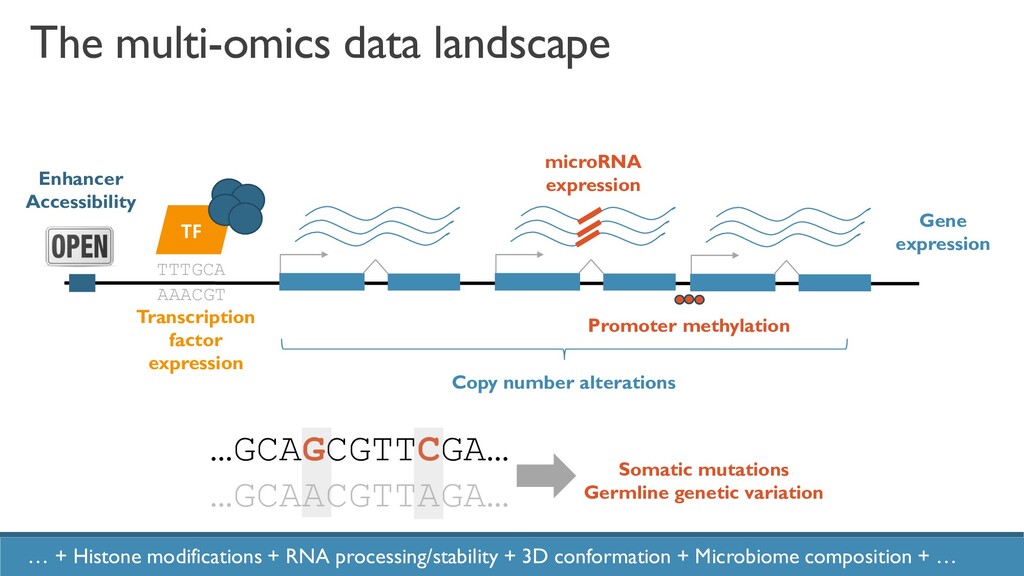
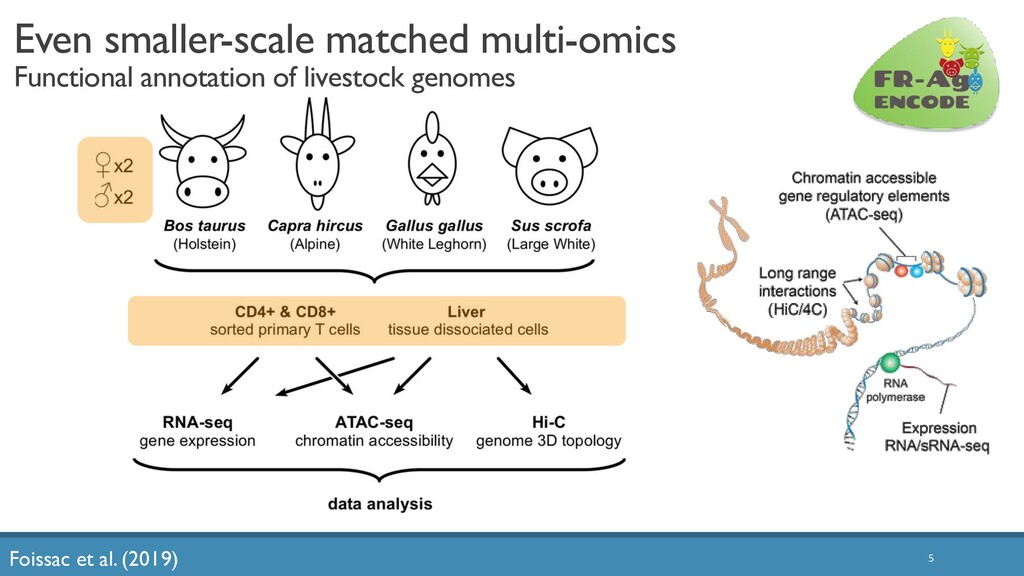
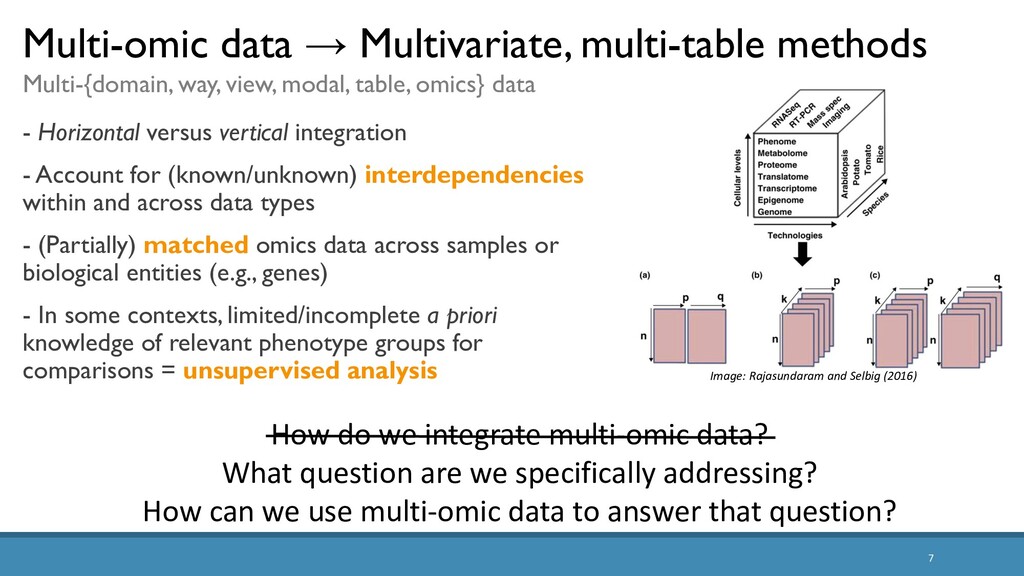
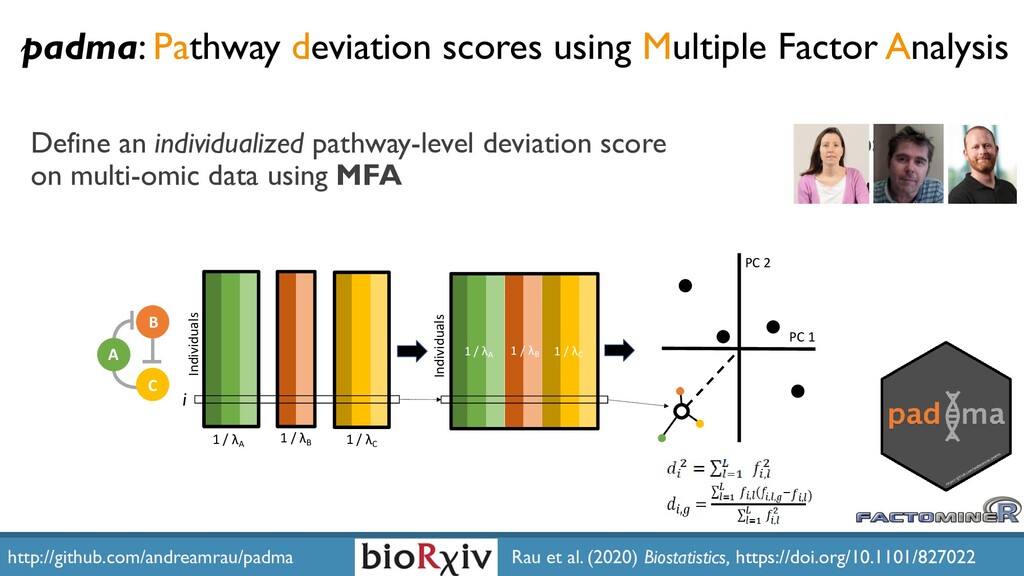
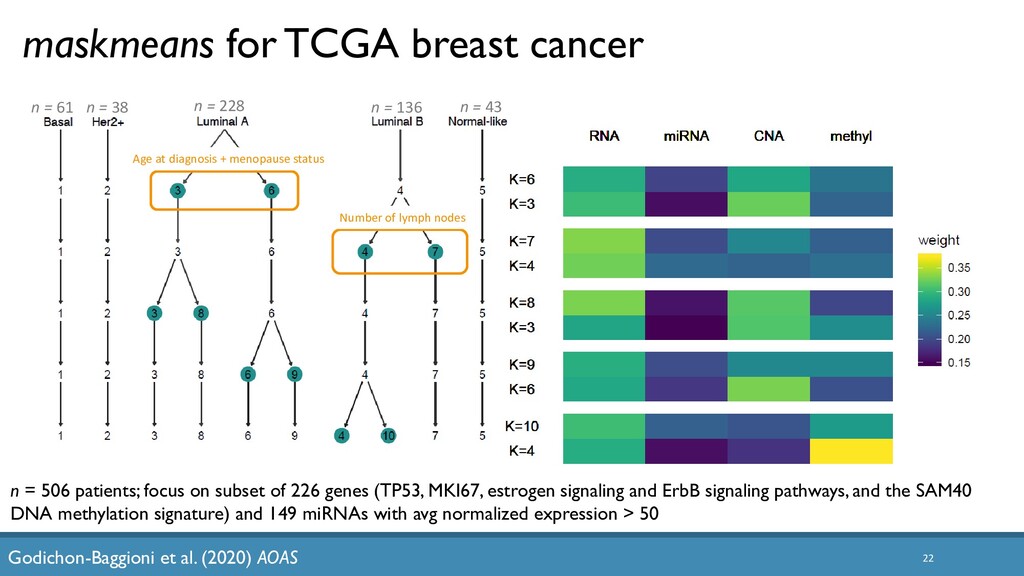
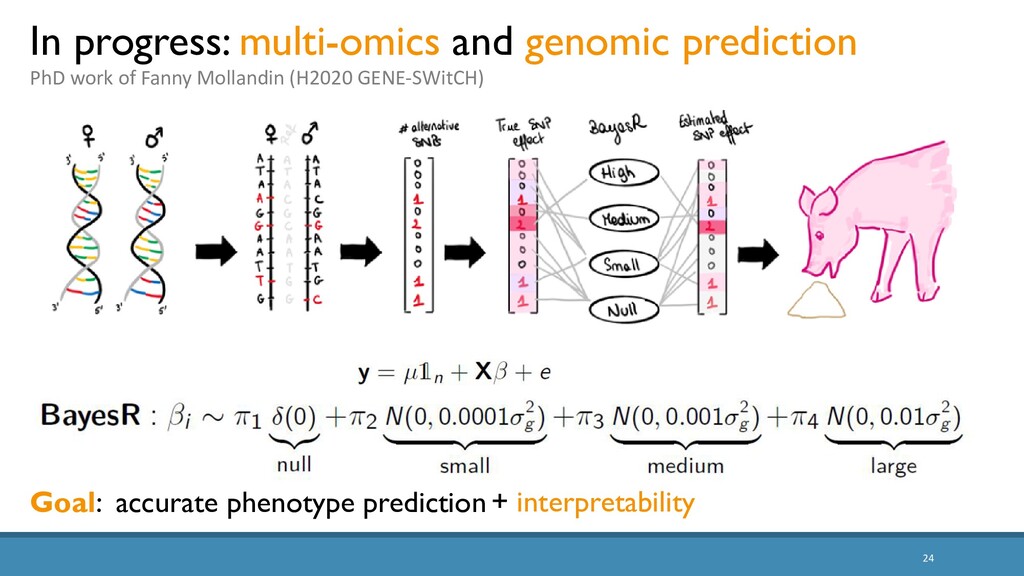
The increased availability and affordability of high-throughput sequencing technologies in recent years has facilitated the use of multi-omic studies to expand and enrich our understanding of complex systems across hierarchical biological levels. Integrative methods for these heterogeneous and multi-faceted ‘omics data have shown promise for enhancing the interpretability of exploratory analyses, improving predictive power, and contributing to a holistic understanding of systems biology. However, such integrative analyses are accompanied by several major obstacles, including the unknown hierarchy and potentially ambiguous relationships among different sources of data, high dimensionality coupled with small sample sizes, issues due to batch effects and quality control, potentially incomplete or missing data… and the occasional difficulty in posing well-defined and answerable research questions of such data. In light of these challenges, in this talk I will discuss two recent methodological contributions to exploratory integrative multi-omic analyses: (1) padma, a multiple factor analysis approach for quantifying and visualizing individualized multi-omic pathway deviation patterns; and (2) maskmeans, an approach for aggregating/splitting an existing clustering partition using multi-view data. Finally, I will discuss some practical considerations for multi-omics integration in practice, as well as some current and future areas of methodological research in this area.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}