Machine Translation for Extremely Low Resource Languages Jiatao Gu∗, Hany Hassan, Jacob Devlin, Victor O.K. Li Takeshi Hayakawa, Osaka University At journal club for NAACL 2018 1
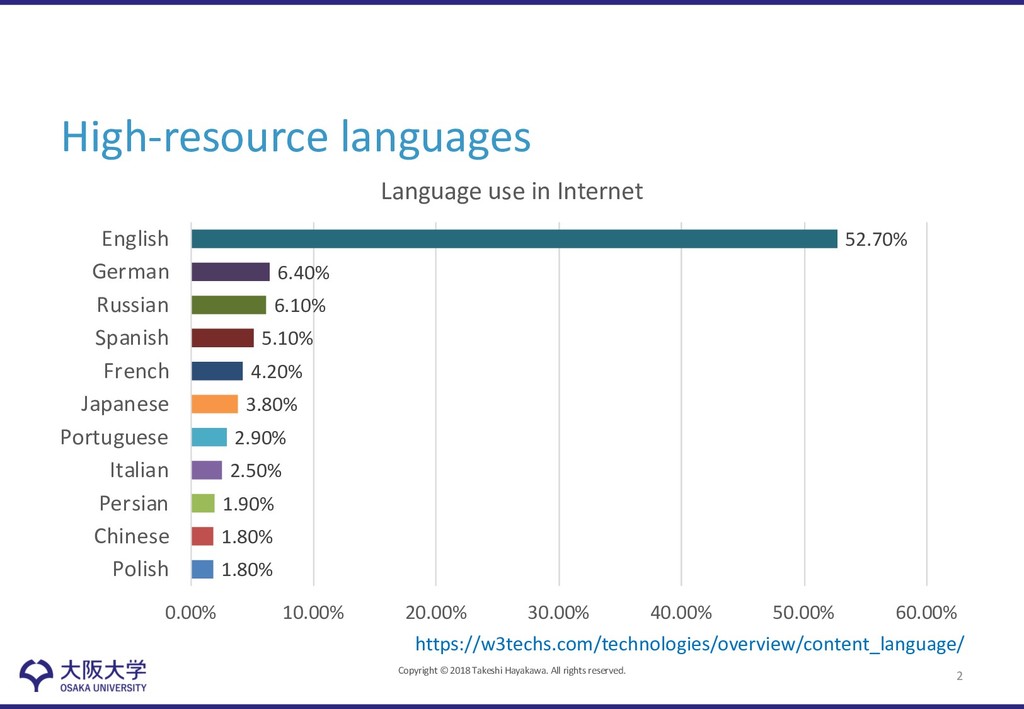
2 1.80% 1.80% 1.90% 2.50% 2.90% 3.80% 4.20% 5.10% 6.10% 6.40% 52.70% 0.00% 10.00% 20.00% 30.00% 40.00% 50.00% 60.00% Polish Chinese Persian Italian Portuguese Japanese French Spanish Russian German English Language use in Internet https://w3techs.com/technologies/overview/content_language/
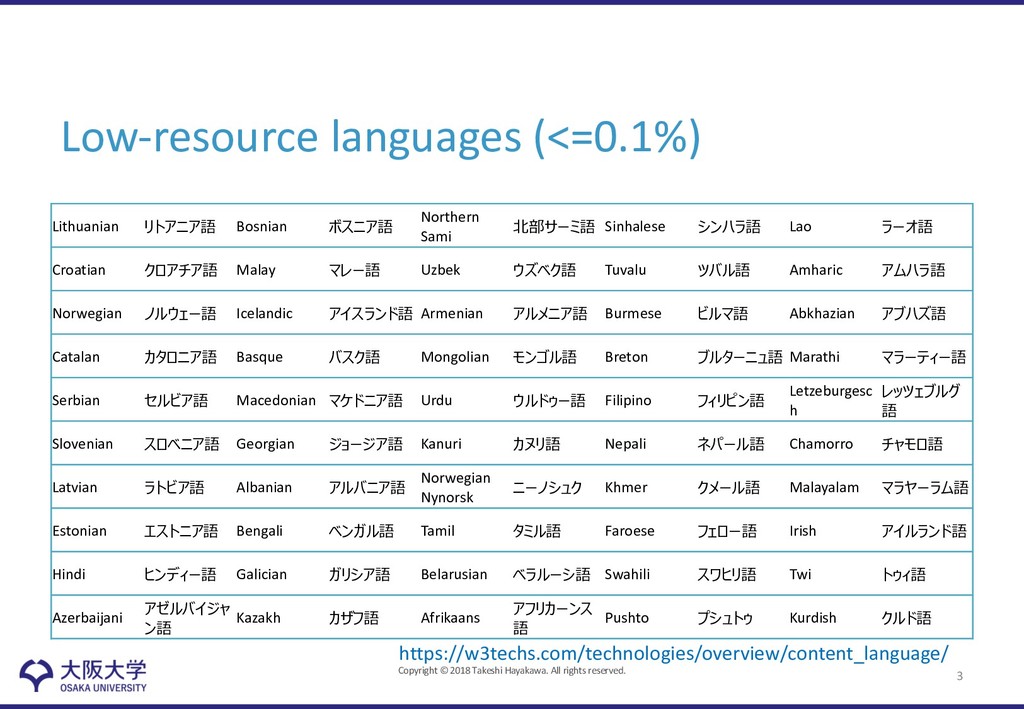
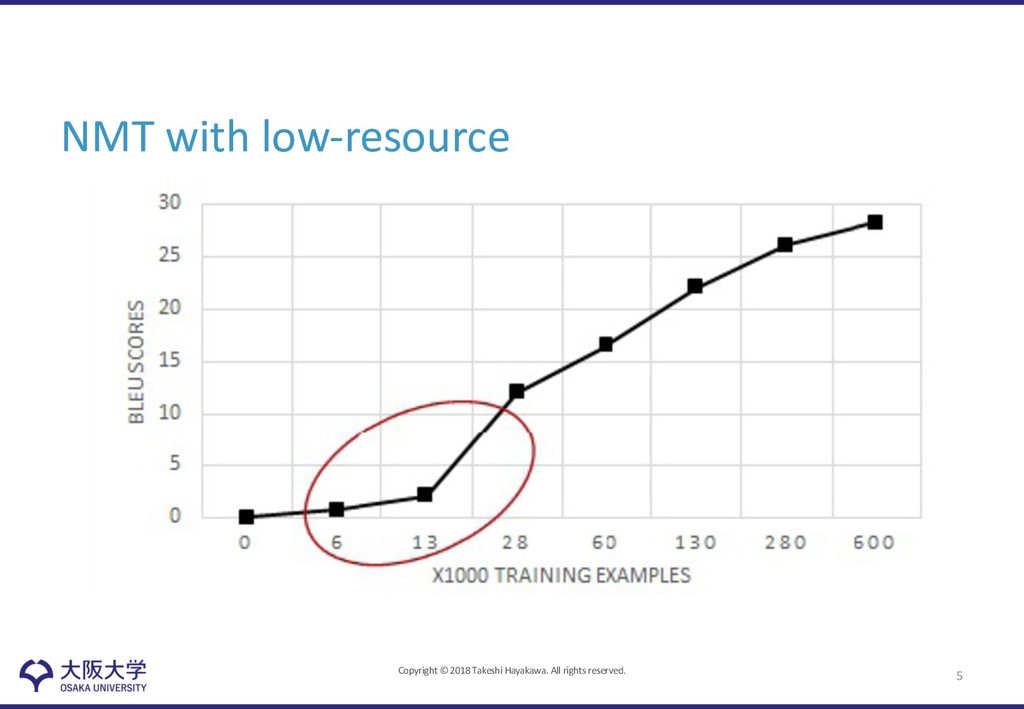
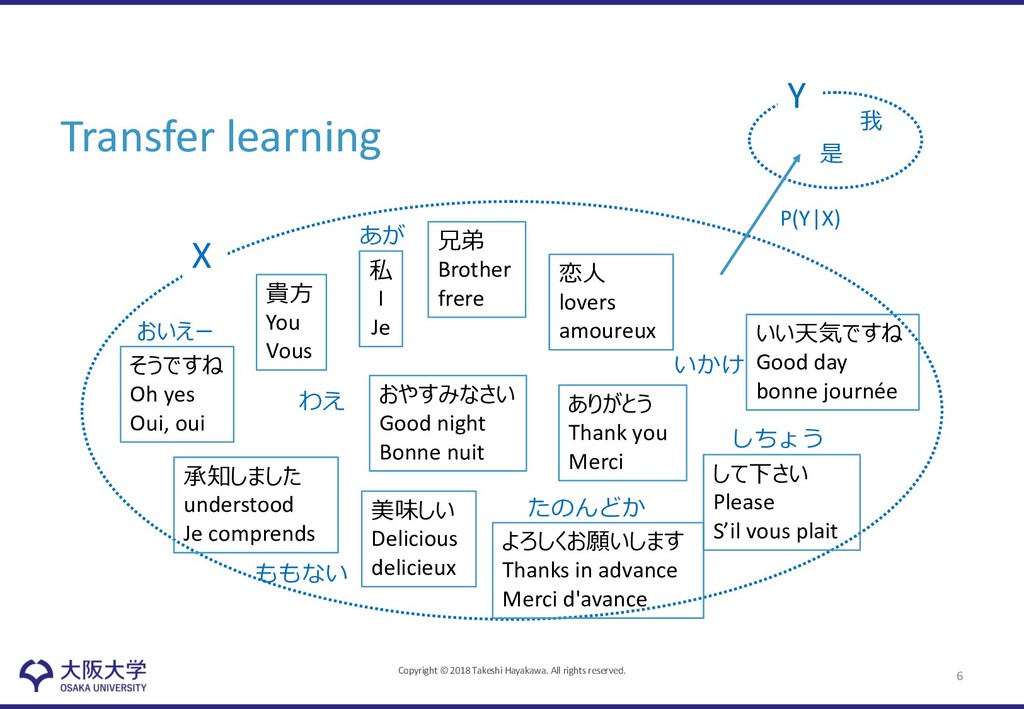
low-resource languages • Challenges – Low-resource language will not have enough training examples to get a reliably trained model with its representation • Lexical-level Sharing – Shares semantic representation across all languages • Sentence-level Sharing – Shares syntactic order with another language with the use of monolingual representation 8
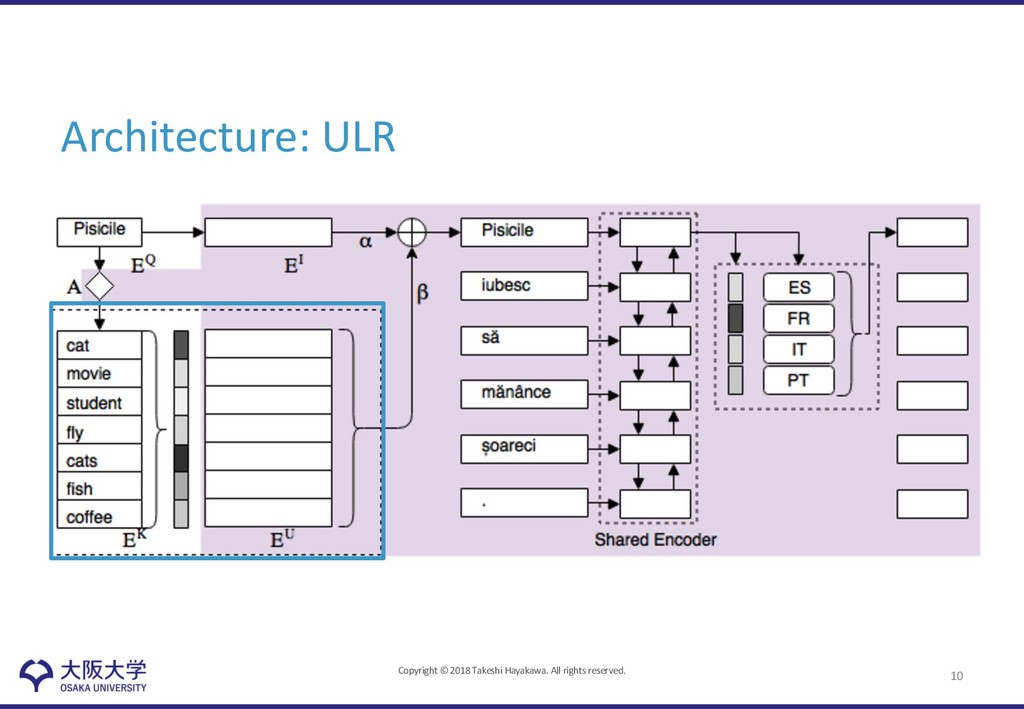
Representation (ULR) • Lexicon Mapping to the Universal Token Space – define universal token into which all source languages are projected – each source word is represented as a mixture of universal tokens – Train the projection matrix embedding each language in a similar semantic space using seed (off-the-shelf) dictionary – Interpolate embedding of low-resource language using functional words, which is frequently appeared 9
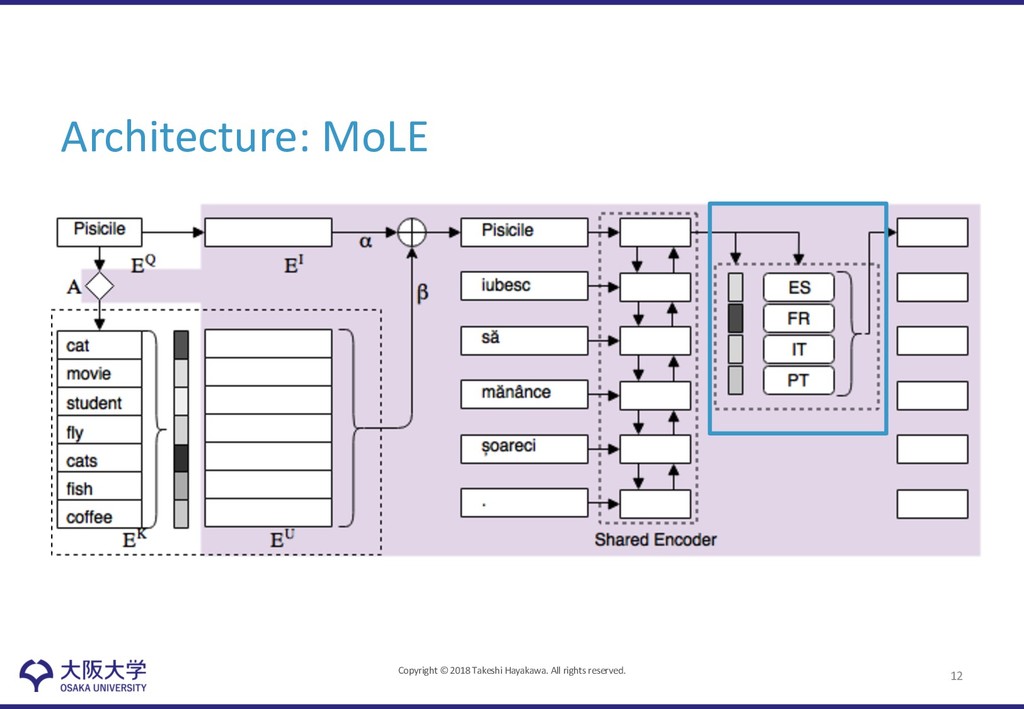
Language Experts (MoLE) • Language-sensitive module to model considering language-specific structure • Mixture experts for languages controlled by gating, which output weight of languages 11
• Languages – Low-resource: Romanian (Ro) / Latvian (Lv) / Korean (Ko) – High-resource: Czech (Cs), German (De), Greek (El), Spanish (Es), Finnish (Fi), French (Fr), Italian (It), Portuguese (Pt) and Russian (Ru) – Target: English (En) • Data – Parallel: WMT16, KPD, Europarl v8 + back translation (BT) – Monolingual: Wikipedia dumps 13
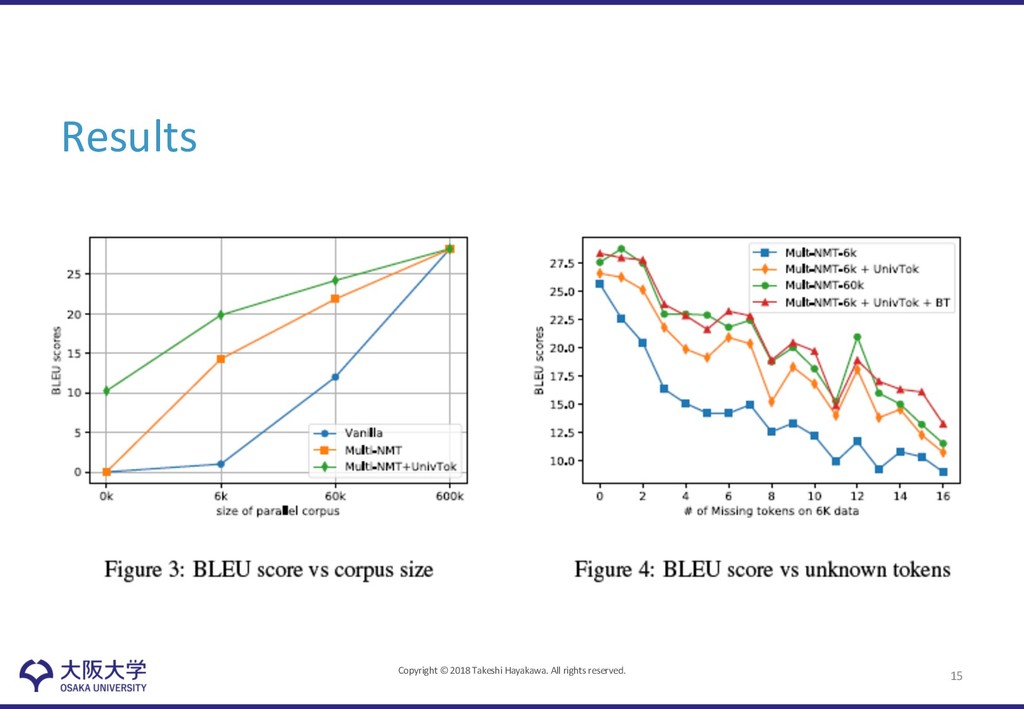
Authors proposed a new universal machine translation approach that enables sharing resources between high resource languages and extremely low resource languages • Achieved 23 BLEU on Romanian-English WMT2016 using parallel corpus of 6k sentences, compared to the 18 BLEU of strong multilingual baseline system 18
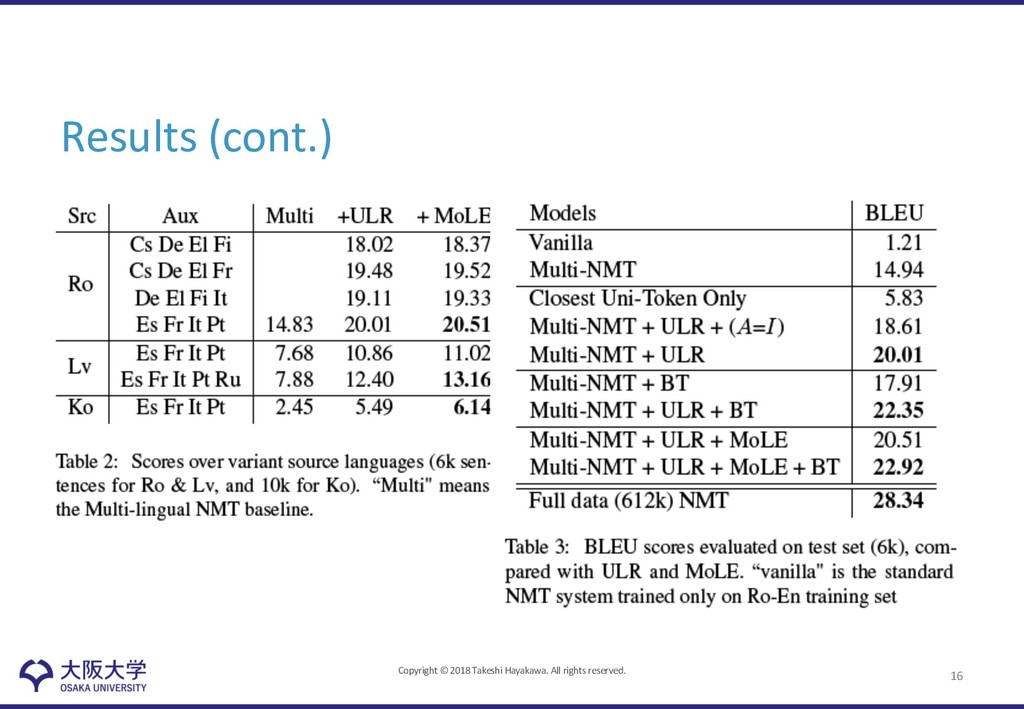
• Variation of scores depending on languages: Ro, 20.51; Lv, 13.16; Ko, 6.14 • Expansion to other NMT models/algorithms • Significant gap by rich-resource NMT by 6 BLEU 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}