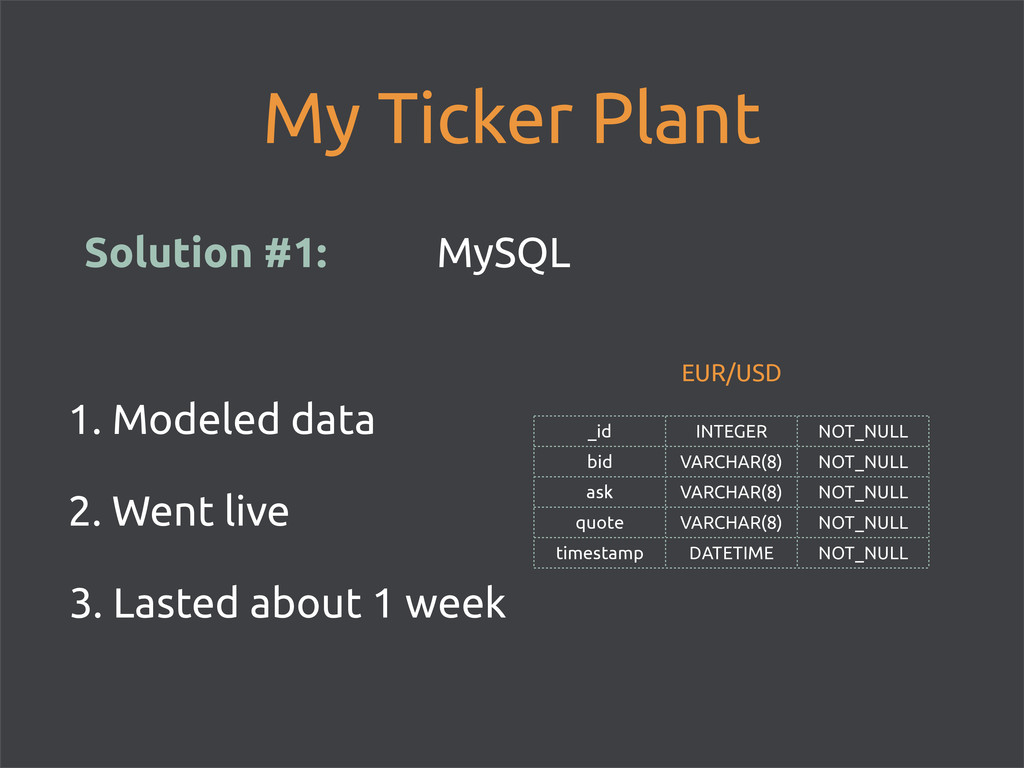
I can chew • this was a widely discussed issue • relational databases are ill suited for analysis of time-series data • while I wasn’t paying attention, a renaissance in data storage tech emerged
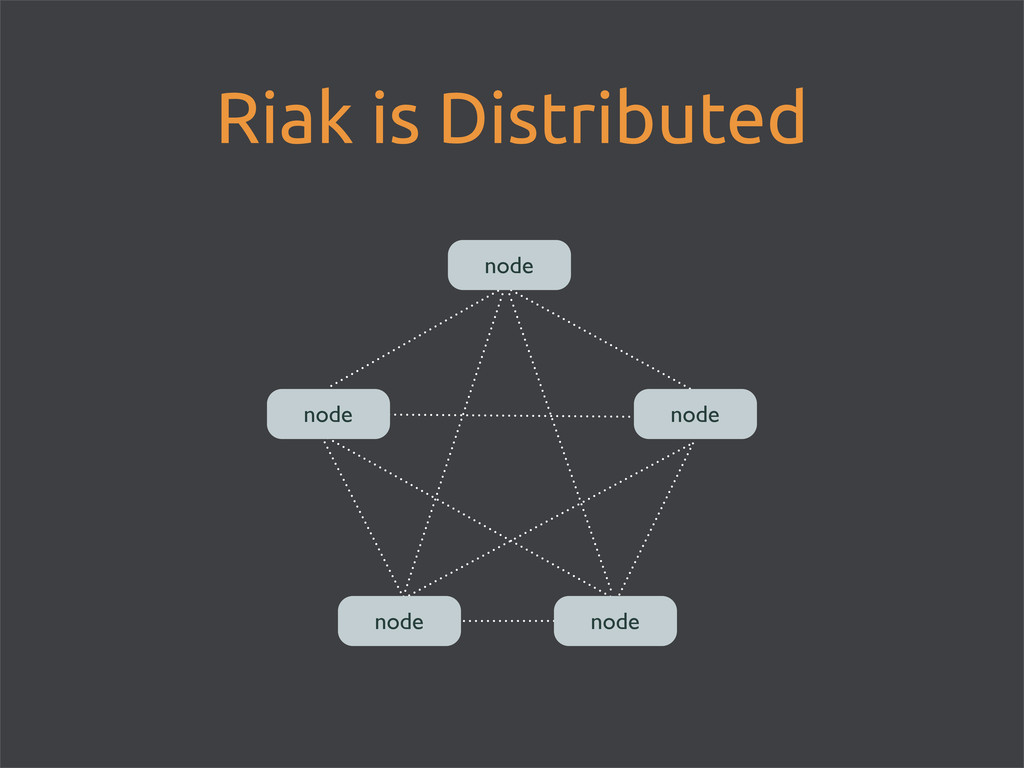
• custom datastore for Basho’s SaaS • Basho pivots, open sourced Riak • September 2011 Riak turned 1.0 • Currently run in production by 1000s • Basho sells commercial extensions to Riak
grouped into namespaces called buckets • basic operations: GET, PUT, DELETE • content-agnostic • accepts any datatype (JSON, XML, JPEG...) • riak objects are stored on disk as binaries
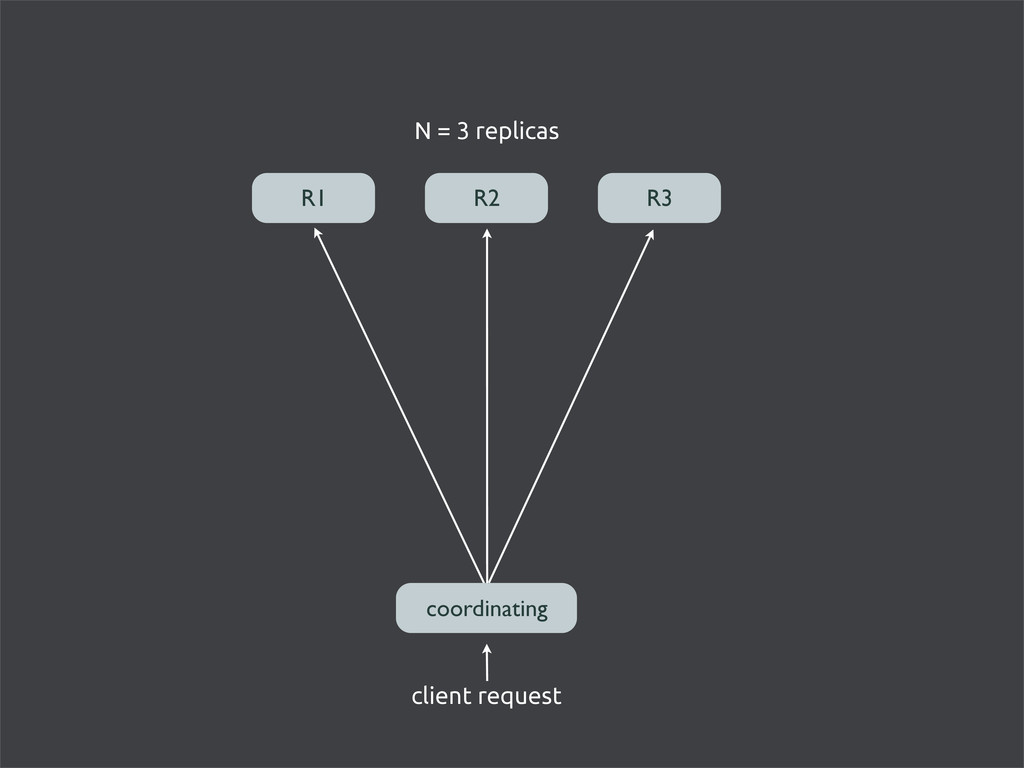
number of evenly-sized partitions • partitions are claimed by nodes in the cluster • replicas go to the N partitions following the key node 0 node 1 node 2 node 3
number of evenly-sized partitions • partitions are claimed by nodes in the cluster • replicas go to the N partitions following the key node 0 node 1 node 2 node 3 hash(“meetups/NYC-postgres”) N=3
than reasonable for 1 physical machine • HA requirements • availability more important than consistency • latency requirements • data easily "ts key/value model
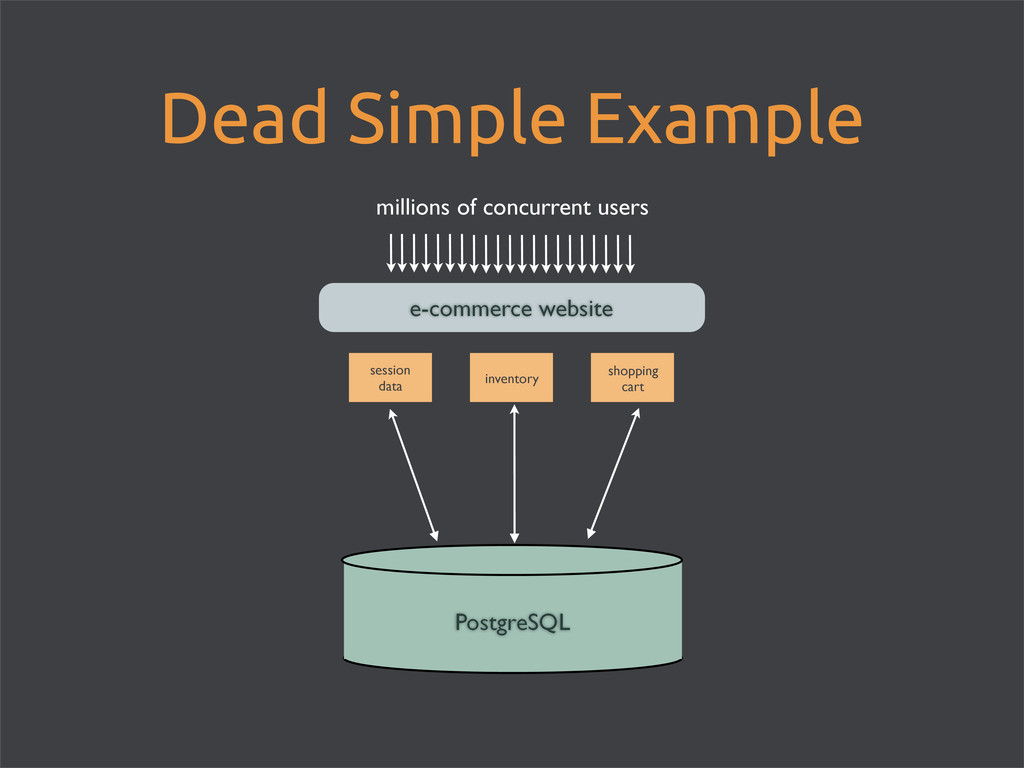
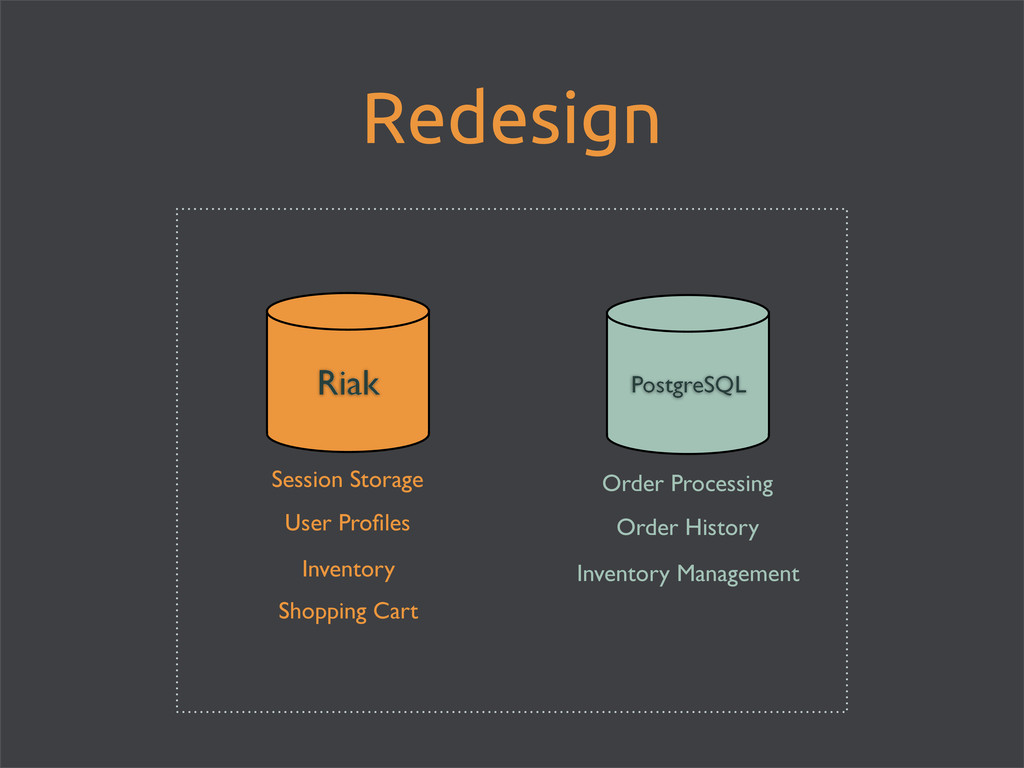
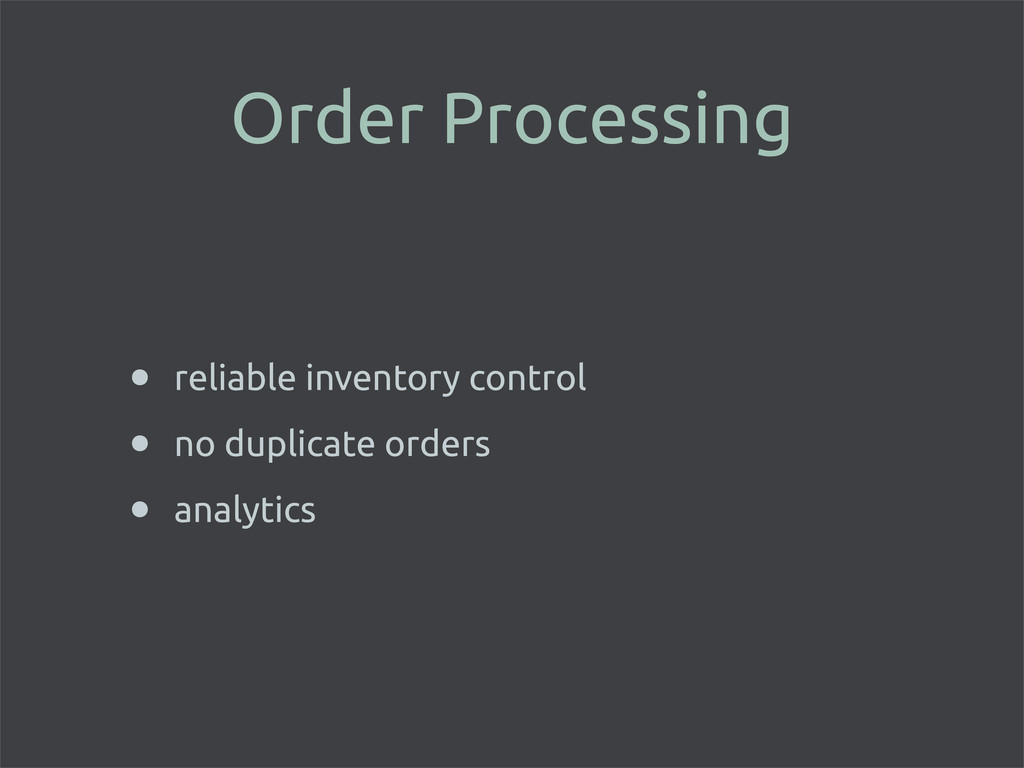
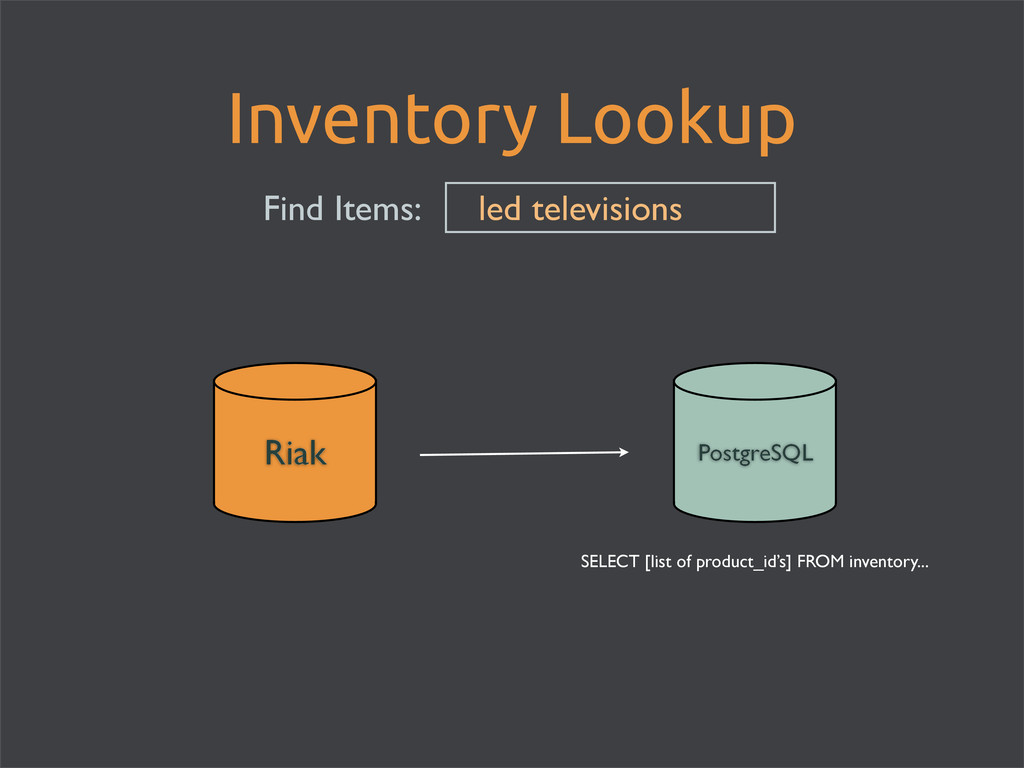
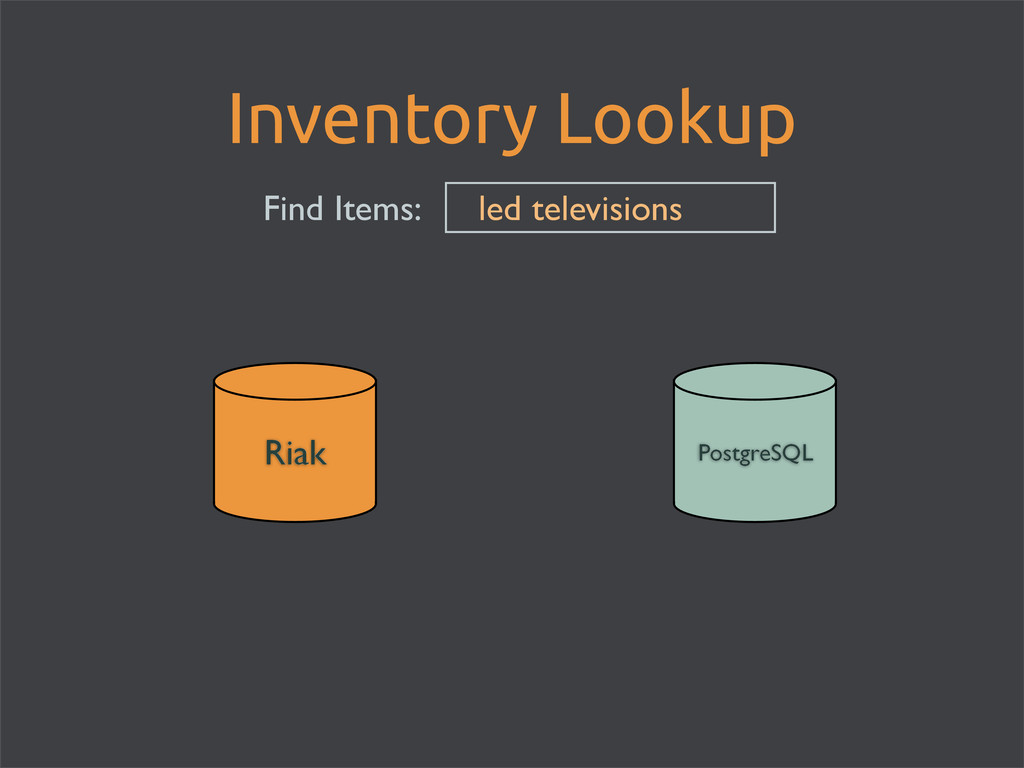
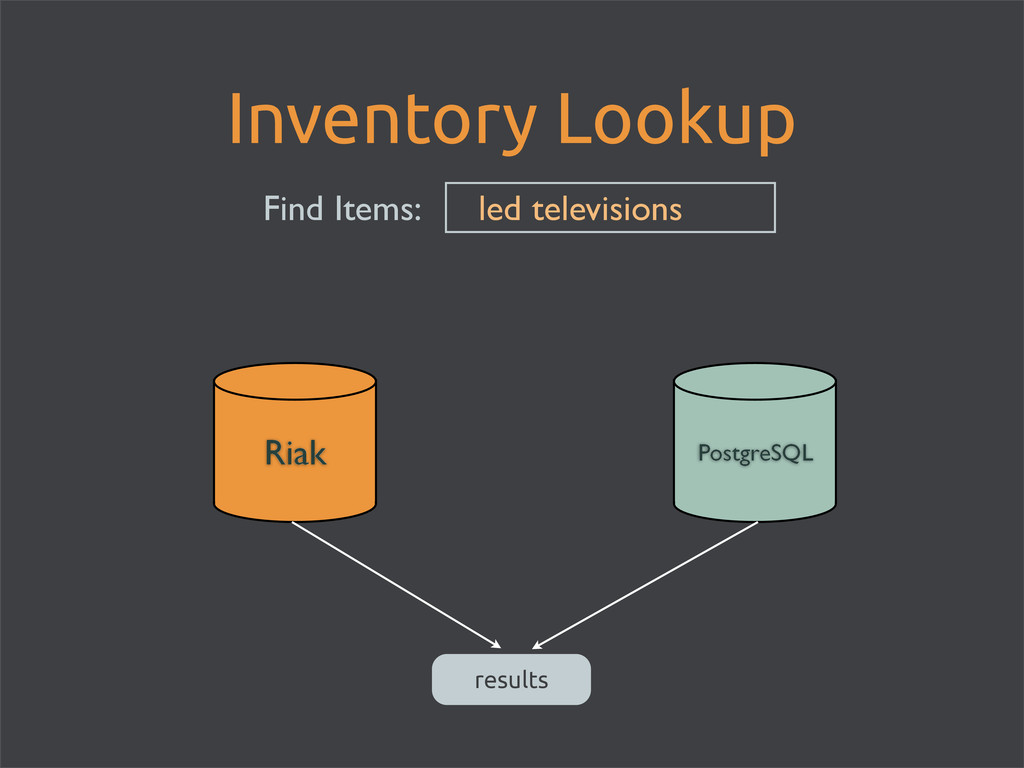
enable Riak Search for full-text searching • store images directly in Riak • maintain an inventory count in PostgreSQL • use matching product_id’s • every* hit to Riak = hit to Postgres • easy schema updates
centric apps • unstructured data in Riak, else: PG • kiip - platform for in-game rewards • K/V data in Riak • rich queries in PostgreSQL • http://blog.engineering.kiip.me/post/20988881092/a-year-with-mongodb
{kind=link}
![$ whoami • Tom Santero • @tsantero • [email protected]](https://files.speakerdeck.com/presentations/505c4e6bae04f500020434ce/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}