Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
EMNLP読み会2020_Non-Autoregressive Machine Transla...
Search
maskcott
November 24, 2020
Research
40
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
EMNLP読み会2020_Non-Autoregressive Machine Translation with Latent Alignments
maskcott
November 24, 2020
More Decks by maskcott
See All by maskcott
論文紹介2022後期(EMNLP2022)_Towards Opening the Black Box of Neural Machine Translation: Source and Target Interpretations of the Transformer
maskcott
0
77
論文紹介2022後期(ACL2022)_DEEP: DEnoising Entity Pre-training for Neural Machine Translation
maskcott
0
43
PACLIC2022_Japanese Named Entity Recognition from Automatic Speech Recognition Using Pre-trained Models
maskcott
0
46
WAT2022_TMU NMT System with Automatic Post-Editing by Multi-Source Levenshtein Transformer for the Restricted Translation Task of WAT 2022
maskcott
0
53
論文紹介2022前期_Redistributing Low Frequency Words: Making the Most of Monolingual Data in Non-Autoregressive Translation
maskcott
0
66
論文紹介2021後期_Analyzing the Source and Target Contributions to Predictions in Neural Machine Translation
maskcott
0
83
WAT2021_Machine Translation with Pre-specified Target-side Words Using a Semi-autoregressive Model
maskcott
0
60
NAACL/EACL読み会2021_NEUROLOGIC DECDING: (Un)supervised Neural Text Generation with Predicate Logic Constraints
maskcott
0
47
論文紹介2021前期_Bilingual Dictionary Based Neural Machine Translation without Using Parallel Sentences
maskcott
0
54
Other Decks in Research
See All in Research
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
shunk031
4
1.1k
第64回CV・PRML勉強会 論文紹介:Linguistic Priors for Visual Decoupling: Towards Symmetric Vision-Brain Alignment
sokikatayama
0
120
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
320
Can We Teach Logical Reasoning to LLMs? – An Approach Using Synthetic Corpora (AAAI 2026 bridge keynote)
morishtr
1
260
CVPR2026論文紹介_VLMにとって良いvision encoderとは何か?Rethinking Model Selection in VLM Through the Lens of Gromov-Wasserstein Distance
kobayashi31
1
150
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
3.9k
【Zozo Research 技術共有会】三次元領域の現在と展望
mickey_0226
3
420
LINEヤフー データサイエンス Meetup「三井物産コモディティ予測チャレンジ」の舞台裏-AlpacaTechパート
gamella
1
580
Apache Gravitinoで実現する Icebergカタログ統合とアクセスの一元化
matsumooon
0
300
IA for theory
gpeyre
0
180
論文紹介:HalluCitation Matters
wasyro
0
110
正規分布と最適化について
koide3
1
270
Featured
See All Featured
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
610
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.3k
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
240
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
360
Typedesign – Prime Four
hannesfritz
42
3.1k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
Deep Space Network (abreviated)
tonyrice
0
210
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
170
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
450
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Transcript
EMNLP2020 紹介者: 今藤誠一郎(TMU 小町研究室 B4) 2020/11/24 EMNLP読み会 1
Abstract 非自己回帰機械翻訳(NAT)にCTCとImputerと呼ばれる二つの手法を導入 現存する他のNATに比べてシンプルな構造 CTCを用いた手法ではシングルステップのNATでSOTA Imputerを用いた手法では4ステップでtarnsformerベースのATと同等の性能 2
Intro 非自己回帰モデルにおける二つの主要な制限 ・出力語のトークンが全て独立して生成されることを仮定 →マルチモーダルな出力を引き起こし、繰り返し出力の原因となる →統計的な検索アルゴリズム (Gu et al., 2018) や、イテラティブなデコード手法(Ghazvininejad
et al., 2019, 2020b) が取り組まれてきた ・事前に出力文の文長を決定 →学習時にターゲット文の文長も別に学習する必要があり、推論時には文長を決めてからその条 件の下で文を生成することになる →いくつかの文長候補を挙げておいてそれぞれの結果に対してリスコアリングして出力を決定する 手法(Ghazvininejad et al., 2019, 2020b)が取られたりする 3
Intro 二つの制限に取り組むため潜在的アラインメント(Latent alignment)モデルを導入 ここで、”アラインメント” とは機械翻訳で使われるもの (Manning et al., 1999; Dyer
et al., 2013) ではなく、CTCの先行研究 (Graves et al., 2006, 2013; Graves and Jaitly, 2014) で定義されるもの →予測単語とターゲット文の間にマッピングされる、ターゲット文にblank tokenを挿入し て事前に決めた長さにすることで作られる アラインメントからblank tokenを取り除くことで元の文を復元する 4
Latent Alignment Model 入力 、出力 ( )、 はターゲットのvocab 二つの仮定 1) モデルの予測とターゲットはモノトニックなマッピングが存在する 2) アラインメント を と 間の離散的な系列として定義
関数 : niに対応する長さ の全てのアラインメントを返す 関数 : 連続しているトークンを削除した後、全ての”_”を削除 例. = 10で のときに考えられるアラインメント 5
Latent Alignment Model ターゲット文の対数尤度: (1)は膨大な組み合わせが存在するため一般的に扱いづらい →この対数尤度の計算を動的的計画法を用いて扱いやすくしたモデルが, Connectionist Temporal Classification (CTC)
(Graves et al., 2006) と Imputer (Chan et al., 2020) 6
Connectionist Temporal Classification (CTC) アラインメントに強力な独立条件を仮定 →動的計画法を用いて効果的に対数尤度を求められる 先行研究(Graves et al., 2006)より→
推論時はアラインメントの確率分布を1ステップで 生成し、この論文では貪欲に決定する 7
Imputer CTCで仮定した独立条件は複雑なマルチモーダルな分布をモデル化する能力にも制限 をかける 一方でATは連鎖律を利用するので複雑なマルチモーダルな分布のモデル化をする能 力があるものの、デコードに文長分ステップが必要になる →これらの問題に取り組んだのがImputer 推定に定数回の生成ステップだけが必要なイテラティブな生成モデル マスクしておいて1ステップに (文長) /
(ステップ数) のアラインメントを生成 1ステップに生成される単語間のみが独立に生成される 8
Imputer アラインメントの確率分布: : 部分的にマスクされたアラインメント, : になり得るマスクをかけたもの集合 を次の にしてマスクが無くなるまで繰り返す 9 1step内では独立
MTへの適用 (再掲) Latent Alignment Modelを使うにあたっての2つの仮定 1) モデルの予測とターゲットはモノトニックなマッピングが存在する 2) 機械学習は音声認識と違ってこの二つの仮定が成立しないケースが多い 1)
→ Transformerのような強力で深いニューラルネットワークならターゲットとほぼ単調になるように文脈 に応じてエンベディングを並び変えることを学習する能力があると仮定 2) → ソース文のエンベディングを単純にアップサンプリングすることで次元をs倍にする (Libovicky and Helcl (2018)) 10
Model 11
Advantages NATでしばしば問題になる2つの問題を軽減 1) 繰り返し出力が少なくなる →直接ターゲット文を生成するわけではないのが他のモデルとの大きな違い 生成されたalignmentを で復元する際に繰り返しを除去するので、繰り返しの出力を出しにくくなり、精度が 向上する 2) 文長予測の必要が無い →
アラインメントを介して文長が決められる アラインメントの長さは srcのものをs倍にするだけでいい 文長予測のためのモデルの構築も推論時に文長を考える必要もないのでよりシンプルなモデルになる 12
Experiments 設定: transformerのデコーダーのレイヤを2倍にして利用 学習は2Mステップ回して、Imputerの学習の際は最初の1MステップはCTCの lossを利用し、残りの1MステップでImputer用の学習を行う データセット: WMT’14 En↔De, WMT’16 En-Ro
(Sentence Pieceを利用) 知識蒸留: base Transformer と big Transformer を利用 (知識蒸留に関する分析も後 ほど) 13 文をブロックに分割してブロック内の単語を b個(b<B)マスクして学習
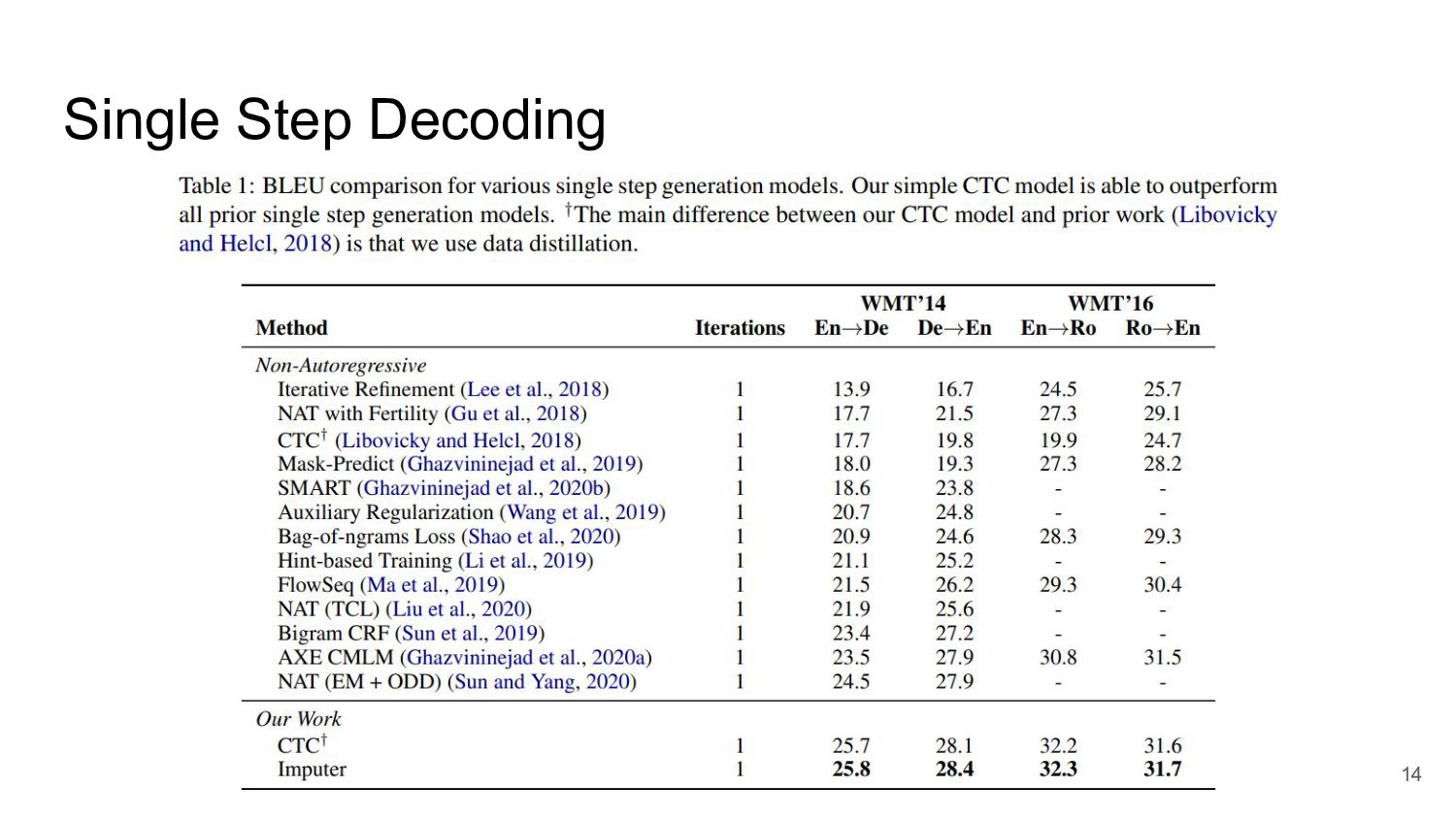
Single Step Decoding 14
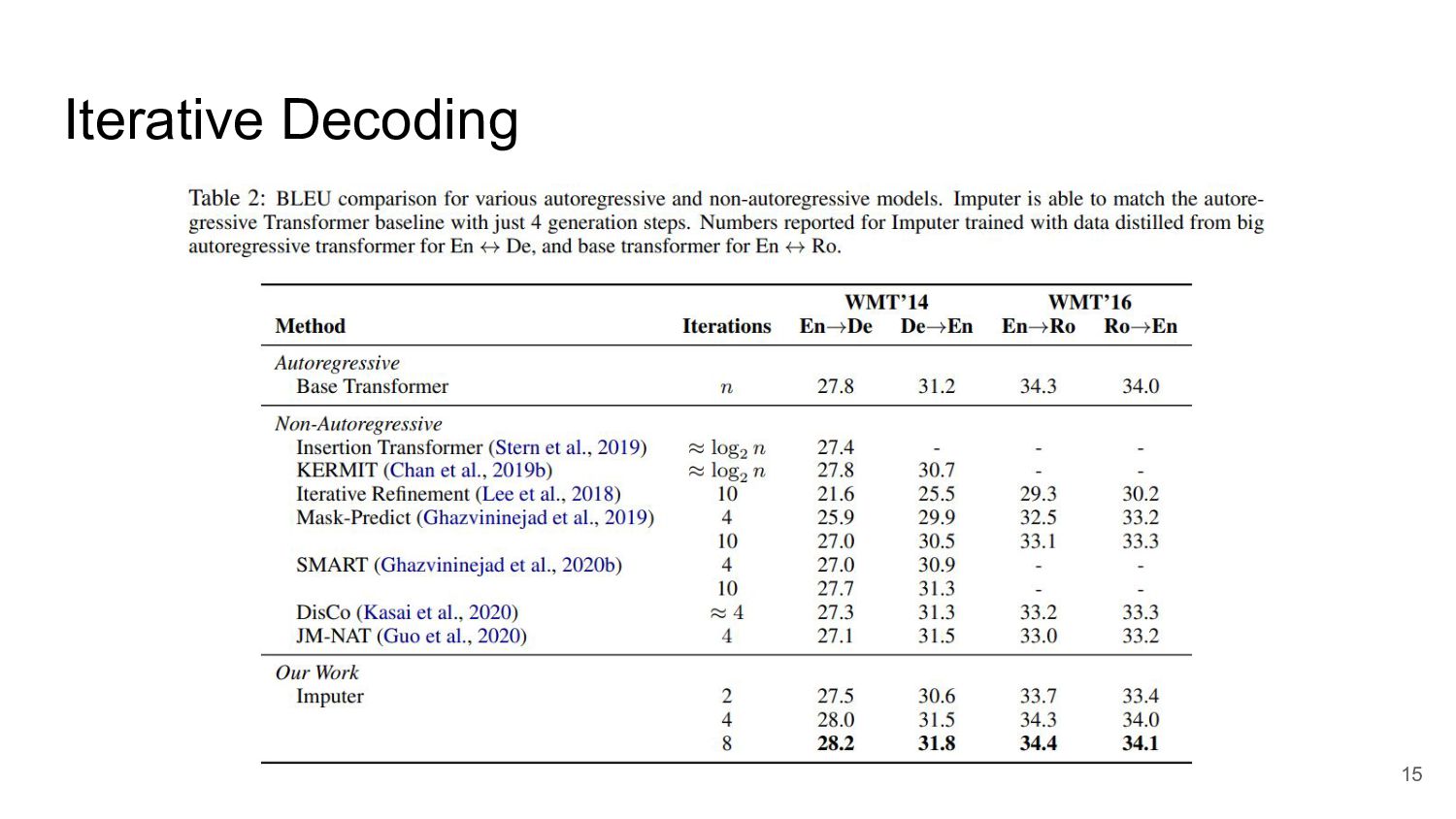
Iterative Decoding 15
Imputerの出力例 16
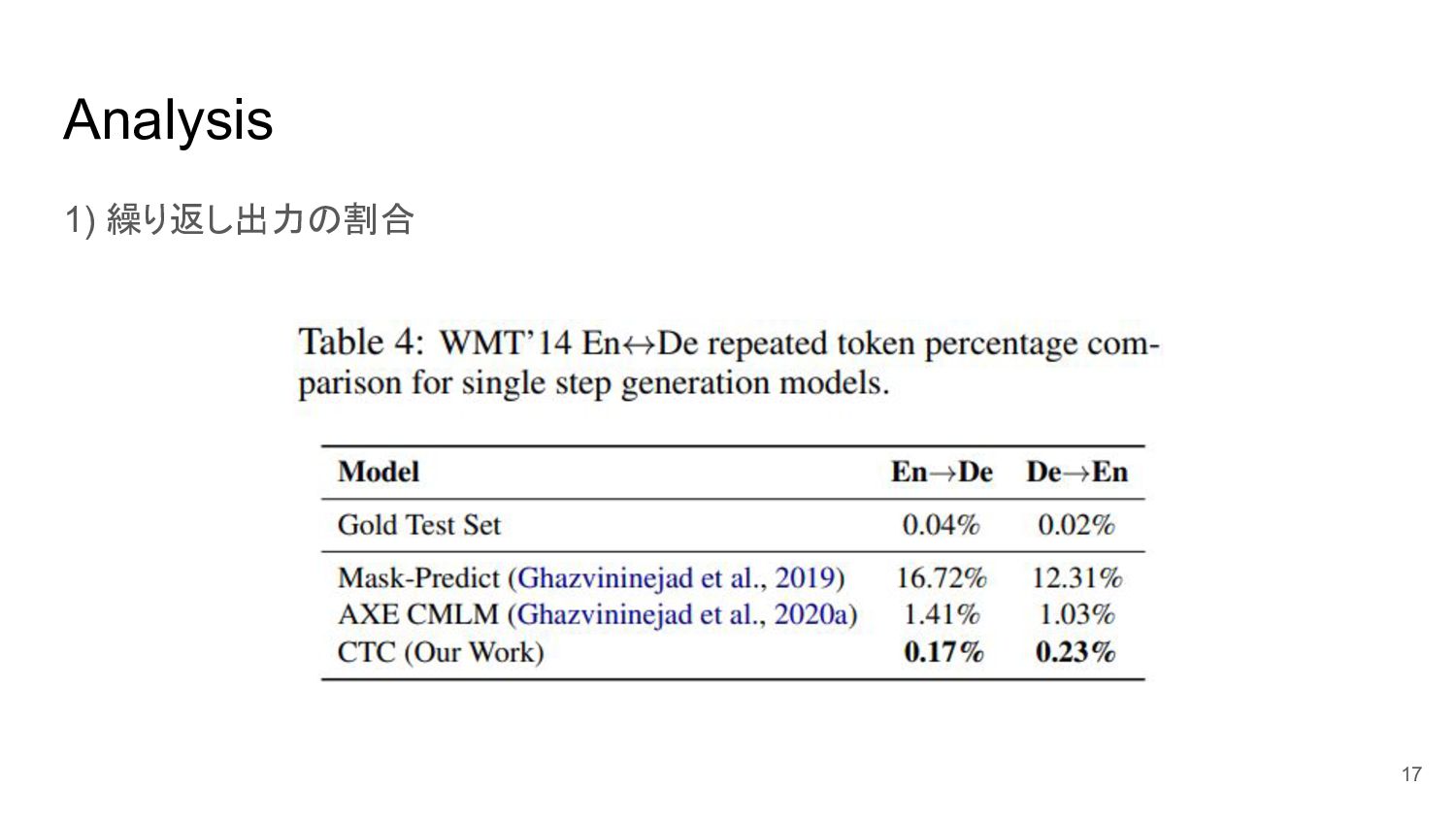
Analysis 1) 繰り返し出力の割合 17
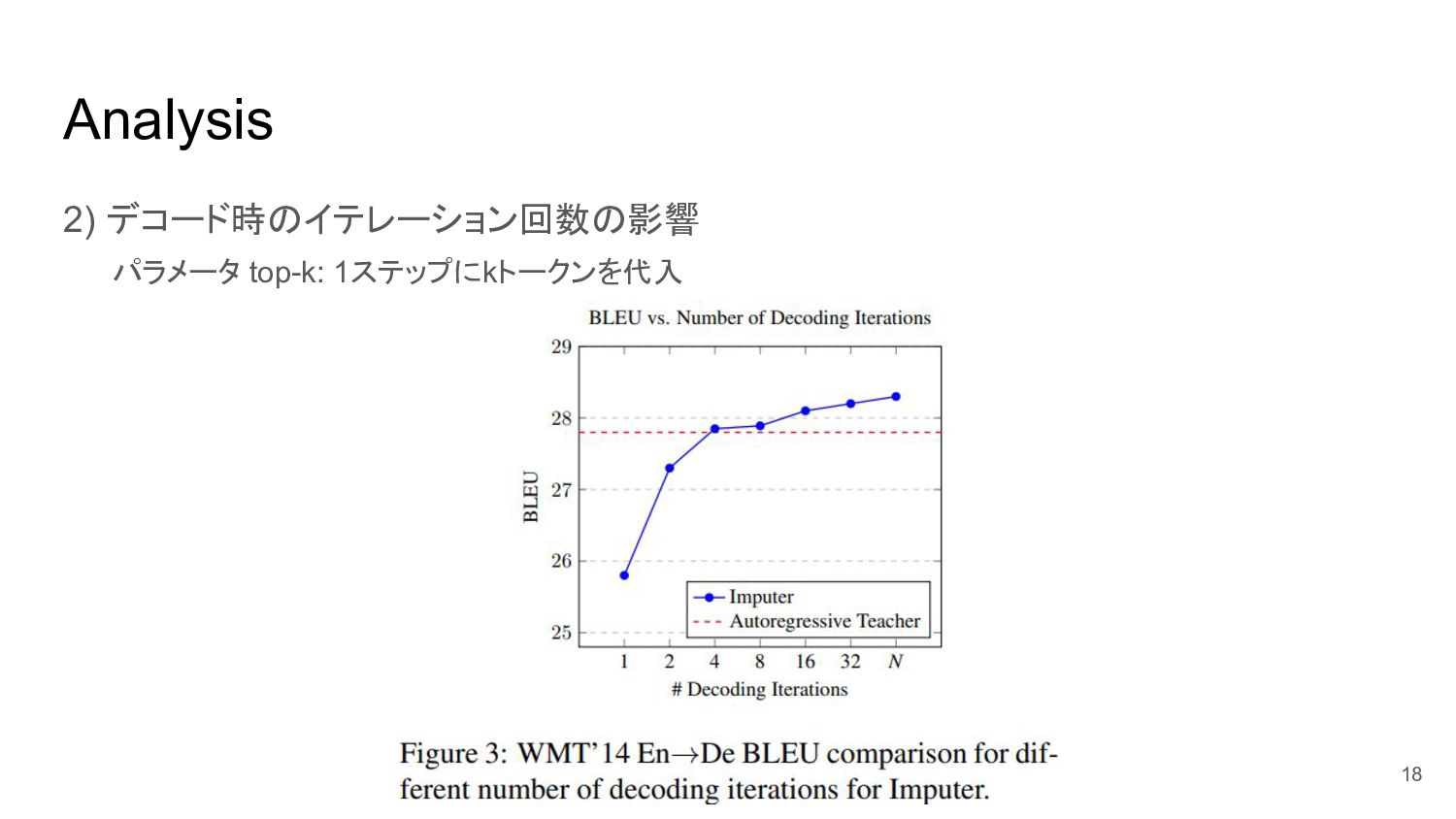
Analysis 2) デコード時のイテレーション回数の影響 パラメータ top-k: 1ステップにkトークンを代入 18
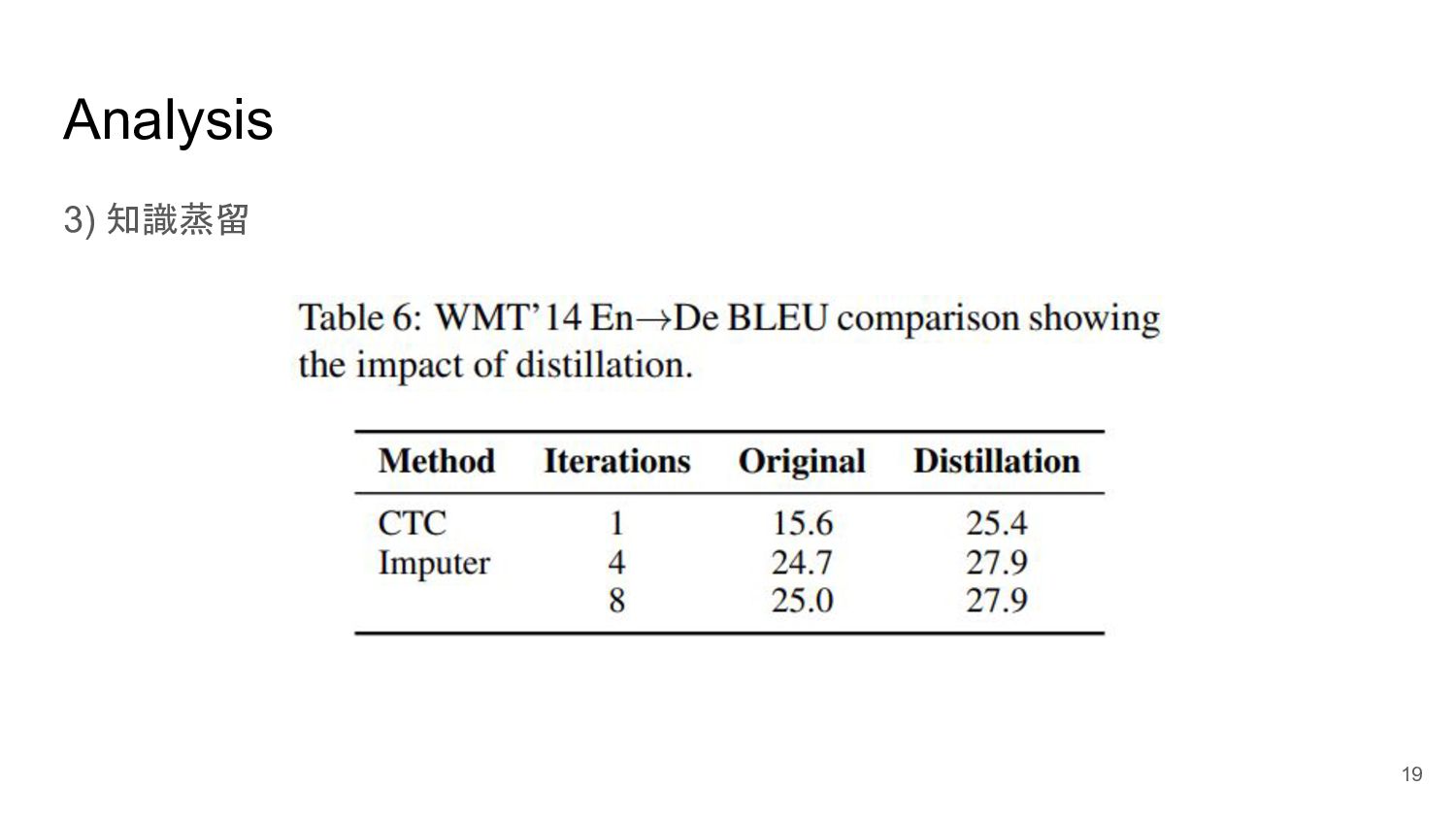
Analysis 3) 知識蒸留 19
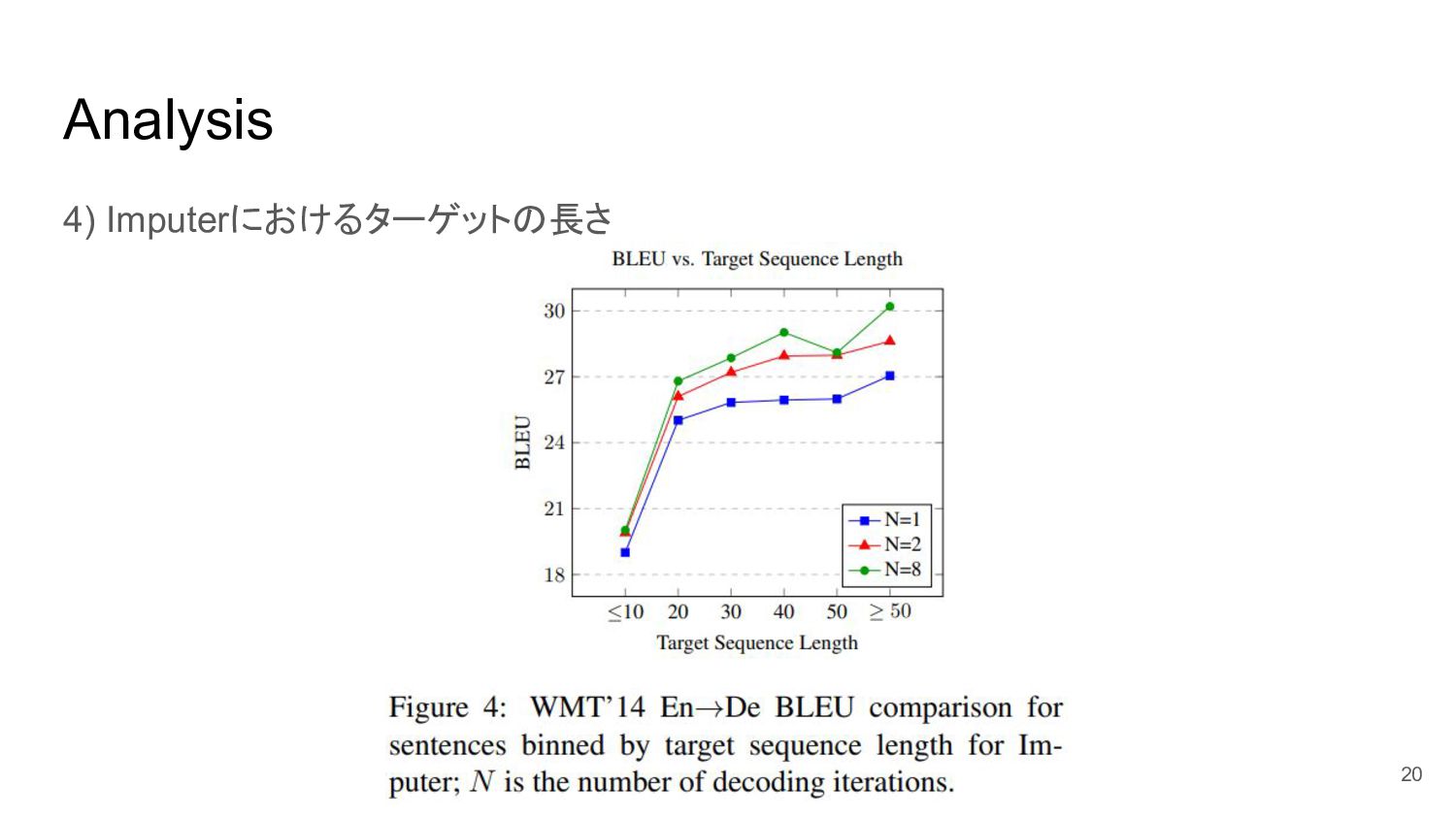
Analysis 4) Imputerにおけるターゲットの長さ 20
Conclusion 二種類のlatent alignments model, CTCとImputerをNATに導入した 先行研究と異なり、文長予測や re-scoringを用いない手法を用いており、他の encoder-decoderモデルで利用されている cross-attentionが不要な、シンプルな構造 のモデル
主に音声認識で用いられている単純なlatent alignments modelの機械翻訳への適用 の容易さと有効性も示せた 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}