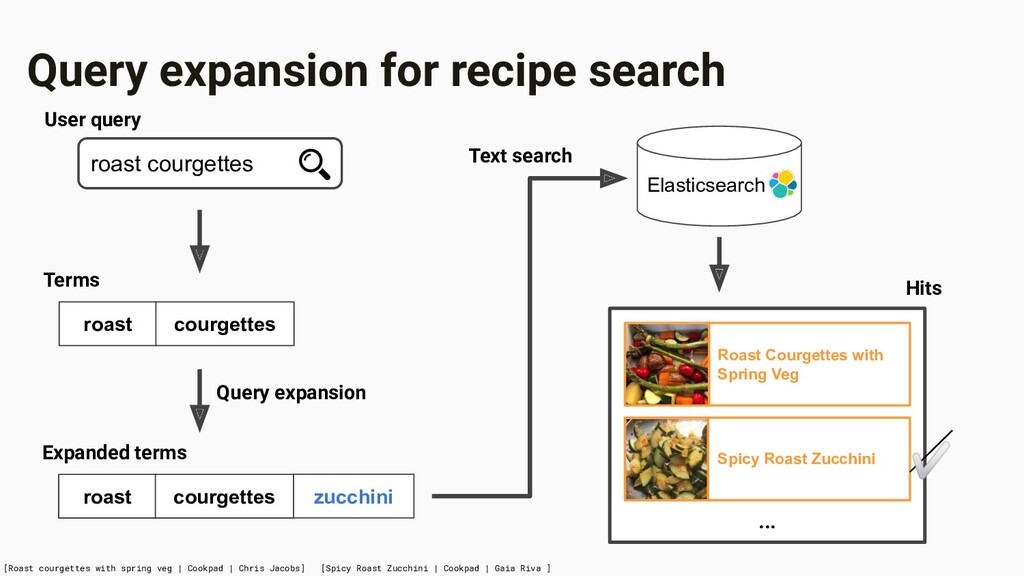
to substitute our hand-curated search dictionary for automated query expansion in our recipe search, to see how far we could go with a completely automated approach. we didn’t know if it would work ♂ a machine learning technique ♂ synonyms ‘n’ stuff = eggplant = aubergine
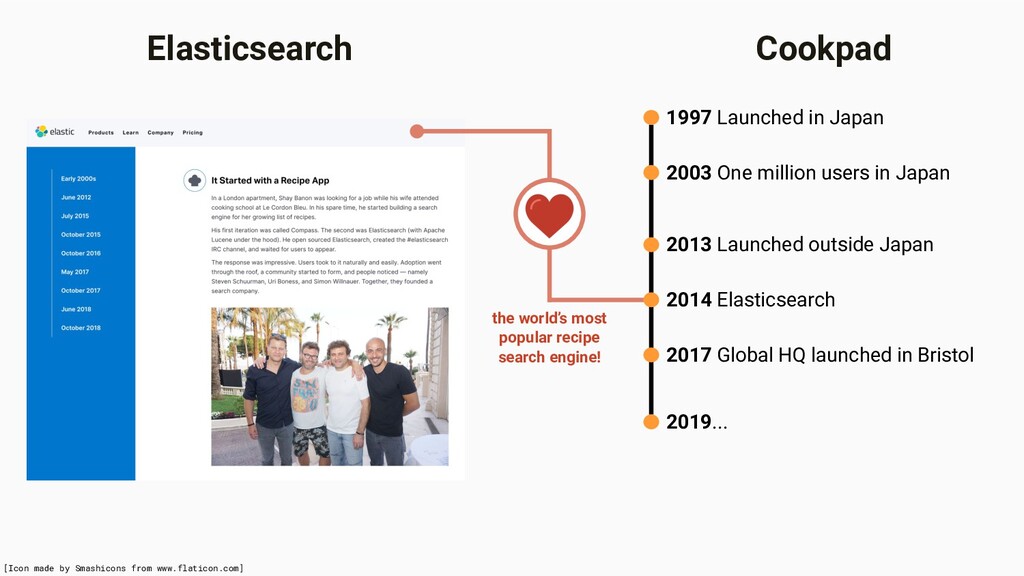
in Japan 2013 Launched outside Japan 2017 Global HQ launched in Bristol 2019... 2014 Elasticsearch [Icon made by Smashicons from www.flaticon.com] the world’s most popular recipe search engine!
in Japan 2013 Launched outside Japan 2017 Global HQ launched in Bristol 2019... 2014 Elasticsearch 100M users (60M in Japan) 5M recipes 75 countries 28 languages [Icon made by Smashicons from www.flaticon.com] the world’s most popular recipe search engine!
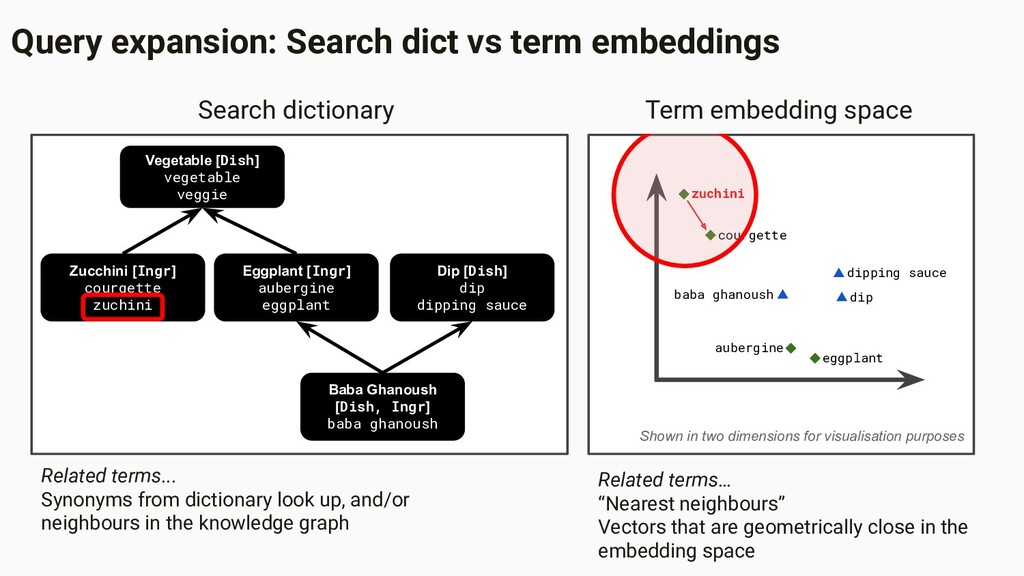
vegetable veggie Eggplant [Ingr] aubergine eggplant Baba Ghanoush [Dish, Ingr] baba ghanoush Dip [Dish] dip dipping sauce An admin-curated knowledge graph of dishes, ingredients, skills, and other cooking-related concepts • Used in query expansion to find synonyms, hyponyms/hypernyms, and other related terms • Improves recall • Also encodes some cultural rules for some countries; e.g., only suggest pork if explicitly searched for
are no shortcuts—everything is reps, reps, reps ” ? - Arnie From Total Recall: My Unbelievably True Life Story by Arnold Schwarzenegger B: naps D: jazz A: reps C: steps
kept my eyes down on the reading list the teacher had given me. It was fairly basic: Bronte, Shakespeare, Chaucer, and Faulkner. I’d already read everything.” ? - Bella From Twilight by Stephenie Meyer B: Shakespeare D: Xylophone A: Carrots C: Terrance
are breakfast foods breakfast foods… Like, why don’t we have curry for breakfast?” ? - Hazel From The Fault in Our Stars by John Green B: Curry D: Jerry A: Shoes C: Cereal
inner goddess is doing the merengue with some salsa moves.” ? - Anastasia From Fifty Shades of Grey by E. L. James B: Banana D: Merenge A: Macarena C: Gangagam
oil over the tomatoes the drizzle then lemon over the tomatoes the drizzle then chorizo over the tomatoes the drizzle then pasta over the tomatoes the drizzle then knife over the tomatoes ✅✅ ✅ ❌ ❌❌ ❌❌❌
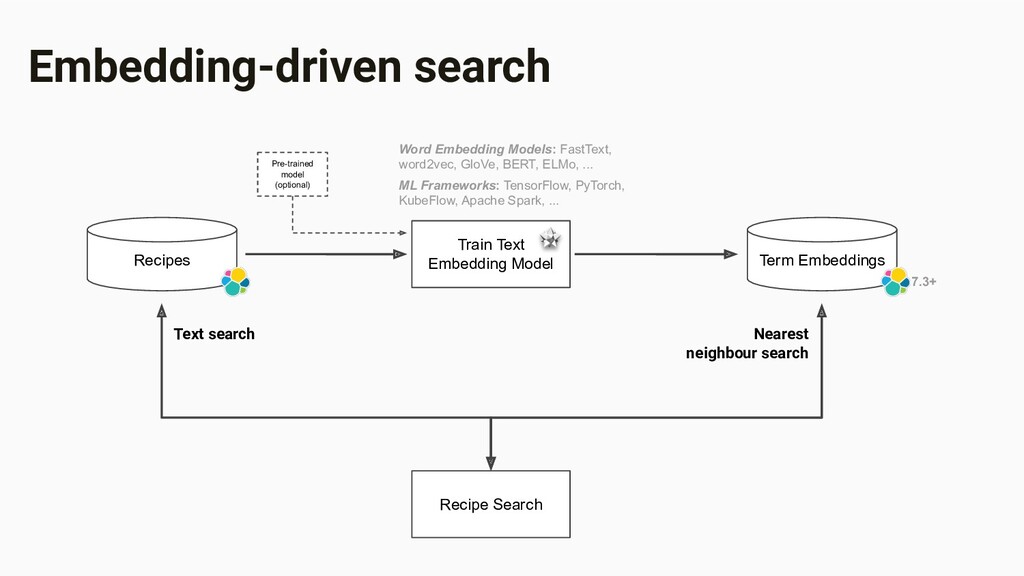
to discriminate words based on their context • Output: n-dimensional vector for each term • n is a constant, usually between 50 and 200 Term embeddings (also known as word embeddings) [https://nathanrooy.github.io/posts/2018-03-22/word2vec-from-scratch-with-python-and-numpy/ | Nathan Rooy | 2018]
embedding space Shown in two dimensions for visualisation Usually vectors have many dimensions: E.g., 50 to 200. Distance between two terms gives us an idea of how related those terms are.
aubergine baba ghanoush dip dipping sauce Related terms… “Nearest neighbours” Vectors that are geometrically close in the embedding space Search dictionary Zucchini [Ingr] courgette zuchini Vegetable [Dish] vegetable veggie Eggplant [Ingr] aubergine eggplant Baba Ghanoush [Dish, Ingr] baba ghanoush Dip [Dish] dip dipping sauce Term embedding space Query expansion: Search dict vs term embeddings Related terms... Synonyms from dictionary look up, and/or neighbours in the knowledge graph
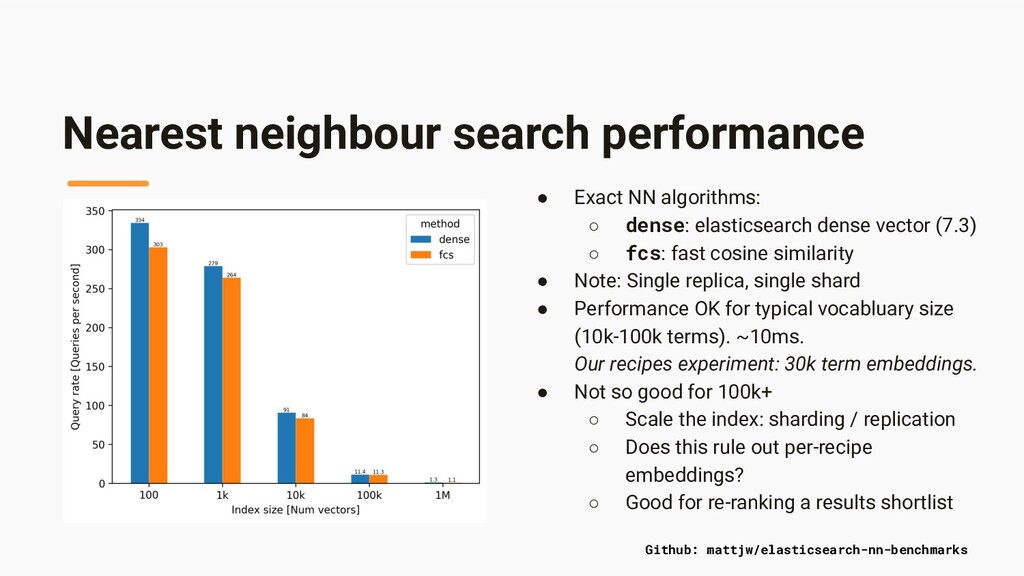
(Facebook) Exact nearest neighbour tools: • Dense vectors (Elasticsearch 7.3+) • Fast cosine similarity plugin (Elasticsearch 6.4+) Nearest neighbour search The task: For a given term t, find the k nearest term vectors within a distance of d. [Github: cookpad/fast-cosine-similarity] [Github: StaySense/fast-cosine-similarity] Exact computation => scaling limit. No features or plugins for Elasticsearch (yet?!) Approximate computation => Scalable to large numbers of embeddings.
elasticsearch dense vector (7.3) ◦ fcs: fast cosine similarity • Note: Single replica, single shard • Performance OK for typical vocabluary size (10k-100k terms). ~10ms. Our recipes experiment: 30k term embeddings. • Not so good for 100k+ ◦ Scale the index: sharding / replication ◦ Does this rule out per-recipe embeddings? ◦ Good for re-ranking a results shortlist Github: mattjw/elasticsearch-nn-benchmarks
Human effort Machine effort Train ML model Control and oversight Human-in-the-loop Automated To change expansion behaviour, need to tune the ML model Explainability Strong Weak Prequisites Dictionary administrators Community Managers, with regional cooking knowledge, supported by Search Engineers Large corpus
of docs Learning word representations 1k - 10k Learning document representations 1k - 10k Text generation 10k - 100k Machine translation 10k - 100k Learning image representations 10k - 100k A minimum requirement for deep learning / representation learning: How many docs do you have to train your models on? [Deep Learning for Search | Tommaso Teofili | 2019]
E.g., for recipe embeddings – related recipes feature? ◦ Scale the cluster? ◦ Implement an approximate NN algorithm in Elastic? ⏱ ◦ Use an external database (Annoy, Faiss)? • Dense vectors allows us to do nearest neighbour searches in Elasticsearch Note: It’s currently an experimental feature. We hope it will go GA • Can a pure ML approach beat a curated search dictionary? In some cases! A lot more work needed for a firm conclusion. Better approach: Combine the both? • Still unclear what factors affect how easy it is to beat the search dictionary. More investigation needed. Summary
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Query expansion: Search dictionary Zucchini [Ingr] courgette zucchini Vegetable [Dish]](https://files.speakerdeck.com/presentations/209e078b116a417e8571adff9ef6b078/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}