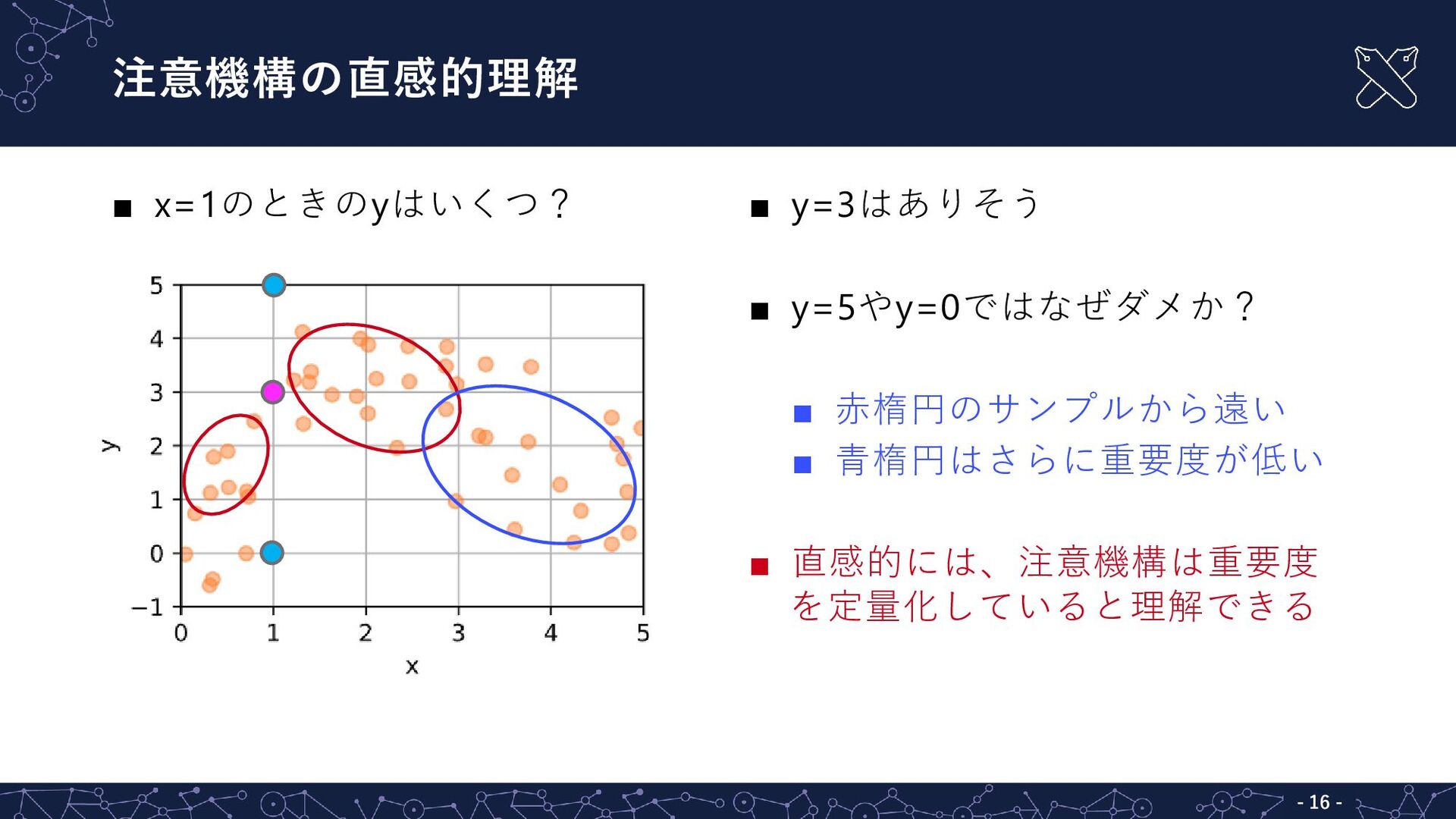{kind=link}
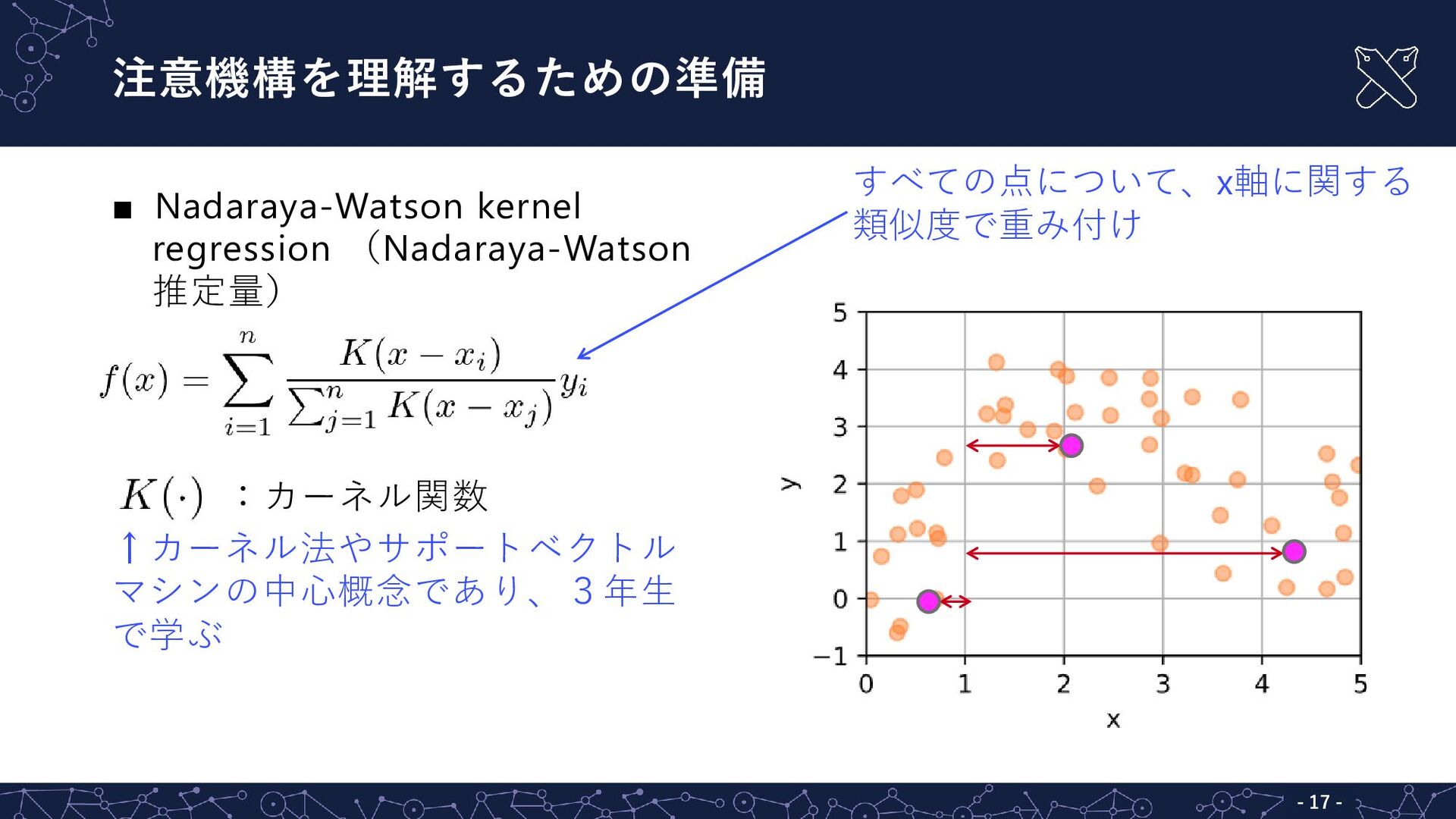{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
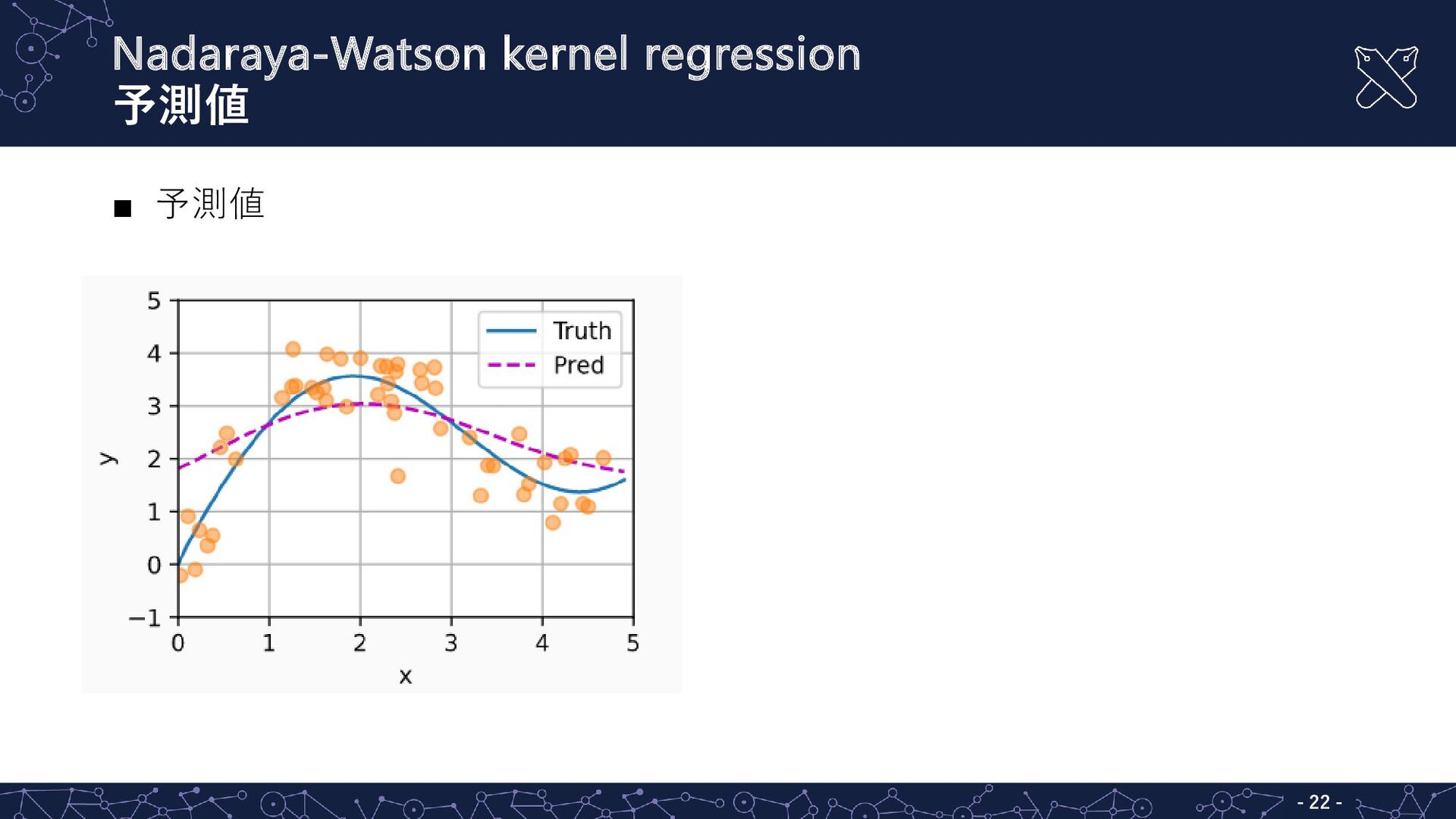{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
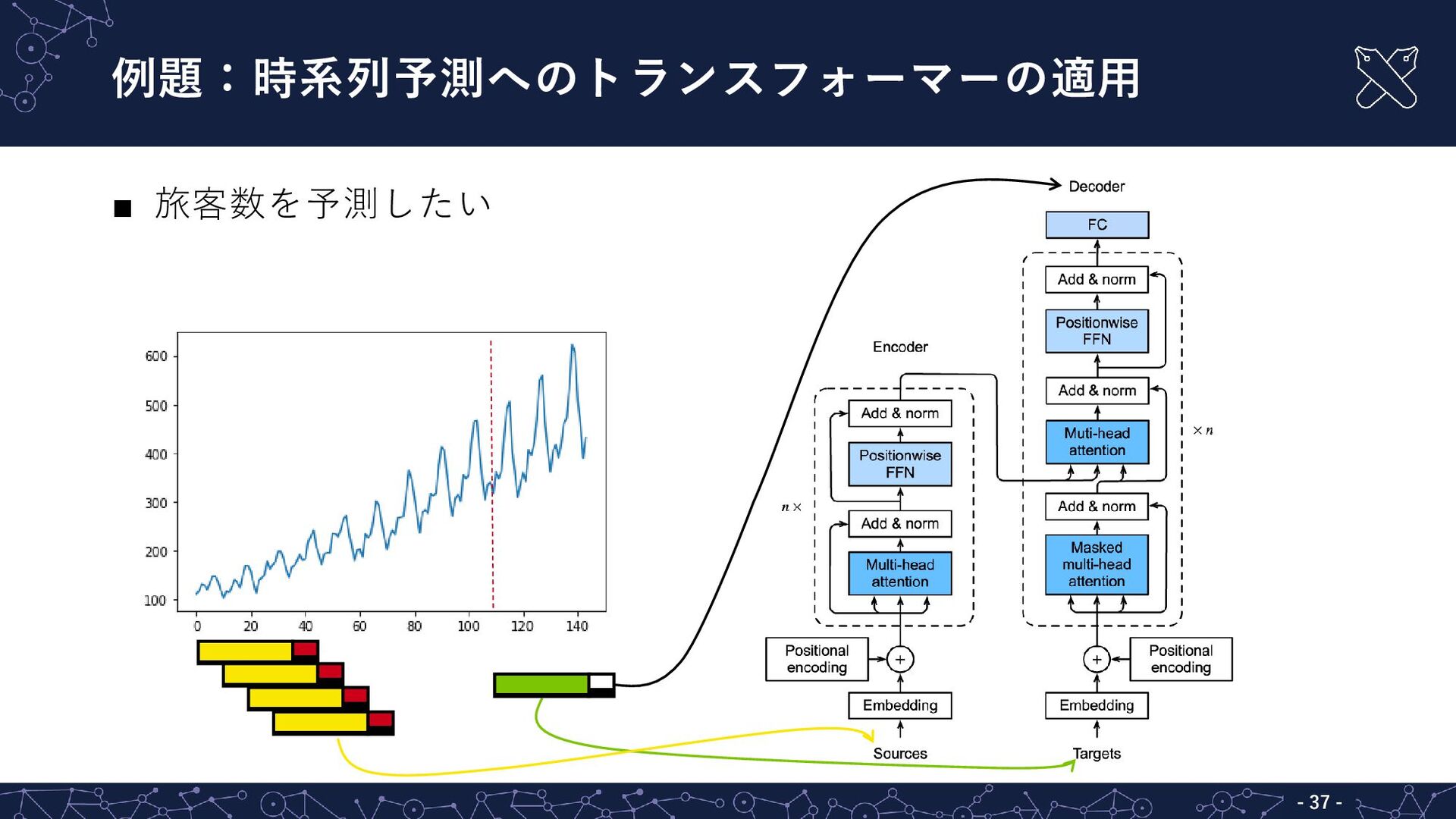
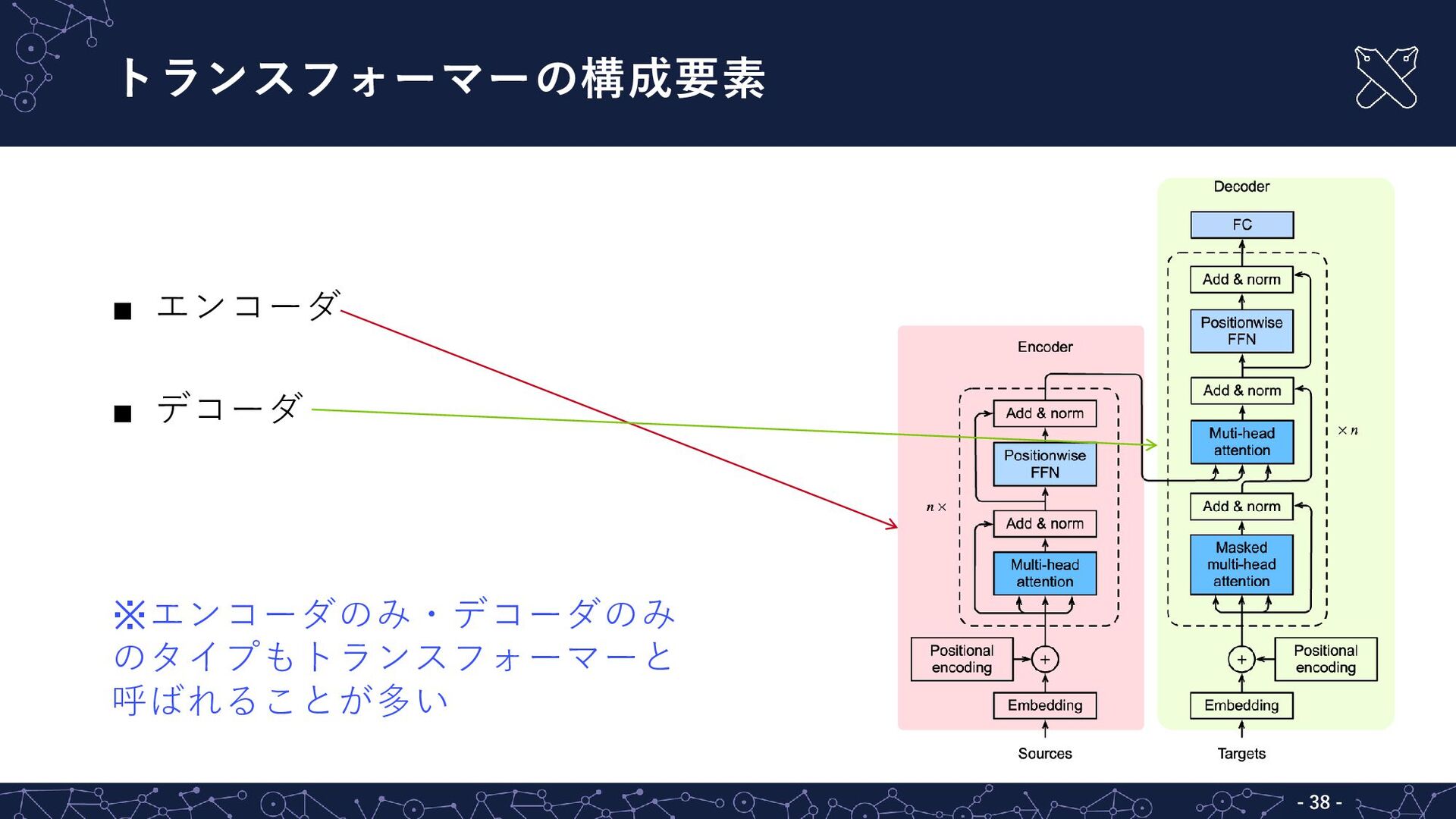
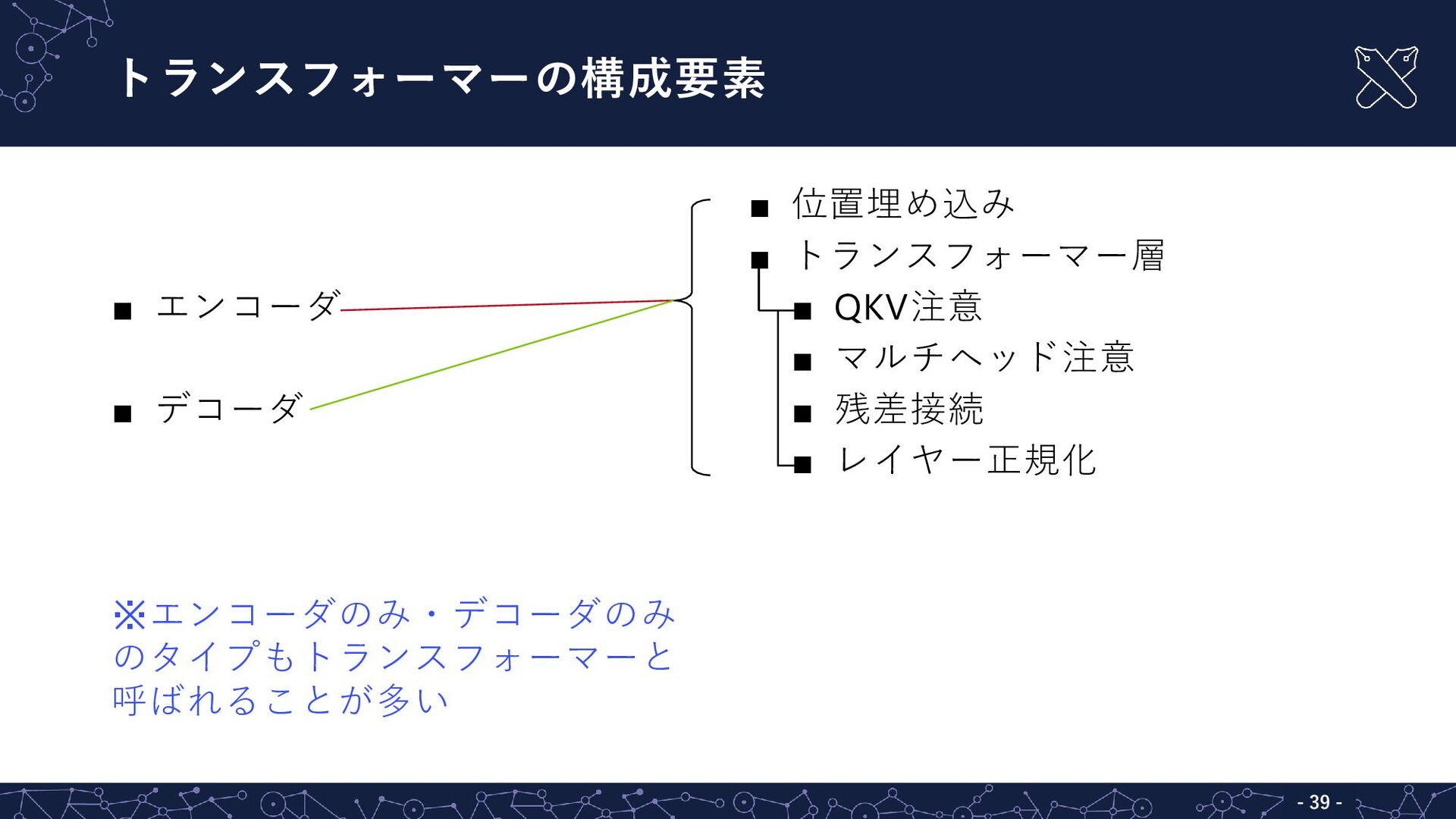
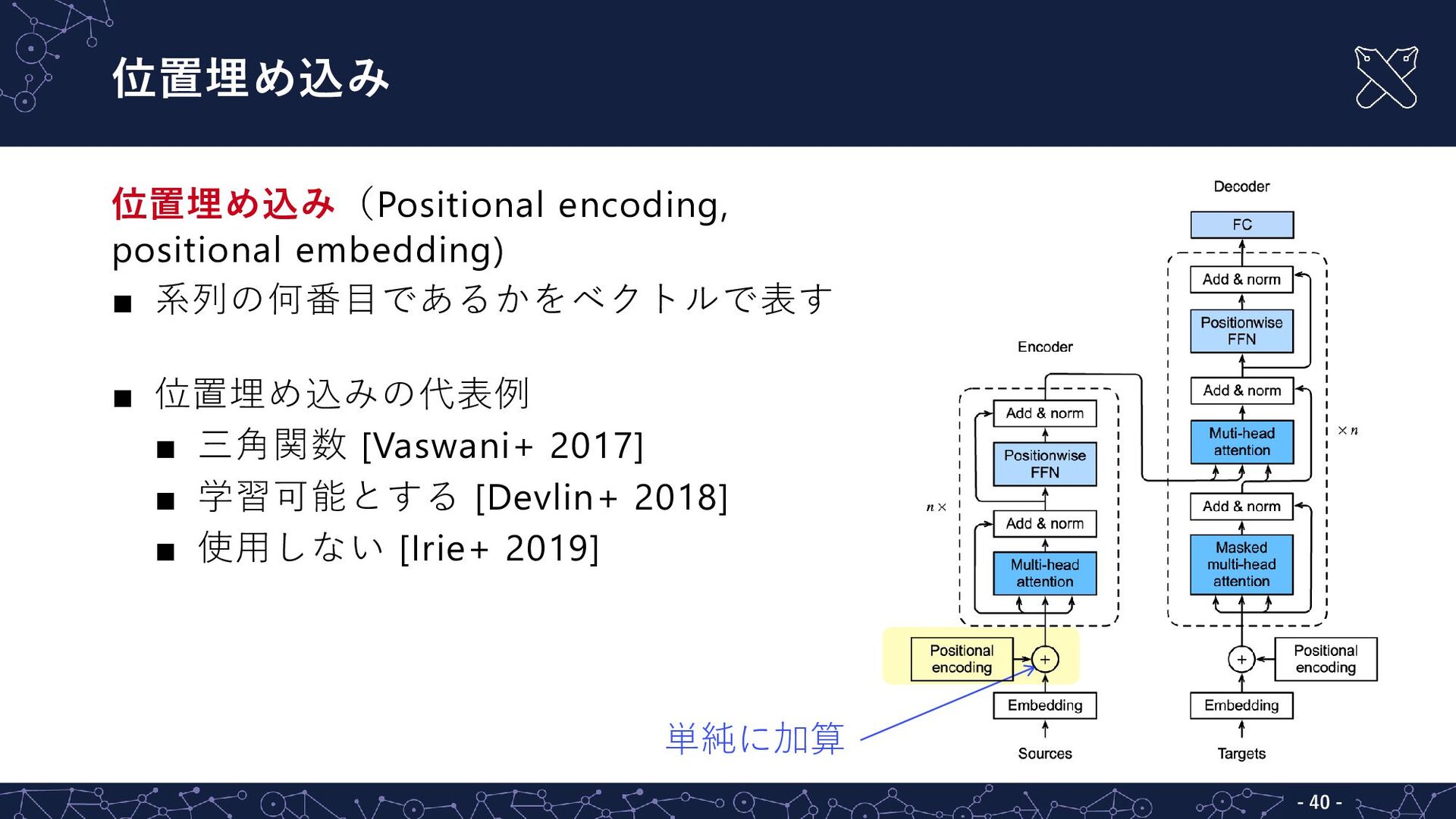
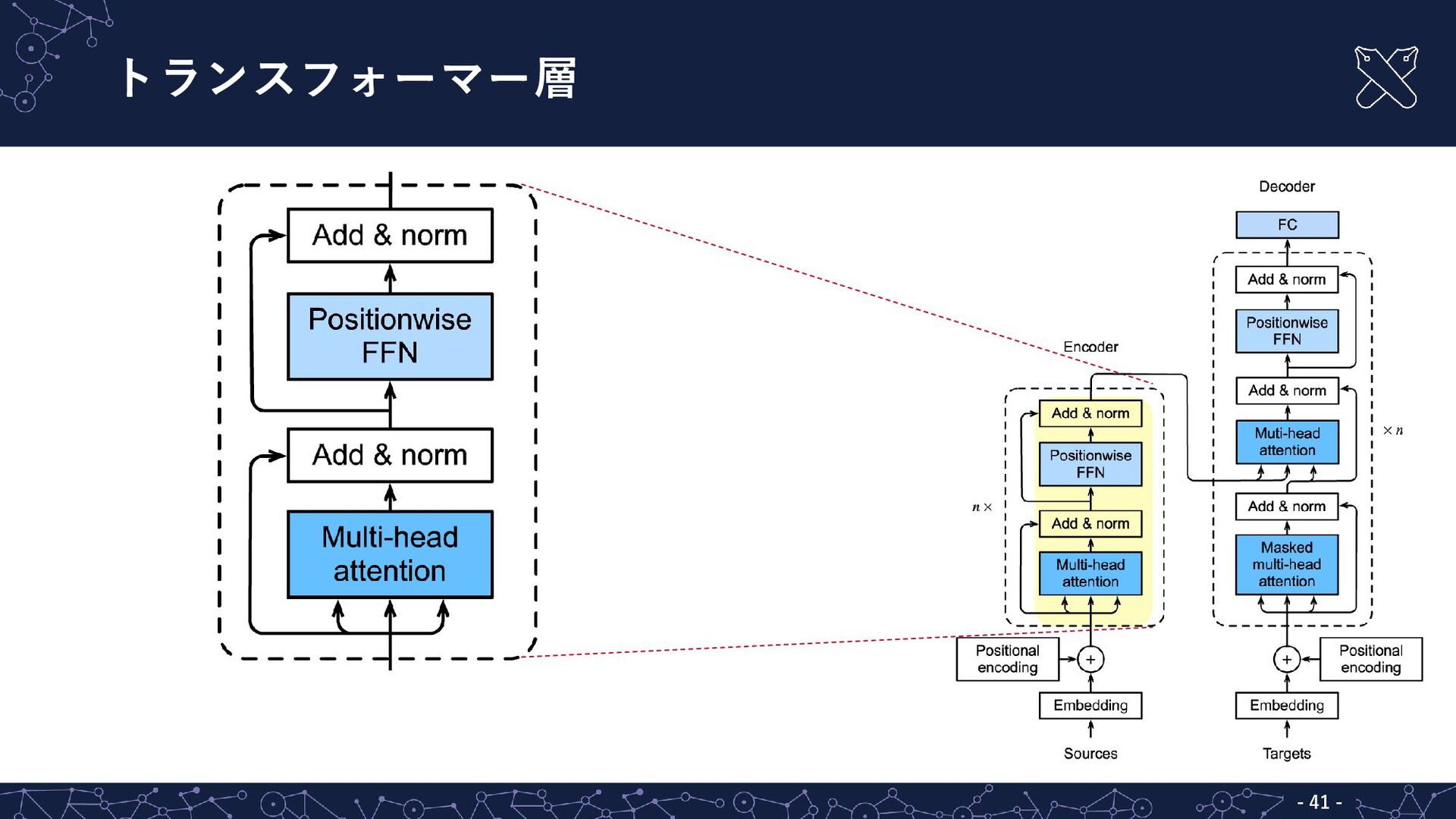
![トランスフォーマー - - 36 トランスフォーマー(transformer)[Vaswani+ 2017] ▪ 機械翻訳用のニューラルネットとして提案 ▪ 自然言語処理タスクの多くで主流](https://files.speakerdeck.com/presentations/7f88bb8c5b1e475bbe637e6b6dc754aa/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![QKV注意 [Vaswani+ 2017] - - 42 ▪ 前述の内積注意(scaled dot-product attention)を利用して](https://files.speakerdeck.com/presentations/7f88bb8c5b1e475bbe637e6b6dc754aa/slide_33.jpg){kind=link}
![マルチヘッド注意 [Vaswani+ 2017] - - 43 ▪ Query/Key/Valueを複数に分割してQKV注意を 計算してから結合](https://files.speakerdeck.com/presentations/7f88bb8c5b1e475bbe637e6b6dc754aa/slide_34.jpg){kind=link}
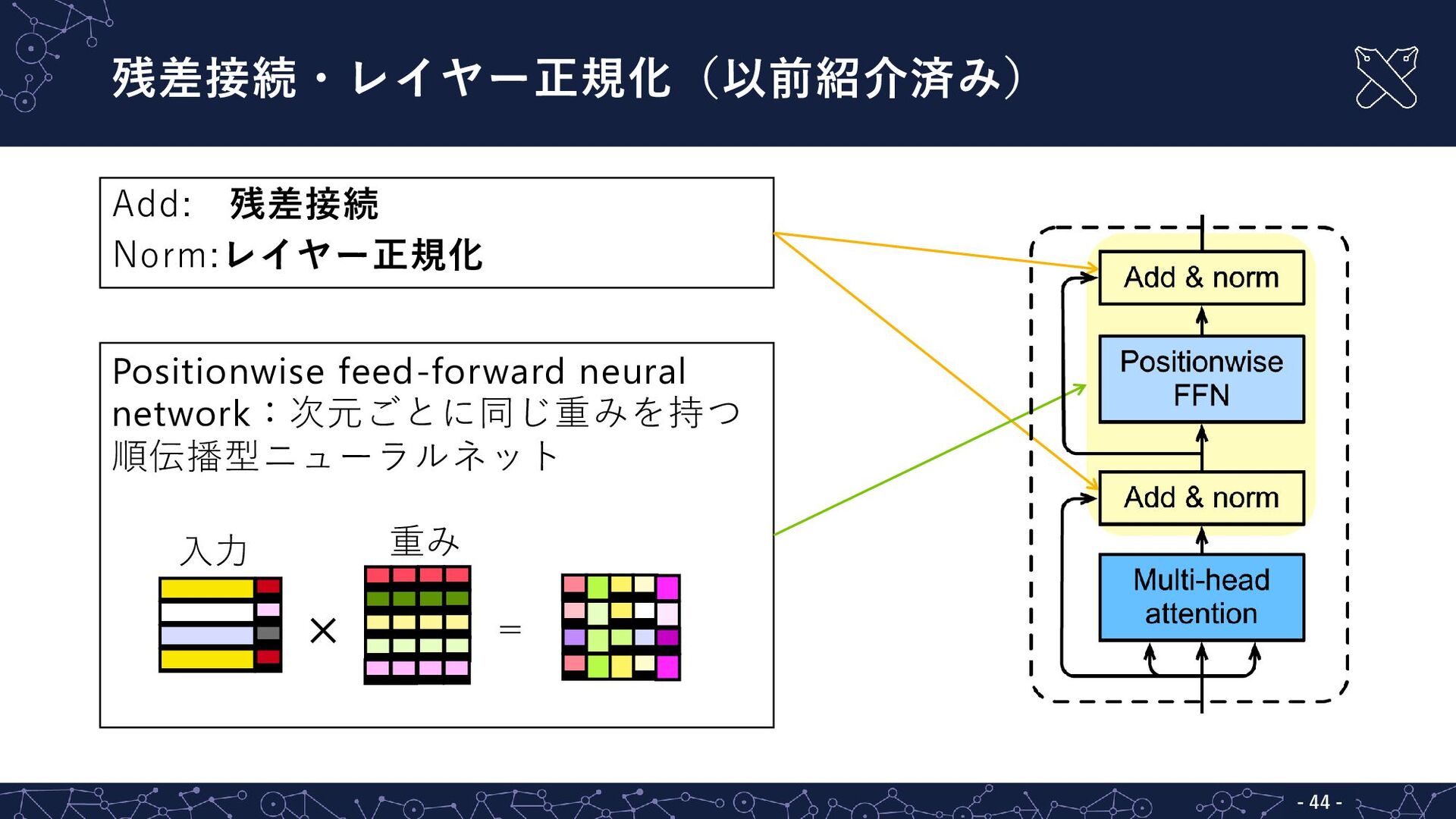{kind=link}
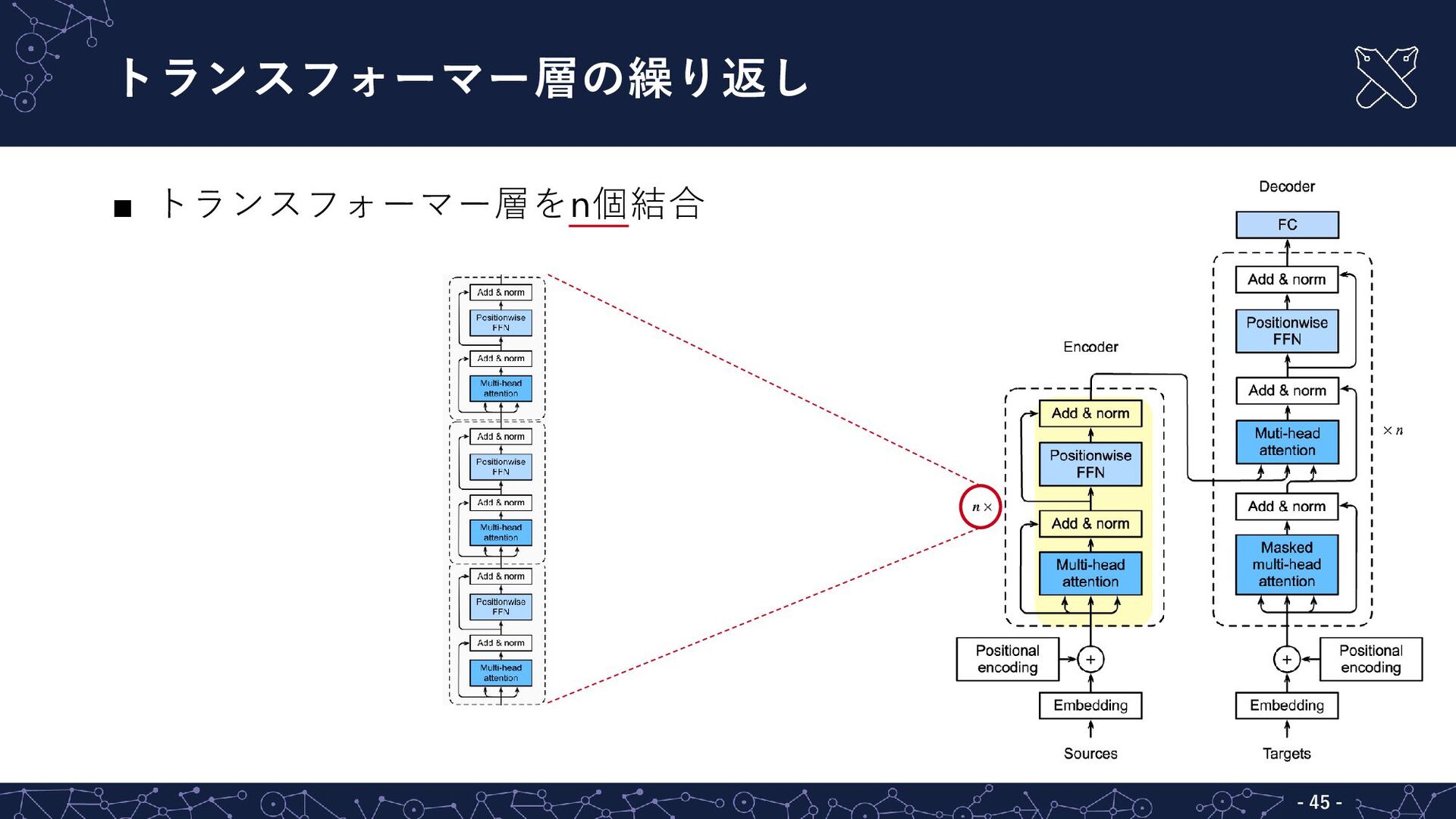{kind=link}
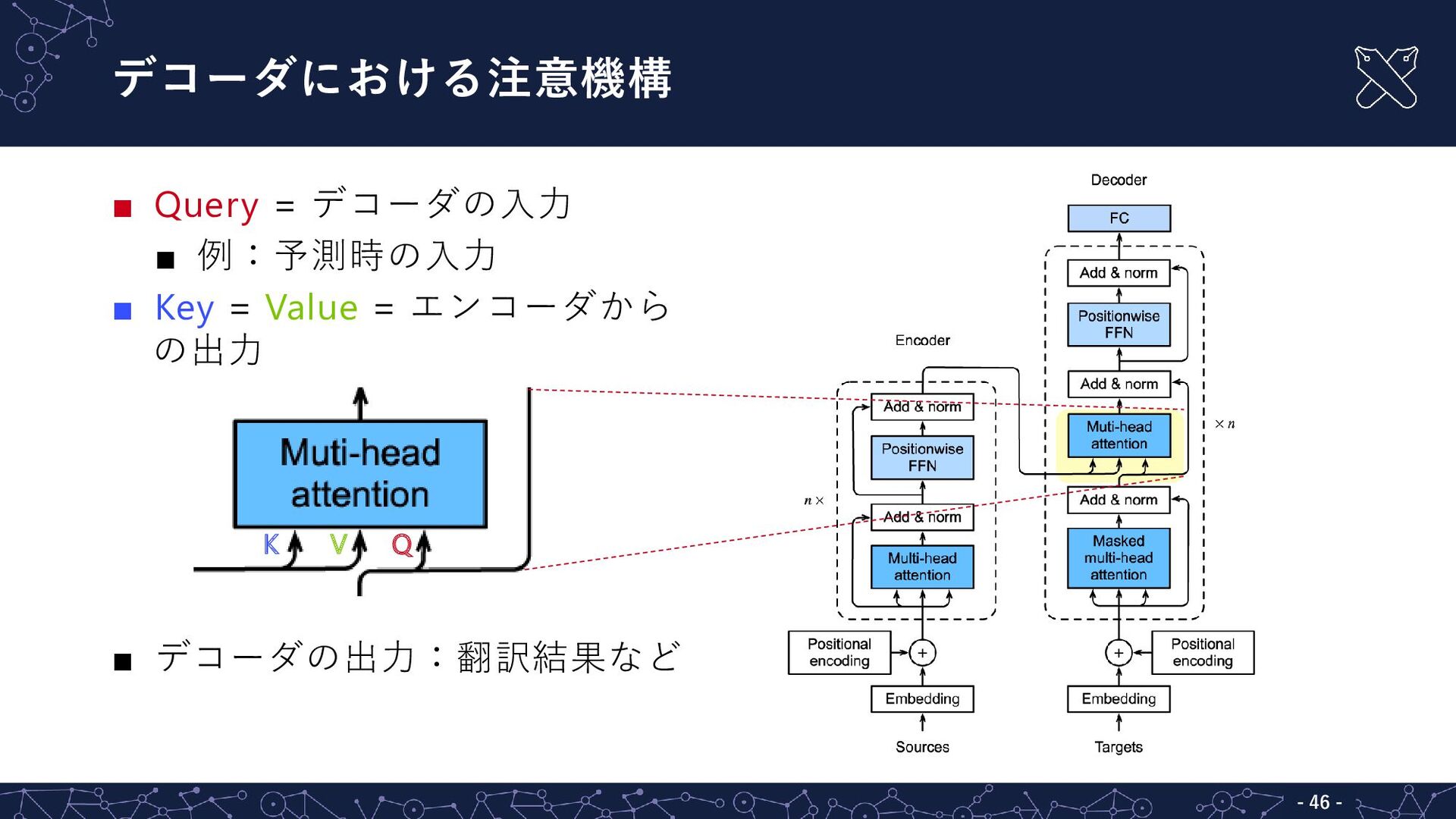{kind=link}
{kind=link}
{kind=link}
{kind=link}
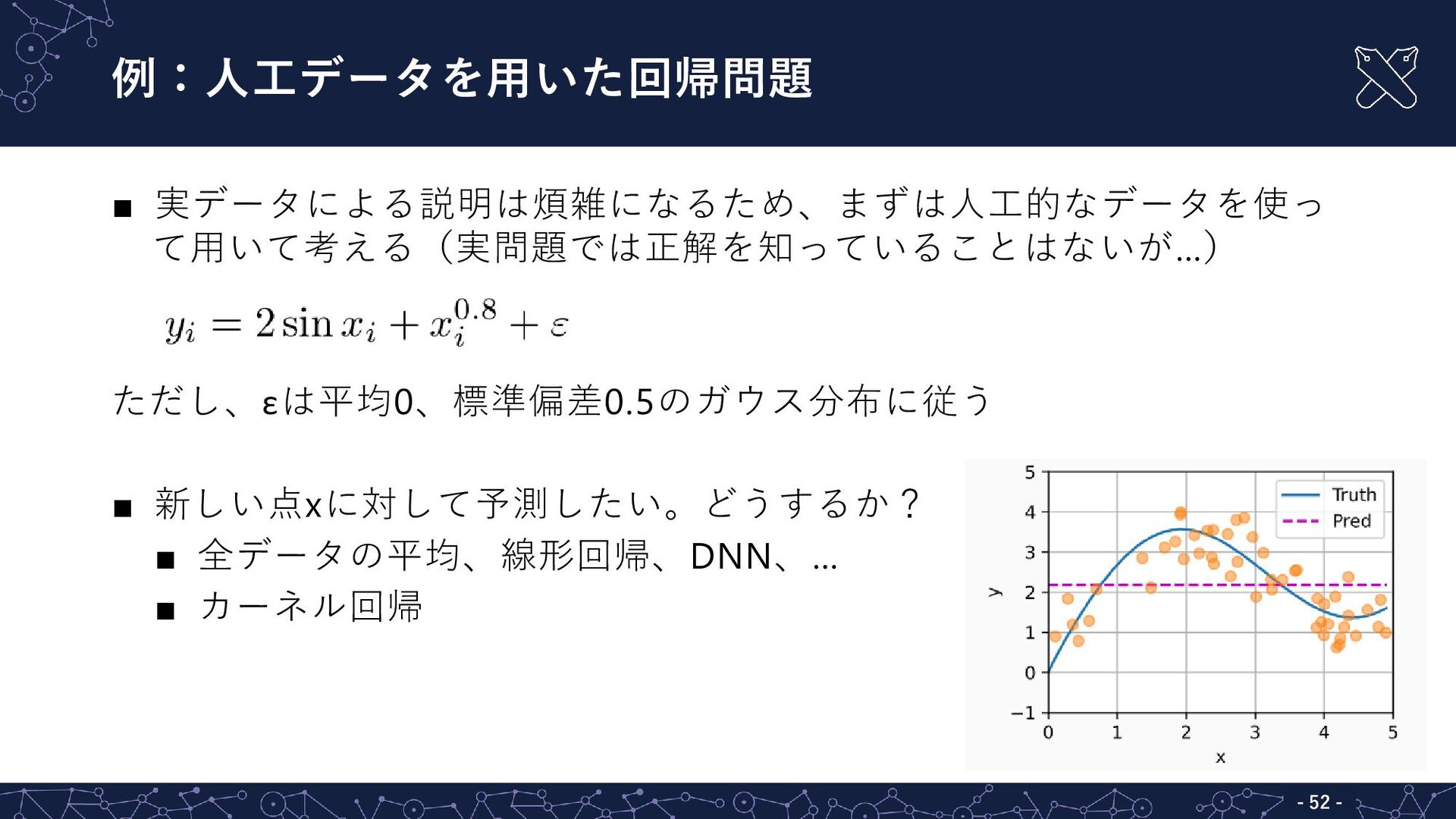{kind=link}
{kind=link}
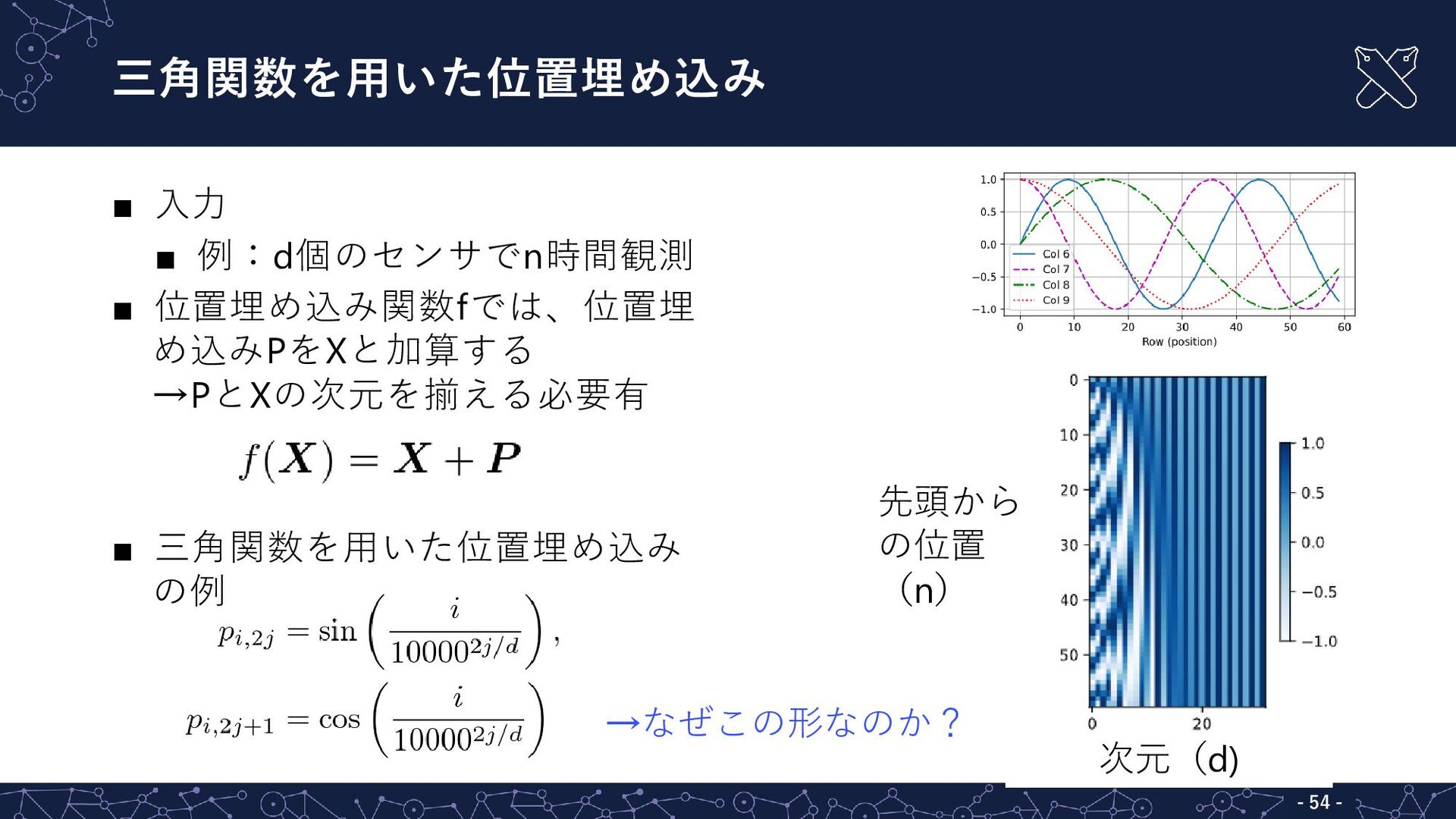{kind=link}
{kind=link}
{kind=link}