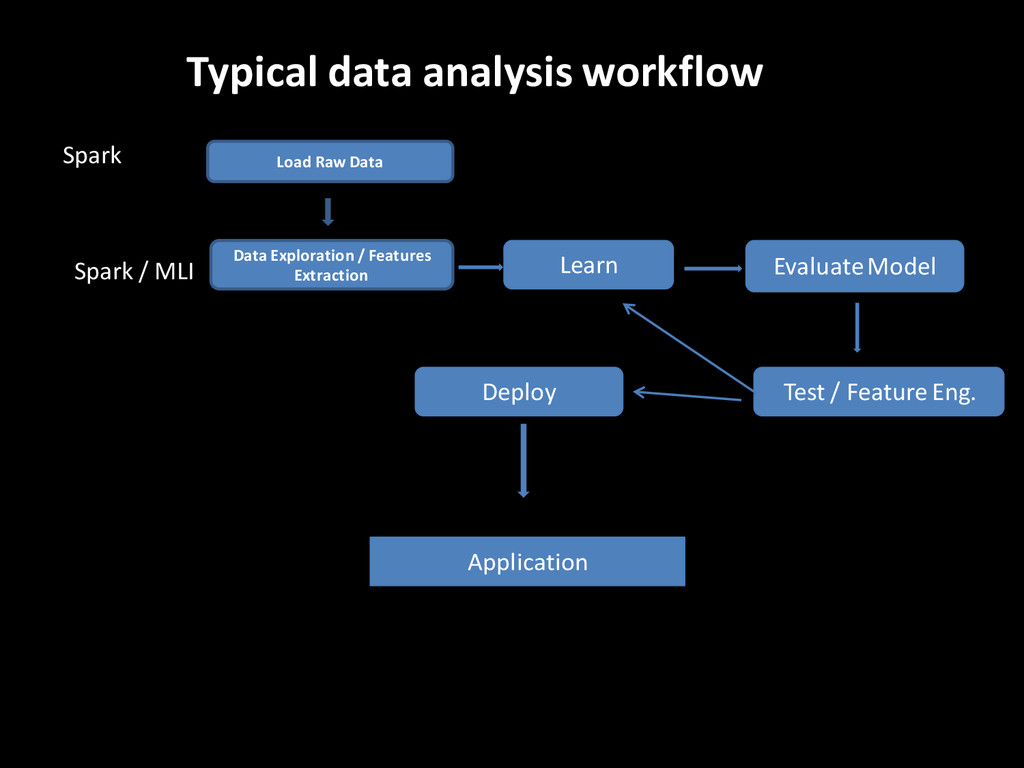
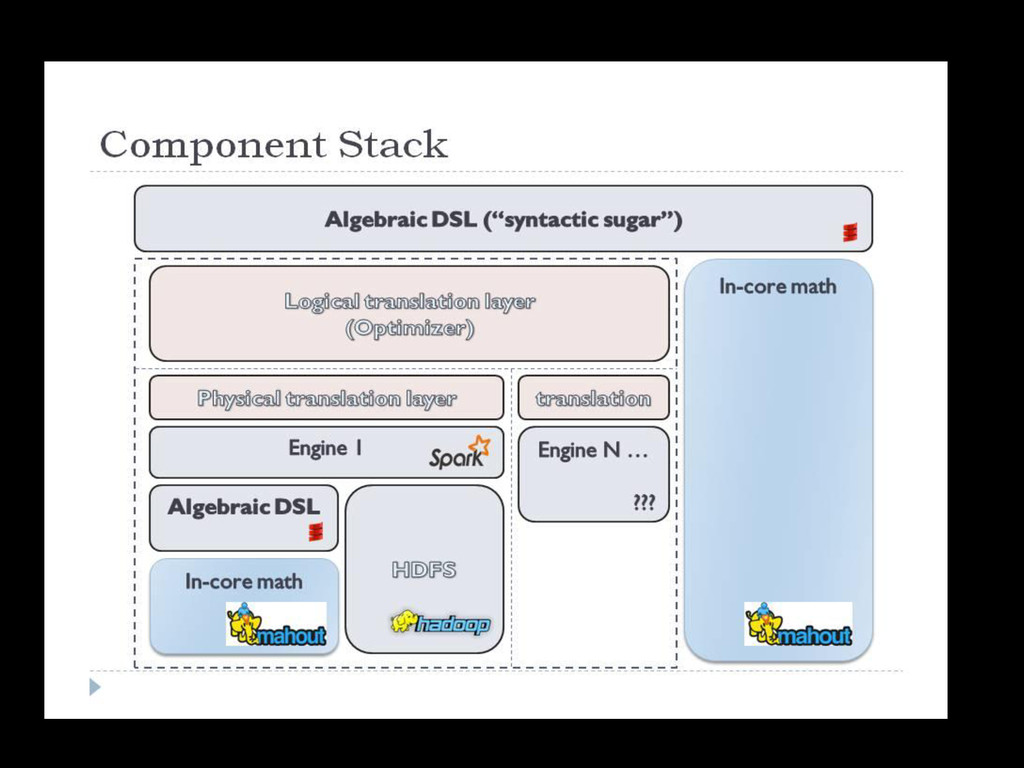
memory data, suited for iterative and complex workloads • Its own ML library (MLLIB) and more … • Built in Scala, fully interoperable with Java Can use most of the work done in the JVM • Fluent and intuitive API, thanks to Scala functional style • Comes with a REPL, like R and Python, for quick feedback and interactive testing. • Not just for ML , but fit for data pipelines, integration, data access and ETL
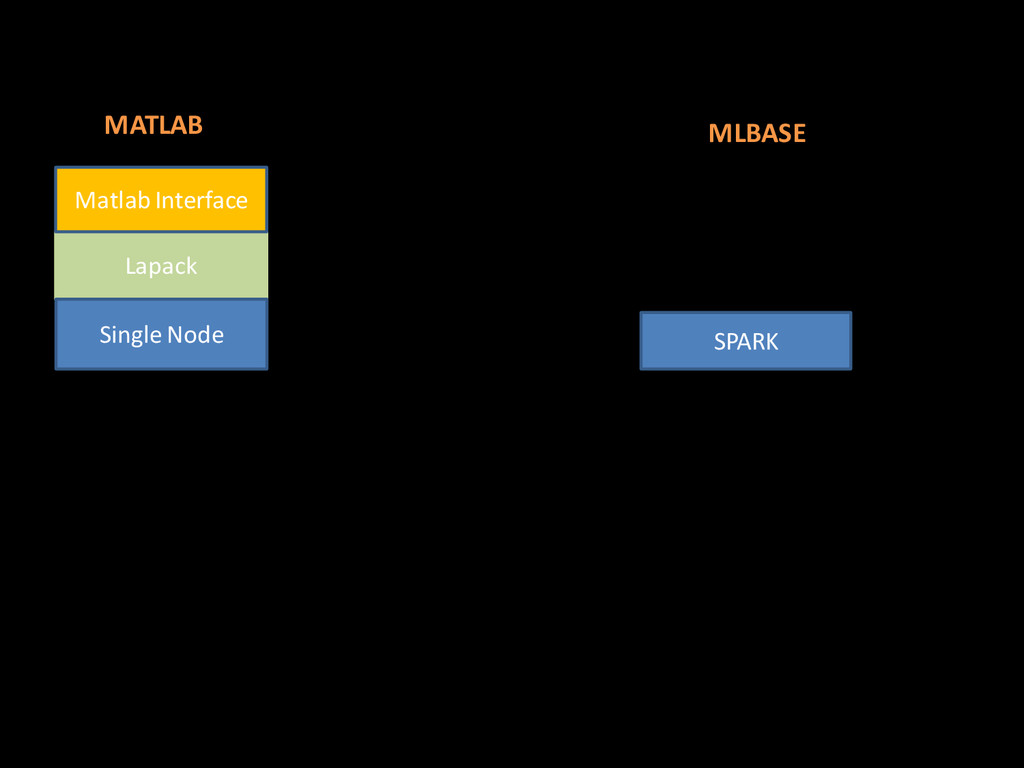
access and processing tools - Leverages and extends the Lapack functionalities But doesn’t scale to distributed environments. Single Node Lapack Matlab Interface
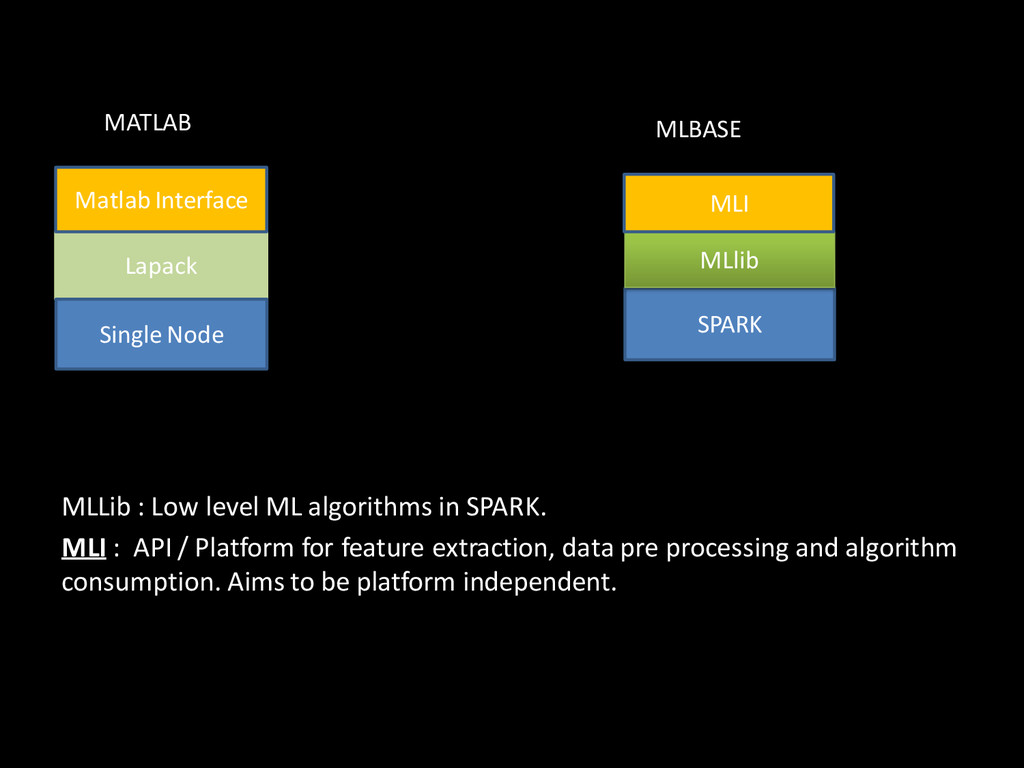
API / Platform for feature extraction, data pre processing and algorithm consumption. Aims to be platform independent. Lapack Single Node Matlab Interface MATLAB SPARK MLBASE MLlib MLI
Low level ML algorithms in Spark. MLI : API / Platform for feature extraction, data pre processing and algorithm consumption. Aims to be platform independent. ML Optimizer : automates model selection, by solving a search problem over features extractors SPARK MLBASE MLlib MLI ML Optimizer
model • So far contains algorithms for : - Regression : Ridge, Lasso - Classification : Support Vector Machine, Logistic Regression, - RecSys : Matrix Factorisation with ALS - Clustering : K means - Optimisation : Stochastic Gradient Descent More being contributed ….
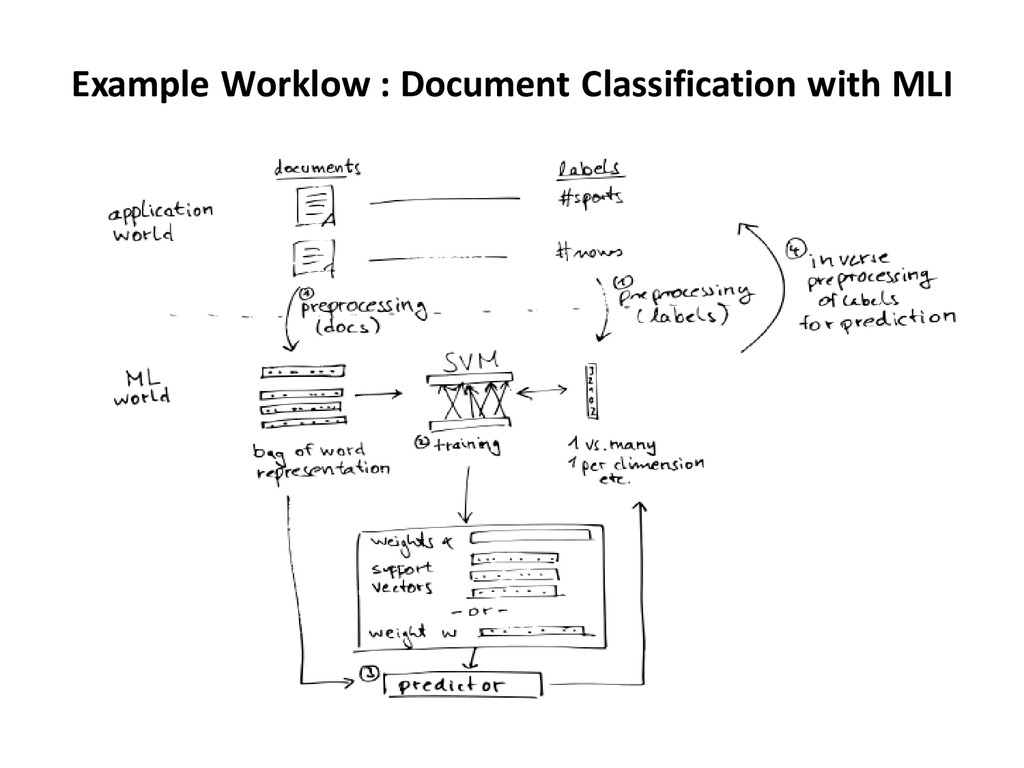
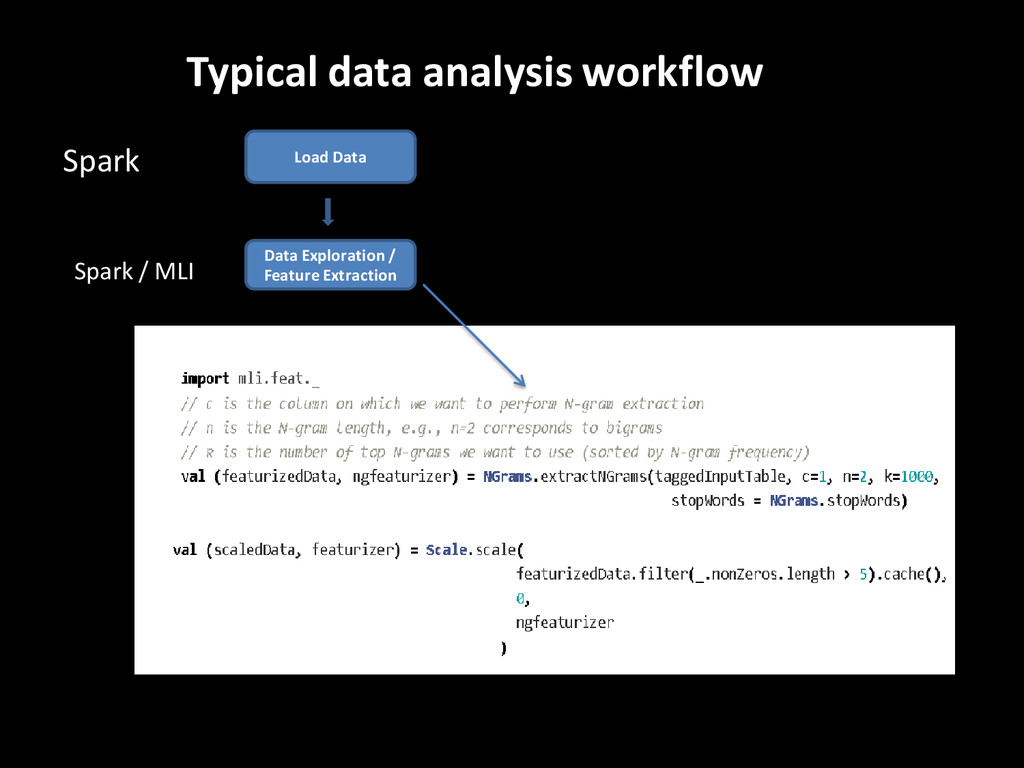
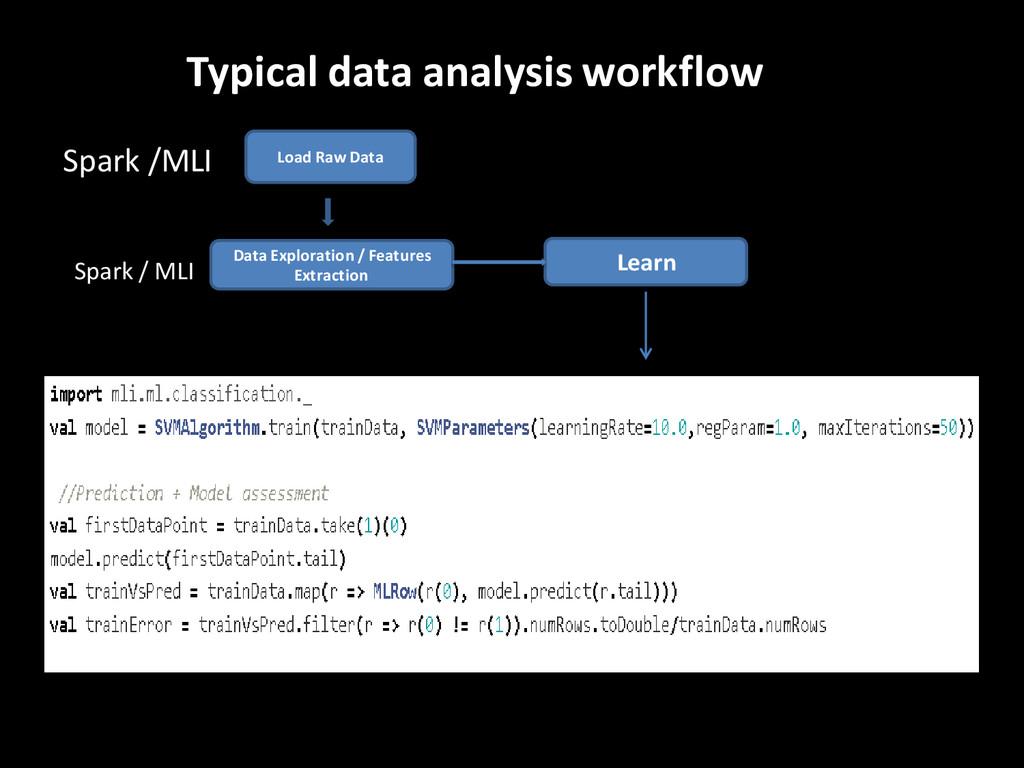
developers from runtimes implementation. • High level abstractions and operators to build models compatible with parallel data processing tools. • Linear Algebra : MLMatrix, MLRow, MLVector … - Linear algebra on local partitions - Sparse and Dense matrix support • Table Computations : MLTable - Similar to R/Pandas(Python) DataFrame or NumPy Array - Flexibility when loading /processing data - Common interface for feature extraction
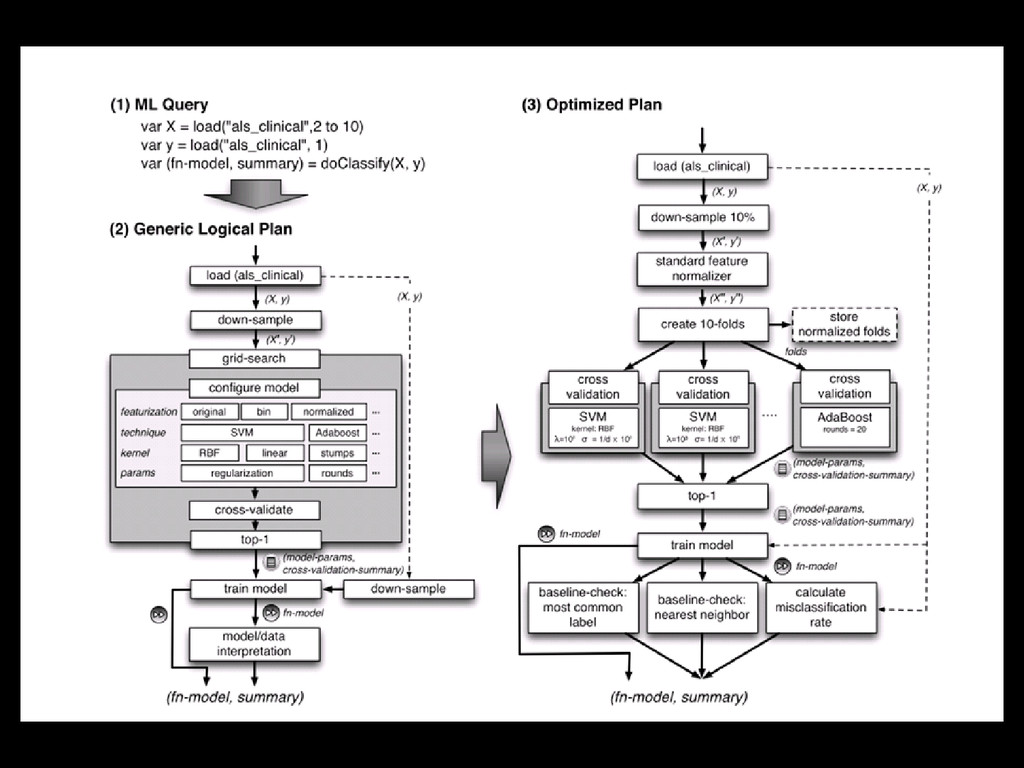
ML tasks declaratively • Have the system do all the heavy lifting using MLI and MLLib. var X = load (‘’local_file ’’, 2 to 10) var Y = load (‘’text_file’’, 1) var (fn-model, summary) = doClassify(X, y) Not available yet, currently under development .
• Primarily written in Scala, but can be used in PySpark via PythonMLLibAPI • So far contains algorithms for : - Regression : Ridge, Lasso, Linear - Classification : Support Vector Machines, Logistic Regression, Naive Bayes, Decision Trees - Linear Algebra : DistributedMatrix, RowMatrix, etc. - Recommenders : Alternating Least squares, (SVD++ in GraphX) - Clustering : K means - Optimisation : Stochastic Gradient Descent - … … More being contributed …. Look at the Spark JIRA and for the Spark 1.0 release
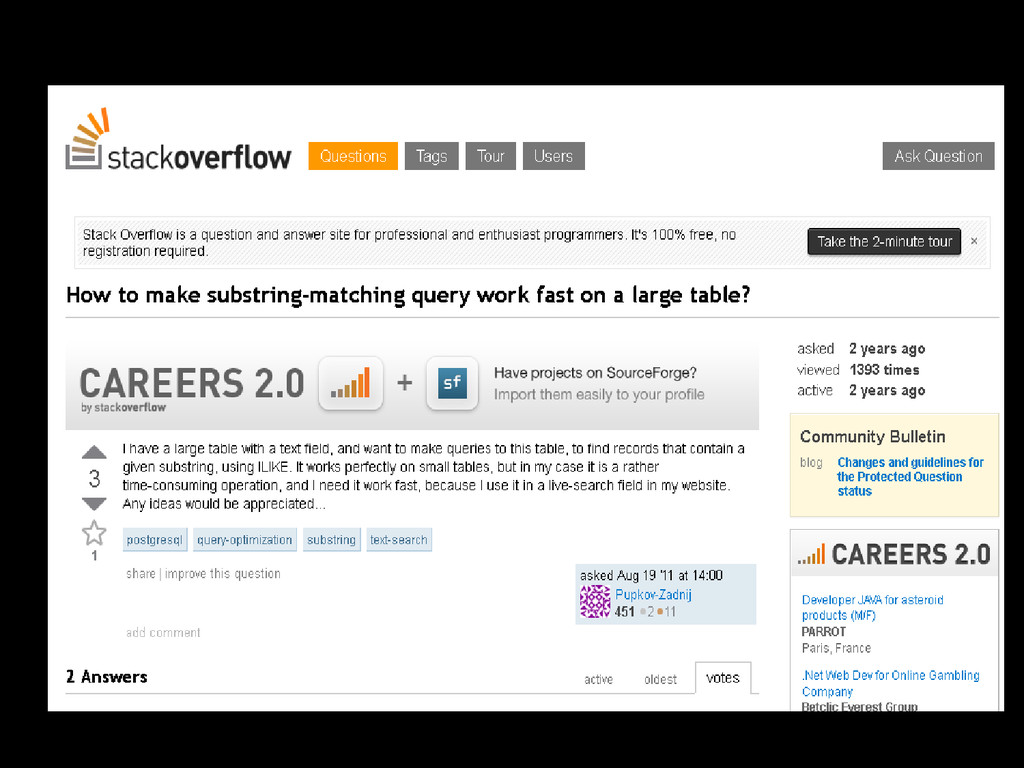
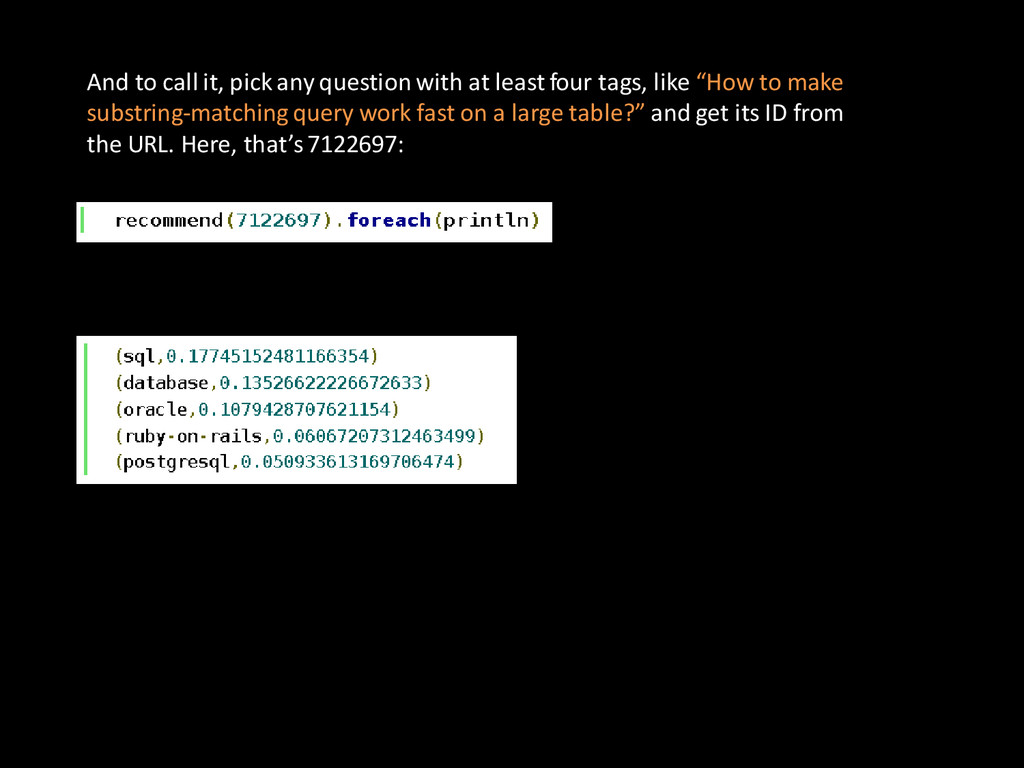
: http://blog.cloudera.com/blog/2014/03/why-apache-spark-is-a-crossover-hit-for-data-scientists/ • Stackoverflow tags suggestions • Build a model that can suggest new tags to questions based on existing tags, using the alternating least squares recommender algorithm; • Questions are “users” and tags are “items
Convert those tuples into Rating(userId, productId, rating) to be fed to ALS We get a factored matrix model, from which we can predict recommendations. Not in Mllib
a set of algorithms that requires some extra work to get value from - Many people are contributing, and a lot more trying to build on top of it. - Look for the Spark 1.0 release. - A new version of MLI should join Spark soon too.
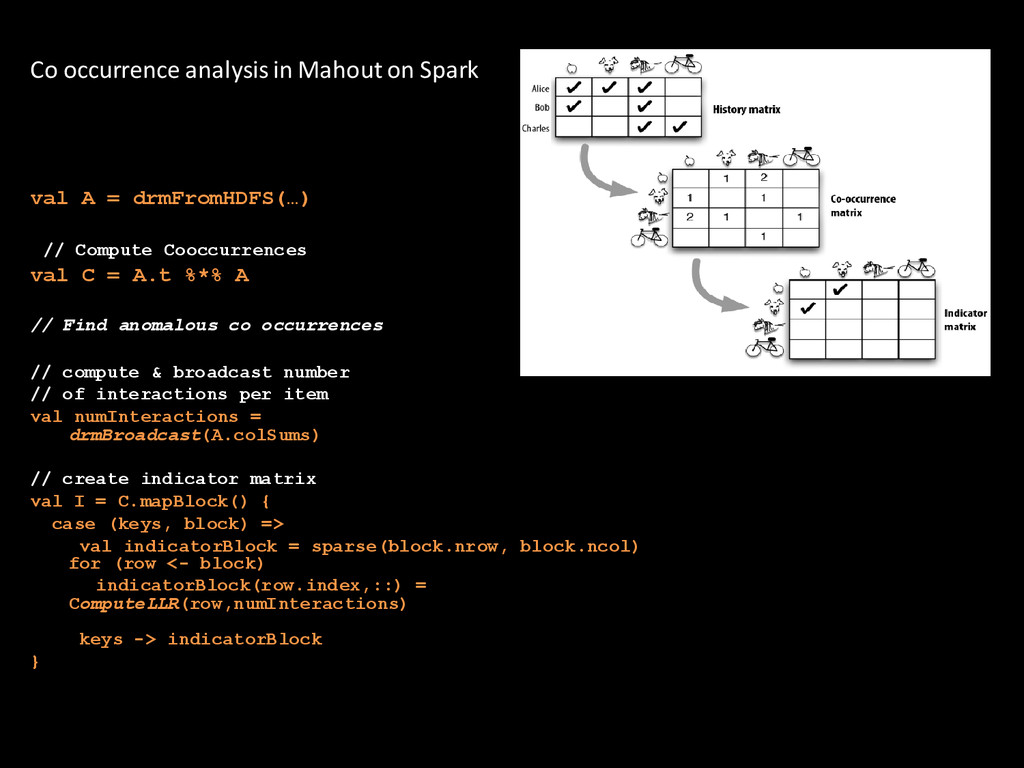
for Matrix operation for Mahout. • SPARK is being adopted as a second backend for Mahout (even Oryx) • Provides so far algorithms for - Mahout’s Distributed Row Matrices (DRM) - ALS and Cooccurence (coming soon ) - SSVD
A.t %*% A // Find anomalous co occurrences // compute & broadcast number // of interactions per item val numInteractions = drmBroadcast(A.colSums) // create indicator matrix val I = C.mapBlock() { case (keys, block) => val indicatorBlock = sparse(block.nrow, block.ncol) for (row <- block) indicatorBlock(row.index,::) = ComputeLLR(row,numInteractions) keys -> indicatorBlock } Co occurrence analysis in Mahout on Spark
for Spark. Built from the Graphlab ideas, and provide some machine learning functions like PageRank, ALS, SVD++, TriangleCount, SparkR and PySPARK, leverages R and Python data analysis tools with on SPARK. Spark Streaming : Stream processing on Spark, a great abstraction for stream mining, and analytics (think Algebird) SparkSQL and SHARK, to build machine learning workflows.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}