DFG research fellow Centre des recherches linguistiques sur l’Asie Orientale Team Adaptation, Integration, Reticulation, Evolution EHESS and UPMC, Paris 2015-08-20 1 / 50
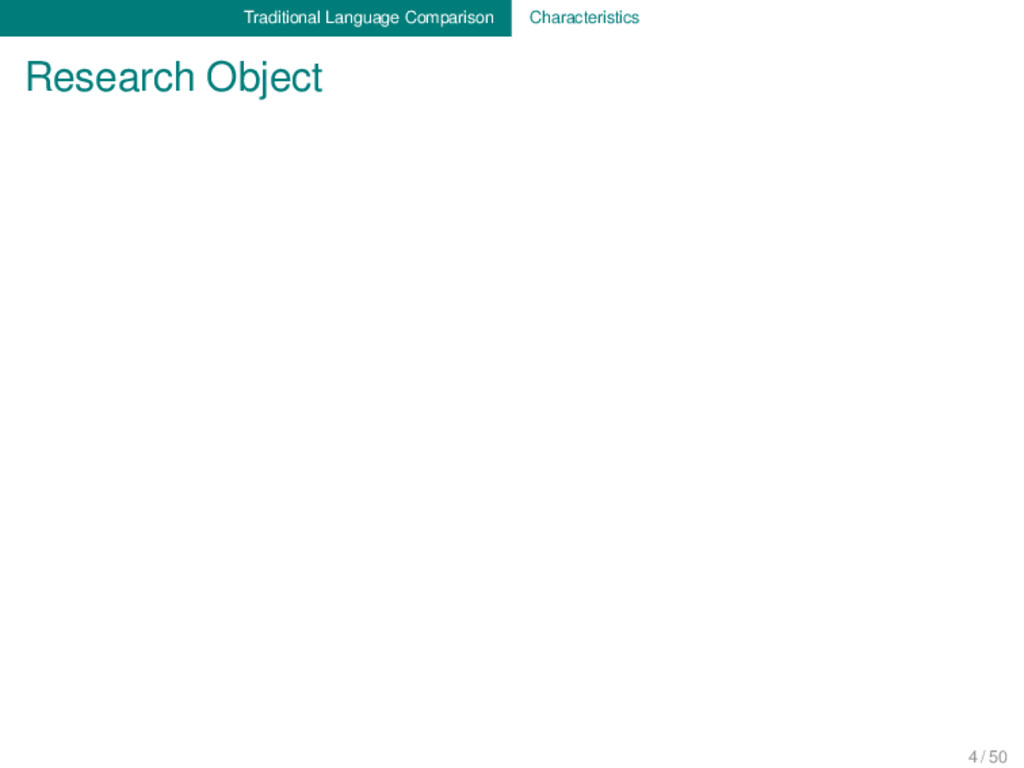
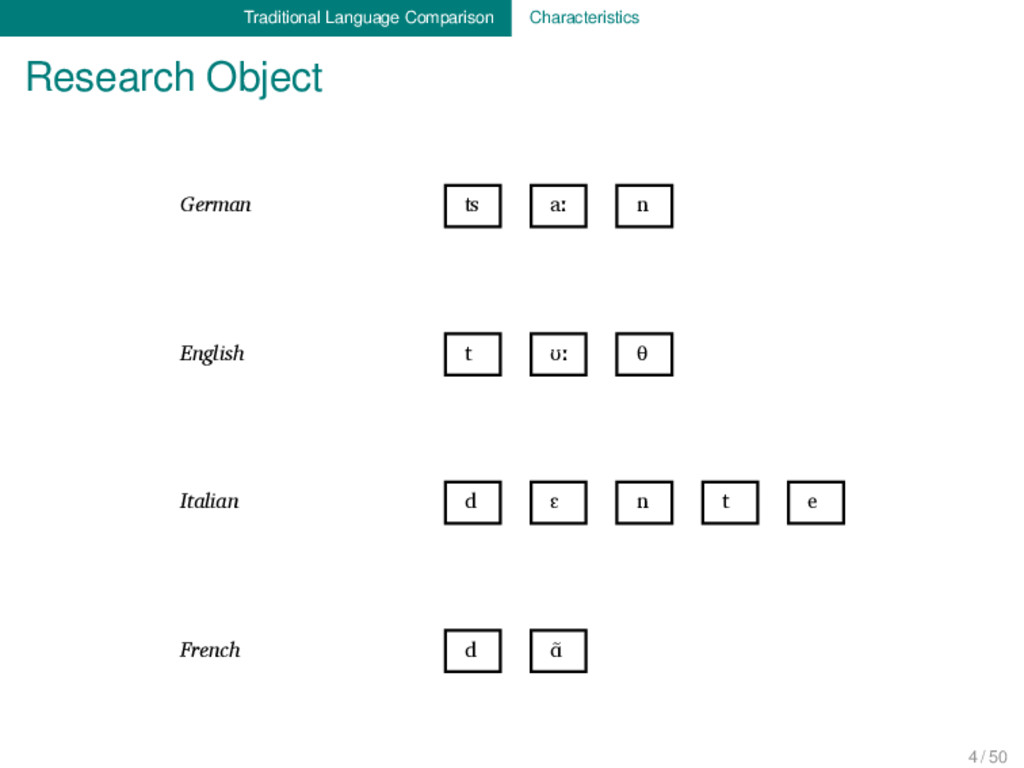
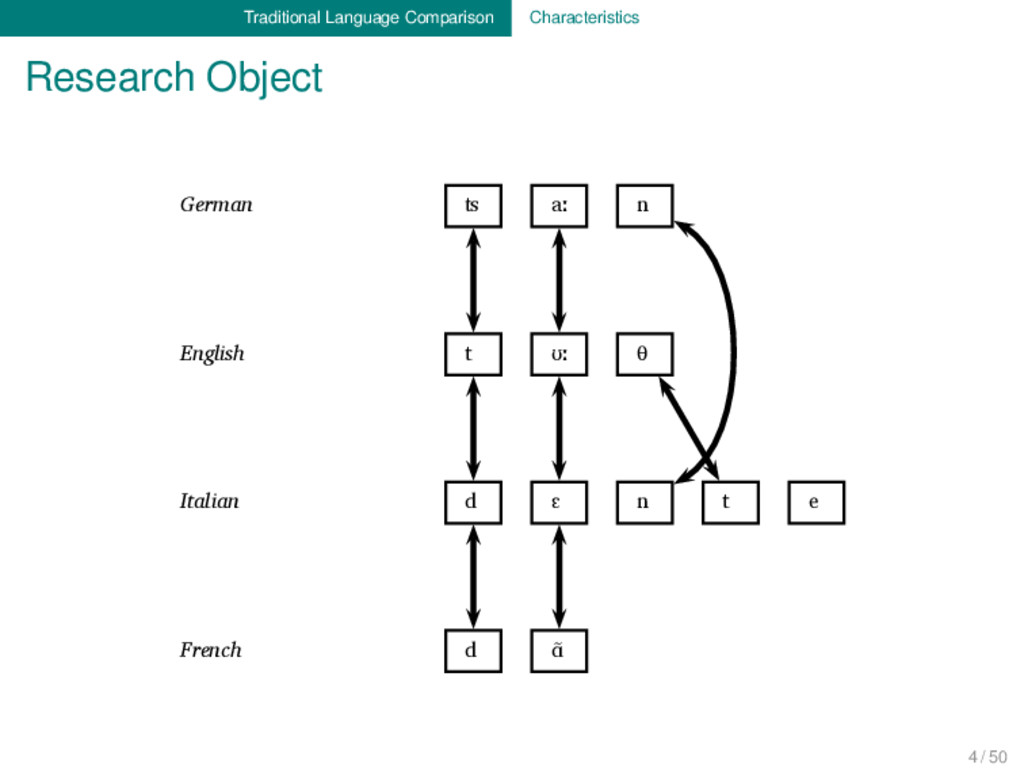
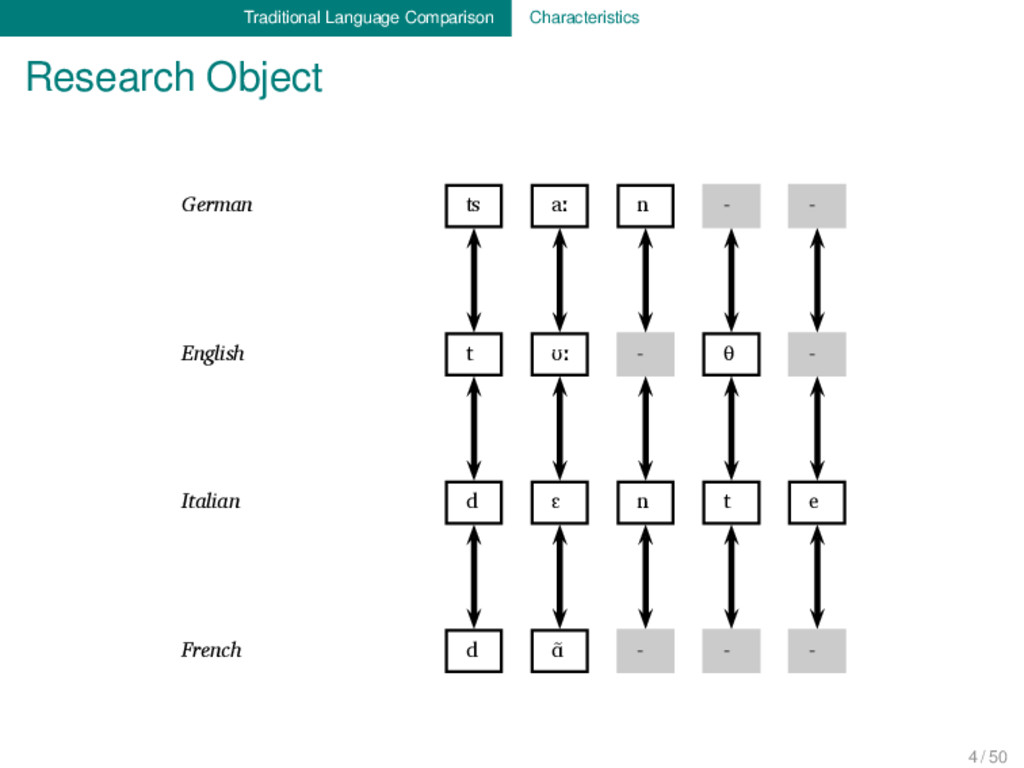
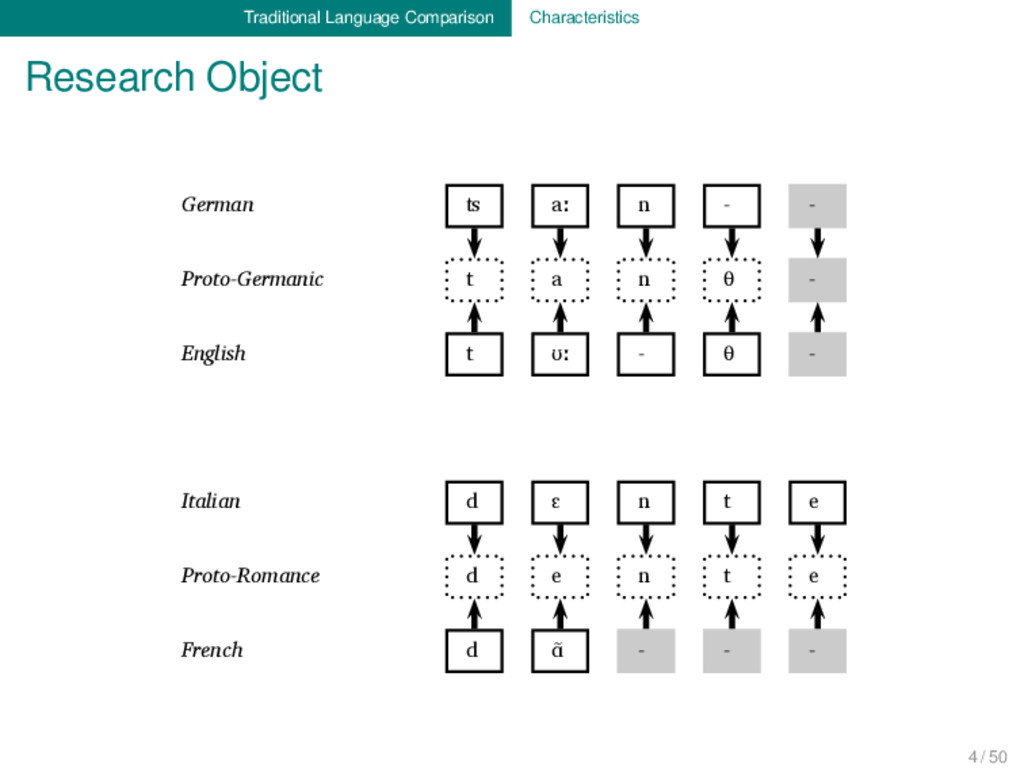
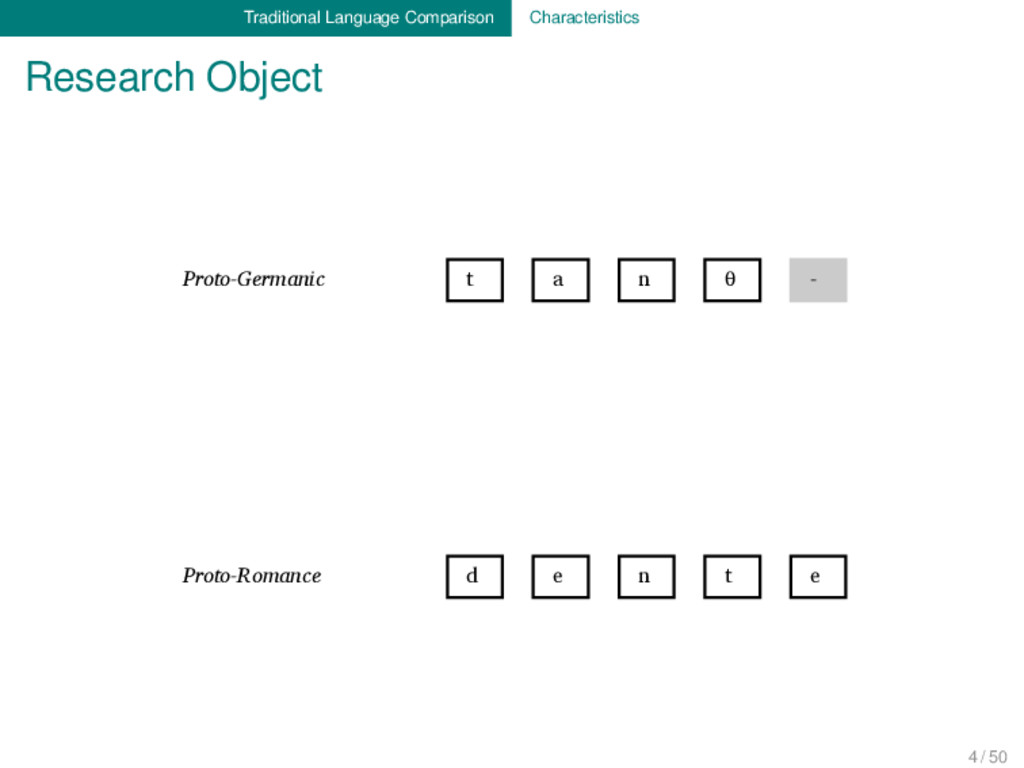
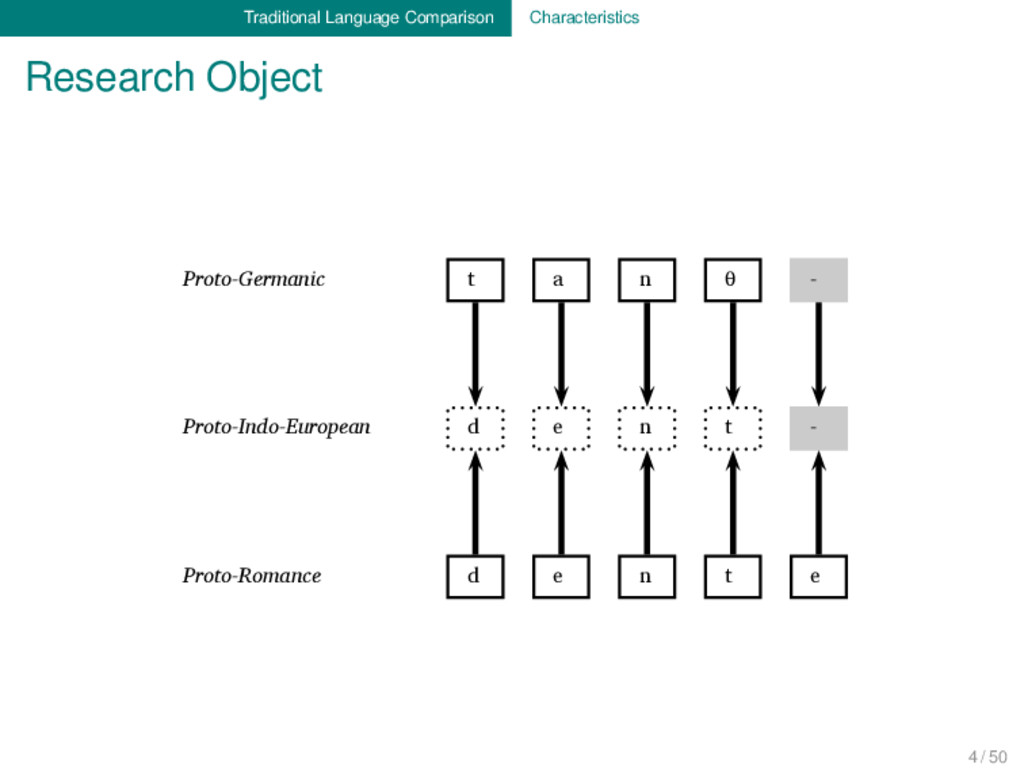
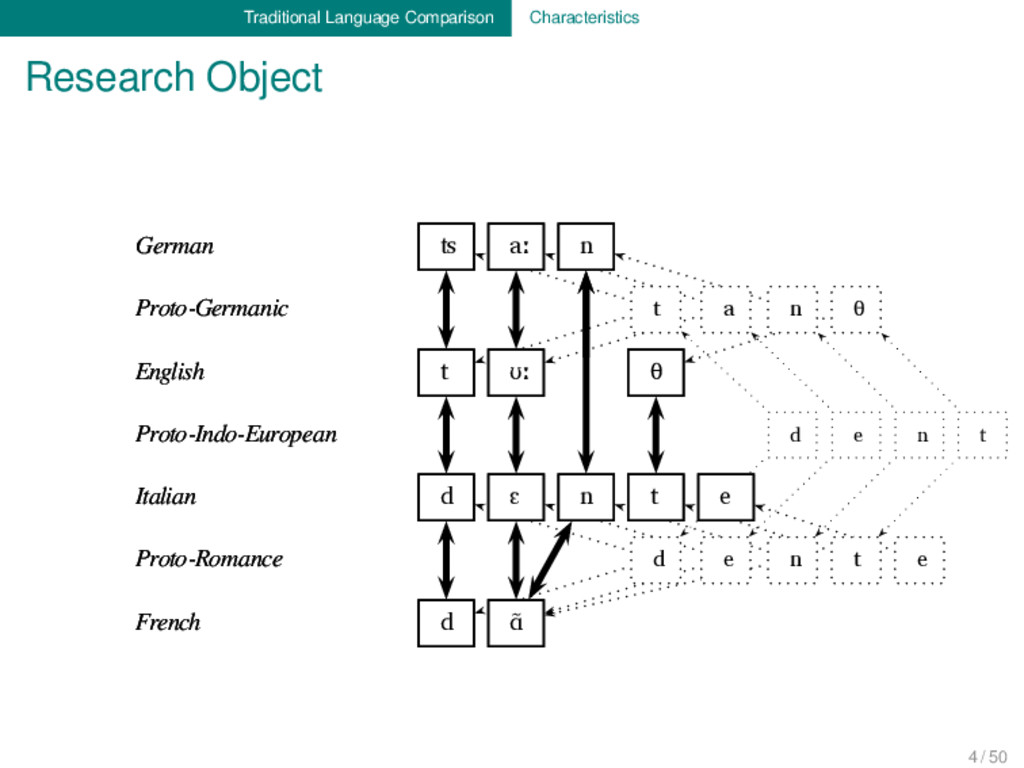
Proto-Germanic t a n θ English t ʊː θ Proto-Indo-European d e n t Italian d ɛ n t e Proto-Romance d e n t e French d ɑ̃ German ʦ aː n Proto-Germanic t a n θ English t ʊː θ Proto-Indo-European d e n t Italian d ɛ n t e Proto-Romance d e n t e French d ɑ̃ 1 4 / 50
change is independent of time and space “graduality of change” – change is neither abrupt nor chaotic “uniformity of change” – change is not heterogeneous, but uniform Founding Fathers Franz Bopp (1791–1867): language comparison (Bopp 1816) Rasmus Rask (1787-1832) and Jacob Grimm (1785-1863): sound law (Rask 1818, Grimm 1822) August Schleicher (1821–1868): family tree and linguistic reconstruction (Schleicher 1853 & 1861) 5 / 50
1925) Basic procedure for proving language relationship and reconstructing unattested ancestral language states, etymologies, and genetic classifications. Family Tree Model and Wave Theory (Schleicher 1853, Schmidt 1872) Two partially incompatible models to describe historical language relations. Regularity Hypothesis (Osthoff & Brugmann 1878) Fundamental working hypothesis that states that certain sound change processes proceed regularly (universally, gradually, and in a uniform manner). 7 / 50
historical linguistics, the history of a considerable (but still small) amount of languages has been thoroughly investigated. External Language History Thanks to historical linguistics, a considerable amount of the languages in the world has been genetically classified (although there remain many unsolved and controversially discussed questions). General Language History Some work on general processes of language history has been done, yet many questions still remain unsolved or are controversially debated. 8 / 50
“becoming” a competent Indo-Europeanist has always been recognized as coming to grasp “intuitively” concepts and types of changes in language so as to be able to pick and choose between alternative explanations for the history and development of specific features of the reconstructed language and its offspring. Schwink (1994) 10 / 50
std. (9. Jh.), mhd. vruht, ahd. fruht, as. fruht. Ent- lehnt aus l. frūctus m. gleicher Bedeutung (zu l. fruī “ge- nieße”). Das deutsche Wort ist Femininum geworden im Anschluß an die ti- Abstrakta wie Flucht² usw. Adjekti- ve: fruchtig, fruchtbar; Verb: (be-)fruchten. Ebenso nndl. vrucht, ne. fruit, nfrz. fruit, nschw. frukt, nnorw. frukt; frugal. (Kluge und Seebold 2002) 11 / 50
data for the lan- guages of the world is growing from day to day, while there are only a few historical linguists who are trained to carry out the comparison of these languages. It seems impossible to handle this task when relying only on the traditional, time- consuming manual procedures developed in tra- ditional historical linguistics. 12 / 50
linguistics has some clear shortcomings, such as a lack of transparency in methodology, the “philological” form of knowledge representation, and the questionable validity of certain results. 14 / 50
Warnow and Taylor 2002) “Language-tree divergence times support the Anatolian theory of Indo-European origin” (Gray und Atkinson 2003) “Language classification by numbers” (McMahon und McMahon 2005) “Curious Parallels and Curious Connections: Phylogenetic Thinking in Biology and Historical Linguistics” (Atkinson und Gray 2005) “Automated classification of the world’s languages” (Brown et al. 2008) “Computational Feature-Sensitive Reconstruction of Language Relationships: Developing the ALINE Distance for Comparative Historical Linguistic Reconstruction” (Downey et al. 2008) “Networks uncover hidden lexical borrowing in Indo-European language evolution” (Nelson-Sathi et al. 2011) “A pipeline for computational historical linguistics” (Steiner, Stadler, und Cysouw 2011) 17 / 50
reconstruction sequence comparison general questions of language development Primary Goal If we cannot guarantee getting the same results from the same data considered by different linguists, we jeopardize the essential scientific criterion of repeatability. (McMahon & McMahon 2005) 18 / 50
among others, Gray & Atkinson 2003 Ringe et al. 2002, Brown et al. 2008) phonetic alignment (cf., among others, Kondrak 2000, Prokić et al. 2009, List 2012a) cognate detection (cf. Steiner et al. 2011, List 2012b) borrowing detection (cf. Nelson-Sathi et al. 2011, List et al. 2014a) 19 / 50
more attention than before “Indo-Euro-Centrism” is replaced by a more cross-linguistic paradigm new questions regarding general language history new proposals to model language history 21 / 50
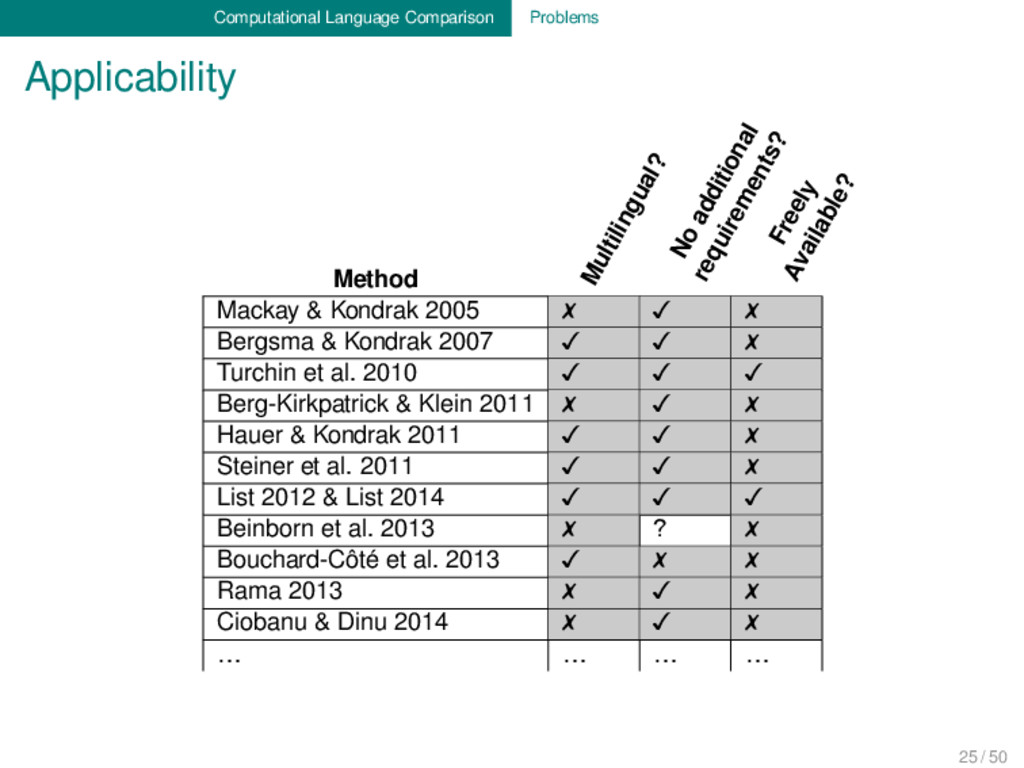
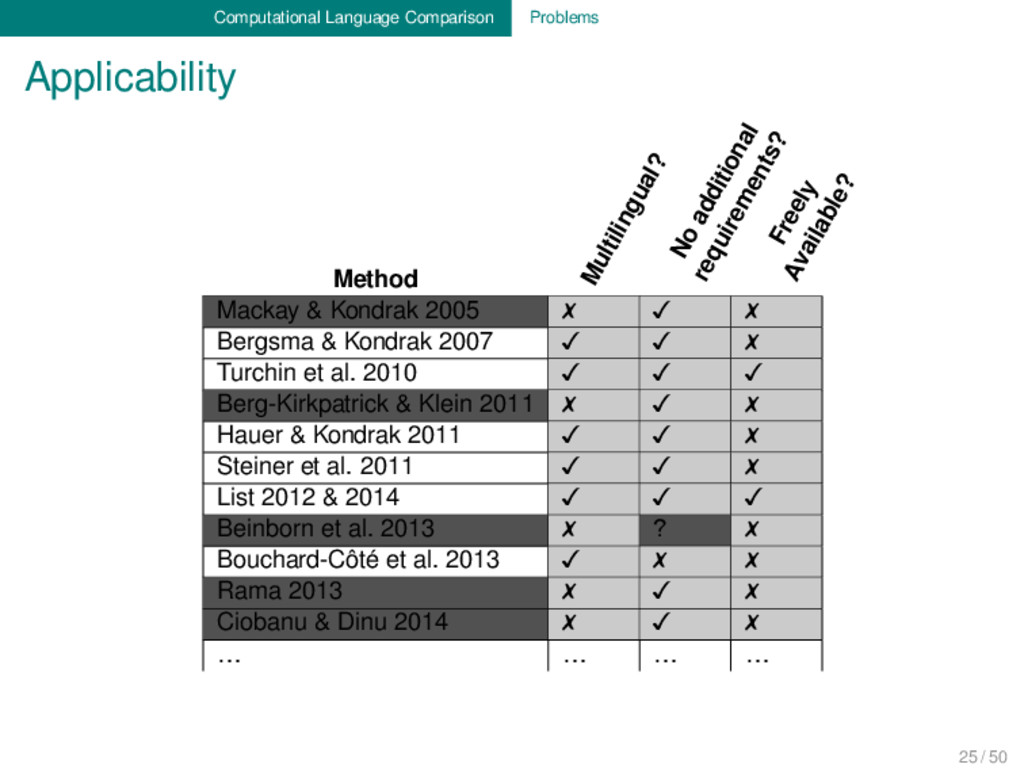
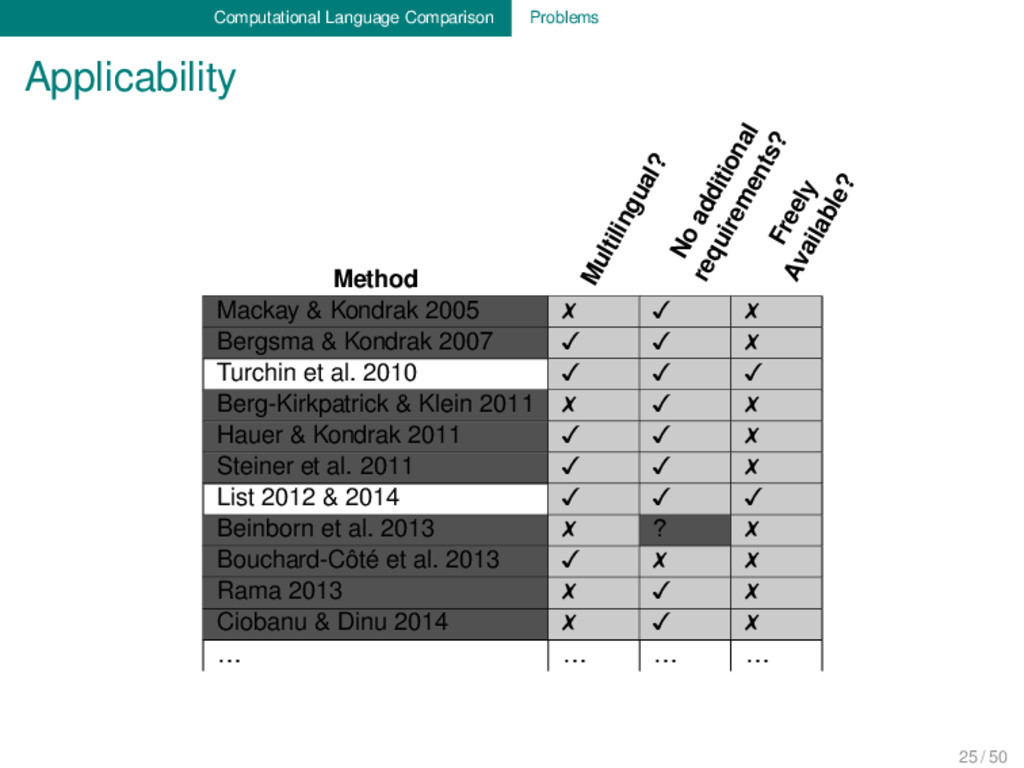
methods are not very intuitive and vary greatly. Benchmark databases are rarely used, especially in phylogenetic approaches eyeballing of phylogenetic trees is sold as proof for “valid approaches”. 24 / 50
methods are not very intuitive and vary greatly. Benchmark databases are rarely used, especially in phylogenetic approaches eyeballing of phylogenetic trees is sold as proof for “valid approaches”. It is difficult to communicate the results to traditional linguists. 24 / 50
methods are not very intuitive and vary greatly. Benchmark databases are rarely used, especially in phylogenetic approaches eyeballing of phylogenetic trees is sold as proof for “valid approaches”. It is difficult to communicate the results to traditional linguists. → Many linguists regard automatic approaches as 24 / 50
methods are not very intuitive and vary greatly. Benchmark databases are rarely used, especially in phylogenetic approaches eyeballing of phylogenetic trees is sold as proof for “valid approaches”. It is difficult to communicate the results to traditional linguists. → Many linguists regard automatic approaches as – not trustworthy and error-prone, or 24 / 50
methods are not very intuitive and vary greatly. Benchmark databases are rarely used, especially in phylogenetic approaches eyeballing of phylogenetic trees is sold as proof for “valid approaches”. It is difficult to communicate the results to traditional linguists. → Many linguists regard automatic approaches as – not trustworthy and error-prone, or – “impossible per se”, or 24 / 50
methods are not very intuitive and vary greatly. Benchmark databases are rarely used, especially in phylogenetic approaches eyeballing of phylogenetic trees is sold as proof for “valid approaches”. It is difficult to communicate the results to traditional linguists. → Many linguists regard automatic approaches as – not trustworthy and error-prone, or – “impossible per se”, or – as useful as “rolling a dice”. 24 / 50
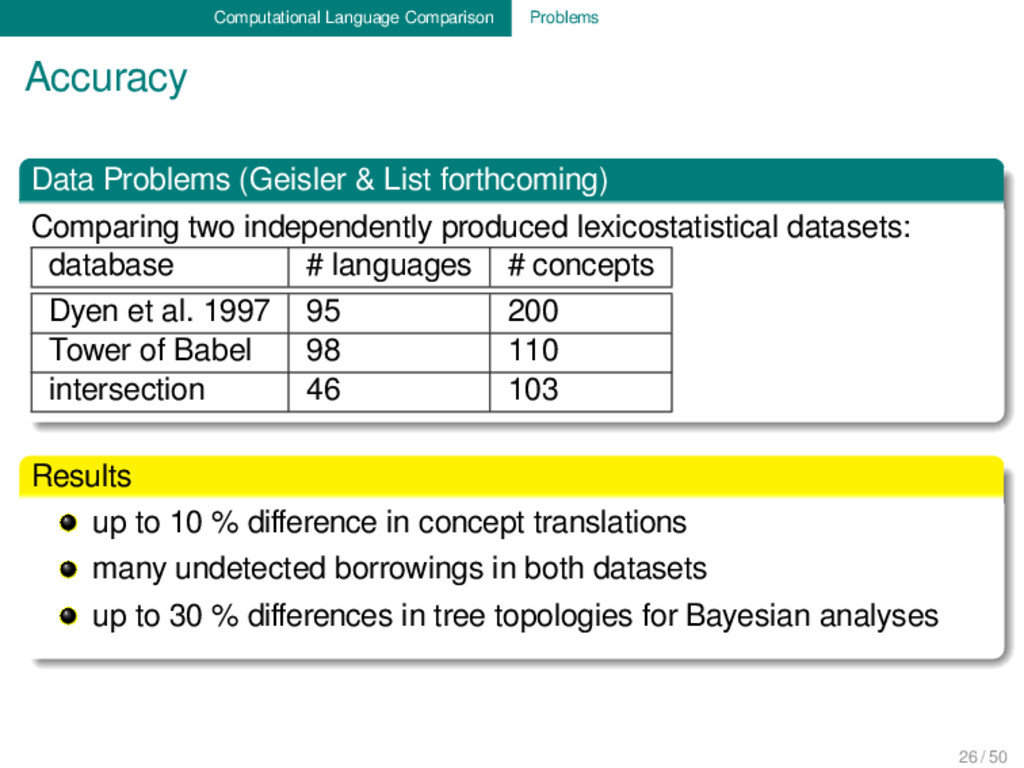
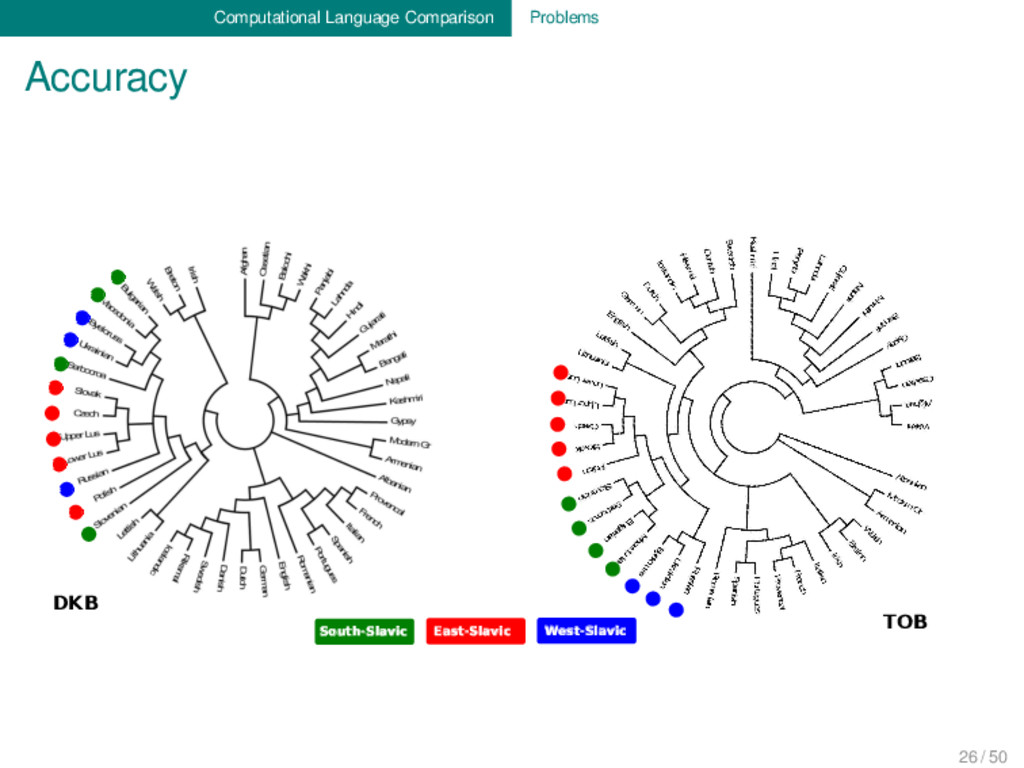
forthcoming) Comparing two independently produced lexicostatistical datasets: database # languages # concepts Dyen et al. 1997 95 200 Tower of Babel 98 110 intersection 46 103 Results up to 10 % difference in concept translations many undetected borrowings in both datasets up to 30 % differences in tree topologies for Bayesian analyses 26 / 50
based on manually compiled datasets cannot cope with errors resulting from inconsistent data compilation. They are only as objective as the data being fed to them! Many quantitative approaches are insufficiently tested, and scholars are often content with results traditional linguists would never accept. Additionally, quantitative approaches are often presented in a way that makes it hard (not only for traditional linguists) to understand what they are based upon. Results are reported in an intransparent way, supplementary data is often lacking, concrete examples are seldom provided and source code (essential to check and replicate analyses) is missing in almost all recent publications. 27 / 50
multiple types of evidence CONTRA: - has to sleep and rest - does not like to count and do boring work - can oversee facts when doing boring work CONTRA: - no intuition - no background knowledge - can't juggle with multiple types of evidence PRO: - doesn't need to sleep - is very good at counting and boring work - doesn't make errors in boring work P(A|B)=(P(B|A)P(A))/(P(B) FRANZ BOPP VERY, VERY LONG TITLE 28 / 50
multiple types of evidence CONTRA: - has to sleep and rest - does not like to count and do boring work - can oversee facts when doing boring work CONTRA: - no intuition - no background knowledge - can't juggle with multiple types of evidence PRO: - doesn't need to sleep - is very good at counting and boring work - doesn't make errors in boring work P(A|B)=(P(B|A)P(A))/(P(B) FRANZ BOPP VERY, VERY LONG TITLE 28 / 50
multiple types of evidence CONTRA: - has to sleep and rest - does not like to count and do boring work - can oversee facts when doing boring work CONTRA: - no intuition - no background knowledge - can't juggle with multiple types of evidence PRO: - doesn't need to sleep - is very good at counting and boring work - doesn't make errors in boring work P(A|B)=(P(B|A)P(A))/(P(B) FRANZ BOPP VERY, VERY LONG TITLE COMPUTER-ASSISTED LANGUAGE COMPARISON 28 / 50
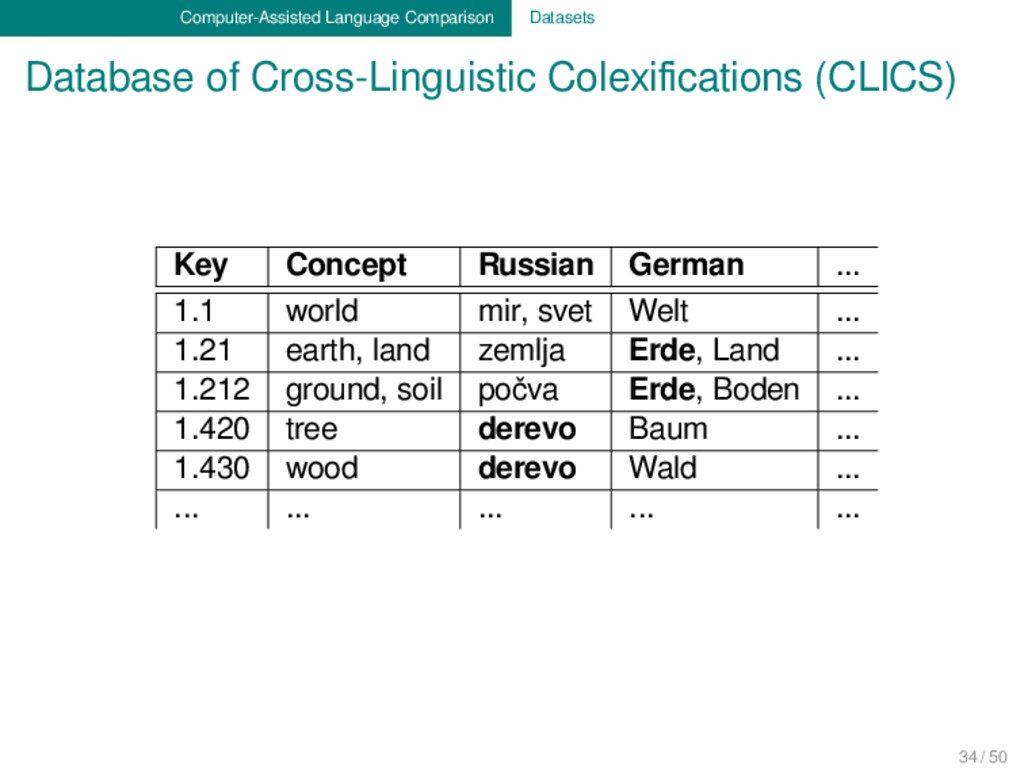
to publish a benchmark database for linguistic reconstruction in addition to the two benchmark databases mentioned before. Due to all different kinds of problems, this undertaking was delayed ever since I started to collect the first datasets. In the future, the initial ideas for the benchmark, along with the datasets created so far, will be included as part a larger collaborative effort to launch a database for cross-linguistic historical phonology (PhonoBank, MPI Jena). 33 / 50
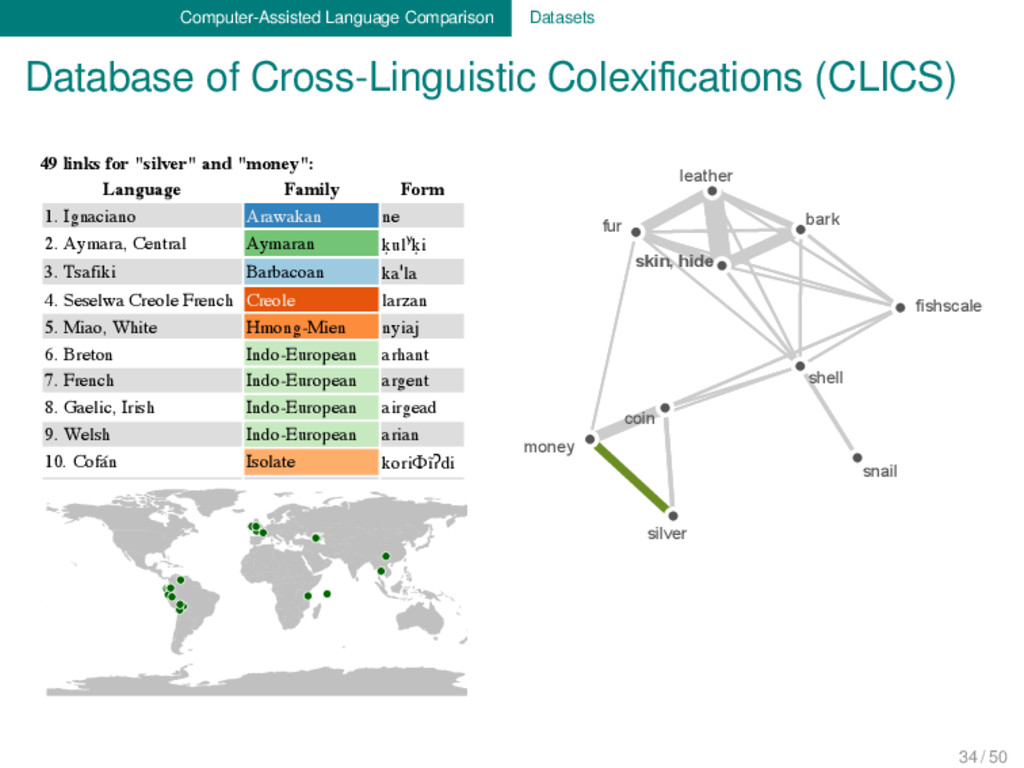
"money" is part of a cluster with the central concept "fishscale" with a total of 10 nodes. Hover over forms for each link. Click on the forms to check their sources. Click HERE to export the current network. ity: Line weights: Coloring: Family silver leather fishscale bark coin fur snail skin, hide money shell 49 links for "silver" and "money": Language Family Form 1. Ignaciano Arawakan ne 2. Aymara, Central Aymaran ḳulʸḳi 3. Tsafiki Barbacoan kaˈla 4. Seselwa Creole French Creole larzan 5. Miao, White Hmong-Mien nyiaj 6. Breton Indo-European arhant 7. French Indo-European argent 8. Gaelic, Irish Indo-European airgead 9. Welsh Indo-European arian 10. Cofán Isolate koriΦĩʔdi 34 / 50
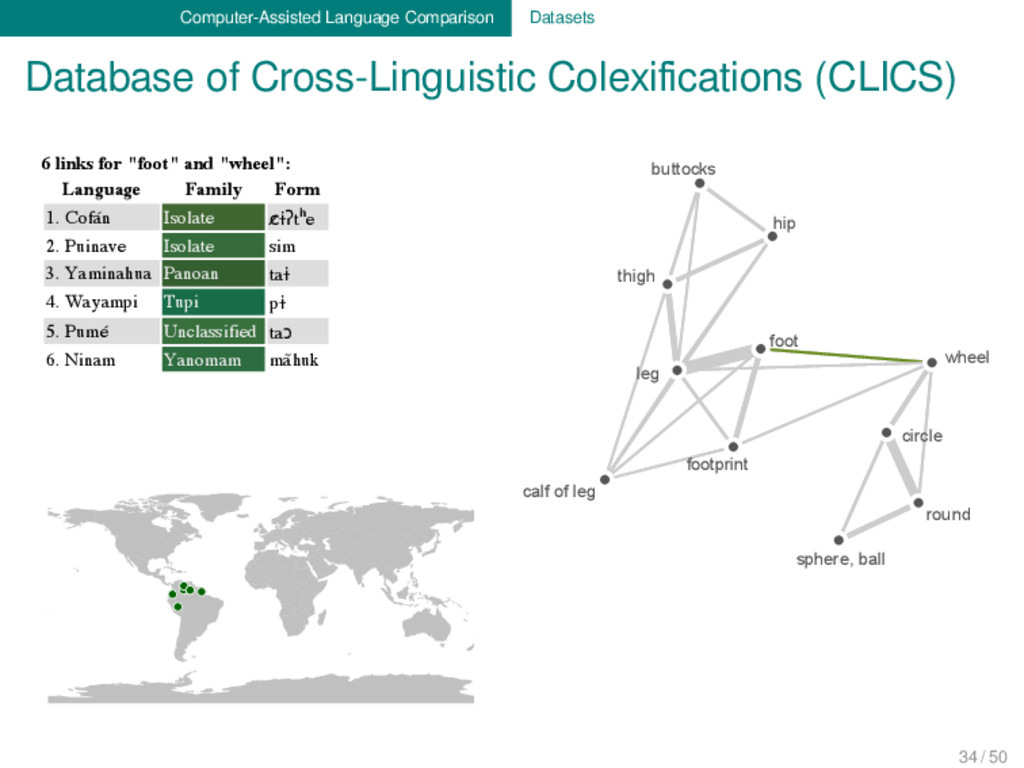
"wheel" is part of a cluster with the central concept "leg" with a total of 11 nodes. Hover over the e each link. Click on the forms to check their sources. Click HERE to export the current network. ity: Line weights: Coloring: Geolocation sphere, ball round footprint foot calf of leg circle thigh wheel leg hip buttocks 6 links for "foot" and "wheel": Language Family Form 1. Cofán Isolate c̷ɨʔtʰe 2. Puinave Isolate sim 3. Yaminahua Panoan taɨ 4. Wayampi Tupi pɨ 5. Pumé Unclassified taɔ 6. Ninam Yanomam mãhuk 34 / 50
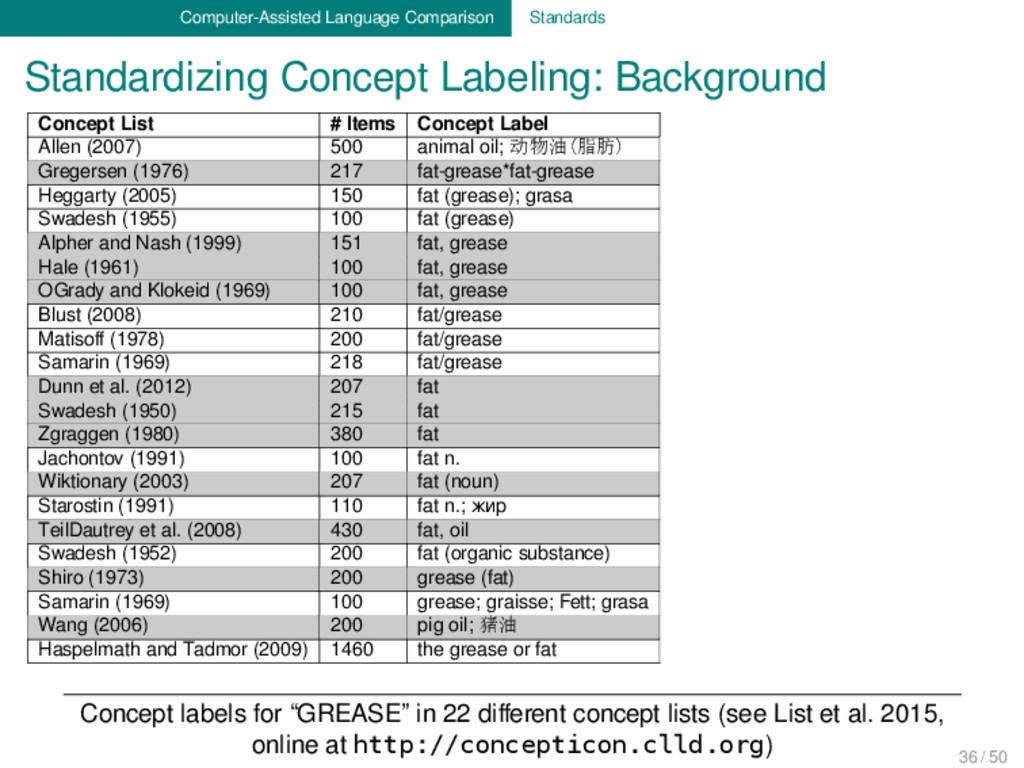
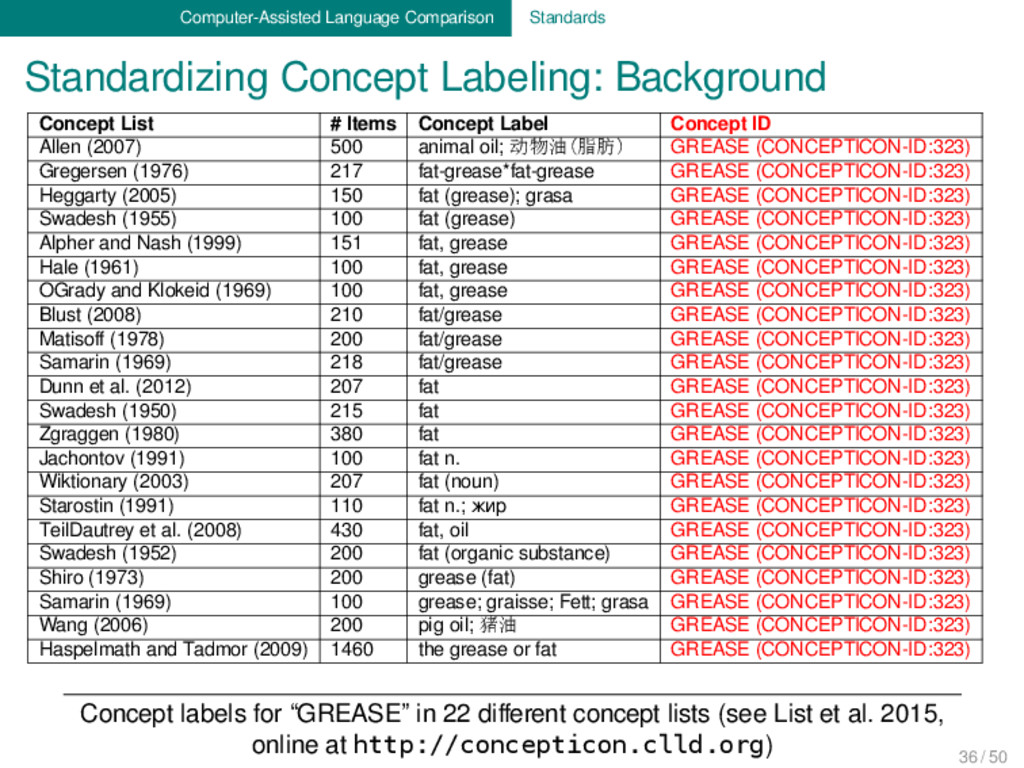
Concepticon is an attempt to link the many different con- cept lists (“Swadesh Lists”) which are used in the linguistic lite- rature. In practice, all entries from the various concept lists are linked to a concept set as an intermediate way to reference the concepts. The Concepticon links 9611 concepts from 51 concept lists to 2206 concept sets and defines 243 relations between the concept sets. List, Cysouw & Forkel (2015): Concepticon. Version 0.1, http:// concepticon.clld.org. 37 / 50
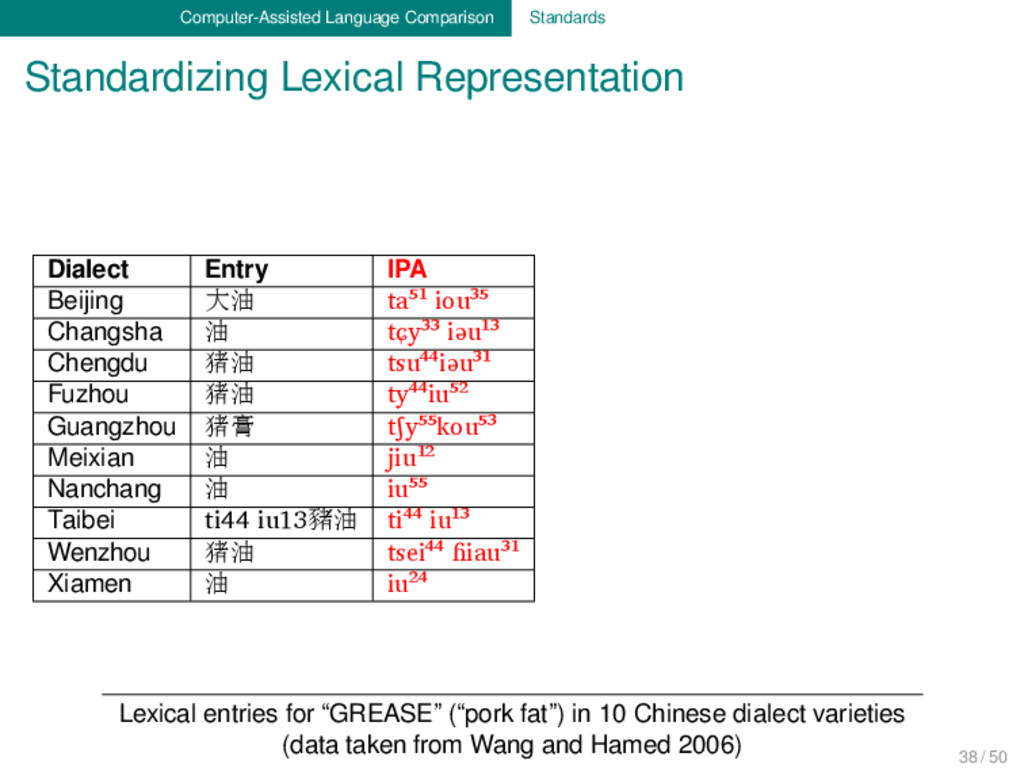
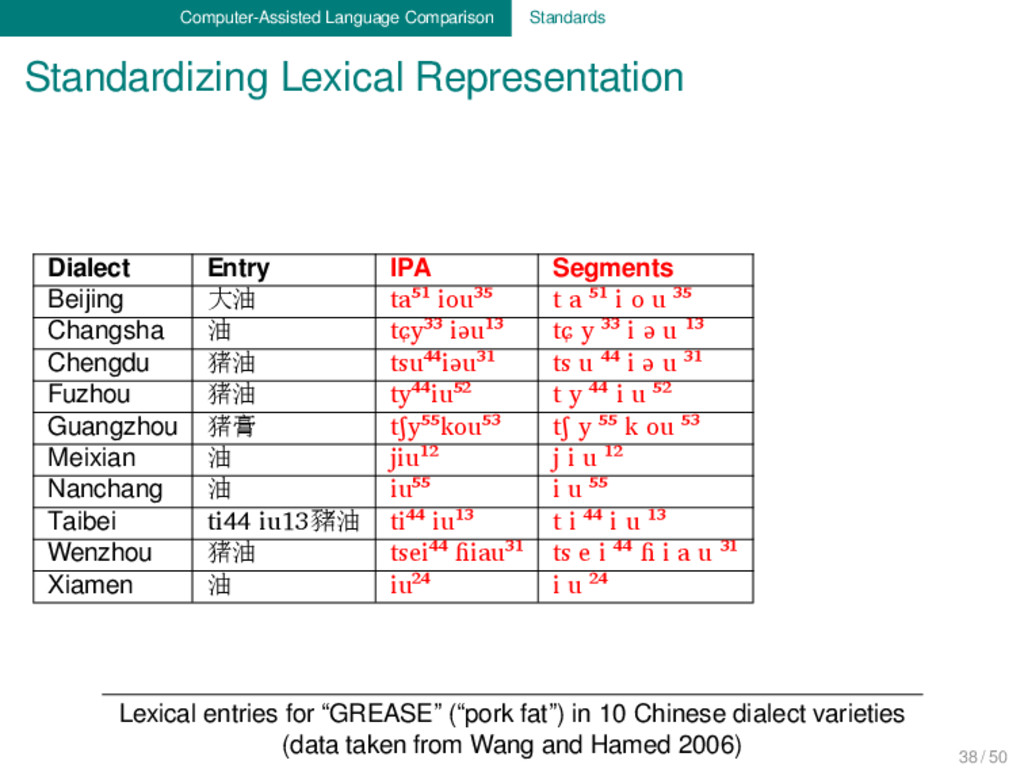
Segments Morphemes Beijing 大油 ta⁵¹ iou³⁵ t a ⁵¹ i o u ³⁵ t a ⁵¹ + i o u ³⁵ Changsha 油 tɕy³³ iəu¹³ tɕ y ³³ i ə u ¹³ tɕ y ³³ + i ə u ¹³ Chengdu 猪油 tsu⁴⁴iəu³¹ ts u ⁴⁴ i ə u ³¹ ts u ⁴⁴ + i ə u ³¹ Fuzhou 猪油 ty⁴⁴iu⁵² t y ⁴⁴ i u ⁵² t y ⁴⁴ + i u ⁵² Guangzhou 猪膏 tʃy⁵⁵kou⁵³ tʃ y ⁵⁵ k ou ⁵³ tʃ y ⁵⁵ + k ou ⁵³ Meixian 油 jiu¹² j i u ¹² j i u ¹ ² Nanchang 油 iu⁵⁵ i u ⁵⁵ i u ⁵⁵ Taibei ti44 iu13豬油 ti⁴⁴ iu¹³ t i ⁴⁴ i u ¹³ t i ⁴⁴ + i u ¹³ Wenzhou 猪油 tsei⁴⁴ ɦiau³¹ ts e i ⁴⁴ ɦ i a u ³¹ ts e i +⁴⁴ ɦ i a u ³¹ Xiamen 油 iu²⁴ i u ²⁴ i u ²⁴ Lexical entries for “GREASE” (“pork fat”) in 10 Chinese dialect varieties (data taken from Wang and Hamed 2006) 38 / 50
“GREASE” (“pork fat”) in 10 Chinese dialect varieties (data taken from Wang and Hamed 2006) Dialect Entry IPA Segments Morphemes Beijing 大油 ta⁵¹ iou³⁵ t a ⁵¹ i o u ³⁵ t a ⁵¹ + i o u ³⁵ Changsha 油 tɕy³³ iəu¹³ tɕ y ³³ i ə u ¹³ tɕ y ³³ + i ə u ¹³ Chengdu 猪油 tsu⁴⁴iəu³¹ ts u ⁴⁴ i ə u ³¹ ts u ⁴⁴ + i ə u ³¹ Fuzhou 猪油 ty⁴⁴iu⁵² t y ⁴⁴ i u ⁵² t y ⁴⁴ + i u ⁵² Guangzhou 猪膏 tʃy⁵⁵kou⁵³ tʃ y ⁵⁵ k ou ⁵³ tʃ y ⁵⁵ + k ou ⁵³ Meixian 油 jiu¹² j i u ¹² j i u ¹ ² Nanchang 油 iu⁵⁵ i u ⁵⁵ i u ⁵⁵ Taibei ti44 iu13豬油 ti⁴⁴ iu¹³ t i ⁴⁴ i u ¹³ t i ⁴⁴ + i u ¹³ Wenzhou 猪油 tsei⁴⁴ ɦiau³¹ ts e i ⁴⁴ ɦ i a u ³¹ ts e i ⁴⁴ + ɦ i a u ³¹ Xiamen 油 iu²⁴ i u ²⁴ i u ²⁴ 38 / 50
“GREASE” (“pork fat”) in 10 Chinese dialect varieties (data taken from Wang and Hamed 2006) Dialect Entry IPA Segments Morphemes Beijing 大油 ta⁵¹ iou³⁵ t a ⁵¹ i o u ³⁵ t a ⁵¹ + i o u ³⁵ Changsha 油 tɕy³³ iəu¹³ tɕ y ³³ i ə u ¹³ tɕ y ³³ + i ə u ¹³ Chengdu 猪油 tsu⁴⁴iəu³¹ ts u ⁴⁴ i ə u ³¹ ts u ⁴⁴ + i ə u ³¹ Fuzhou 猪油 ty⁴⁴iu⁵² t y ⁴⁴ i u ⁵² t y ⁴⁴ + i u ⁵² Guangzhou 猪膏 tʃy⁵⁵kou⁵³ tʃ y ⁵⁵ k ou ⁵³ tʃ y ⁵⁵ + k ou ⁵³ Meixian 油 jiu¹² j i u ¹² j i u ¹ ² Nanchang 油 iu⁵⁵ i u ⁵⁵ i u ⁵⁵ Taibei ti44 iu13豬油 ti⁴⁴ iu¹³ t i ⁴⁴ i u ¹³ t i ⁴⁴ + i u ¹³ Wenzhou 猪油 tsei⁴⁴ ɦiau³¹ ts e i ⁴⁴ ɦ i a u ³¹ ts e i +⁴⁴ ɦ i a u ³¹ Xiamen 油 iu²⁴ i u ²⁴ i u ²⁴ 38 / 50
“GREASE” (“pork fat”) in 10 Chinese dialect varieties (data taken from Wang and Hamed 2006) Dialect Entry IPA Segments Morphemes Beijing 大油 ta⁵¹ iou³⁵ t a ⁵¹ i o u ³⁵ t a ⁵¹ + i o u ³⁵ Changsha 油 tɕy³³ iəu¹³ tɕ y ³³ i ə u ¹³ tɕ y ³³ + i ə u ¹³ Chengdu 猪油 tsu⁴⁴iəu³¹ ts u ⁴⁴ i ə u ³¹ ts u ⁴⁴ + i ə u ³¹ Fuzhou 猪油 ty⁴⁴iu⁵² t y ⁴⁴ i u ⁵² t y ⁴⁴ + i u ⁵² Guangzhou 猪膏 tʃy⁵⁵kou⁵³ tʃ y ⁵⁵ k ou ⁵³ tʃ y ⁵⁵ + k ou ⁵³ Meixian 油 jiu¹² j i u ¹² j i u ¹ ² Nanchang 油 iu⁵⁵ i u ⁵⁵ i u ⁵⁵ Taibei ti44 iu13豬油 ti⁴⁴ iu¹³ t i ⁴⁴ i u ¹³ t i ⁴⁴ + i u ¹³ Wenzhou 猪油 tsei⁴⁴ ɦiau³¹ ts e i ⁴⁴ ɦ i a u ³¹ ts e i ⁴⁴ + ɦ i a u ³¹ Xiamen 油 iu²⁴ i u ²⁴ i u ²⁴ 38 / 50
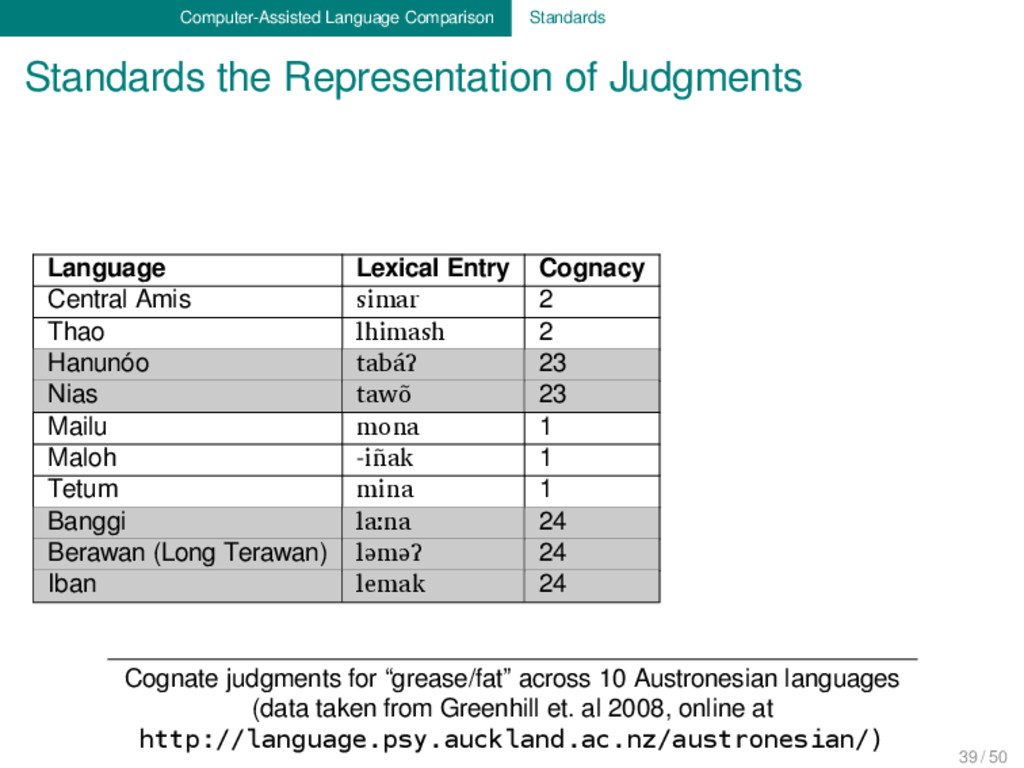
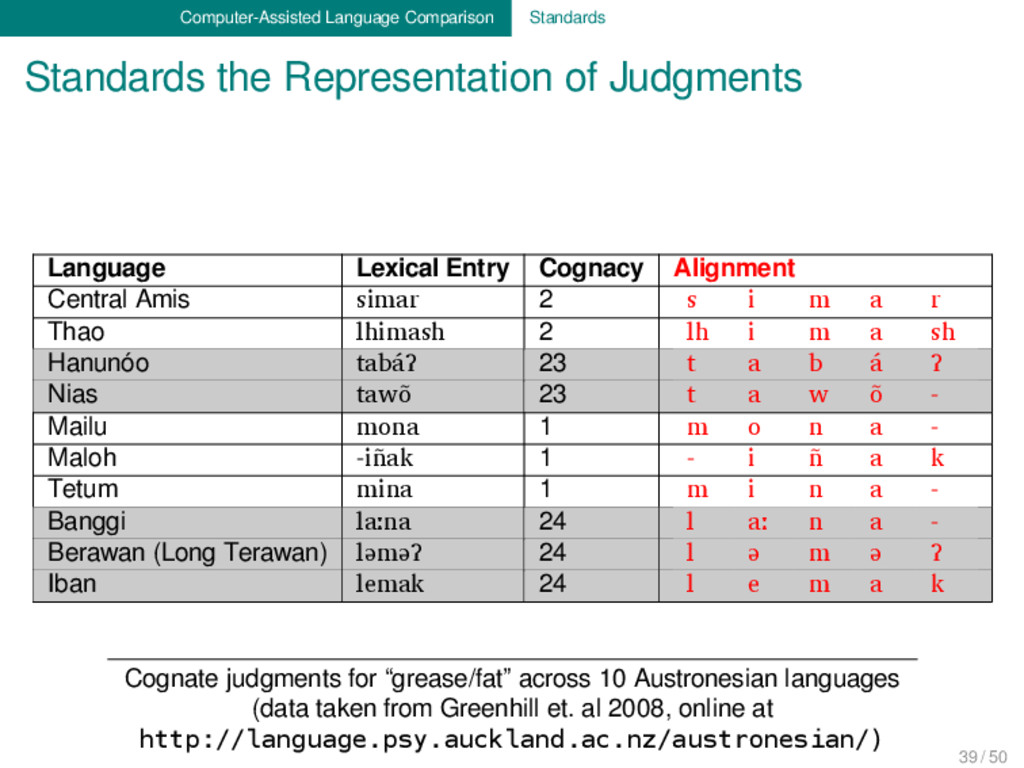
Lexical Entry Cognacy Alignment Central Amis simar 2 s i m a r Thao lhimash 2 lh i m a sh Hanunóo tabáʔ 23 t a b á ʔ Nias tawõ 23 t a w õ - Mailu mona 1 m o n a - Maloh -iñak 1 - i ñ a k Tetum mina 1 m i n a - Banggi laːna 24 l aː n a - Berawan (Long Terawan) ləməʔ 24 l ə m ə ʔ Iban lemak 24 l e m a k Cognate judgments for “grease/fat” across 10 Austronesian languages (data taken from Greenhill et. al 2008, online at http://language.psy.auckland.ac.nz/austronesian/) 39 / 50
judgments for “grease/fat” across 10 Austronesian languages (data taken from Greenhill et. al 2008, online at http://language.psy.auckland.ac.nz/austronesian/) Language Lexical Entry Cognacy Alignment Central Amis simar 2 s i m a r Thao lhimash 2 lh i m a sh Hanunóo tabáʔ 23 t a b á ʔ Nias tawõ 23 t a w õ - Mailu mona 1 m o n a - Maloh -iñak 1 - i ñ a k Tetum mina 1 m i n a - Banggi laːna 24 l aː n a - Berawan (Long Terawan) ləməʔ 24 l ə m ə ʔ Iban lemak 24 l e m a k 39 / 50
The Jena Wordlist Standard is being developed by the NESCent style working group “GlottoBank: Towards a Global Language Phylogeny” under the direction of Russel Gray 40 / 50
Standard is being developed by the NESCent style working group “GlottoBank: Towards a Global Language Phylogeny” under the direction of Russel Gray JENA WORDLIST STANDARD DEFINE STANDARDS FOR - Wordlists - Cognate Sets - Alignments PROVIDE TOOLS FOR - Data Validation - Data Exchange - Data Enrichment 40 / 50
Standard is being developed by the NESCent style working group “GlottoBank: Towards a Global Language Phylogeny” under the direction of Russel Gray JENA WORDLIST STANDARD arbitrarité Glottolog http://glottolog.clld.org Phoible http://phoible.clld.org CONCEPTICON http://concepticon.clld.org [ˈfɔi.bł] INTEGRATE EXISTING STANDARDS 40 / 50
Standard is being developed by the NESCent style working group “GlottoBank: Towards a Global Language Phylogeny” under the direction of Russel Gray PROVIDE TOOLS FOR EDITING AND ANALYSIS LingPy http://lingpy.org TSV EDICTOR http://tsv.lingpy.org JENA WORDLIST STANDARD 40 / 50
Standard is being developed by the NESCent style working group “GlottoBank: Towards a Global Language Phylogeny” under the direction of Russel Gray JENA WORDLIST STANDARD LexiBank - Cross-Linguistic Database of Lexical Cognate Sets PhonoBank - Cross-Linguistic Database of Regular Sound Change Patterns USE THE STANDARD TO BUILD NEW DATABASES 40 / 50
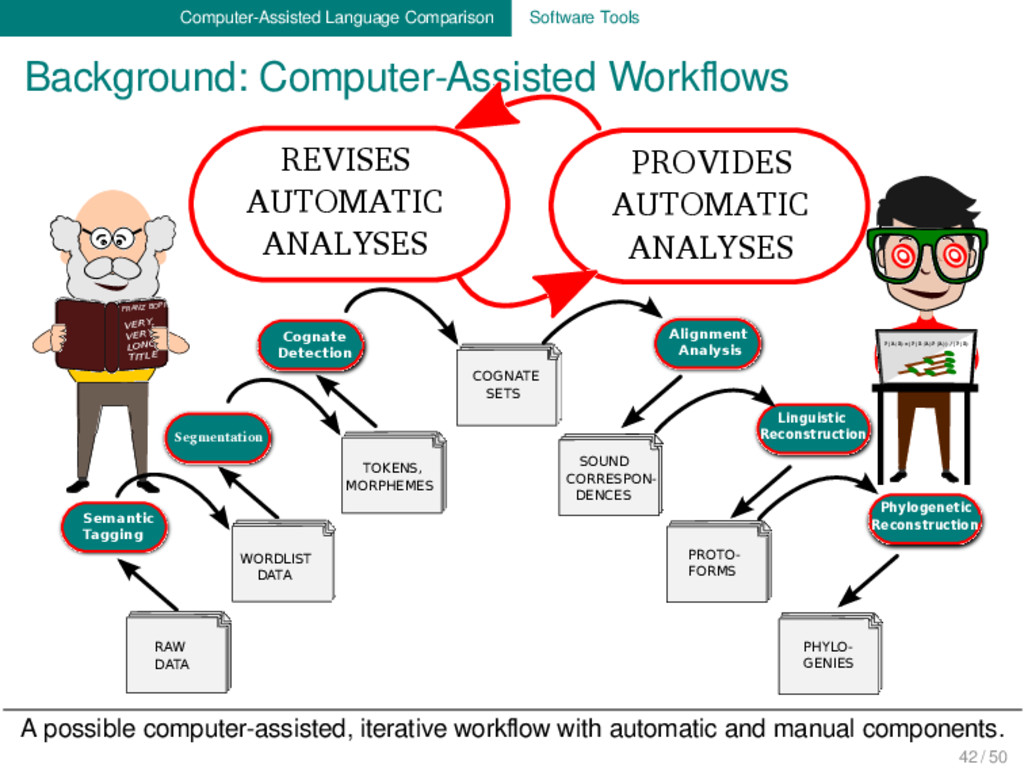
BOPP VERY, VERY LONG TITLE Semantic Tagging Segmentation Cognate Detection Alignment Analysis Linguistic Reconstruction Phylogenetic Reconstruction HAND [hænd] FOOT [fʊt] EARTH [ɜːrθ] TREE [triː] BARK [bɑːrk] RAW DATA HAND [hænd] FOOT [fʊt] EARTH [ɜːrθ] TREE [triː] BARK [bɑːrk] WORDLIST DATA HAND [hænd] FOOT [fʊt] EARTH [ɜːrθ] TREE [triː] BARK [bɑːrk] TOKENS, MORPHEMES HAND [hænd] FOOT [fʊt] EARTH [ɜːrθ] TREE [triː] BARK [bɑːrk] COGNATE SETS HAND [hænd] FOOT [fʊt] EARTH [ɜːrθ] TREE [triː] BARK [bɑːrk] SOUND CORRESPON- DENCES HAND [hænd] FOOT [fʊt] EARTH [ɜːrθ] TREE [triː] BARK [bɑːrk] PROTO- FORMS HAND [hænd] FOOT [fʊt] EARTH [ɜːrθ] TREE [triː] BARK [bɑːrk] PHYLO- GENIES PROVIDES AUTOMATIC ANALYSES REVISES AUTOMATIC ANALYSES A possible computer-assisted, iterative workflow with automatic and manual components. 42 / 50
EDICTOR: Two tools for computer-assisted language comparison. TSV LingPy http://lingpy.org Online Tool for Computer- Assisted Language Comparison - server- and client-based - data validation - phonetic segmentation - cognate set editor - alignment editor - correspondence evaluation 43 / 50
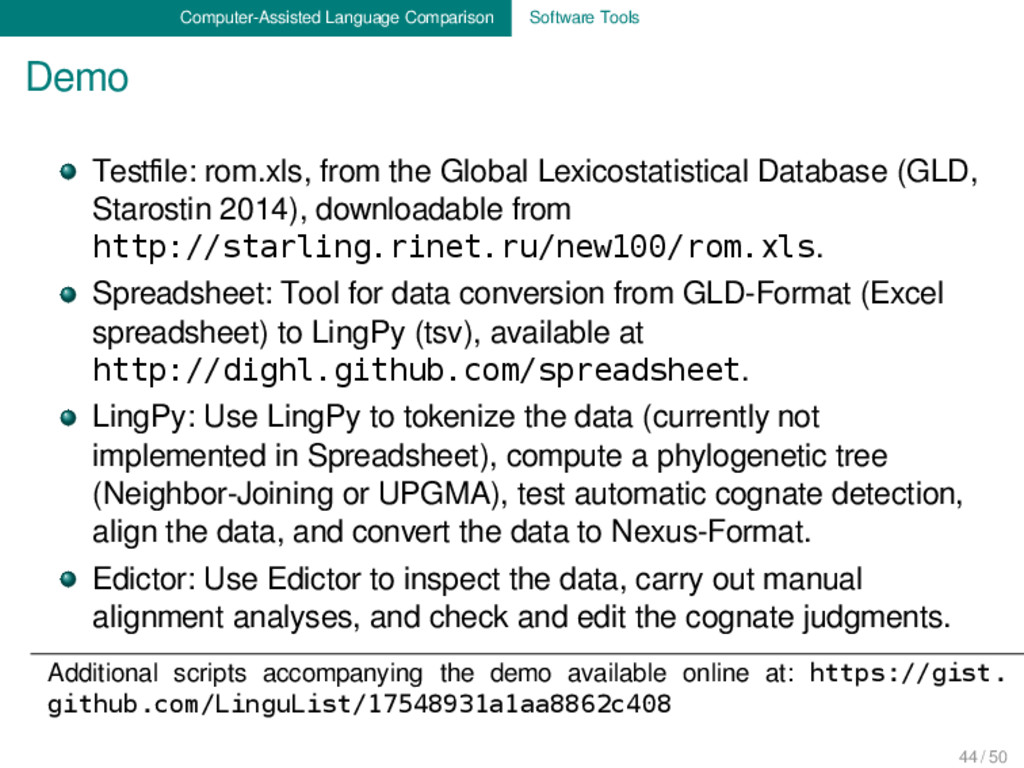
Global Lexicostatistical Database (GLD, Starostin 2014), downloadable from http://starling.rinet.ru/new100/rom.xls. Spreadsheet: Tool for data conversion from GLD-Format (Excel spreadsheet) to LingPy (tsv), available at http://dighl.github.com/spreadsheet. LingPy: Use LingPy to tokenize the data (currently not implemented in Spreadsheet), compute a phylogenetic tree (Neighbor-Joining or UPGMA), test automatic cognate detection, align the data, and convert the data to Nexus-Format. Edictor: Use Edictor to inspect the data, carry out manual alignment analyses, and check and edit the cognate judgments. Additional scripts accompanying the demo available online at: https://gist. github.com/LinguList/17548931a1aa8862c408 44 / 50
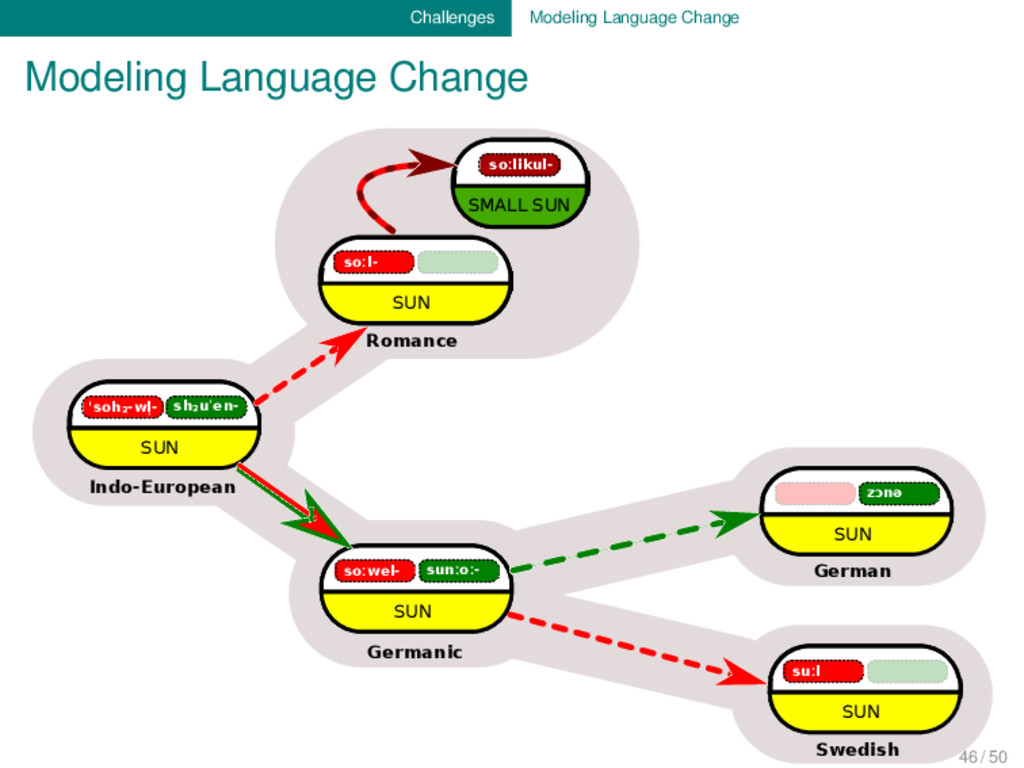
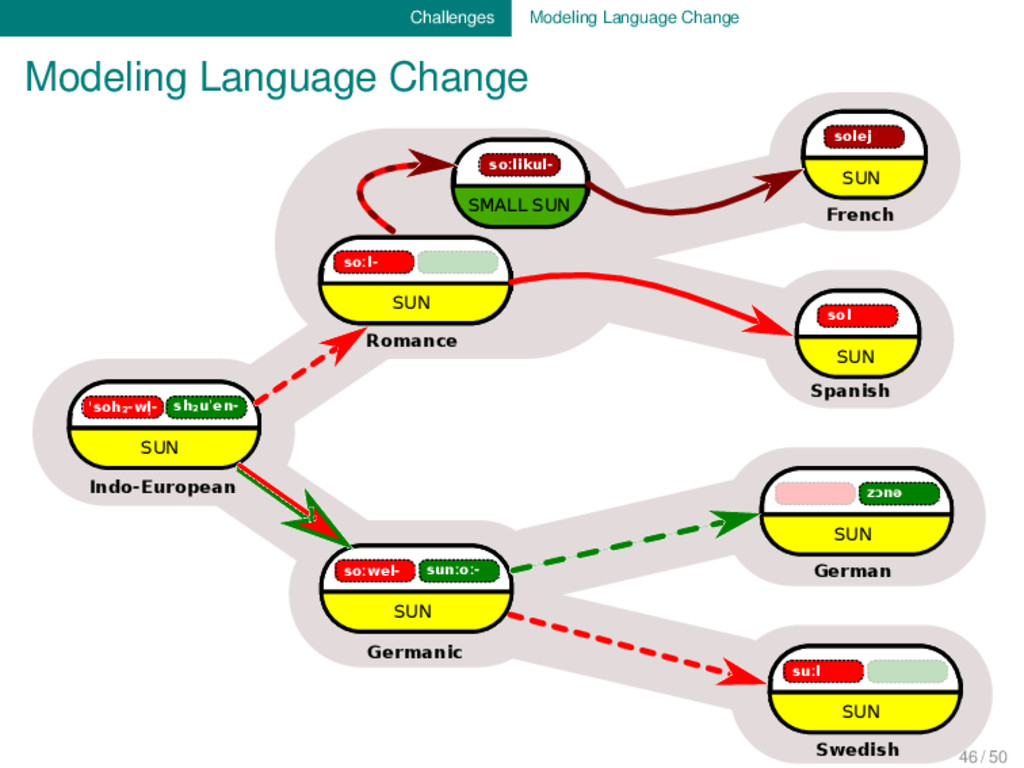
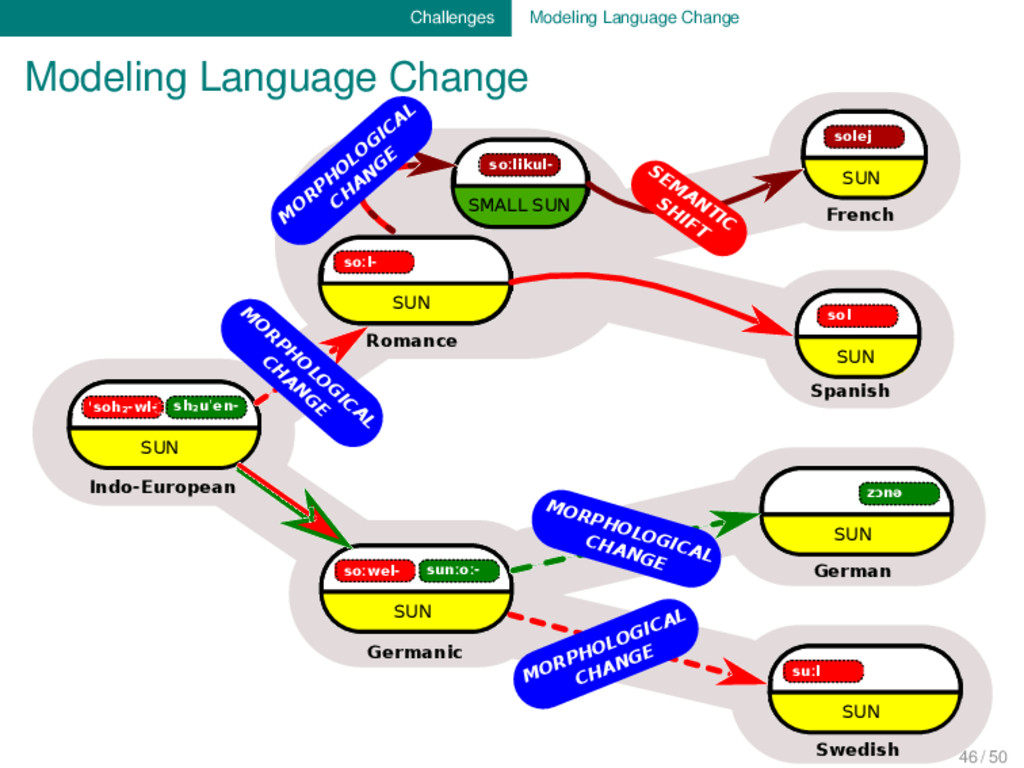
Indo-European soːwel- sunːoː- SUN Germanic soːl- SUN soːlikul- SMALL SUN Romance solej SUN French sol SUN Spanish zɔnə SUN German suːl SUN Swedish 46 / 50
SUN Indo-European soːwel- sunːoː- SUN Germanic soːl- SUN soːlikul- SMALL SUN Romance solej SUN French sol SUN Spanish zɔnə SUN German suːl SUN Swedish SEM ANTIC SHIFT M O RPH O LO G ICAL CH AN G E M O R PH O LO G ICA L CH A N G E MORPHOLOGICAL CHANGE MORPHOLOGICAL CHANGE 46 / 50
linguistic databases mostly model the relati- ons between different linguistic entities (cognacy, borrowing, etc.). To fully reflect what is “philologically” encoded in ety- mological dictionaries, however, we need to start thinking of how to model processes. 46 / 50
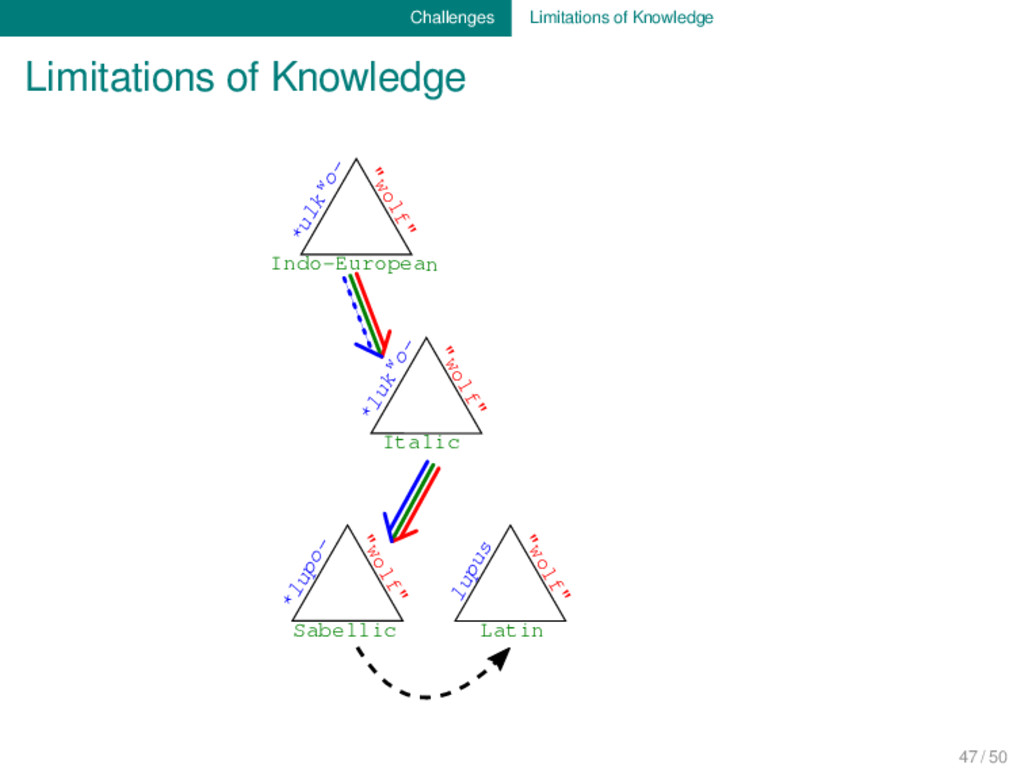
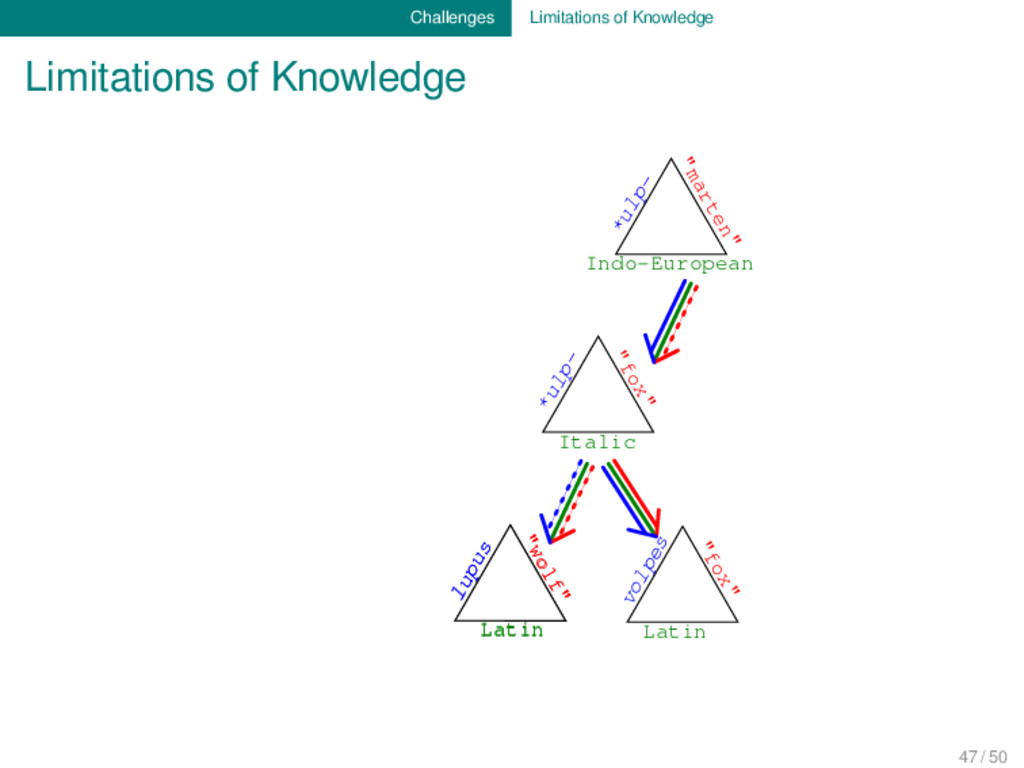
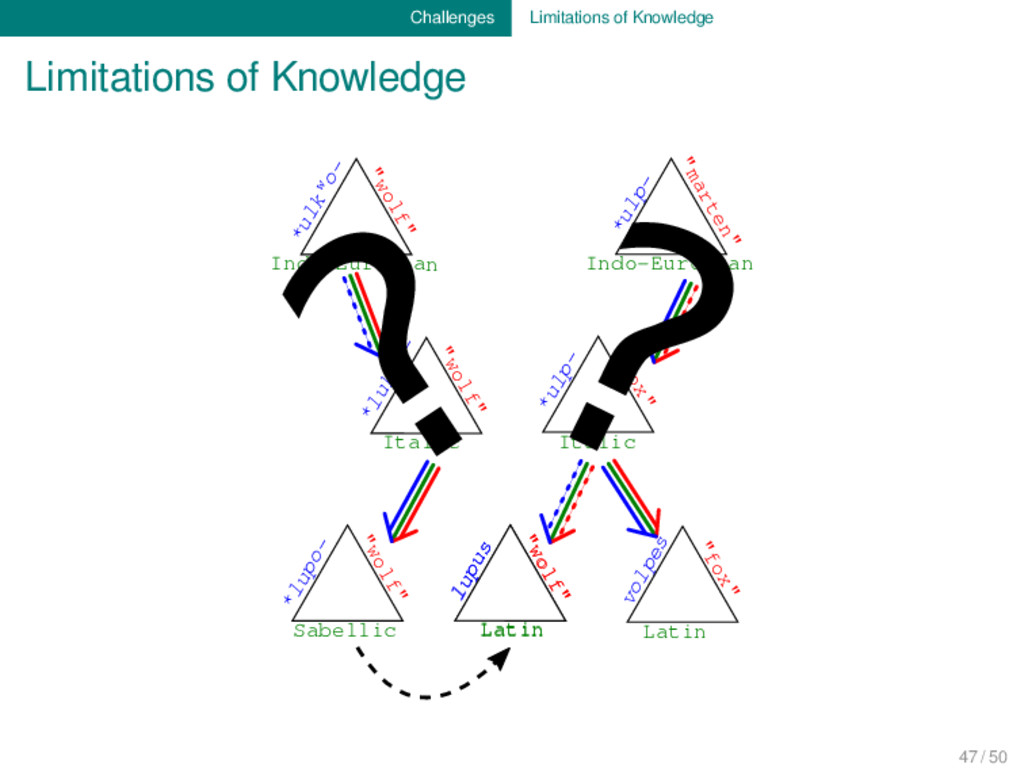
algorithms are getting better and better at modeling uncertainties, our databases still give the impression as if they represented fully proven facts. We need to find a way to include uncertainties when modeling and representing our data. 47 / 50
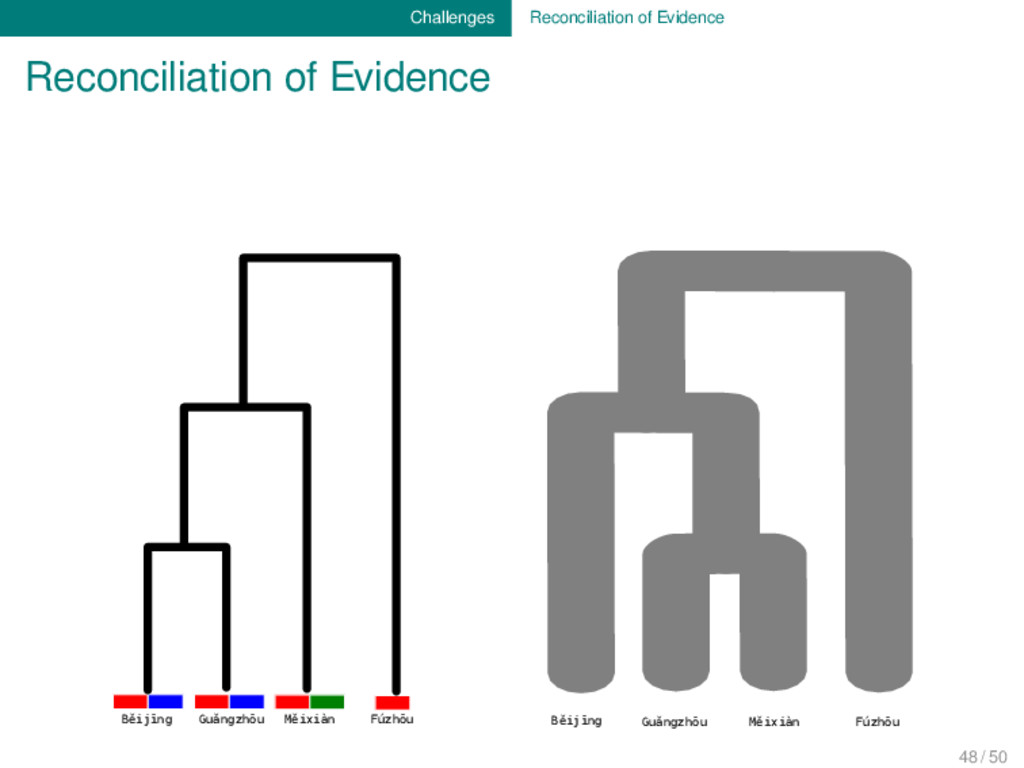
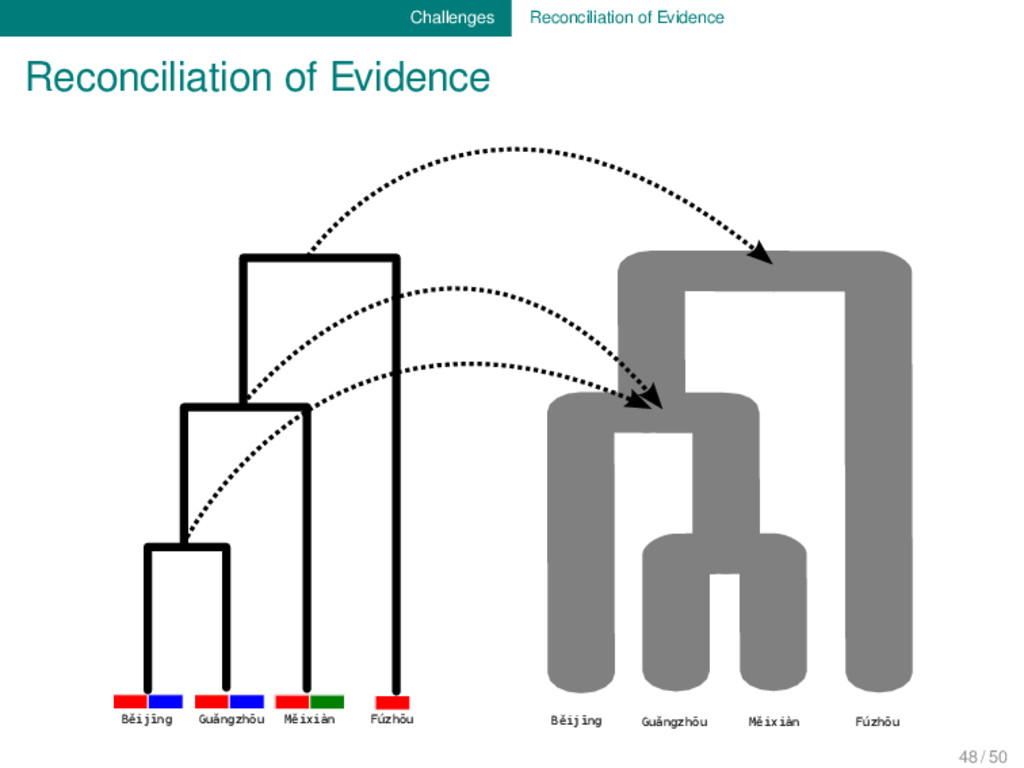
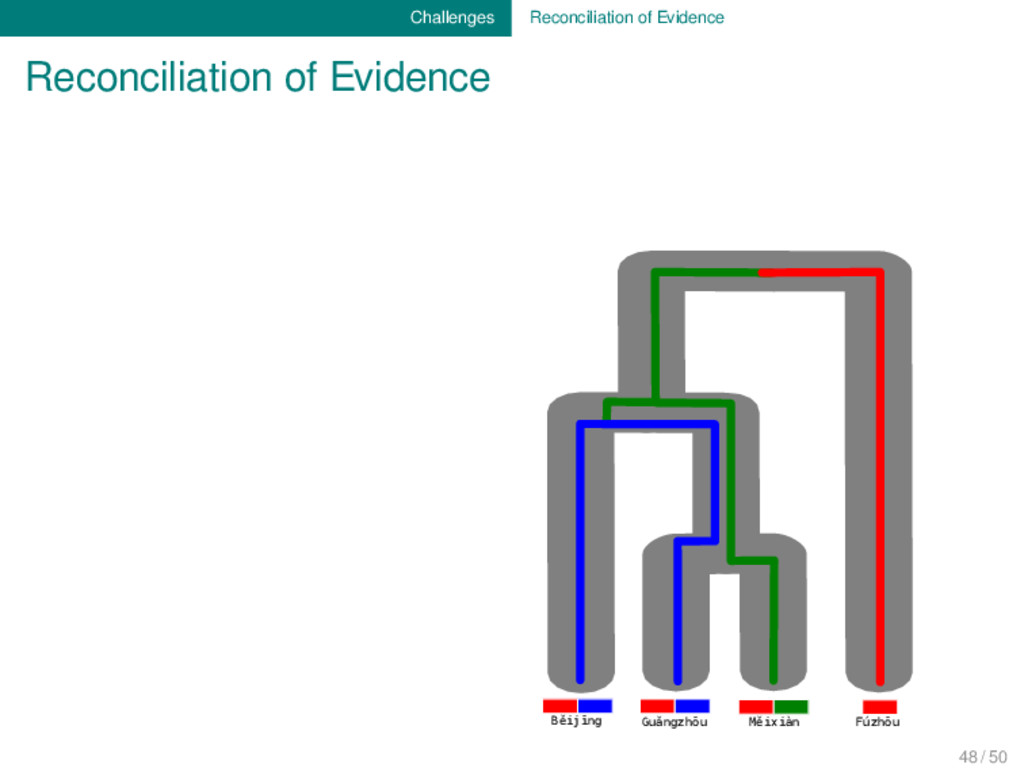
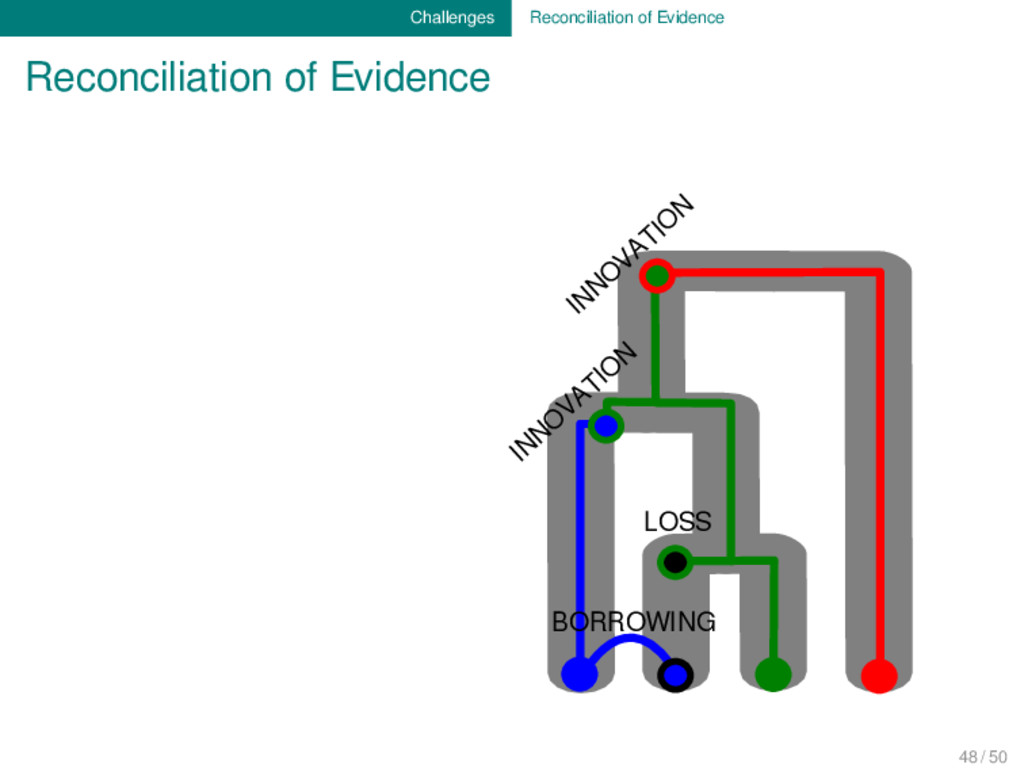
body of data which has been accumu- lated during the last two centuries of research, we are still far away from being able to sufficiently reconcile all the different types of evidence which are important for our discipline. 48 / 50
Concluding Remarks The possibilities for research in historical linguistics are nowadays greater than ever before. But so are our challenges. In order to be up to the job, we cannot do without computers, but likewise, we cannot do wi- thout the intuition and experience of trai- ned historical linguists. What we further need are combined efforts of standardiza- tion and knowledge exchange. We need to bridge disciplines and break down the frontiers between different schools. 50 / 50
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}