This presentation was made at General Assembly in San Francisco, on January 25, 2017.
It presents newest 'Machine Learning" models in Python.
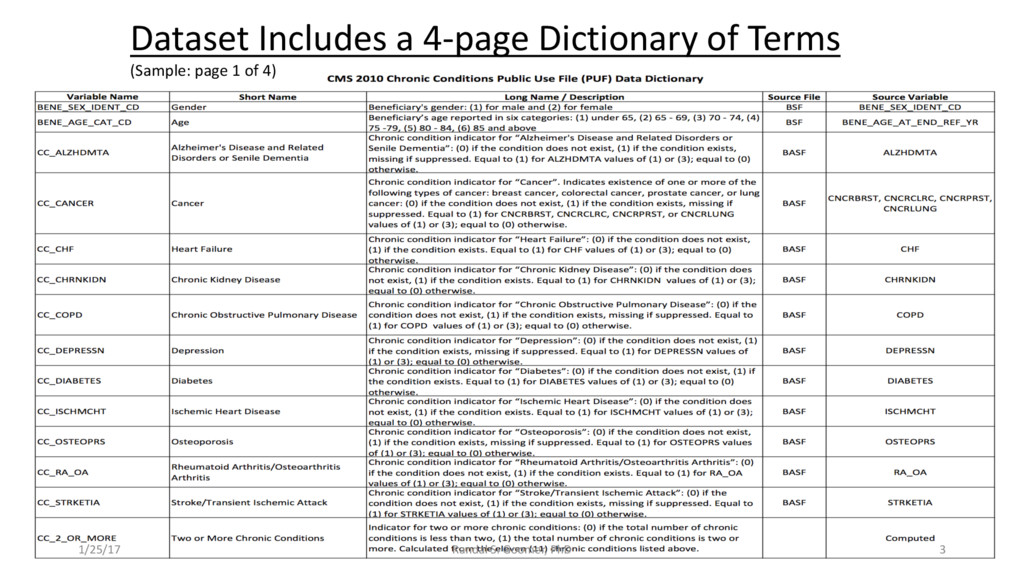
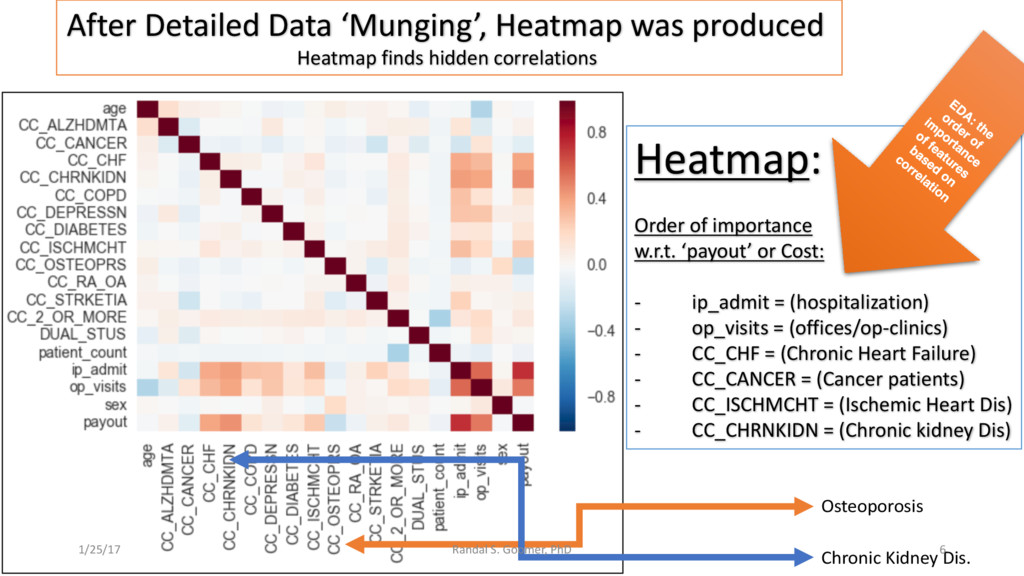
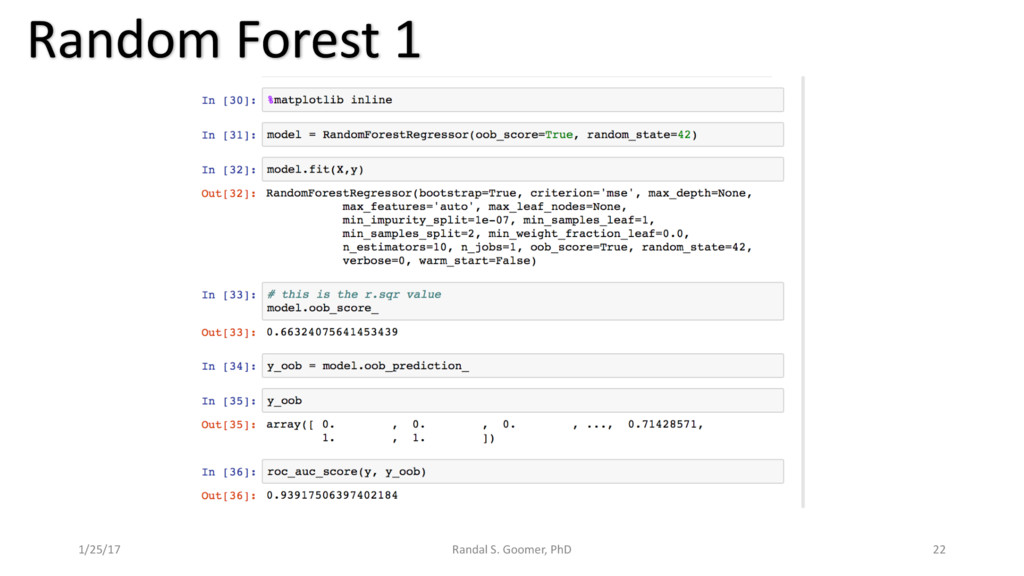
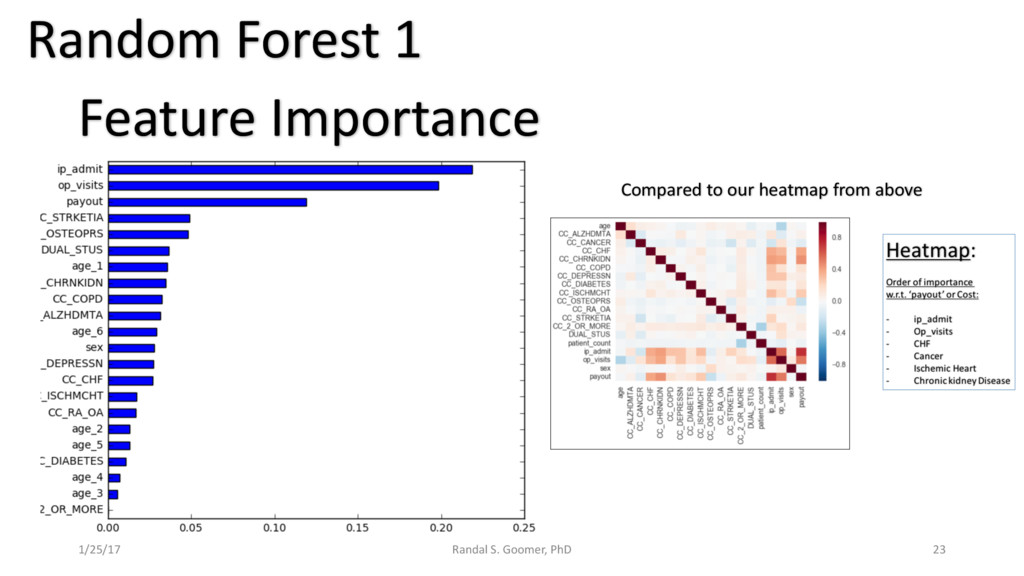
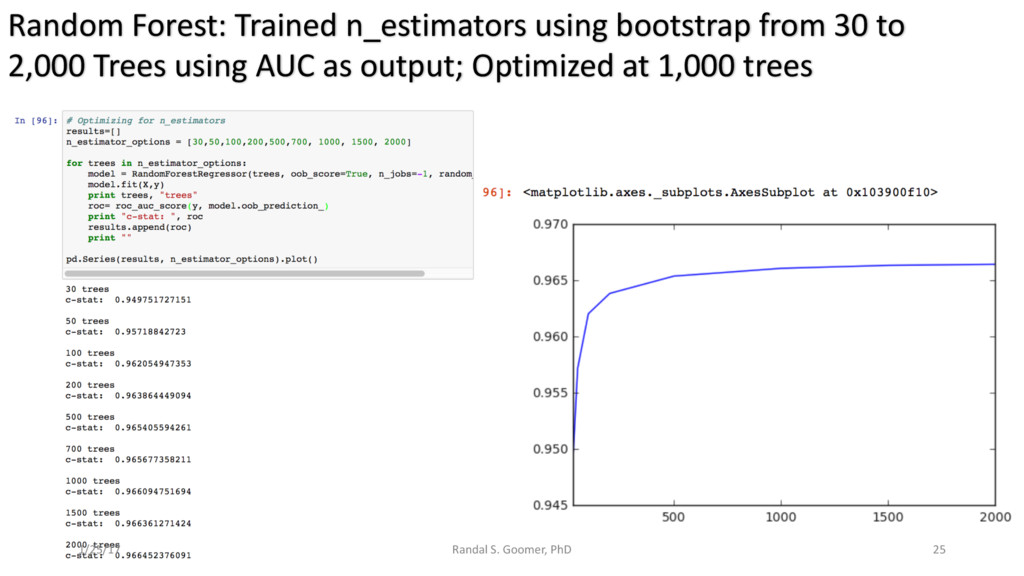
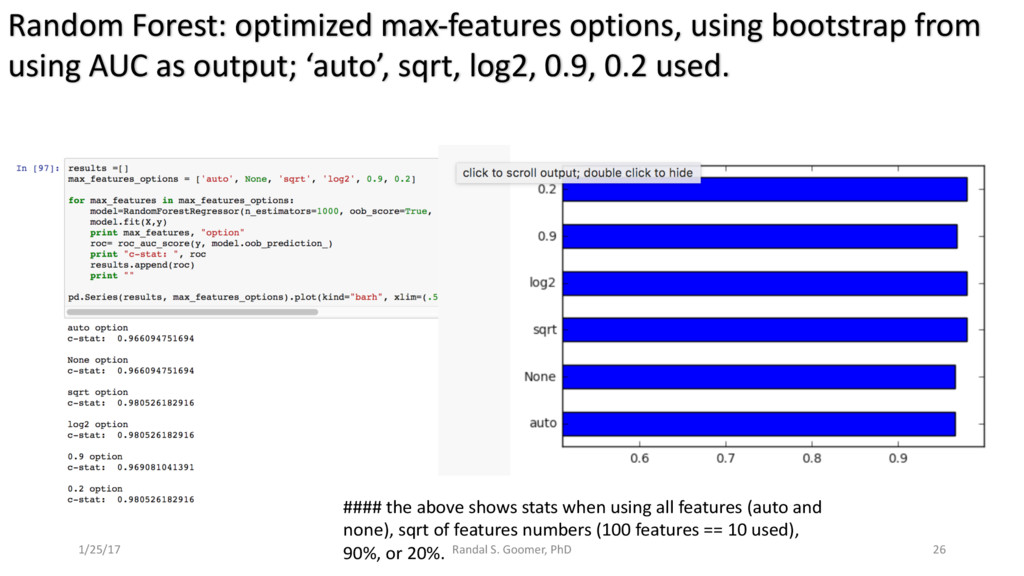
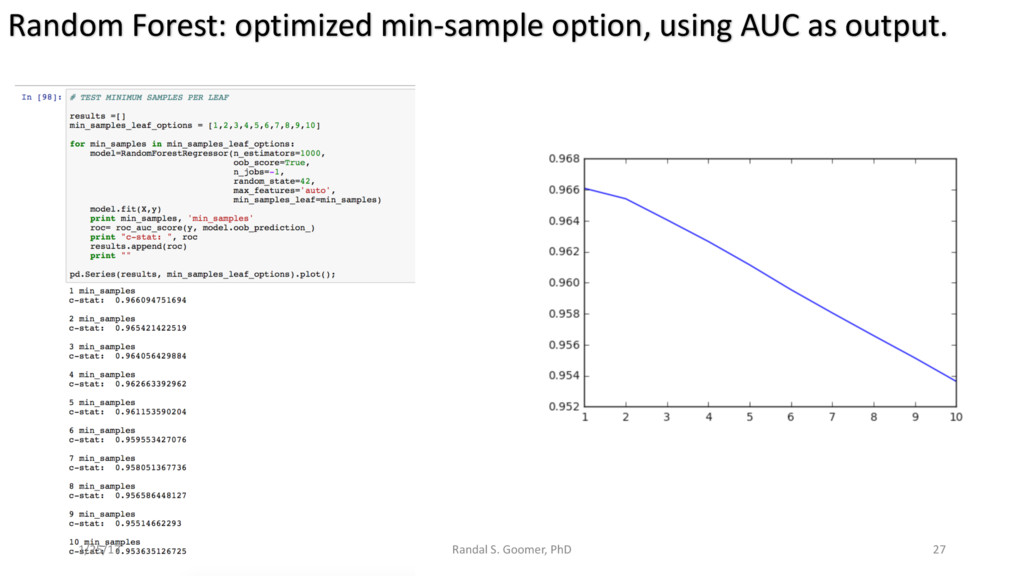
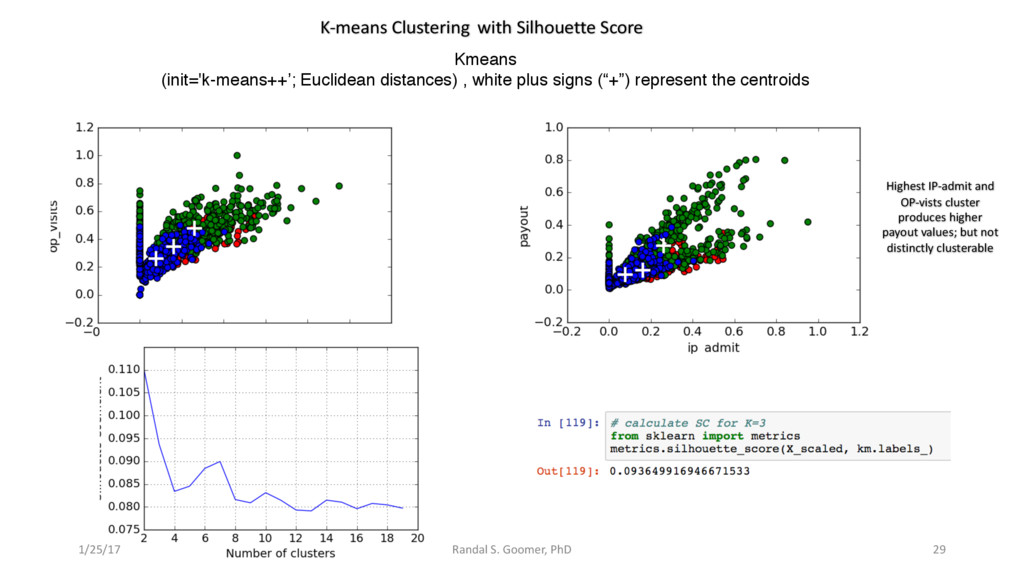
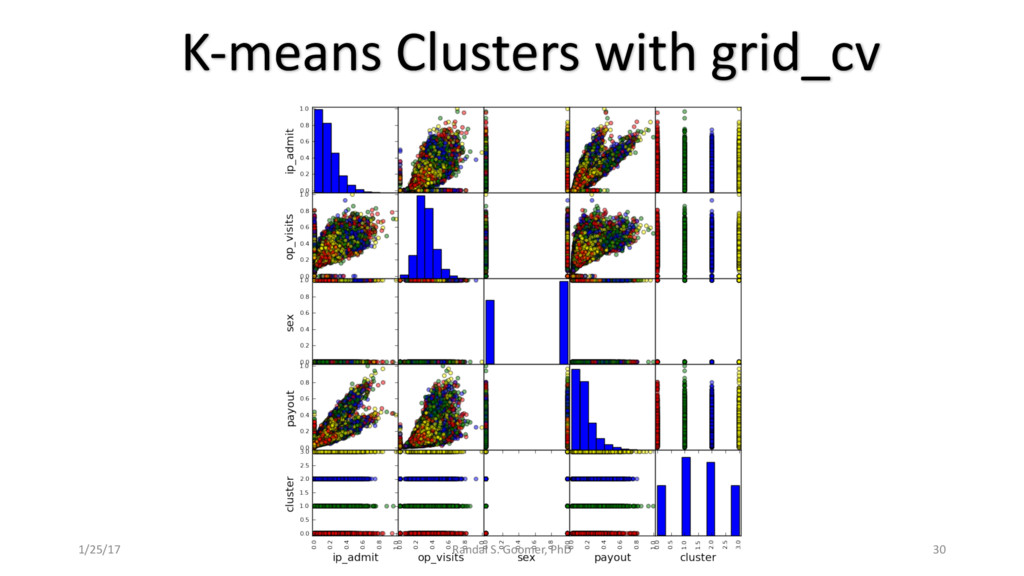
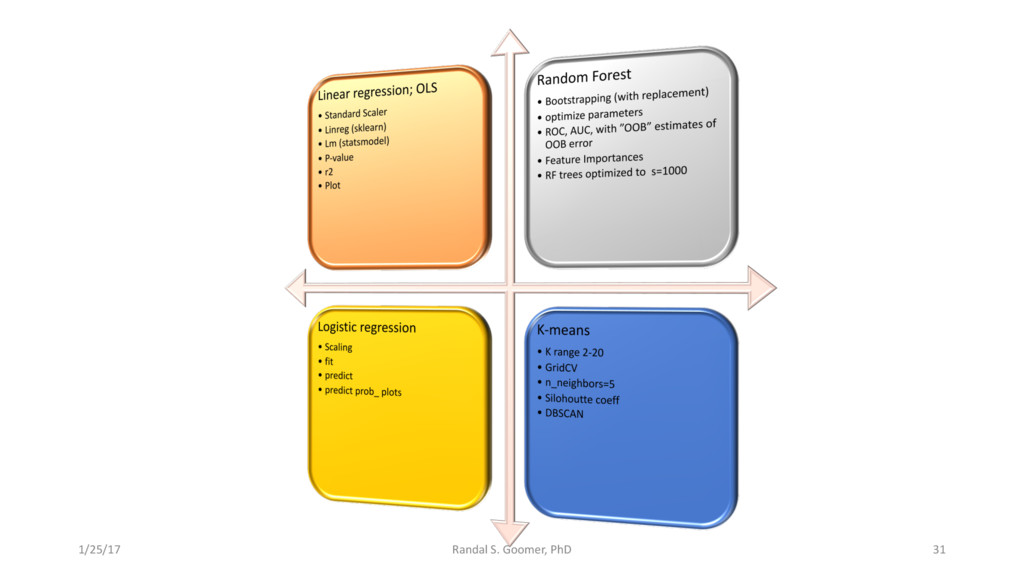
Models used include: 'Random Forest' classification and prediction : bootstrapping optimized with ROC/AUC .Decision Tree algorithm for Health-Tech BI. Advanced Feature selection, Feature scaling and Logistic regression predictions.
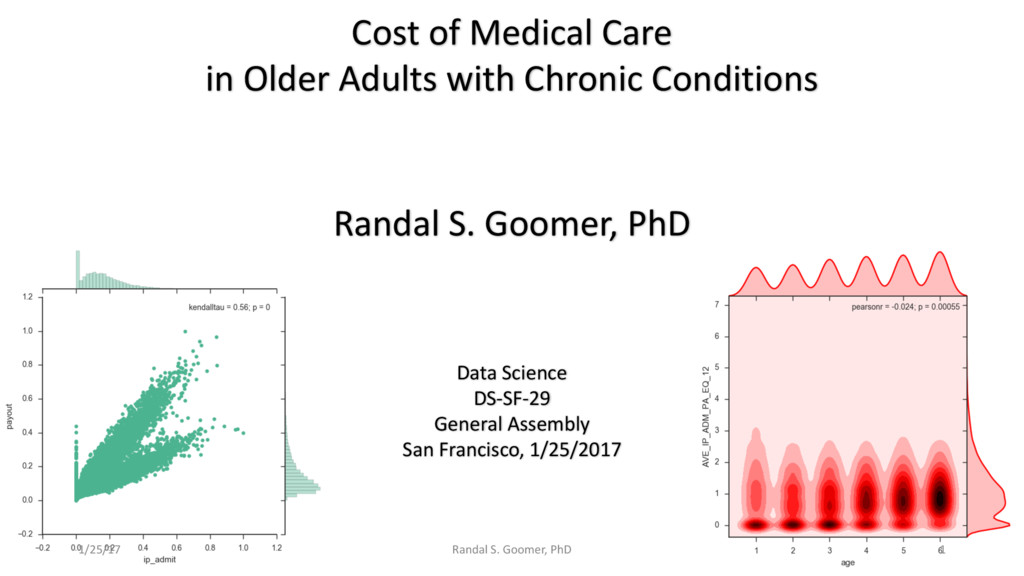
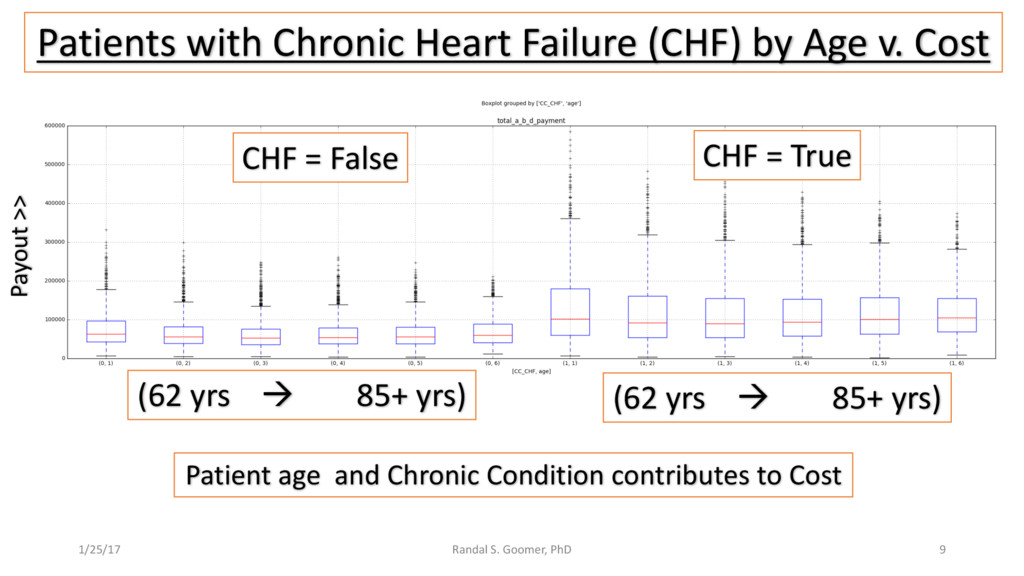
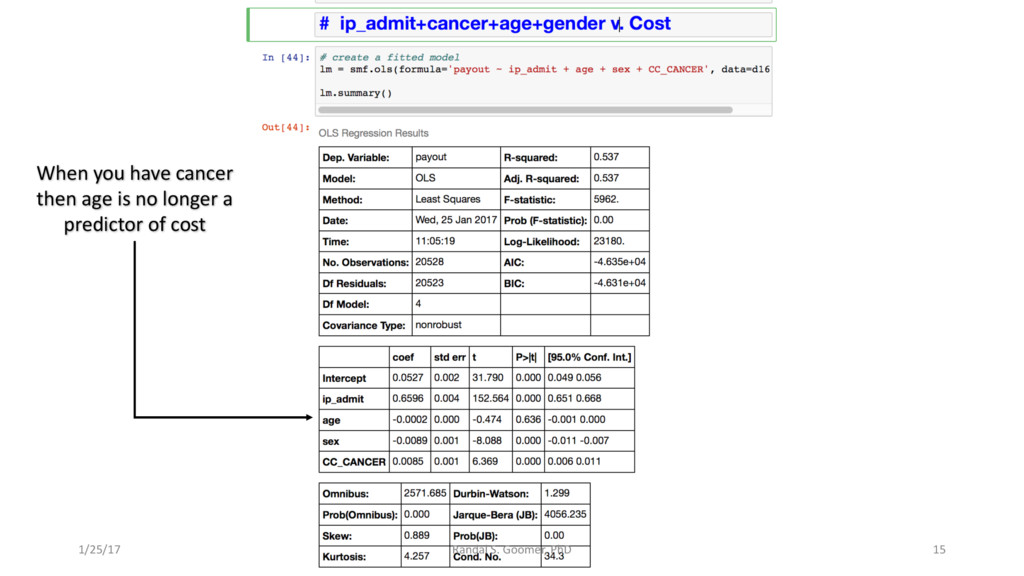
Examples include Chronic Heart Disease v. osteoporosis.
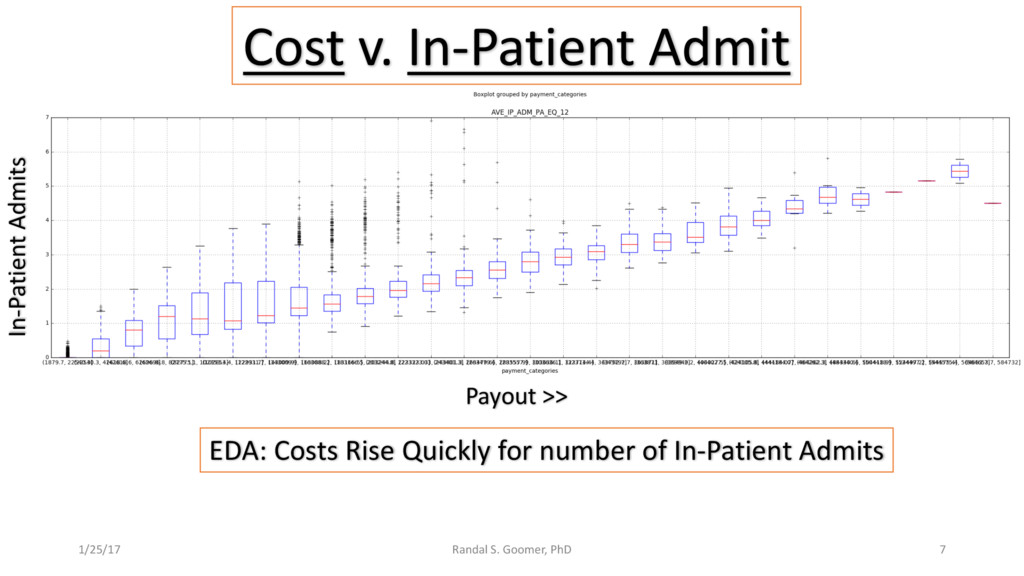
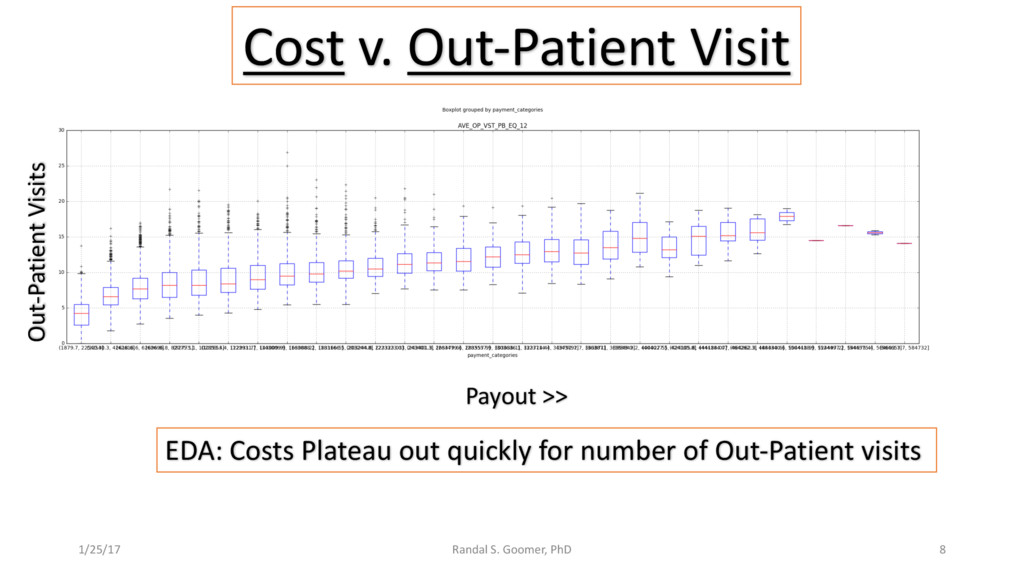
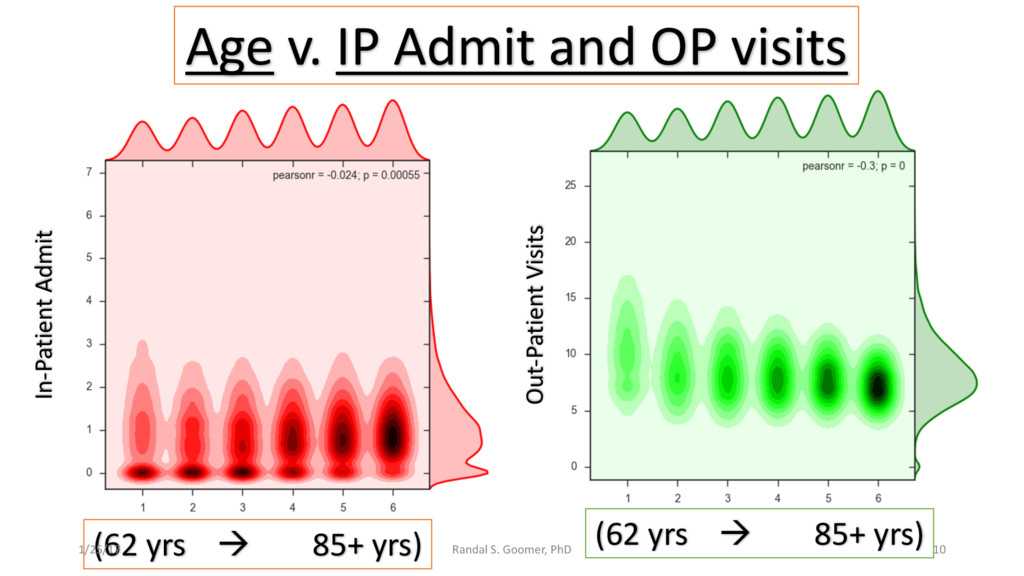
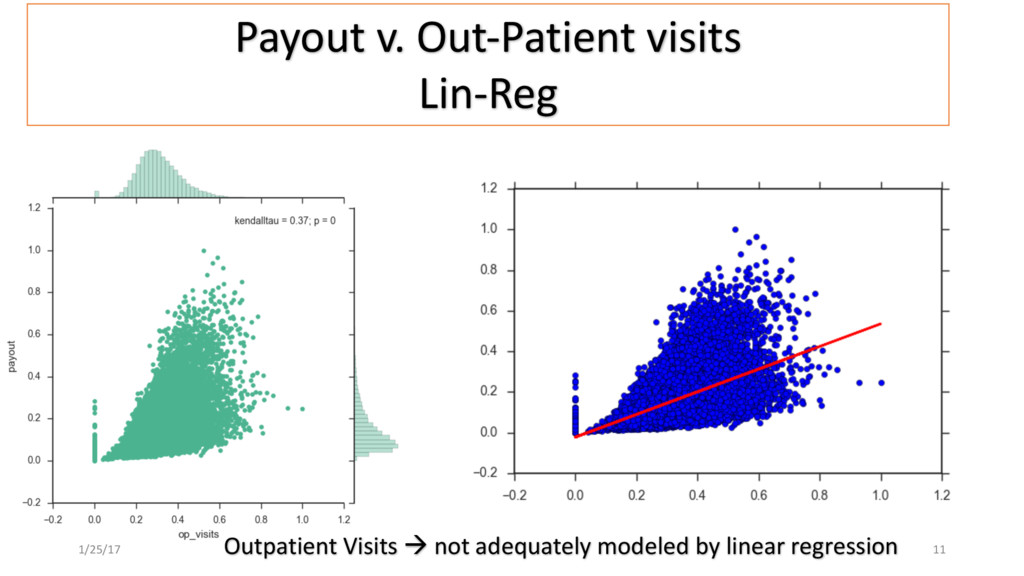
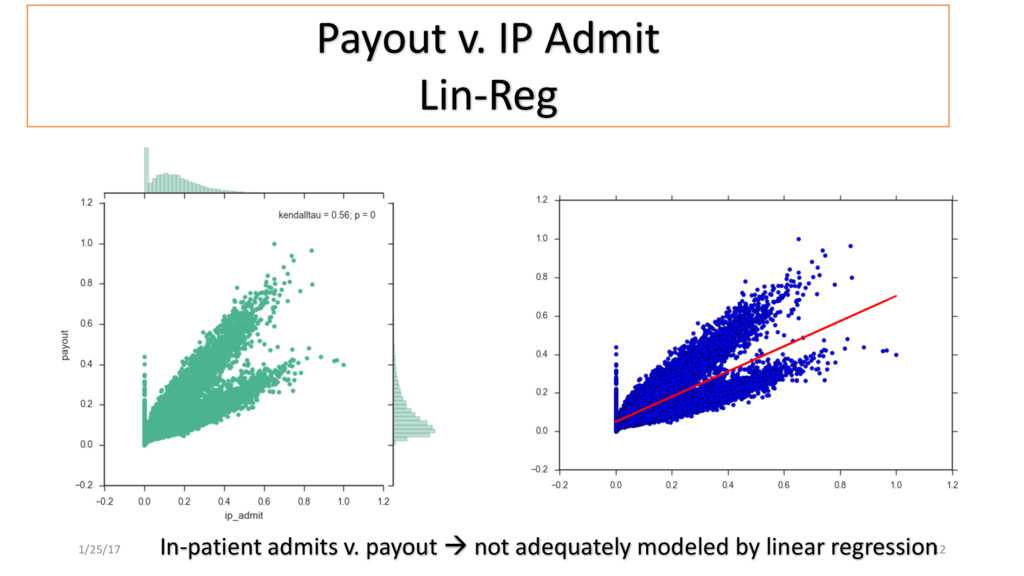
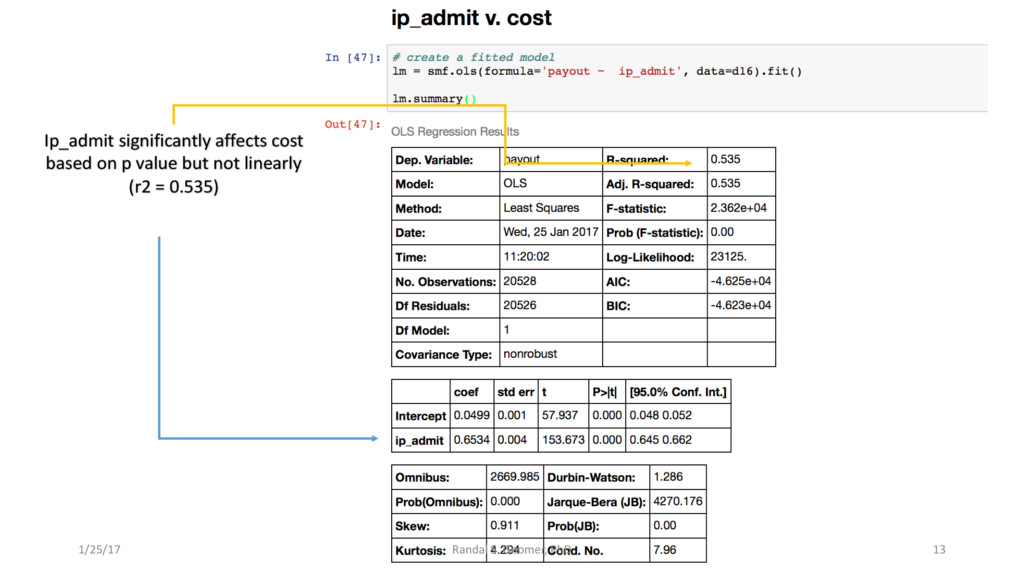
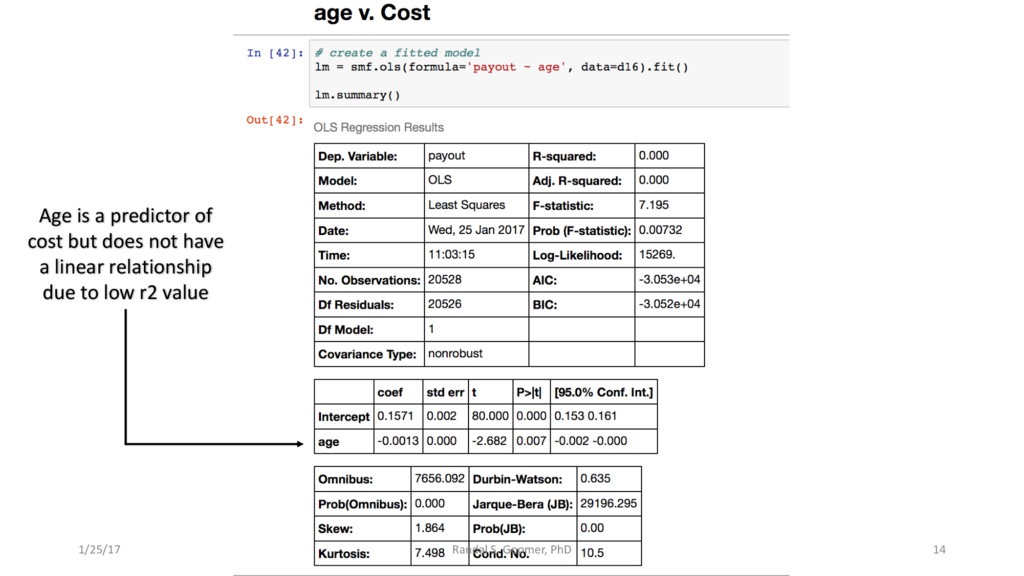
Patient use of in-Patient admits vs. out-patient services as cost minimizer, etc..
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
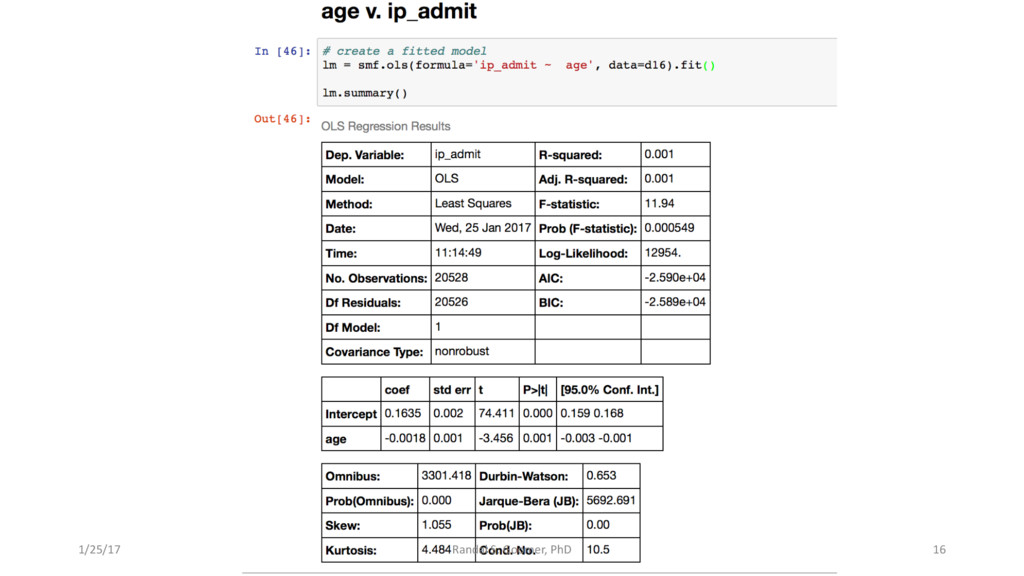{kind=link}
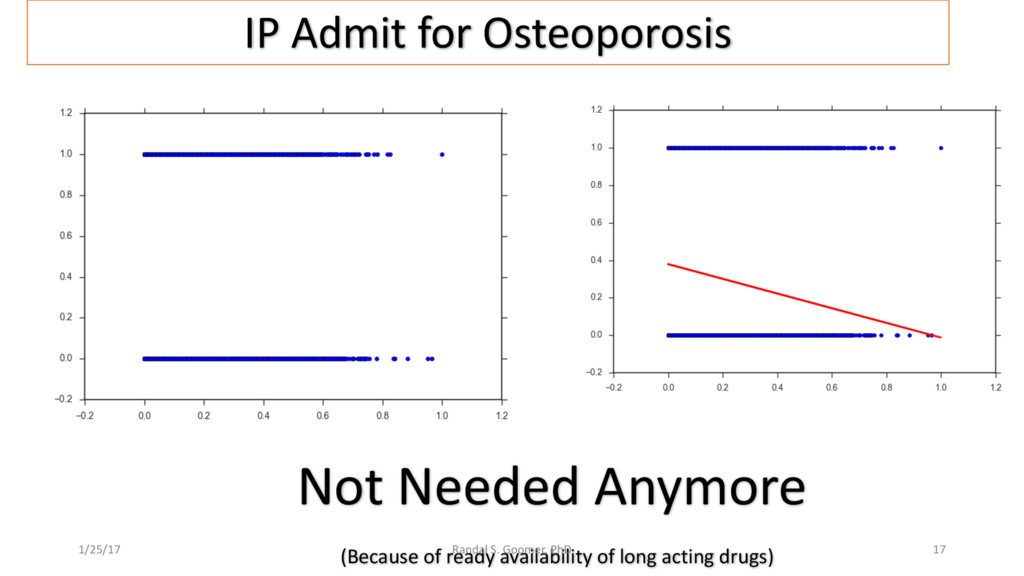{kind=link}
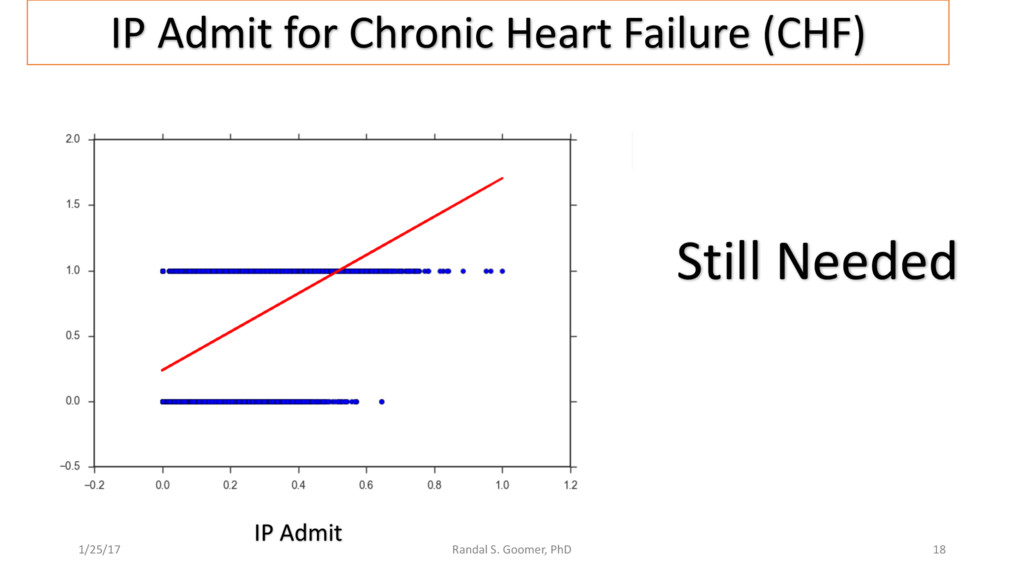{kind=link}
{kind=link}
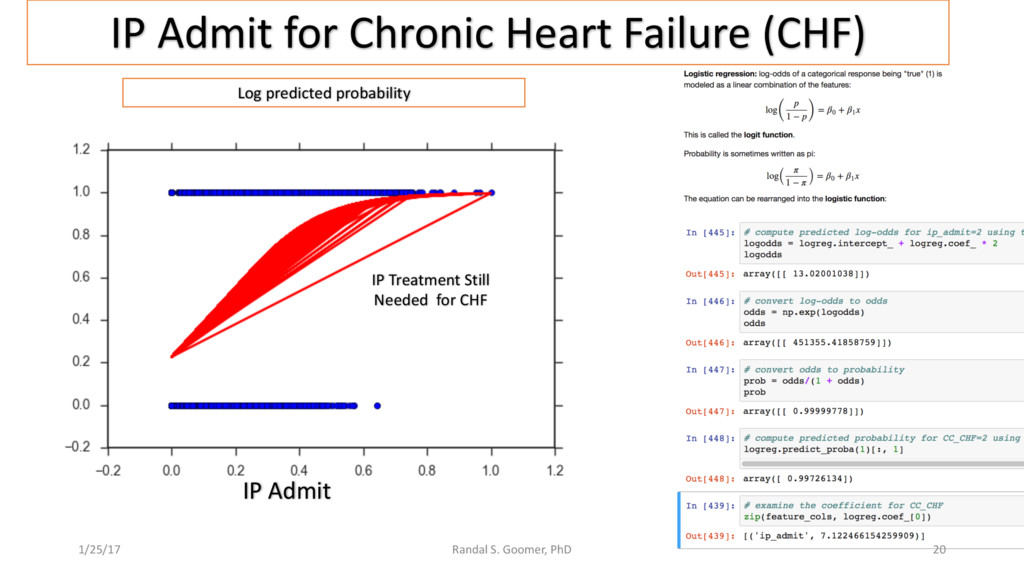{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}