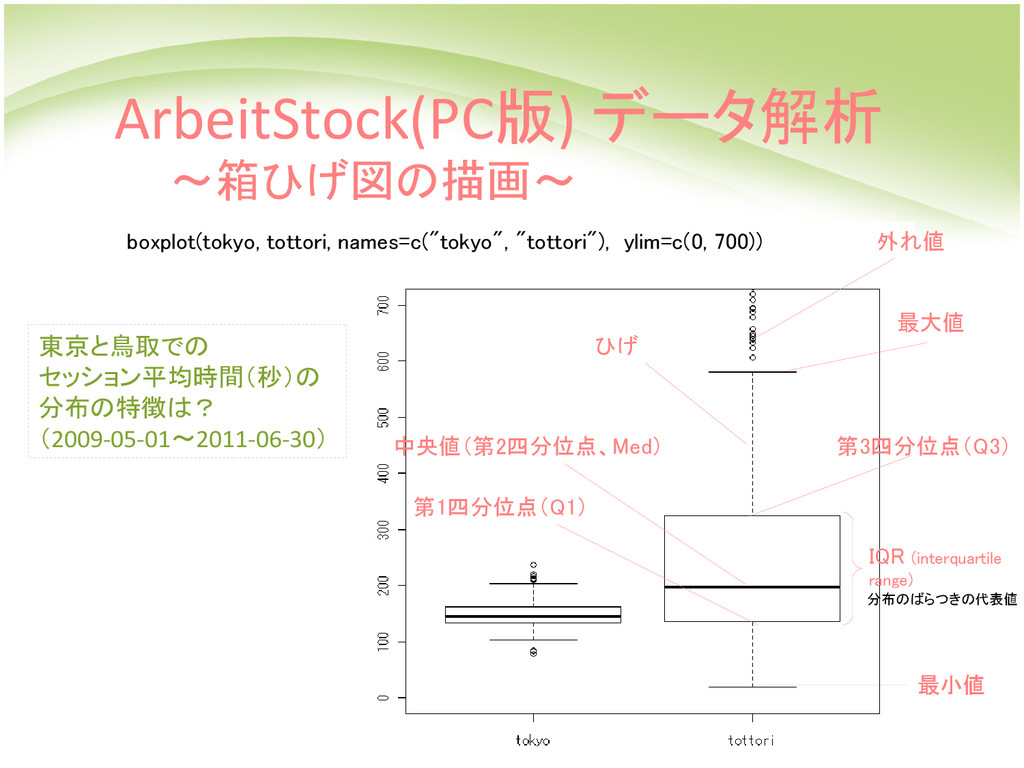
and tottori t = -11.9525, df = 507.686, p-value < 2.2e-16 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -151.5008 -108.7268 sample estimates: mean of x mean of y 148.1075 278.2213 P値<0.05 → 有意水準5%において有意 → 帰無仮説棄却 → セッション平均時間に差がある ArbeitStock(PC版) データ解析 ~2標本t検定~ (帰無仮説:二群の 母平均は等しい) ※ 2種類のt検定 : Welch's t-test 、 Student's t-test 東京と鳥取でセッション平均時間に差がある?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
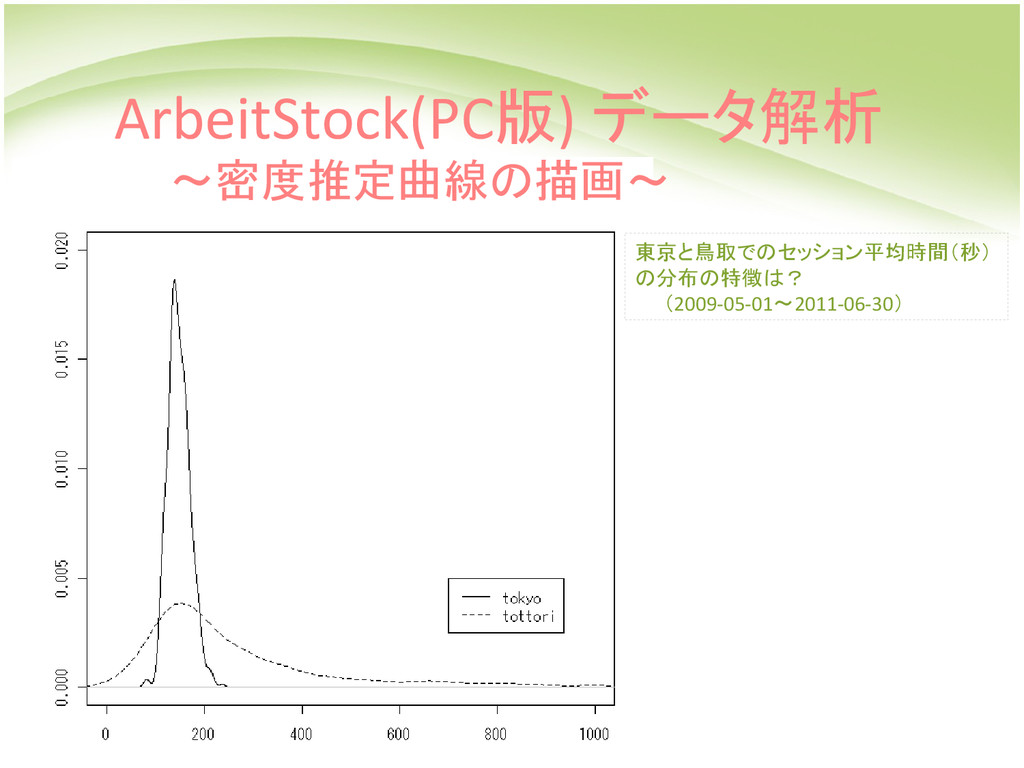
![ArbeitStock(PC版) データ解析 ~密度推定曲線の描画~ tokyo <- ga.data$data[data[2]=="Tokyo", ][3]$ga tottori <- ga.data$data[data[2]=="Tottori",](https://files.speakerdeck.com/presentations/24c2a870acc901314e4a62dac57ab14e/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
![不偏共分散 > var(tokyo, tottori) [1] 526.1022 ArbeitStock(PC版) データ解析 ~統計値の算出~ 東京と鳥取での](https://files.speakerdeck.com/presentations/24c2a870acc901314e4a62dac57ab14e/slide_11.jpg){kind=link}
{kind=link}
{kind=link}