Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AWSにテストデータをかっこよく投入したいのでAWS SDK for pandasと向き合うこ...
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
watany
October 08, 2022
Technology
2.9k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AWSにテストデータをかっこよく投入したいのでAWS SDK for pandasと向き合うことにした
JAWS DAYS 2022 - Satellitesでお話しした内容(その2)です。
watany
October 08, 2022
More Decks by watany
See All by watany
AIエージェントがあれば技術書なんてすぐ書けるでしょ→無理でした
watany
4
440
穢れた技術選定について
watany
20
6.3k
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
330
The Tyranny of Not Measuring
watany
5
410
新しいVibe Codingと”自走”について
watany
6
430
Equip GitHub Copilot CLI
watany
3
1.5k
SkillsをS3 Filesに置く時のあれこれ
watany
4
2.4k
App Runner最近使ってなかったのなんでだっけ
watany
1
140
CDK Deployのための ”反響定位”
watany
5
1.1k
Other Decks in Technology
See All in Technology
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
540
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
180
テックカンファレンス三大ステークホルダーの文化人類学 ─ 違いを認め合う関係性作り
bash0c7
2
580
それでも、技術なブログを書く理由 #kichijojipm / Why I Still Write Tech Blogs Even Now
shinkufencer
0
860
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
480
書籍セキュアAPIについて
riiimparm
0
330
Power Automateアップデート情報
miyakemito
0
240
Git 研修【MIXI 26新卒技術研修】#2
mixi_engineers
PRO
1
170
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
340
歴史から理解するクラウドインフラのしくみ
kizawa2020
0
130
AIで楽になるはずが、なぜ疲れる?
kinopeee
0
100
Jitera Company Deck
jitera
0
550
Featured
See All Featured
How to Ace a Technical Interview
jacobian
281
24k
How to Talk to Developers About Accessibility
jct
2
430
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.3k
Building Adaptive Systems
keathley
44
3.1k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Design in an AI World
tapps
1
270
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.7k
Build your cross-platform service in a week with App Engine
jlugia
234
18k
A better future with KSS
kneath
240
18k
Building AI with AI
inesmontani
PRO
1
1.1k
Transcript
JAWS DAYS 2022 - Satellites AWS にテストデータをかっこよく投入したいので AWS SDK for
pandas と 向き合うことにした 2022/10/08 渡邉 洋平 1
About me Watanabe Yohei (Twitter: _@watany) Company Name: NTT TechnoCross
Corporation Role: AWS Architect, Instructor, CCoE AWS, CDK 2022 APN ALL AWS Certifications Engineers AWS Community Builder(Cloud Operations) Contributer (AWS CDK) 2
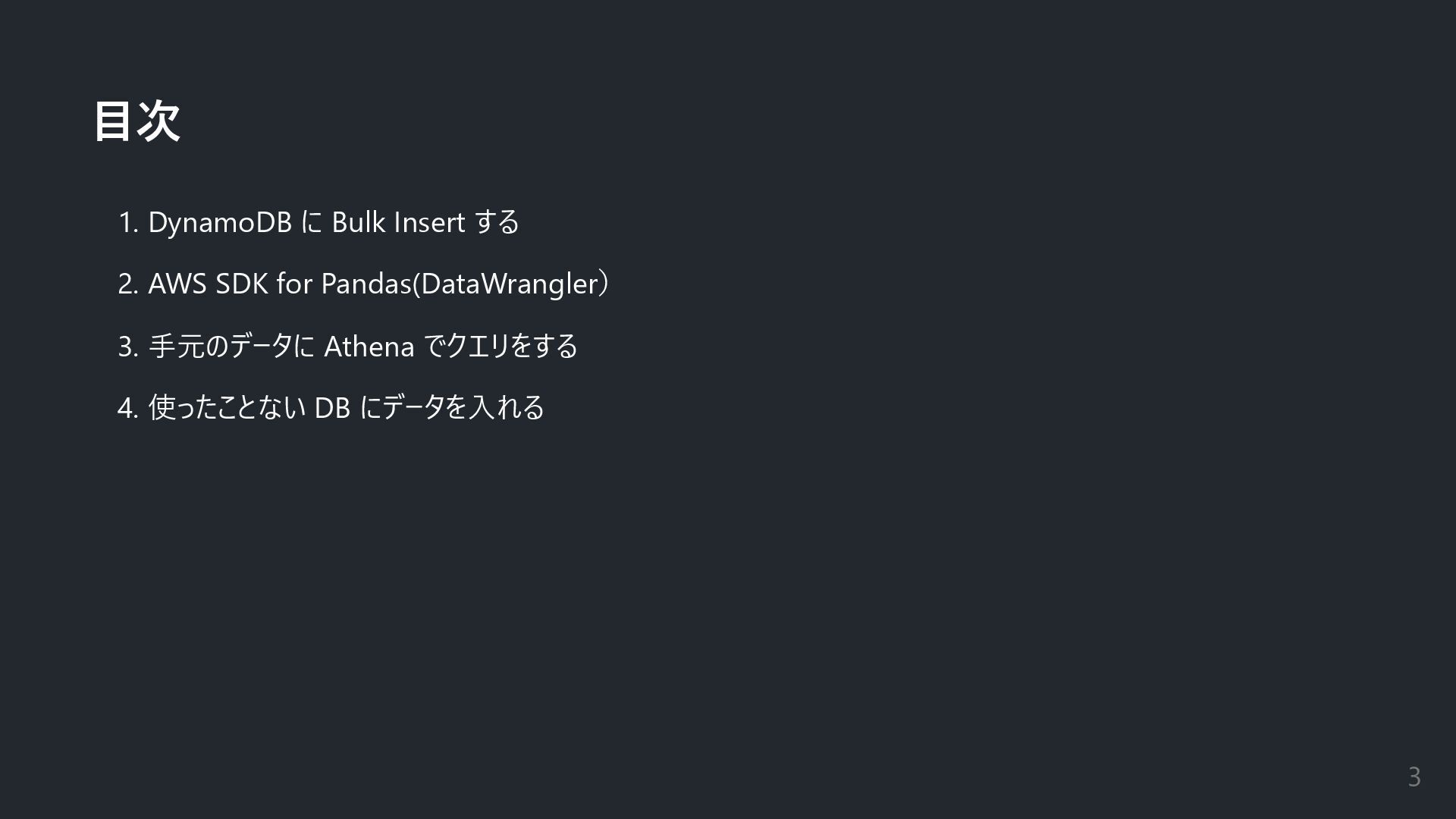
目次 1. DynamoDB に Bulk Insert する 2. AWS SDK
for Pandas(DataWrangler) 3. 手元のデータに Athena でクエリをする 4. 使ったことない DB にデータを入れる 3
1. DynamoDB に Bulk Insert する 4
例: 100,000 Records in DynamoDB が欲しい! みつもり: 多分 2h くらい
実際に必要な時間は i. DB 構築: 0.25h ii. データ投入: 0.5h iii. 手順化: 0.25h iv. バッファ: 0.5h 5
何とかなりそう i. DB 構築 CDK でスッと作れる DB のスキーマは…主キーまでは定義できる iii. 手順化
また同じ作業やり直すかも。Markdown で残す 6
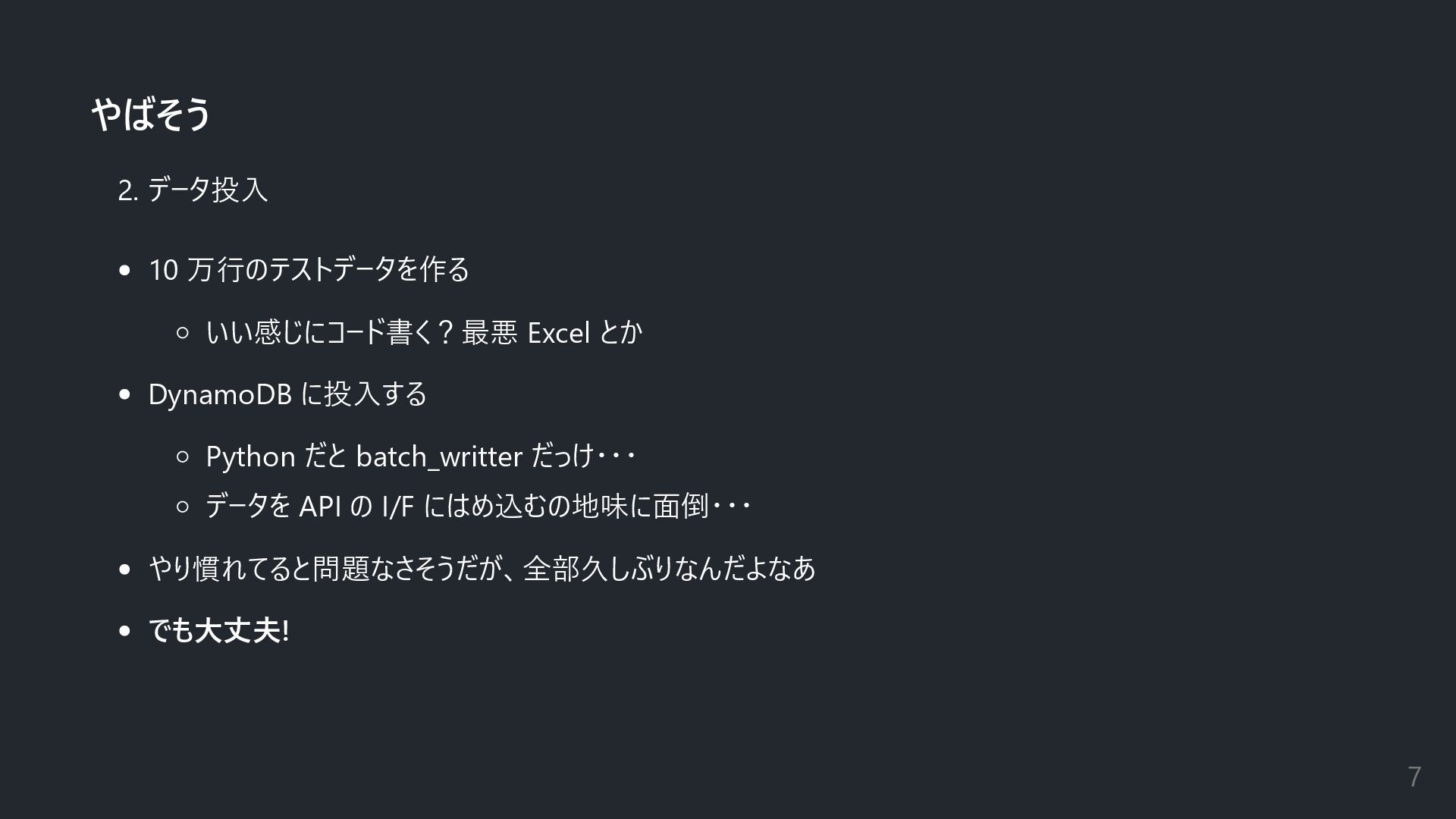
やばそう 2. データ投入 10 万行のテストデータを作る いい感じにコード書く?最悪 Excel とか DynamoDB に投入する
Python だと batch_writter だっけ・・・ データを API の I/F にはめ込むの地味に面倒・・・ やり慣れてると問題なさそうだが、全部久しぶりなんだよなあ でも大丈夫! 7
import import import import numpy numpy numpy numpy as as
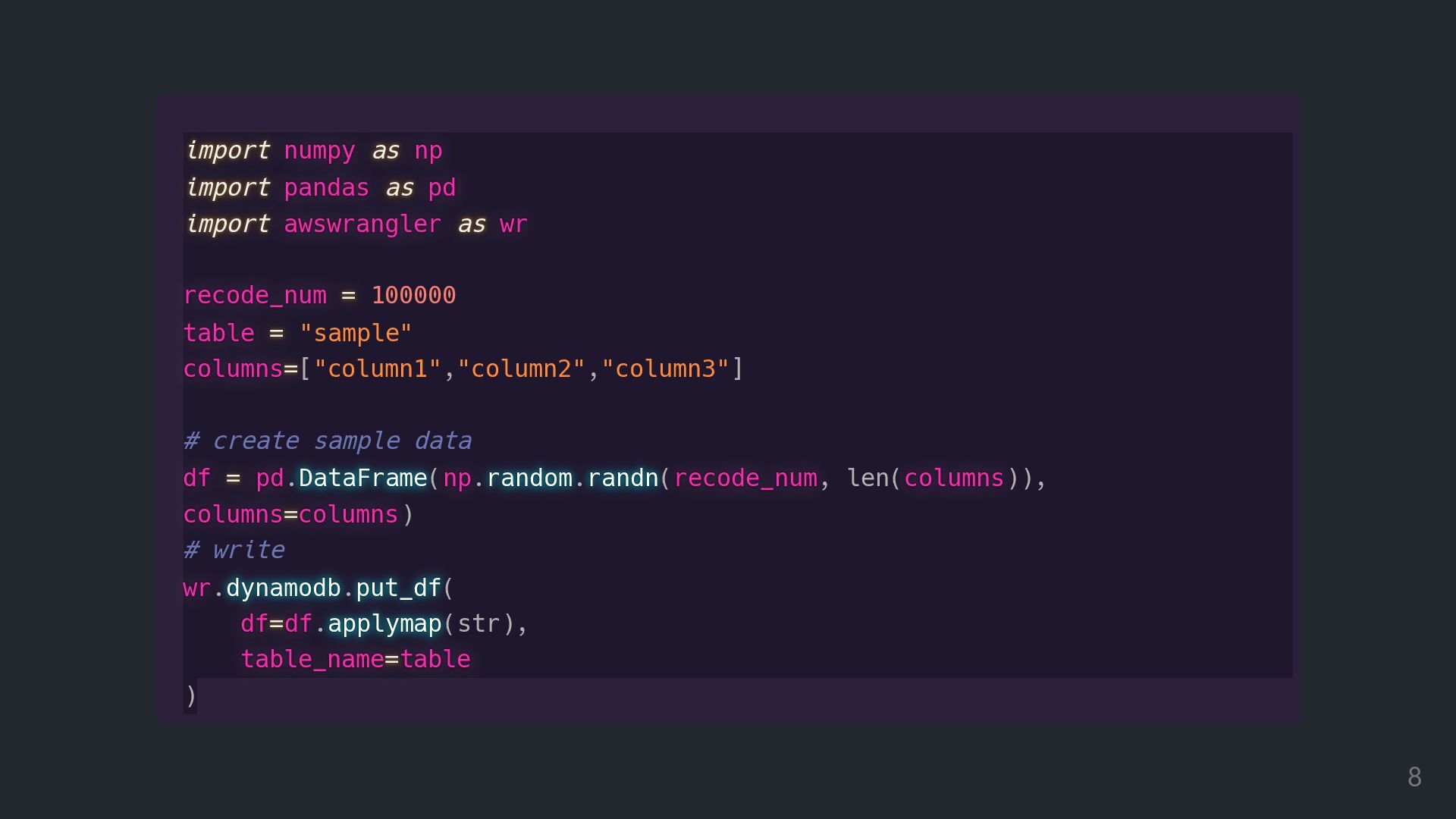
as as np np np np import import import import pandas pandas pandas pandas as as as as pd pd pd pd import import import import awswrangler awswrangler awswrangler awswrangler as as as as wr wr wr wr recode_num recode_num recode_num recode_num = = = = 100000 table table table table = = = = "sample" columns columns columns columns= = = =["column1","column2","column3"] # create sample data df df df df = = = = pd pd pd pd.DataFrame DataFrame DataFrame DataFrame DataFrame(np np np np.random random random random random.randn randn randn randn randn(recode_num recode_num recode_num recode_num, len(columns columns columns columns)), columns columns columns columns= = = =columns columns columns columns) # write wr wr wr wr.dynamodb dynamodb dynamodb dynamodb dynamodb.put_df put_df put_df put_df put_df( df df df df= = = =df df df df.applymap applymap applymap applymap applymap(str), table_name table_name table_name table_name= = = =table table table table ) 8
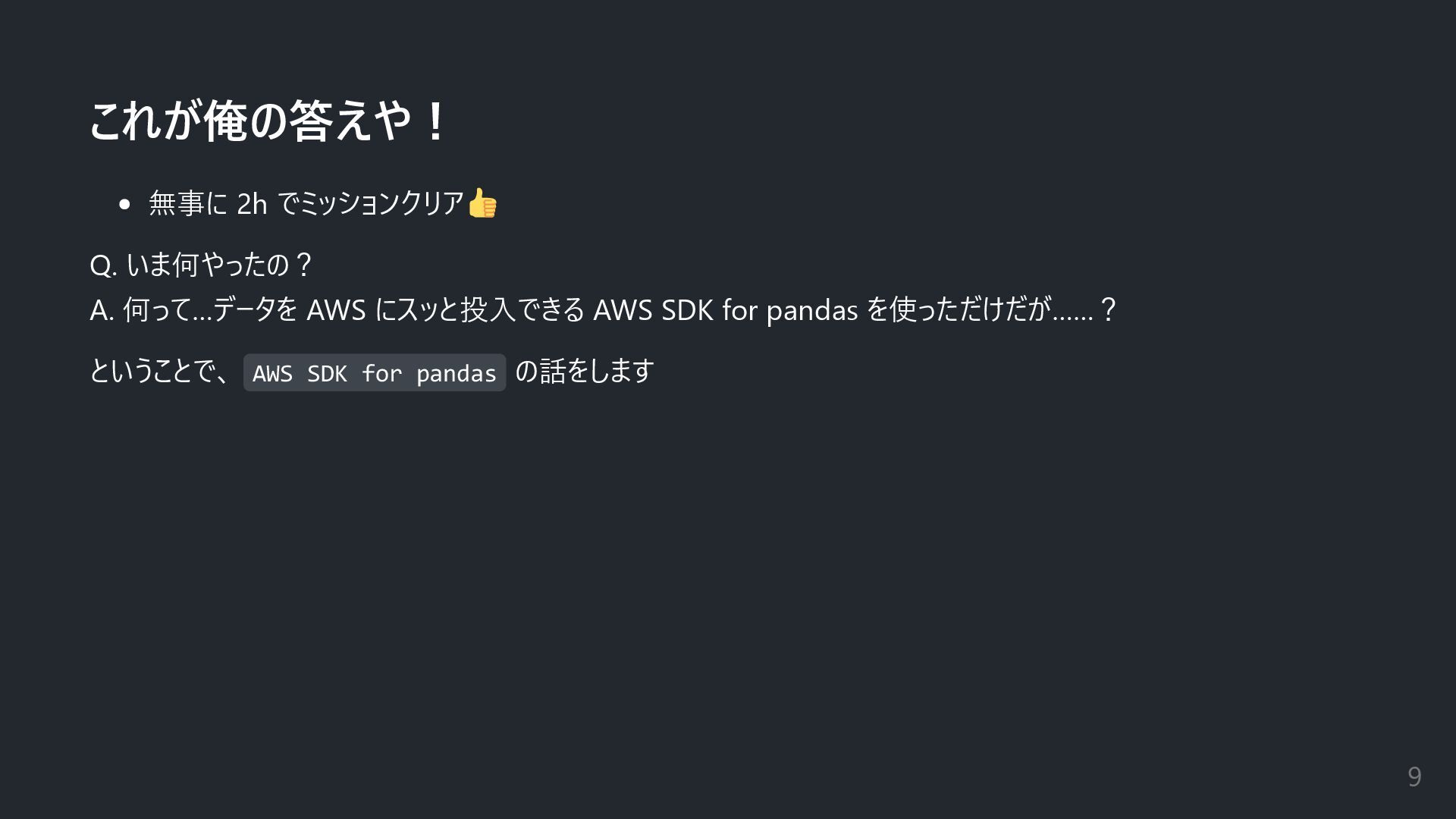
これが俺の答えや! 無事に 2h でミッションクリア Q. いま何やったの? A. 何って…データを AWS にスッと投入できる
AWS SDK for pandas を使っただけだが……? ということで、 AWS SDK for pandas の話をします 9
2. AWS SDK for Pandas(Data Wrangler) 10
AWS SDK for pandas Easy integration with Athena, Glue, Redshift,
Timestream, OpenSearch, Neptune, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretManager, PostgreSQL, MySQL, SQLServer and S3 (Parquet, CSV, JSON and EXCEL). 要は Pandas の Dataframe 形式で、AWS リソースへデ ータを出し入れできる。 on several platforms (AWS Lambda, AWS Glue Python Shell, EMR, EC2, on-premises, Amazon SageMaker, local, etc). Python ベースでの基盤なら動かせるので、オンプレから 各種マネージドサービス上でも簡単動作 11
read_* to_* CSV XLS PARQUET HTML <> HDF5 JSON {}
GBQ SQL ... CSV XLS PARQUET HTML <> HDF5 JSON {} GBQ SQL ... What's pandas? 言わずと知れた Python のデータ分析ライブラリ。 n 次元配列計算ライブラリ numpy をベースに、数値以 外のデータも一通り抽象化 ビッグデータや ML 方面での ETL 処理が主。 テストデータの投入って Extract, Transform, Load ですよね(暴論) 12
前からご存じの方向け Q. 変な名前で呼んでるけど、それって DataWrangler だ よね? A. CFP 書いてた時(2020/8/XX)まではそう 参
考:https://twitter.com/AWSOpen/status/1564 613913416704012 ぶっちゃけ呼びずらいので、以降モジュール名でもある DataWrangler と呼びます 13
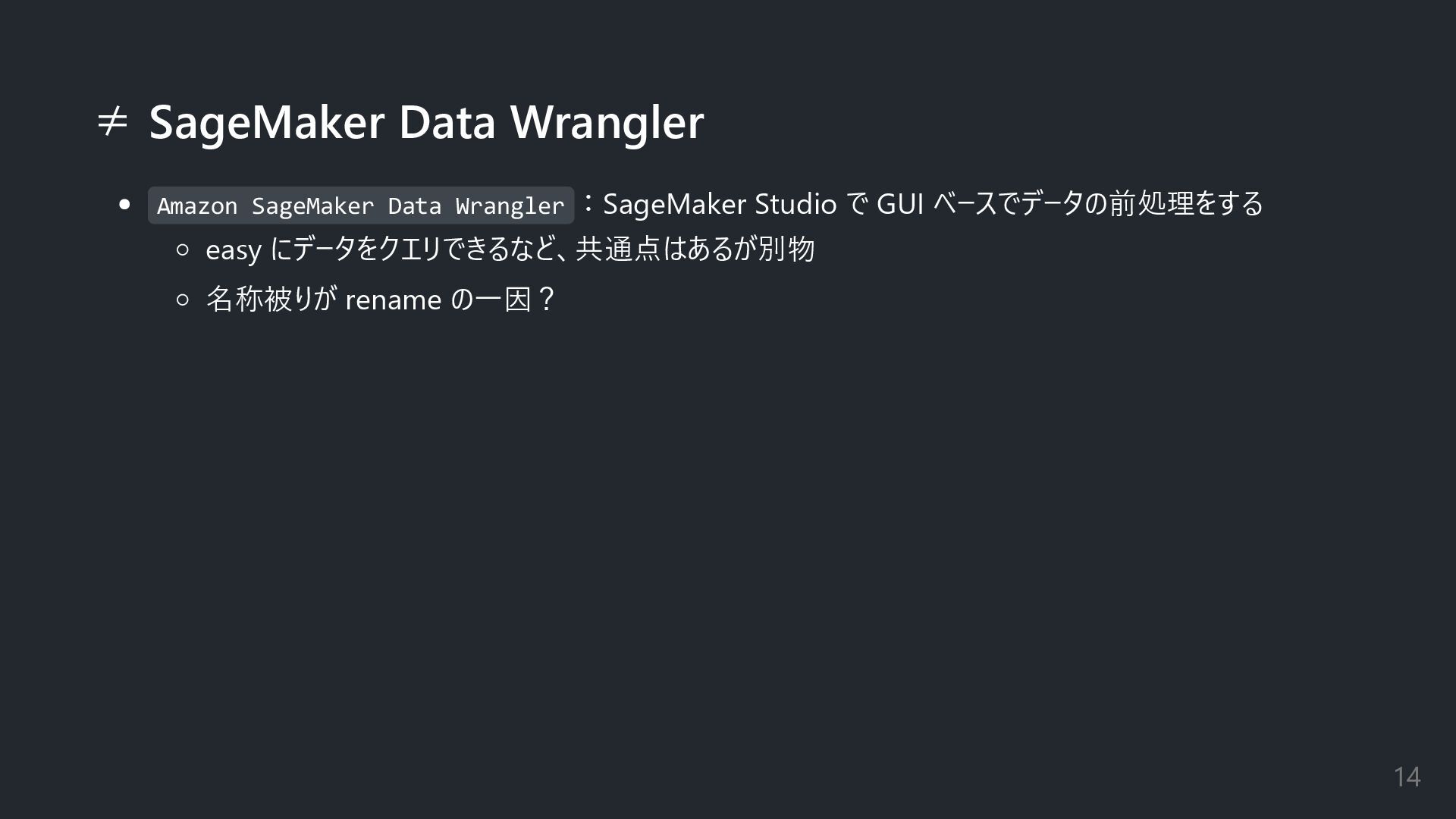
≠ SageMaker Data Wrangler Amazon SageMaker Data Wrangler :SageMaker Studio
で GUI ベースでデータの前処理をする easy にデータをクエリできるなど、共通点はあるが別物 名称被りが rename の一因? 14
大量データをリソースに入れるのしんどい AWS リソース構築の情報は充実している CDK、Terraform、other IaC... SDK の help を横目に JSON
職人 Excel→CSV→ some logic →AWS API だったのが、 DataWrangler で解決 15
3. 手元のデータを Athena で Query する 16
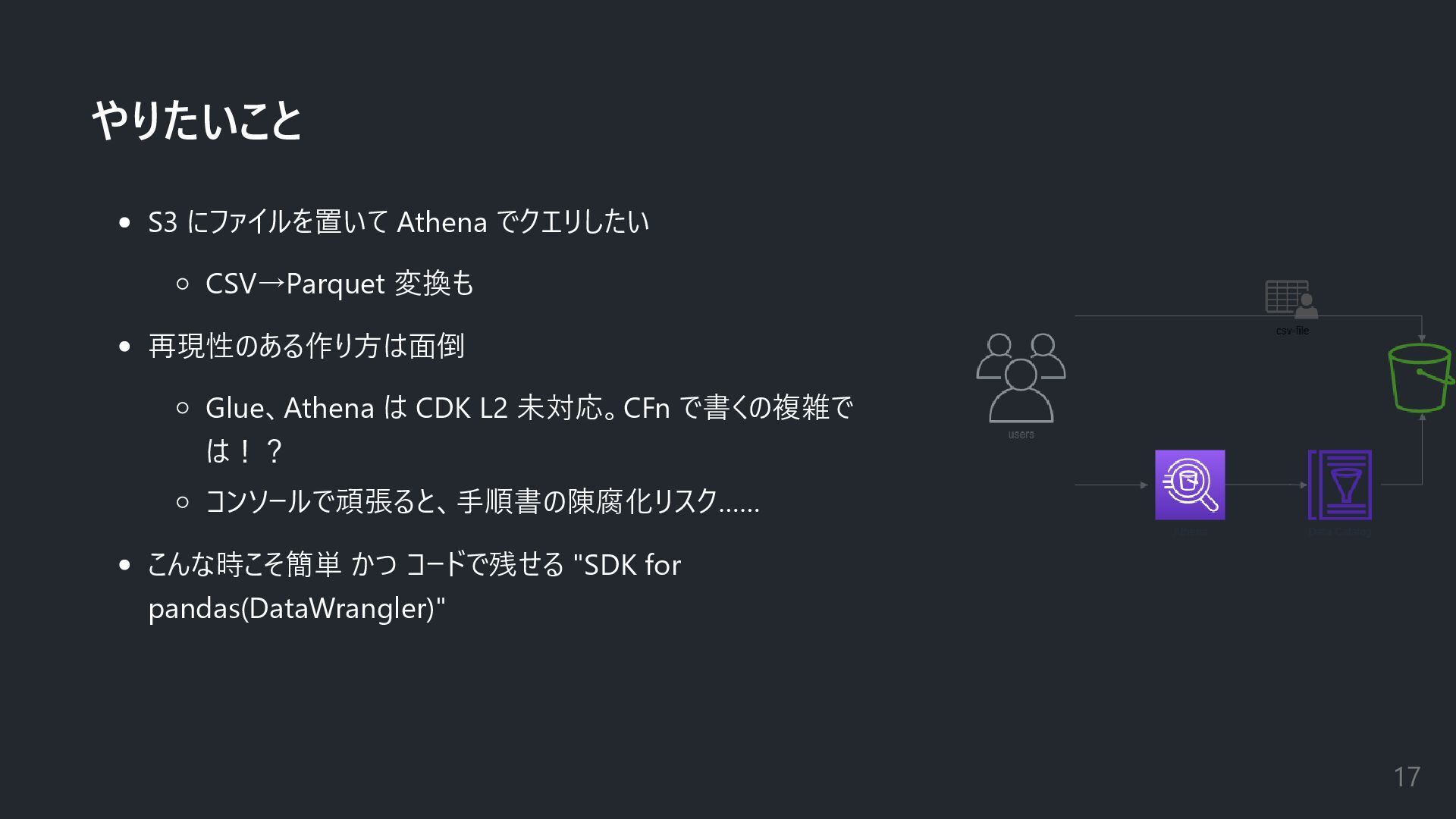
やりたいこと S3 にファイルを置いて Athena でクエリしたい CSV→Parquet 変換も 再現性のある作り方は面倒 Glue、Athena は
CDK L2 未対応。CFn で書くの複雑で は!? コンソールで頑張ると、手順書の陳腐化リスク…… こんな時こそ簡単 かつ コードで残せる "SDK for pandas(DataWrangler)" 17
import import import import awswrangler awswrangler awswrangler awswrangler as as
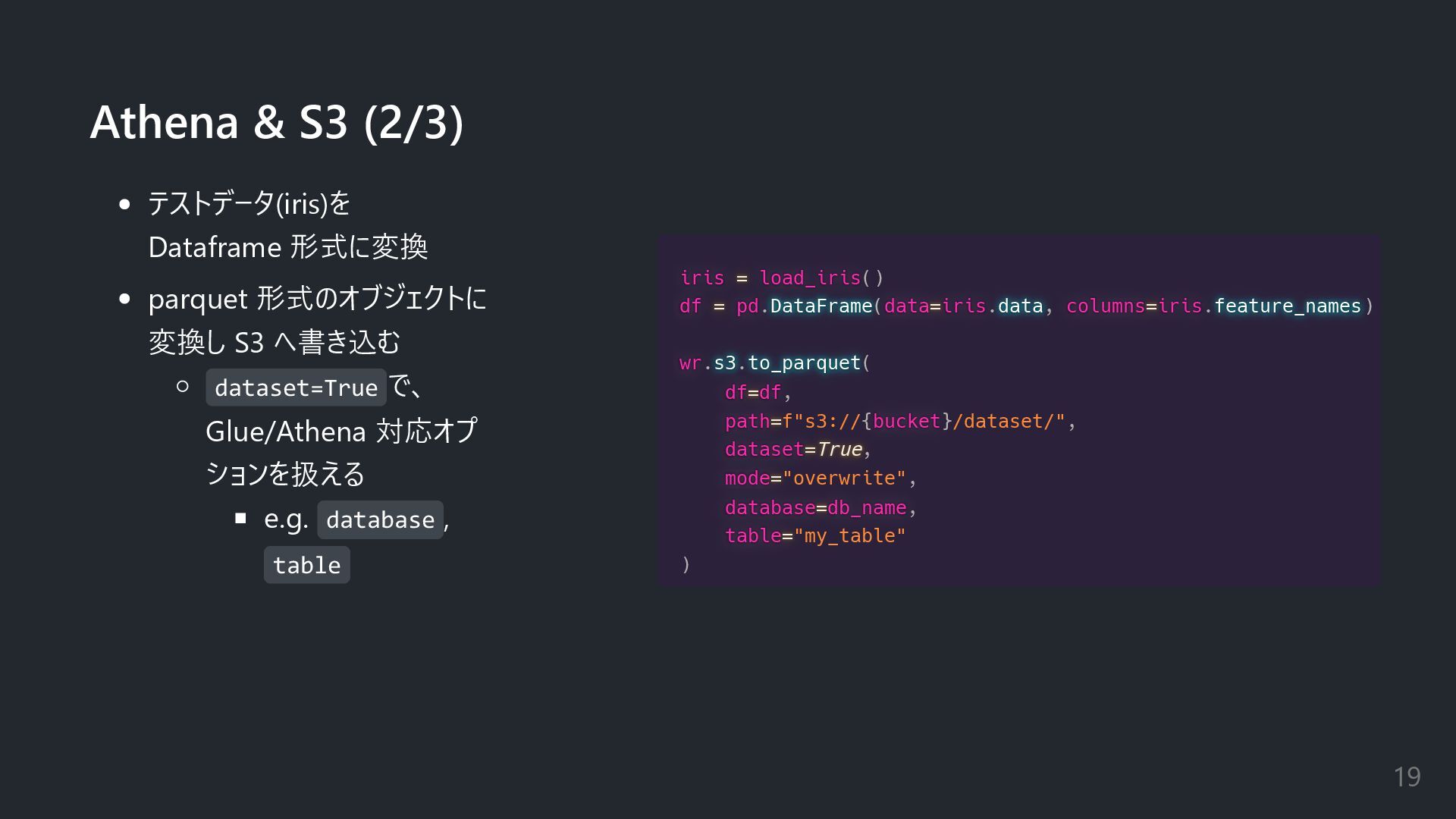
as as wr wr wr wr import import import import pandas pandas pandas pandas as as as as pd pd pd pd from from from from sklearn sklearn sklearn sklearn.datasets datasets datasets datasets datasets import import import import load_iris load_iris load_iris load_iris db_name db_name db_name db_name = = = = "aws_sdk_pandas" catalog_db catalog_db catalog_db catalog_db = = = = wr wr wr wr.catalog catalog catalog catalog catalog.databases databases databases databases databases() if if if if not not not not db_name db_name db_name db_name in in in in catalog_db catalog_db catalog_db catalog_db.values values values values values: wr wr wr wr.catalog catalog catalog catalog catalog.create_database create_database create_database create_database create_database(db_name db_name db_name db_name) Athena & S3 (1/3) モジュール読み込み awswrangler, pandas: 今回紹介 scikit-learn の datasets: サンプル Glue の DB 作成 wr.catalog.database s() で 存在をチェック 18
iris iris iris iris = = = = load_iris load_iris
load_iris load_iris() df df df df = = = = pd pd pd pd.DataFrame DataFrame DataFrame DataFrame DataFrame(data data data data= = = =iris iris iris iris.data data data data data, columns columns columns columns= = = =iris iris iris iris.feature_names feature_names feature_names feature_names feature_names) wr wr wr wr.s3 s3 s3 s3 s3.to_parquet to_parquet to_parquet to_parquet to_parquet( df df df df= = = =df df df df, path path path path= = = =f"s3://{bucket bucket bucket bucket}/dataset/", dataset dataset dataset dataset= = = =True True True True, mode mode mode mode= = = ="overwrite", database database database database= = = =db_name db_name db_name db_name, table table table table= = = ="my_table" ) Athena & S3 (2/3) テストデータ(iris)を Dataframe 形式に変換 parquet 形式のオブジェクトに 変換し S3 へ書き込む dataset=True で、 Glue/Athena 対応オプ ションを扱える e.g. database , table 19
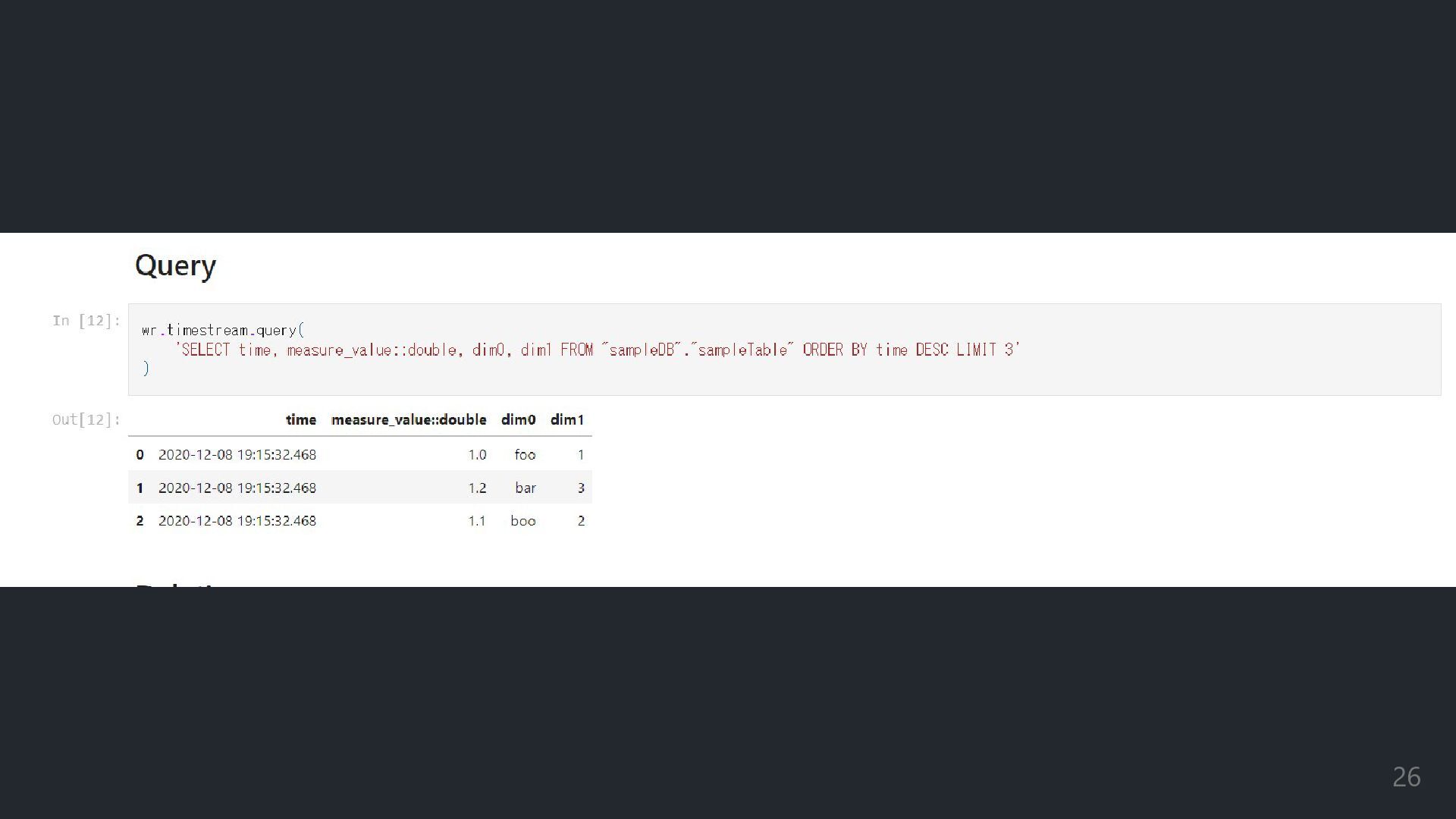
query query query query = = = = "SELECT *
FROM my_table where sepal_length_cm_ > 5.2", result result result result = = = = wr wr wr wr.athena athena athena athena athena.read_sql_query read_sql_query read_sql_query read_sql_query read_sql_query( database database database database= = = =db_name db_name db_name db_name ) print(result result result result) Athena & S3 (3/3) 参照クエリをスッと投げ、結果 を表示 今回も無事にミッションクリア 20
ちなみに 通常の SDK(boto3)で必要だった処理 dataset to parquet Glue Setting(DB & TABLE)
実際はもうちょい面倒 Athena Query クエリは非同期実行。結果の表示は waiter と取得処理が必要 「実際に書くと面倒な BoilerPlate」からの解放 21
4. 未知の DB と立ち向かう 22
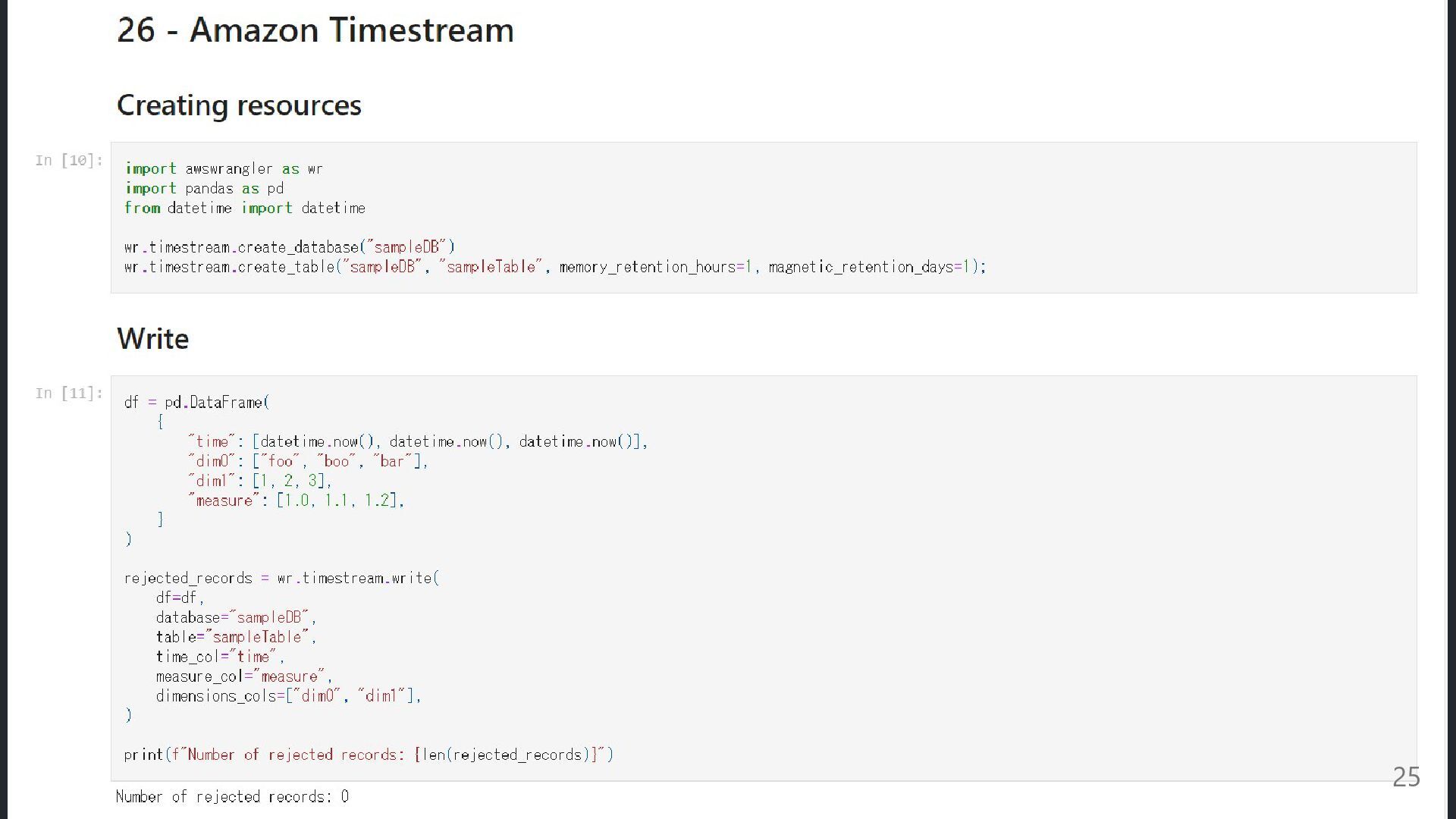
Q1. この DB を知っていますか? Amazon Timestream サーバレスな時系列データベースサービス 皆さんはご存じですか? 使っている 使ったことない
名前だけ知ってる Q2. 実際に使ったことはありますか? 少なくとも私はない GA は 2020/10 だが、日本(ap-northeast-1)では 2022.7 使いたいユースケースにまだ出会えていない 23
ない話 AWS 使ったことあるんだよね? は、はい TimeStream ってやつ、よくわかんなくて。 AWS 得意なんだよね?テストデータ 10 万
件入れといてくれない? ?????????? 24
25
26
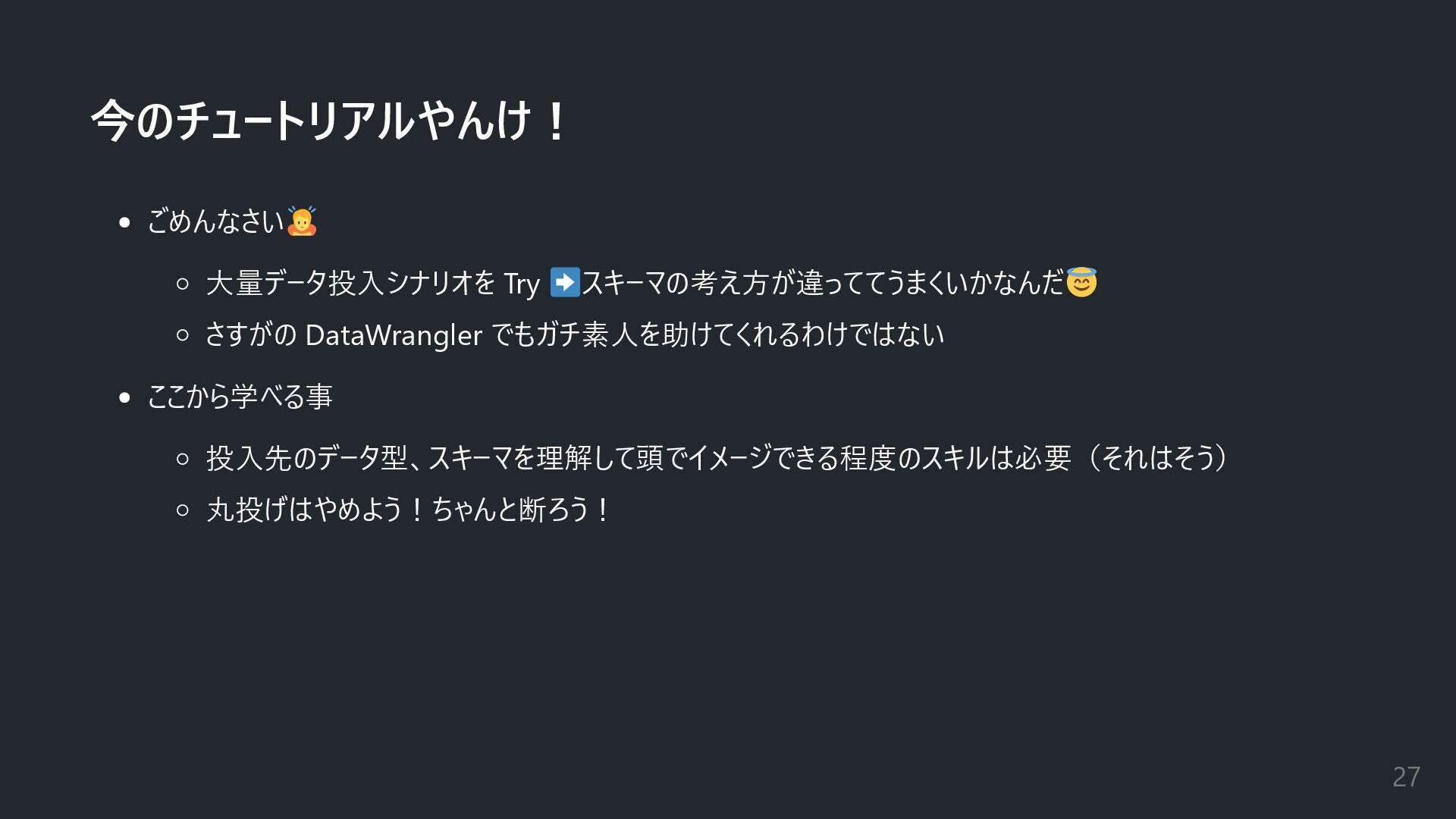
今のチュートリアルやんけ! ごめんなさい 大量データ投入シナリオを Try スキーマの考え方が違っててうまくいかなんだ さすがの DataWrangler でもガチ素人を助けてくれるわけではない ここから学べる事 投入先のデータ型、スキーマを理解して頭でイメージできる程度のスキルは必要(それはそう)
丸投げはやめよう!ちゃんと断ろう! 27
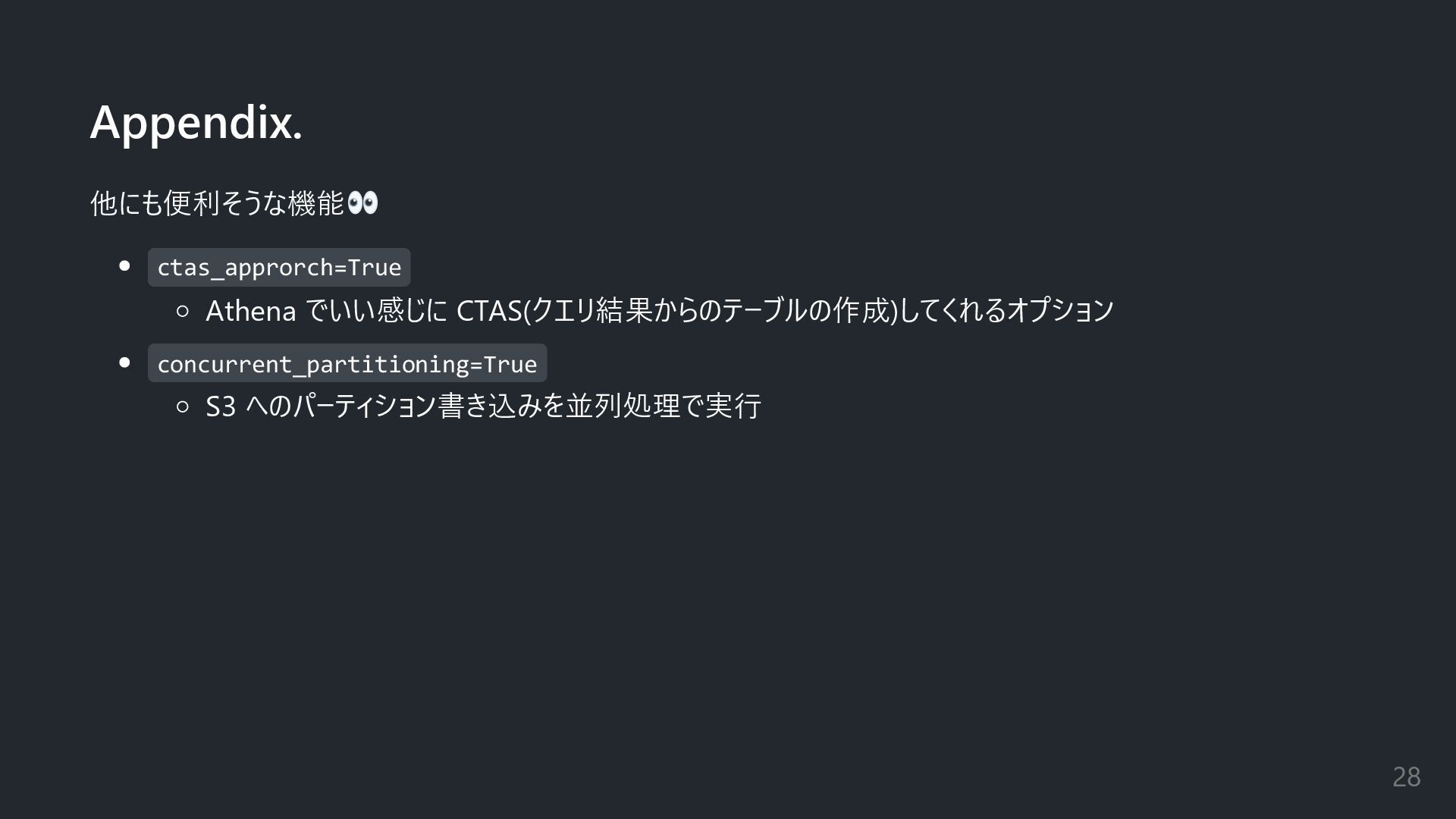
Appendix. 他にも便利そうな機能 ctas_approrch=True Athena でいい感じに CTAS(クエリ結果からのテーブルの作成)してくれるオプション concurrent_partitioning=True S3 へのパーティション書き込みを並列処理で実行 28
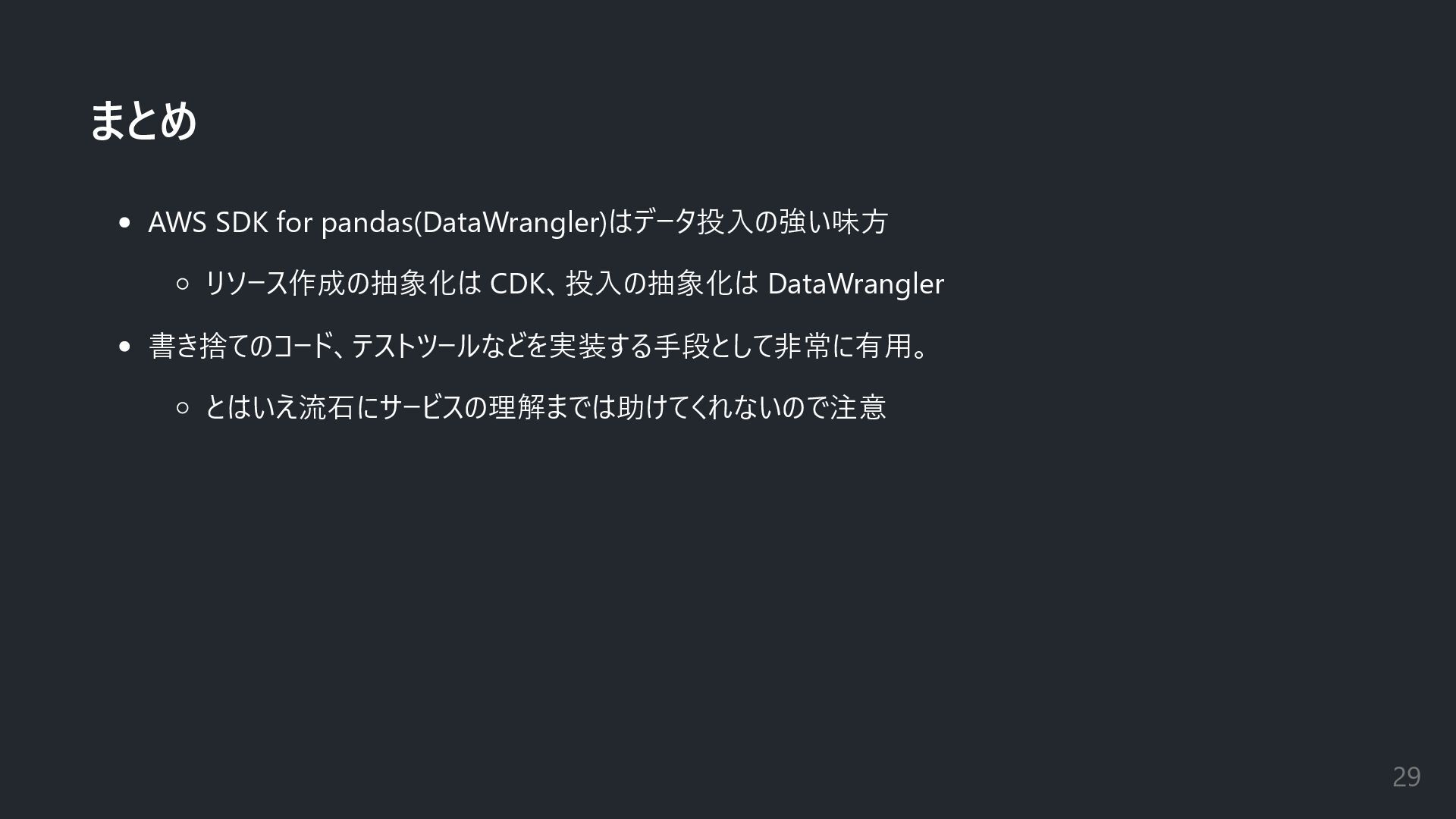
まとめ AWS SDK for pandas(DataWrangler)はデータ投入の強い味方 リソース作成の抽象化は CDK、投入の抽象化は DataWrangler 書き捨てのコード、テストツールなどを実装する手段として非常に有用。 とはいえ流石にサービスの理解までは助けてくれないので注意
29
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}