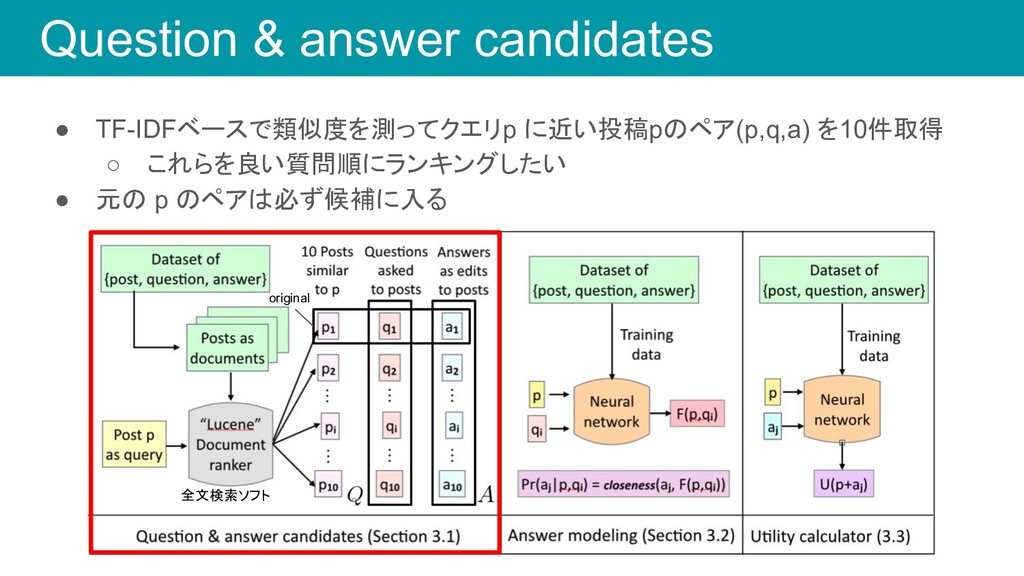
question ◦ 1のような投稿にない情報を尋ねる質問 1. What version of Ubuntu do you have? 2. What is the make of your wifi card? 3. Are you running Ubuntu 14.10 kernel 4.4.0-59 generic on an x86_64 architecture?
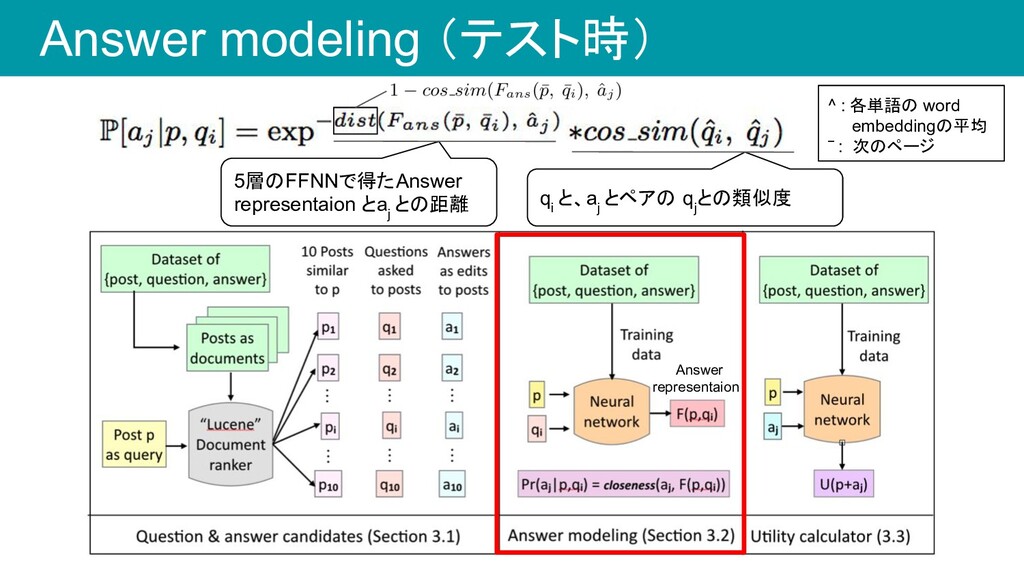
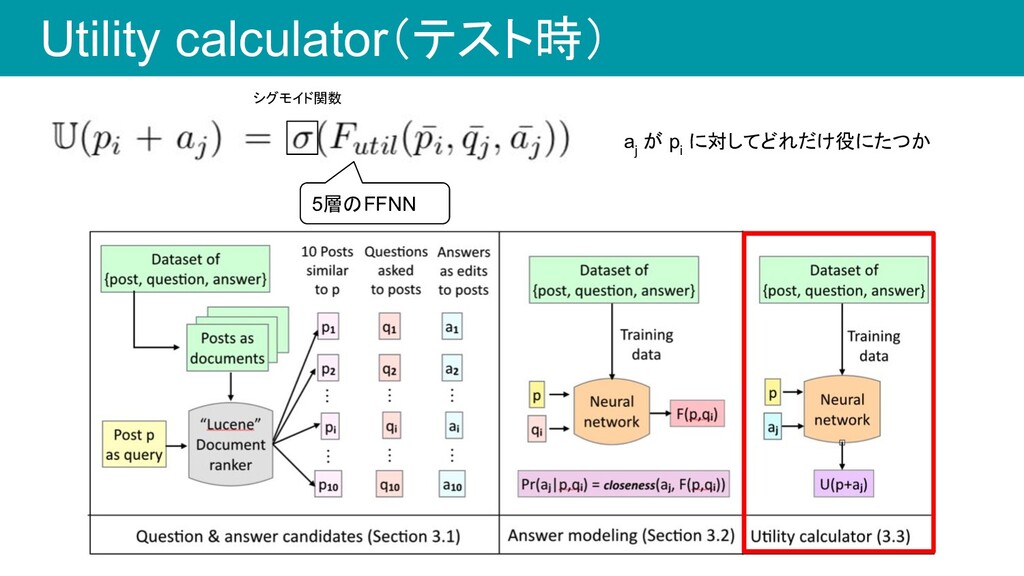
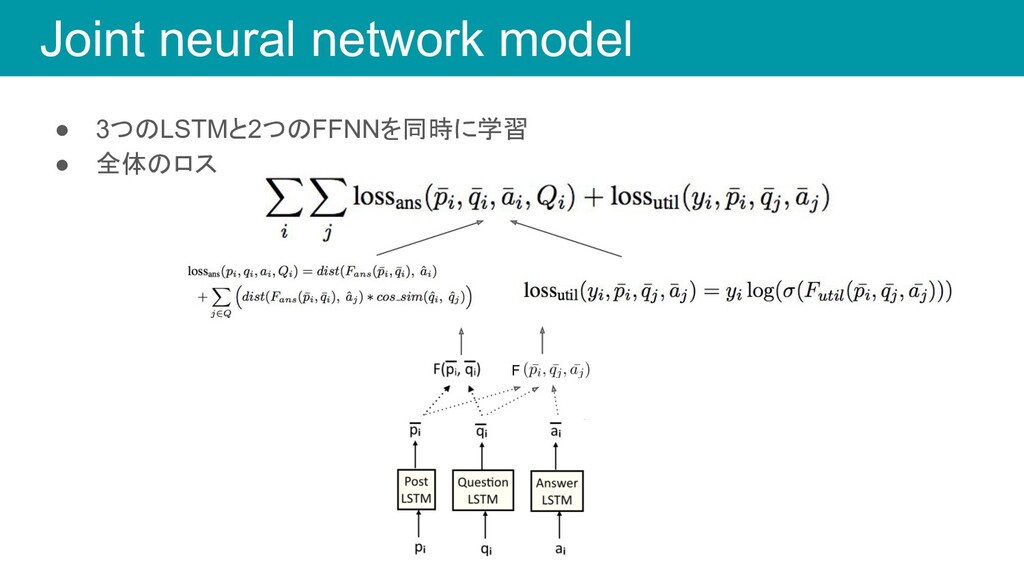
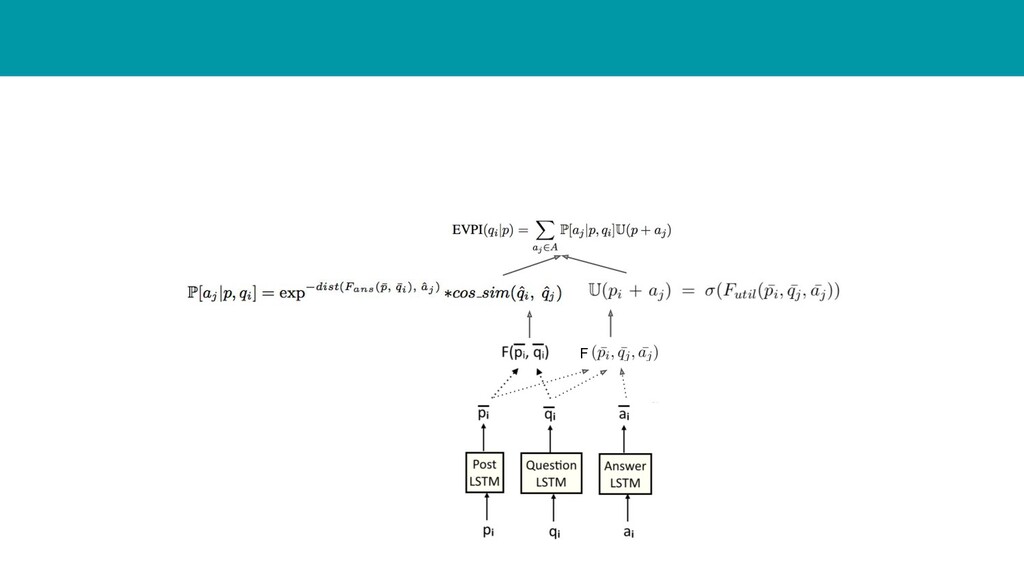
◦ 情報 X がどれだけ有用なのかを評価する手法 • 今回の研究では以下のようにしてモデル化 ◦ 投稿 p に対して質問 q i がどれだけ有用なのか ◦ この値を用いて候補質問をランキングする p : 投稿 q i : 質問 a j : 回答 A : 回答候補(次スライド) 投稿 p と質問 q i が与えられた 時に回答 a j が答えられる確率 Utility function: 回答 a j が投稿 p に対してどれだけ有 効に働いたかを示す
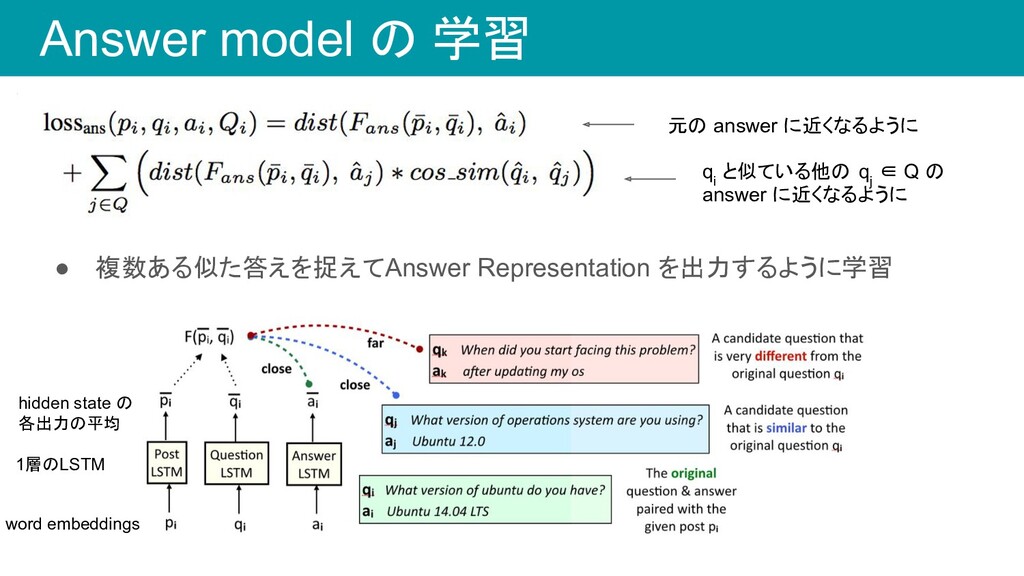
各 p i に対して、1つの positive sample と 9つの negative sample を作る 1. 学習データの全てのペア(p i , q i , a i ) を、y = 1でラベル付け 2. 各 p i に対する候補を出して a j = a i 以外の(p i , q j , a j ) を y = 0 でラベル付け • loss 関数 • Utility function が positive label(y=1)の時に1になるように学習
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}