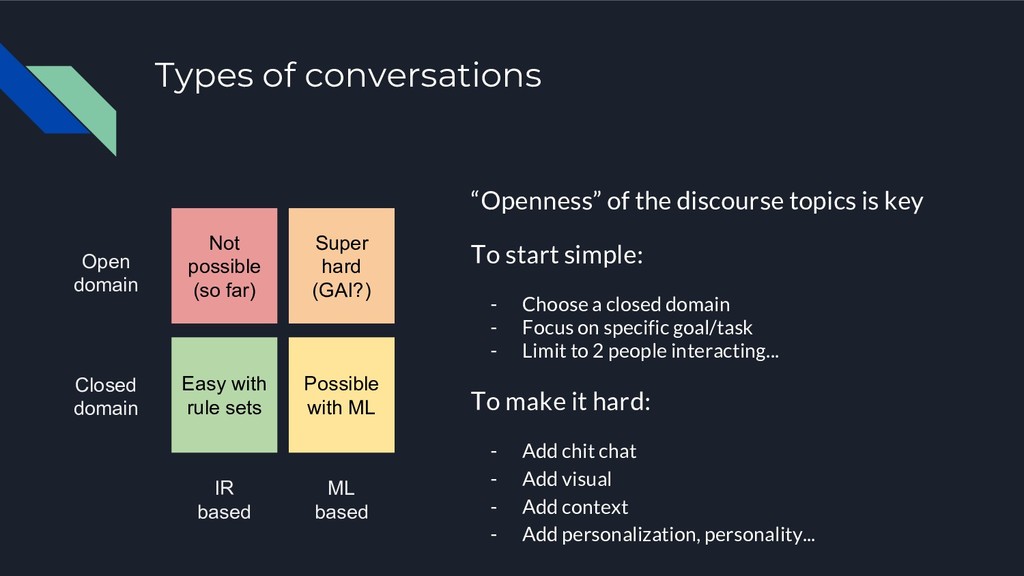
2018, c'est bon la folie des chatbots est enfin derrière nous. On va enfin pouvoir... s'y remettre sérieusement. Au delà du hype, l'interaction en language naturel (à l'oral ou bien à l'écrit) restera une approche naturelle et humaine. Mais comment dépasser la pile if/else d'un bot de base ? Comment rendre le chatbot utile ? Comment avancer vers le fameux agent personnel interactif promis par tous les bouquins de SF ?
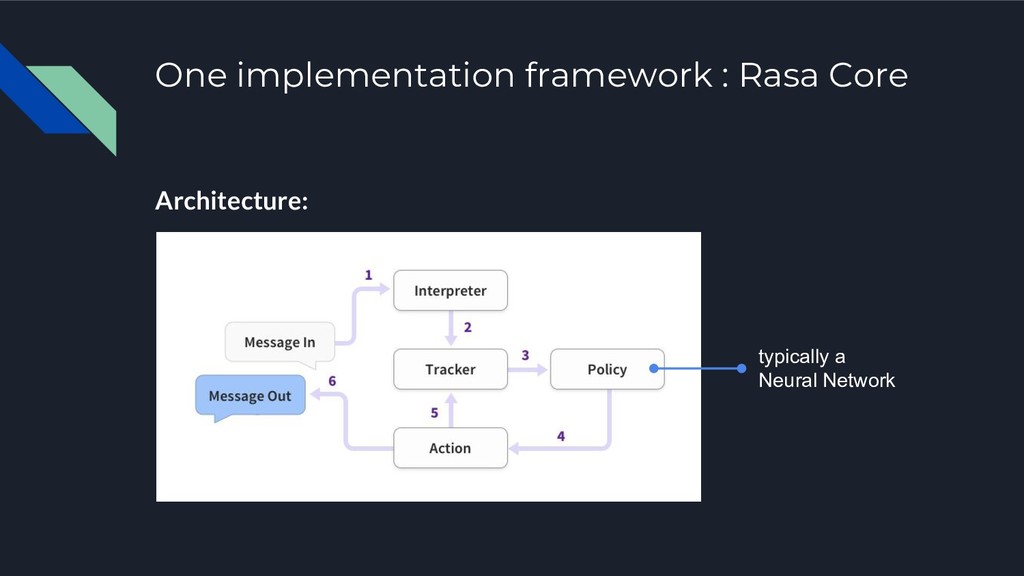
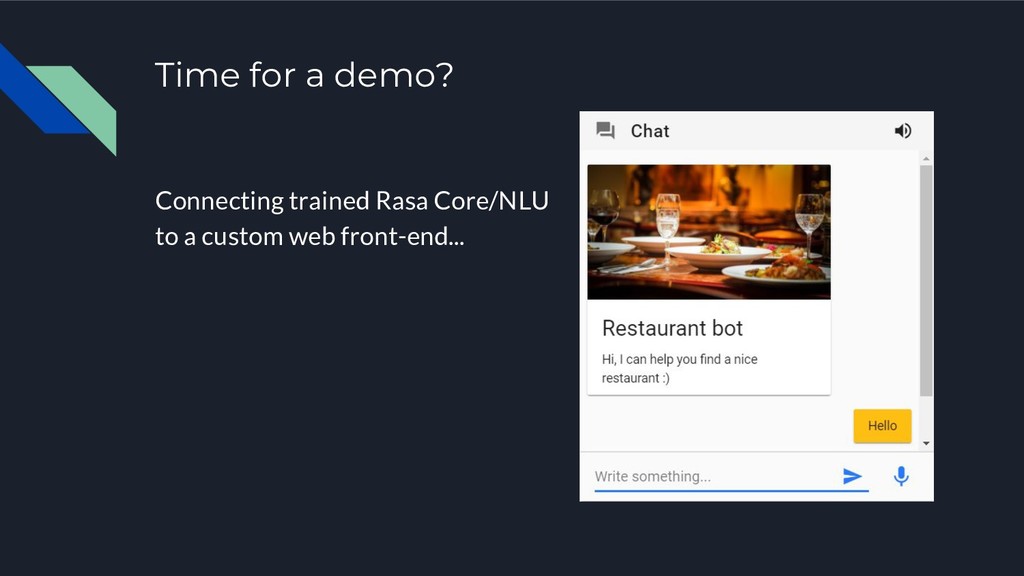
Ce talk proposera d'explorer l'état actuel des choses en s'attachant - en plus de la mise un place d'un bot - au problème de la gestion des modèles ML sous-jacent et de leur évaluation par rapport à un cas d'utilisation réaliste. En particulier nous présenterons ParlAI, le projet open source issue de Facebook qui s'attaque à ce problème de la mesure de performance de chatbots.
Bio:
- Gérard DUPONT - senior data scientist - AIRBUS research
- Alexandre ARNOLD - senior data scientist - AIRBUS research
{kind=link}
![Gérard Dupont [email protected] More than 10 years on research projects](https://files.speakerdeck.com/presentations/bd95af583dc8490eabf645c7312948ee/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Q/A time? Central Research & Technology Gérard Dupont [email protected] Alexandre](https://files.speakerdeck.com/presentations/bd95af583dc8490eabf645c7312948ee/slide_51.jpg){kind=link}
{kind=link}
{kind=link}