Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
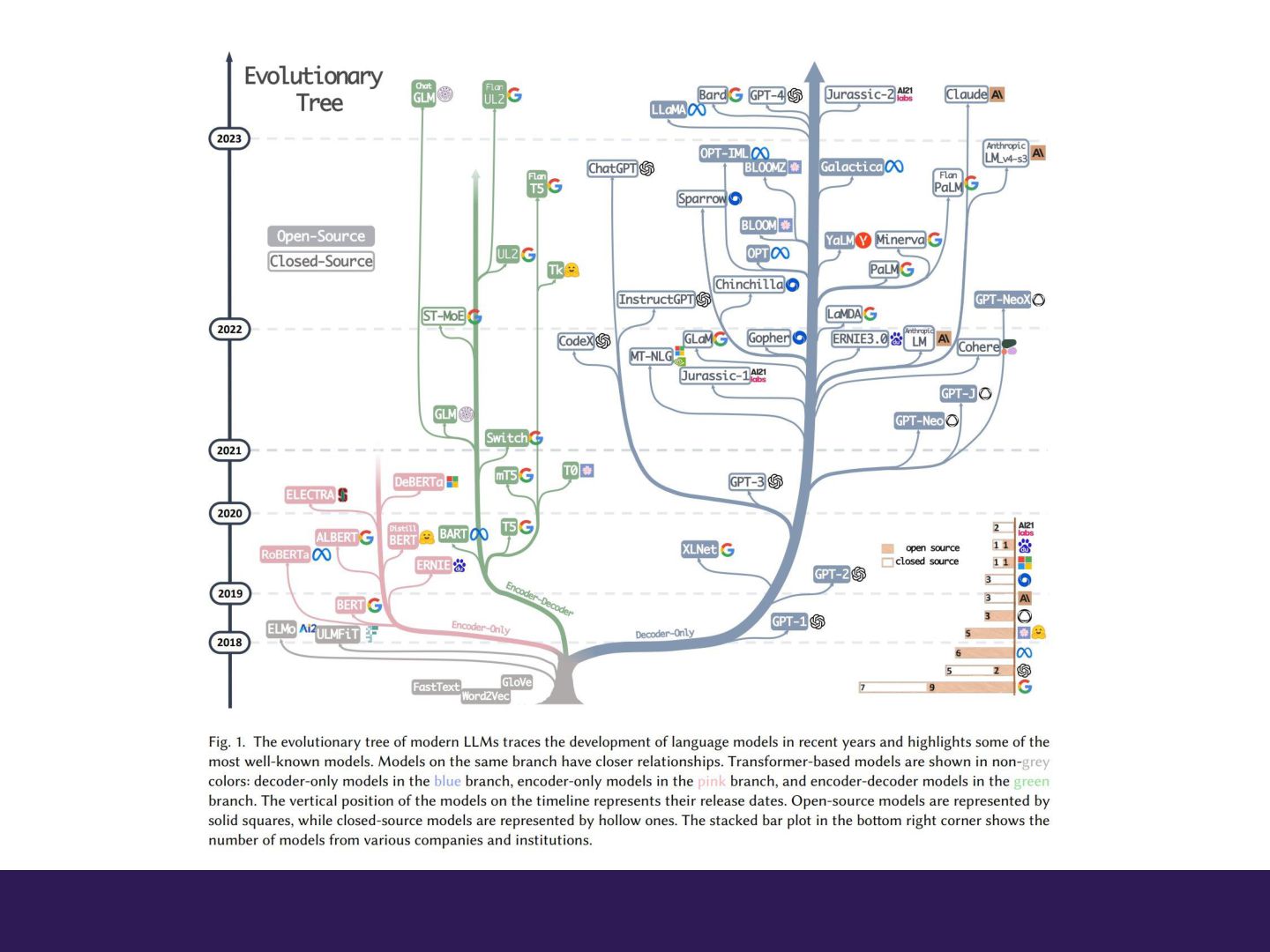
[輪講] Transformer(大規模言語モデル入門第2章)
Search
Taro Nakasone
September 05, 2025
Research
51
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[輪講] Transformer(大規模言語モデル入門第2章)
※過去に作成した資料の内部共有用の掲載です
Taro Nakasone
September 05, 2025
More Decks by Taro Nakasone
See All by Taro Nakasone
データセットシフト・Batch Normalization
taro_nakasone
0
28
次元削減・多様体学習 /maniford-learning20200707
taro_nakasone
2
2.2k
論文読み:Identifying Mislabeled Data using the Area Under the Margin Ranking (NeurIPS'20) /Area_Under_the_Margin_Ranking
taro_nakasone
0
210
Other Decks in Research
See All in Research
NII S. Koyama's Lab Research Overview AY2026
skoyamalab
0
460
[CV勉強会@関東 CVPR2026] PSDesigner: Automated Graphic Design with a Human-Like Creative Workflow / kantocv 67th CVPR 2026
shunk031
0
210
医療LLMの現在地〜最新研究から社会実装までを考える〜
kento1109
1
1.6k
LLM Compute Infrastructure Overview
karakurist
2
1.6k
Fukui Shibiten 39 - AI Art
butchi
0
160
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
380
GLIM とMegaParticles:正規分布近似の限界とタイトカップリング&パーティクルフィルタの進展 / GLIM and MegaParticles : Progress of the distribution representation in SLAM
koide3
0
660
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
720
MIRU2026 チュートリアル講演2:三次元データ処理の動向
nnchiba
1
850
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey
shunk031
4
1.1k
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
160
明日から使える!研究効率化ツール入門
matsui_528
13
7.5k
Featured
See All Featured
Mobile First: as difficult as doing things right
swwweet
225
10k
Marketing to machines
jonoalderson
1
5.6k
Building Applications with DynamoDB
mza
96
7.1k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
From π to Pie charts
rasagy
0
240
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
"I'm Feeling Lucky" - Building Great Search Experiences for Today's Users (#IAC19)
danielanewman
230
23k
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
430
The Curious Case for Waylosing
cassininazir
1
440
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
420
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
ReactJS: Keep Simple. Everything can be a component!
pedronauck
666
130k
Transcript
Transformer -大規模言語モデル入門第2章- 仲宗根太朗 櫻井研究室・輪講資料 作成日:2023/09/15
agenda ◼ 概要: ⚫ Transformerとは ⚫ Transformerが提案された背景 ⚫ Transformerの何がすごいのか ◼
Transformerの全体像 ► 入力トークン埋め込み ► Position encoding ► Attention ► Multi-head attention ► Feed-forward-layer ► Residual connection ► Layer normalization ► Dropout ► Masked Multi-head attention ► Cross-attention
None
Transformerとは ◼ Attention Is All You Need? ⚫Googleの研究チーム[Vaswani+, 2017]が機械翻訳タスクのモデル として「Transformer」を提案
⚫幅広いタスクに応用 → 現代のNLPの「基礎アーキテクチャ」となった それまで主流であった畳み込み構造(CNN)や再帰構造(RNN) を使用せず、Attention機構のみに基づいたアーキテクチャで従来 のモデルの精度を大幅に更新したことで注目を浴びた
Transformerが提案された背景 ◼提案以前の機械翻訳タスクはRNN(LSTM)+Attention機構が 主流だった ⚫問題点①:長期記憶が苦手 ► RNNは入力系列が長くなればなるほど、精度が低下 ► LSTMやAttention機構が提案され緩和されたものの改善余地は大き かった ⚫問題点②:並列処理ができない
► RNNは単語を逐次的に処理していく「自己回帰モデル」のため並列計 算が難しい ► これに付随して、処理速度が遅い・大規模な学習データを使用できな い
Transformerの何がすごいのか ◼従来モデルよりも優れている点 1. 処理速度: ► 並列化処理によって学習時間を大幅に短縮 2. 精度: ► 機械翻訳タスクで当時のSoTAを大幅に更新
► その後様々な系列変換タスクで性能向上を記録 3. 汎用性(スケーラビリティ) ► 大規模なデータを学習することが可能 ► BERTやGPT, 近年の大規模言語モデルのベースモデルとして採用 https://paperswithcode.com/sota/machine-translation-on-wmt2014-english-german
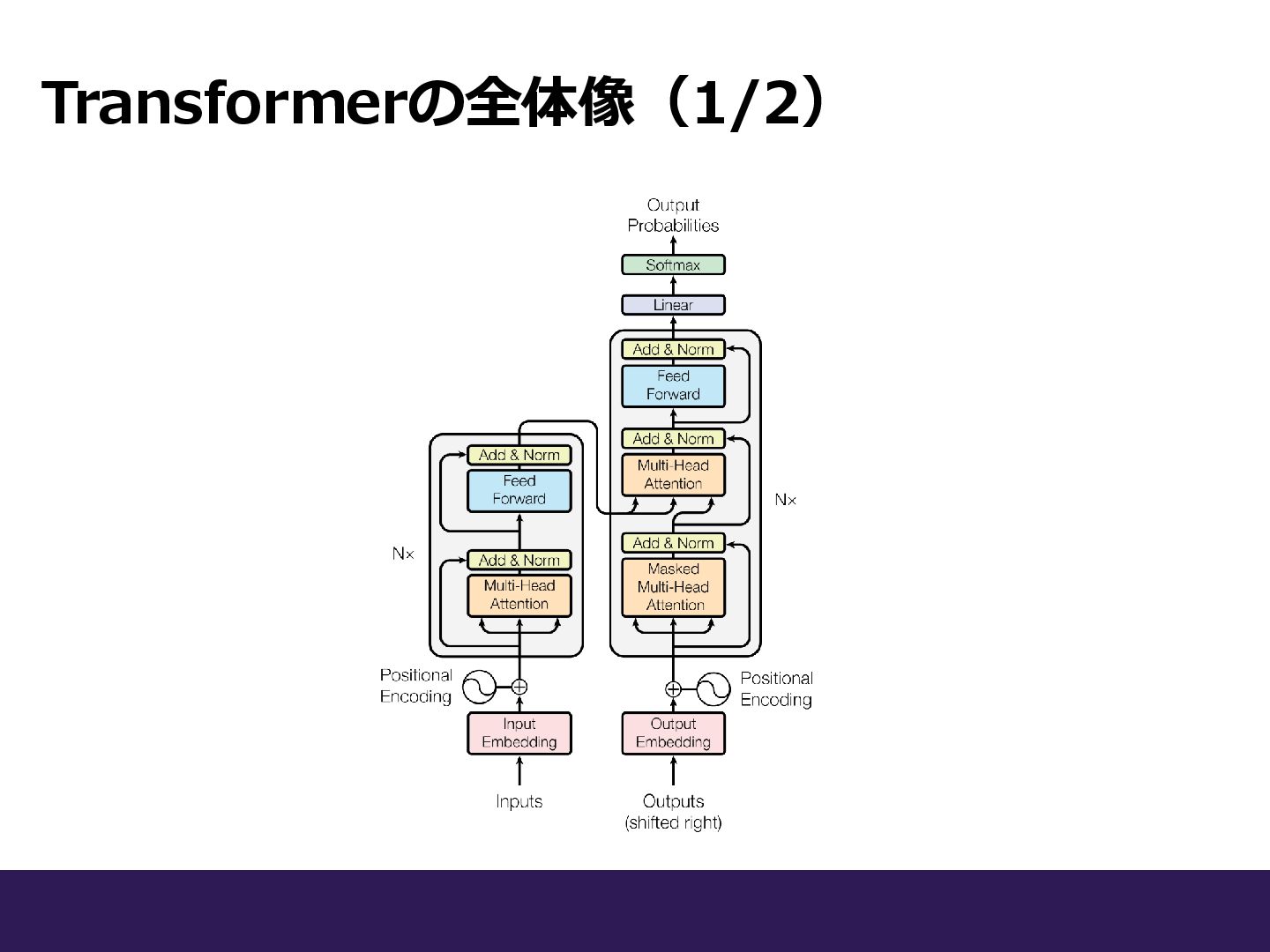
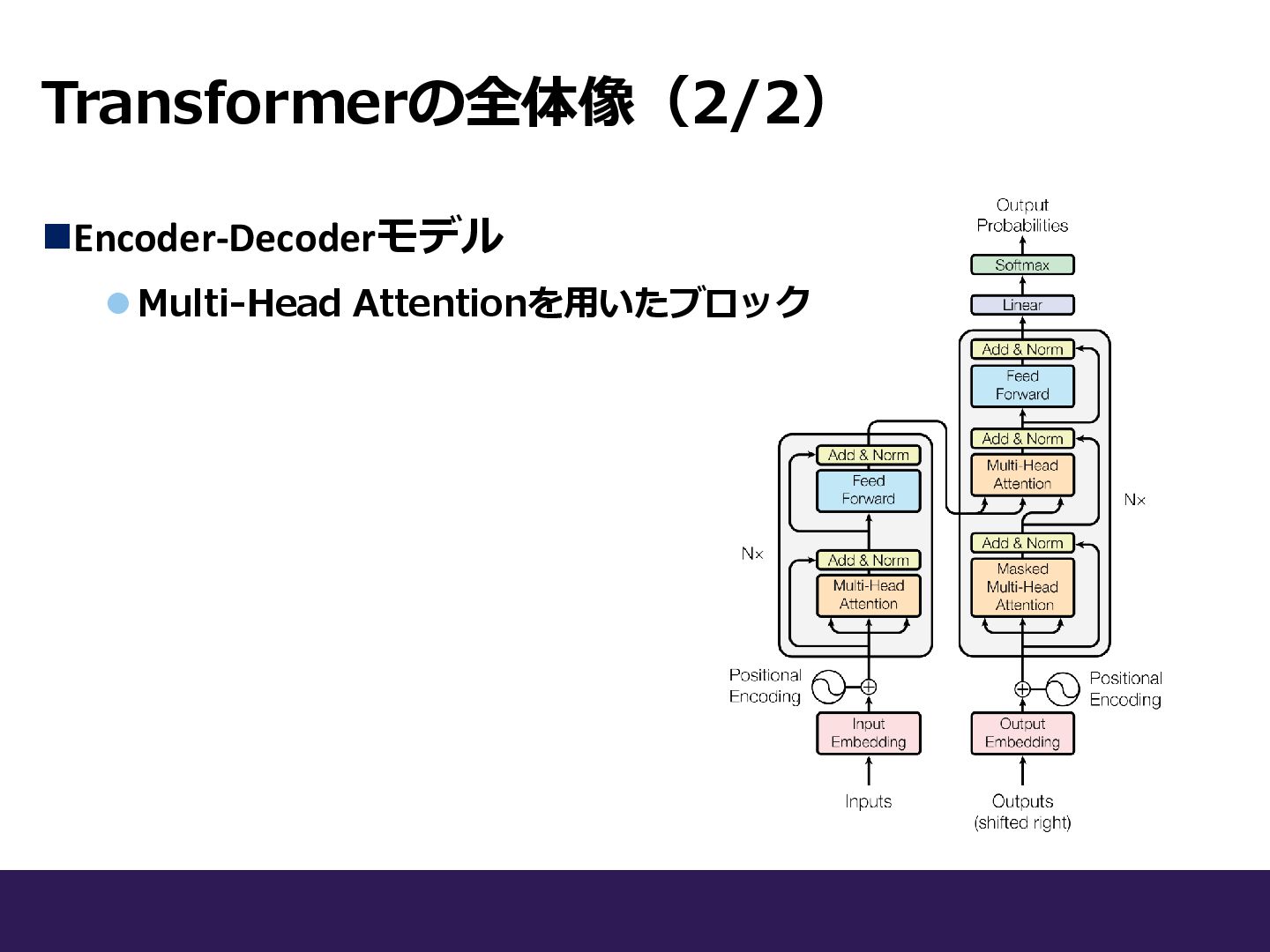
Transformerの全体像(1/2)
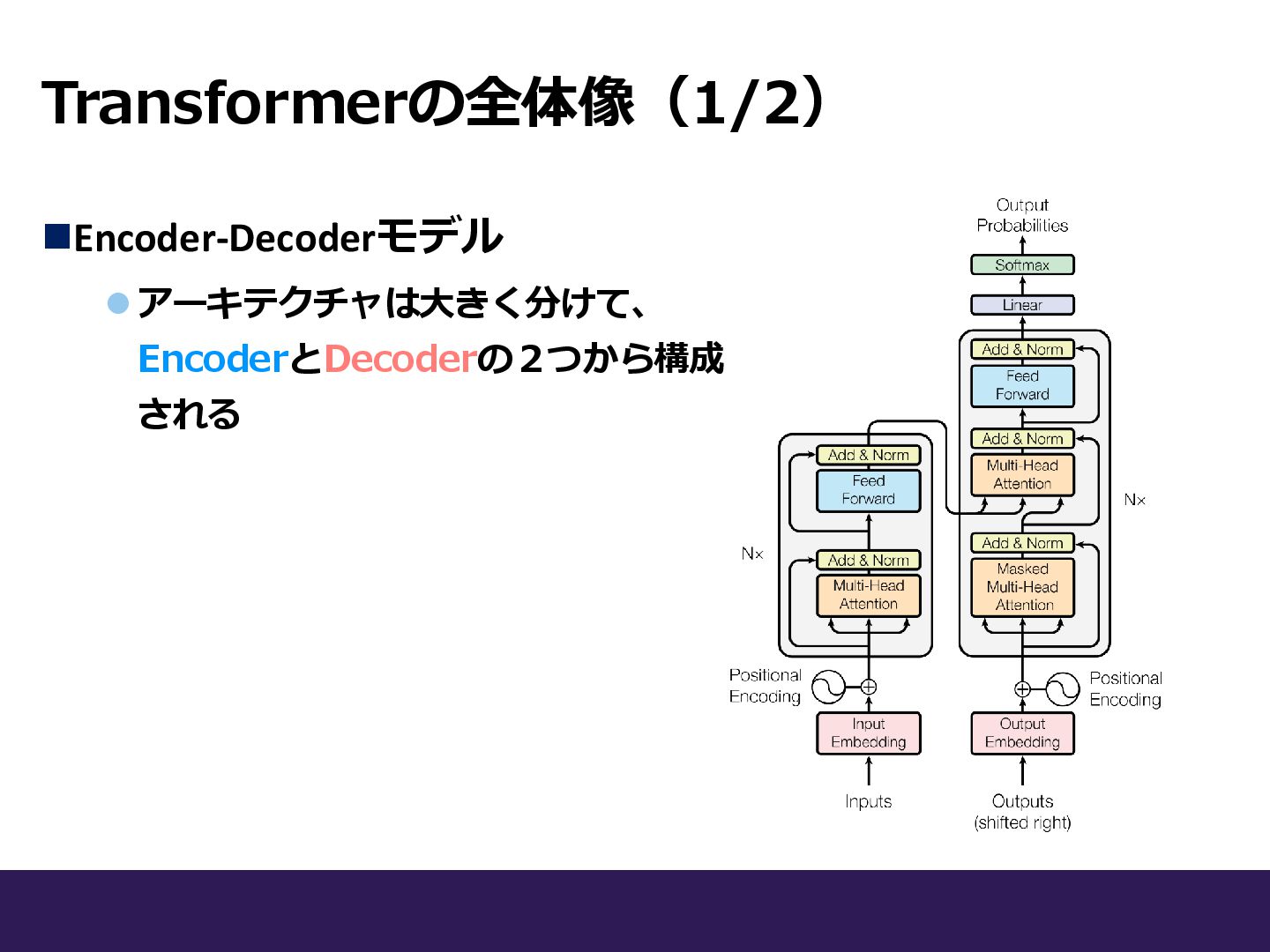
Transformerの全体像(1/2) ◼Encoder-Decoderモデル ⚫アーキテクチャは大きく分けて、 EncoderとDecoderの2つから構成 される
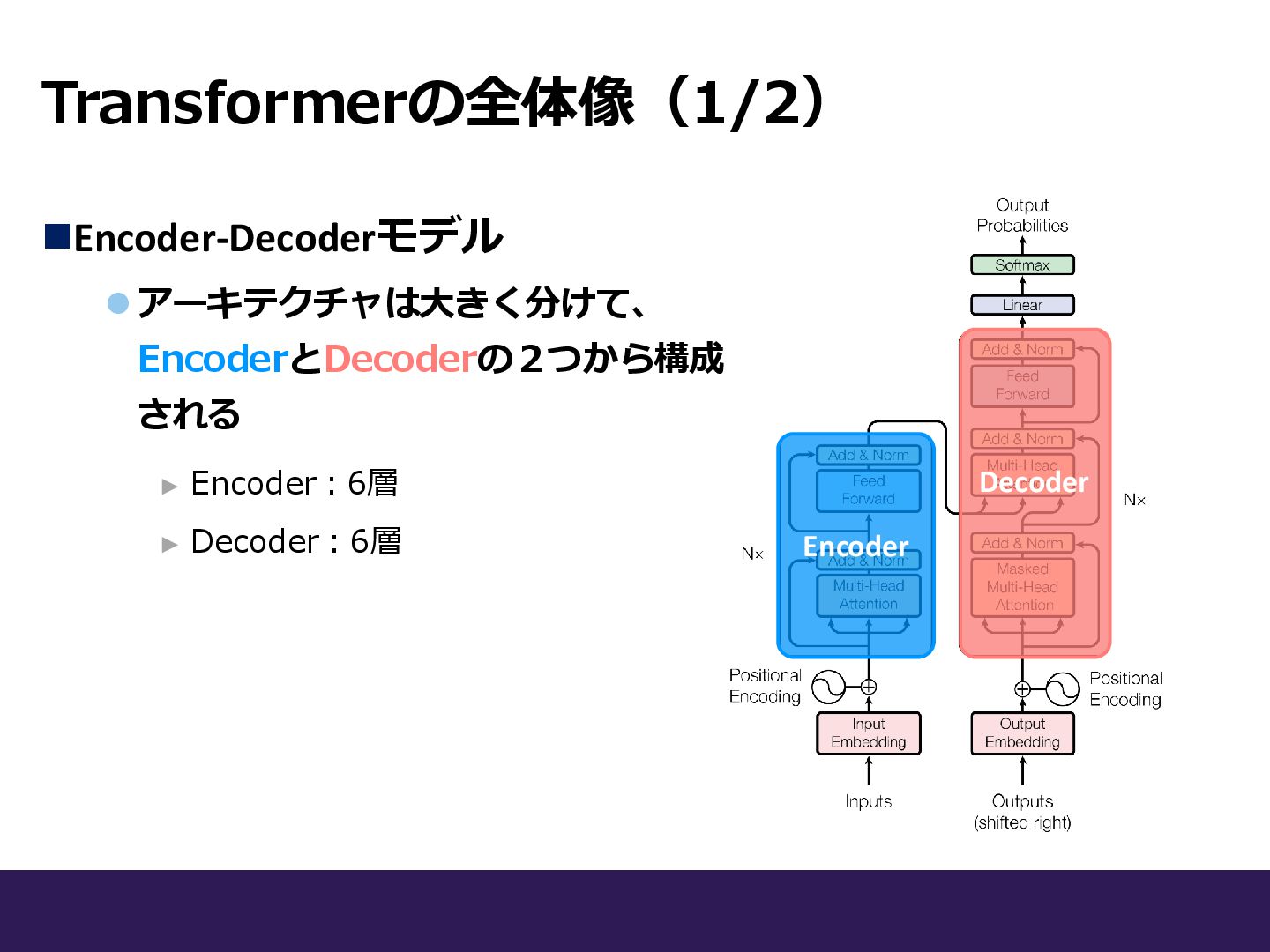
Transformerの全体像(1/2) ◼Encoder-Decoderモデル ⚫アーキテクチャは大きく分けて、 EncoderとDecoderの2つから構成 される Encoder Decoder ► Encoder:6層 ►
Decoder:6層
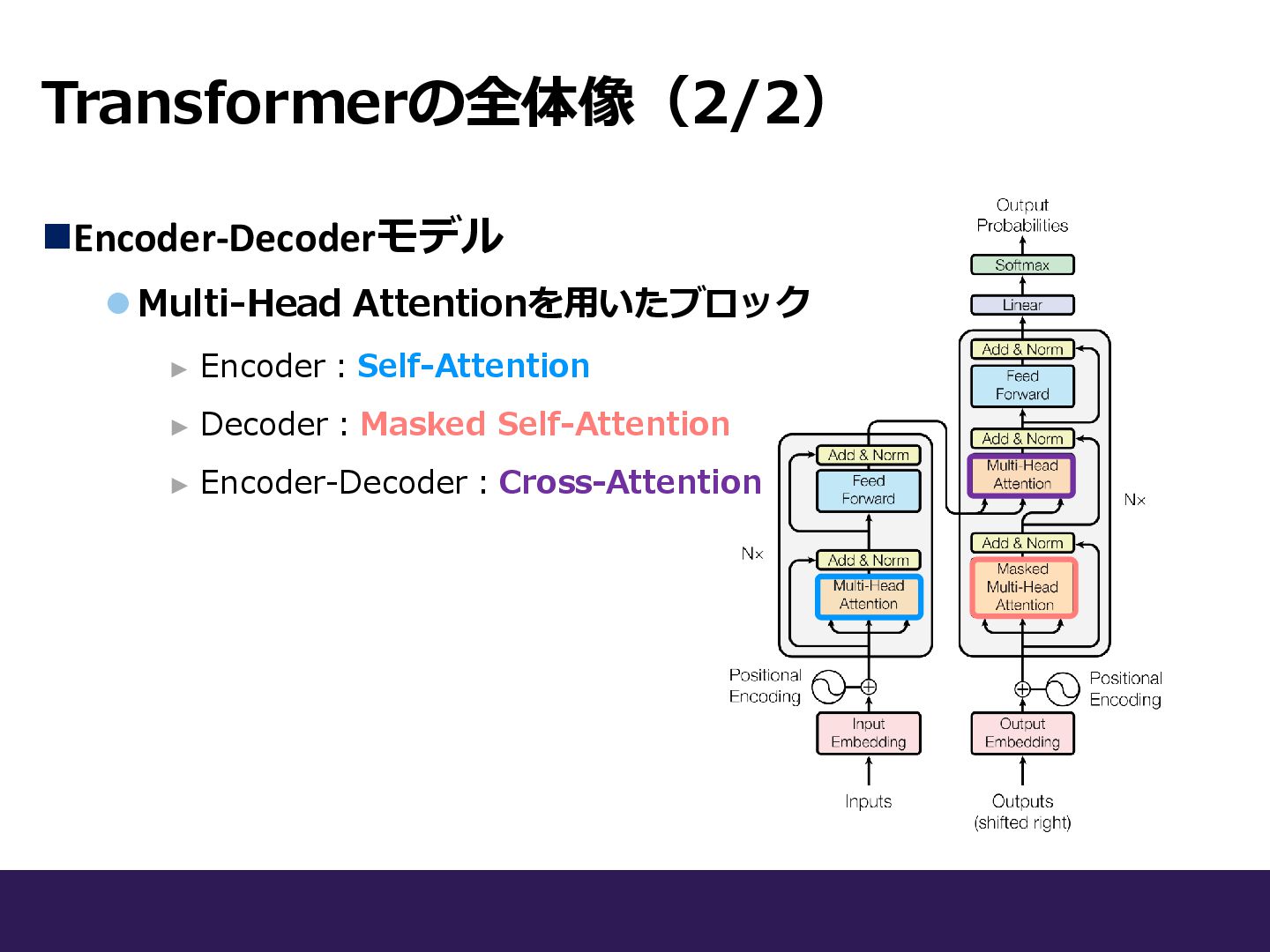
Transformerの全体像(2/2) ◼Encoder-Decoderモデル ⚫Multi-Head Attentionを用いたブロック
Transformerの全体像(2/2) ◼Encoder-Decoderモデル ⚫Multi-Head Attentionを用いたブロック ► Encoder:Self-Attention ► Decoder:Masked Self-Attention ►
Encoder-Decoder:Cross-Attention
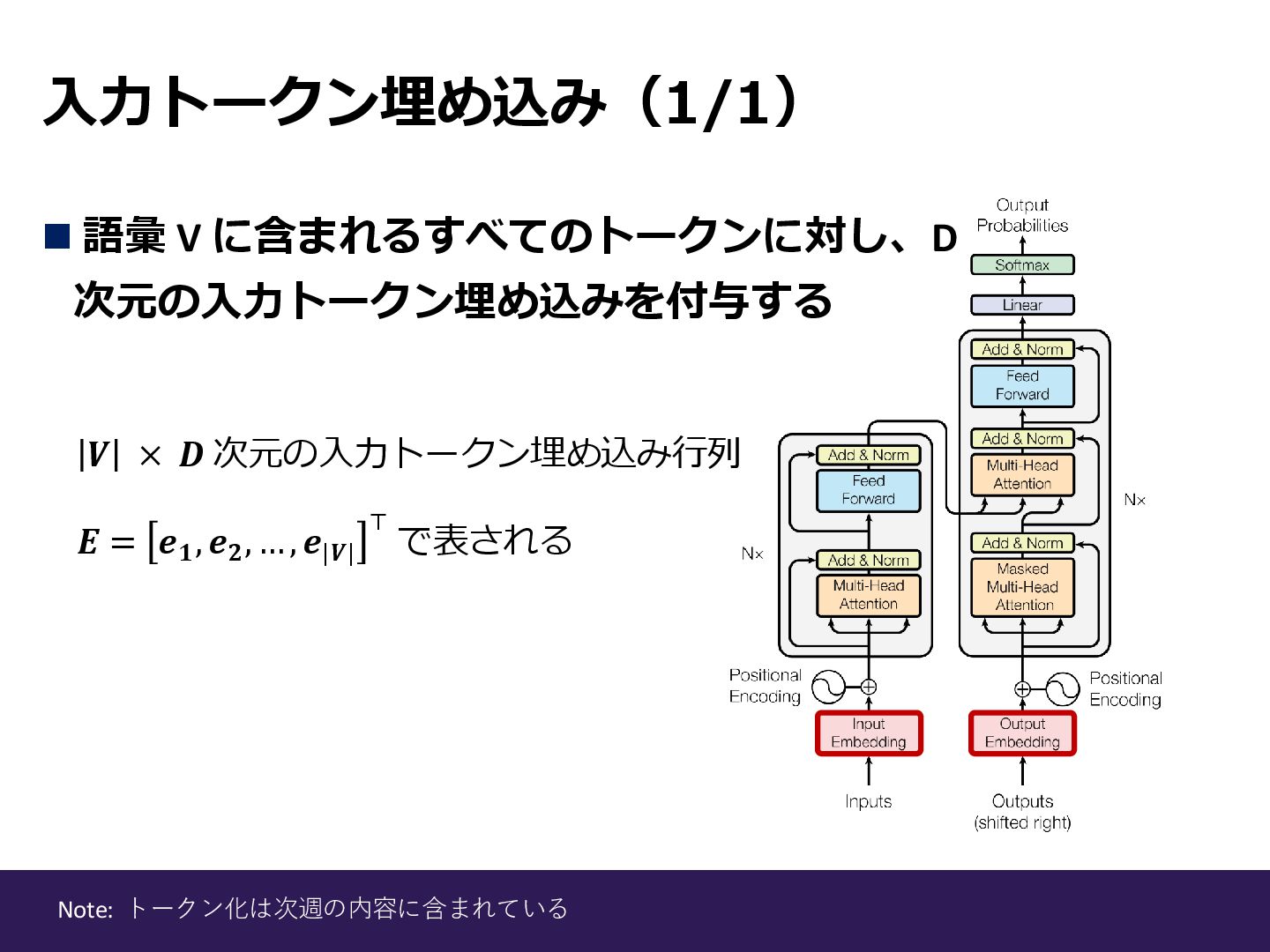
入力トークン埋め込み(1/1) ◼ 語彙 V に含まれるすべてのトークンに対し、D 次元の入力トークン埋め込みを付与する 𝑽 × 𝑫 次元の入力トークン埋め込み行列
𝜠 = 𝒆𝟏 , 𝒆𝟐 , … , 𝒆|𝑽| ⊤ で表される Note: トークン化は次週の内容に含まれている
補足①:入力トークン埋め込み ◼入力埋め込み層を用いる一般的な処理 1. 与えられた単語列を辞書に基づいて、単語IDに変換する • Birds fly in the sky.
→ [102, 304, 56, 12, 401] 2. 単語ID列に対して入力埋め込み層を適用して、単語ベクトルに変換 • [102, 304, 56, 12, 401] → 𝒆𝐵𝑖𝑟𝑑𝑠 , 𝒆𝑓𝑙𝑦 , … , 𝒆𝑠𝑘𝑦 ⊤ Birds fly in the sky. 𝒆𝐵𝑖𝑟𝑑𝑠 , 𝒆𝑓𝑙𝑦 , … , 𝒆𝑠𝑘𝑦 ⊤
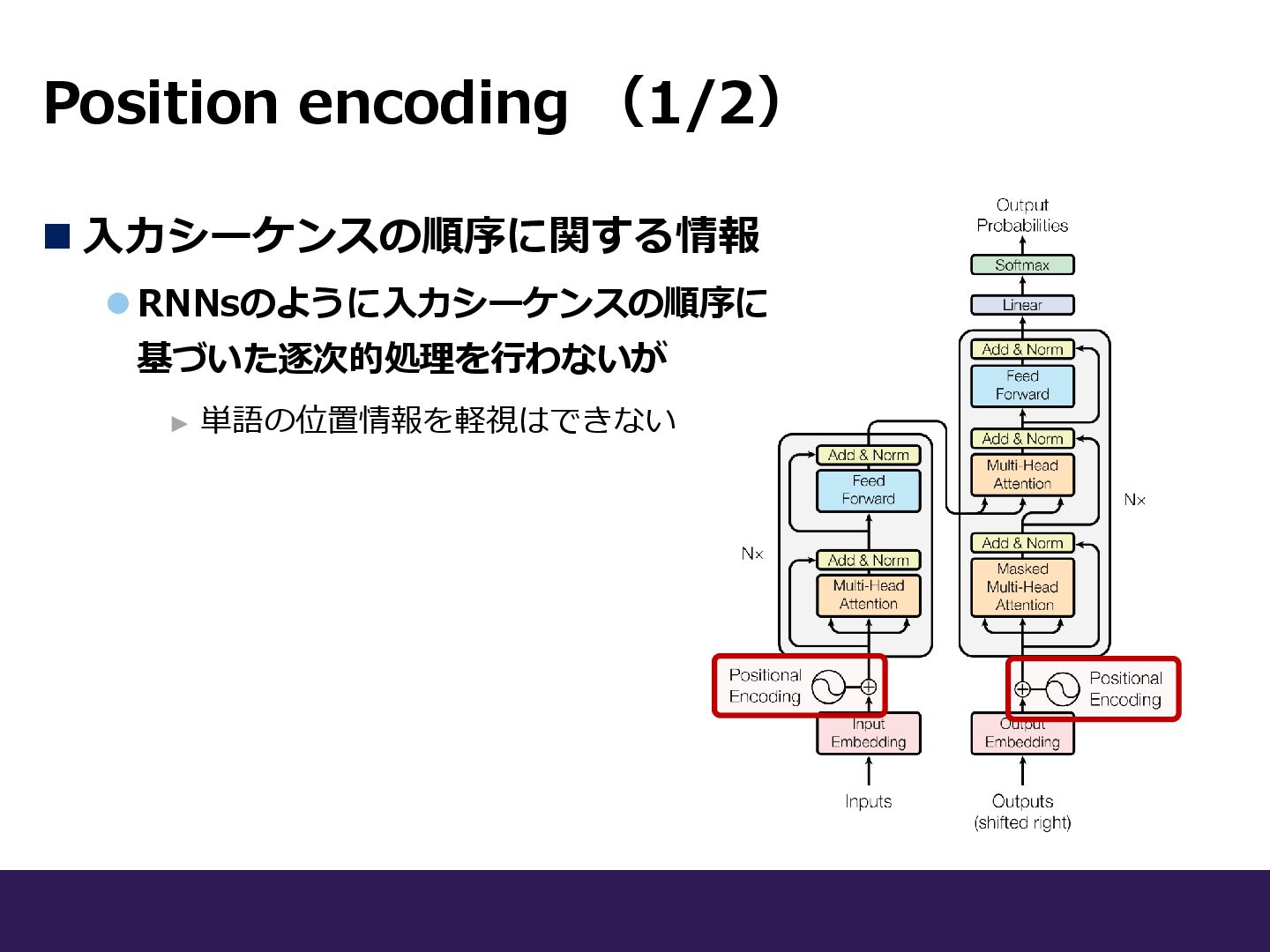
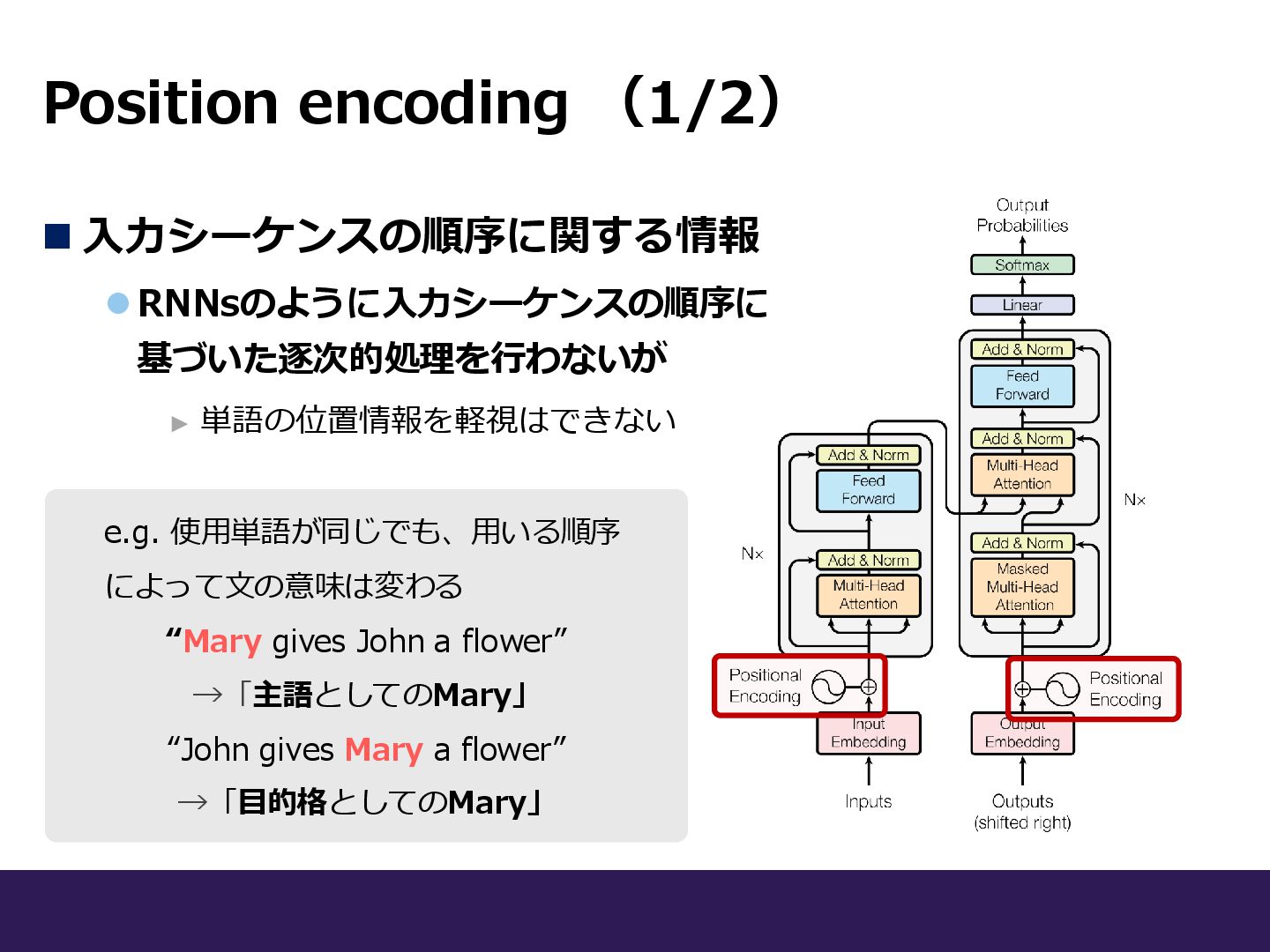
Position encoding (1/2) ◼ 入力シーケンスの順序に関する情報 ⚫RNNsのように入力シーケンスの順序に 基づいた逐次的処理を行わないが ► 単語の位置情報を軽視はできない
Position encoding (1/2) ◼ 入力シーケンスの順序に関する情報 ⚫RNNsのように入力シーケンスの順序に 基づいた逐次的処理を行わないが ► 単語の位置情報を軽視はできない e.g.
使用単語が同じでも、用いる順序 によって文の意味は変わる “Mary gives John a flower” →「主語としてのMary」 “John gives Mary a flower” →「目的格としてのMary」
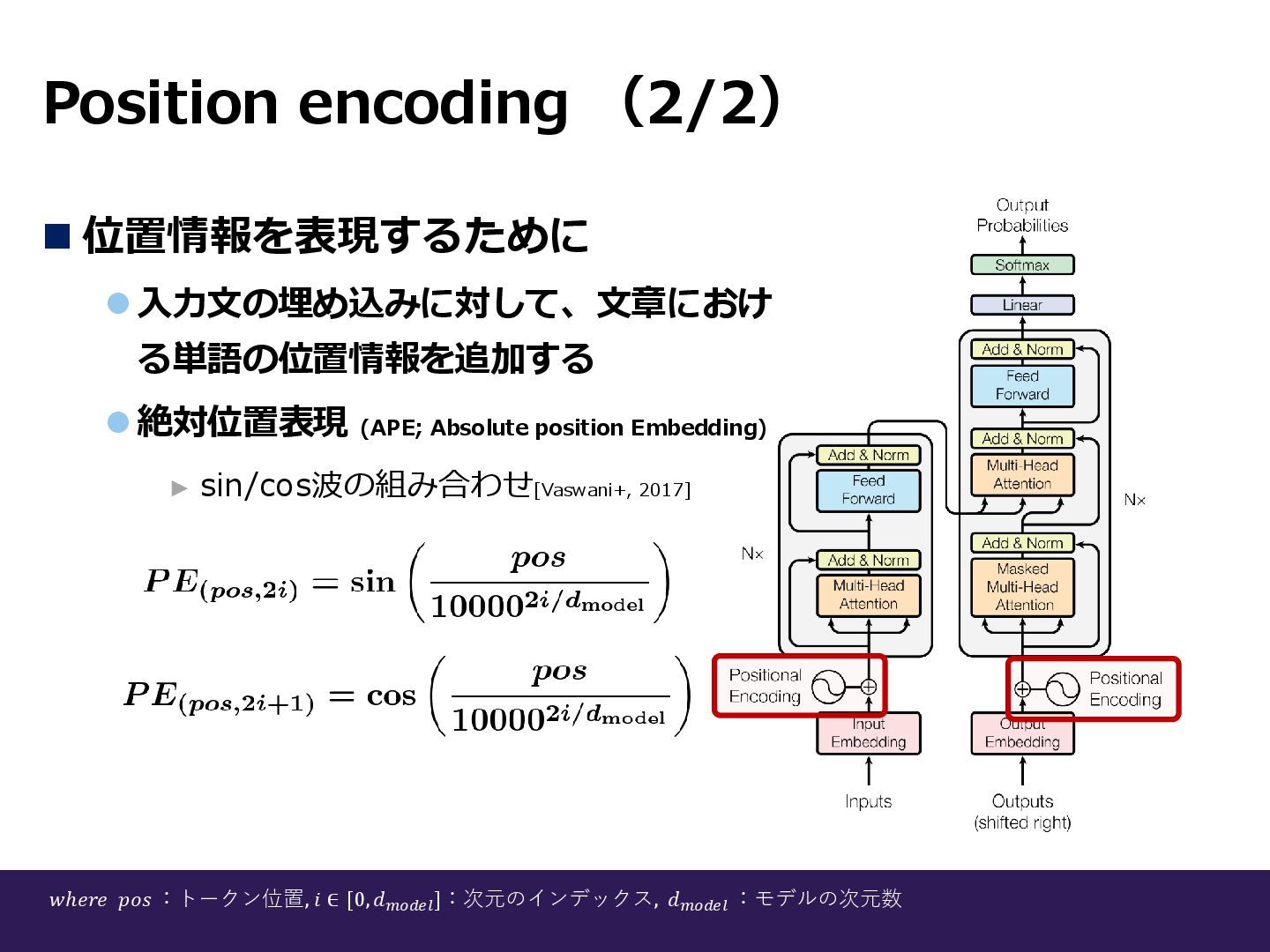
Position encoding (2/2) ◼ 位置情報を表現するために ⚫入力文の埋め込みに対して、文章におけ る単語の位置情報を追加する ⚫絶対位置表現 (APE; Absolute
position Embedding) ► sin/cos波の組み合わせ[Vaswani+, 2017] 𝑤ℎ𝑒𝑟𝑒 𝑝𝑜𝑠 :トークン位置, 𝑖 ∈ [0, 𝑑𝑚𝑜𝑑𝑒𝑙 ]:次元のインデックス, 𝑑𝑚𝑜𝑑𝑒𝑙 :モデルの次元数
𝑤ℎ𝑒𝑟𝑒 𝑝𝑜𝑠 :トークン位置, 𝑖 ∈ [0, 𝑑𝑚𝑜𝑑𝑒𝑙 ]:次元のインデックス, 𝑑𝑚𝑜𝑑𝑒𝑙 :モデルの次元数
補足②:Position encoding • トークン位置:入力系列内の先頭からの位置 • 𝑖 が偶数のときsin関数、𝑖 が奇数のときcos関数 • 10000という値:原論で設定された「想定されうる最長系列長の値」
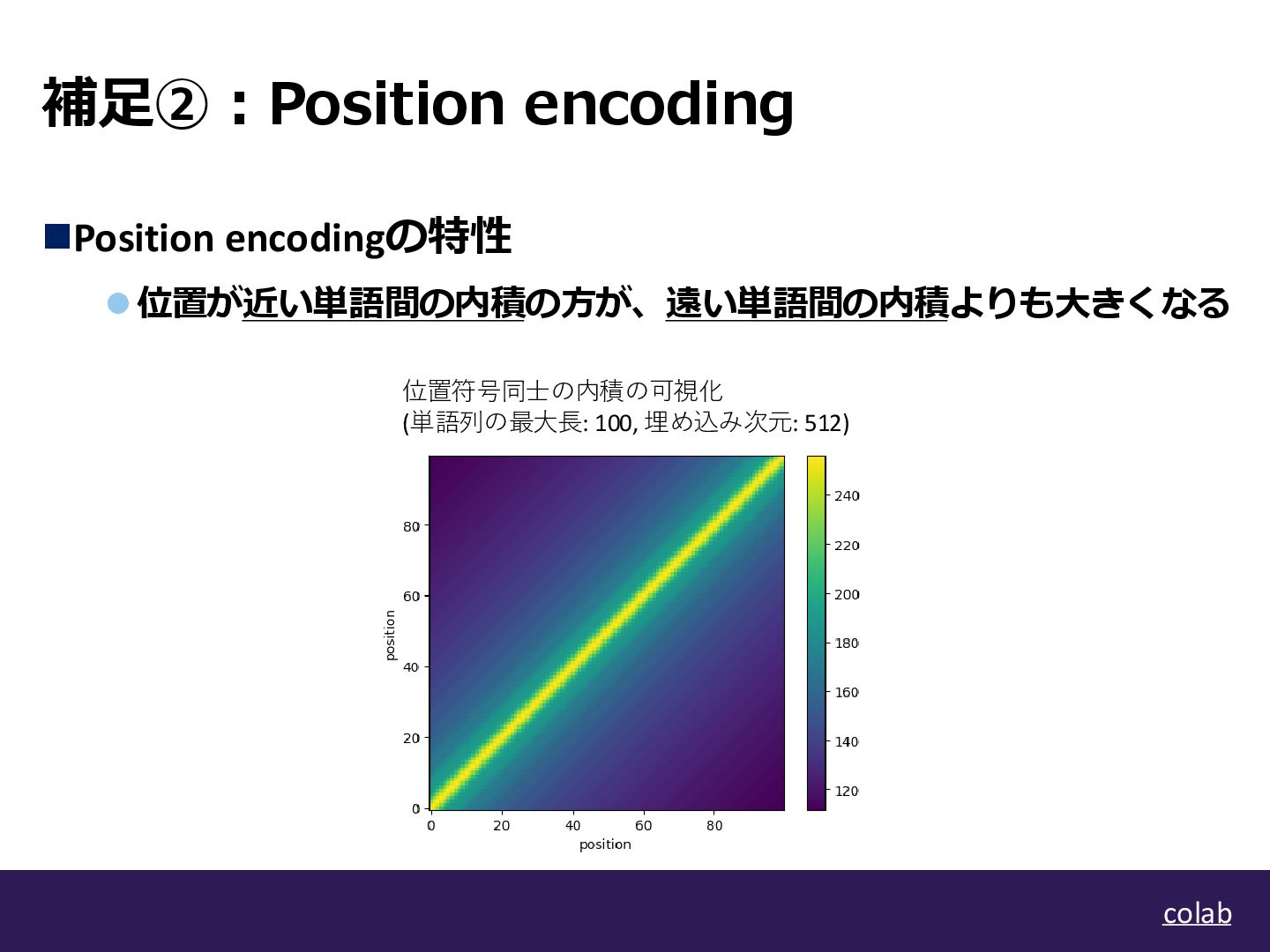
補足②:Position encoding ◼Position encodingの特性 ⚫位置が近い単語間の内積の方が、遠い単語間の内積よりも大きくなる colab 位置符号同士の内積の可視化 (単語列の最大長: 100, 埋め込み次元:
512)
Self-attention ◼ 入力トークン埋め込みに対して文脈情報を付与していく ⚫Query, Key, Valueに基づいて計算されるAttention ► しばしば「key-query-value attention mechanism」と呼ばれる
⚫特に、 Query, Key, Valueがすべて同じであるAttention ► 「Self-attention」と呼ぶ
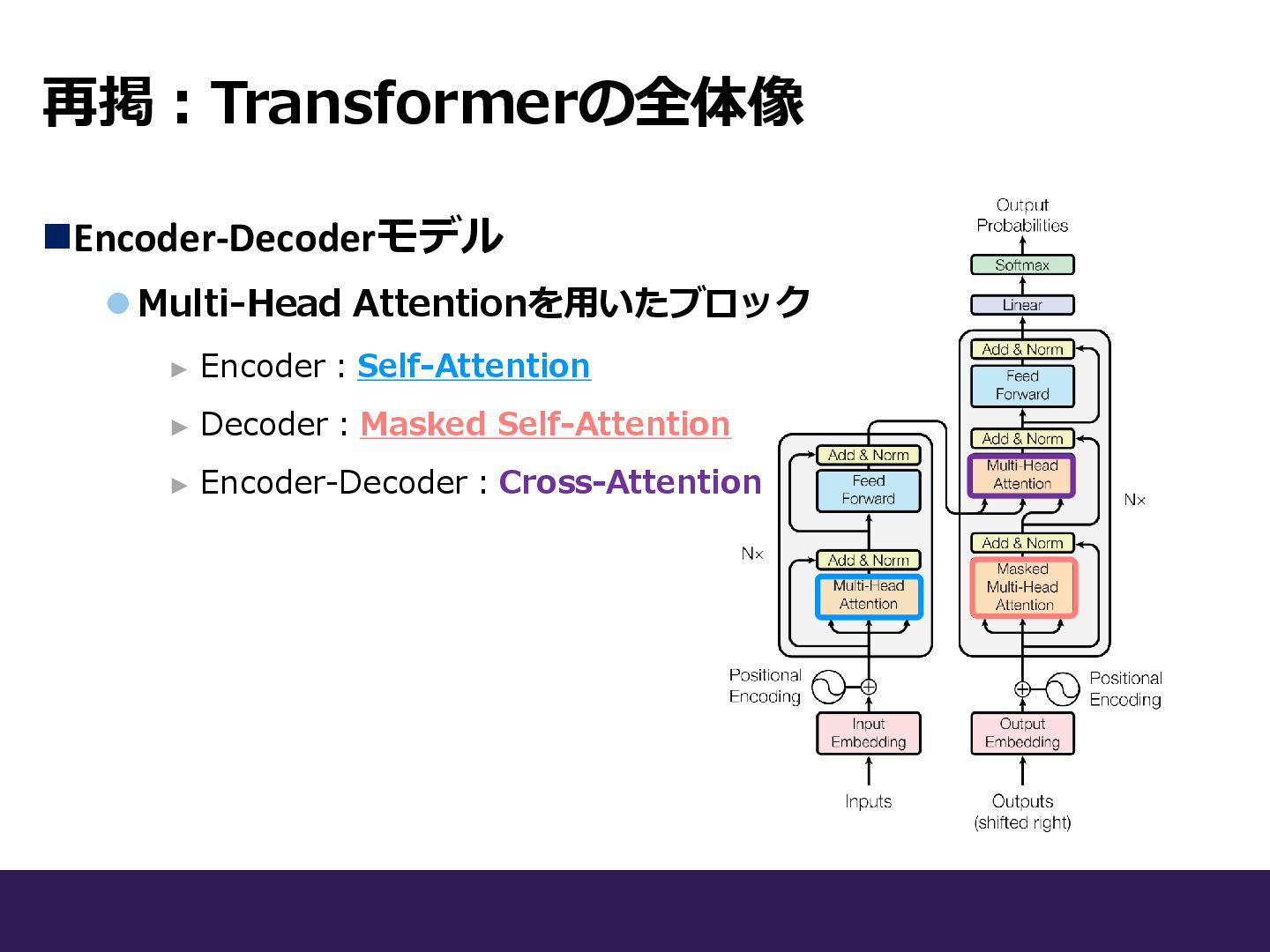
再掲:Transformerの全体像 ◼Encoder-Decoderモデル ⚫Multi-Head Attentionを用いたブロック ► Encoder:Self-Attention ► Decoder:Masked Self-Attention ►
Encoder-Decoder:Cross-Attention
Self-attention(1/6) ◼ 入力トークン埋め込みに対して文脈情報を付与していく ⚫Query, Key, Valueに基づいて計算されるAttention ► しばしば「key-query-value attention mechanism」と呼ばれる
⚫特に、 Query, Key, Valueがすべて同じであるAttention ► 「Self-attention」と呼ぶ ⚫関連性スコアとして, QueryとKeyのドット積(内積)を計算し、 Keyの次元𝒅𝒌 の平方根でスケーリングしたAttention ► Scaled Dot-Product Attention [Vaswani+, 2017]
Self-attention(2/6) ◼ 入力トークン埋め込みに対して文脈情報を付与していく ⚫Scaled Dot-Product Attention [Vaswani+, 2017] 𝑤ℎ𝑒𝑟𝑒 𝑄,
K, 𝑉: それぞれクエリ・キー・ 値の行列, 𝑑𝑘 : キーの次元 1. 内積で各クエリに対する全てのキーの関連性 スコアを計算する+スケーリング 2. ソフトマックス関数で各値の重要度を表す確 率分布(値 V に対する重み)を取得する 3. 重みと値Vの重み付き和によって出力を計算 Step Step Step
Self-attention(3/6) ◼ Step 0. 入力トークン埋め込み行列からQKVへ分割 ⚫ 𝑬𝒊 = 𝒆𝟏 ,
𝒆𝟐 , … , 𝒆|𝑽| ⊤ ∈ ℝ 𝑽 × 𝑫 を得られたとする ► 𝑒𝑖 はd次元のベクトル ⚫ QKVに分割する際、 𝑾𝒒 , 𝑾𝒌 , 𝑾𝒗 重み行列を用いて計算される 𝑸𝒊 = 𝑾𝒒 𝑬𝒊 ( 𝑾𝒒 ∈ ℝ 𝑫 × 𝑫) 𝑲𝒊 = 𝑾𝒌 𝑬𝒊 ( 𝑾𝒌 ∈ ℝ 𝑫 × 𝑫) 𝑽𝒊 = 𝑾𝒗 𝑬𝒊 ( 𝑾𝒗 ∈ ℝ 𝑫 × 𝑫) ► 訓練時に 重み行列の𝑾𝒒 , 𝑾𝒌 , 𝑾𝒗 を最適化することで、重要度を加味した 文脈化ができる
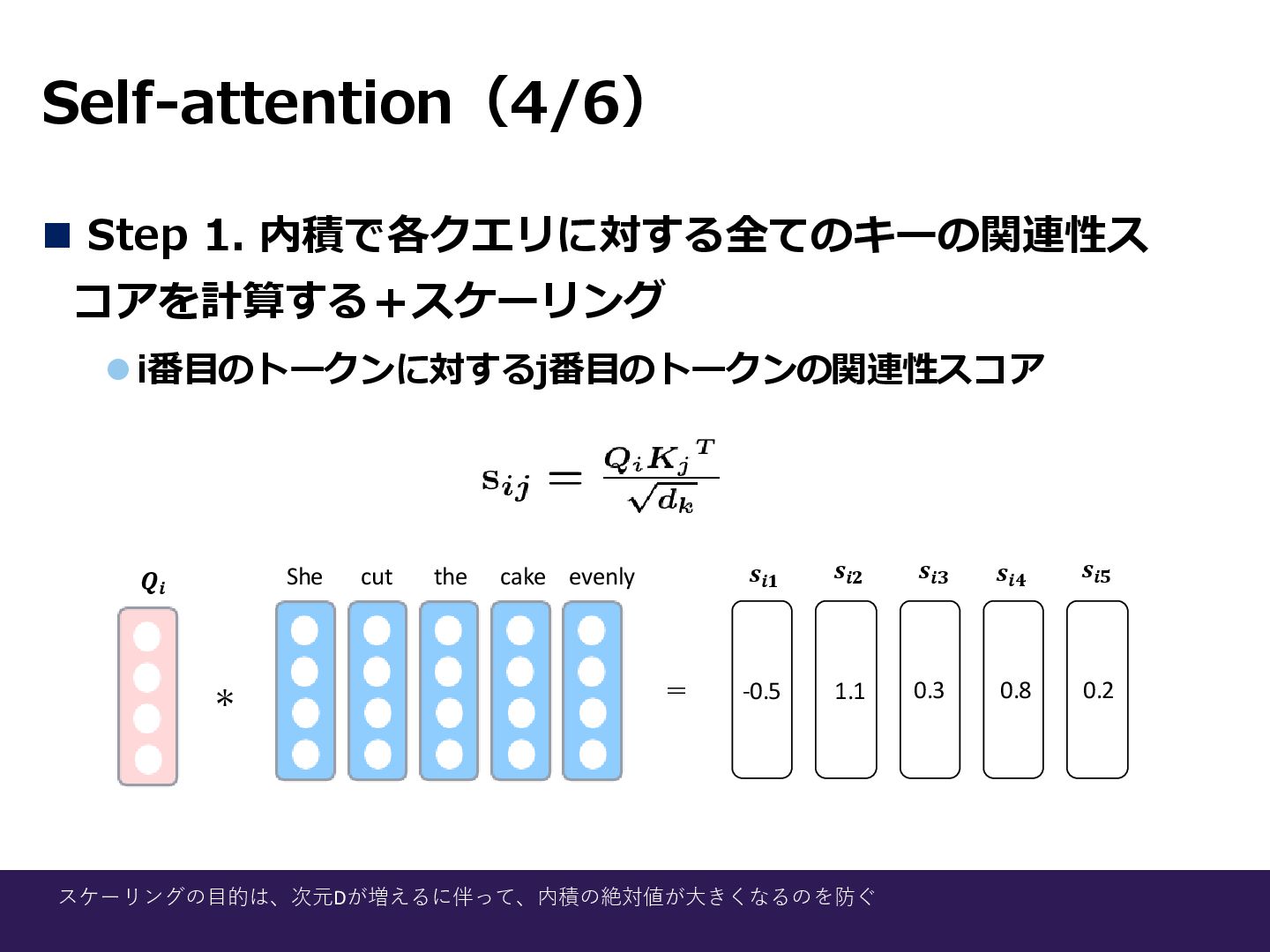
Self-attention(4/6) ◼ Step 1. 内積で各クエリに対する全てのキーの関連性ス コアを計算する+スケーリング ⚫i番目のトークンに対するj番目のトークンの関連性スコア スケーリングの目的は、次元Dが増えるに伴って、内積の絶対値が大きくなるのを防ぐ * =
She cut the cake evenly 𝑸𝒊 𝒔𝒊𝟏 𝒔𝒊𝟐 𝒔𝒊𝟑 𝒔𝒊𝟒 𝒔𝒊𝟓 -0.5 1.1 0.8 0.3 0.2
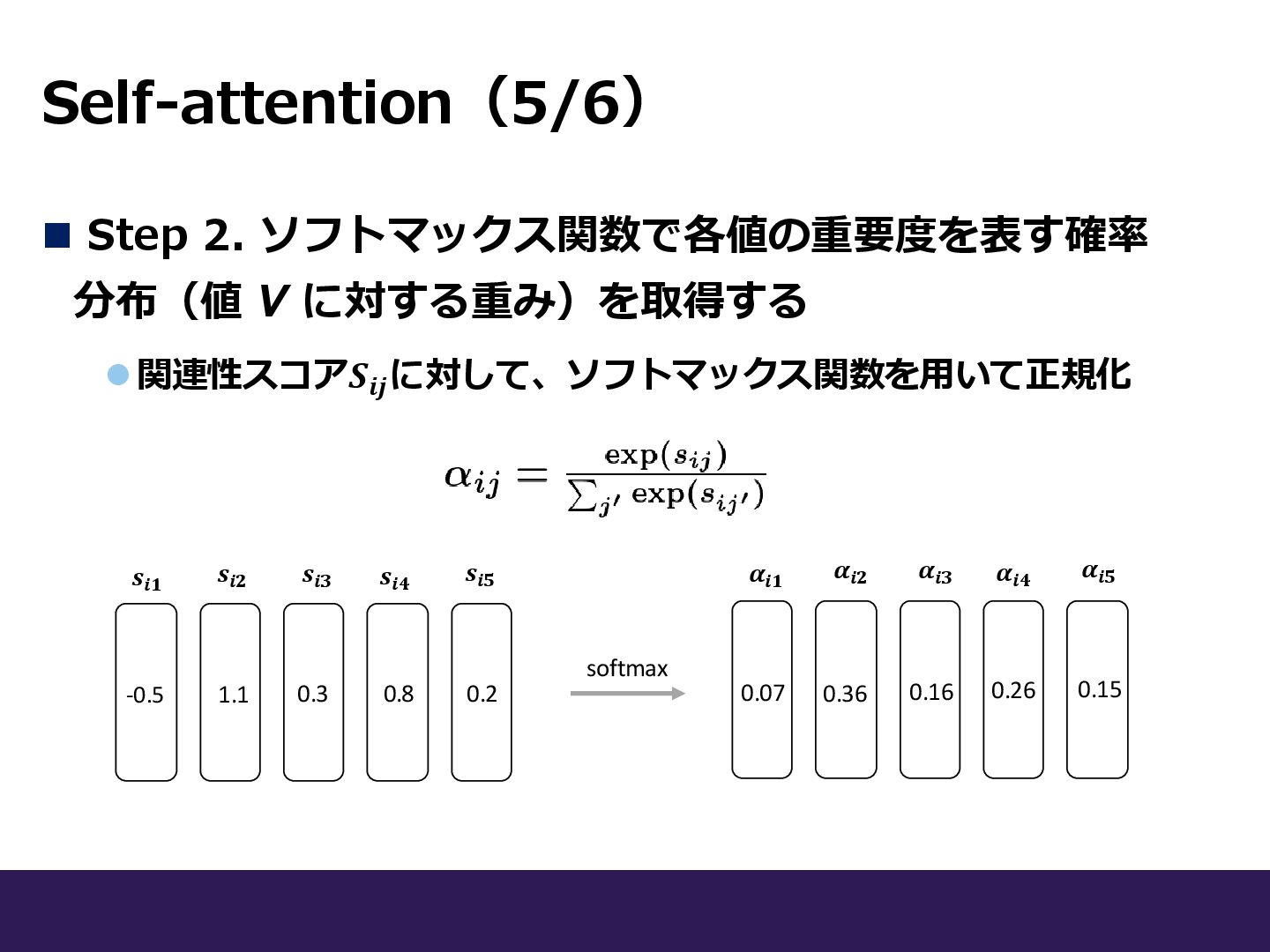
Self-attention(5/6) ◼ Step 2. ソフトマックス関数で各値の重要度を表す確率 分布(値 V に対する重み)を取得する ⚫関連性スコア𝑺𝒊𝒋 に対して、ソフトマックス関数を用いて正規化
softmax 𝒔𝒊𝟏 𝒔𝒊𝟐 𝒔𝒊𝟑 𝒔𝒊𝟒 𝒔𝒊𝟓 -0.5 1.1 0.8 0.3 0.2 𝜶𝒊𝟏 𝜶𝒊𝟐 𝜶𝒊𝟑 𝜶𝒊𝟒 𝜶𝒊𝟓 0.36 0.26 0.16 0.15 0.07
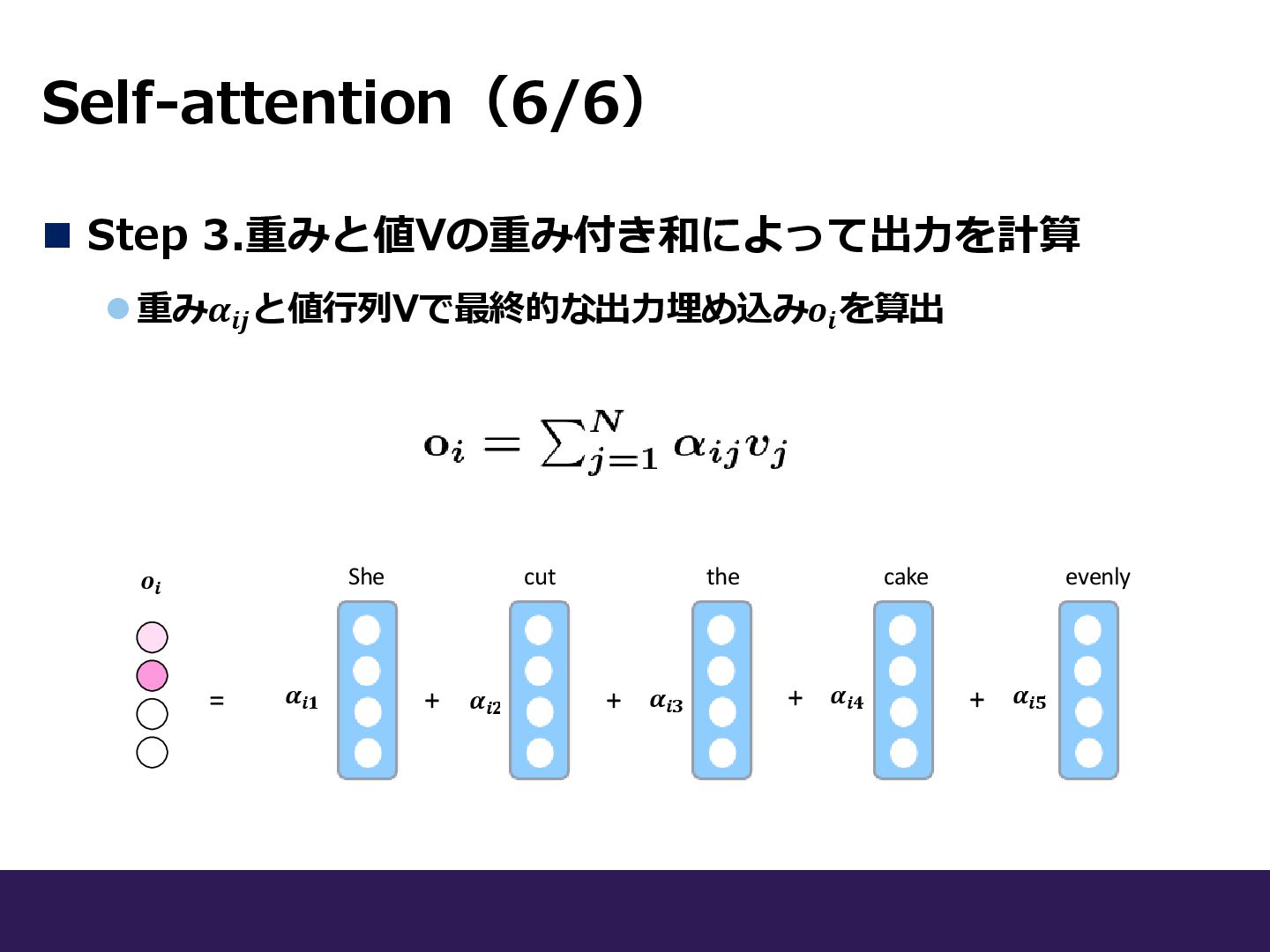
Self-attention(6/6) ◼ Step 3.重みと値Vの重み付き和によって出力を計算 ⚫重み𝜶𝒊𝒋 と値行列Vで最終的な出力埋め込み𝒐𝒊 を算出 = 𝒐𝒊 𝜶𝒊𝟏
𝜶𝒊𝟐 𝜶𝒊𝟑 𝜶𝒊𝟒 𝜶𝒊𝟓 She cut the cake evenly + + + +
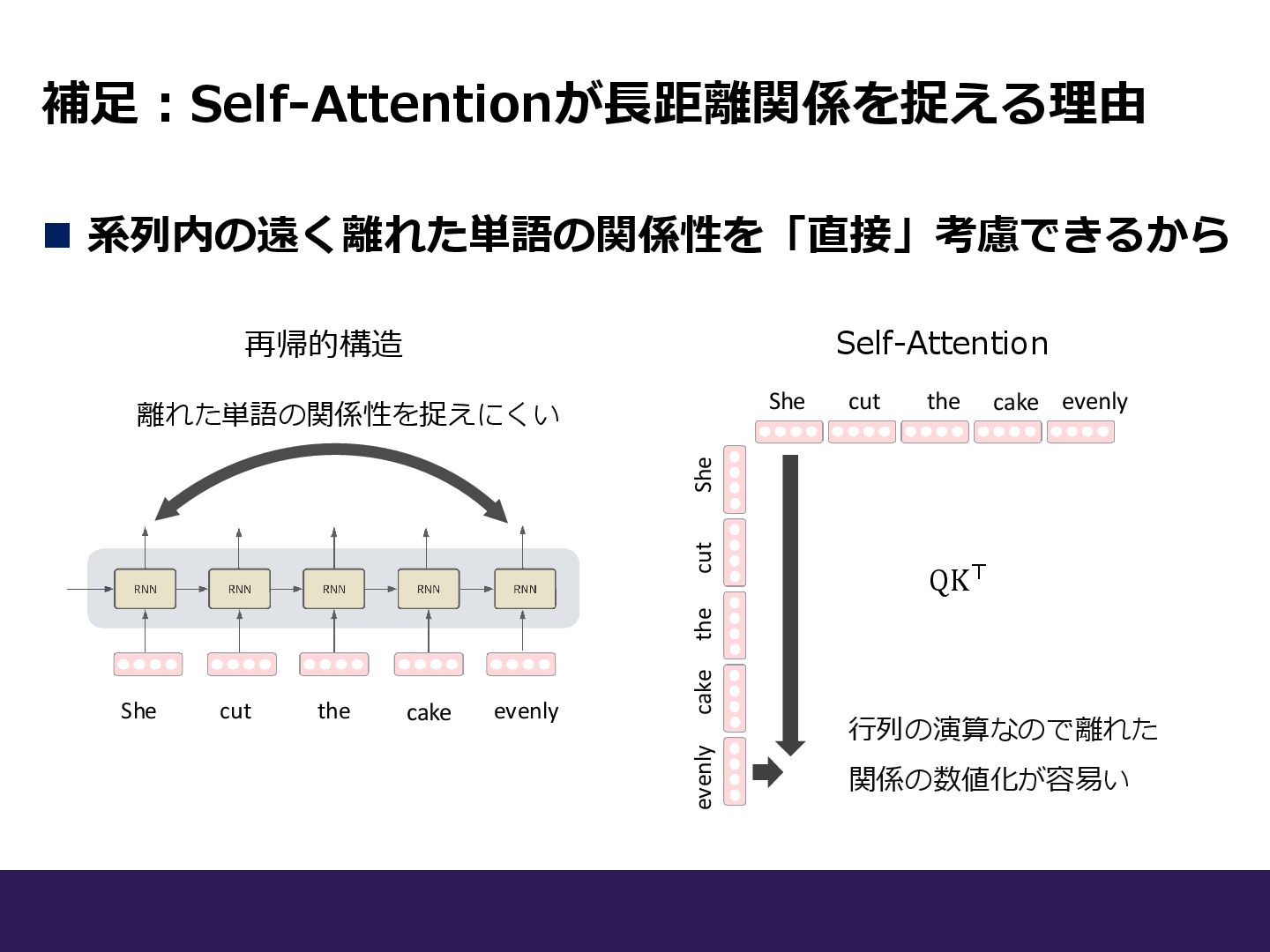
補足:Self-Attentionが長距離関係を捉える理由 ◼ 系列内の遠く離れた単語の関係性を「直接」考慮できるから 再帰的構造 Self-Attention QK⊤ 離れた単語の関係性を捉えにくい She cut the
cake evenly She cut the cake evenly She cut the cake evenly 行列の演算なので離れた 関係の数値化が容易い
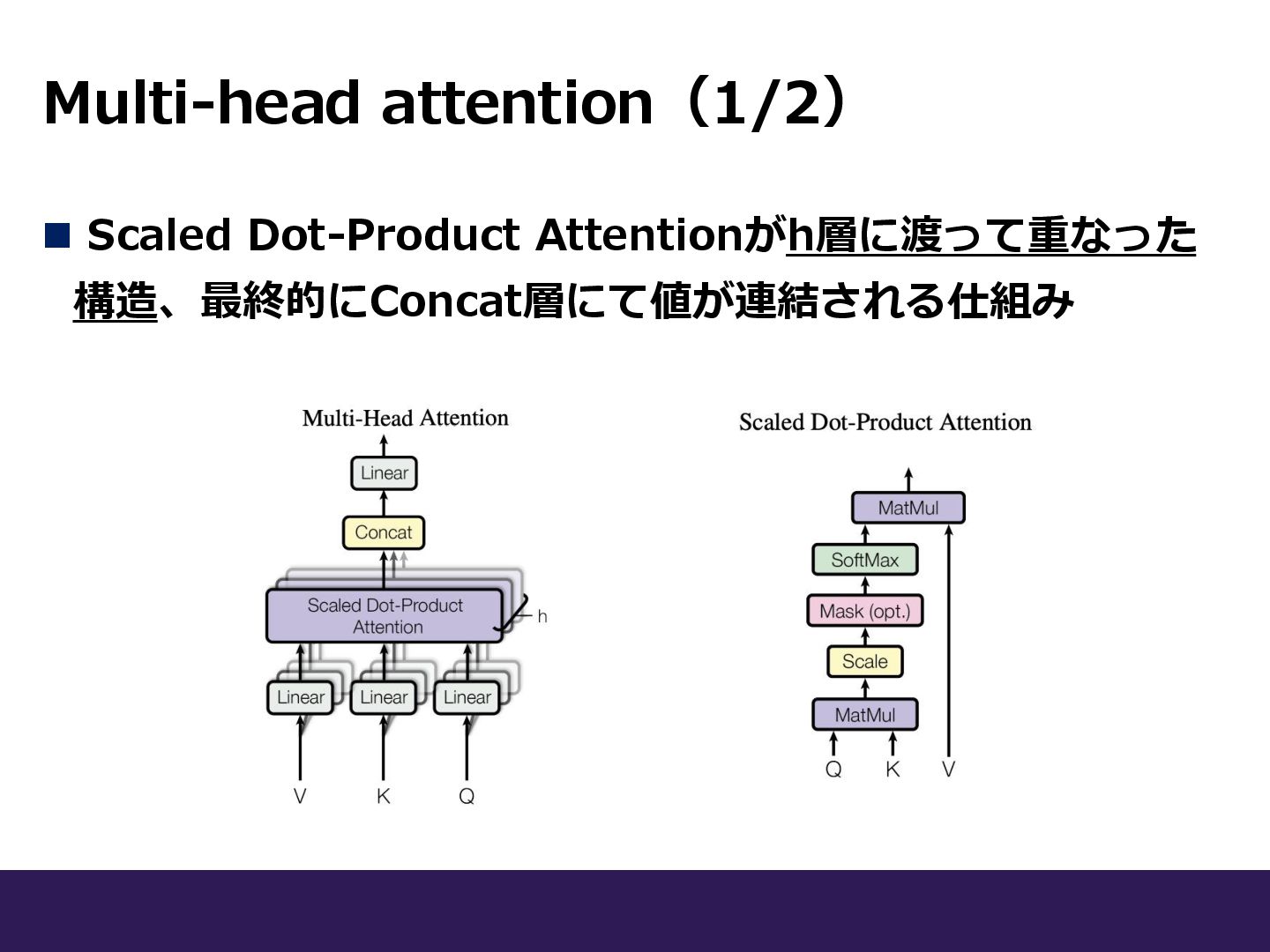
Multi-head attention(1/2) ◼ Scaled Dot-Product Attentionがh層に渡って重なった 構造、最終的にConcat層にて値が連結される仕組み
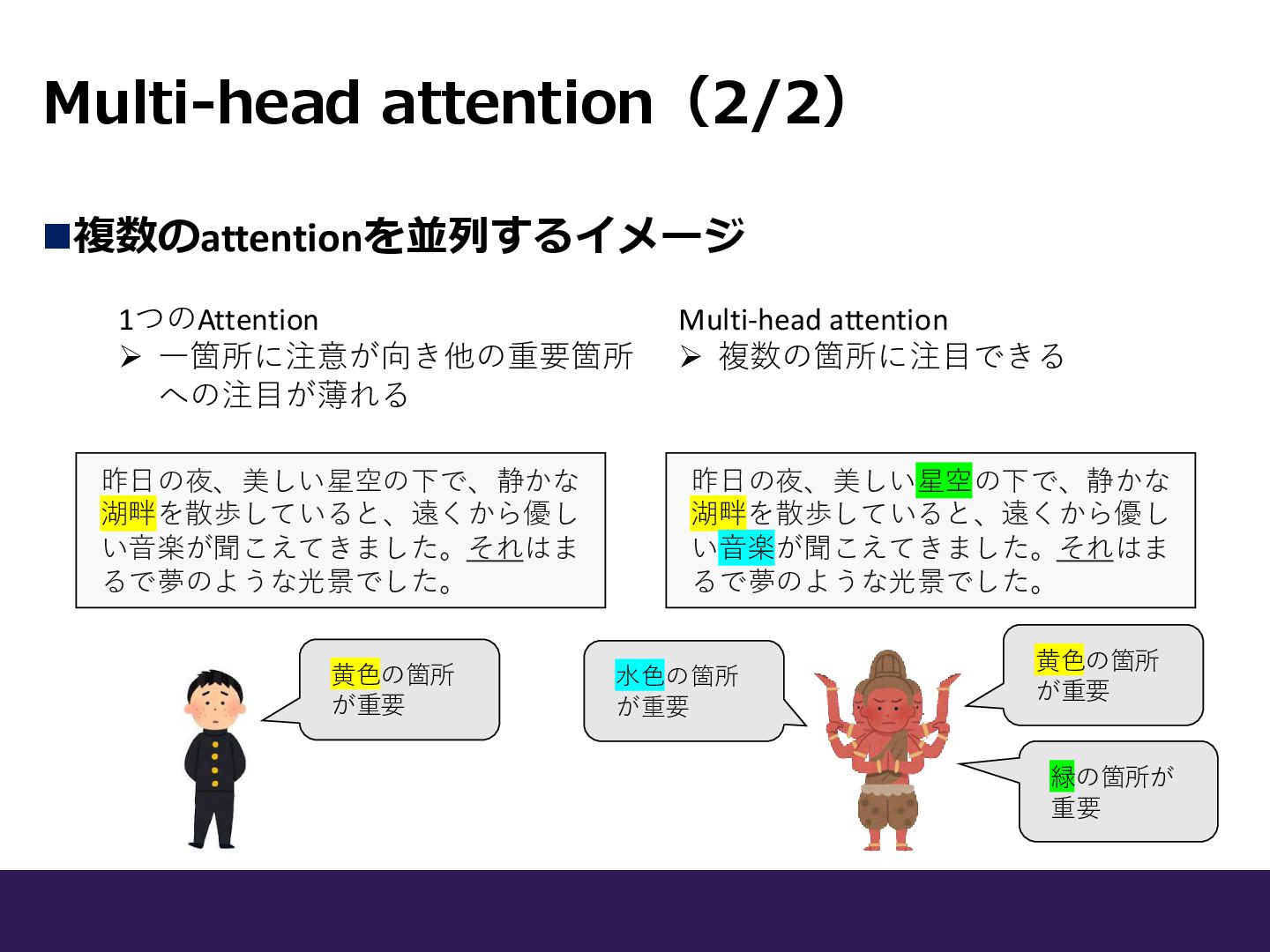
Multi-head attention(2/2) ◼複数のattentionを並列するイメージ 1つのAttention ➢ 一箇所に注意が向き他の重要箇所 への注目が薄れる Multi-head attention ➢
複数の箇所に注目できる 昨日の夜、美しい星空の下で、静かな 湖畔を散歩していると、遠くから優し い音楽が聞こえてきました。それはま るで夢のような光景でした。 昨日の夜、美しい星空の下で、静かな 湖畔を散歩していると、遠くから優し い音楽が聞こえてきました。それはま るで夢のような光景でした。 黄色の箇所 が重要 黄色の箇所 が重要 緑の箇所が 重要 水色の箇所 が重要
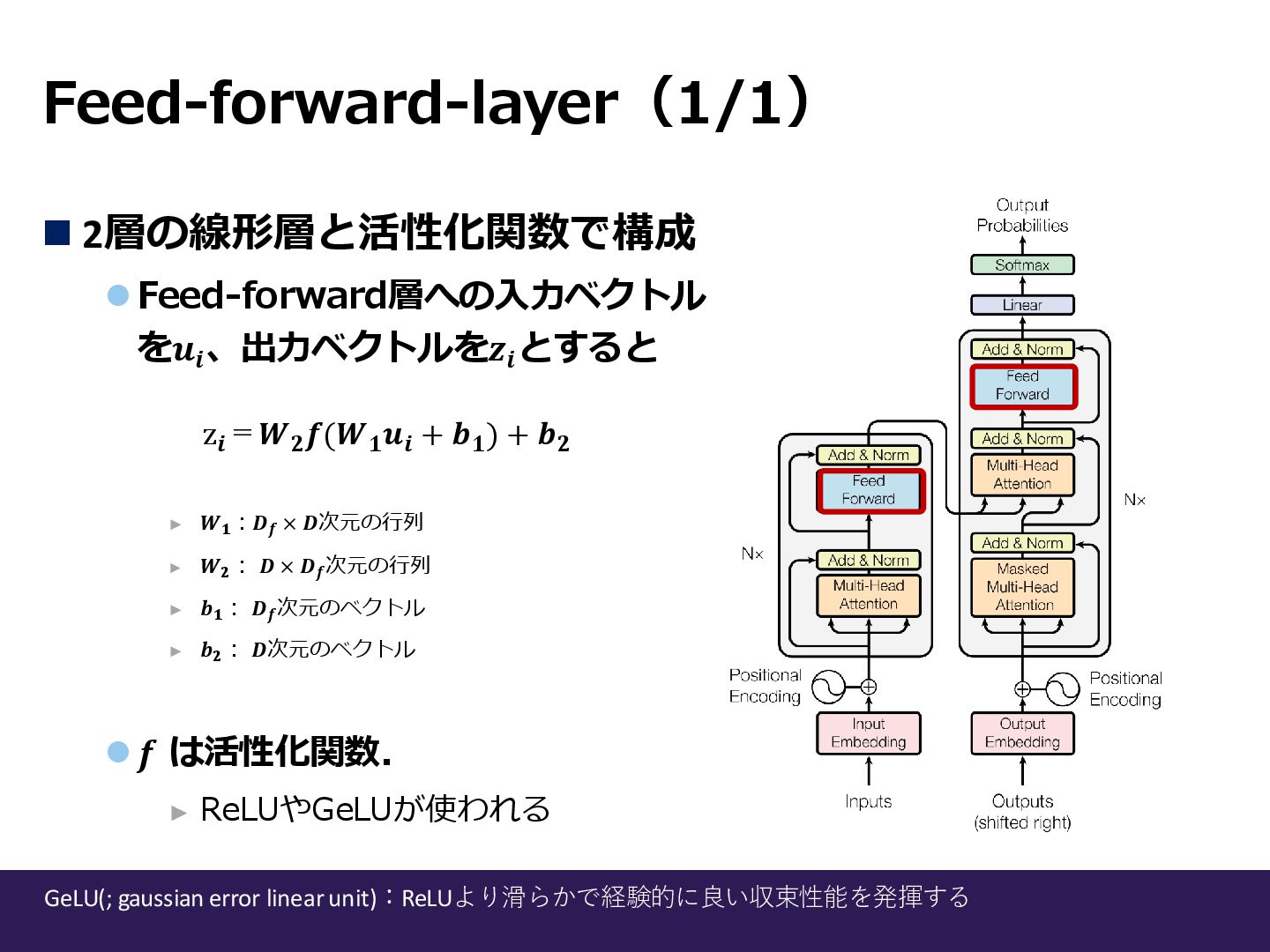
Feed-forward-layer(1/1) ◼ 2層の線形層と活性化関数で構成 ⚫Feed-forward層への入力ベクトル を𝒖𝒊 、出力ベクトルを𝒛𝒊 とすると ► 𝑾𝟏 :𝑫𝒇
× 𝑫次元の行列 ► 𝑾𝟐 : 𝑫 × 𝑫𝒇 次元の行列 ► 𝒃𝟏 : 𝑫𝒇 次元のベクトル ► 𝒃𝟐 : 𝑫次元のベクトル ⚫𝒇 は活性化関数. ► ReLUやGeLUが使われる z𝒊 =𝑾𝟐 𝒇(𝑾𝟏 𝒖𝒊 + 𝒃𝟏 ) + 𝒃𝟐 GeLU(; gaussian error linear unit):ReLUより滑らかで経験的に良い収束性能を発揮する
Residual connection(1/1) ◼ResNet[He+, CVPR’16]で提案された手法 ⚫勾配消失を防ぐのに非常に有効 ⚫入力に近い層にまで勾配が十分に伝搬されるようになる ◼Transformerでは、Attention機構, FFN層の箇所に配置 ⚫K番目の層への入力ベクトル列を𝑿(𝒌) =
𝒙 𝟏 𝒌 , 𝒙 𝟐 𝒌 , … , 𝒙 𝑵 𝒌 ⊤ とすると 残差結合を適用した出力は以下のように表せる。 𝑿(𝒌+𝟏) = 𝓕 𝑿 𝒌 + 𝑿 𝒌
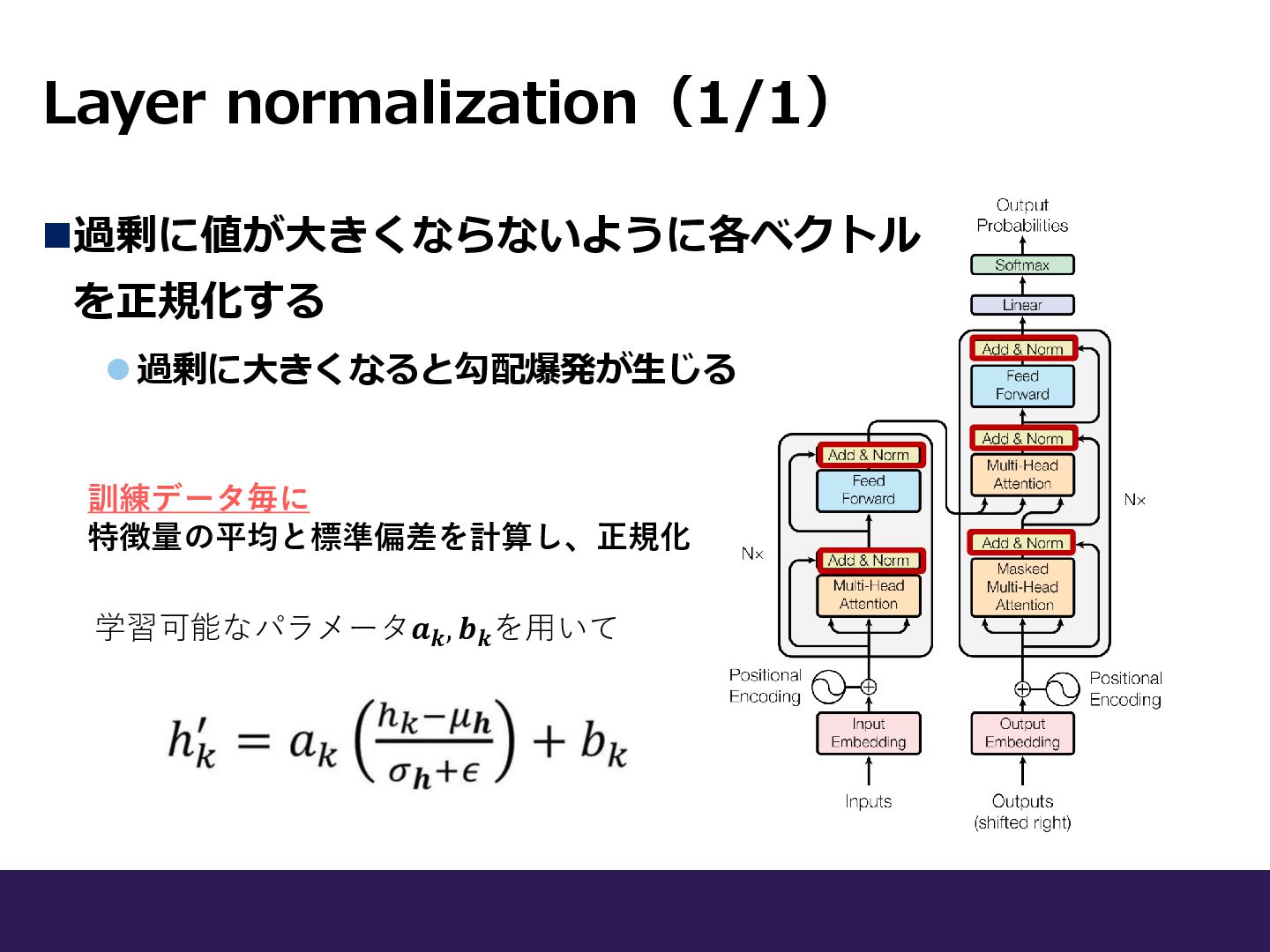
Layer normalization(1/1) ◼過剰に値が大きくならないように各ベクトル を正規化する ⚫過剰に大きくなると勾配爆発が生じる 訓練データ毎に 特徴量の平均と標準偏差を計算し、正規化 学習可能なパラメータ𝒂𝒌 , 𝒃𝒌
を用いて
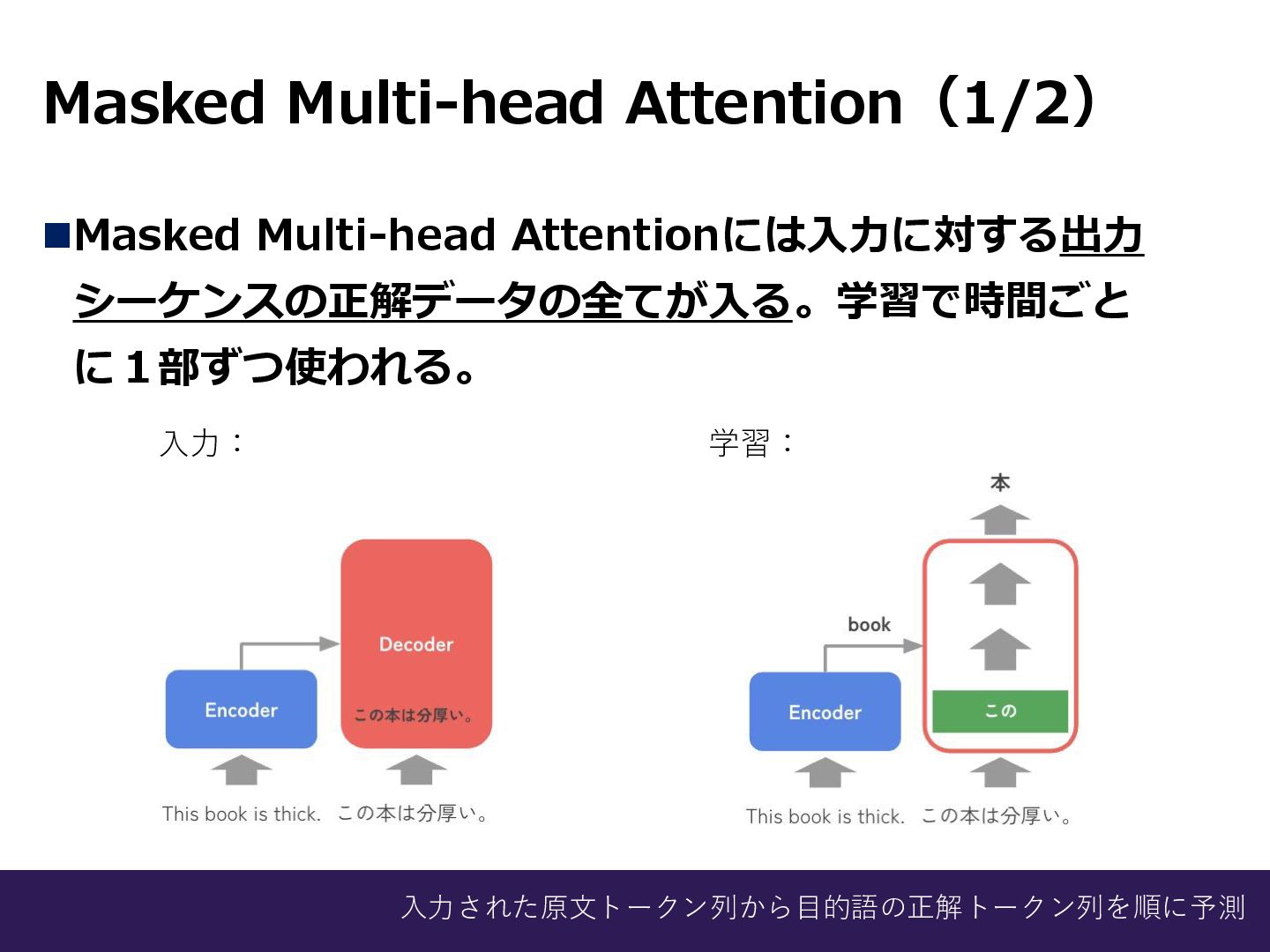
Masked Multi-head Attention(1/2) ◼Masked Multi-head Attentionには入力に対する出力 シーケンスの正解データの全てが入る。学習で時間ごと に1部ずつ使われる。 入力: 学習:
入力された原文トークン列から目的語の正解トークン列を順に予測
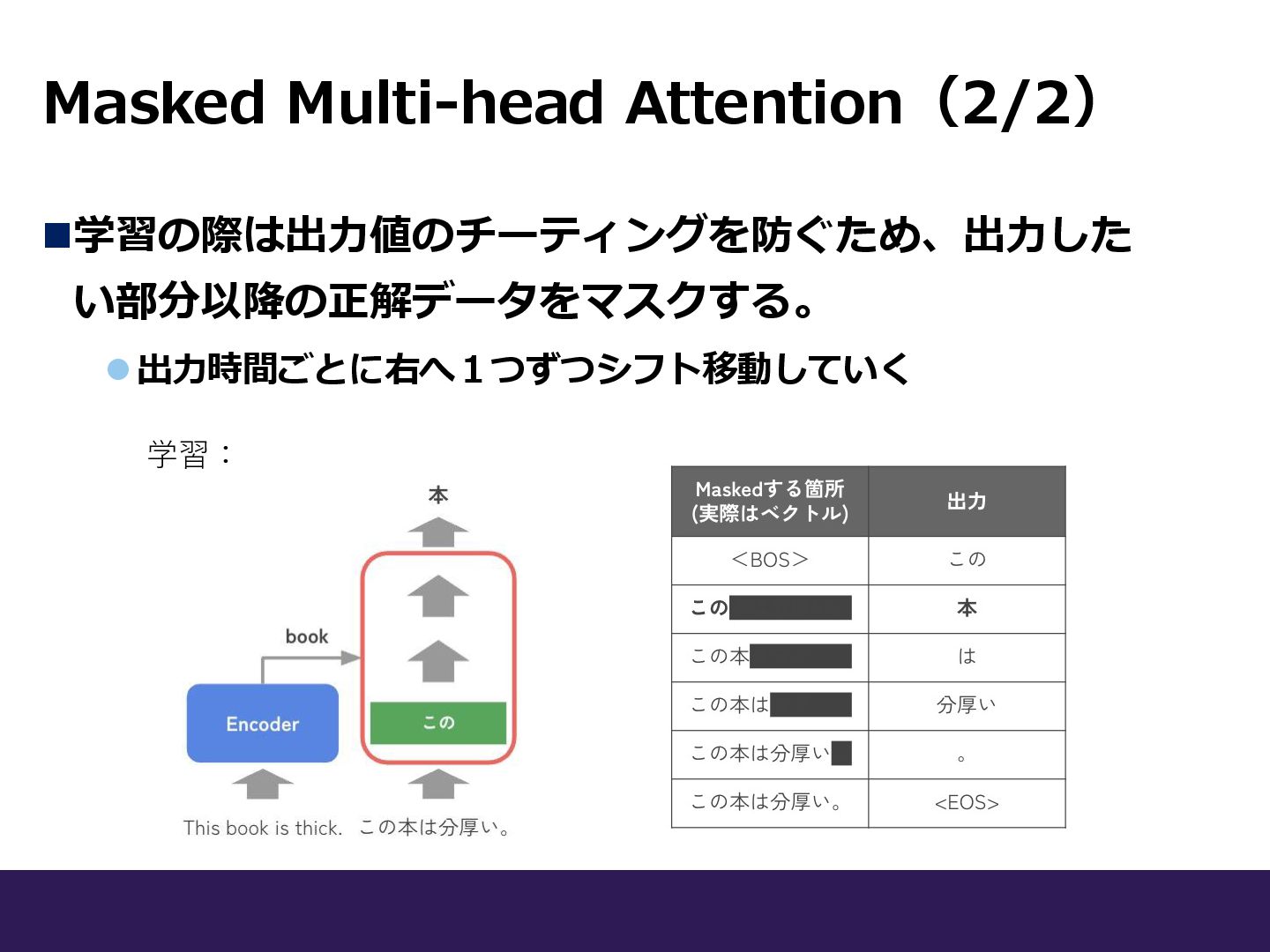
Masked Multi-head Attention(2/2) ◼学習の際は出力値のチーティングを防ぐため、出力した い部分以降の正解データをマスクする。 ⚫出力時間ごとに右へ1つずつシフト移動していく 学習:
Cross-attention ◼ QueryがDecoderからのベクトル、Key/Valueが Encoderからのベクトルとなるだけで、計算方法はこれ までと同じ 𝑸𝒊 = 𝑾𝒒 𝑬𝒊 (
𝑾𝒒 ∈ ℝ 𝑫 × 𝑫) … Decoder内のベクトル 𝑲𝒊 = 𝑾𝒌 𝑬𝒊 ( 𝑾𝒒 ∈ ℝ 𝑫 × 𝑫) … Encoder内のベクトル 𝑽𝒊 = 𝑾𝒗 𝑬𝒊 ( 𝑾𝒒 ∈ ℝ 𝑫 × 𝑫) … Encoder内のベクトル
総括 ◼ 概要 ⚫ Transformerは、RNNやLSTMの逐次処理の限界(並列化の難しさ、長期依存の 捕捉の難易度)を克服するため、2017年にVaswani et al.により提案。 ⚫ スケーラブルで、BERTやGPTなどの大規模モデルを生み出し、AIの進化を加速。
◼全体像のポイント ⚫ 入力処理: ► 入力トークン埋め込みとPosition Encodingにより、シーケンスの位置情報を追加。 ⚫ コアメカニズム: ► AttentionとMulti-Head Attentionで重要な部分に焦点を当て、複数の視点から特徴を 捉える。 ► Masked Multi-Head Attentionで未来情報をマスク、Cross-AttentionでEncoder- Decoder間の情報共有。 ⚫ 追加レイヤー: ► Feed-Forward Layerで非線形変換、Residual ConnectionとLayer Normalizationで 学習の安定化、Dropoutで過学習防止。
Appendix.
{kind=link}
{kind=link}
{kind=link}
![Transformerとは ◼ Attention Is All You Need? ⚫Googleの研究チーム[Vaswani+, 2017]が機械翻訳タスクのモデル として「Transformer」を提案](https://files.speakerdeck.com/presentations/05b44f5ace4b49c68849e98798ba904a/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![𝑤ℎ𝑒𝑟𝑒 𝑝𝑜𝑠 :トークン位置, 𝑖 ∈ [0, 𝑑𝑚𝑜𝑑𝑒𝑙 ]:次元のインデックス, 𝑑𝑚𝑜𝑑𝑒𝑙 :モデルの次元数](https://files.speakerdeck.com/presentations/05b44f5ace4b49c68849e98798ba904a/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Self-attention(2/6) ◼ 入力トークン埋め込みに対して文脈情報を付与していく ⚫Scaled Dot-Product Attention [Vaswani+, 2017] 𝑤ℎ𝑒𝑟𝑒 𝑄,](https://files.speakerdeck.com/presentations/05b44f5ace4b49c68849e98798ba904a/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Residual connection(1/1) ◼ResNet[He+, CVPR’16]で提案された手法 ⚫勾配消失を防ぐのに非常に有効 ⚫入力に近い層にまで勾配が十分に伝搬されるようになる ◼Transformerでは、Attention機構, FFN層の箇所に配置 ⚫K番目の層への入力ベクトル列を𝑿(𝒌) =](https://files.speakerdeck.com/presentations/05b44f5ace4b49c68849e98798ba904a/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}