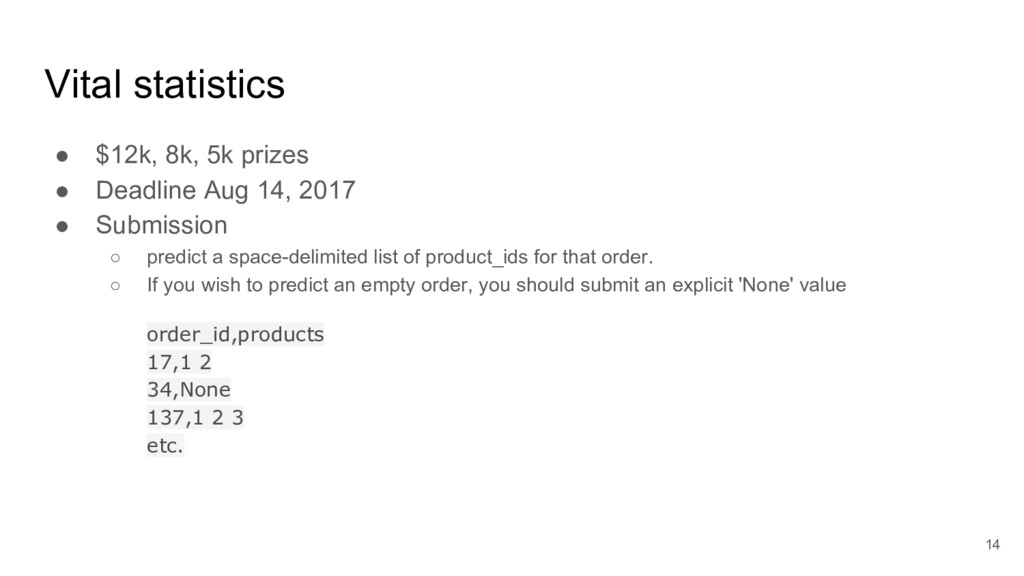
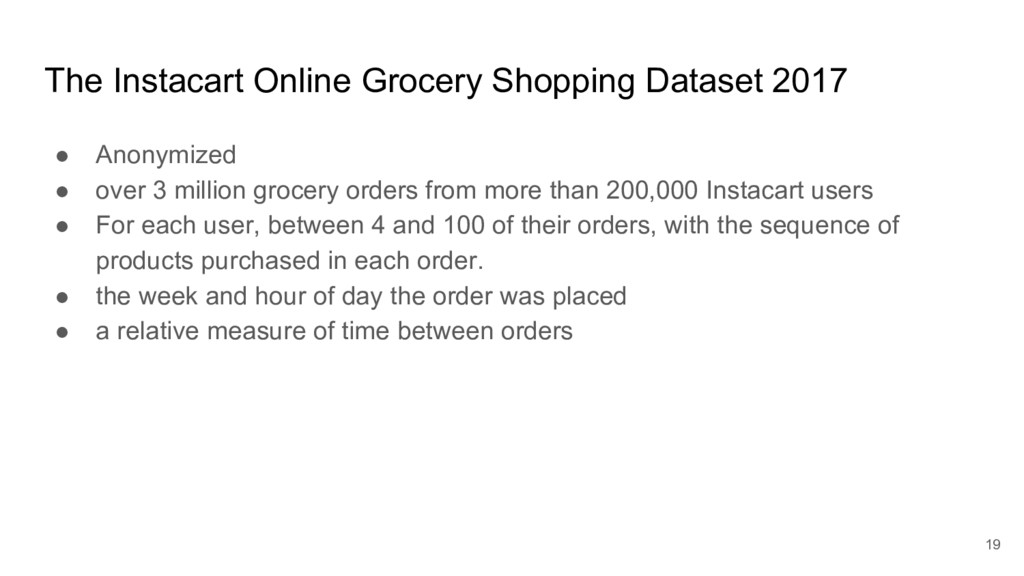
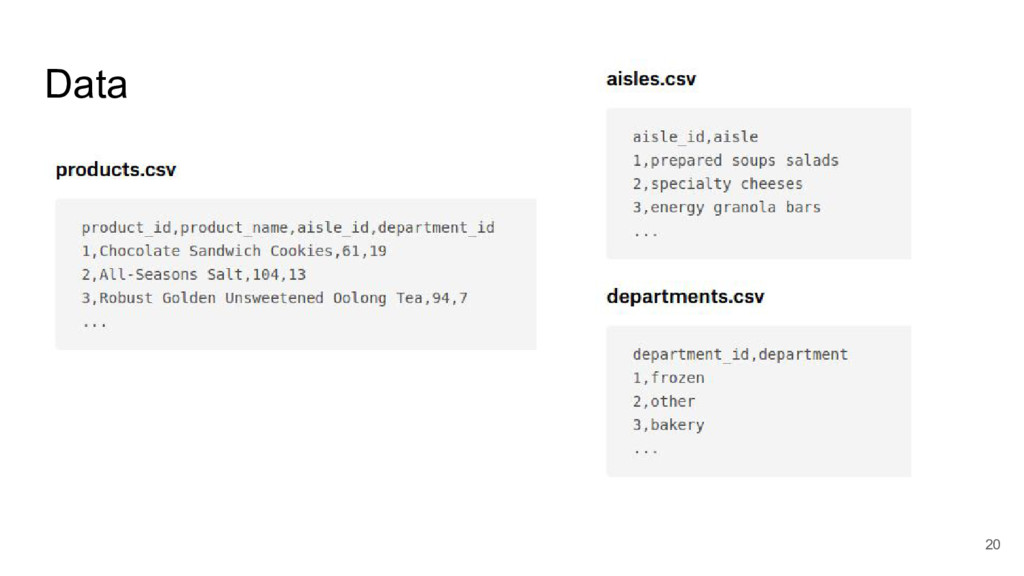
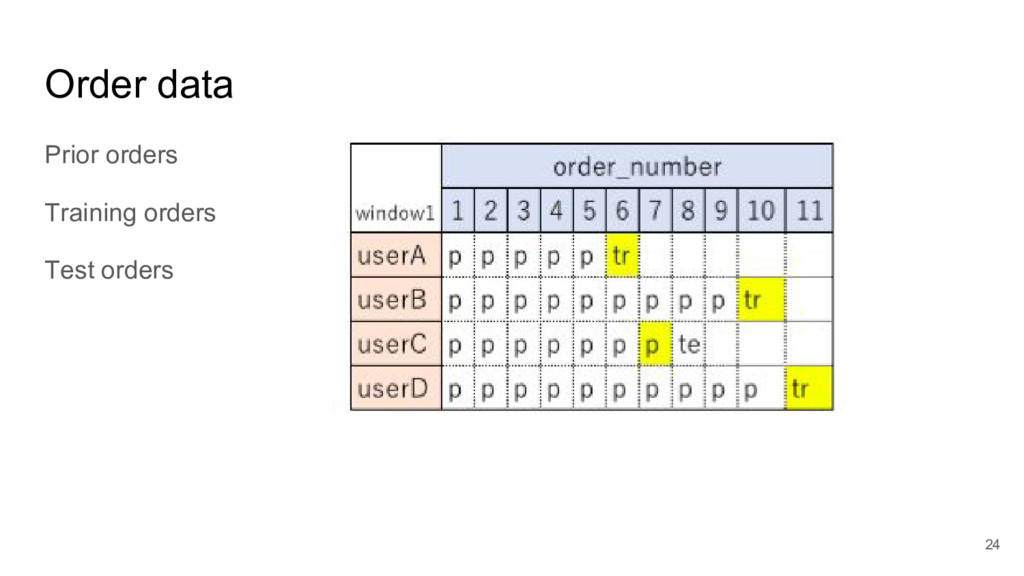
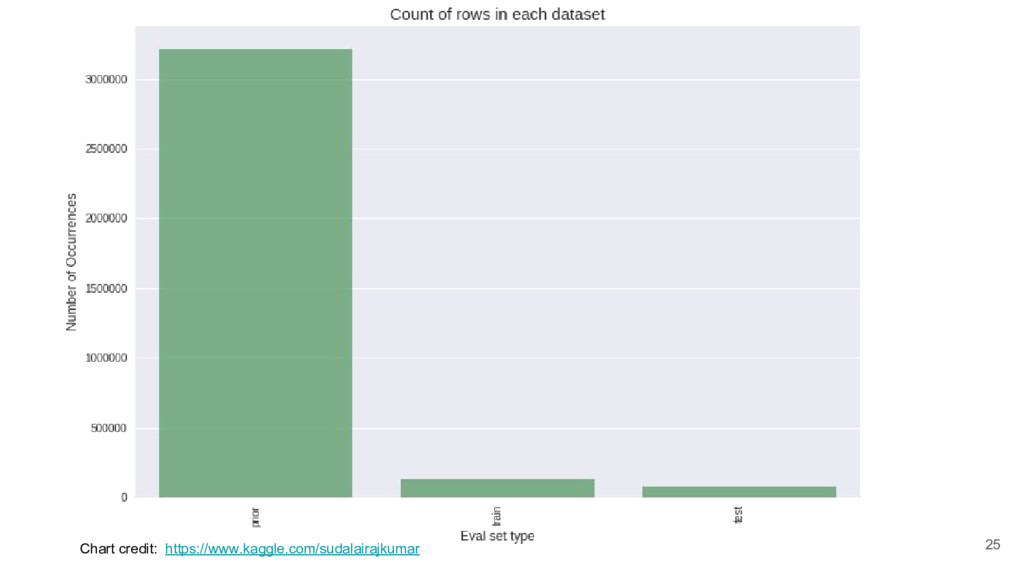
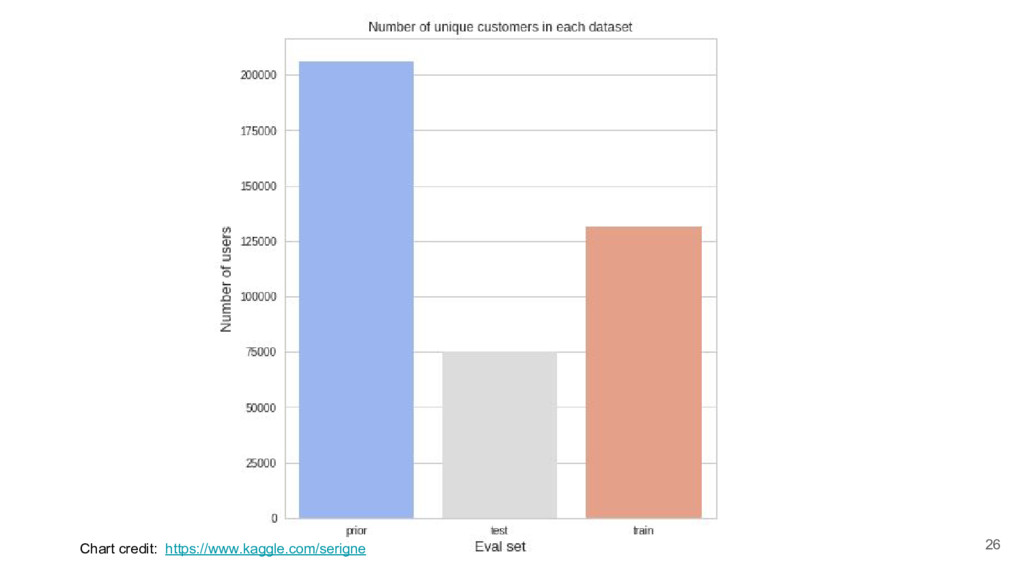
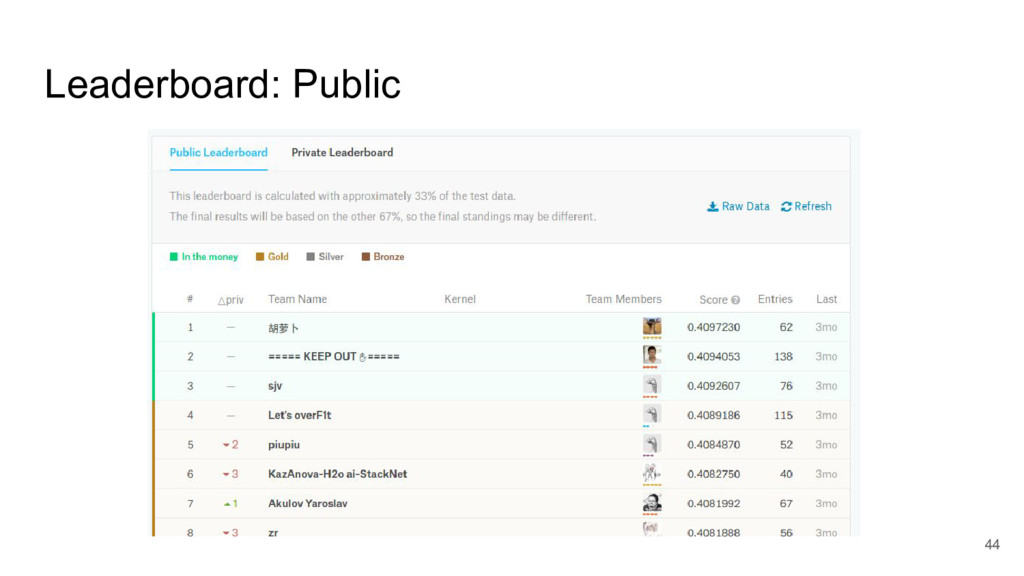
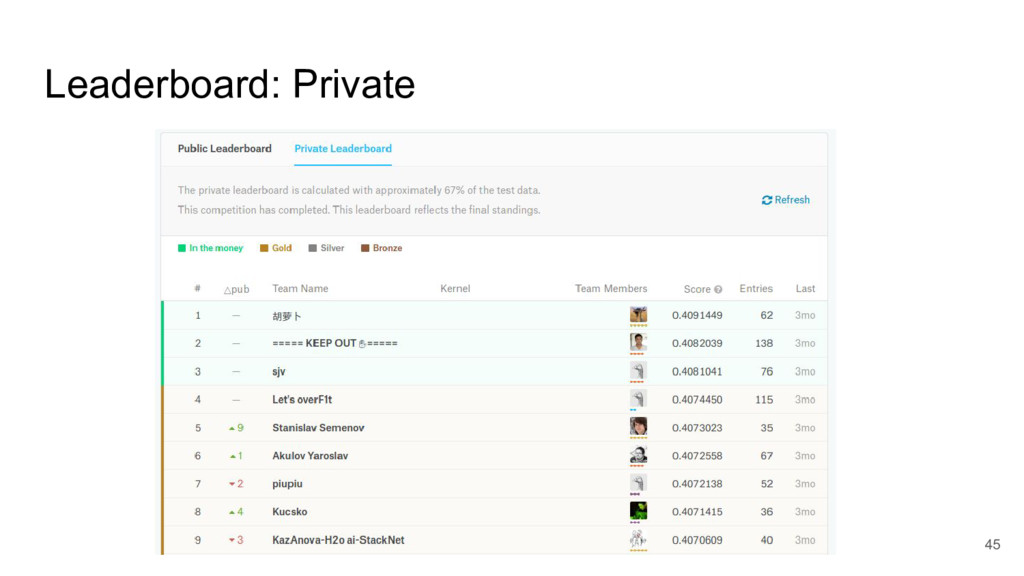
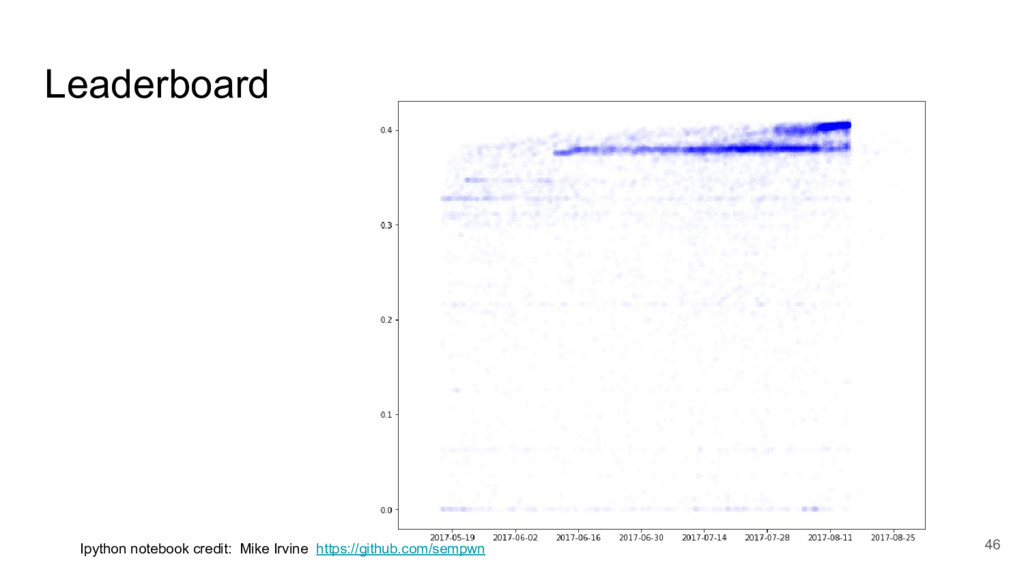
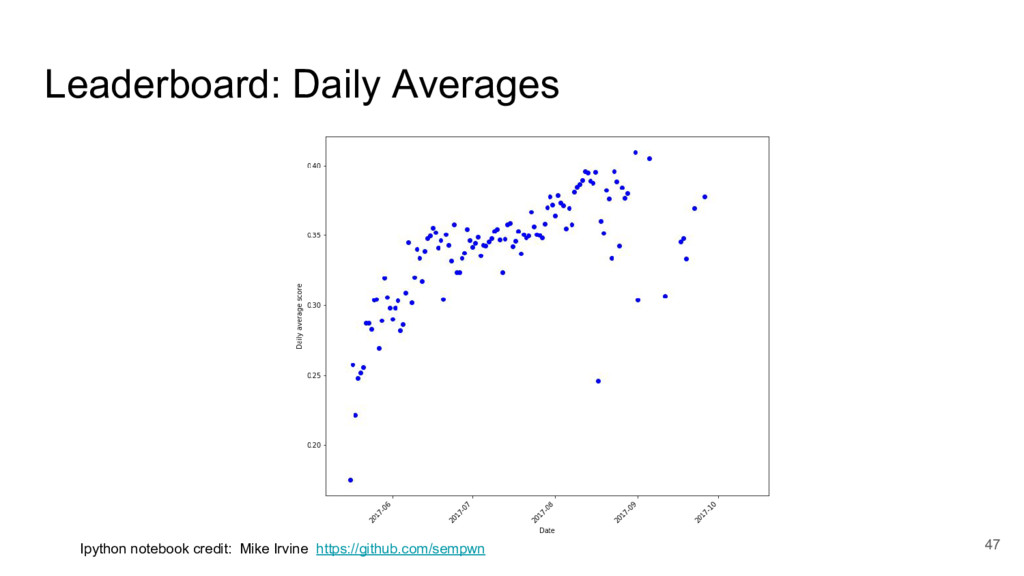
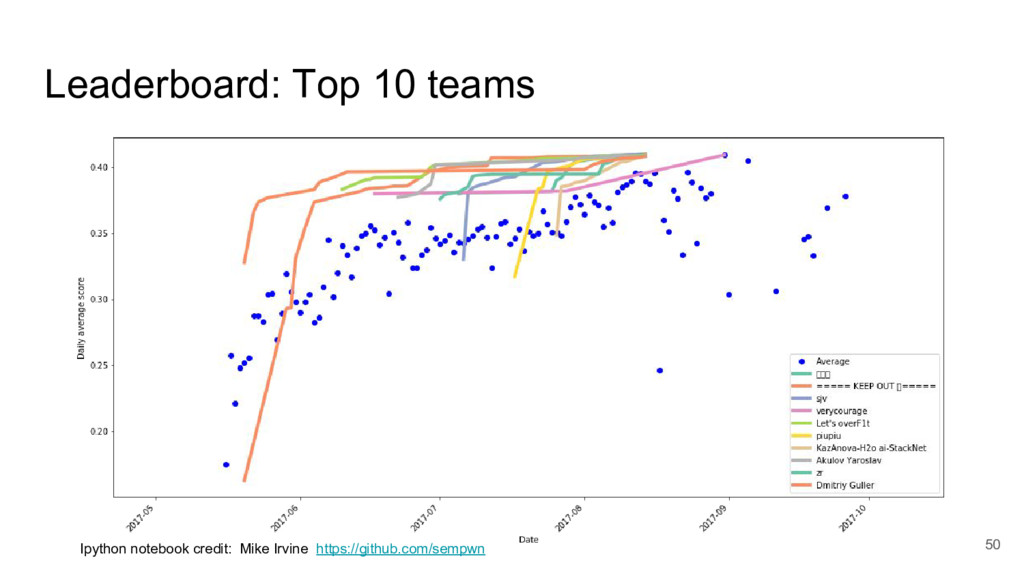
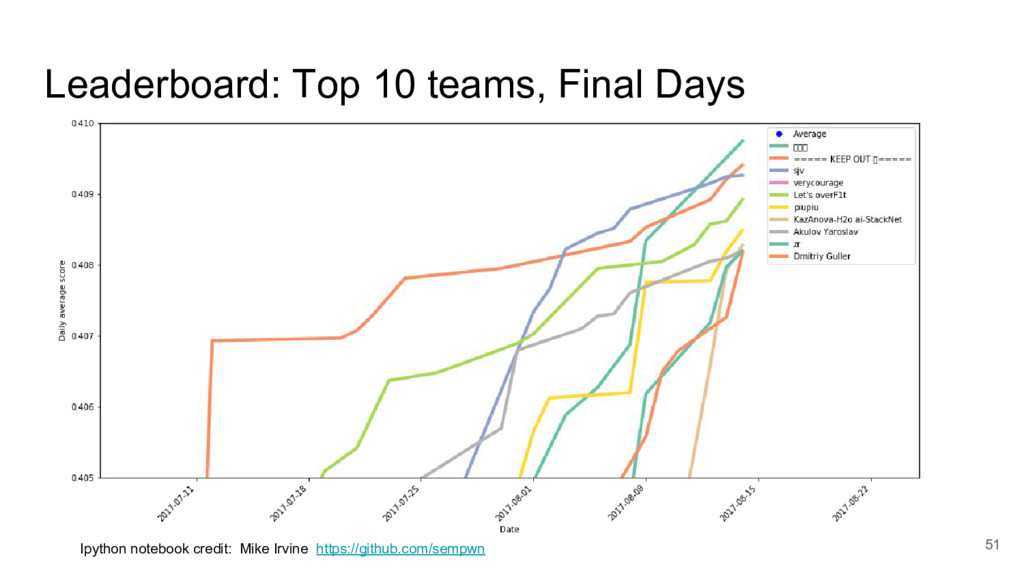
I took a close look at a recent predictive modelling competition on Kaggle.com. The challenge was to predict gocery re-orders on Instacart.com, based on historical data and the particular user’s history.
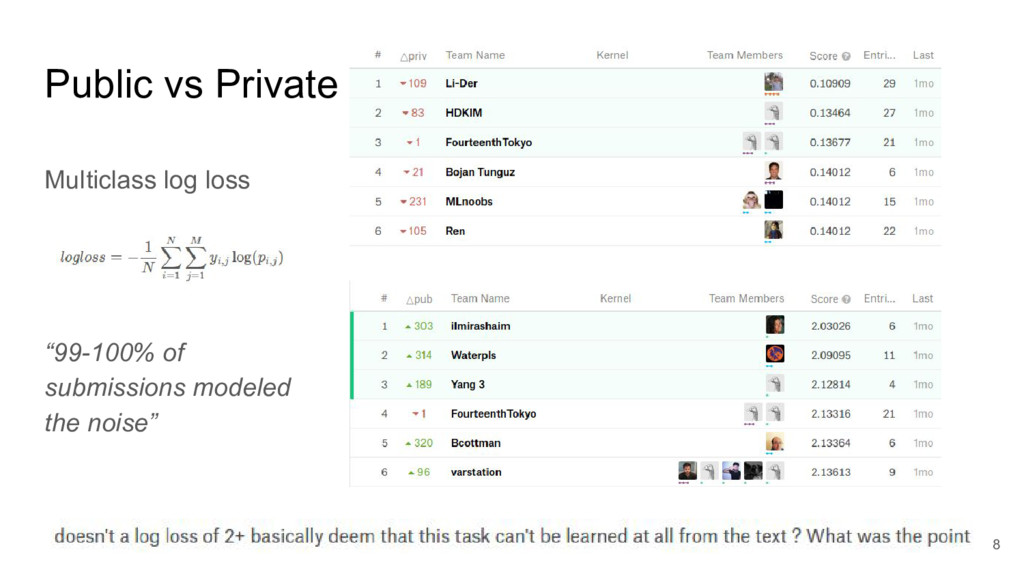
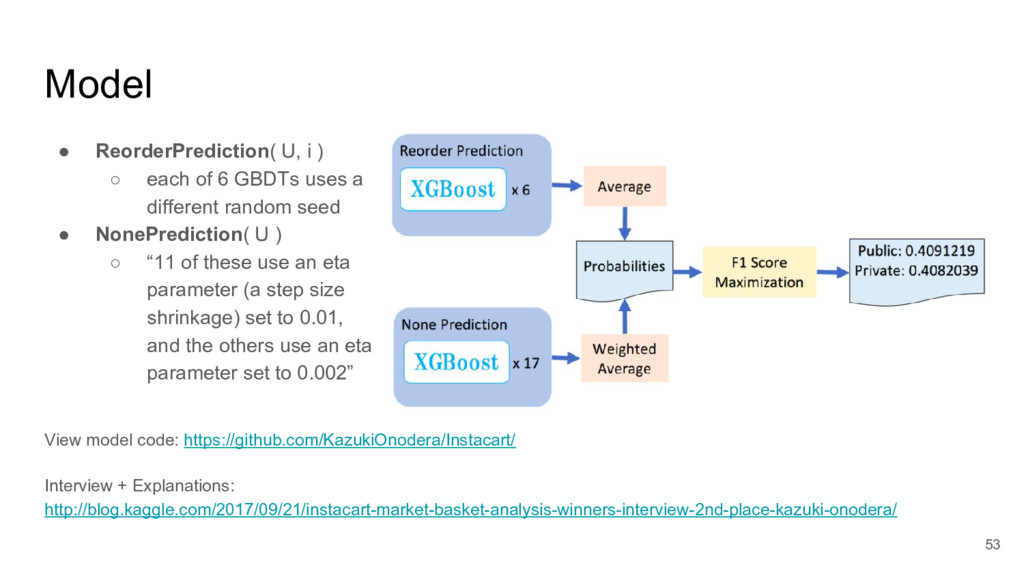
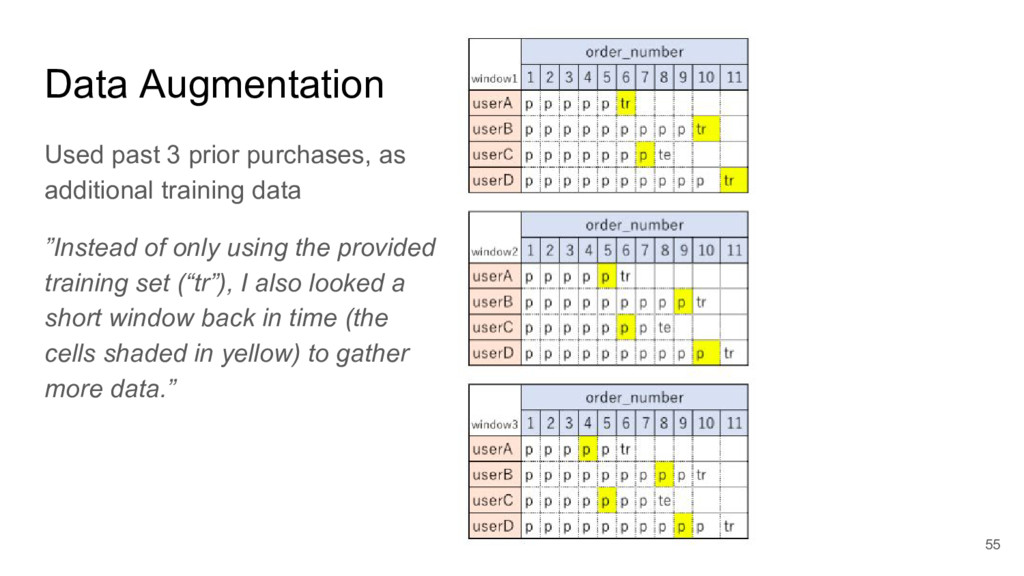
I focused on two submissions, ranked #2 and #3 on the leader board. These two solutions yielded nearly identical scores, using completely different approaches.
These two approaches are emblematic of two approaches to machine learning today.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
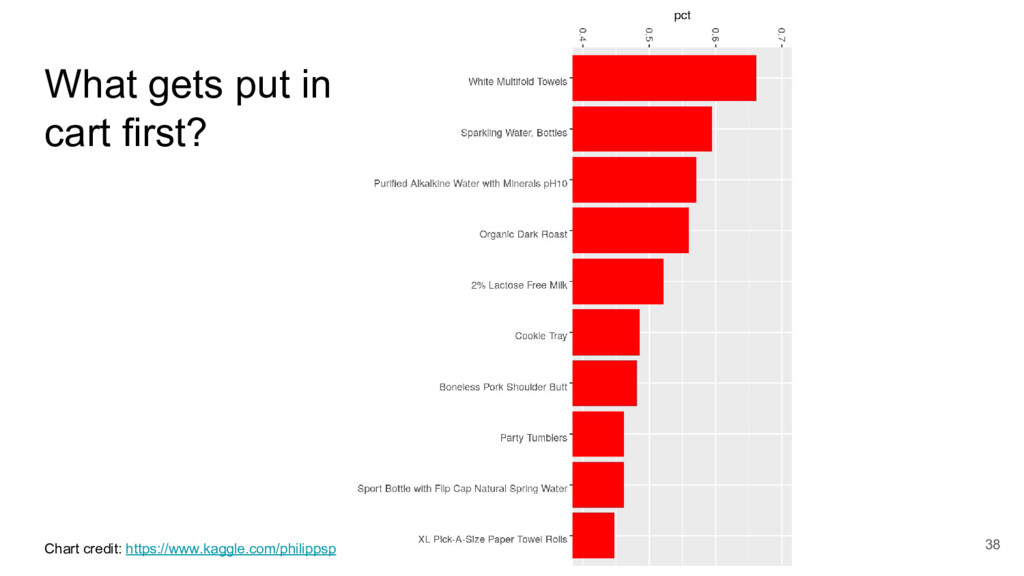{kind=link}
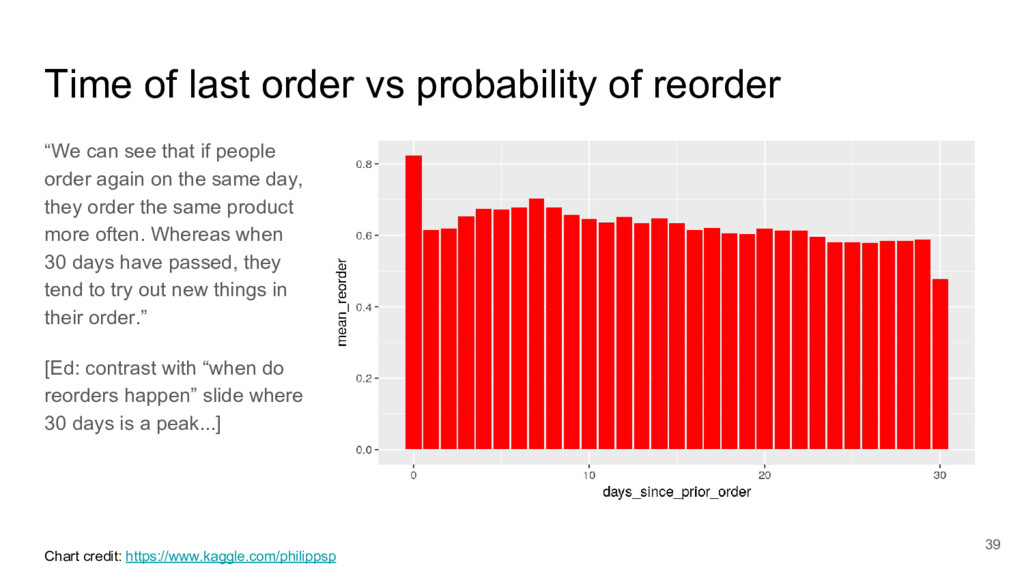{kind=link}
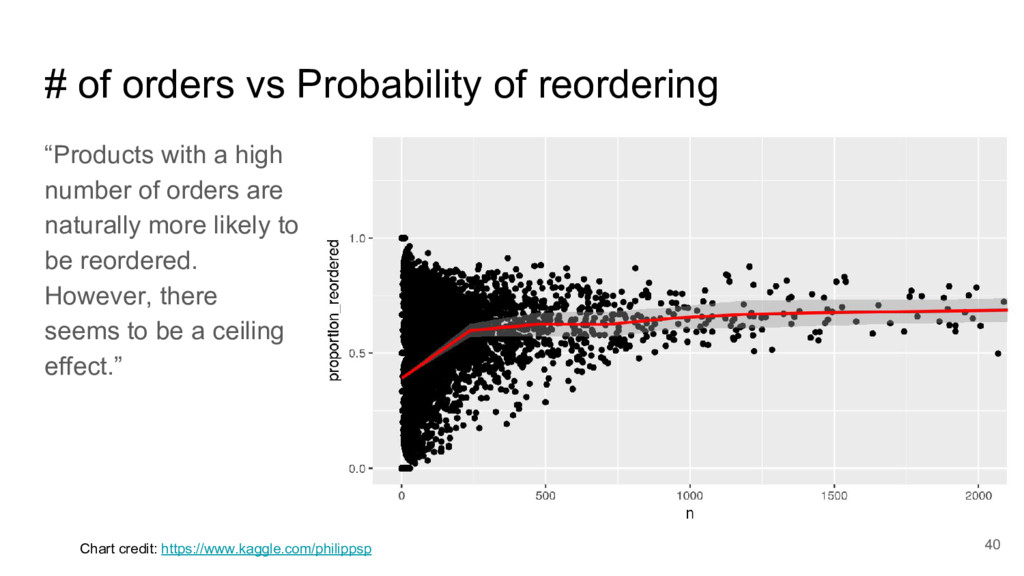{kind=link}
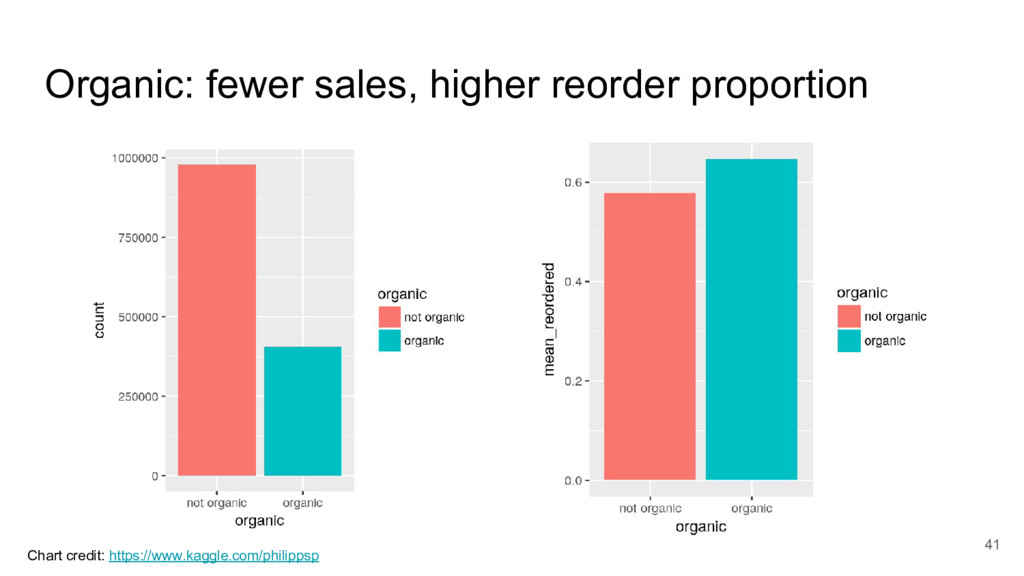{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
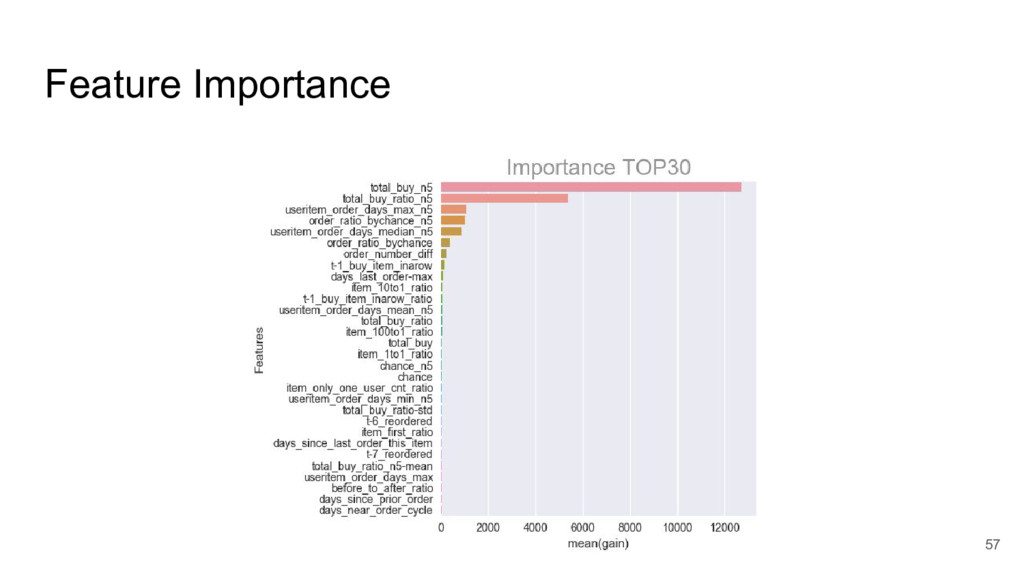{kind=link}
{kind=link}
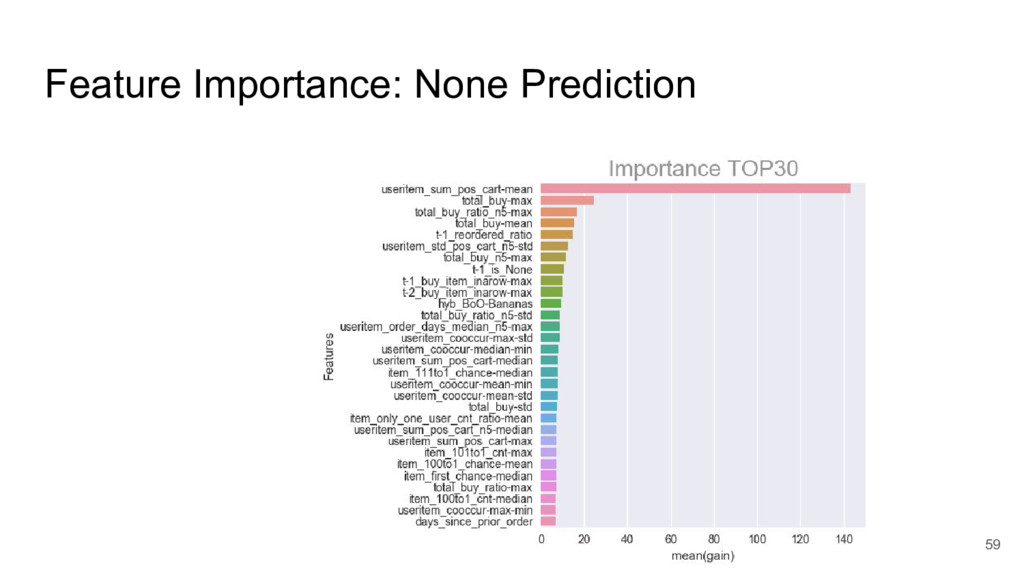{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
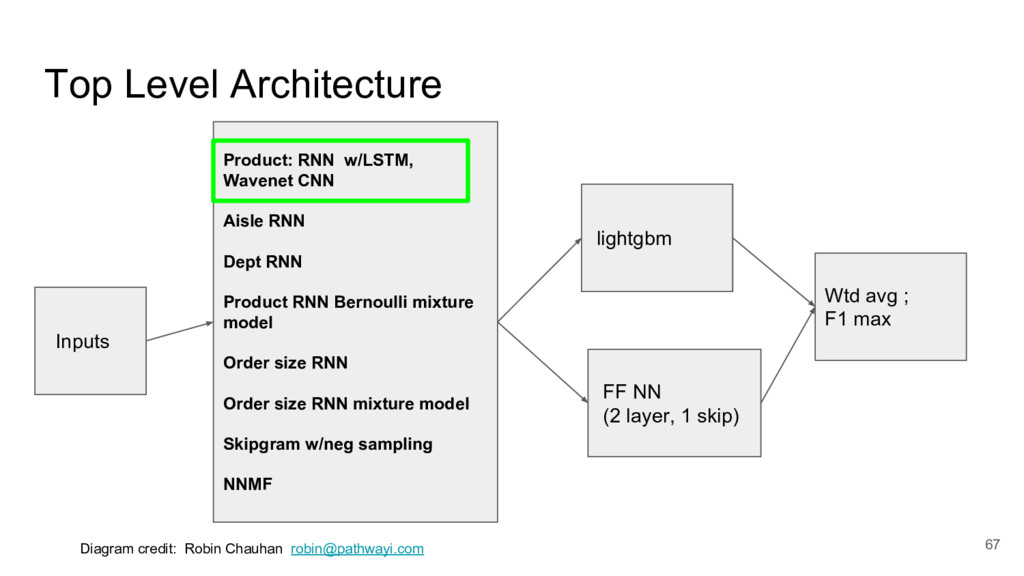{kind=link}
{kind=link}
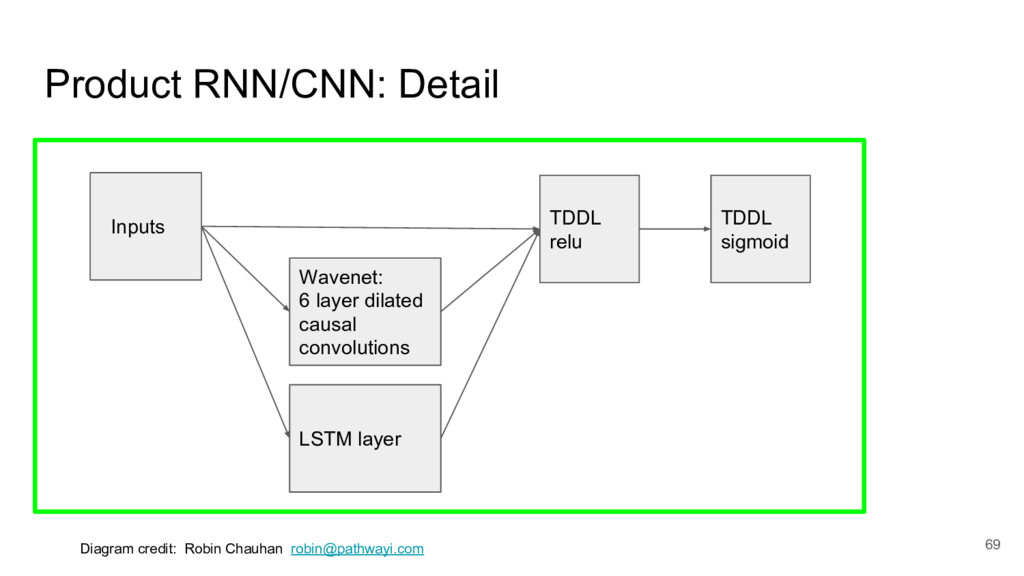{kind=link}
{kind=link}
![Product RNN/CNN: Inputs def get_input_sequences(self): self.user_id = tf.placeholder(tf.int32, [None]) self.product_id](https://files.speakerdeck.com/presentations/c9aafeea826f40978647b1f309f25f0a/slide_70.jpg){kind=link}
{kind=link}
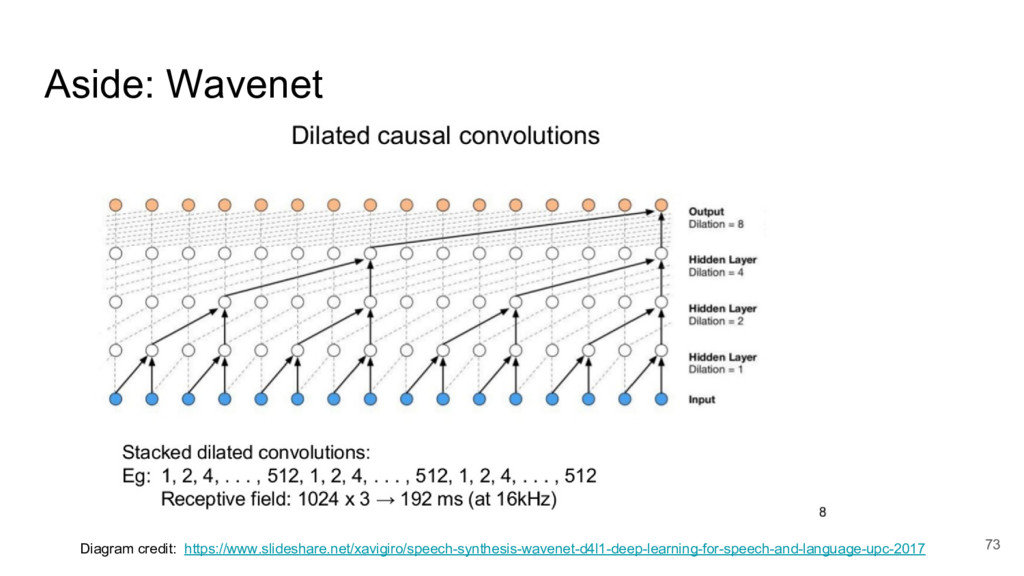{kind=link}
{kind=link}
![Product RNN/CNN: Embeddings product_embeddings = tf.get_variable( name='product_embeddings', shape=[50000, self.lstm_size], dtype=tf.float32](https://files.speakerdeck.com/presentations/c9aafeea826f40978647b1f309f25f0a/slide_74.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
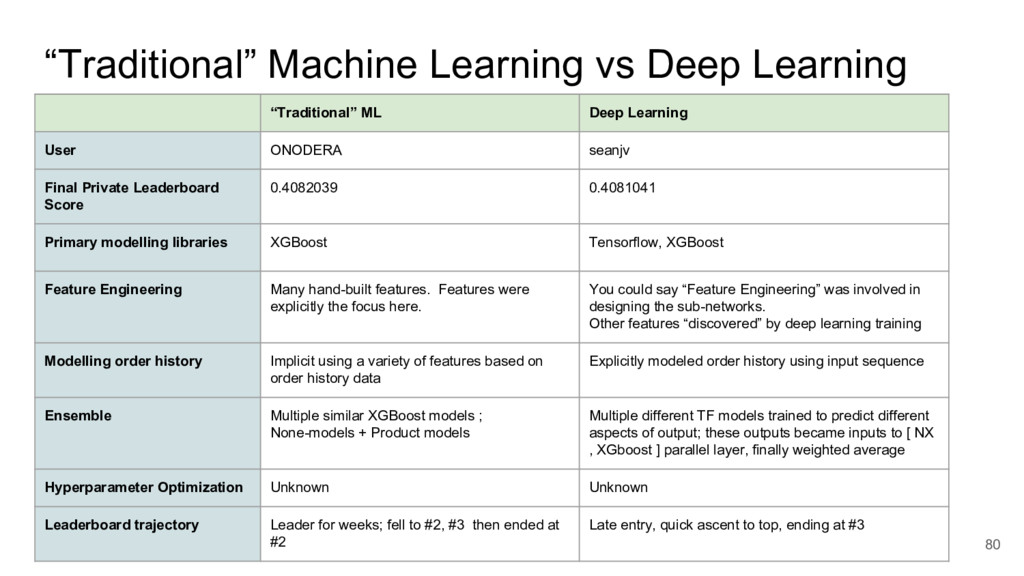{kind=link}