Presentation video: https://www.youtube.com/watch?v=aDysORX1zIs
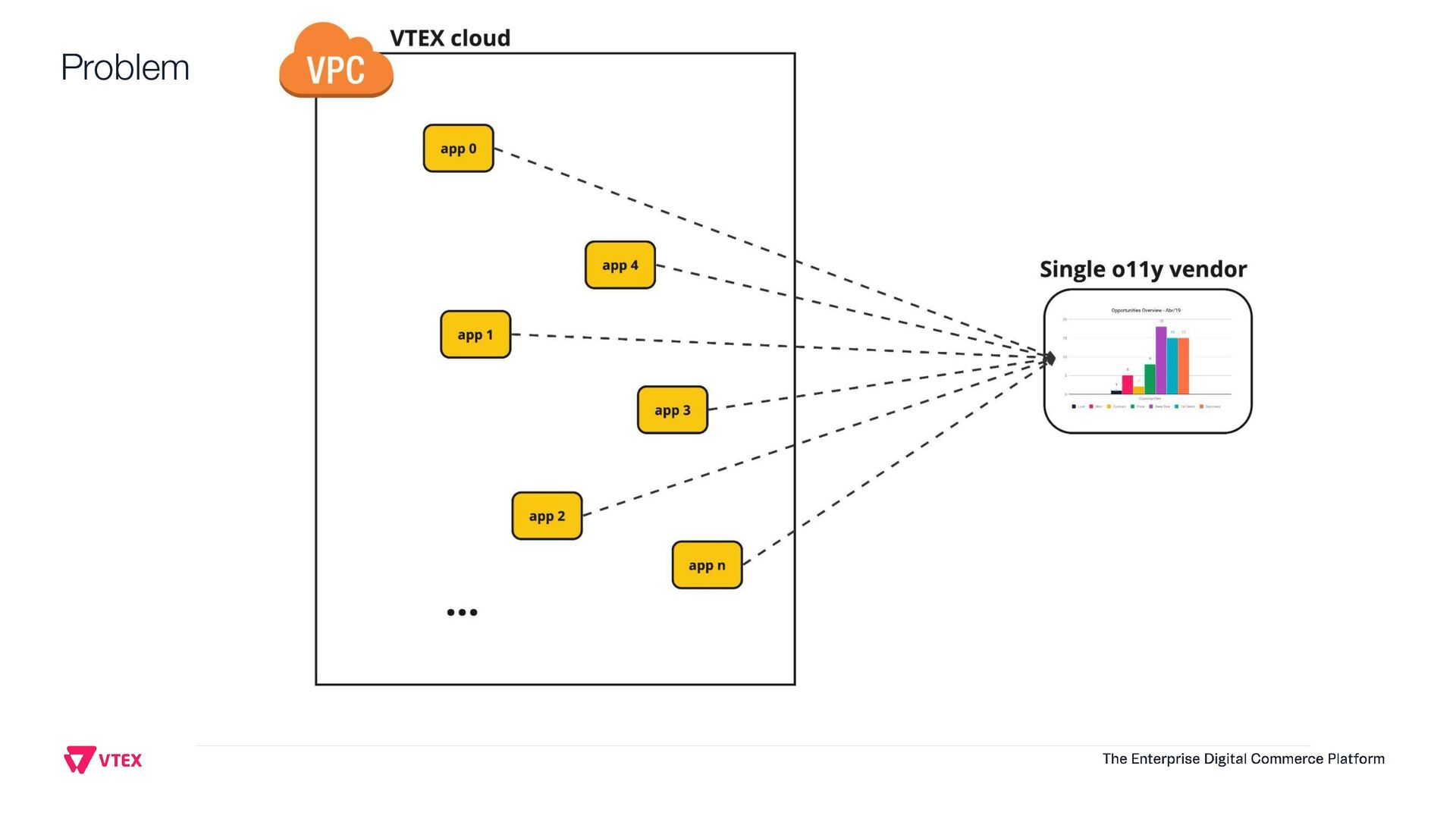
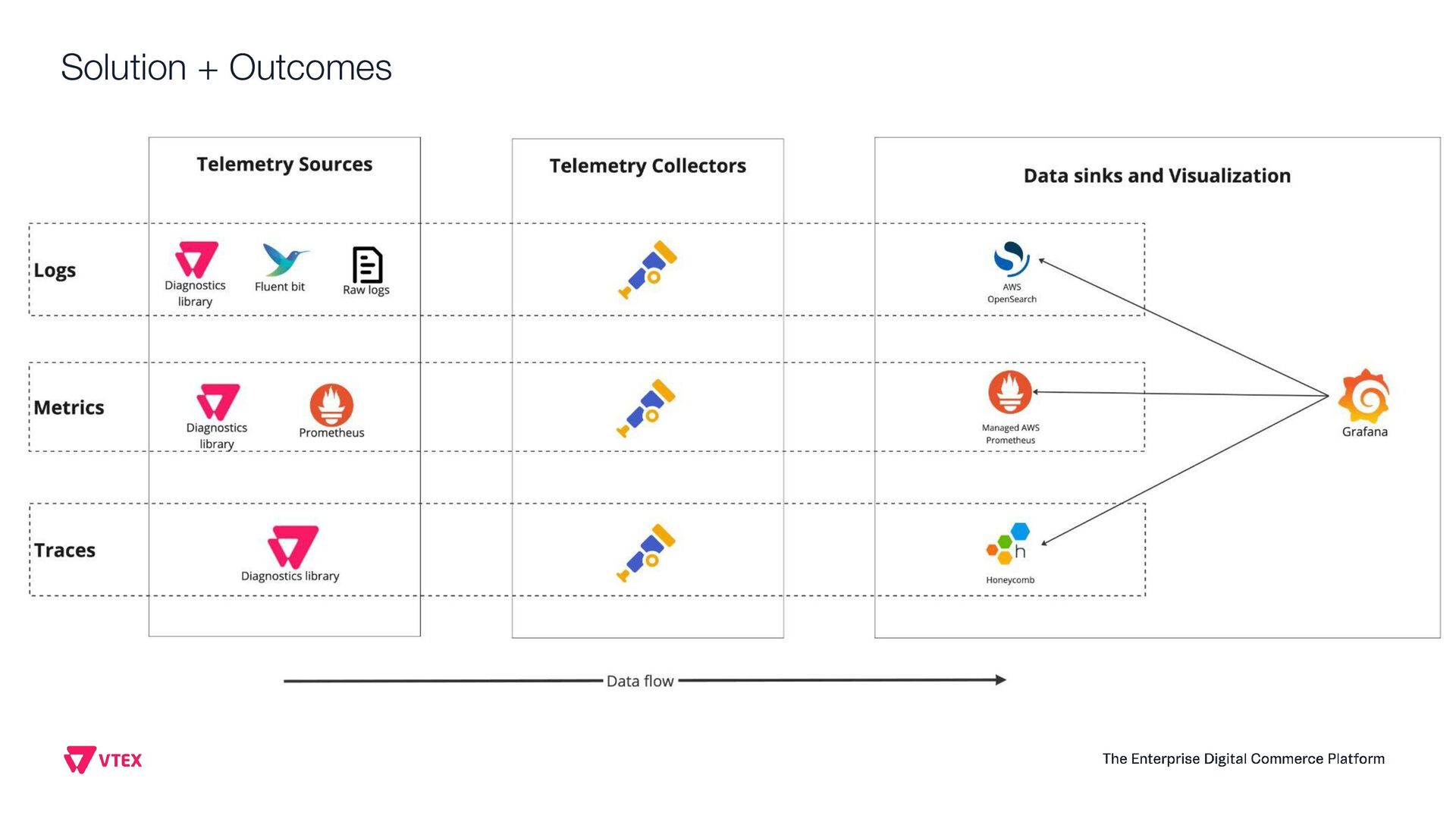
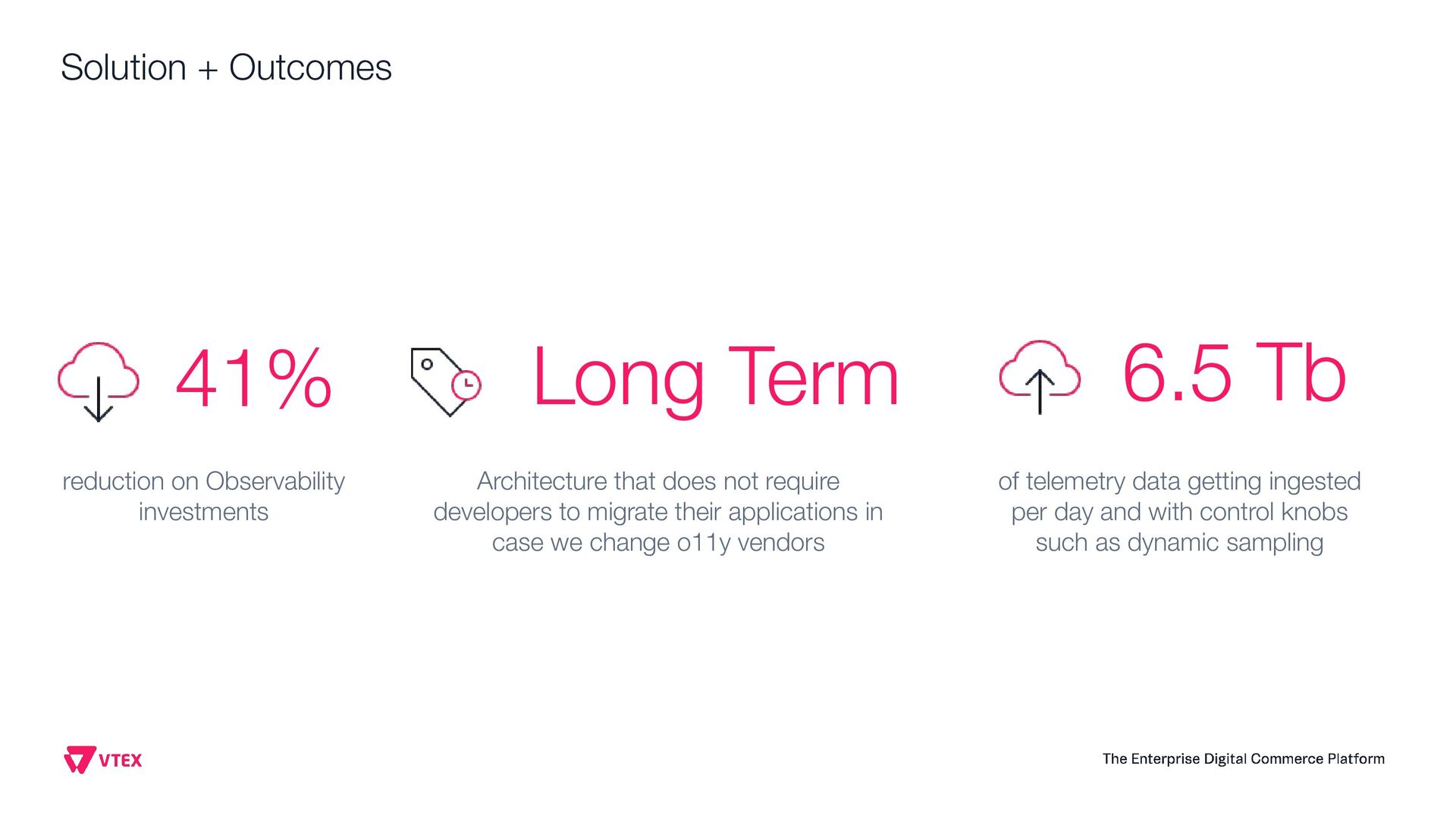
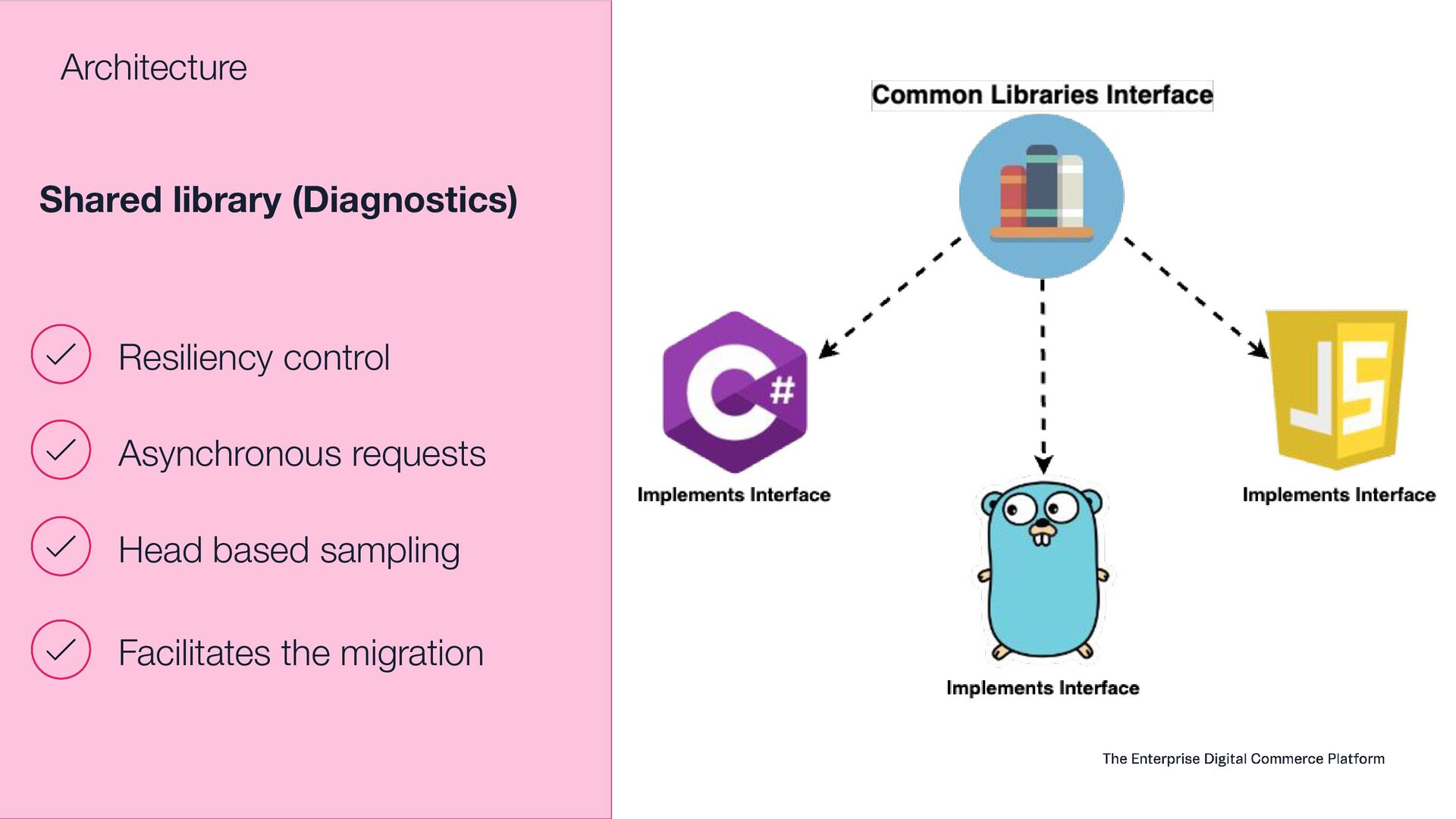
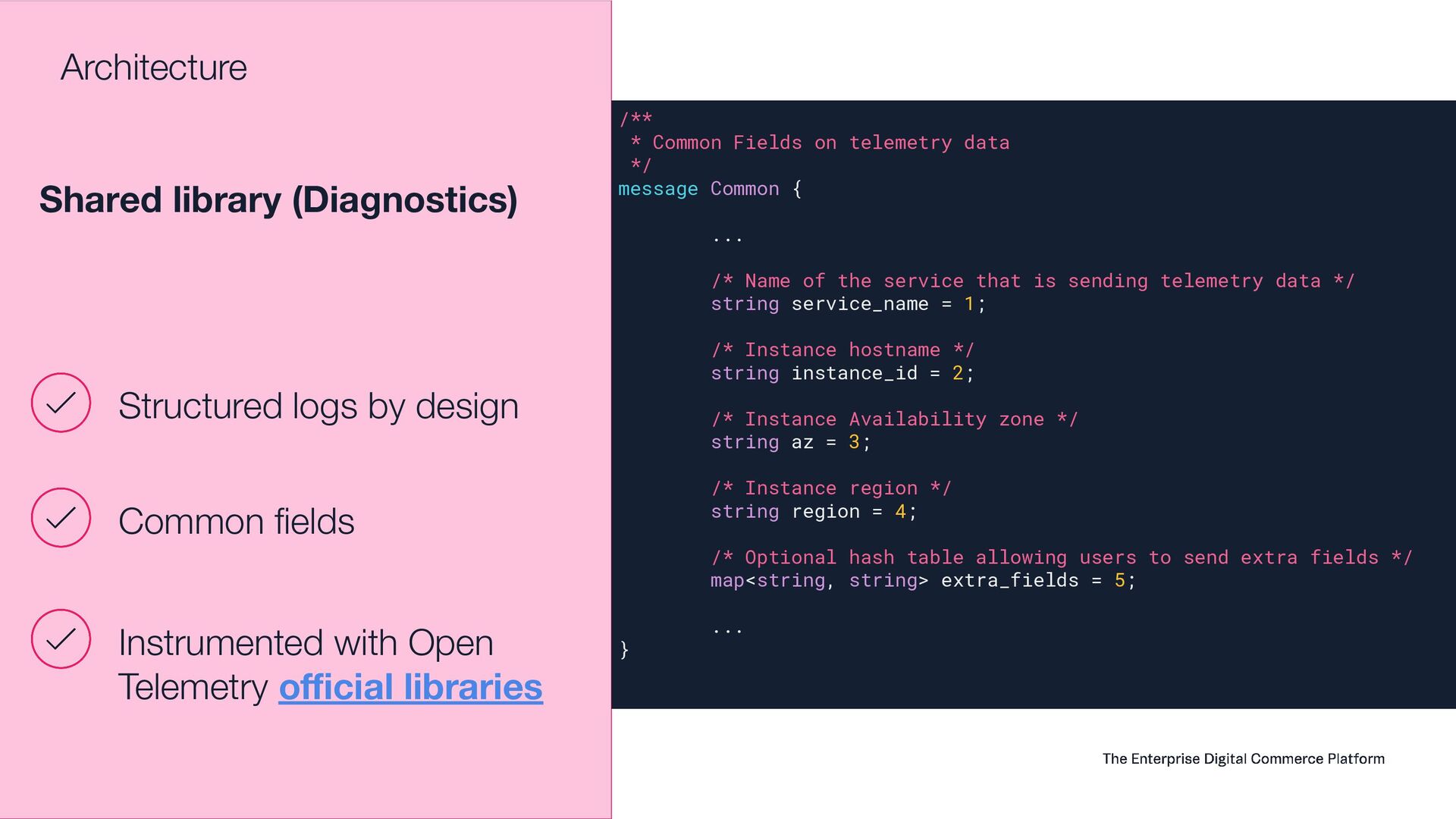
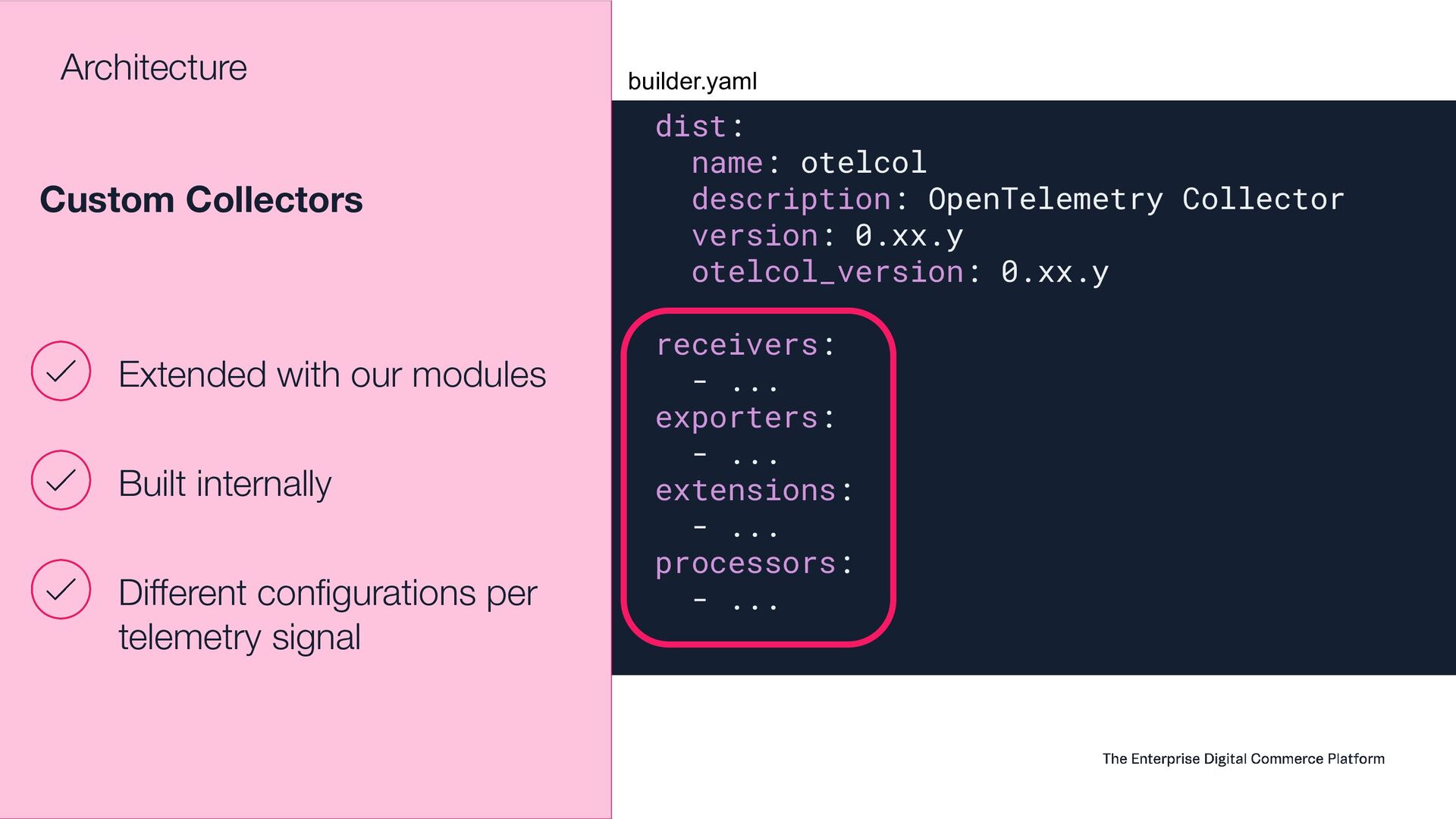
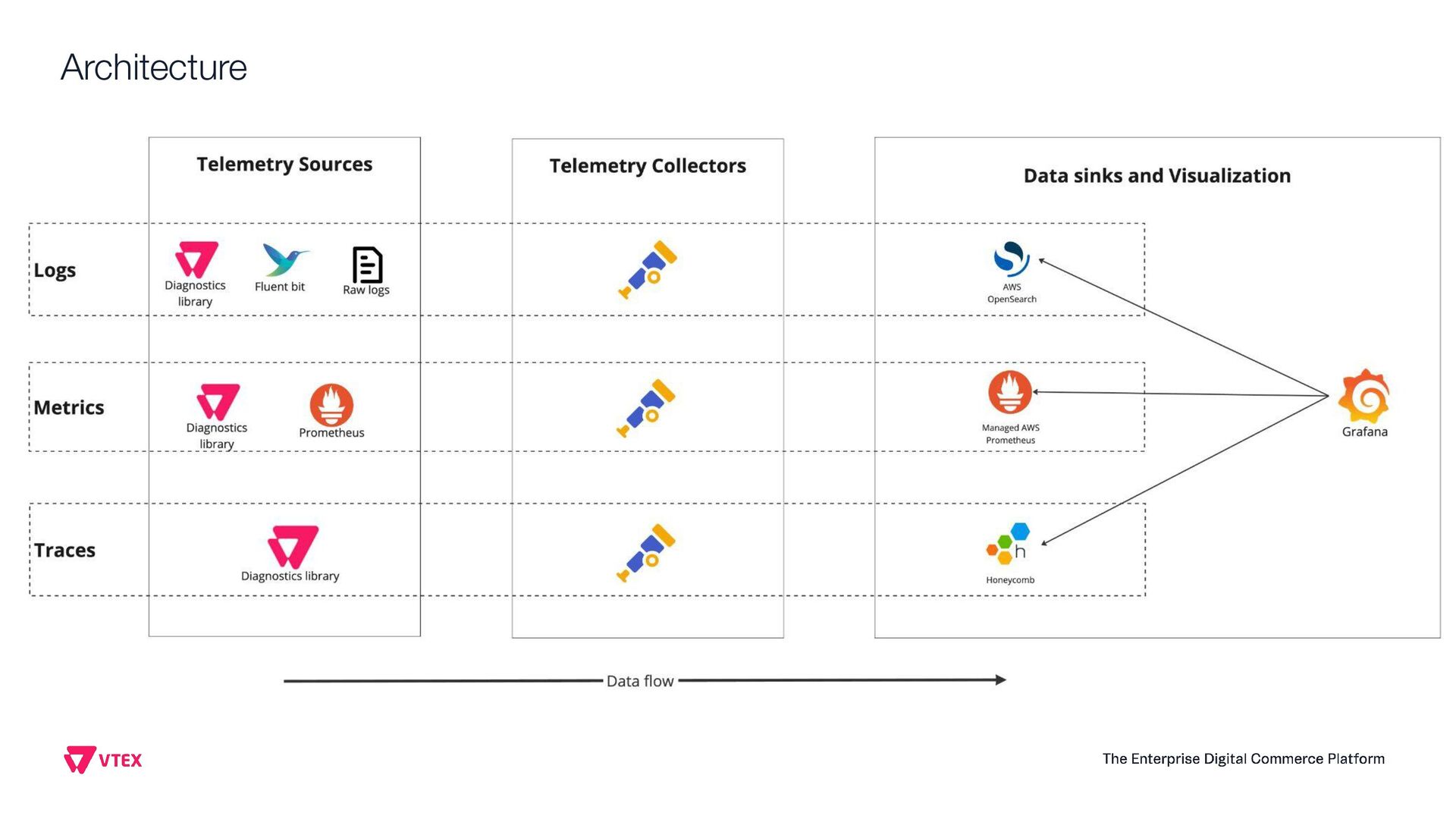
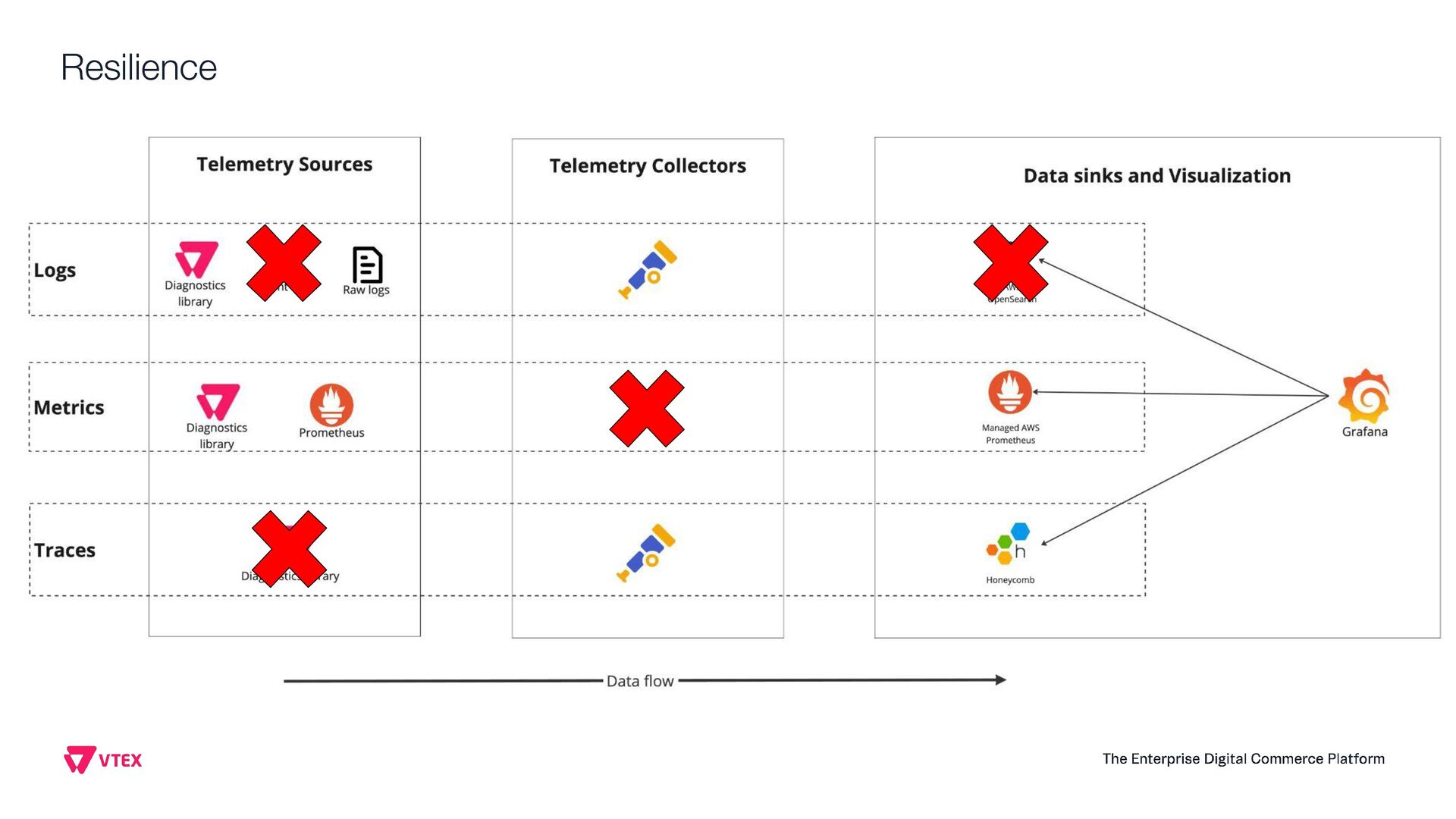
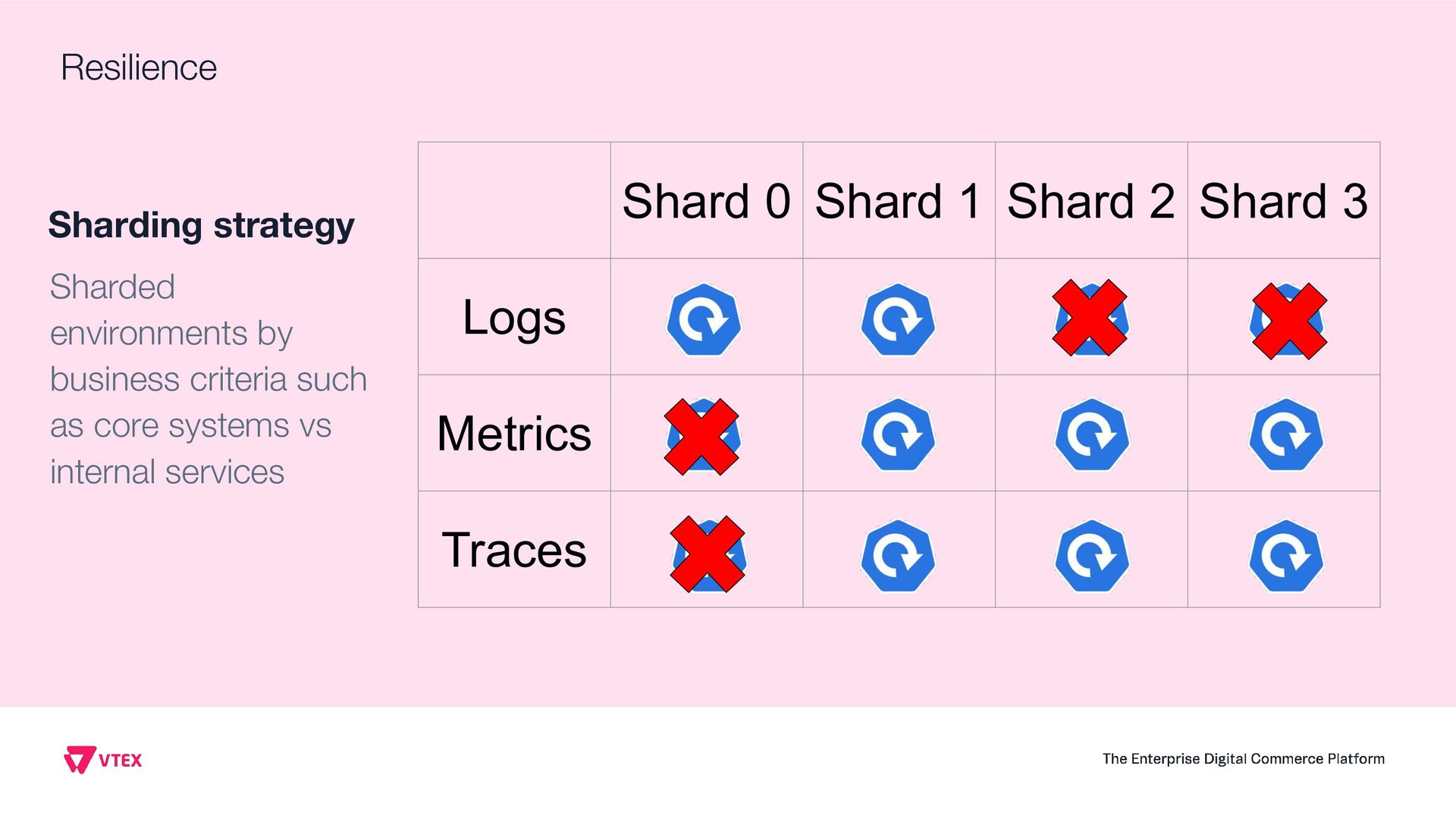
This presentation aims to share how VTEX observability team moved from a single vendor to a full Open Telemetry protocol solution that handles 6.5 terabytes of telemetry data per day (logs, system metrics, business metrics, traces and audit logs). Thinking on the CNCF community, this talk will show the entire architecture, the tradeoffs, how to instrument every application inside the company, how to manage OTEL Collectors at scale, how to centralize visualization, how to extend collectors code and how to guarantee resiliency. Open Telemetry allowed VTEX to completely modernize its Observability stack looking to a horizon of at least 5 years ahead without requiring any sort of migrations on the VTEX's applications. With the architecture this talk presents, VTEX can switch backend vendors without impacting instrumented code. Thus, allow engineering organization to move faster. Last but not least, this solution made VTEX reduce 40% of its Observability costs while enabling a modern, safer and efficient way to engineers to observe their applications at scale. If these topics are interesting to you, please come to this presentation. The idea is to give back to CNCF community what they gave to us: knowledge and cutting edge solutions.
kubecon europe 2023
Tuesday April 18, 2023 11:55 - 12:20 CEST
Hall 7, Room E | Ground Floor | Europe Complex
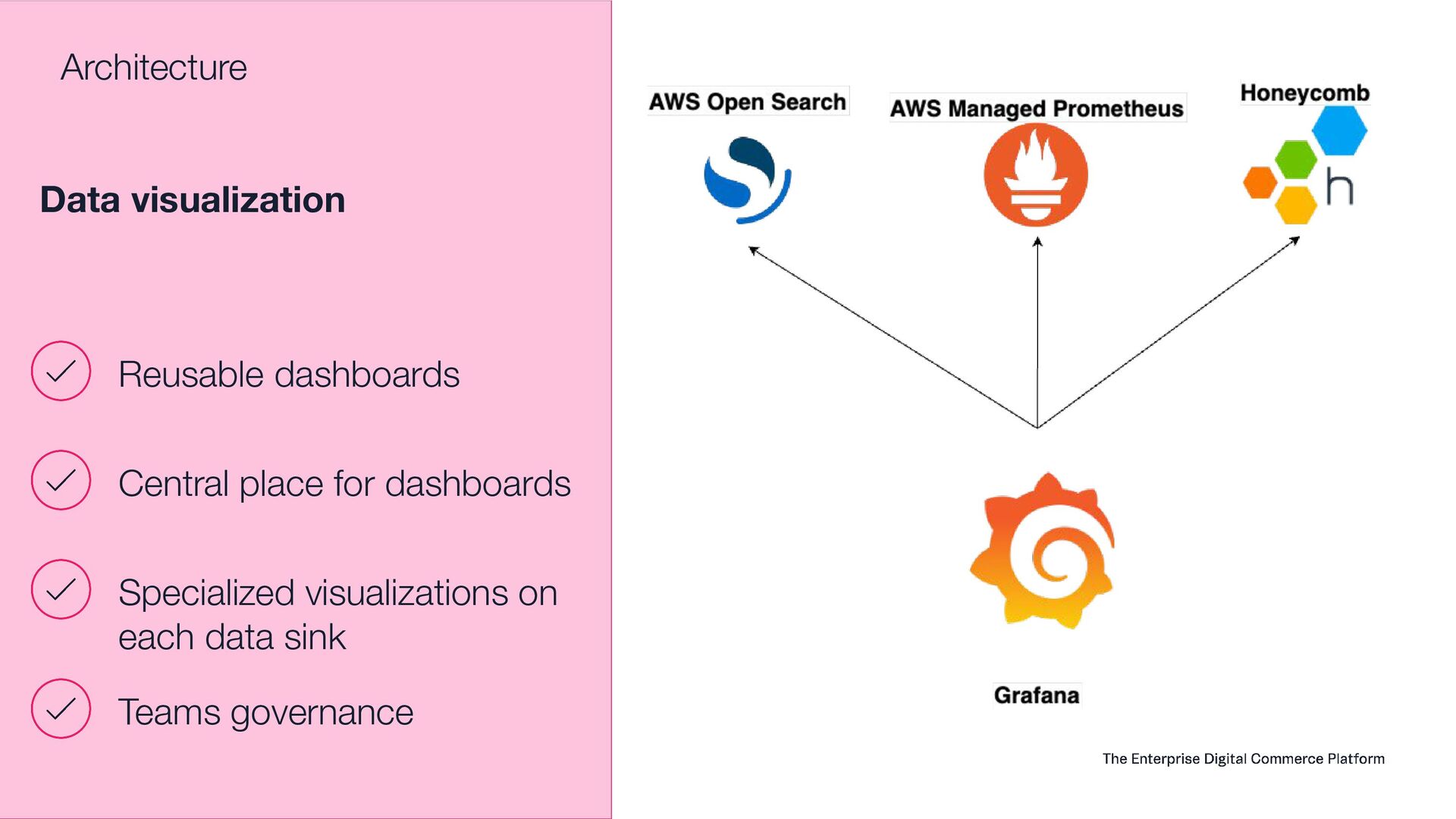
Observability Day, Project-specific: Observability + Prometheus + OpenMetrics + OpenTelemetry +Fluentbit
{kind=link}
{kind=link}
![About me Personal blog on Computer Science [pt-BR] https://blog.pantuza.com @gpantuza](https://files.speakerdeck.com/presentations/3dda2b2da7f2471aa7ae1c1dbf2b80d4/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Personal blog on Computer Science [pt-BR] https://blog.pantuza.com @gpantuza pantuza](https://files.speakerdeck.com/presentations/3dda2b2da7f2471aa7ae1c1dbf2b80d4/slide_38.jpg){kind=link}