Presented at DevOpsDays Minneapolis 2017.
More info and video in blog post: TBD
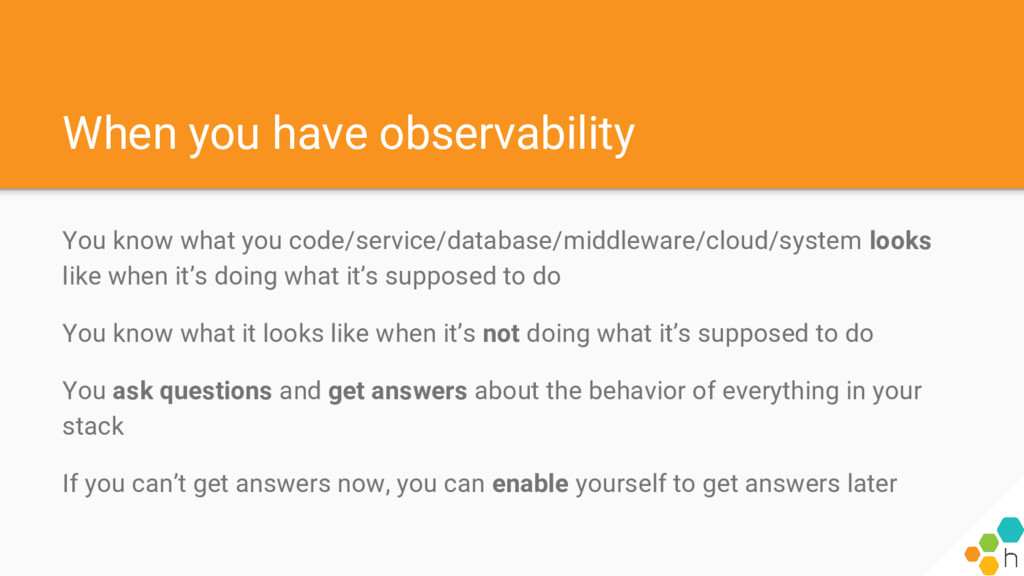
Operating with insufficient data is a failing proposition; you can’t operate what you can’t measure. So we have to measure things, and measurement starts early in the development lifecycle.
Let’s walk through a brief field guide to the theory and practice of observability
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Observability [Wikipedia formal] A system is said to be observable](https://files.speakerdeck.com/presentations/7f77cd49d0e64abf858e5c665a34e031/slide_7.jpg){kind=link}
![Observability [Wikipedia not formal] One can determine the behavior of](https://files.speakerdeck.com/presentations/7f77cd49d0e64abf858e5c665a34e031/slide_8.jpg){kind=link}
![Observability [Sam Stokes] Observability is a combination of a property](https://files.speakerdeck.com/presentations/7f77cd49d0e64abf858e5c665a34e031/slide_9.jpg){kind=link}
![Observability [Me] Observability is a combination of a property of](https://files.speakerdeck.com/presentations/7f77cd49d0e64abf858e5c665a34e031/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
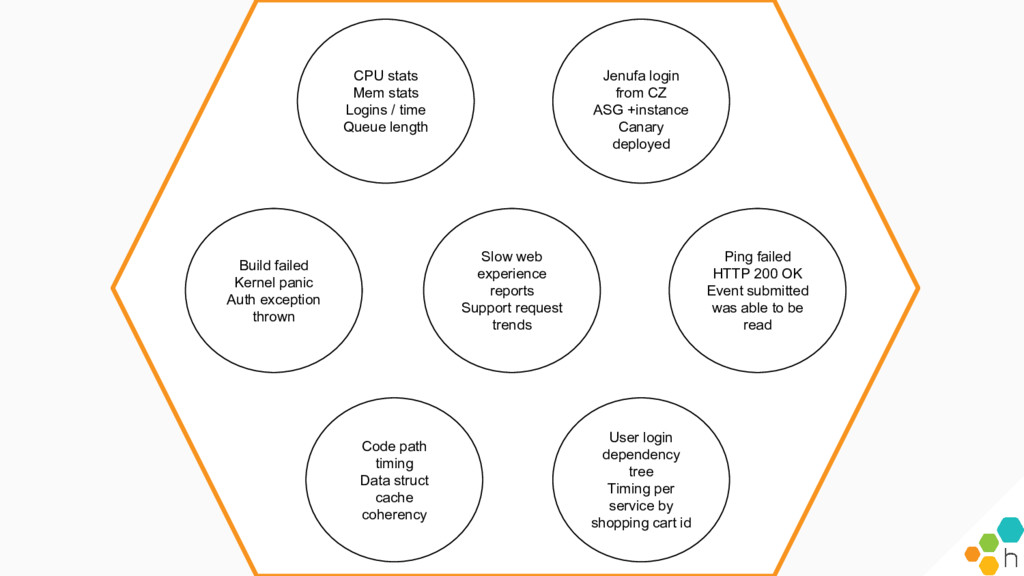{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! [email protected] | @aneel Try Honeycomb! honeycomb.io/signup](https://files.speakerdeck.com/presentations/7f77cd49d0e64abf858e5c665a34e031/slide_31.jpg){kind=link}
{kind=link}