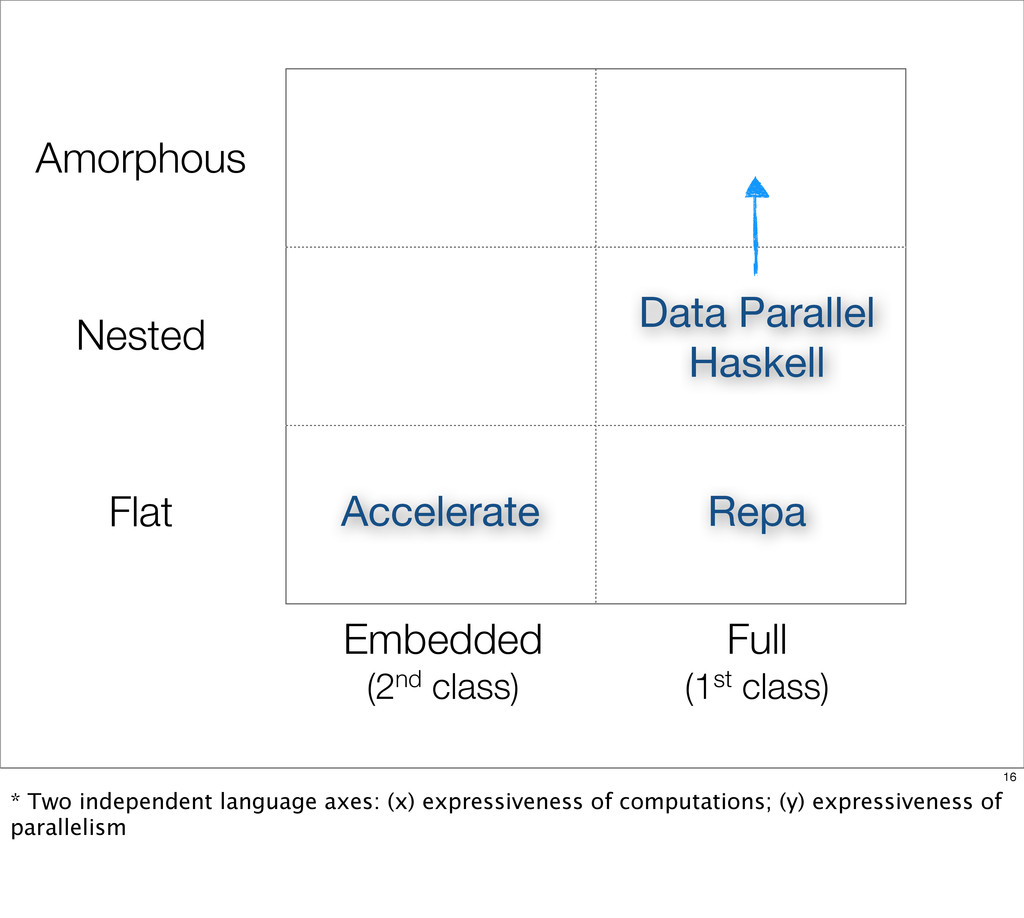
The implicit data parallelism in collective operations on aggregate data structures constitutes an attractive parallel programming model for functional languages. Beginning with our work on integrating nested data parallelism into Haskell, we explored a variety of different approaches to array-centric data parallel programming in Haskell, experimented with a range of code generation and optimisation strategies, and targeted both multicore CPUs and GPUs. In addition to practical tools for parallel programming, the outcomes of this research programme include more widely applicable concepts, such as Haskell’s type families and stream fusion. In this talk, I will contrast the different approaches to data parallel programming that we explored. I will discuss their strengths and weaknesses and review what we have learnt in the course of exploring the various options. This includes our experience of implementing these approaches in the Glasgow Haskell Compiler as well as the experimental results that we have gathered so far. Finally, I will outline the remaining open challenges and our plans for the future.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![type Vector = [:Double:] type SparseVector = [:(Int, Double):] sdotp](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_37.jpg){kind=link}
![type Vector = [:Double:] type SparseVector = [:(Int, Double):] sdotp](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_38.jpg){kind=link}
![type Vector = [:Double:] type SparseVector = [:(Int, Double):] sdotp](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_39.jpg){kind=link}
![type Vector = [:Double:] type SparseVector = [:(Int, Double):] sdotp](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_40.jpg){kind=link}
![type Vector = [:Double:] type SparseVector = [:(Int, Double):] sdotp](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
![[: f x | x <- xs :] 26 *](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_44.jpg){kind=link}
![[: f x | x <- xs :] Vectoriser map](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_45.jpg){kind=link}
![[: f x | x <- xs :] Vectoriser map](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_46.jpg){kind=link}
![[: f x | x <- xs :] Vectoriser map](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_47.jpg){kind=link}
![[: f x | x <- xs :] Vectoriser map](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_48.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[: f x | x <- xs :] Vectoriser Generalisation](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_56.jpg){kind=link}
![[: f x | x <- xs :] Vectoriser Generalisation](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_57.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![dotp :: [:Float:] -> [:Float:] -> Float dotp xs ys](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_83.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![map (\x -> x + 1) arr [DAMP 2011] 51](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_99.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[Embed 2013] 53 Essence of skeleton-based generative programming (transcending Accelerate)](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_106.jpg){kind=link}
![Skeletons are templates …encapsulating efficient code idioms [Embed 2013] 53](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_107.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References [EuroPar 2001] Nepal -- Nested Data-Parallelism in Haskell. Chakravarty,](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_118.jpg){kind=link}
![[FSTTCS 2008] Harnessing the Multicores: Nested Data Parallelism in Haskell.](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_119.jpg){kind=link}
![[Haskell 2012a] Guiding Parallel Array Fusion with Indexed Types. Lippmeier,](https://files.speakerdeck.com/presentations/f439a53009af013148dc5ef39c4a67aa/slide_120.jpg){kind=link}
{kind=link}