Share
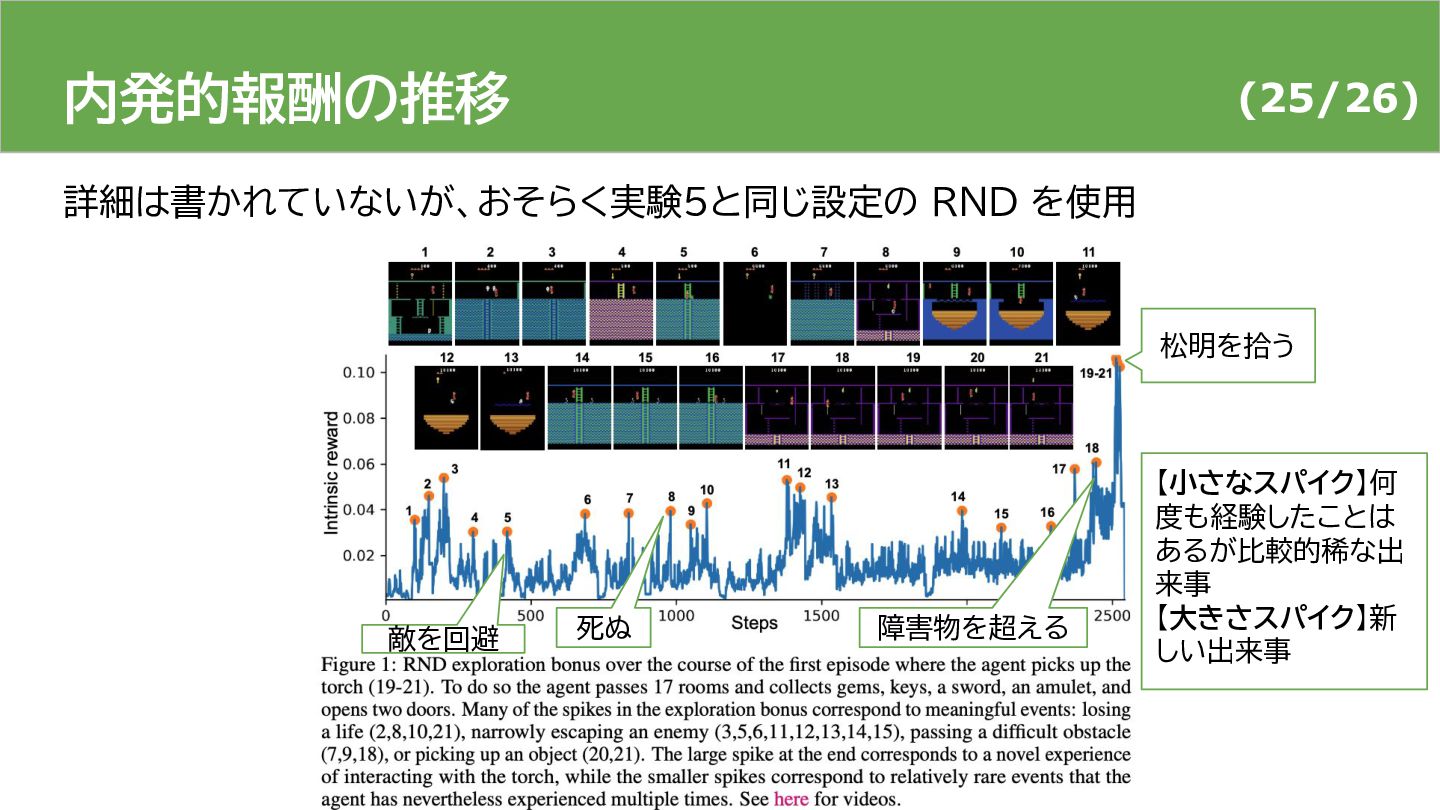
ICLR2019 で発表された Random Network Distillation と呼ばれる深層強化学習手法の紹介です。この手法は、好奇心(内発的動機づけ)をエージェントに与えるための内発的報酬を設計する機構であり、生成された内発的報酬を利用することでエージェントは探索を促進します。
{kind=link}
{kind=link}
{kind=link}
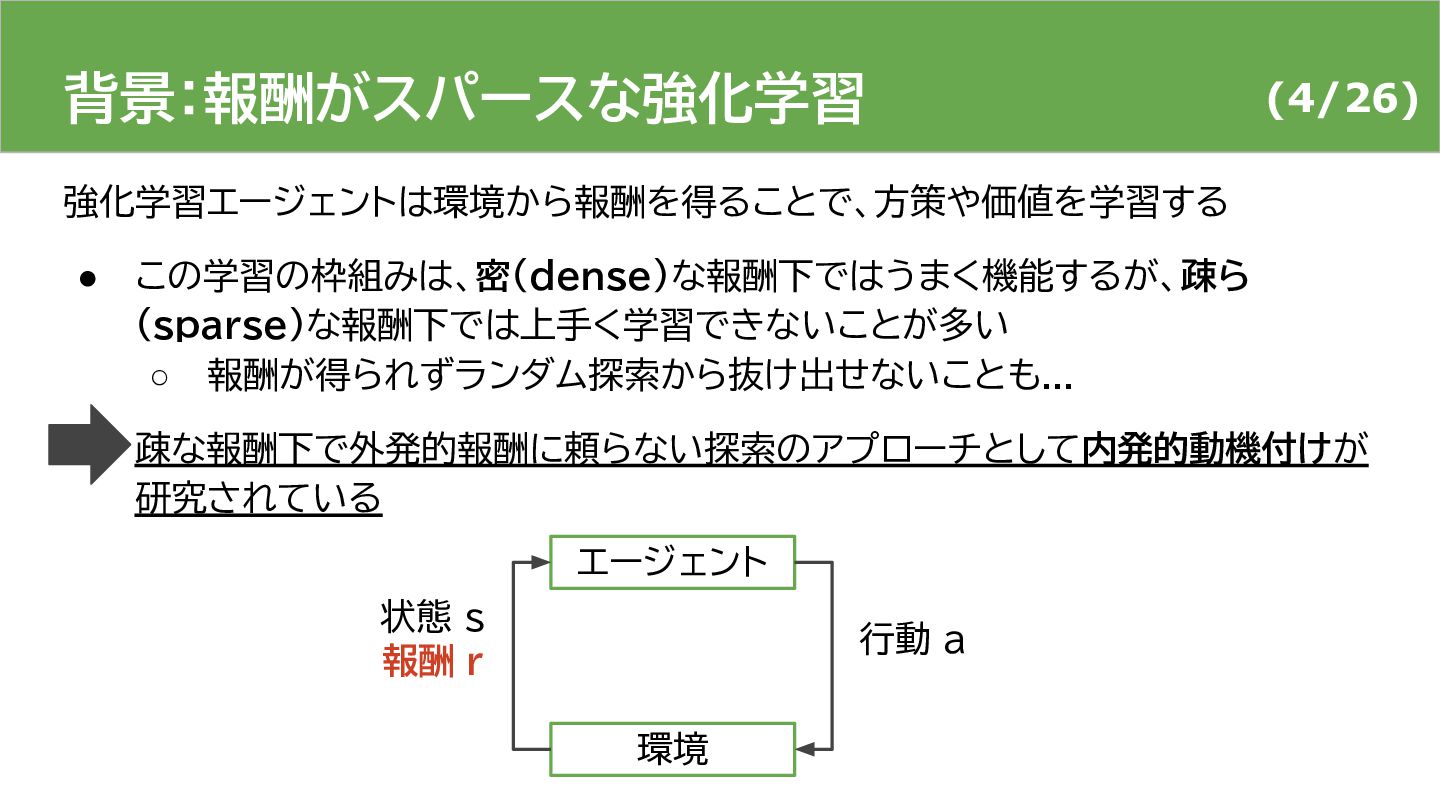{kind=link}
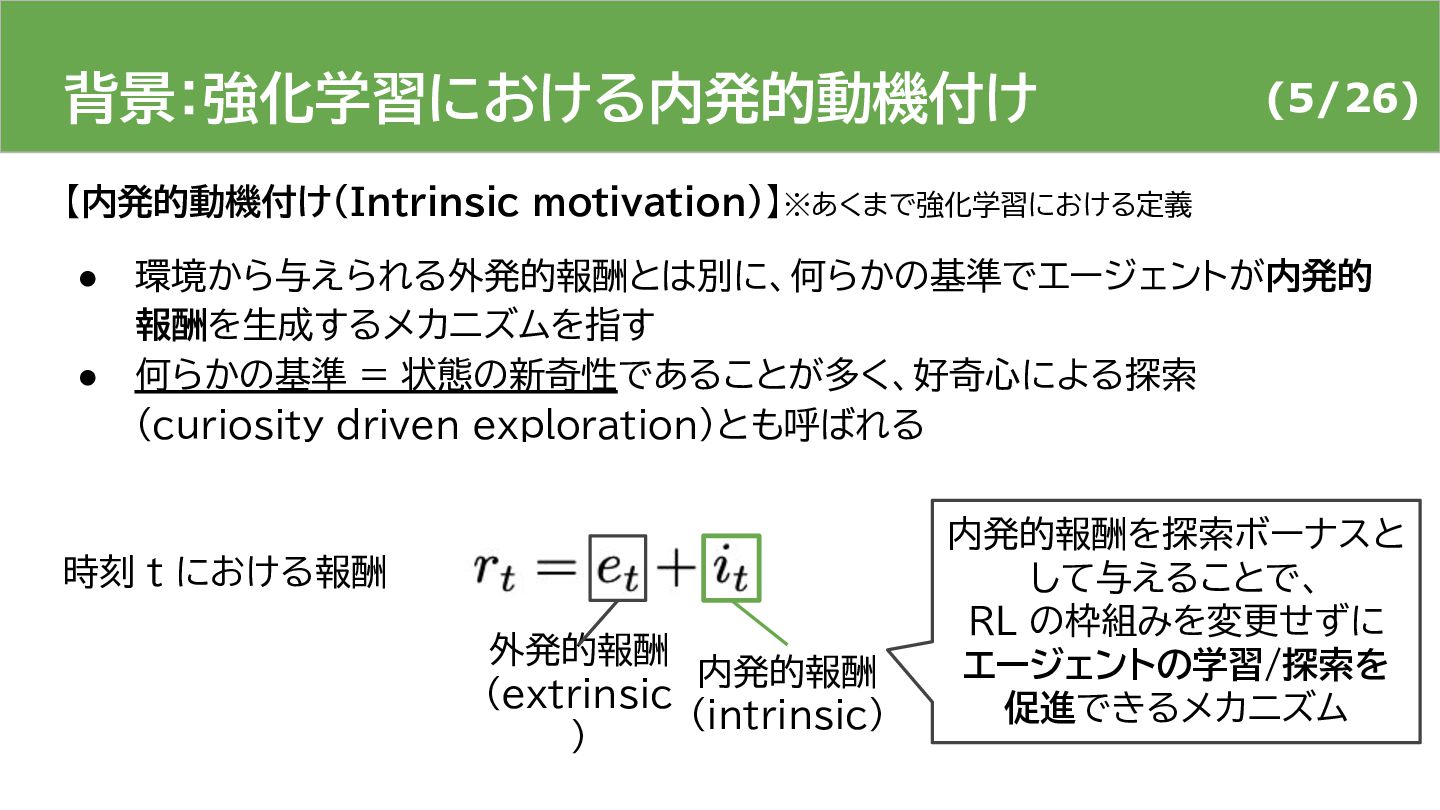{kind=link}
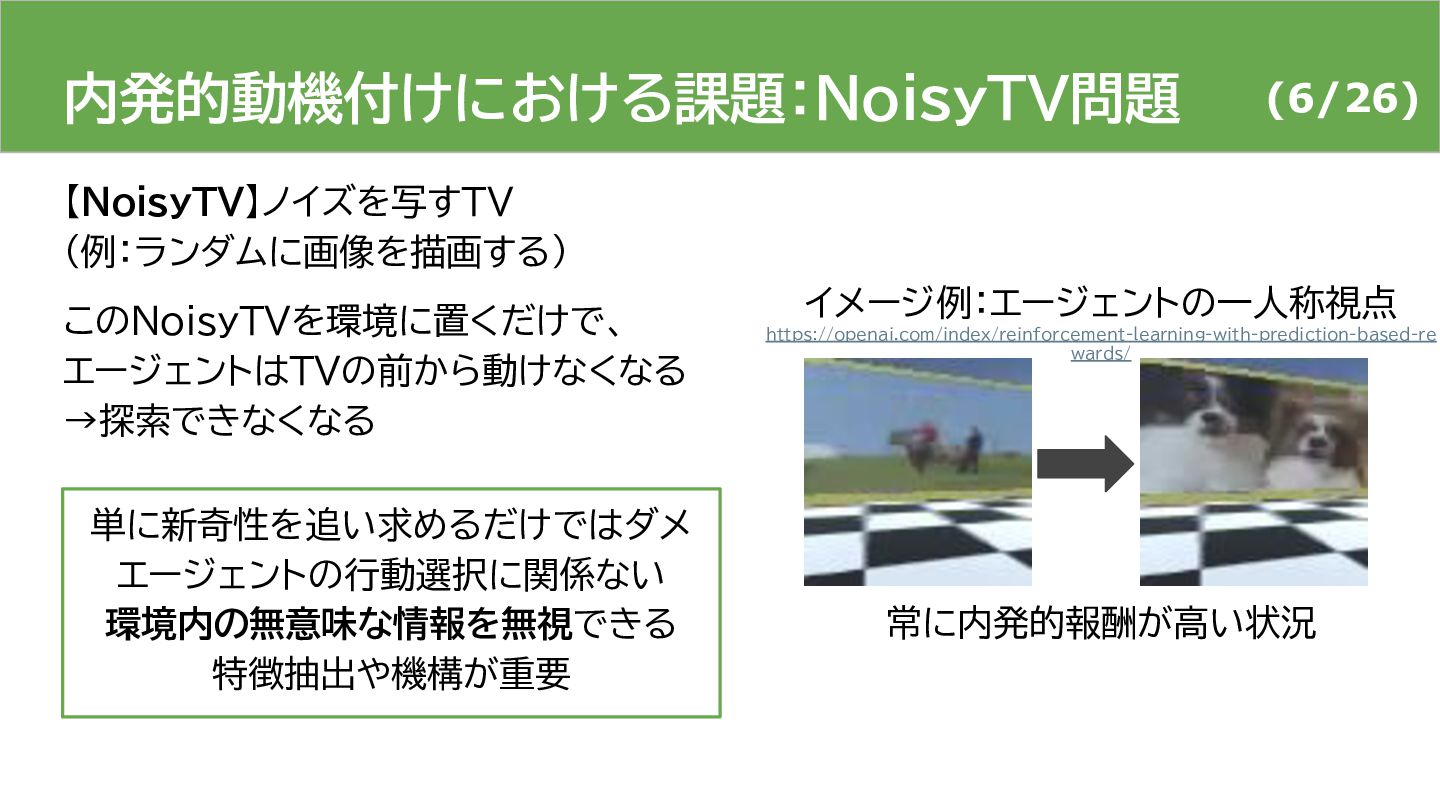{kind=link}
{kind=link}
{kind=link}
{kind=link}
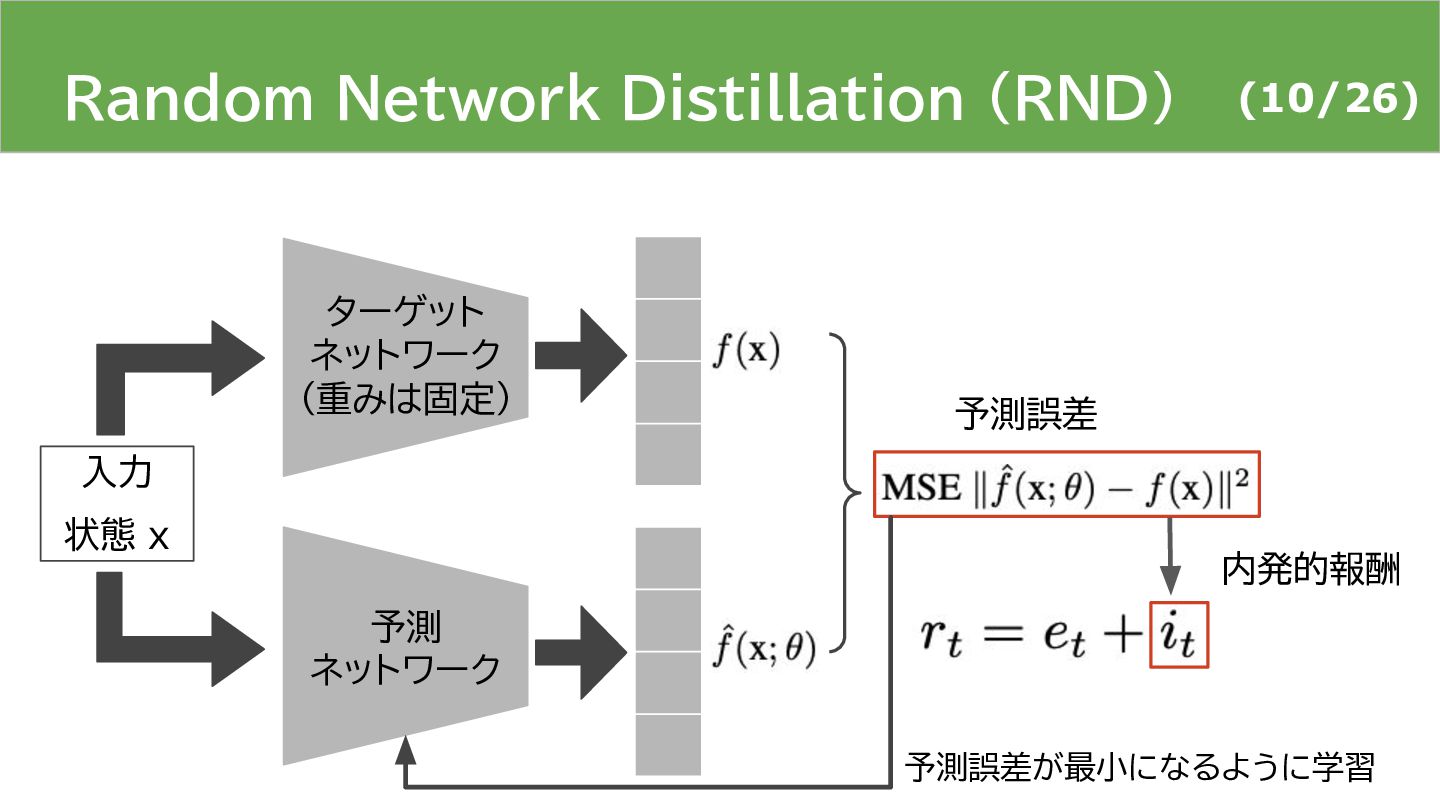{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
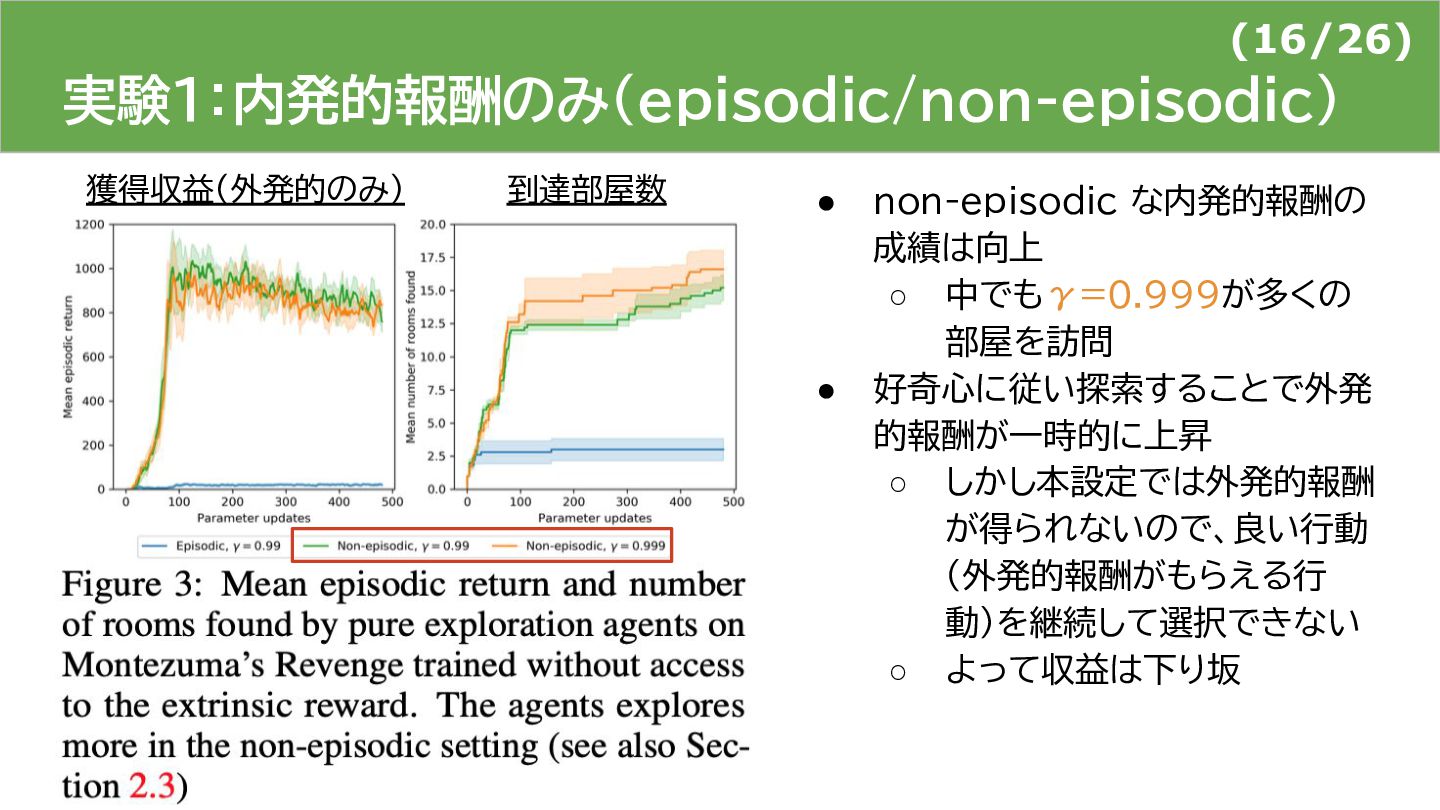{kind=link}
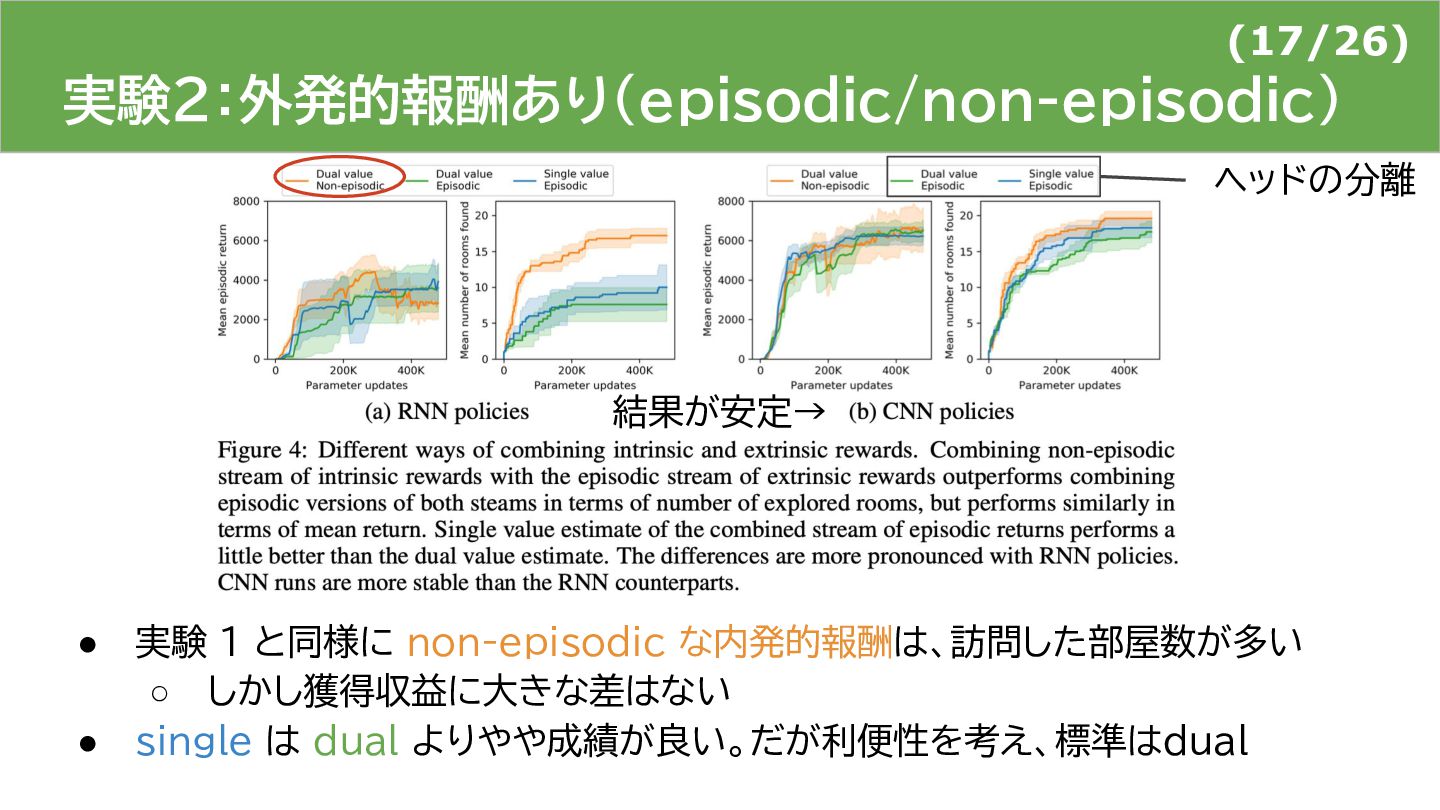{kind=link}
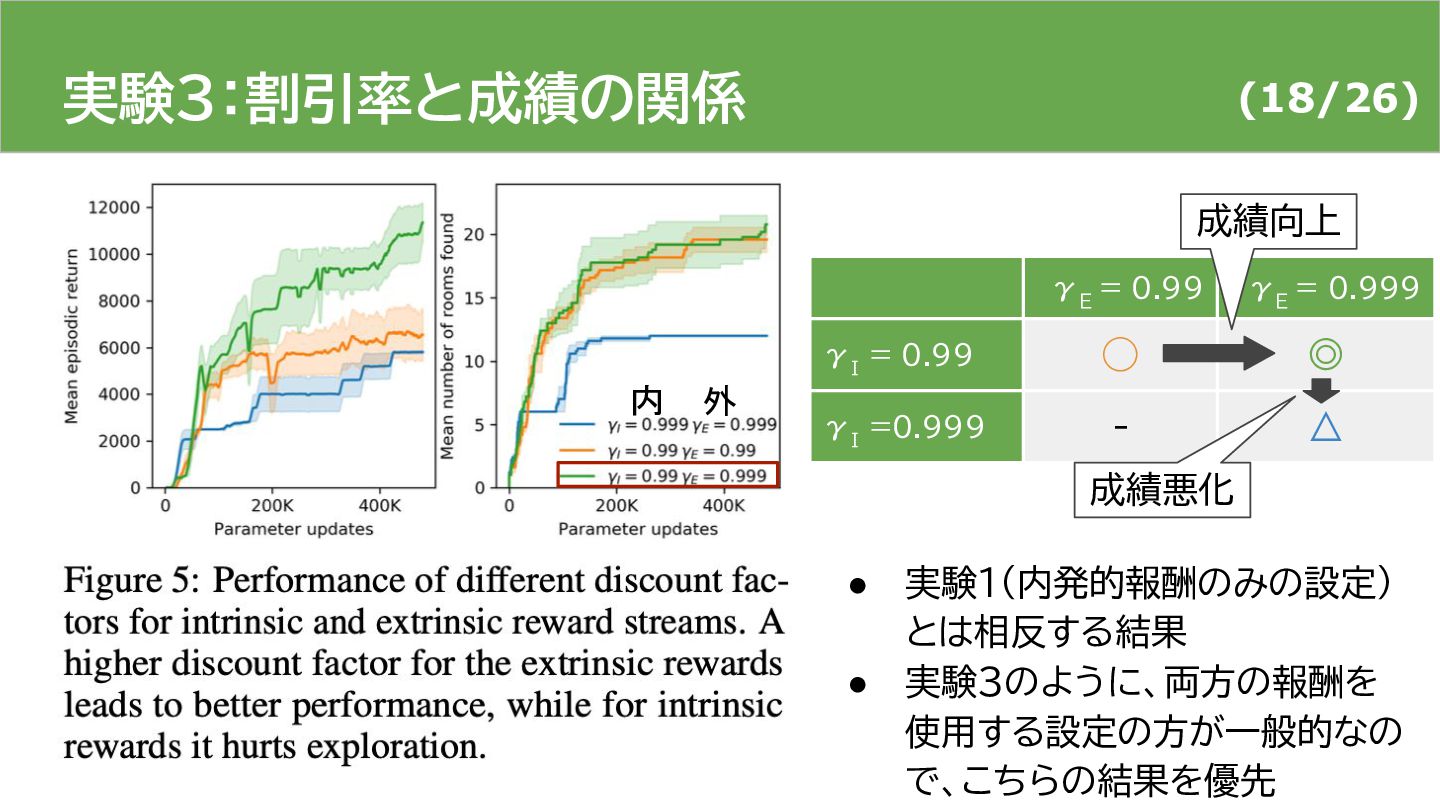{kind=link}
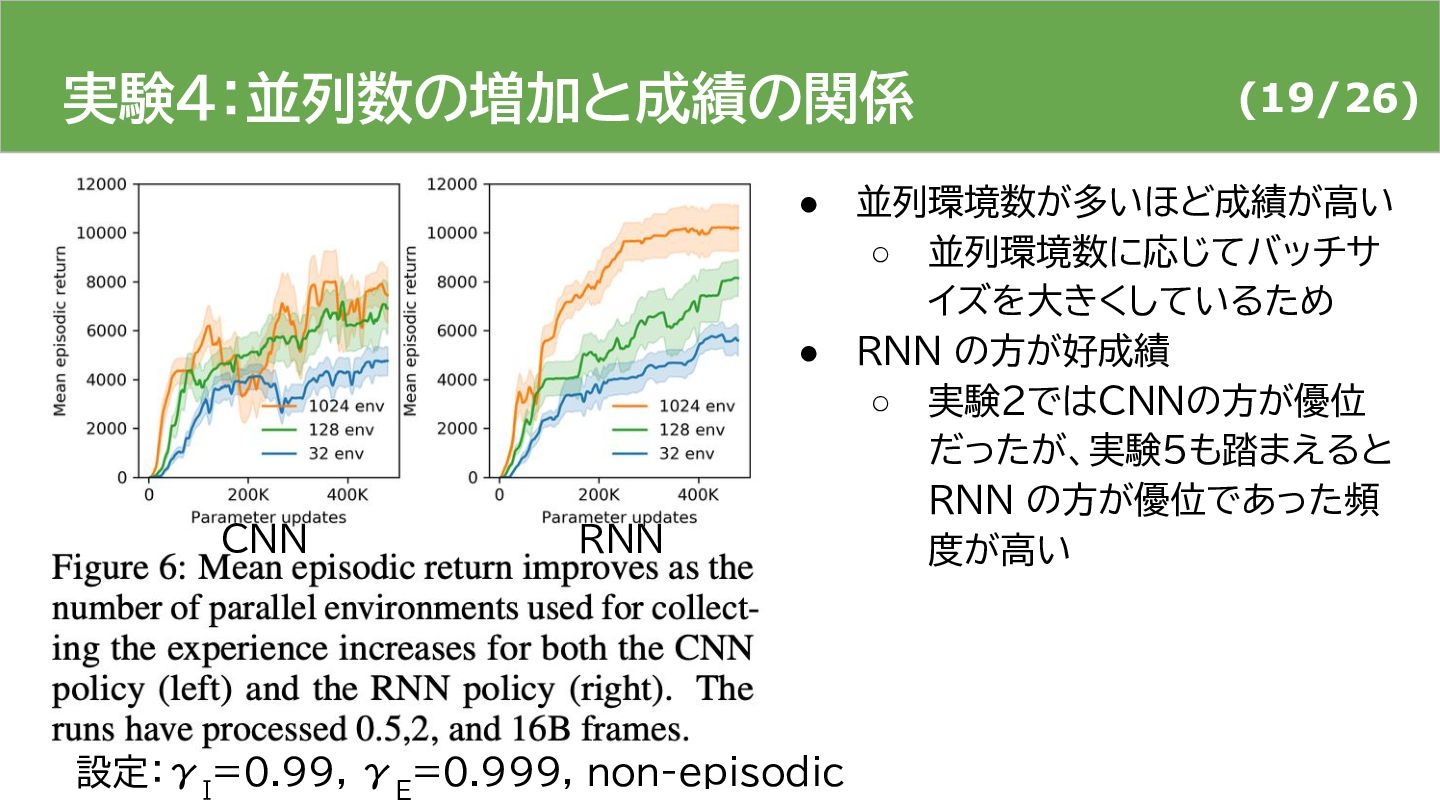{kind=link}
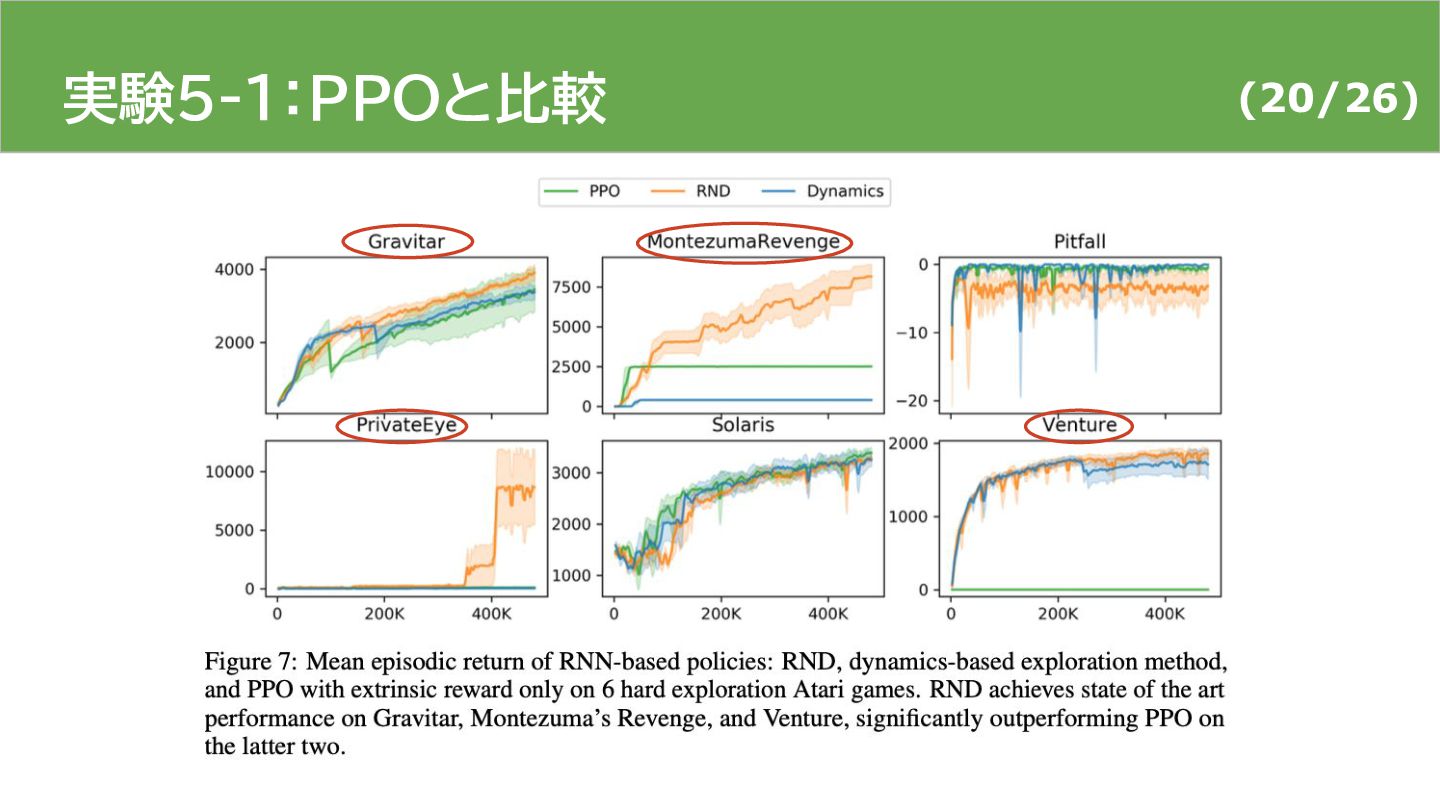{kind=link}
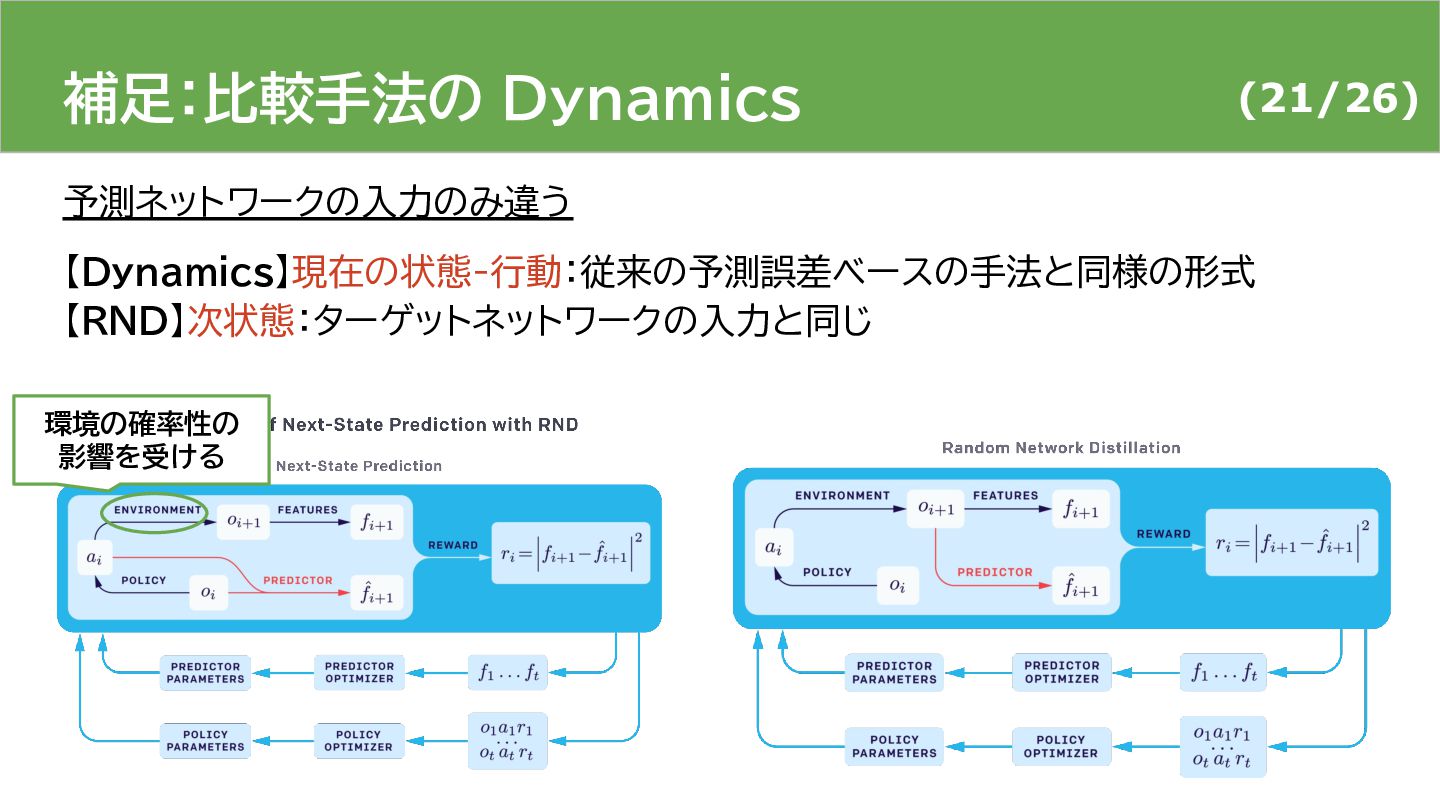{kind=link}
{kind=link}
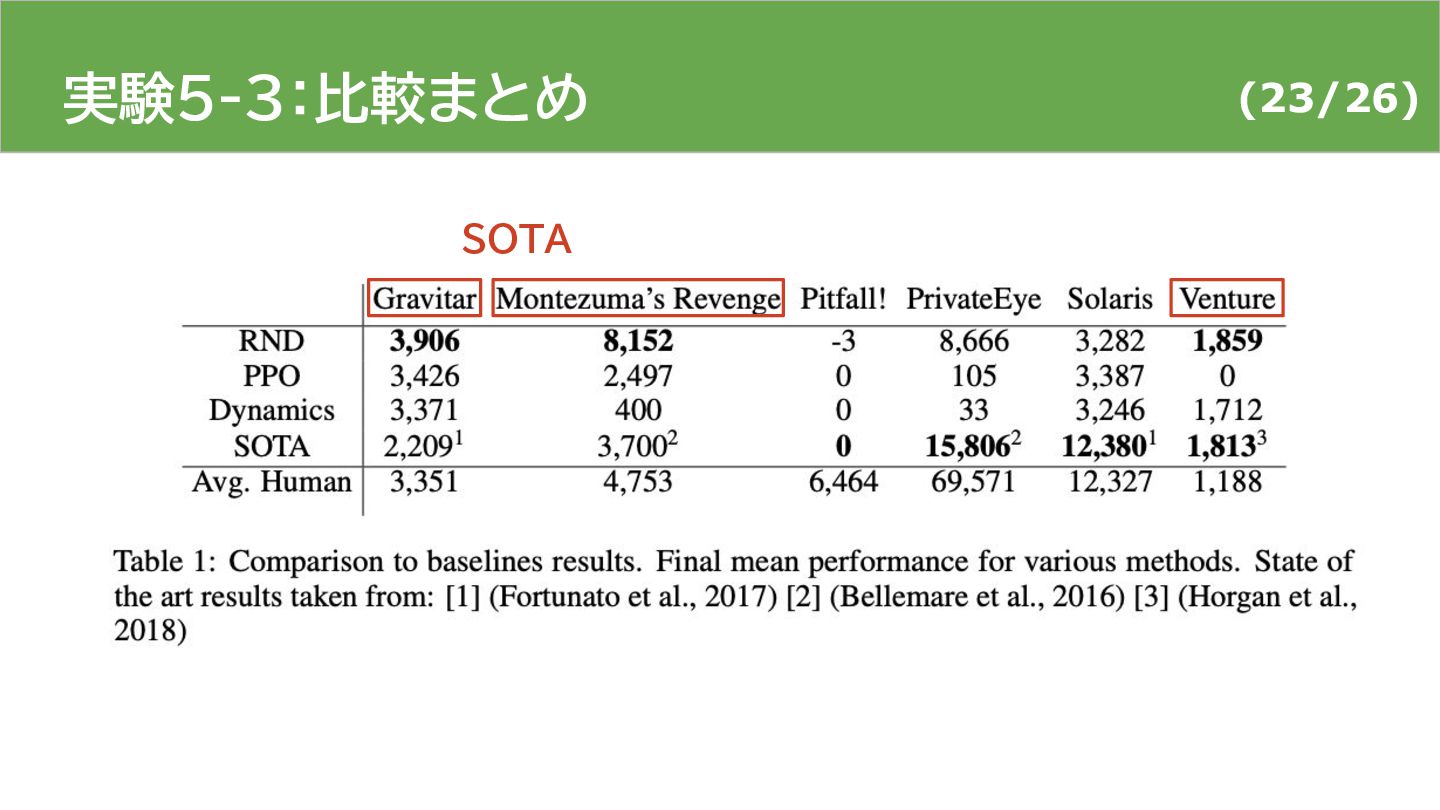{kind=link}
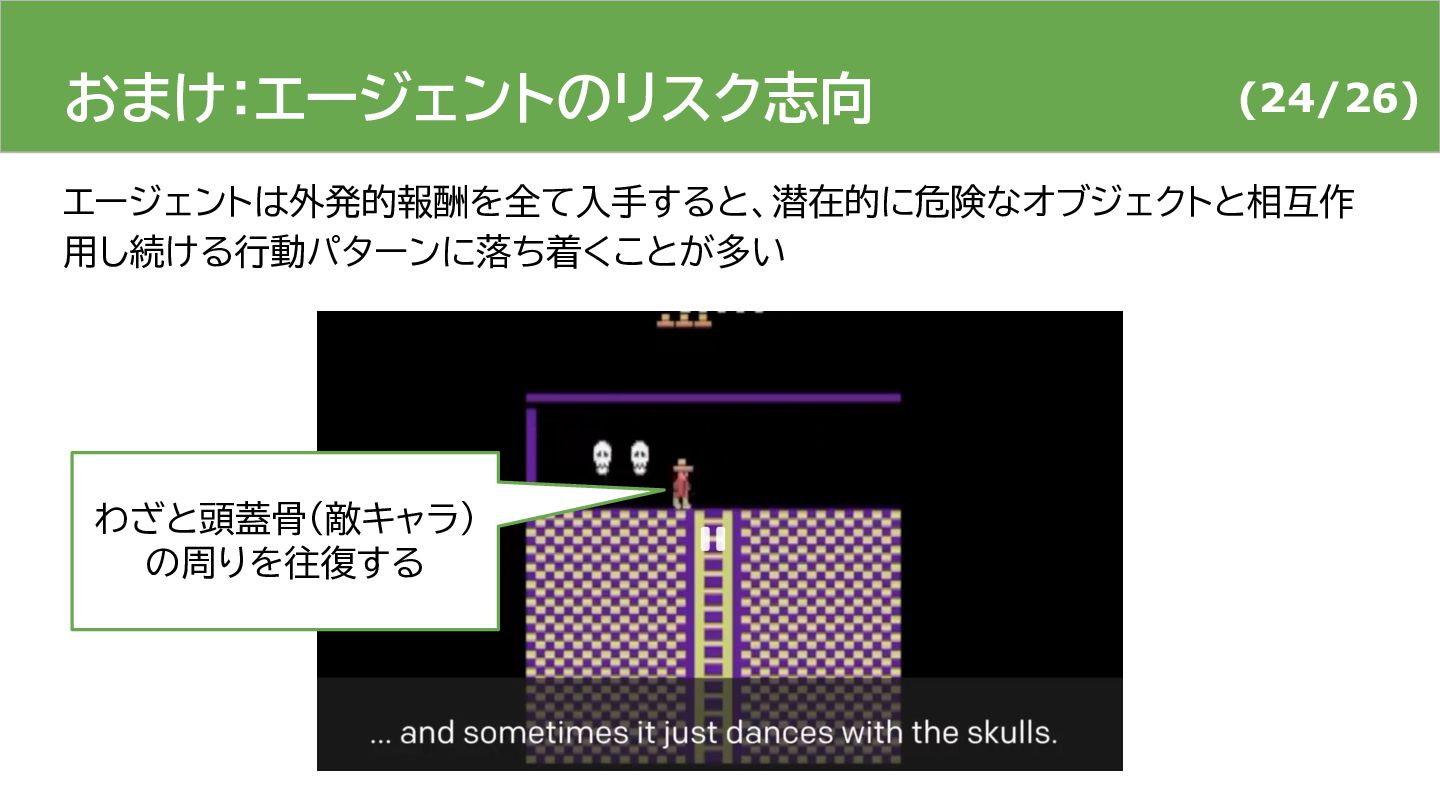{kind=link}
{kind=link}
{kind=link}