is a trademark of Elasticsearch BV, registered in the U.S. and in other countries. Kibana is a trademark of Elasticsearch BV, registered in the U.S. and in other countries. Logstash is a trademark of Elasticsearch BV, registered in the U.S. and in other countries ※文章や製品以外のアイコンについては、 弊社、および作成者(長谷川)に帰属します。 3
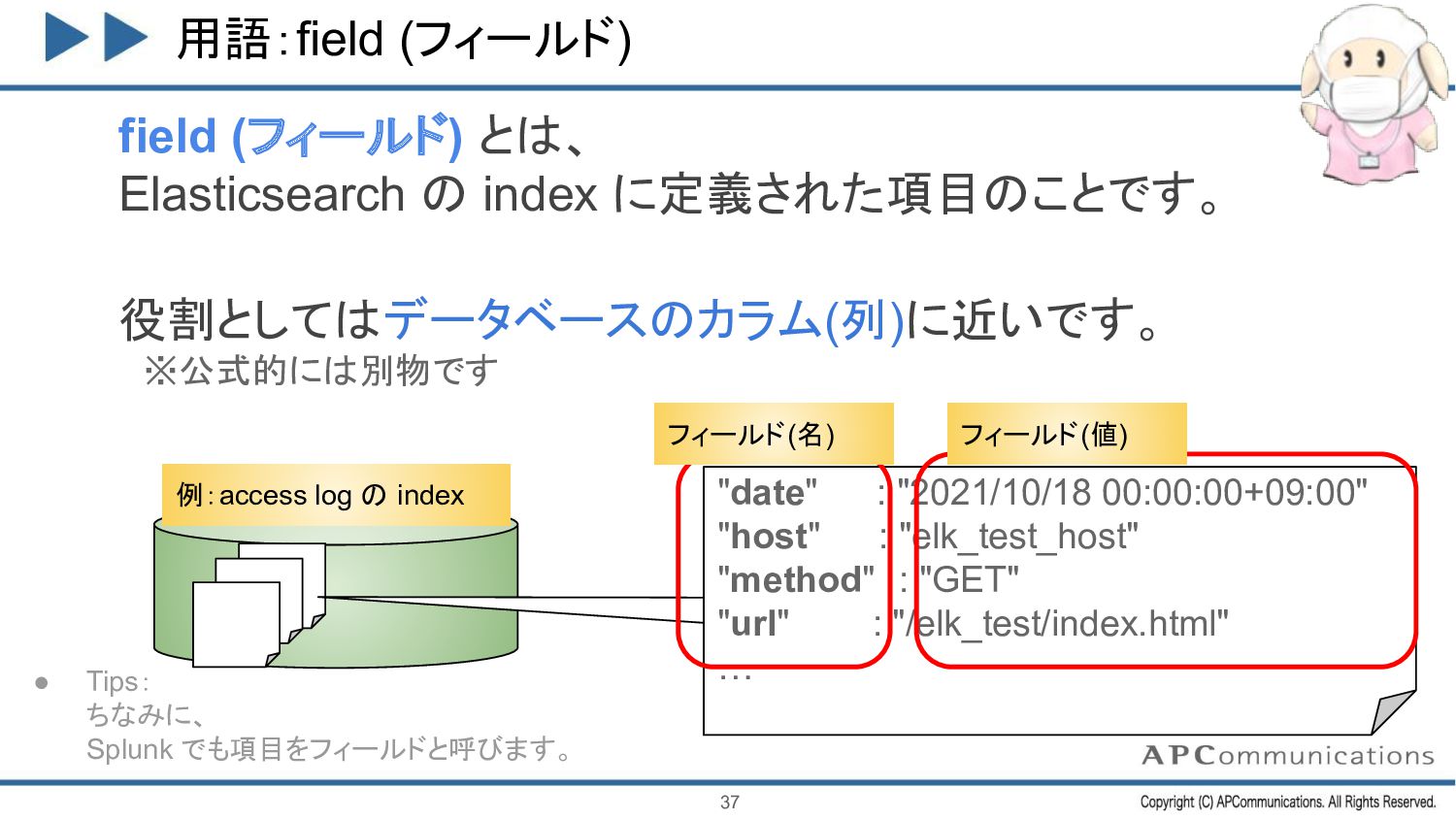
2021/12/14 10:00 GET https://xxxx 例: index に格納した access.log の一行 一行 を ドキュメント と呼ぶ 例:access log の index 2021/12/14 11:00 POST http://xxxx 2021/12/14 12:00 PUT http://xxxx
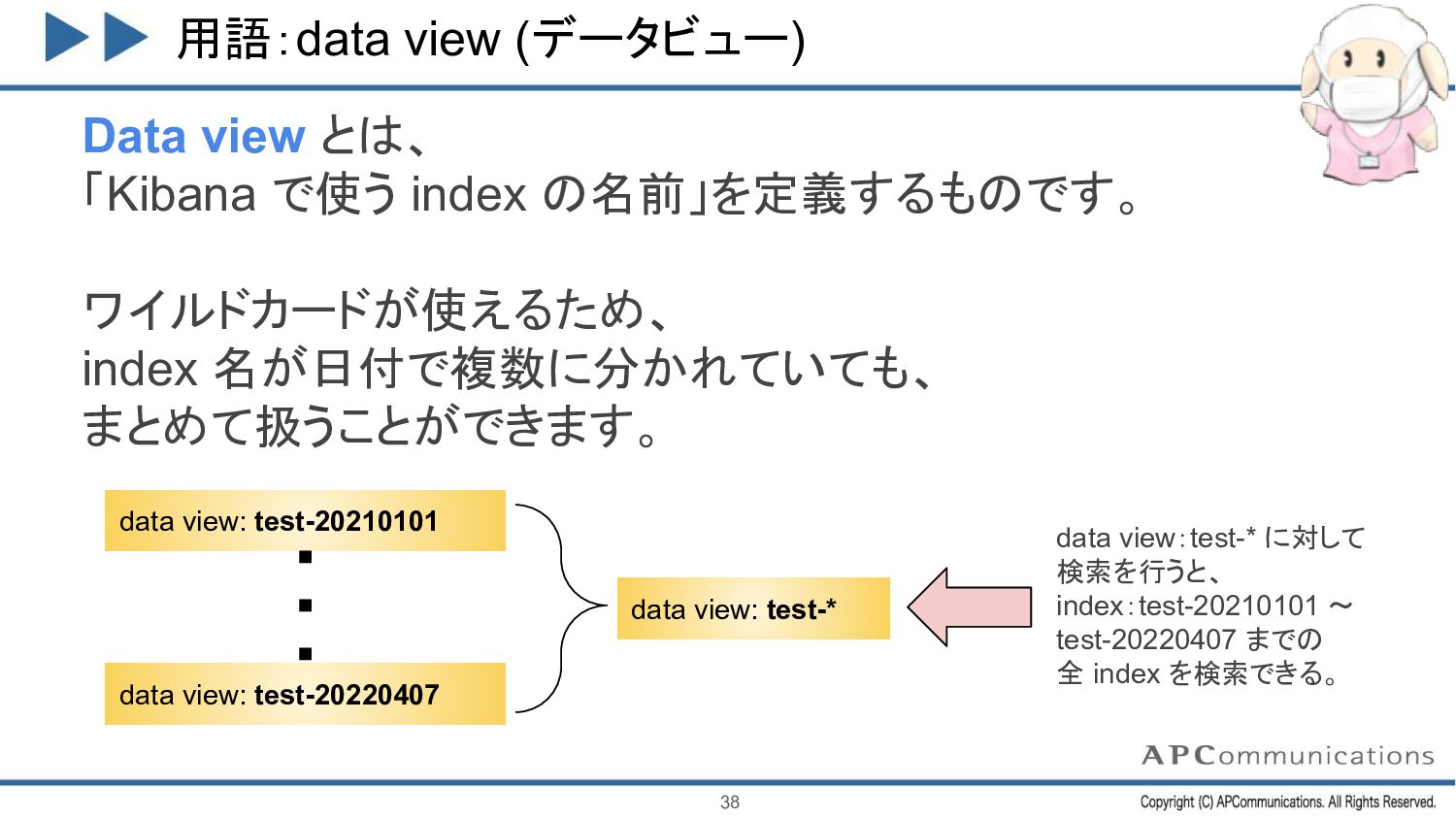
ワイルドカードが使えるため、 index 名が日付で複数に分かれていても、 まとめて扱うことができます。 38 data view: test-* data view: test-20210101 data view: test-20220407 data view:test-* に対して 検索を行うと、 index:test-20210101 ~ test-20220407 までの 全 index を検索できる。
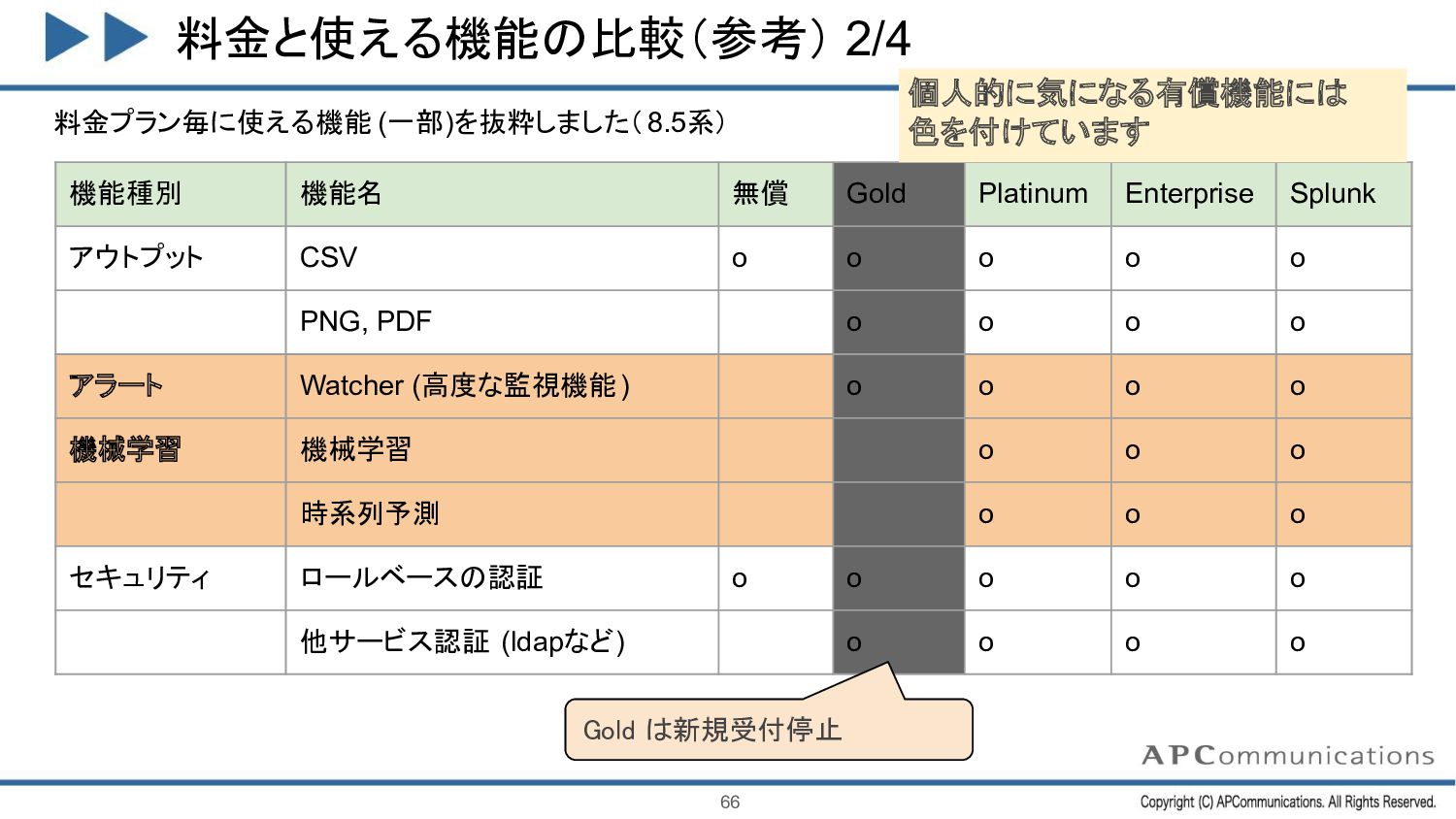
アウトプット CSV o o o o o PNG, PDF o o o o アラート Watcher (高度な監視機能) o o o o 機械学習 機械学習 o o o 時系列予測 o o o セキュリティ ロールベースの認証 o o o o o 他サービス認証 (ldapなど) o o o o 個人的に気になる有償機能には 色を付けています 料金プラン毎に使える機能 (一部)を抜粋しました(8.5系) Gold は新規受付停止
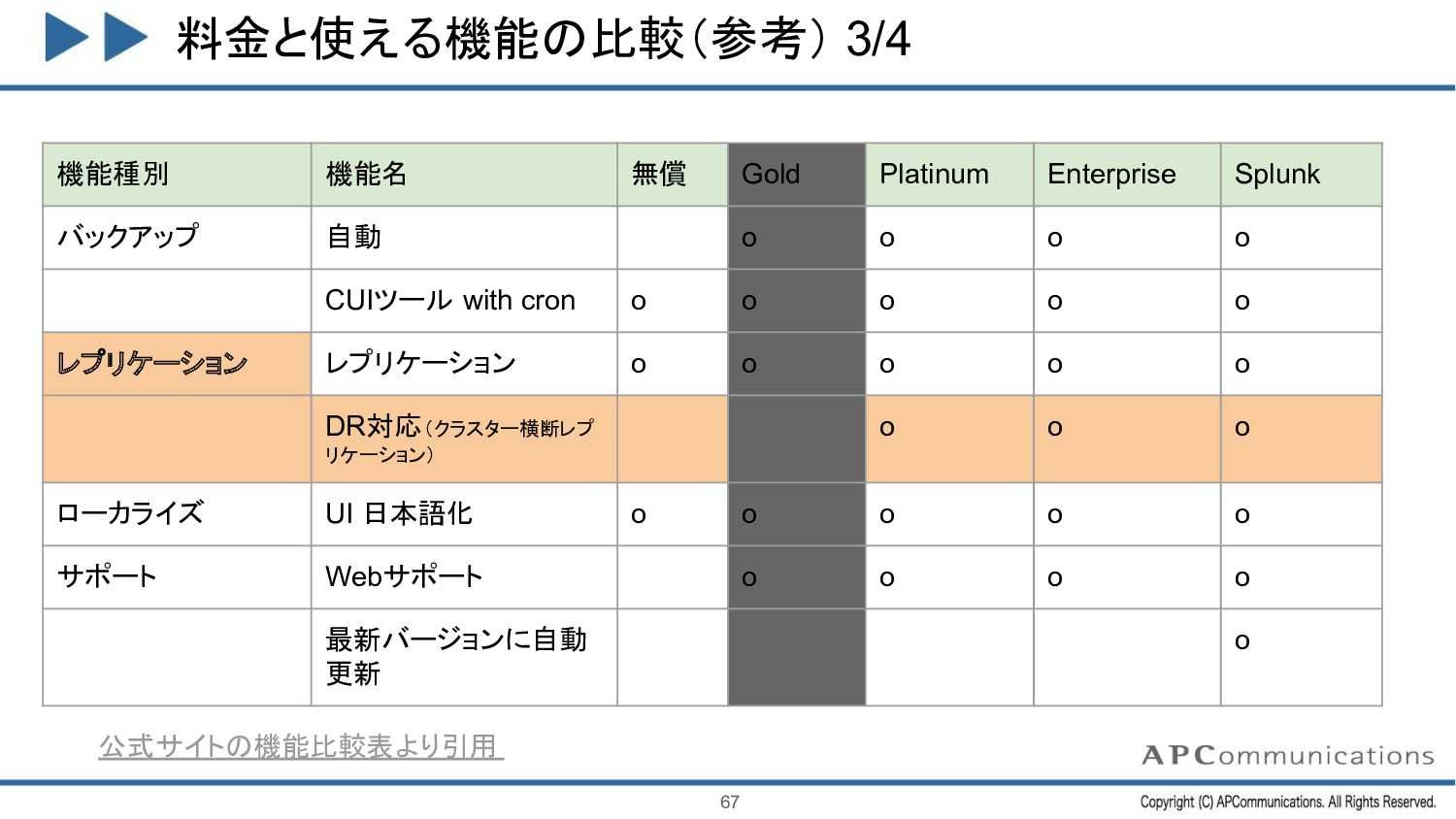
バックアップ 自動 o o o o CUIツール with cron o o o o o レプリケーション レプリケーション o o o o o DR対応(クラスター横断レプ リケーション) o o o ローカライズ UI 日本語化 o o o o o サポート Webサポート o o o o 最新バージョンに自動 更新 o 公式サイトの機能比較表より引用
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
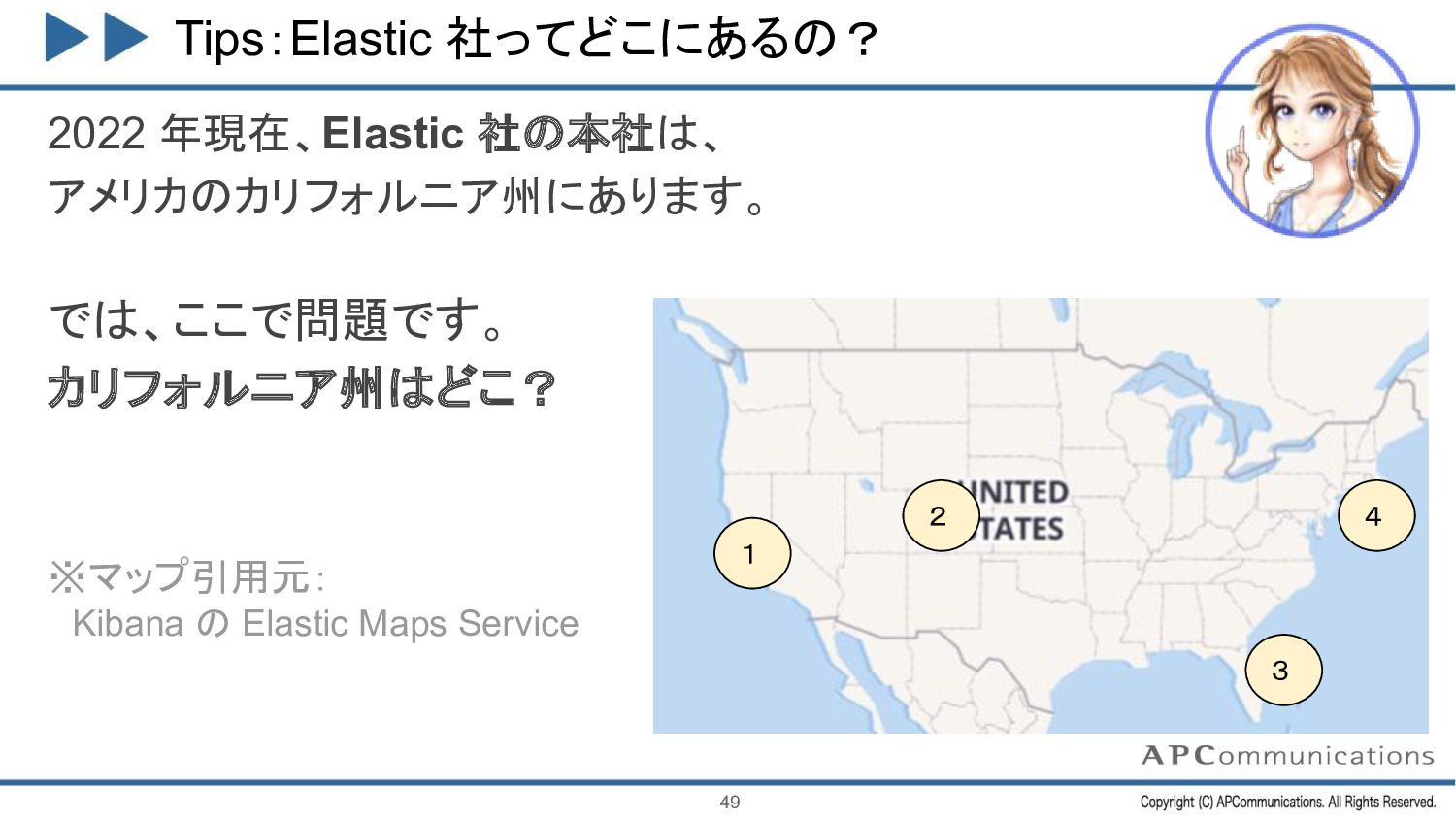{kind=link}
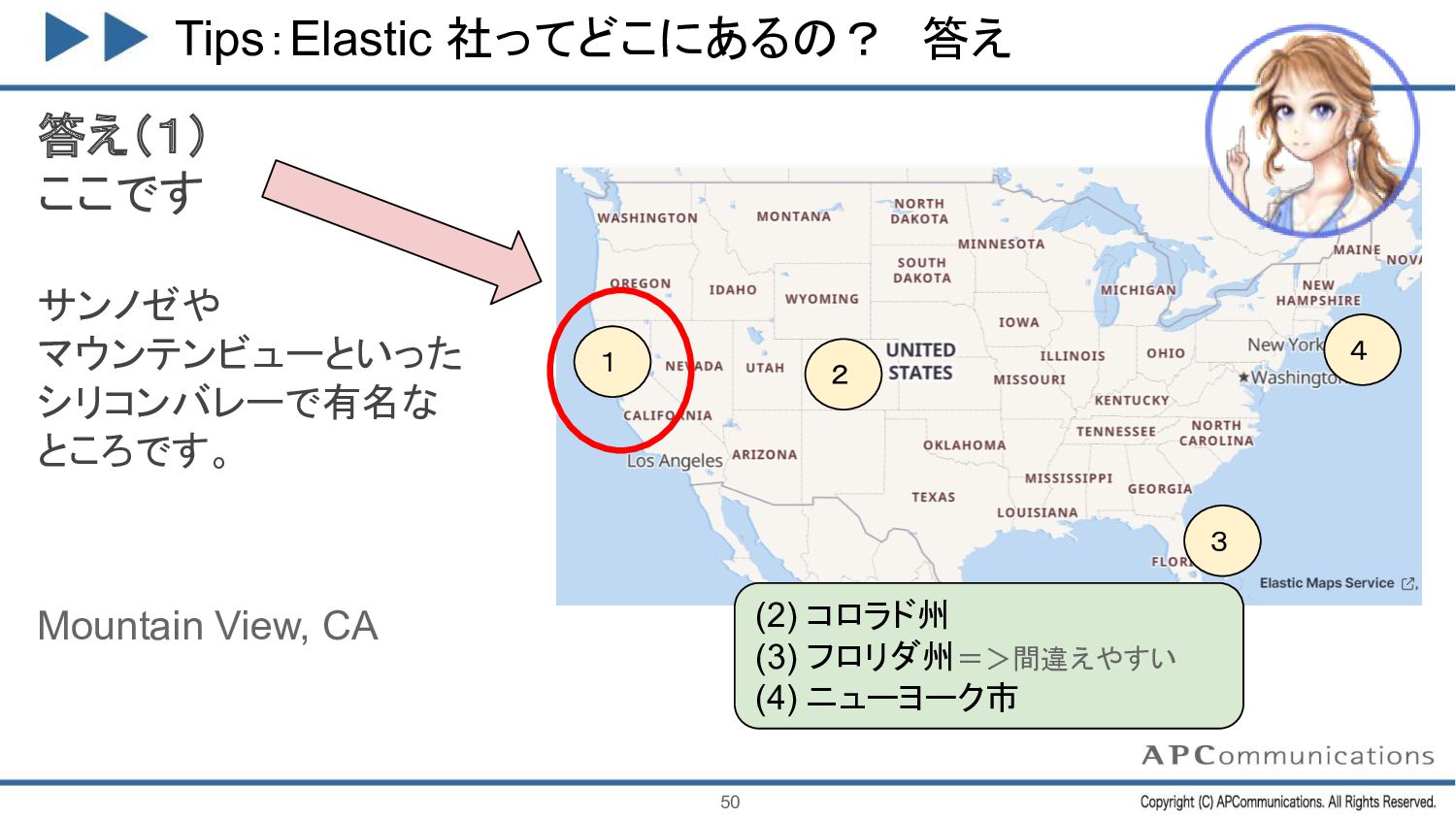{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
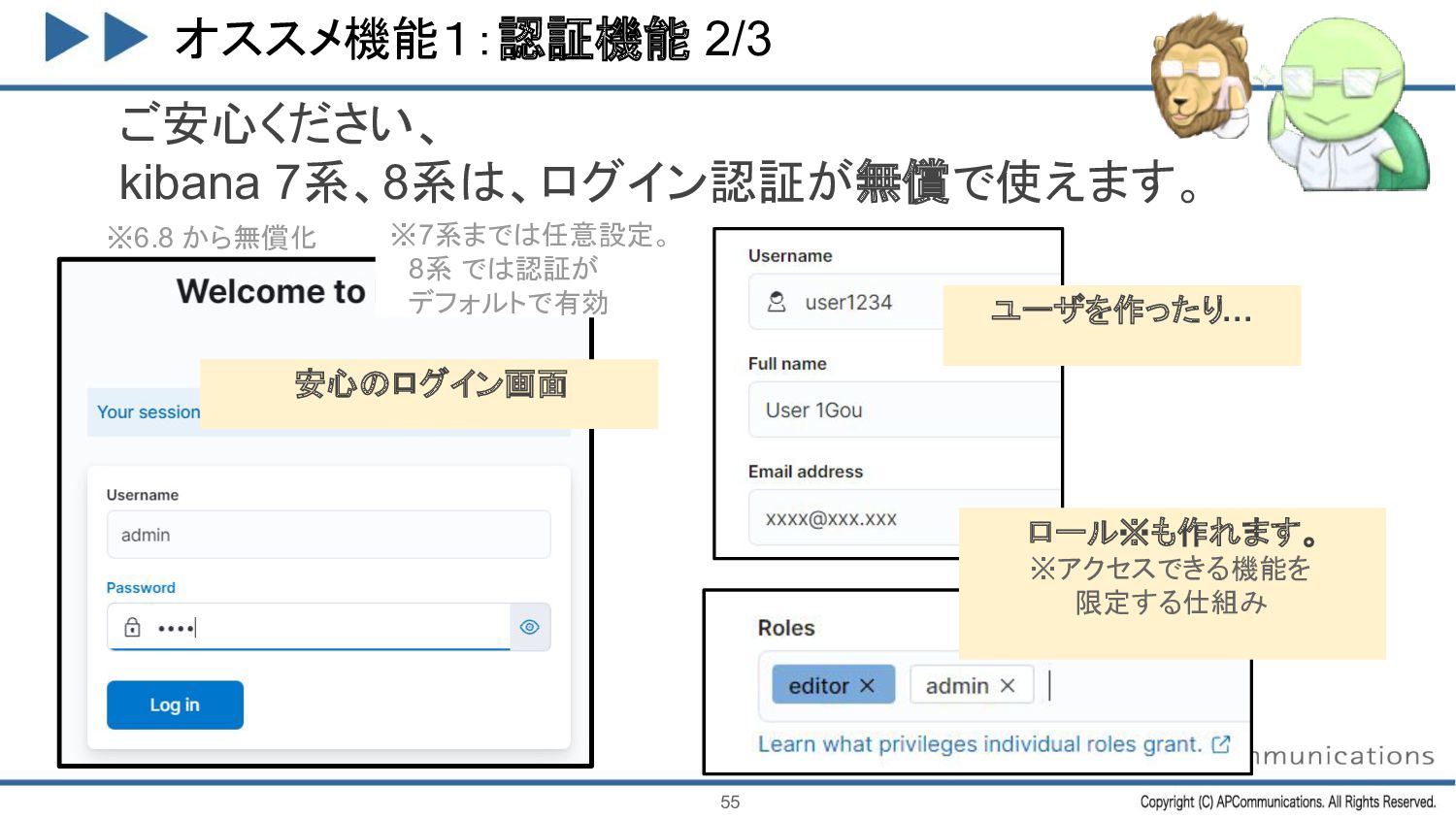{kind=link}
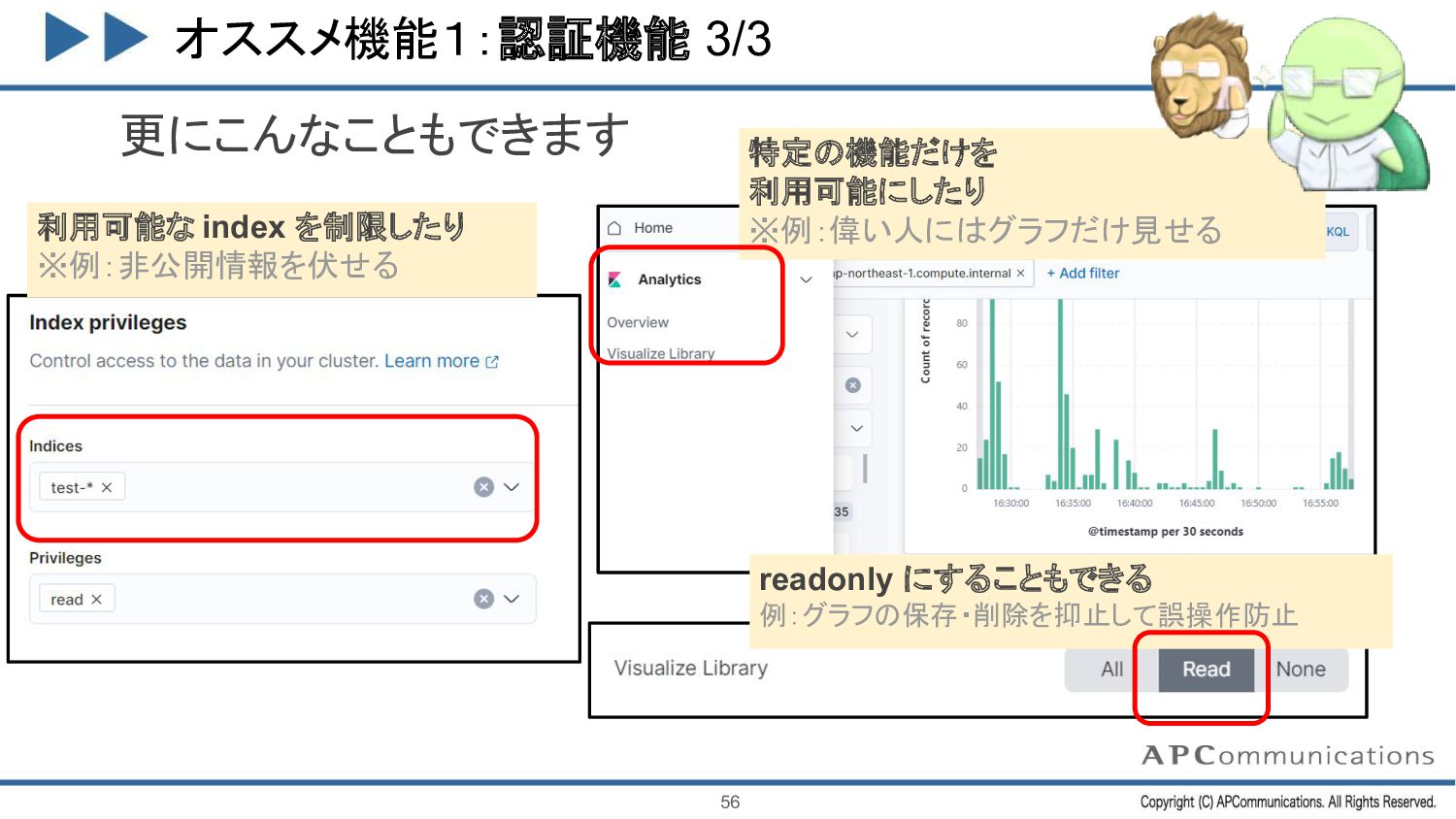{kind=link}
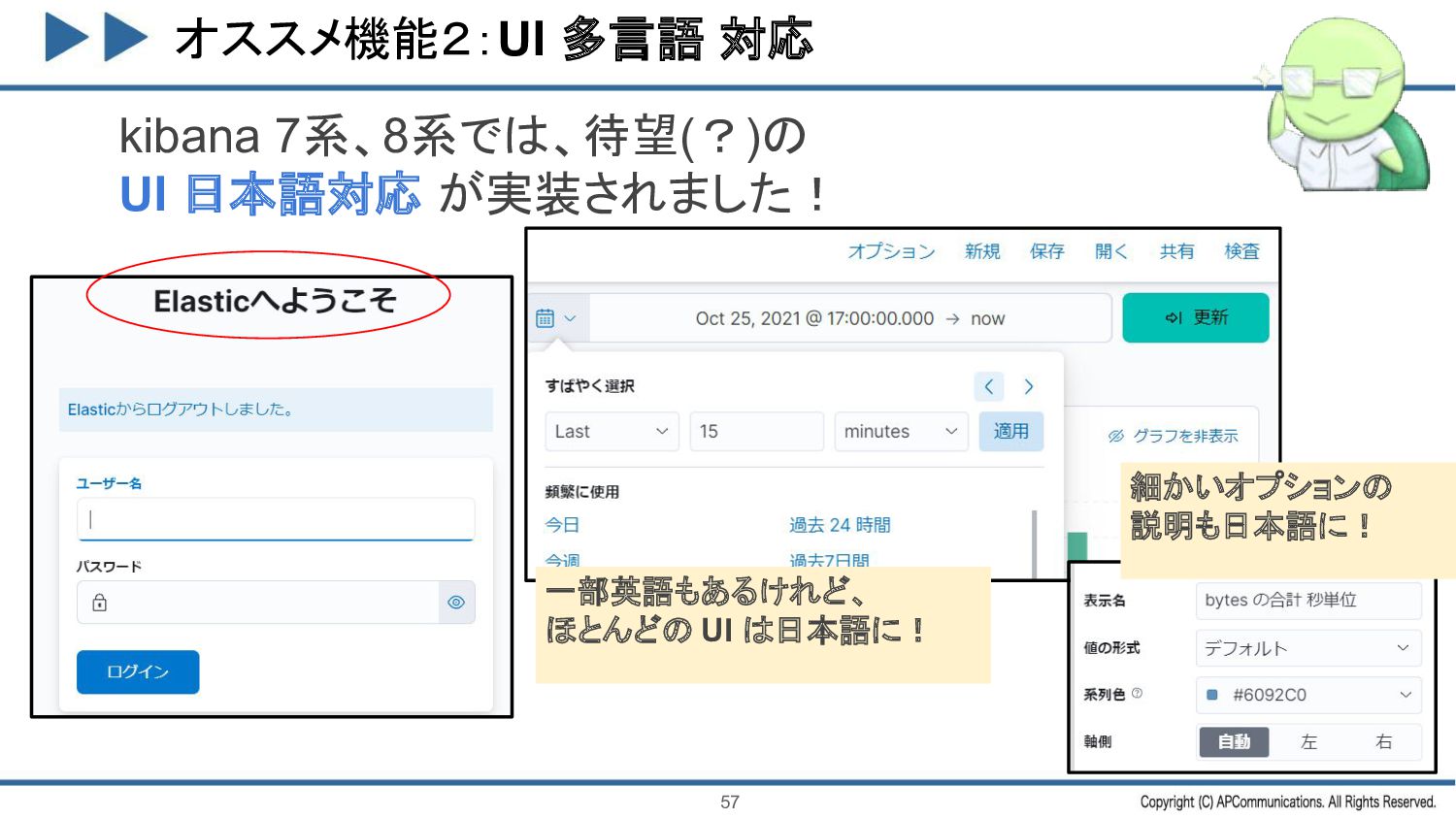{kind=link}
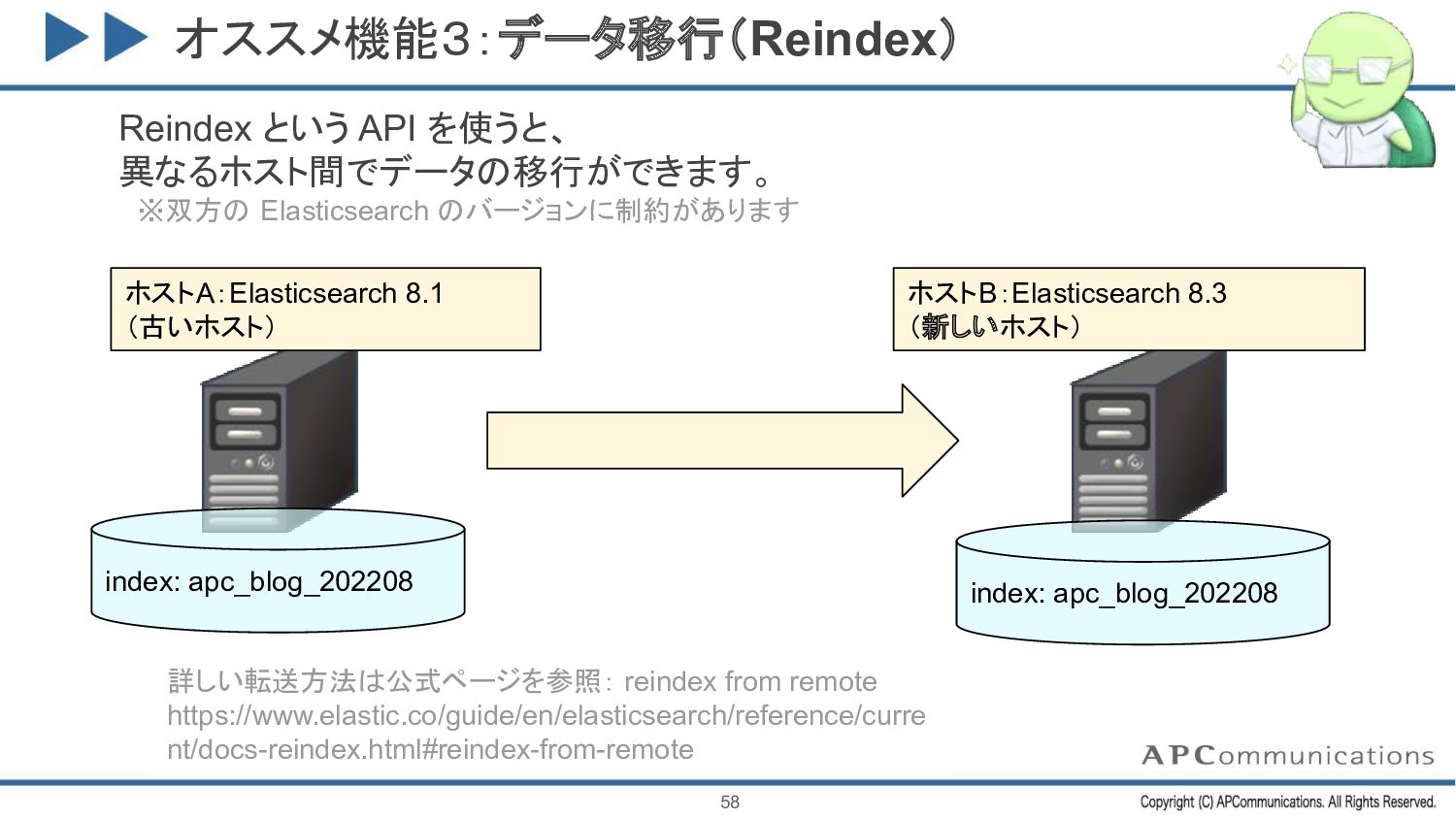{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
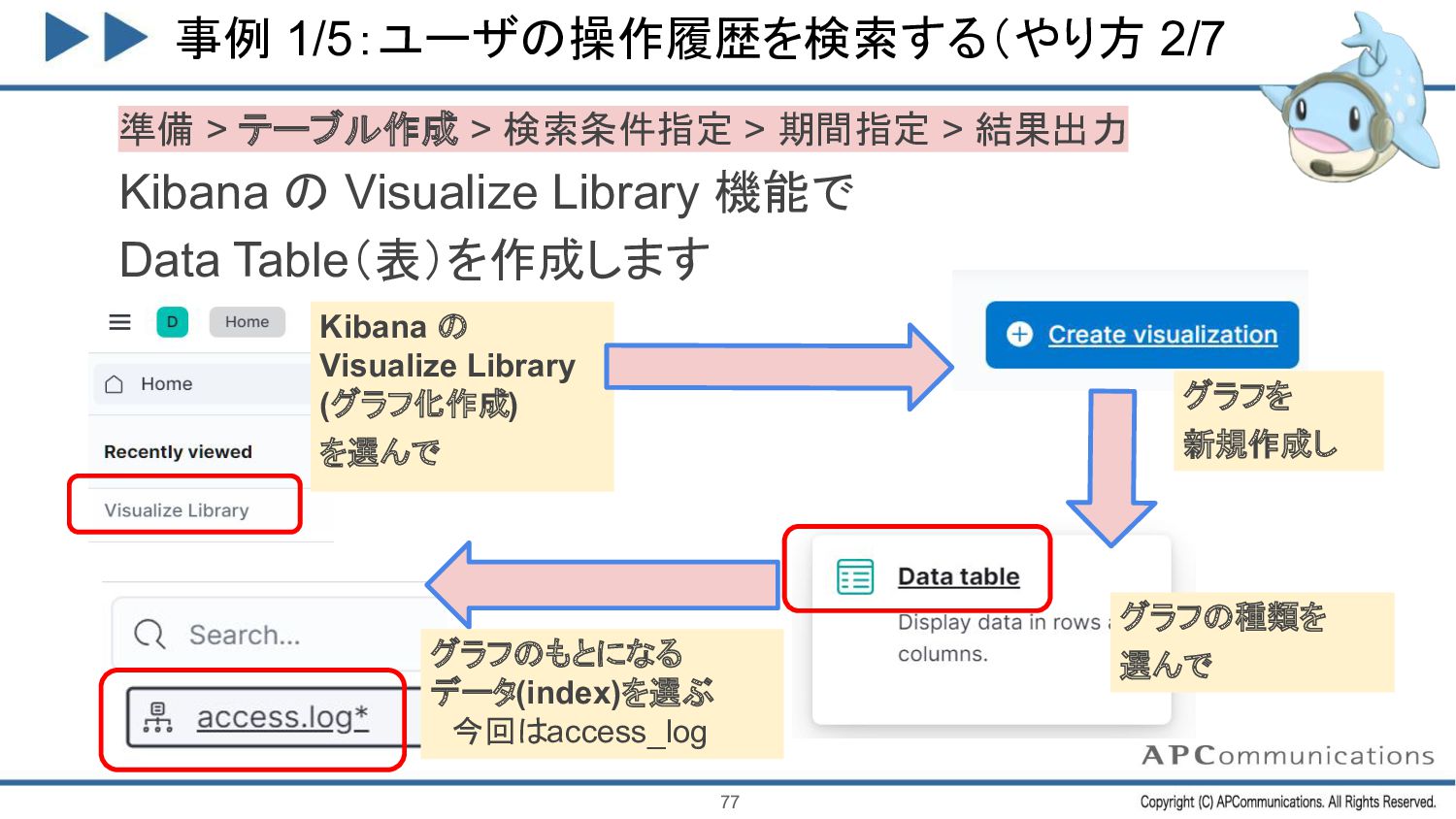{kind=link}
{kind=link}
{kind=link}
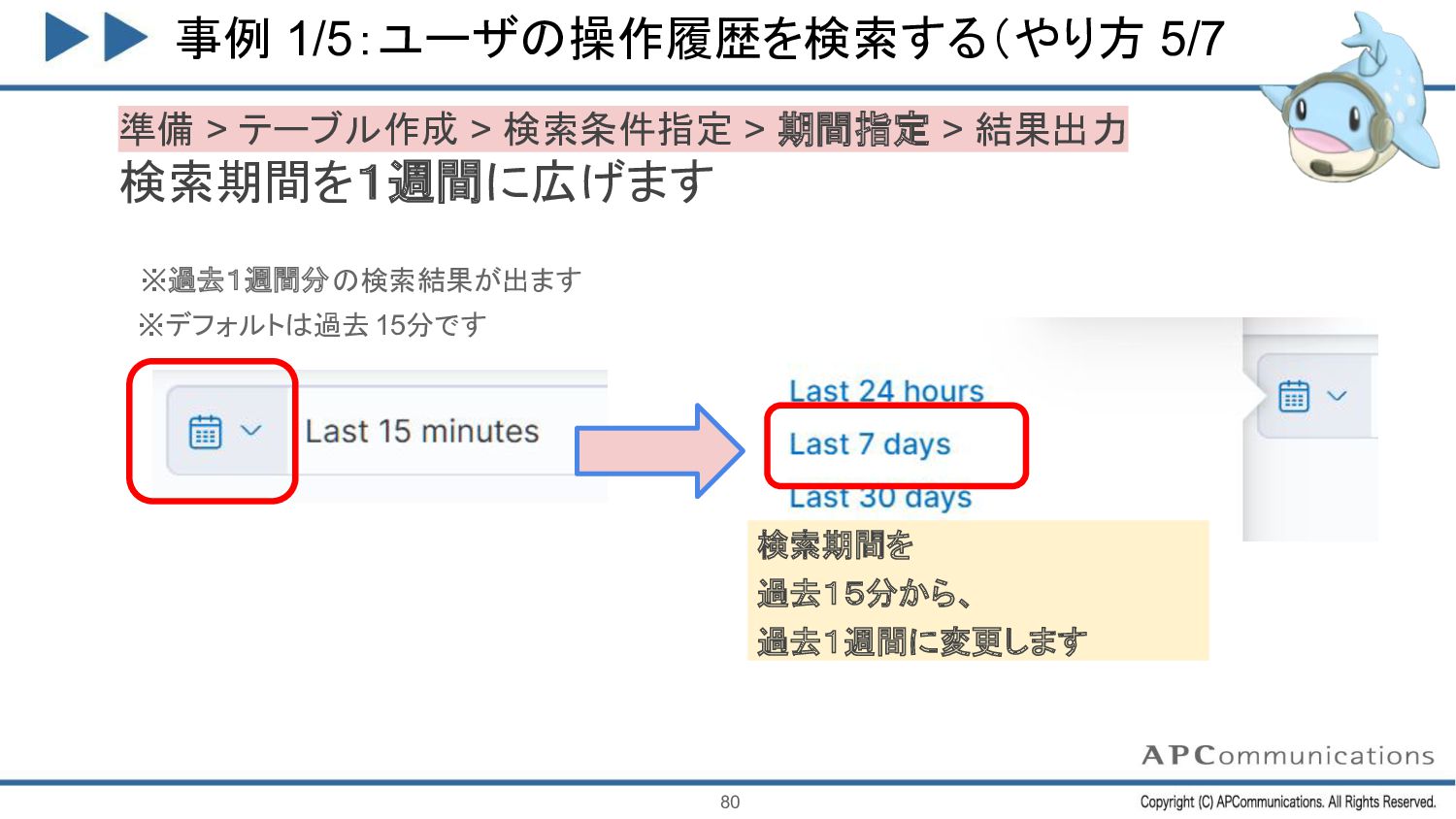{kind=link}
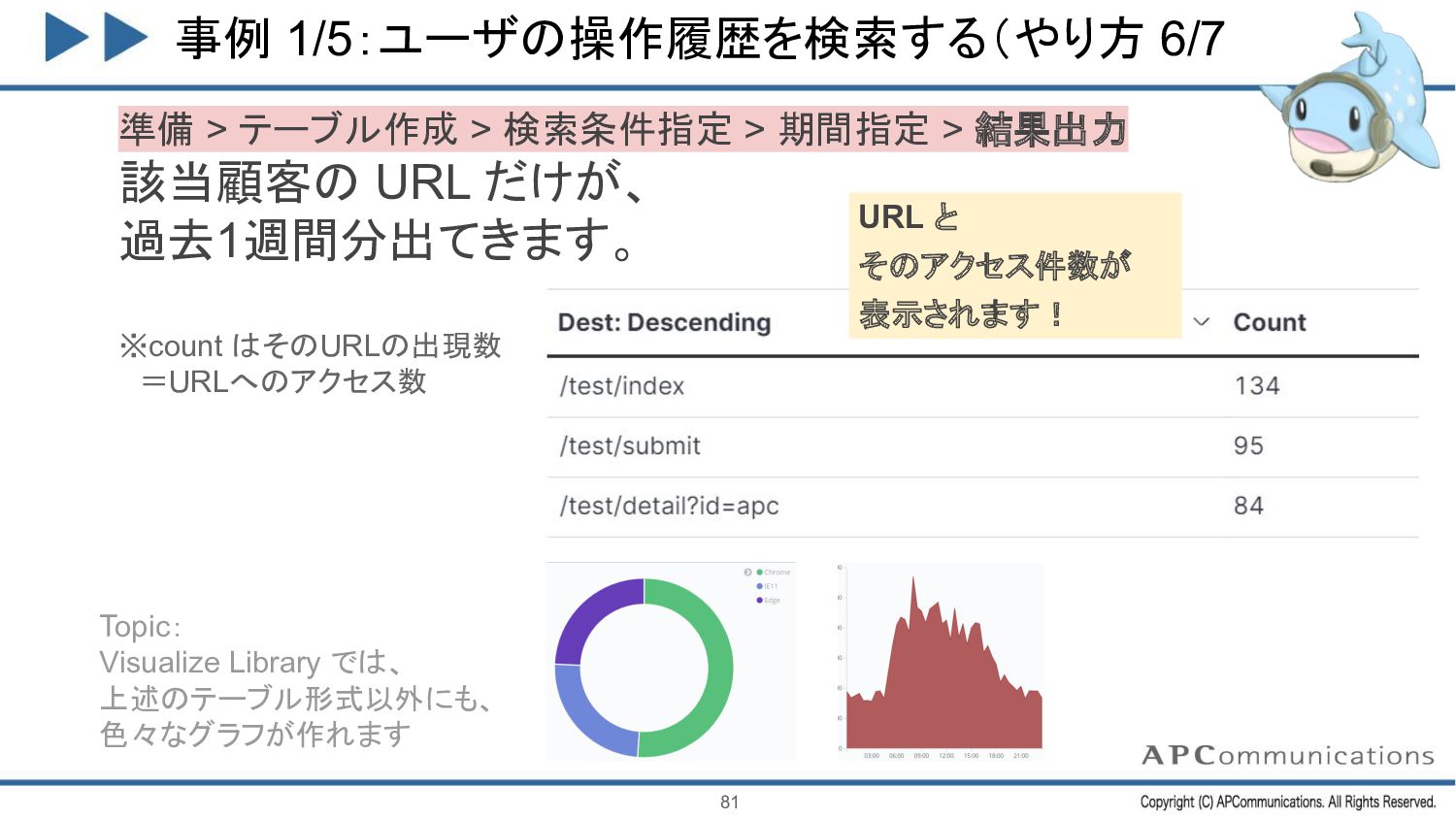{kind=link}
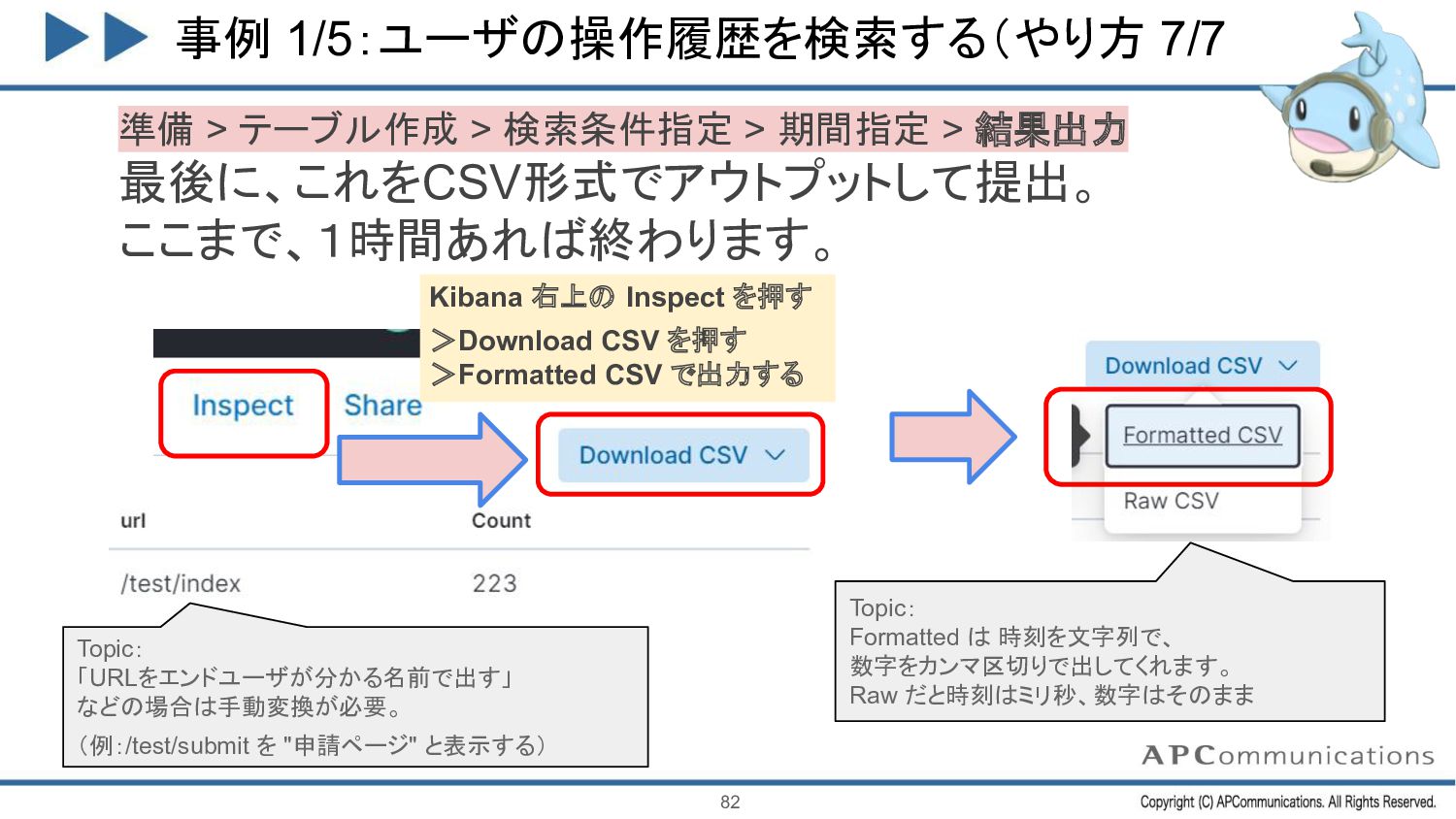{kind=link}
{kind=link}
{kind=link}
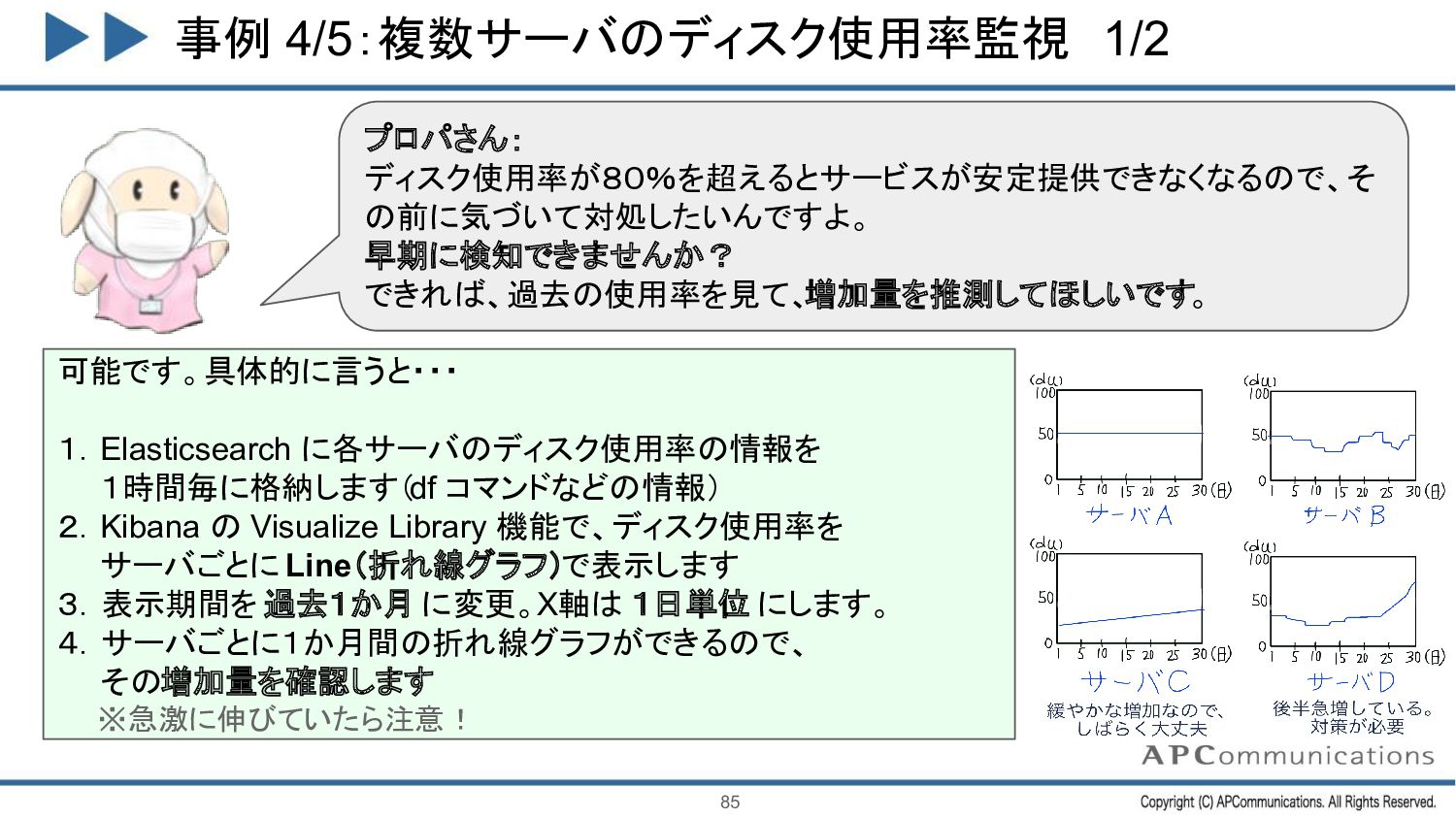{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}