on great success story • huge dictionaries have been published (Pokorny 1959, Kluge 1883, Mayerhofer 1986–2001, Meyer-Luebke 1911) • thousands of word histories have been reconstructed “Chaque mot a son histoire!” (attr. to Jules Gillieron, 1854-1926)
consuming to produce and to use 2. insufficiently formalized, untransparent, and idiosyncratic 3. difficult if not unrealistic to produce for understudied languages
linguistics: • rely on wordlists of basic vocabulary (Atkinson & Gray 2006) • show an increase in breadth (more languages) • show a decrease in depth (fewer words per language) • usually ignore morphology (important in traditional approaches) • show an untransparent motivation for cognate judgements • usually never reach the etymological dictionary level of annotation
data-rich and theory-poor.” (William S.-Y. Wang, 1996) • many datasets on South-East Asian languages have been published (Sidwell 2015, Wang 2004, Huang 1992, etc.) • large digitized collections have been made available via the STEDT project (Matisoff 2011) • but the majority of these data is unprocessed (not further checked by linguists), lacking etymologies, cognate judgments, phonetic transcriptions, or concept annotations
of traditional and quantitative approaches to profit from computational efficiency and human insight? Which challenges do we face when pursuing integrated frameworks in South-East Asian languages?
synergy grant 'Beyond Boundaries' (SOAS, British Museum, British Museum) Goal: • creating a classical etymological dictionary, taking full advantage of computational approaches with an openly published database online
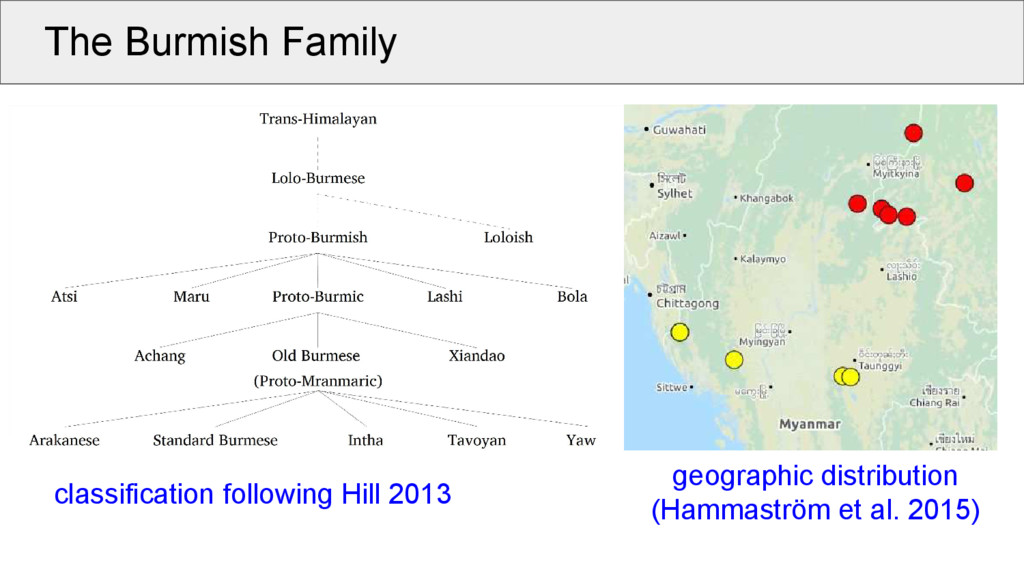
sparse Bradley (1979): inexplicit, not Burmish (Loloish) Mann (1998): no use of Old Burmese, no relative chronology of changes, morphemes as cognate sets Nishi (1999): no reconstruction, very clean organization into cognate sets, larger dataset than predecessors
which are in the same prosodic position of a word. Notably processes like tonogenesis and various patterns of aspiration and voicing often co-occur with other sound changes. In these cases, a simple alignment of the words under consideration is usually not enough, but an analysis of the patterns of sound correspondences needs to be carried out.
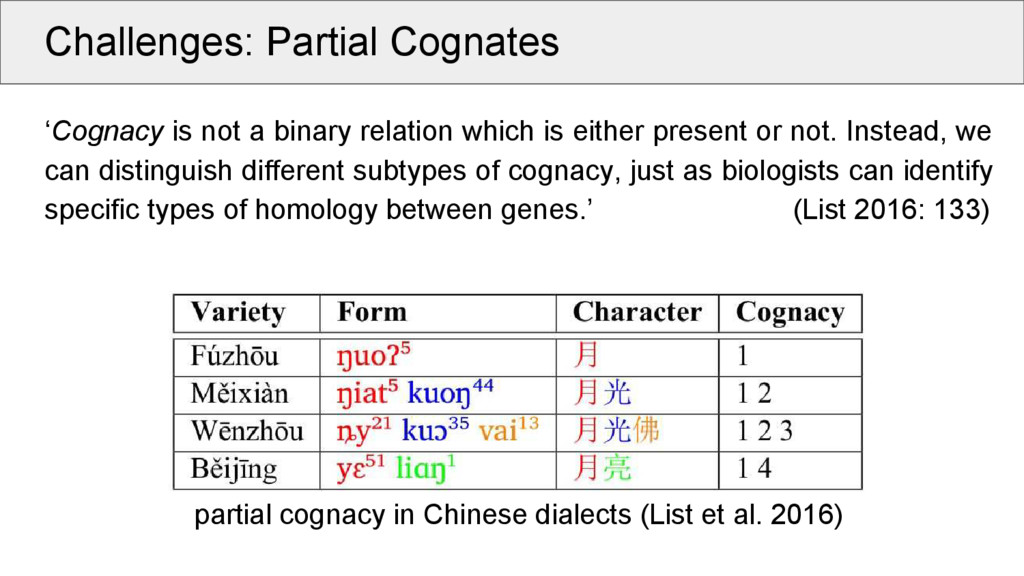
is either present or not. Instead, we can distinguish different subtypes of cognacy, just as biologists can identify specific types of homology between genes.’ (List 2016: 133) partial cognacy in Chinese dialects (List et al. 2016)
(only fully identical words are considered cognate) • loose (words sharing a cognate morpheme are cognate) Problems of Binarisation: • not realistic with respect to lexical change • over- or underestimates the amount of shared cognates
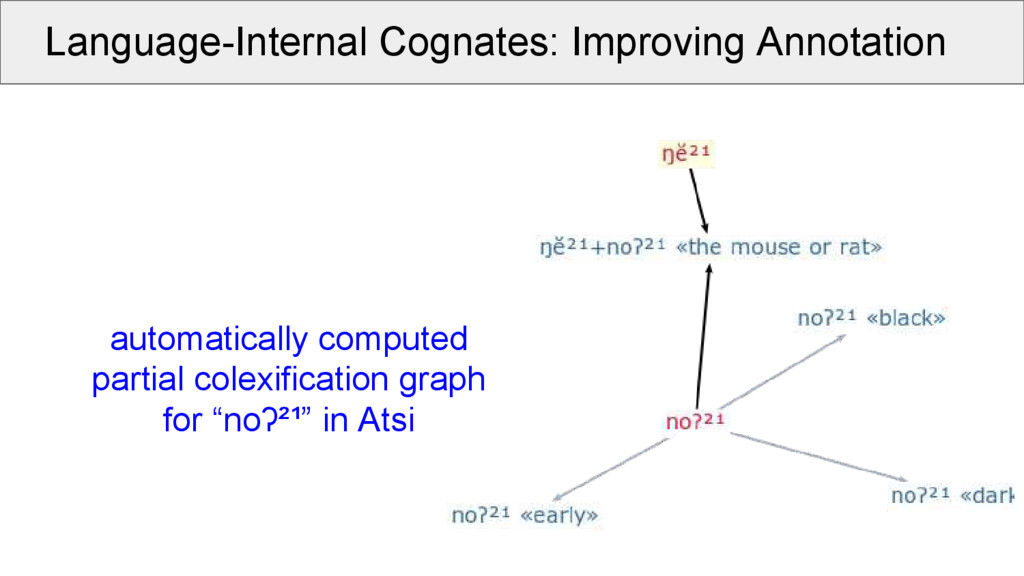
sound correspondences, dependencies inside a language need to be taken into account to avoid an overscoring of regularities. Language-internal cognates are invaluable evidence in classical cognate judgments and reconstruction. Current computational approaches ignore them completely.
branch” a khak • “the mother” a miy • “the flower” a po₁ṅʔ • “the feather” a muyḥ • “the father” a phiy • “the leaf” a ro₁k “the dog” in Atsi • “the wolf” [vam ¹kʰui²¹mo ] • “the dog” [kʰui²¹] • “the fox” [tan kʰui²¹]
Burmish varieties • 248 concepts selected (basic vocabulary, and etymologically important words) • partial cognates were automatically inferred and then manually corrected • alignments were automatically computed (will be manually corrected)
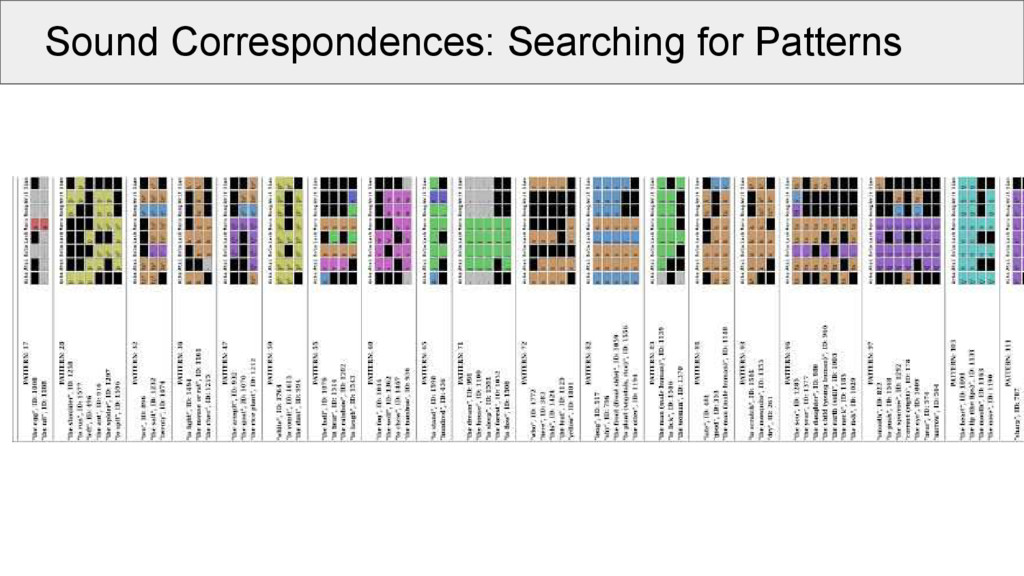
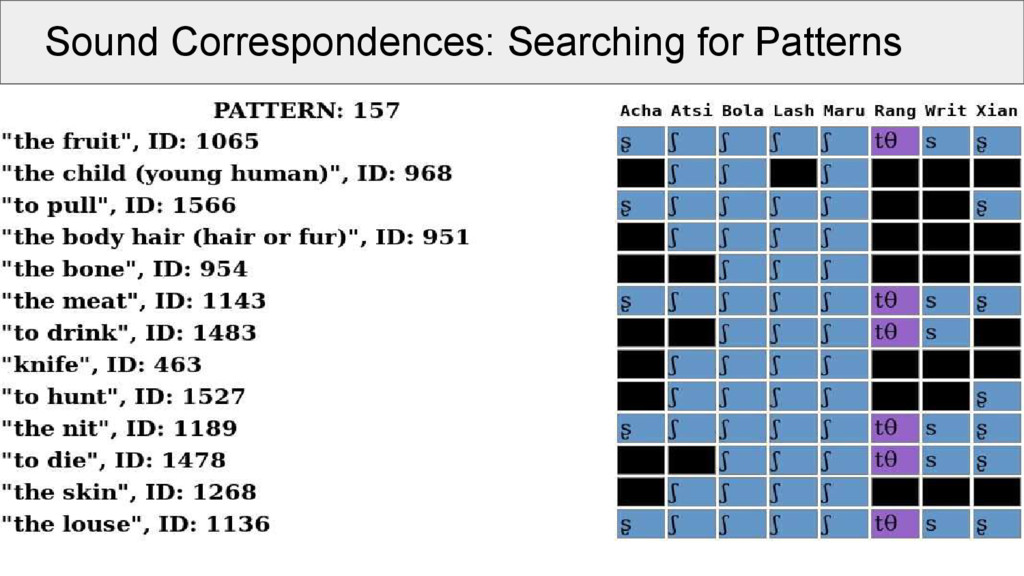
morpheme alignments? • if the Neogrammarians are right, ◦ a given proto-form in a given context should always yield the same reflex in a given descendant language • this means, ◦ compatible patterns in aligned cognate sets will hint to specific proto-sounds or proto-sounds in specific contexts
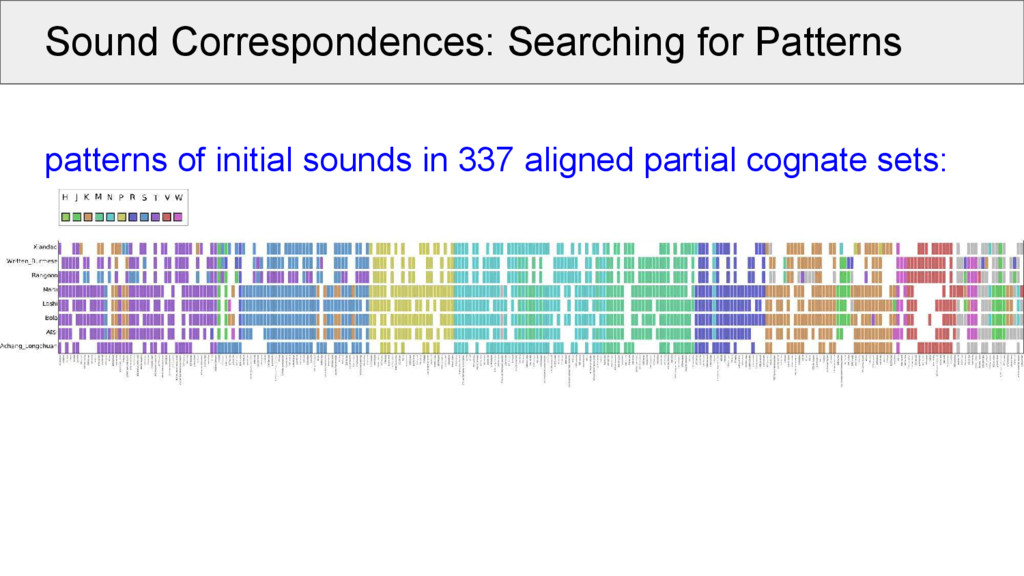
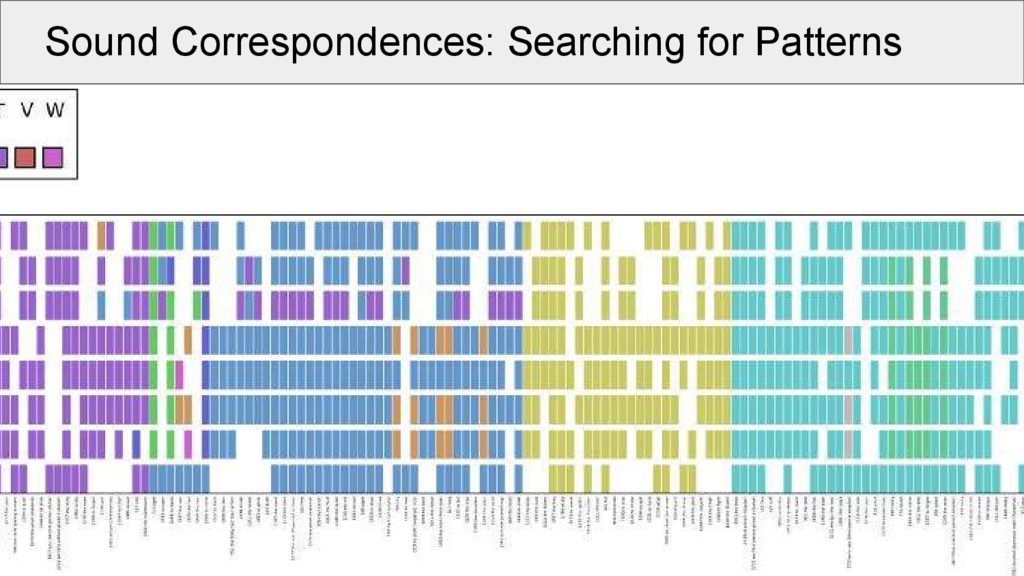
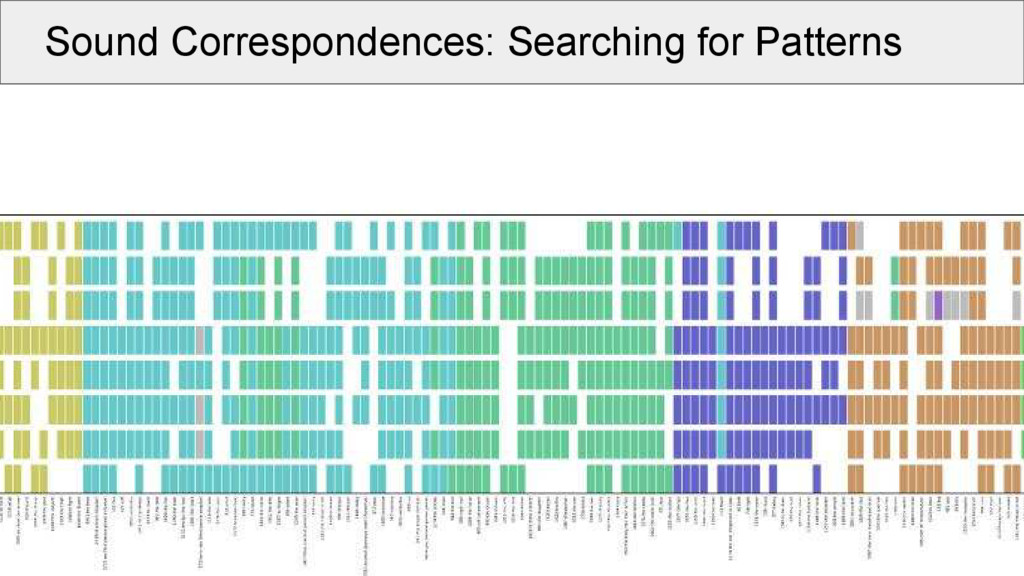
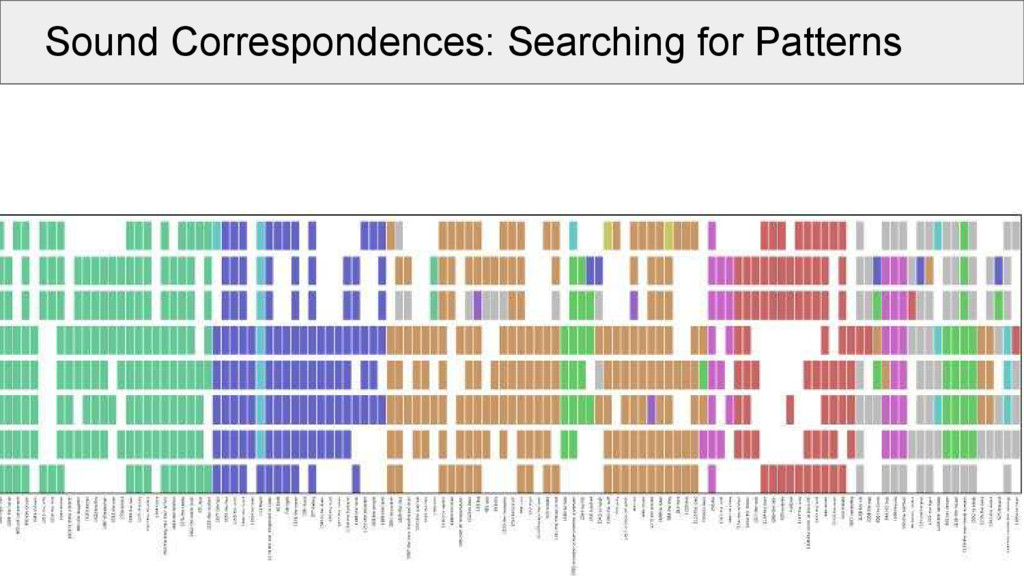
all alignments for a given dataset, and select one common sound position (e.g., initial of each morpheme) • when plotting for each language in our sample, which sound occurs in a given cognate set in the position, we can make a first step to compare these patterns
of two identical positions in different alignments is a necessary requirement to assume that the two alignments represent a common proto-sound in a common proto-context • it is not sufficient, as we have to deal with missing data, which may sufficiently blur the picture
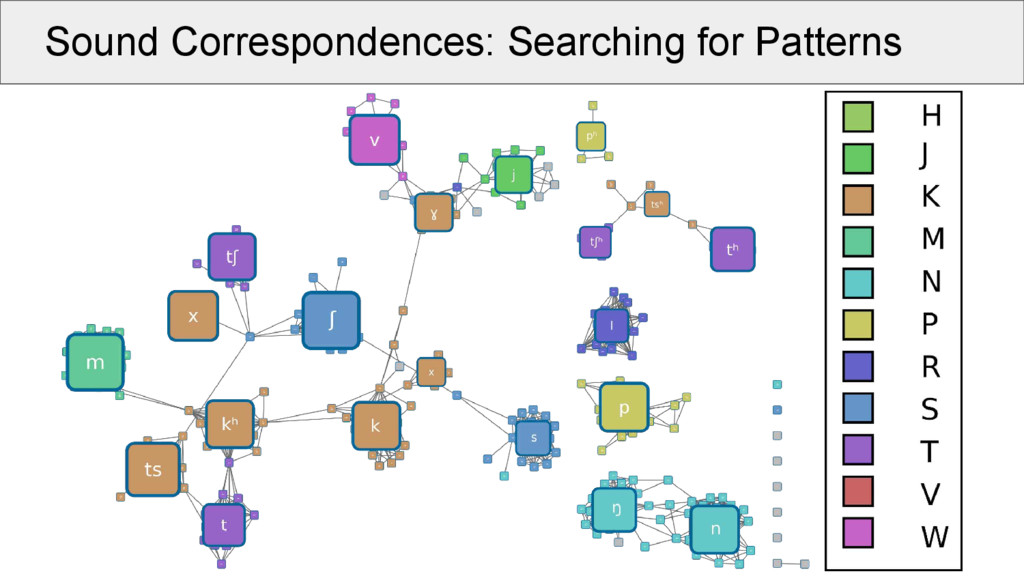
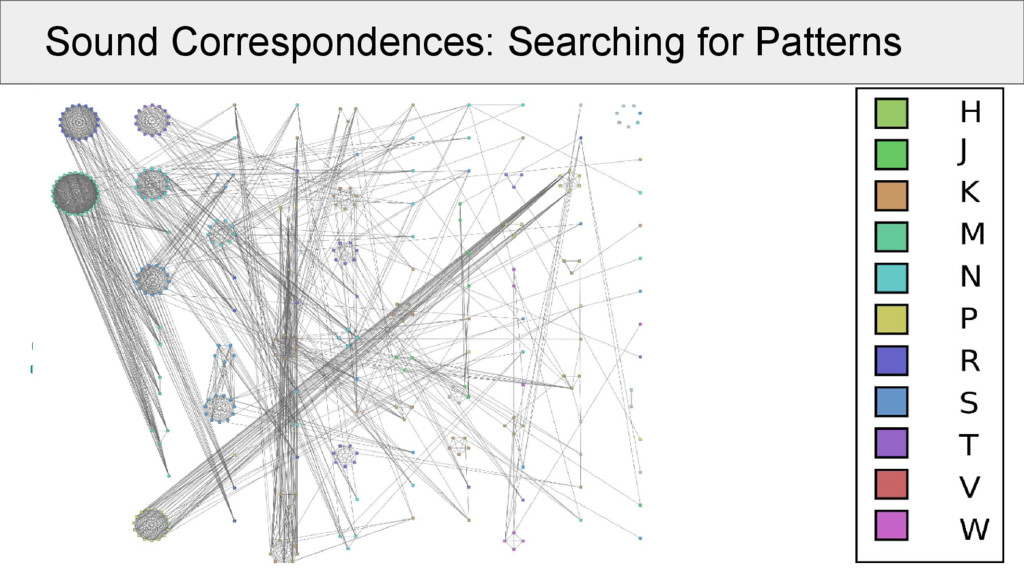
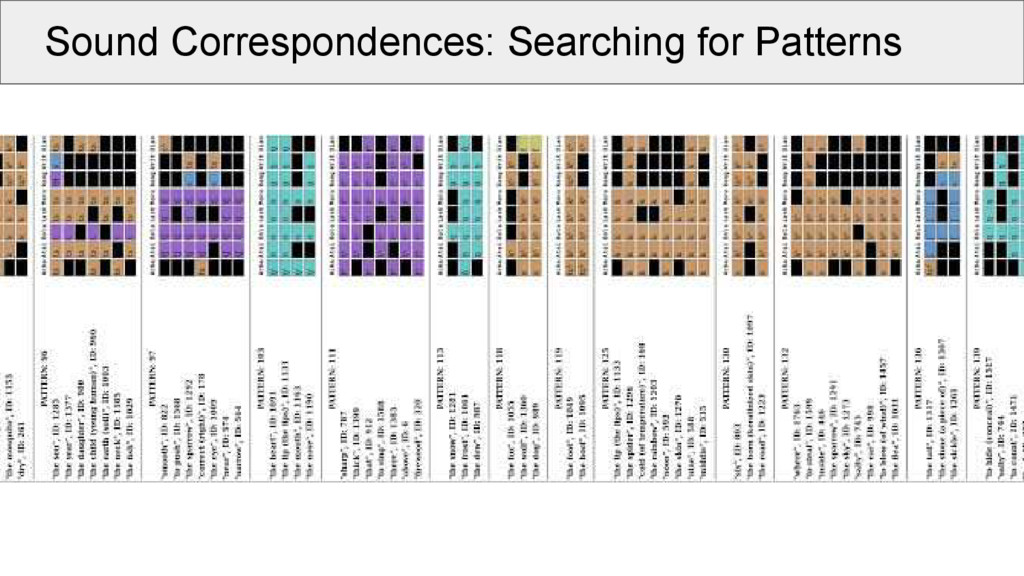
aligned cognate sets: • take the same position (e.g., initial consonant) in all alignments (called a “site” of the alignment) • make a network in which the alignment sites are nodes • edges in the network are drawn between two nodes if these are compatible with each other • weights between the edges are determined by counting the positions without a gap in both alignment sites
increase cluster compatibility: • A clique in a network is a group of nodes which are all connected with each other. • Cliques of compatible alignment sites represent the strongest evidence for a coherent group of regular correspondences pointing to the same proto-sound in a given context. • We use a simple method to search for non-overlapping cliques by maximizing their size, which is done in an iterative manner.
increase cluster compatibility: • What looks chaotic is less scary, if we look at the patterns! • Of 638 cognate sets: ◦ 337 occur in at least 3 taxa ◦ 317 start with an initial consonant ◦ 234 could be assigned to 35 transitive groups of minimal size 2 ◦ 74% (234 / 337) of the cognate sets can be seen as “regular”. The remaining cognate sets will be checked and either corrected or their incompatibility will be explained.
of compatibility networks: • remember, one clique in our network does not necessarily correspond to one proto-sound in the proto-language (maybe, our alignments are wrong, our cognates are wrong, the words are borrowed…) • but: if a proto-sound in a certain number of identical contexts has derived regularly from proto-language to descendant languages, it should form a clique in our data! • compatibility networks of prosodically similar alignment sites are just a first step towards computer-assisted language reconstruction
mo ] • “the tiger” [lo²¹mo ] • “the wolf” [vam ¹kʰui²¹mo ] • “the dog” [kʰui²¹] • “the fox” [tan kʰui²¹] Bola • “the wolf” [mjaŋ kʰui³ ] • “the dog” [kʰui³ ] • “the thunder” [mau³¹mjaŋ ] • “the sky” [mau³¹kʰauŋ ]
moon lo ̱ mo moon m-suffix Atsi the tiger lo²¹mo tiger m-suffix Atsi the wolf vam ¹kʰui²¹mo bear dog m-suffix Atsi the dog kʰui²¹ dog Atsi the fox tan kʰui²¹ fox(?) dog
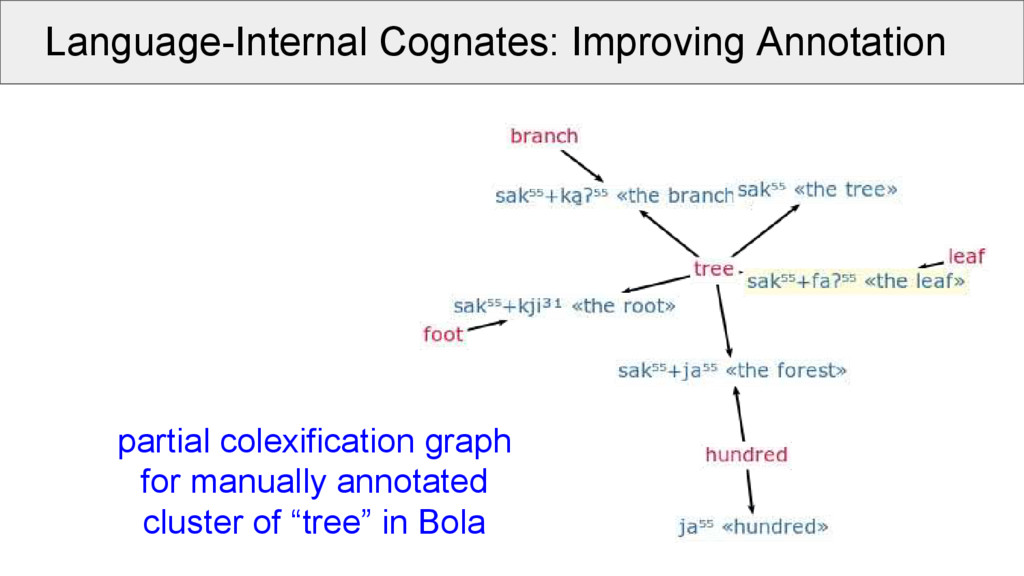
• simplified schema, all glosses are allowed, as long they do not contain white-space • question marks can be used to express doubt • identically annotated morphemes can be inspected (they indicated language-internal cognates) • partial and full colexifications can be used to assist the morphological analysis • data can be visualized with help of partial colexification graphs
the realism of our analyses • working with alignments opens new horizons for computer-assisted consistency analysis • annotation of language-internal cognacy opens exciting research avenues for the investigation of semantic change, lexical typology, and language relationship
clusters in our alignments to first reconstructions? • Can we use compatibility to test the consistency of reconstruction systems? • How can we formalize the assignment of cross-semantic cognates in our wordlists?
(UPMC, Paris) for inspiration and help with network analyses • Guillaume Jacques and Laurent Sagart for helpful feedback on EDICTOR tool and active help in creating the first concept list • Doug Cooper for helping out with parts of the data that we used
(1967). Proto-Lolo-Burmese. Bloomington: Indiana University. Hill, Nathan W. (2013) 'The merger of Proto-Burmish *ts and *č in Burmese.' SOAS Working Papers in Linguistics 16: 334-345. Kluge, Friedrich (1883). Etymologische Wörterbuch der deutschen Sprache. Strassburg: K. J. Trübner. List, Johann-Mattis (2014): Sequence comparison in historical linguistics. Düsseldorf: Düsseldorf University Press.
sequence similarity networks to identify partial cognates in multilingual wordlists. Proceedings of the Annual Meeting of the ACL. Berlin: Association of Computational Linguistics. 599–605. Mann, Noel Walter (1998). A phonological reconstruction of Proto Northern Burmic. Unpublished thesis. Arlington: The University of Texas. Mayerhofer, Manfred (1986-2001). Etymologisches Wörterbuch des Altindoarischen. Heidelberg: Carl Winter.
Yoshio (1999). Four Papers on Burmese: Toward the history of Burmese (the Myanmar language). Tokyo: Institute for the study of languages and cultures of Asia and Africa, Tokyo University of Foreign Studies. Pokorny, Julius (1959). Indogermanisches etymologisches Wörterbuch. Bern and Münich: Francke.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}