Au cours de l'année passée, les modèles génériques (modèles pré-appris et ré-utilisables pour plusieurs taches) de traitement automatique des langues ont connu un saut inhabituel de performances. De la même manière que word2vec pour les mots, un changement de paradigme se profile pour le traitement des phrases/paragraphes.
Dans cette présentation, nous allons aborder les défis actuels du traitement des langues puis montrer ce que les modèles récents basés sur les Transformers et les modèles de langue (BERT, GPT, XLnet) apportent de nouveau (et d'ancien).
Bio : Damien Sileo est doctorant en 3eme année à Synapse Développement et à l'Université de Toulouse. Il est spécialisé dans la compréhension automatique du langage naturel et s'intéresse particulièrement à la notion de sens dans les représentations neuronales, ainsi qu'à la composition d'embeddings et aux modèles d'encodage (RNN/CNN/Transformers).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
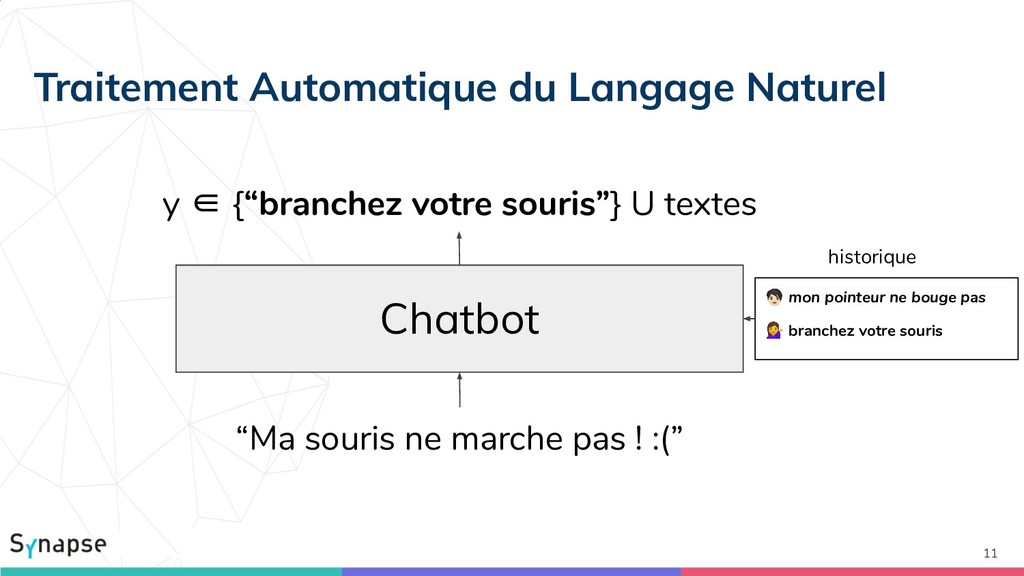
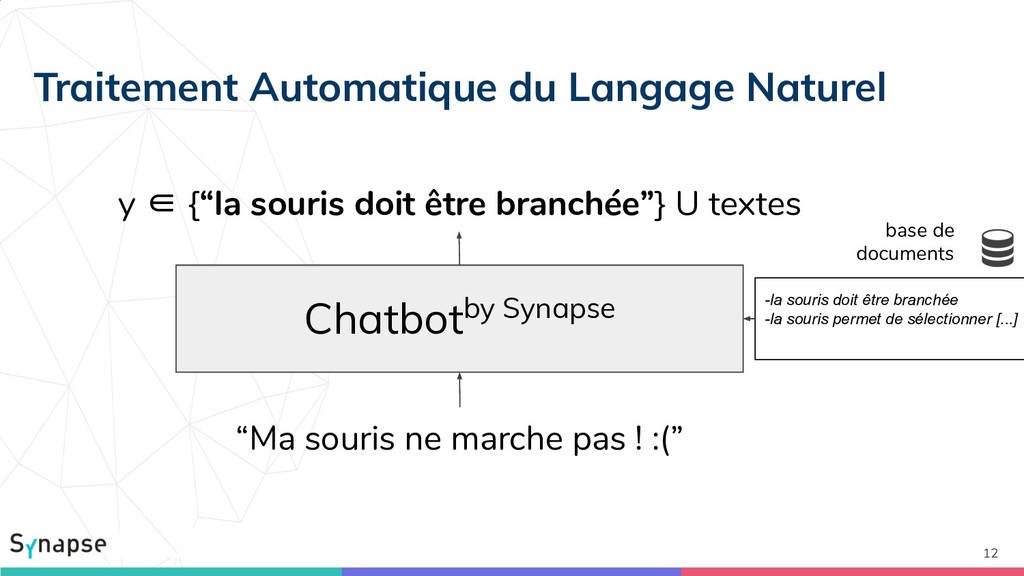
![8 Similarité sémantique y ∈ [0,1] “Ma souris ne marche](https://files.speakerdeck.com/presentations/e71a7808dbb7439aa156ce0c5a864fde/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
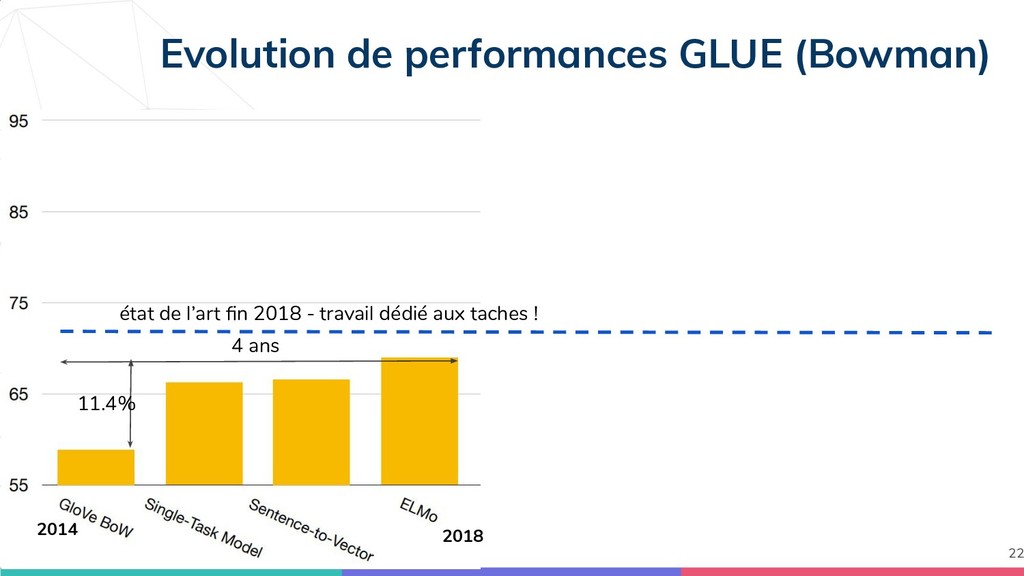{kind=link}
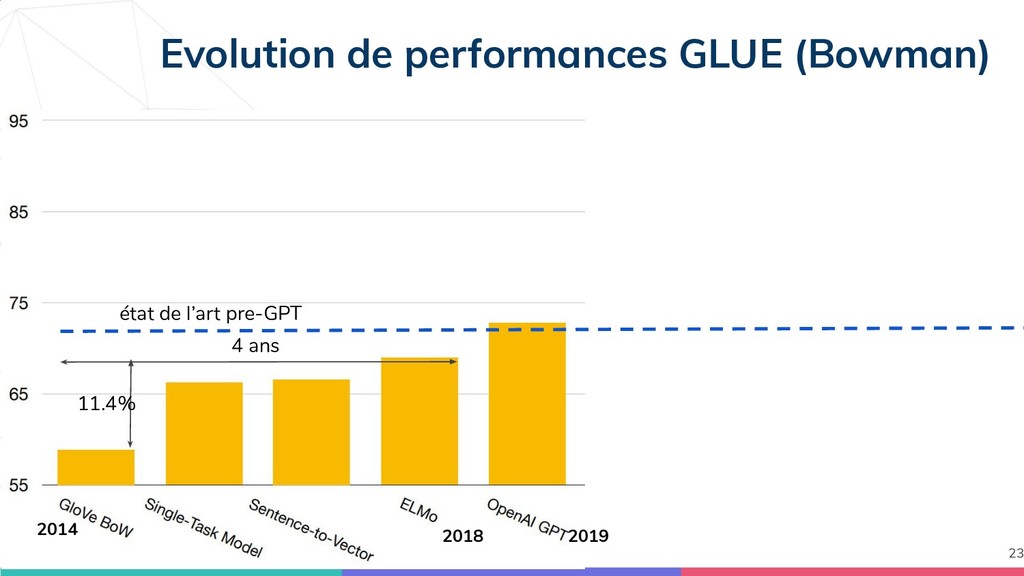{kind=link}
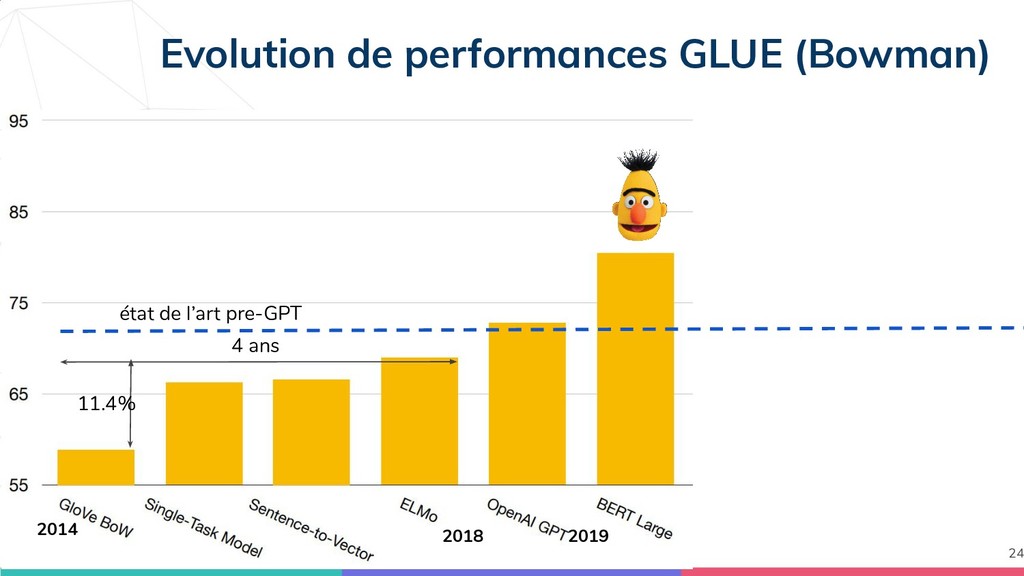{kind=link}
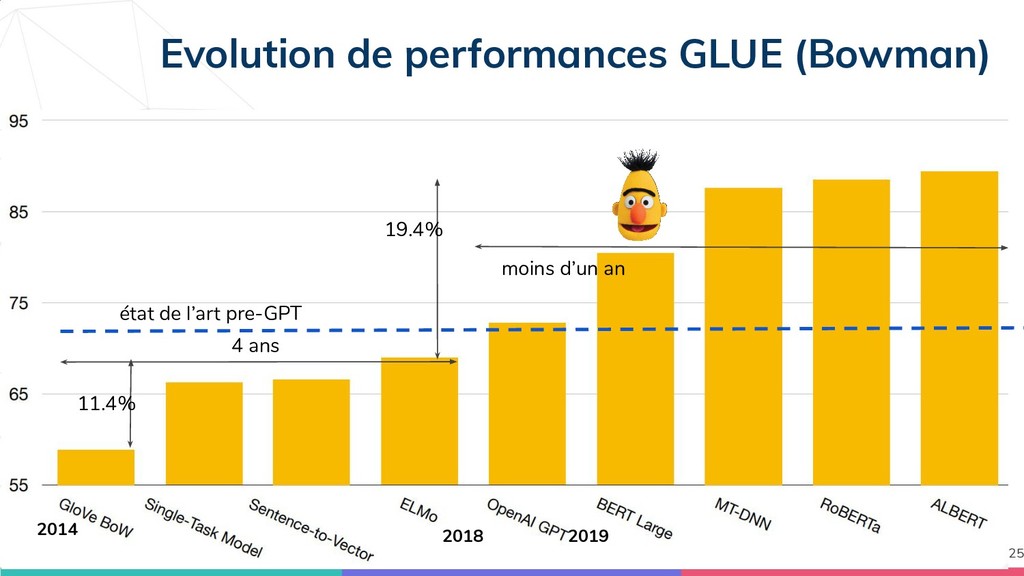{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
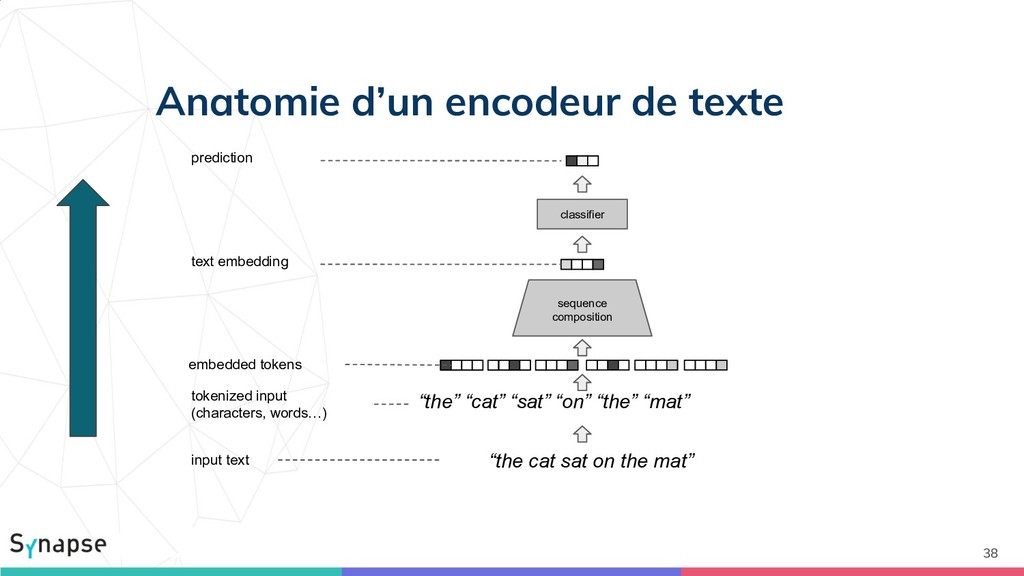{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
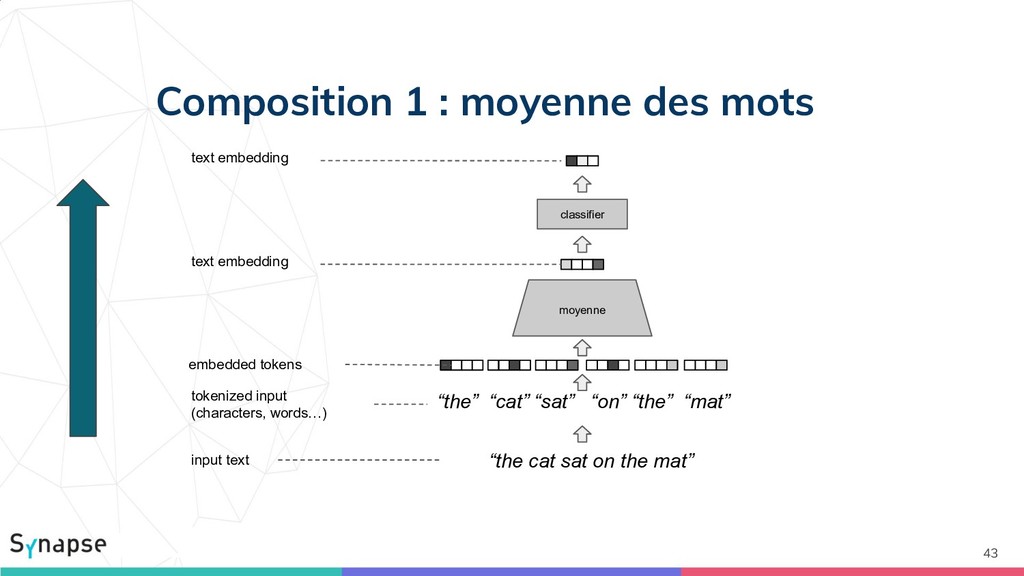{kind=link}
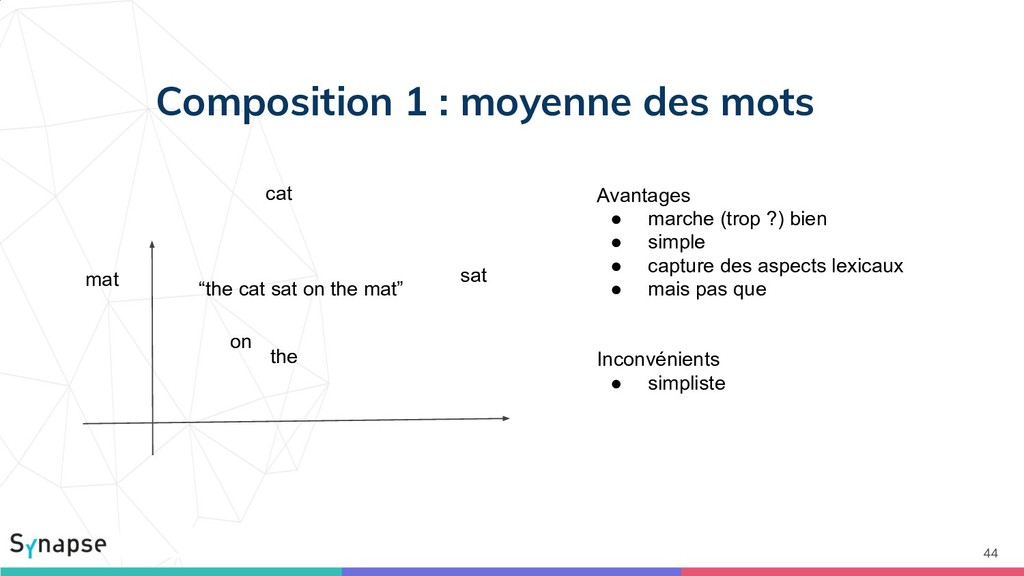{kind=link}
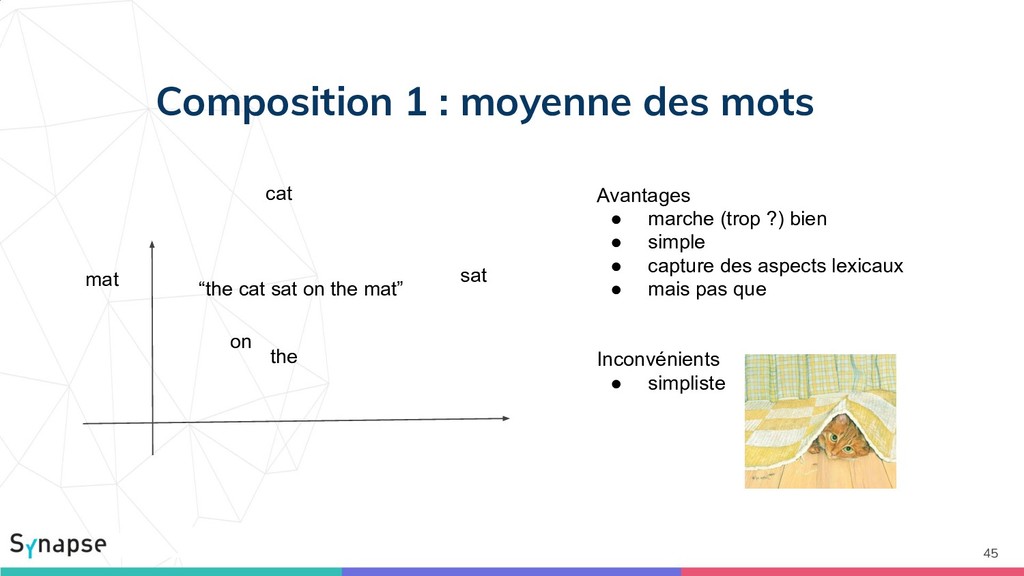{kind=link}
{kind=link}
{kind=link}
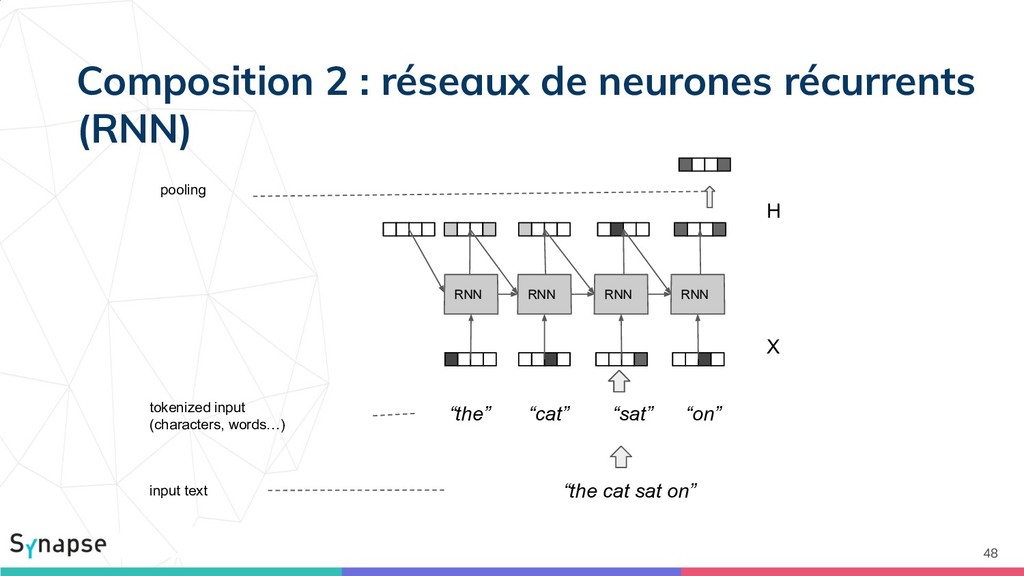{kind=link}
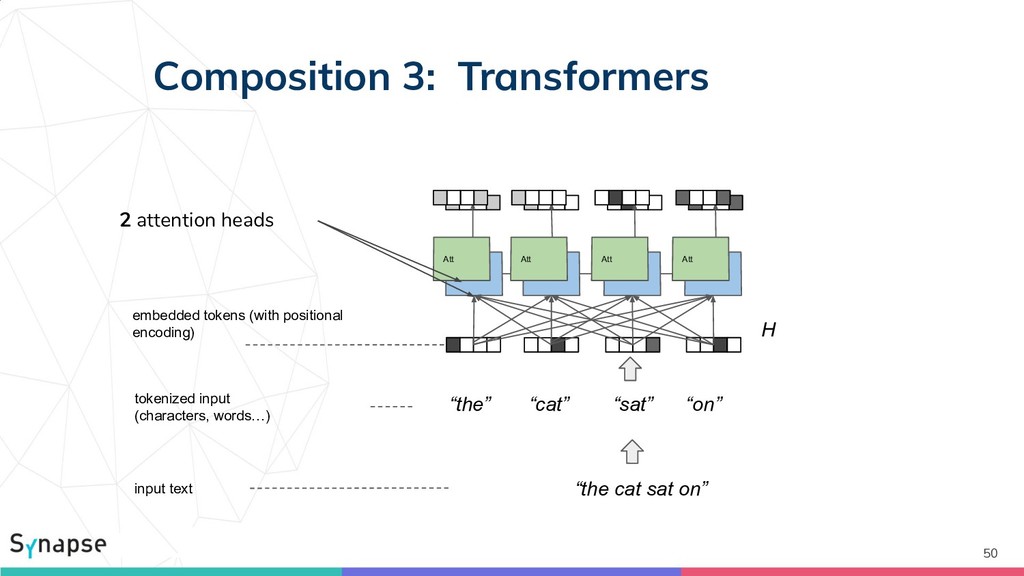
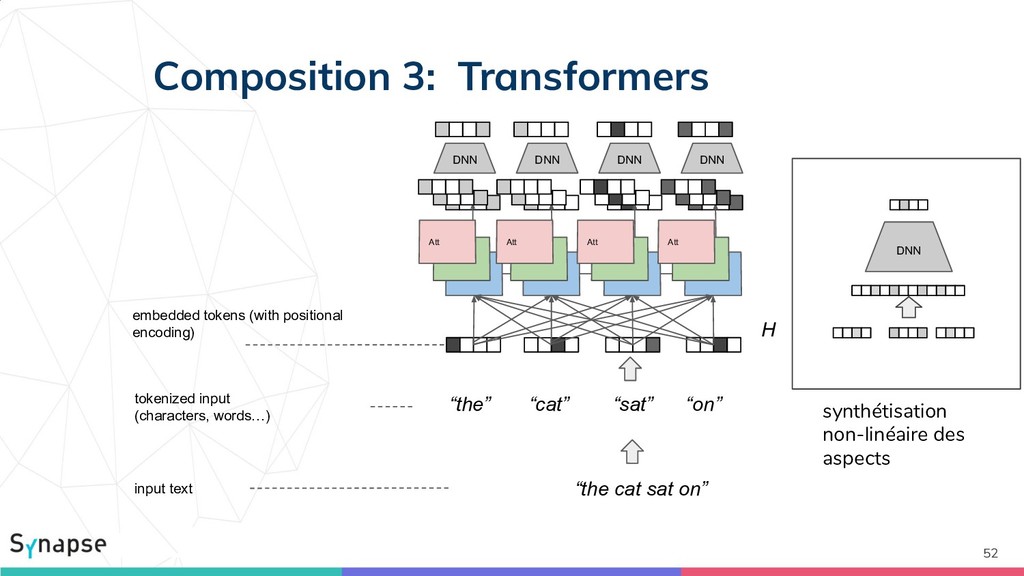
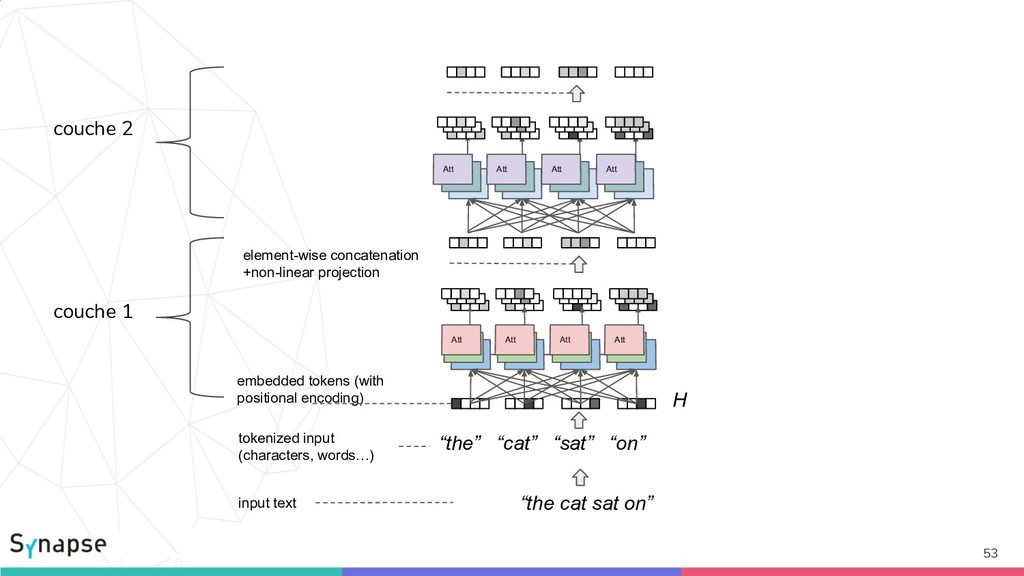
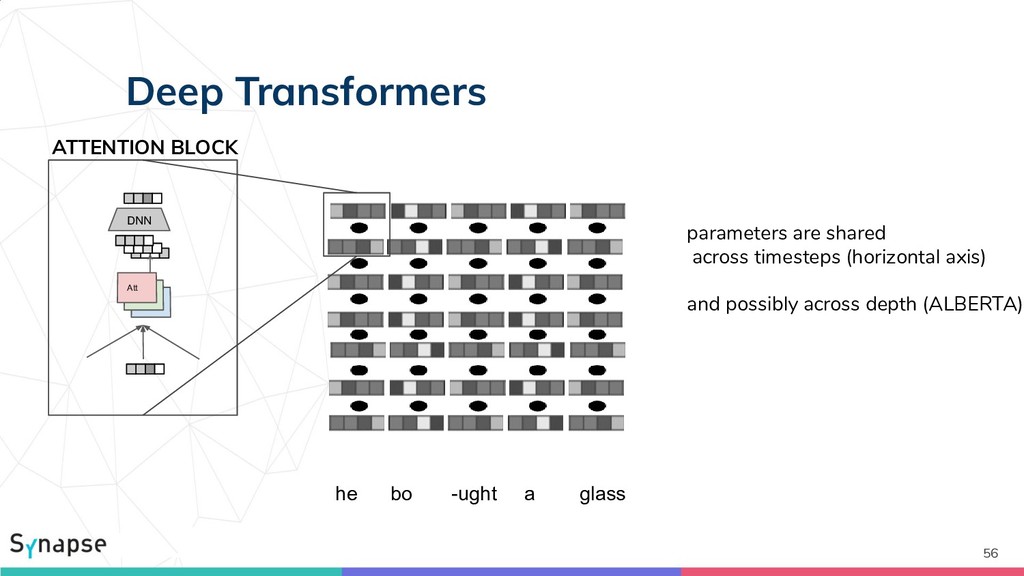
![Composition 3: Transformers [Vaswani2017] 49 Att Att Att Att H](https://files.speakerdeck.com/presentations/e71a7808dbb7439aa156ce0c5a864fde/slide_48.jpg){kind=link}
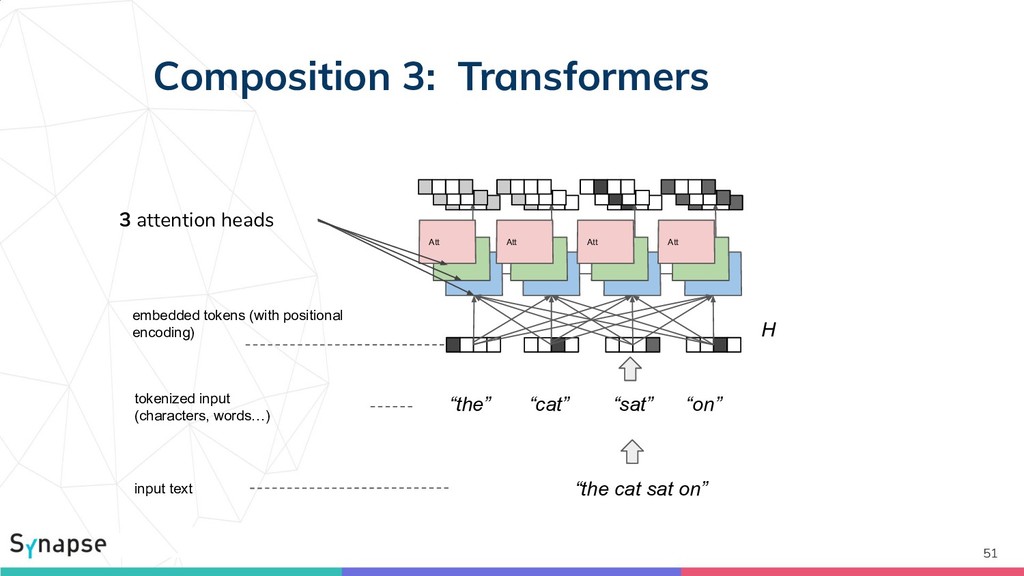
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![59 [CLS] he bo -ught a glass Deep Transformers -](https://files.speakerdeck.com/presentations/e71a7808dbb7439aa156ce0c5a864fde/slide_58.jpg){kind=link}
![60 [CLS] he bo -ught a glass Deep Transformers -](https://files.speakerdeck.com/presentations/e71a7808dbb7439aa156ce0c5a864fde/slide_59.jpg){kind=link}
![61 [CLS] he bo -ught a glass [SEP] he bo](https://files.speakerdeck.com/presentations/e71a7808dbb7439aa156ce0c5a864fde/slide_60.jpg){kind=link}
![62 [CLS] he bo -ught a glass [SEP] he bo](https://files.speakerdeck.com/presentations/e71a7808dbb7439aa156ce0c5a864fde/slide_61.jpg){kind=link}
![63 [CLS] he bo -ught a glass [SEP] he bo](https://files.speakerdeck.com/presentations/e71a7808dbb7439aa156ce0c5a864fde/slide_62.jpg){kind=link}
{kind=link}
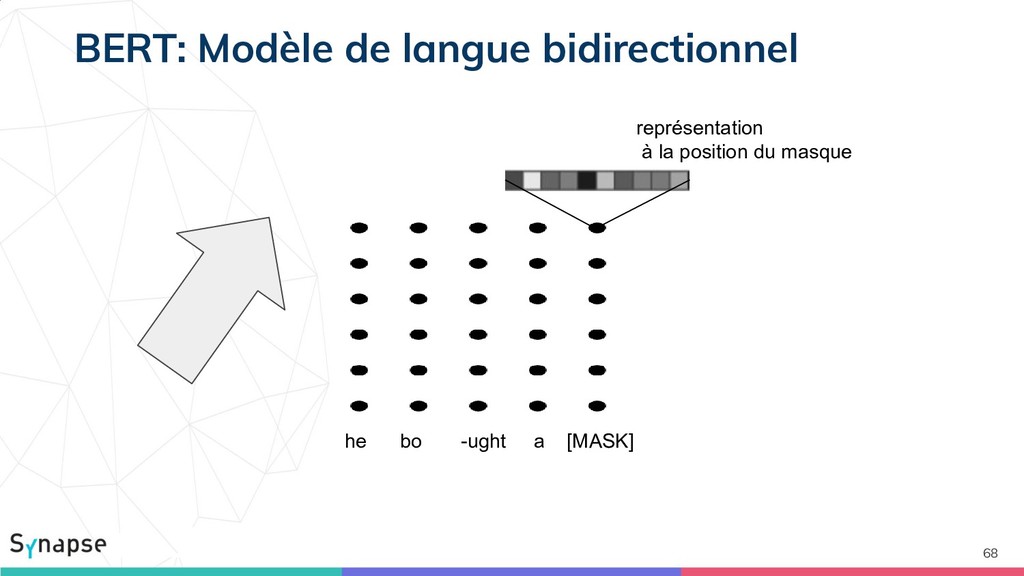
![65 he bo -ught a [MASK] représentation à la position](https://files.speakerdeck.com/presentations/e71a7808dbb7439aa156ce0c5a864fde/slide_64.jpg){kind=link}
![66 he bo -ught a [MASK] GPT = Transformers +](https://files.speakerdeck.com/presentations/e71a7808dbb7439aa156ce0c5a864fde/slide_65.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![70 BERT: prédiction de contiguïté [CLS] he bo -ught a](https://files.speakerdeck.com/presentations/e71a7808dbb7439aa156ce0c5a864fde/slide_69.jpg){kind=link}
![71 BERT: prédiction de contiguïté [CLS] he bo -ught a](https://files.speakerdeck.com/presentations/e71a7808dbb7439aa156ce0c5a864fde/slide_70.jpg){kind=link}
![72 BERT: aspects fonctionnels [CLS] le chat est sur la](https://files.speakerdeck.com/presentations/e71a7808dbb7439aa156ce0c5a864fde/slide_71.jpg){kind=link}
![73 BERT: aspects fonctionnels [CLS] le chat est sur la](https://files.speakerdeck.com/presentations/e71a7808dbb7439aa156ce0c5a864fde/slide_72.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
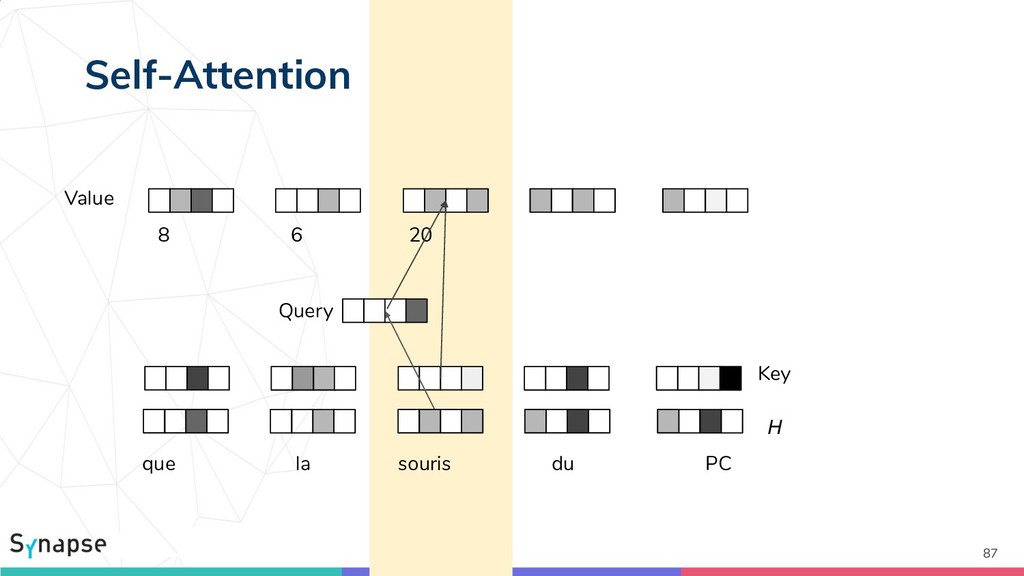{kind=link}
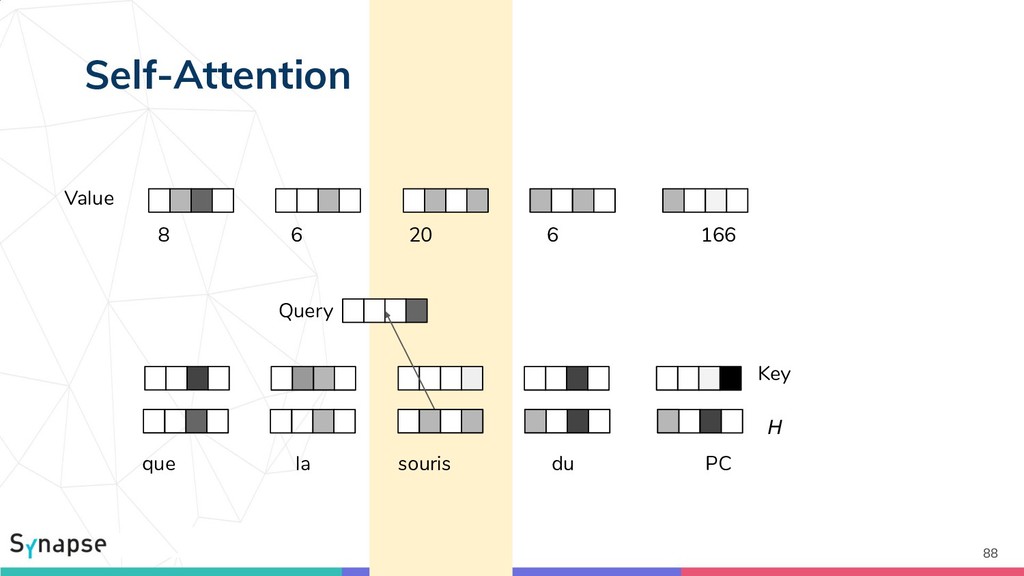{kind=link}
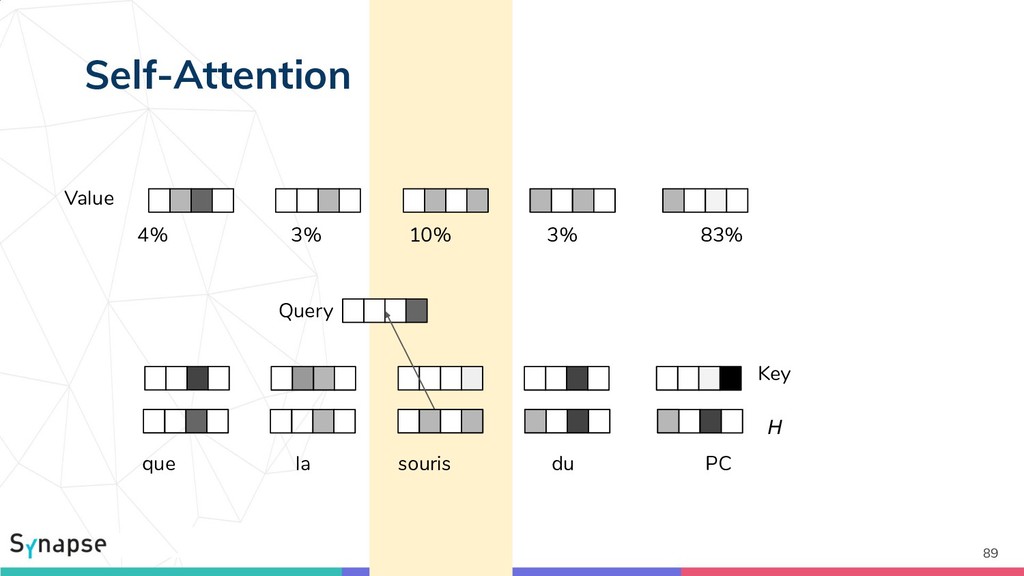{kind=link}
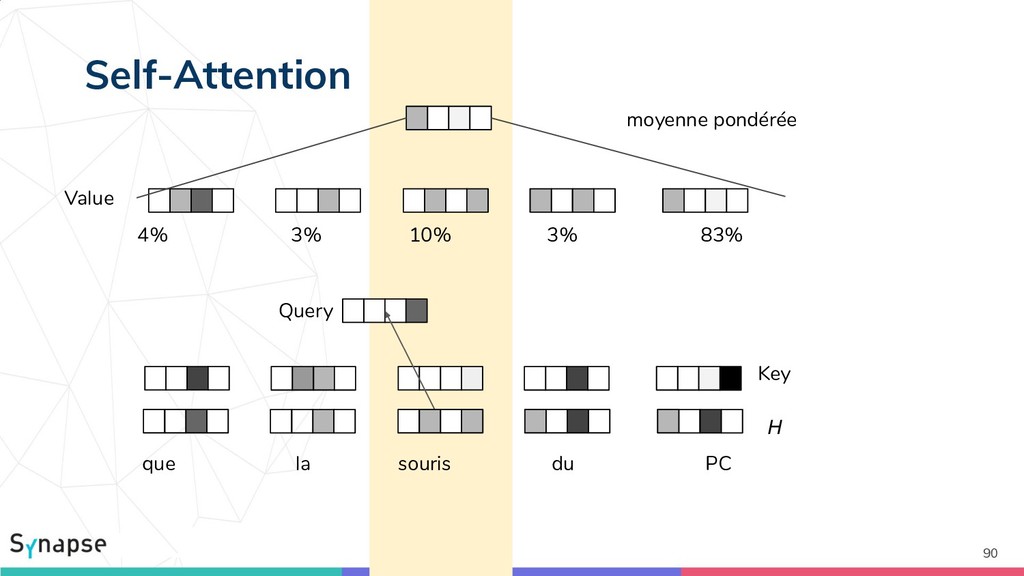{kind=link}
{kind=link}
{kind=link}
{kind=link}