Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
20211118_GKEにおける高負荷時のPodとWorker_Nodeの挙動について.pdf
Search
nezumisannn
November 18, 2021
Technology
180
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
20211118_GKEにおける高負荷時のPodとWorker_Nodeの挙動について.pdf
nezumisannn
November 18, 2021
More Decks by nezumisannn
See All by nezumisannn
20250930_Conohaウェビナー_生成AI_Terraform_ConoHa_VPSサーバー_セットアップ入門編
nezumisannn
1
37
20250723_Conohaウェビナー_高騰する海外クラウド費用を劇的カット_サーバーコスト最適化のポイント解説と成功事例のご紹介.pdf
nezumisannn
0
55
20241204_ビヨンド勉強会_44_AWS_Service_Catalogを利用したIaCのテンプレート化とTerraformによるデプロイ.pdf
nezumisannn
0
390
20240828_ビヨンド勉強会_42_EKS_on_FargateでWebサービスを公開するために覚えておきたいこと.pdf
nezumisannn
0
110
20240530_ビヨンド勉強会#41_ビヨンドのエンジニア新卒研修における取り組み
nezumisannn
0
140
20230511_AWSにおけるコンテナサービスの選択とIaC実装例.pdf
nezumisannn
0
1.4k
リーダーになって1年経過して_取り組んできたことと大事にしている考え方_の裏側_.pdf
nezumisannn
0
92
20211014_Alibaba_Cloud_Container_Service_for_KubernetesにおけるServerless_Kubernetesの概要とManaged_Kubernetesとの違い.pdf
nezumisannn
0
110
20211008_ApsaraDB_for_PolarDBとAWS_Auroraの機能比較.pdf
nezumisannn
1
170
Other Decks in Technology
See All in Technology
Webの技術とガジェットで子どもも大人も楽しめるワクワク体験を提供する / Qiita Tech Festa Day 2026
you
PRO
1
190
Aurora MySQL 8.4リリース! Rubyistが備えること / what-rubyist-should-prepare-for-aurora-mysql-8-4
fkmy
0
790
VPCセキュリティ対応の最新事情
nagisa53
1
290
OpenTelemetryにおけるGoのゼロコード・コンパイル時計装について #fukuokago
quiver
0
230
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
260
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
14
4.8k
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
940
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
290
【公開用】AI_Dev_Ex2026_AI_登壇資料
matsuritechnologies
PRO
2
490
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.5k
SRENEXT_2026_Chairs__Talks_in_Tamachi.sre.pdf
srenext
1
150
「顧客の声を聞かなければ何も始まらない」 ── 顧客の声から生まれた『AI返信補助機能』の開発プロセス / AICon2026_shikata_imai
rakus_dev
1
270
Featured
See All Featured
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
Paper Plane
katiecoart
PRO
2
52k
Leo the Paperboy
mayatellez
8
1.9k
Marketing to machines
jonoalderson
1
5.6k
Context Engineering - Making Every Token Count
addyosmani
9
1k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
Ethics towards AI in product and experience design
skipperchong
2
330
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
370
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
Transcript
GKEにおける高負荷時の PodとWorker Nodeの挙動について MixLeap Study #68 - 各社事例に学ぶKubernetes運用 2021/11/18 株式会社ビヨンド
寺岡 佑樹
自己紹介 resource “my_profile” “nezumisannn” { name = “Yuki.Teraoka” nickname =
“ねずみさん家。” company = “beyond Co., Ltd.” job = “Infra Engineer” twitter = “@yktr_sre” skills = [“Terraform”,”Packer”] }
前提 • 疑似的なリクエストを生成する • 最初は最小スペック/設定で構築する • 負荷が上昇する度に原因を調査 ◦ Clusterの状態の確認と改善に向けた対応案を検討する •
Apache Benchを利用する ◦ ab -n <総リクエスト数> -c <同時接続数> <リクエスト先URL>
ホストマシンスペック • Master Node ◦ GKEのため利用者からは見えないようになっている • Worker Node ◦
初期1台 ◦ v1.20.10-gke.1600 ◦ Container-Optimized OS from Google ◦ containerd://1.4.4 ◦ e2-standard-2(vCPU:2 / Mem:8GB)
マニフェスト • Namespace ◦ 本番環境を想定 • Deployment ◦ コンテナ ▪
Nginx ▪ PHP ◦ アプリケーションフレームワーク ▪ Laravel • Service ◦ NodePortでNginxの80番ポートを公開 • Ingress ◦ CloudLBを利用してserviceを外部公開
平常時 Worker Node ``` $ kubectl top node NAME CPU(cores)
CPU% MEMORY(bytes) MEMORY% gke-gke-cluster-default-pool-a063d899-58t9 149m 15% 799Mi 28% ``` Pod(Production) ``` $ kubectl top pod -n production NAME CPU(cores) MEMORY(bytes) laravel-6dbd68b4f9-7pnln 16m 64Mi ```
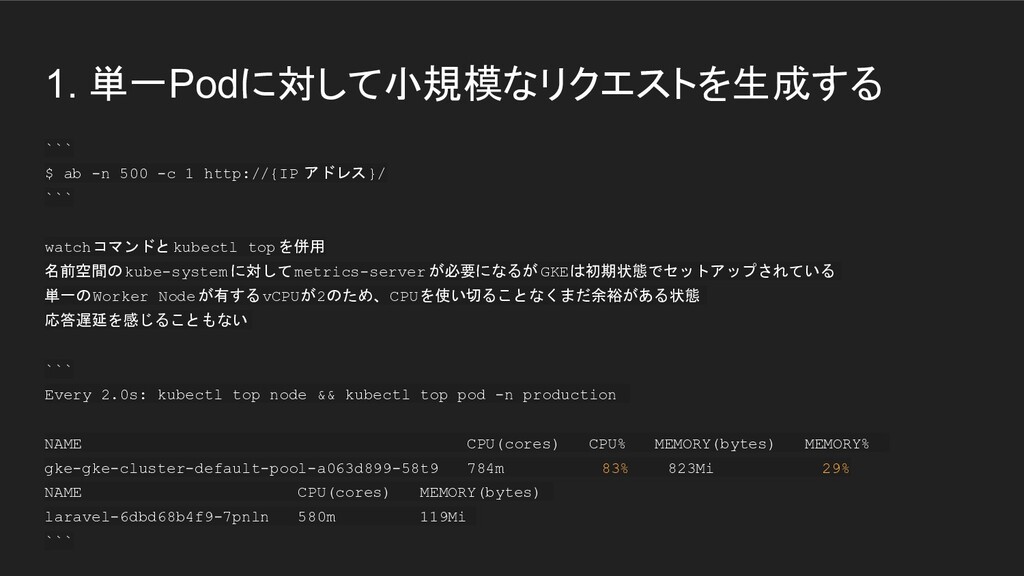
1. 単一Podに対して小規模なリクエストを生成する ``` $ ab -n 500 -c 1 http://{IP
アドレス}/ ``` watchコマンドとkubectl top を併用 名前空間のkube-system に対してmetrics-server が必要になるが GKEは初期状態でセットアップされている 単一のWorker Node が有するvCPUが2のため、CPUを使い切ることなくまだ余裕がある状態 応答遅延を感じることもない ``` Every 2.0s: kubectl top node && kubectl top pod -n production NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% gke-gke-cluster-default-pool-a063d899-58t9 784m 83% 823Mi 29% NAME CPU(cores) MEMORY(bytes) laravel-6dbd68b4f9-7pnln 580m 119Mi ```
2. 単一Podに対して生成するリクエスト量を増やす ``` $ ab -n 10000 -c 50 http://{IPアドレス}/
``` PodによってリクエストされたCPUリソースが増えてWorker Nodeが有するvCPUを使い果たしている 応答遅延が発生してタイムアウトする(Nginxが499エラーで応答する)、本番環境だと普通に障害 Pod * 1 / Worker Node * 1の現状ではここが性能限界 ``` Every 2.0s: kubectl top node && kubectl top pod -n production NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% gke-gke-cluster-default-pool-a063d899-58t9 1998m 212% 855Mi 30% NAME CPU(cores) MEMORY(bytes) laravel-6dbd68b4f9-7pnln 1824m 146Mi ``` 現時点で複数の問題を抱えているが、まずは素直にPodの数を手動で増やしてみる
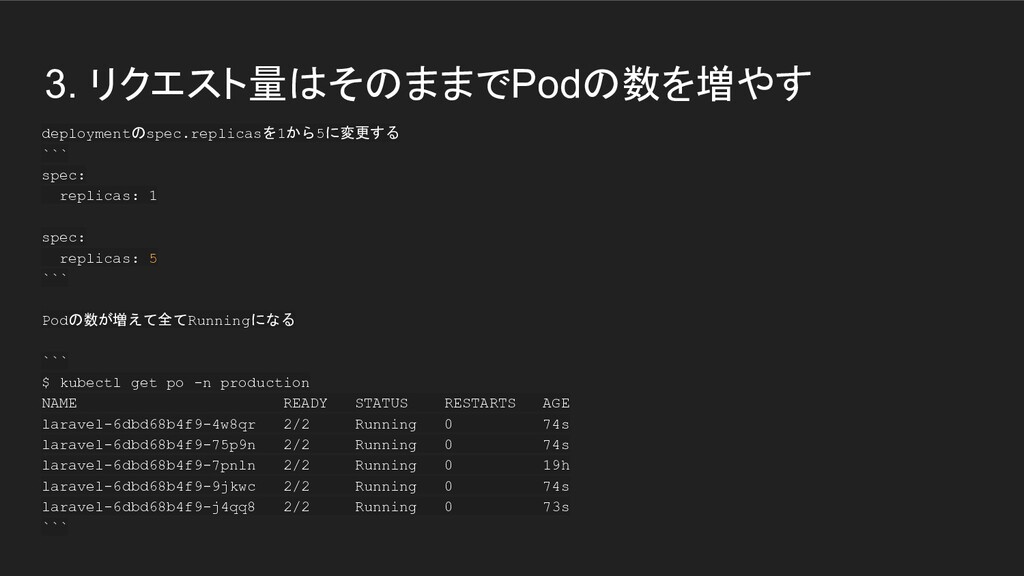
3. リクエスト量はそのままでPodの数を増やす deploymentのspec.replicasを1から5に変更する ``` spec: replicas: 1 spec: replicas: 5
``` Podの数が増えて全てRunningになる ``` $ kubectl get po -n production NAME READY STATUS RESTARTS AGE laravel-6dbd68b4f9-4w8qr 2/2 Running 0 74s laravel-6dbd68b4f9-75p9n 2/2 Running 0 74s laravel-6dbd68b4f9-7pnln 2/2 Running 0 19h laravel-6dbd68b4f9-9jkwc 2/2 Running 0 74s laravel-6dbd68b4f9-j4qq8 2/2 Running 0 73s ```
3. リクエスト量はそのままでPodの数を増やす ``` $ ab -n 10000 -c 50 http://{IPアドレス}/
``` 単一Podごとのリソース使用量は減少した Worker NodeのCPUリソースが枯渇しているのでPodを増やしても応答遅延は解消しない ``` Every 2.0s: kubectl top node && kubectl top pod -n production NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% gke-gke-cluster-default-pool-a063d899-58t9 1999m 212% 1167Mi 41% NAME CPU(cores) MEMORY(bytes) laravel-6dbd68b4f9-4w8qr 376m 82Mi laravel-6dbd68b4f9-75p9n 348m 82Mi laravel-6dbd68b4f9-7pnln 345m 131Mi laravel-6dbd68b4f9-9jkwc 351m 83Mi laravel-6dbd68b4f9-j4qq8 388m 83Mi ```
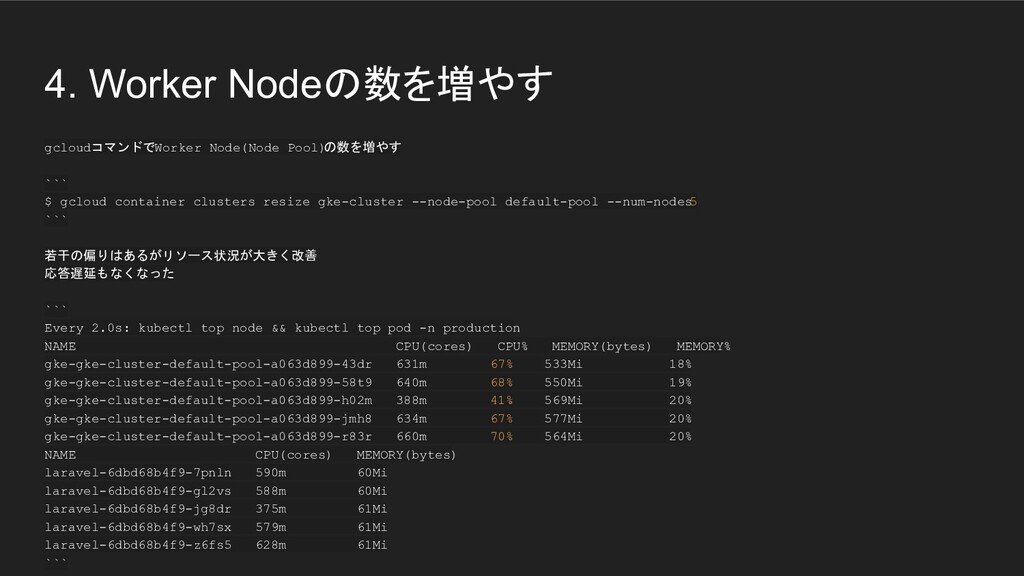
4. Worker Nodeの数を増やす gcloudコマンドでWorker Node(Node Pool) の数を増やす ``` $ gcloud
container clusters resize gke-cluster --node-pool default-pool --num-nodes 5 ``` 若干の偏りはあるがリソース状況が大きく改善 応答遅延もなくなった ``` Every 2.0s: kubectl top node && kubectl top pod -n production NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% gke-gke-cluster-default-pool-a063d899-43dr 631m 67% 533Mi 18% gke-gke-cluster-default-pool-a063d899-58t9 640m 68% 550Mi 19% gke-gke-cluster-default-pool-a063d899-h02m 388m 41% 569Mi 20% gke-gke-cluster-default-pool-a063d899-jmh8 634m 67% 577Mi 20% gke-gke-cluster-default-pool-a063d899-r83r 660m 70% 564Mi 20% NAME CPU(cores) MEMORY(bytes) laravel-6dbd68b4f9-7pnln 590m 60Mi laravel-6dbd68b4f9-gl2vs 588m 60Mi laravel-6dbd68b4f9-jg8dr 375m 61Mi laravel-6dbd68b4f9-wh7sx 579m 61Mi laravel-6dbd68b4f9-z6fs5 628m 61Mi ```
ここまでの整理 • 単一PodでもWorker Nodeのリソースが枯渇しない限りは応答遅延が出なかった • Worker Nodeのリソースが枯渇すると当然ながら Podが起動していても障害状態になる • この状態でPodの数を増やすとRunningにはなるが状況は改善しない
• Worker Nodeを増やしてPodを再配置すると、利用できるリソース量が増えて改善した
課題感 • 単一PodがNodeのリソースのほとんどを無条件に占有してしまっている ◦ 他のPodが起動できなくなる ◦ 同一のクラスタ内に名前空間が複数ある場合はそちらにも影響が出る ◦ kube-systemも例外ではない、Worker Node自体が機能しなくなる可能性
• メモリが枯渇するとやばい、OOM Killerの可能性
対応案 • Pod(及びコンテナ)が利用するリソース量を指定及び制限を設ける ◦ Resource Requests ▪ Podが必要とするリソース量を指定できる ◦ Resource
Limits ▪ Podが利用するリソースに制限を設けることができる ◦ Limits Range ▪ 名前空間単位で利用するリソースの最小 /最大値を指定できる • 設定するとPodのスケジューリング時にPendingになる場合がある ◦ PodはWorker Nodeの使用量は考慮せず Resource Requestsの値を見て起動される ◦ Node自体が落ちるよりまし、安全弁と考える ◦ 「Pending状態になっているPodの数」という指標で監視の基準とできる • 最適値はアプリケーションの特性によって異なる ◦ 負荷テストによる検証を ◦ 指定及び制限を設けながら単一 Podが性能要件を満たせるか否か
対応案2 • Pod及びWorker Nodeの数の調整 ◦ リソース状況に基づいて極力で自動で調整したい • HorizontalPodAutoscaler(HPA) ◦ Podの水平スケーリング
◦ Kubernetes自体の機能なのでGKE以外でも利用可 • MultidimPodAutoscaler(MPA) ◦ GKEの独自機能 ◦ CPU使用率による水平スケーリングとメモリ使用率による垂直スケーリング ◦ HPA / VPAの併用 • ClusterAutoscaler(CA) ◦ Worker Nodeの増減ができる
まとめ • 運用していると様々なトラブルシューティングをすることになる • 今回のその中の一部分を疑似的に再現してみた • 以下のサイトが非常に参考になる ◦ https://learnk8s.io/troubleshooting-deployments
終わり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}