Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
機械学習どこから手をつけよう? Google DevFest 2018 Tokyo
Search
Kazusa
September 01, 2018
Technology
1.4k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
機械学習どこから手をつけよう? Google DevFest 2018 Tokyo
Google DevFest 2018 Tokyo (
https://tokyo2018.gdgjapan.org/ml
)
Kazusa
September 01, 2018
More Decks by Kazusa
See All by Kazusa
20190208_MLSE_NeurIPS2018_tkazusa.pdf
tkazusa
1
820
受託分析屋がKubeflowを使って思うこと_KubeflowMeetup_1.pdf
tkazusa
2
2.5k
機械学習システム開発及び運用にかかる 不確実を考慮した要件定義の考察および提案
tkazusa
0
370
【論文読み】GCVAE-GAN Fine-Grained Image Generation through Asymmetric Training
tkazusa
0
150
【論文読み】Graph Convolutional Networks for Classification with a Structured
tkazusa
0
75
Other Decks in Technology
See All in Technology
「待ち時間」の消滅と「自我消耗」の加速:生成AI時代のエンジニアを救うメンタル・リソース管理
poropinai1966
0
160
セキュリティ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
4
3.1k
そのドキュメント、自動化しませんか?
yuksew
1
440
reFACToring
moznion
0
340
AI時代のPlaywright活用(システムテストを自動化する ー 実行エンジンにPla ywrightを選んだ理由)
ynisqa1988
2
1k
書籍セキュアAPIについて
riiimparm
0
330
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
450
インシデント事例と パッケージの全量解析に学ぶ ソフトウェアサプライチェーンの守り方 / supply-chain-attack-defense
flatt_security
0
1.1k
AI時代の開発生産性を捉え直す — 経営と現場をつなぐ「開発組織のオブザーバビリティ」— / AI Dev Ex Conference 2026
tkyowa
1
1.6k
副作用のある Lambda でも Lambda Power Tuning は使えるのか / lambda-power-tuning-side-effects
koukihosaka
2
150
文字起こし基盤の信頼性
abnoumaru
0
130
CloudWatchから始めるAWS監視
butadora
0
170
Featured
See All Featured
Building the Perfect Custom Keyboard
takai
2
820
KATA
mclloyd
PRO
35
15k
エンジニアに許された特別な時間の終わり
watany
108
250k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
560
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
The World Runs on Bad Software
bkeepers
PRO
72
12k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
How to Talk to Developers About Accessibility
jct
2
440
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
64
56k
It's Worth the Effort
3n
188
29k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Transcript
機械学習どこから 手をつけよう? 2018/9/1 Google DevFest 2018 Tokyo
自己紹介 • 上総 虎智 Taketoshi Kazusa • Github: tkazusa /
Twitter: @tkazusa • BrainPad Inc. 分析官 • 最近の興味範囲 機械学習システムの継続的デプロイ
このセッションで話すこと ✕:機械学習とはなにか ✕:アルゴリズムそのものの話 ✕:機械学習のフレームワークについて ✕:機械学習サービスの使い方について ◯:機械学習使った「手元で動く何か」を作るまでの考え方 ◯:機械学習アプリのプロトタイプを作るために便利なものの整理 ◯:プロトタイプを作った後の話を少し
Agenda • 機械学習で今何ができるんだっけ • 実際どこから手をつければいいんだろう • ちゃんとプロダクトに仕上げるために • まとめ
機械学習で今何ができるんだっけ
Solving problems with AI for everyone
自動運転での活用:Waymo
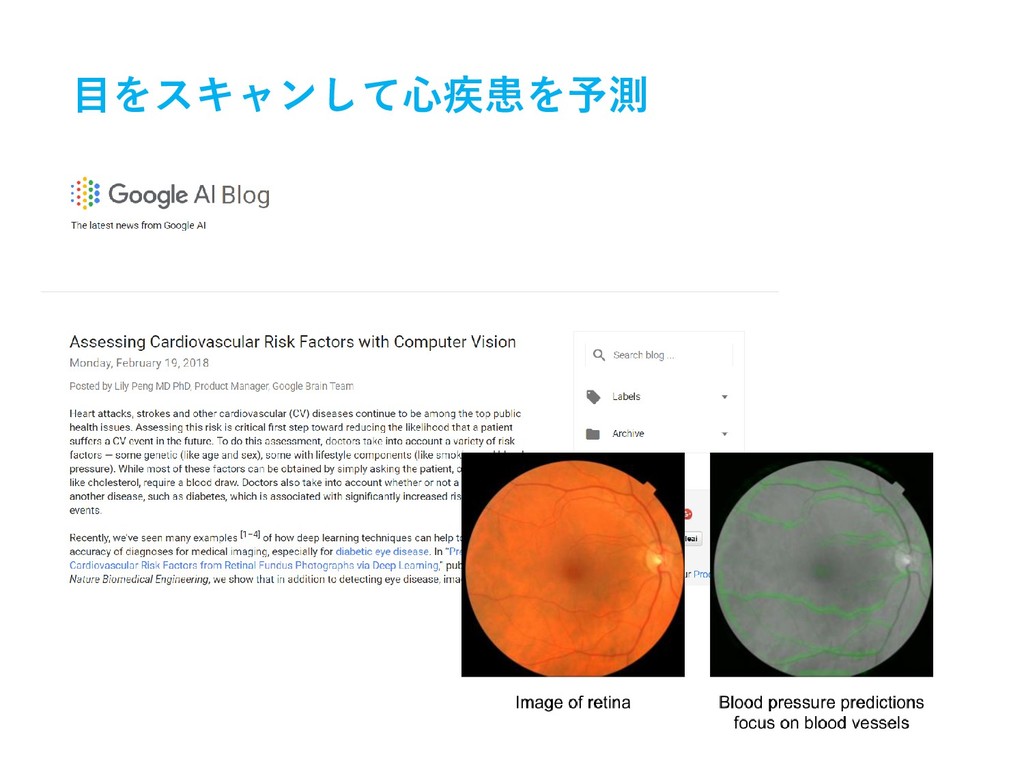
目をスキャンして心疾患を予測
Google Glassでスマートファクトリー AI on Google Glass Drives the Factory to
the Future (Cloud Next '18) https://www.youtube.com/watch?v=yL-LXKrpcvE&feature=
機械学習どこから手を付けよう
さっさと プロトタイプ つくっちゃおう
プロトタイプから作っちゃいましょう • 機械学習はどこまでも“やってみないとわからない”がつきまとう • プロトタイプを作る難易度は圧倒的に下がってきている • 実際に使えるプロダクトにするのは結構距離がある プロトタイプ作ってみて、取り組む価値のあるものだと思ったら プロダクトに仕上げて行くので良いのでは?!
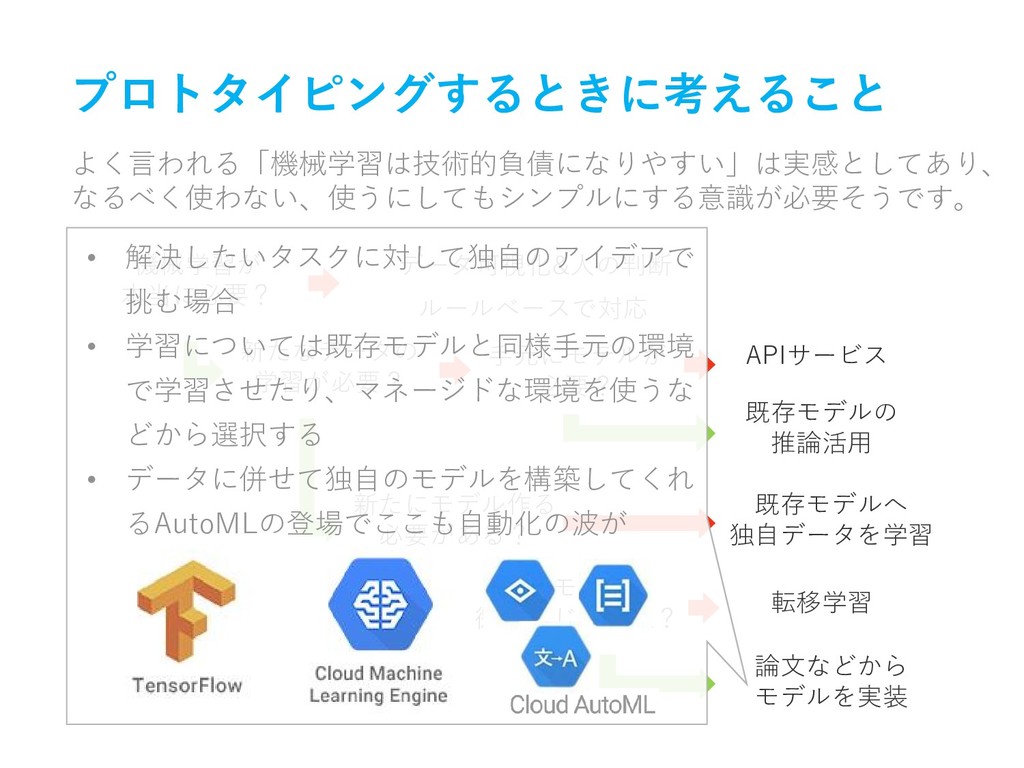
プロトタイピングするときに考えること • 機械学習モデルの学習・実装 「どれだけ楽できるか」、「どれだけシンプルにできるか」 • 学習済モデルのデプロイ先 どこにあるリソースとデータで推論を実行するか? まずは「いったん動くものを作ってみる」という観点では下記を検 討すれば良いと思います。
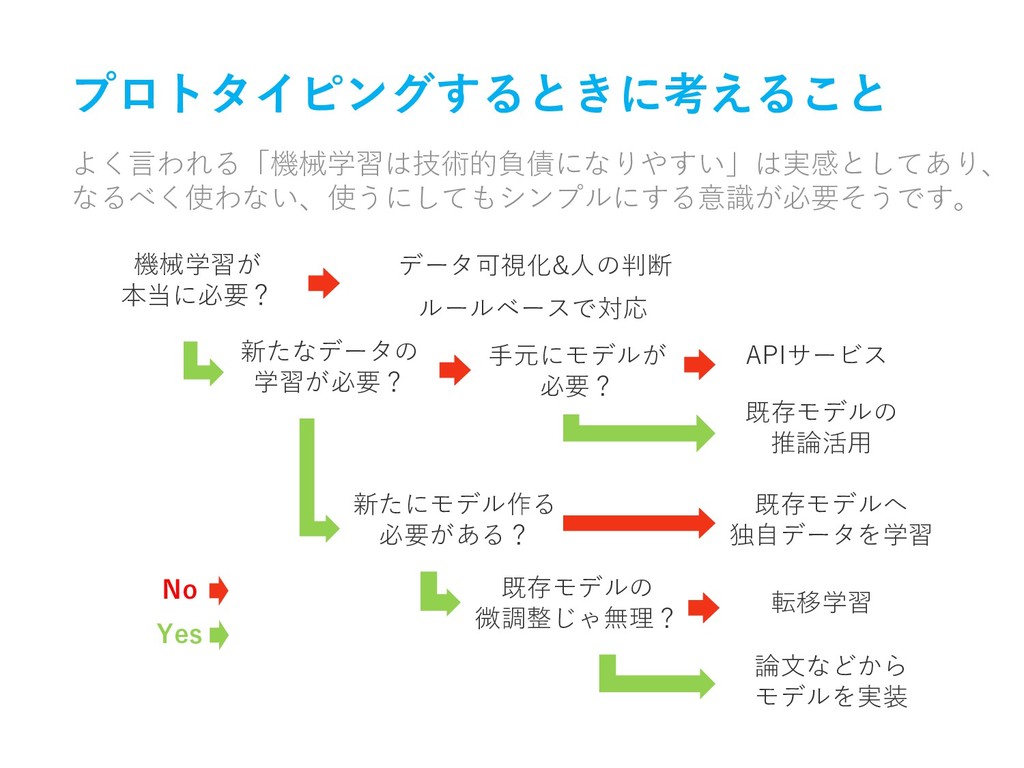
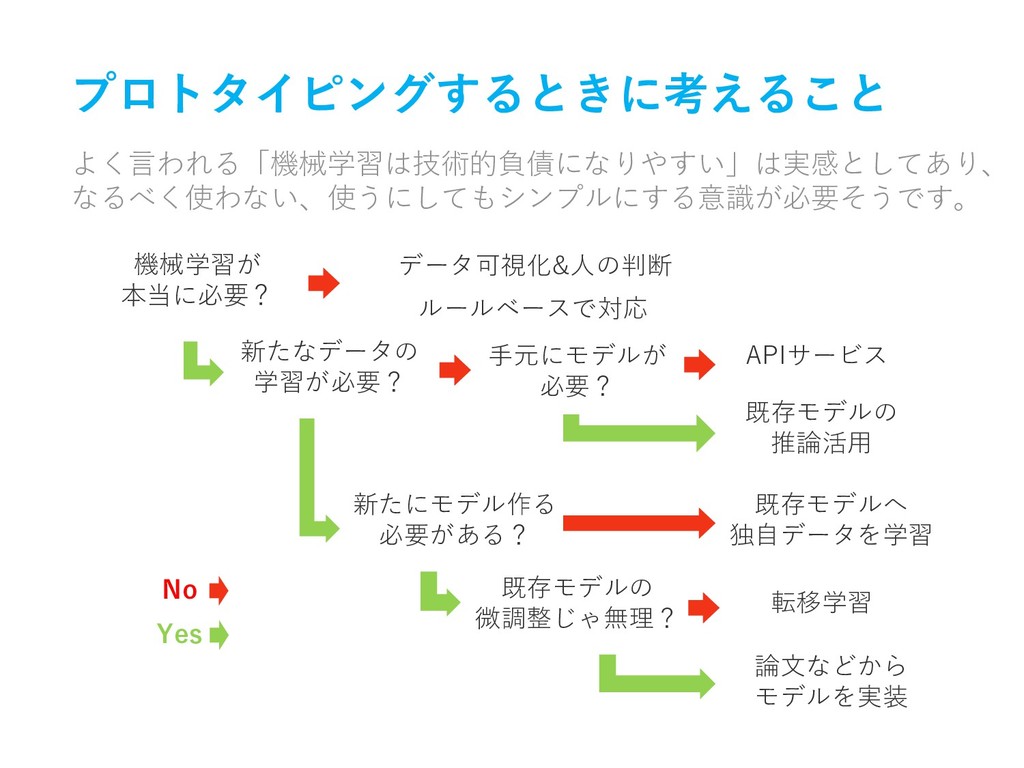
プロトタイピングするときに考えること よく言われる「機械学習は技術的負債になりやすい」は実感としてあり、 なるべく使わない、使うにしてもシンプルにする意識が必要そうです。 機械学習が 本当に必要? 新たなデータの 学習が必要? 手元にモデルが 必要? 新たにモデル作る
必要がある? 論文などから モデルを実装 既存モデルへ 独自データを学習 APIサービス 既存モデルの 推論活用 転移学習 既存モデルの 微調整じゃ無理? ルールベースで対応 データ可視化&人の判断 No Yes
プロトタイピングするときに考えること 今まで一般的だったのはPythonやRでモデルを作ってWebアプリとして デプロイだったが、様々なサービスの発展でデプロイ先の選択肢も増え てきました
プロトタイピングするときに考えること 今まで一般的だったのはPythonやRでモデルを作ってWebアプリとして デプロイだったが、様々なサービスの発展でデプロイ先の選択肢も増え てきました • 遅延が少ない • オフライン環境でも動く • データがデバイス上に留まる
• 電力効率が良い • センサーデータを直接扱える
プロトタイピングするときに考えること 今まで一般的だったのはPythonやRでモデルを作ってWebアプリとして デプロイだったが、様々なサービスの発展でデプロイ先の選択肢も増え てきました • 遅延が少ない • オフライン環境でも動く • データがデバイス上に留まる
• 電力効率が良い • センサーデータを直接扱える
プロトタイピングするときに考えること 今まで一般的だったのはPythonやRでモデルを作ってWebアプリとして デプロイだったが、様々なサービスの発展でデプロイ先の選択肢も増え てきました
どうやってモデルを実装する? どこにデプロイする? を整理したら あとはアイデアを 形にしていく
統計や数学について、 学ばなくて良いんですか?
プロトタイプを作る中で、 必要になったタイミングで 学べば良いのでは?
機械学習モデル開発に便利なサービス
プロトタイピングするときに考えること よく言われる「機械学習は技術的負債になりやすい」は実感としてあり、 なるべく使わない、使うにしてもシンプルにする意識が必要そうです。 機械学習が 本当に必要? 新たなデータの 学習が必要? 手元にモデルが 必要? 新たにモデル作る
必要がある? 論文などから モデルを実装 既存モデルへ 独自データを学習 APIサービス 既存モデルの 推論活用 転移学習 既存モデルの 微調整じゃ無理? ルールベースで対応 データ可視化&人の判断 No Yes
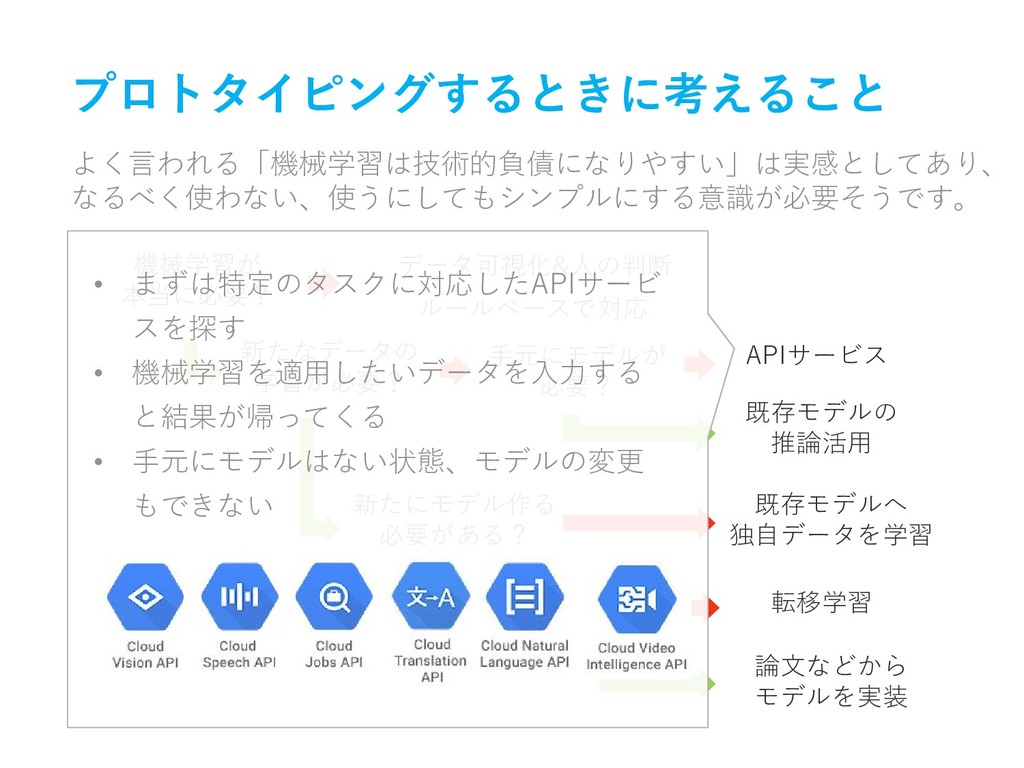
プロトタイピングするときに考えること よく言われる「機械学習は技術的負債になりやすい」は実感としてあり、 なるべく使わない、使うにしてもシンプルにする意識が必要そうです。 機械学習が 本当に必要? 新たなデータの 学習が必要? 手元にモデルが 必要? 新たにモデル作る
必要がある? 論文などから モデルを実装 既存モデルへ 独自データを学習 APIサービス 既存モデルの 推論活用 転移学習 既存モデルの 微調整じゃ無理? ルールベースで対応 データ可視化&人の判断 No Yes • まずは特定のタスクに対応したAPIサービ スを探す • 機械学習を適用したいデータを入力する と結果が帰ってくる • 手元にモデルはない状態、モデルの変更 もできない
プロトタイピングするときに考えること よく言われる「機械学習は技術的負債になりやすい」は実感としてあり、 なるべく使わない、使うにしてもシンプルにする意識が必要そうです。 機械学習が 本当に必要? 新たなデータの 学習が必要? 手元にモデルが 必要? 新たにモデル作る
必要がある? 論文などから モデルを実装 既存モデルへ 独自データを学習 APIサービス 既存モデルの 推論活用 転移学習 既存モデルの 微調整じゃ無理? ルールベースで対応 データ可視化&人の判断 No Yes • 世界中の研究者やエンジニアが開発した 学習済機械学習モデルを借りてきて使う • 「(タスク名) 有名なモデル」とかでググ ると大体出てくる • 最近はTensorFlow Hubにまとめられつつ ある
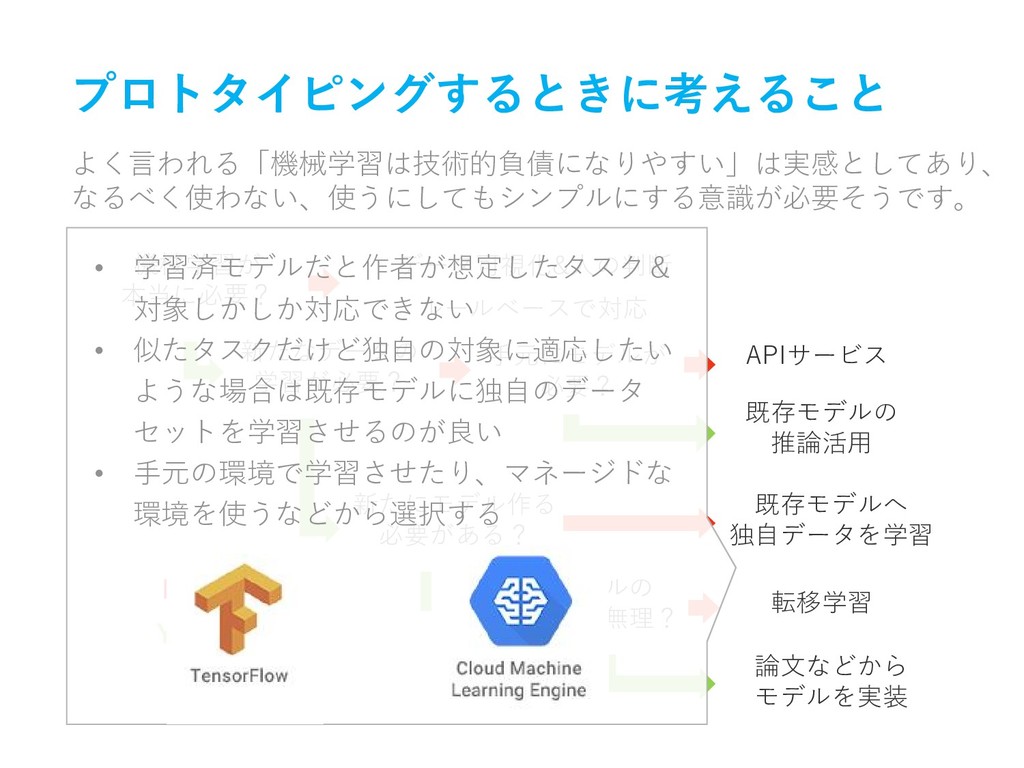
プロトタイピングするときに考えること よく言われる「機械学習は技術的負債になりやすい」は実感としてあり、 なるべく使わない、使うにしてもシンプルにする意識が必要そうです。 機械学習が 本当に必要? 新たなデータの 学習が必要? 手元にモデルが 必要? 新たにモデル作る
必要がある? 論文などから モデルを実装 既存モデルへ 独自データを学習 APIサービス 既存モデルの 推論活用 転移学習 既存モデルの 微調整じゃ無理? ルールベースで対応 データ可視化&人の判断 No Yes • 学習済モデルだと作者が想定したタスク& 対象しかしか対応できない • 似たタスクだけど独自の対象に適応したい ような場合は既存モデルに独自のデータ セットを学習させるのが良い • 手元の環境で学習させたり、マネージドな 環境を使うなどから選択する
プロトタイピングするときに考えること よく言われる「機械学習は技術的負債になりやすい」は実感としてあり、 なるべく使わない、使うにしてもシンプルにする意識が必要そうです。 機械学習が 本当に必要? 新たなデータの 学習が必要? 手元にモデルが 必要? 新たにモデル作る
必要がある? 論文などから モデルを実装 既存モデルへ 独自データを学習 APIサービス 既存モデルの 推論活用 転移学習 既存モデルの 微調整じゃ無理? ルールベースで対応 データ可視化&人の判断 No Yes • 解決したいタスクに対して独自のアイデアで 挑む場合 • 学習については既存モデルと同様手元の環境 で学習させたり、マネージドな環境を使うな どから選択する • データに併せて独自のモデルを構築してくれ るAutoMLの登場でここも自動化の波が
機械学習モデルのデバイスへの デプロイに便利なサービス
None
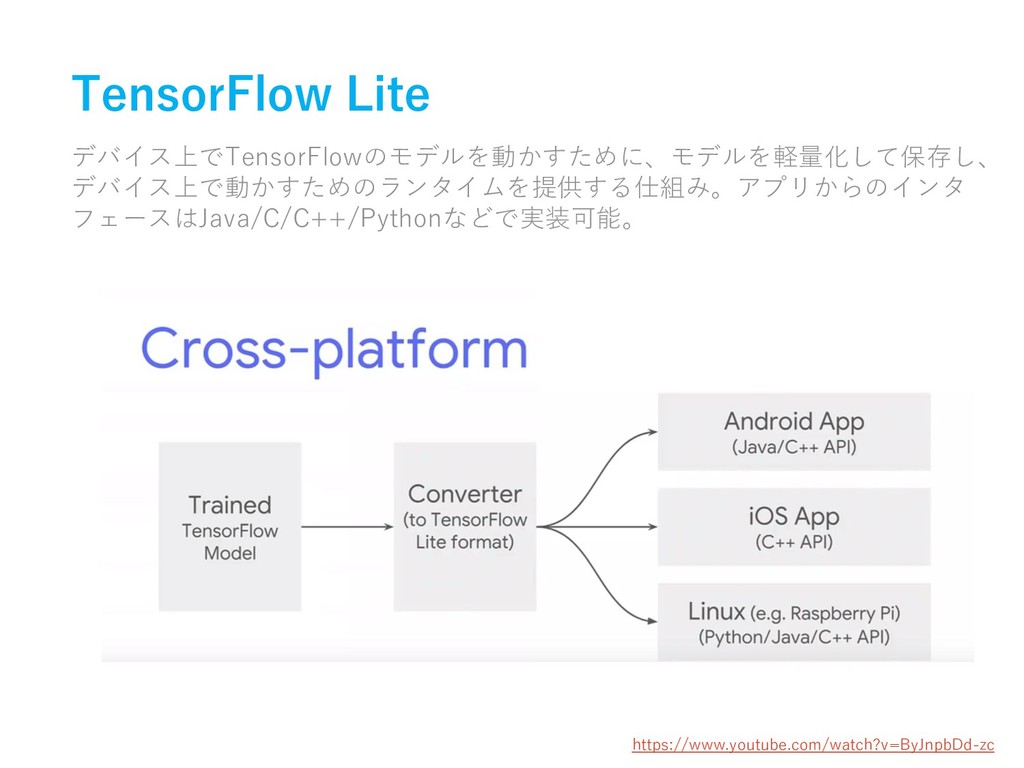
TensorFlow Lite デバイス上でTensorFlowのモデルを動かすために、モデルを軽量化して保存し、 デバイス上で動かすためのランタイムを提供する仕組み。アプリからのインタ フェースはJava/C/C++/Pythonなどで実装可能。 https://www.youtube.com/watch?v=ByJnpbDd-zc
None
ML Kit for Firebase Firebaseでのアプリ開発に機械学習モデルを便利に組み込むためのの仕 組み。 • iOSとAndroidのSDKがある • Base
APIsとカスタムモデルの両方をサポート • On-DeviceとCloud AI inference APIsを使い分けられる
None
TensorFlow.js JavascriptでTensorflowが取り扱えるようになりました。 • JavascriptでTensorflowのモデルを書いたり学習させたりできる • 既存の学習済モデルを簡単にインポートしてくることができる • インポートしたモデルを再学習させることもできる Machine Learning
in JavaScript (TensorFlow Dev Summit 2018) https://www.youtube.com/watch?v=YB-kfeNIPCE
None
None
自作TFモデルを色んなところにデプロイしたい toco TensorFlow.js converter Bonnet Compiler モデル構築 フォーマット 変換 モデルの実行
自作TFモデルを色んなところにデプロイしたい toco TensorFlow.js converter Bonnet Compiler モデル構築 フォーマット 変換 モデルの実行
Demo
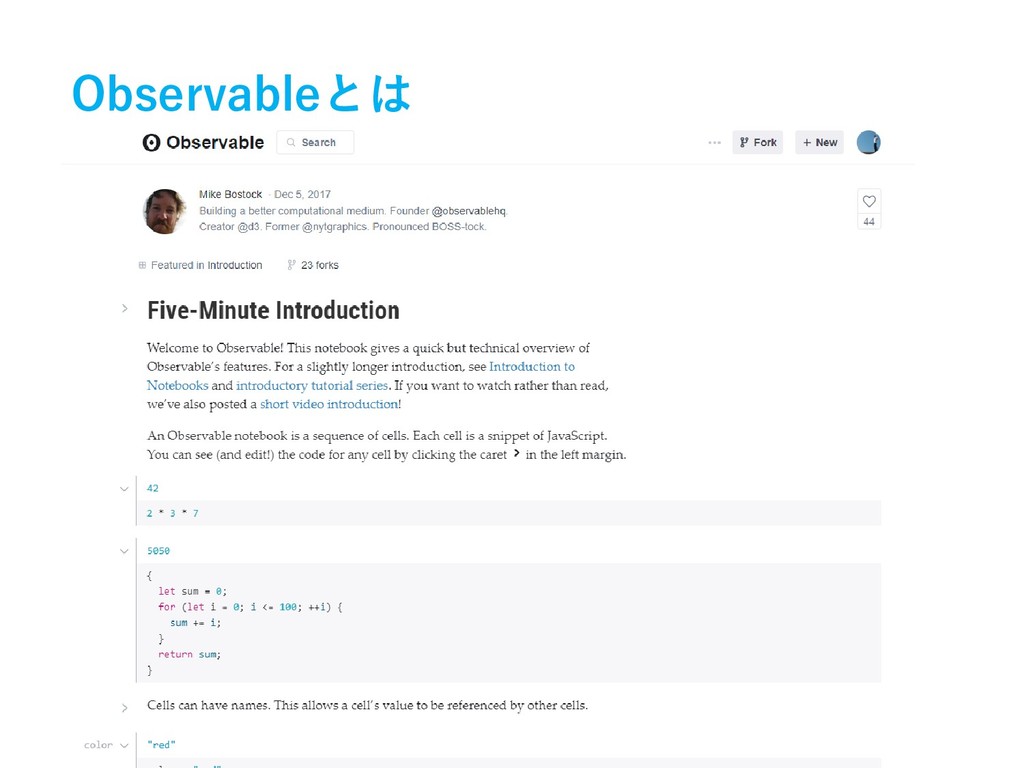
Observableとは
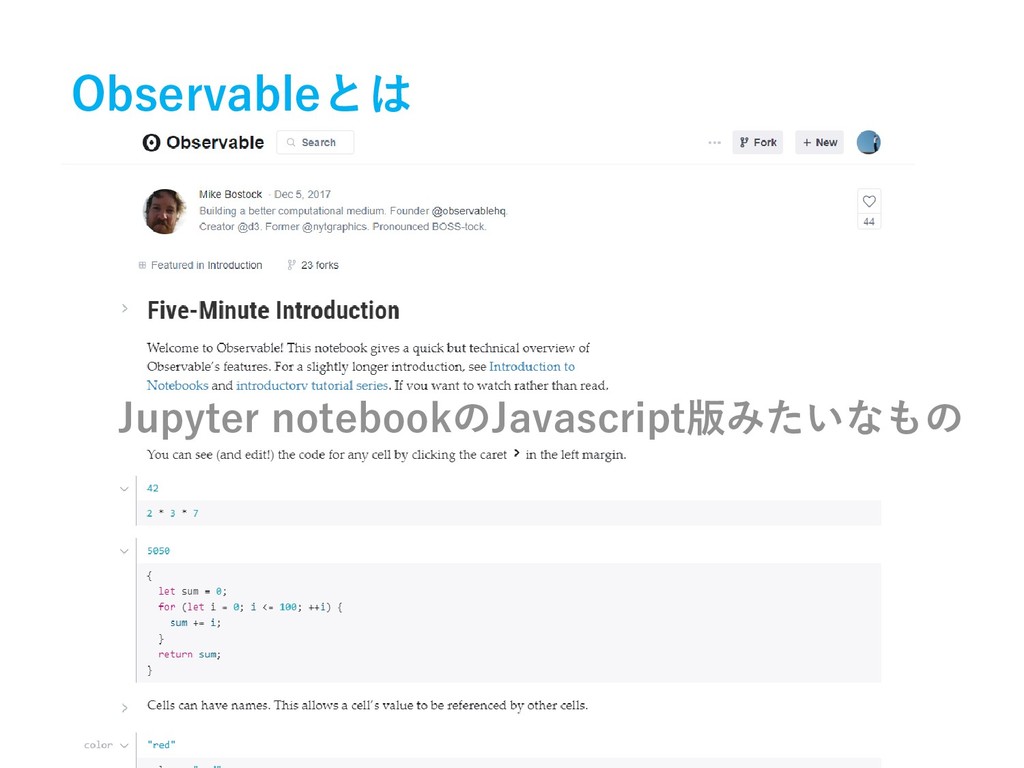
Observableとは Jupyter notebookのJavascript版みたいなもの
Observableとは
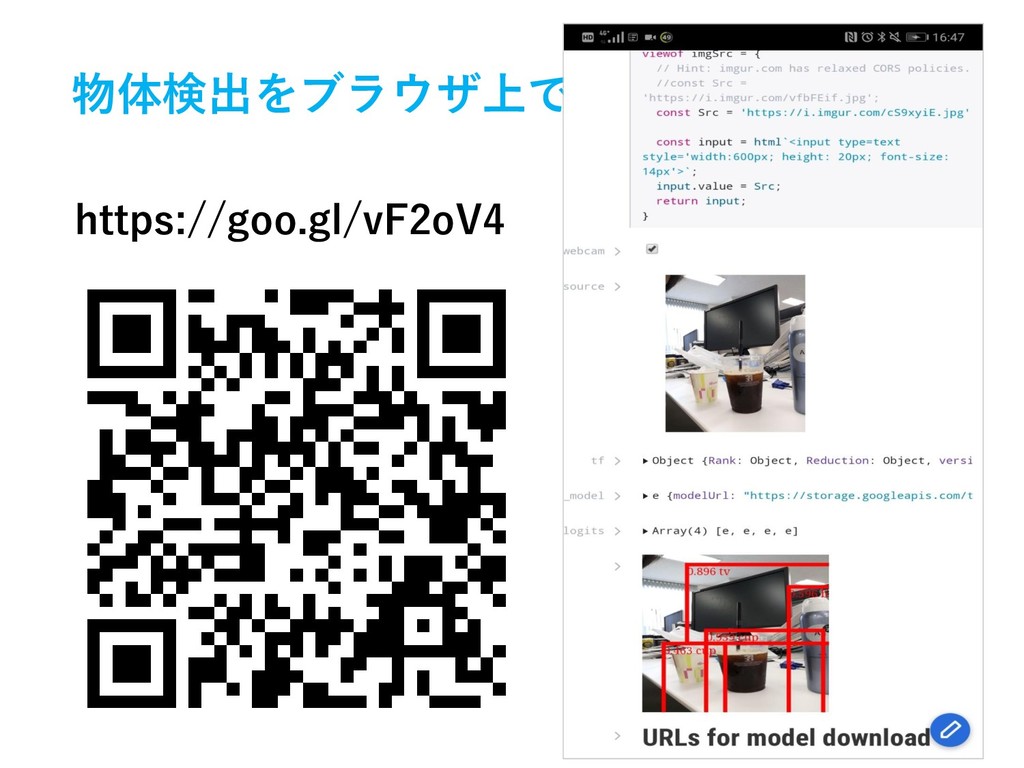
物体検出をブラウザ上で動かしてみる https://goo.gl/vF2oV4
物体検出をブラウザ上で動かしてみる https://goo.gl/vF2oV4
プロダクトに仕上げるために
プロダクトに仕上げるために • 機械学習モデルは使い続けてこそ価値がある しかし、機械学習モデル(というかデータ)は水物 開発し終わった瞬間からメンテし続けないとだめ • その機械学習モデルは本当に使って良いモデル? 機械学習モデルの公平性 機械学習アプリのプロトタイプを作ることはかなりハードル下がっ て来ましたが、あくまでもプロトタイプ。機械学習モデルを使うと
いう観点から考えなければいけないことがたくさんあります。
機械学習システムの継続的デプロイ 機械学習は1回学習させて「モデルができました!」となるような ものは少なく、データの傾向の変遷などから定期的に学習をさせて モデルを刷新させなければいけないような場合があります。 • 製品の需要予測、季節の変化や新製品の投入、プロモーションの 変化をモデルに取り込まなければ • ニュース記事についての分析、時代とともに「やばい」の意味が 変わってきているのに対応しなければ
機械学習システムの継続的デプロイ • モデルの再学習は定期的?それとも精度の劣化がトリガー? • 再学習させるデータの質はどの程度変化しているのか? • 新しいデータを学習させたモデルは以前のモデルとどのように挙 動が変化しているのか? • データ、機械学習モデル、コンフィグ、学習スクリプトのバー
ジョン管理は? • その再学習後のモデル、本番にデプロイしていい?テストどうす る? 機械学習は1回学習させて「モデルができました!」となるような ものは少なく、データの傾向の変遷などから定期的に学習をさせて モデルを刷新させなければいけないような場合があります。
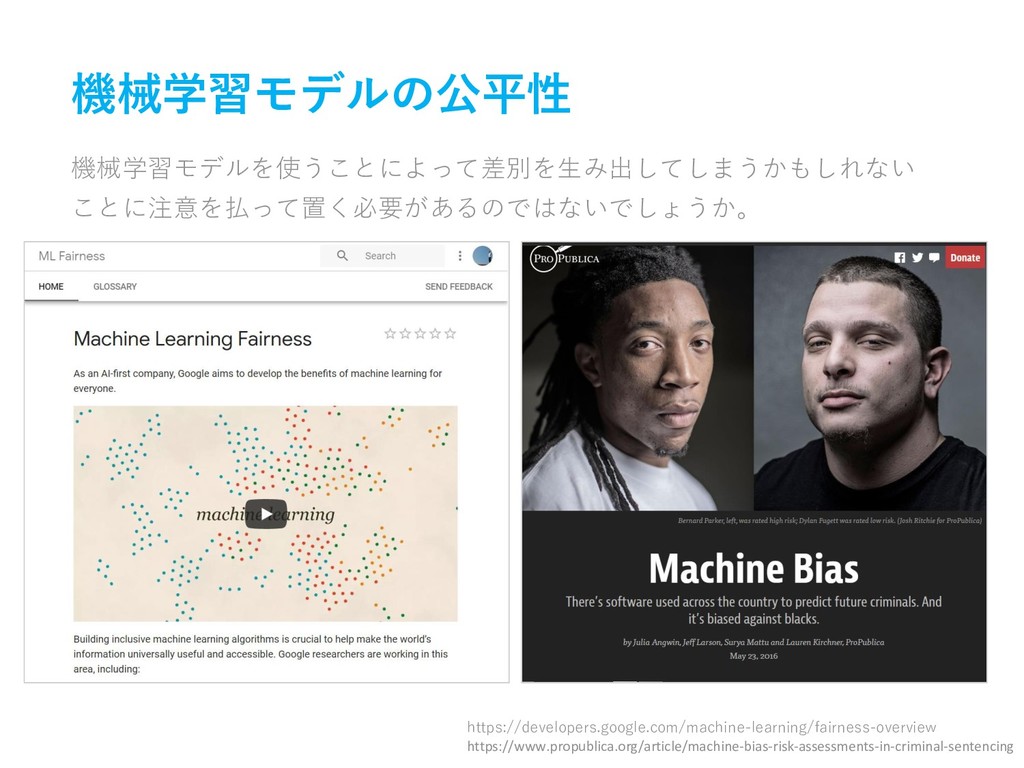
機械学習モデルの公平性 機械学習モデルを使うことによって差別を生み出してしまうかもしれない ことに注意を払って置く必要があるのではないでしょうか。 https://developers.google.com/machine-learning/fairness-overview https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
まとめ
まとめ • 「機械学習モデルの開発が簡単」はもちろん、機械学習アプリのプ ロトタイプ開発のハードルも下がってきた • 重要な課題を解決するのに、必ずしも難しい手法を使う必要はない 機械学習の応用ではシンプルな方法が継続活用には良いかもしれ ない • 今ある技術で解決できる/すべき課題はなにかを考えて実際に手を
動かすのが大事になってきているのでは
ありがとうございました http://www.brainpad.co.jp/recruit/ 株式会社ブレインパッドの採用情報見て下さい
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}