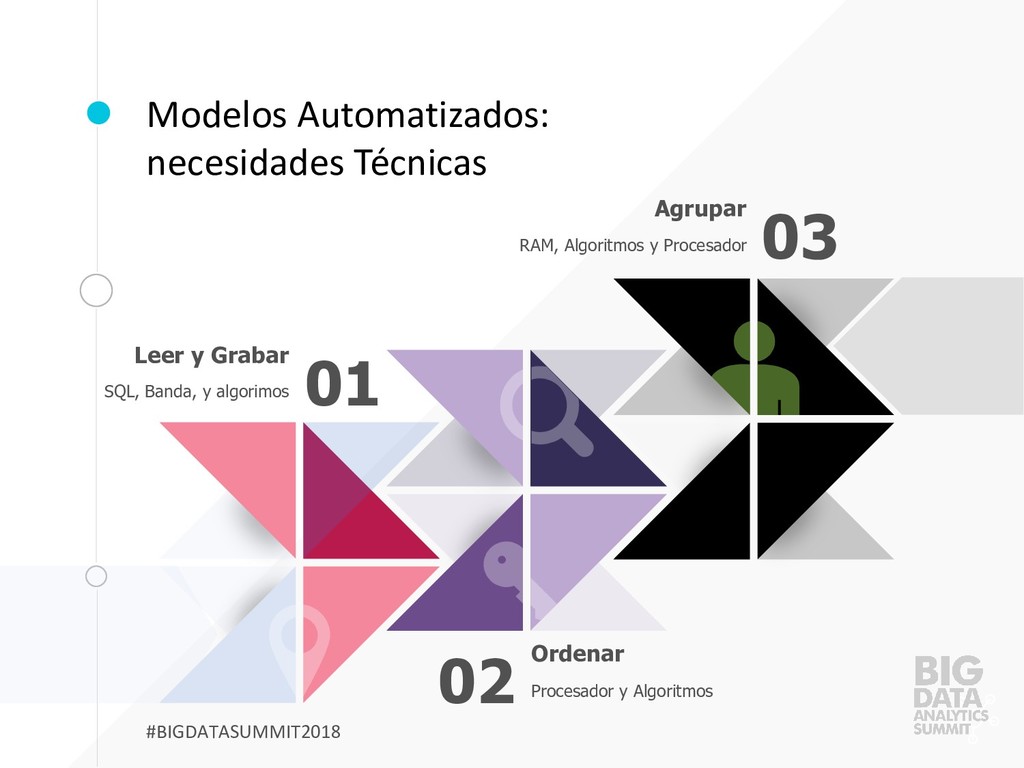
es poco eficiente Cargar la data 01 … y obtener un modelo de calidad razonable Procesar la información 02 Para necesitar una intervención humana mínima Automatizar 03
un procesamiento optimo de la data (4.000.000 filas / segundo). Alta Velocidad 03 Con R, Python y JavaScript Multi-hilo, nodos especiales para transformaciones analíticas…. ¡Sin RAM! Diseñado para Analytics 04 ODBC, OleDB y conector batch DB2, Teradata, Oracle. Conectores Optimizados 01 Para minimizar el espacio y el tiempo de lectura Alta Compresión 02
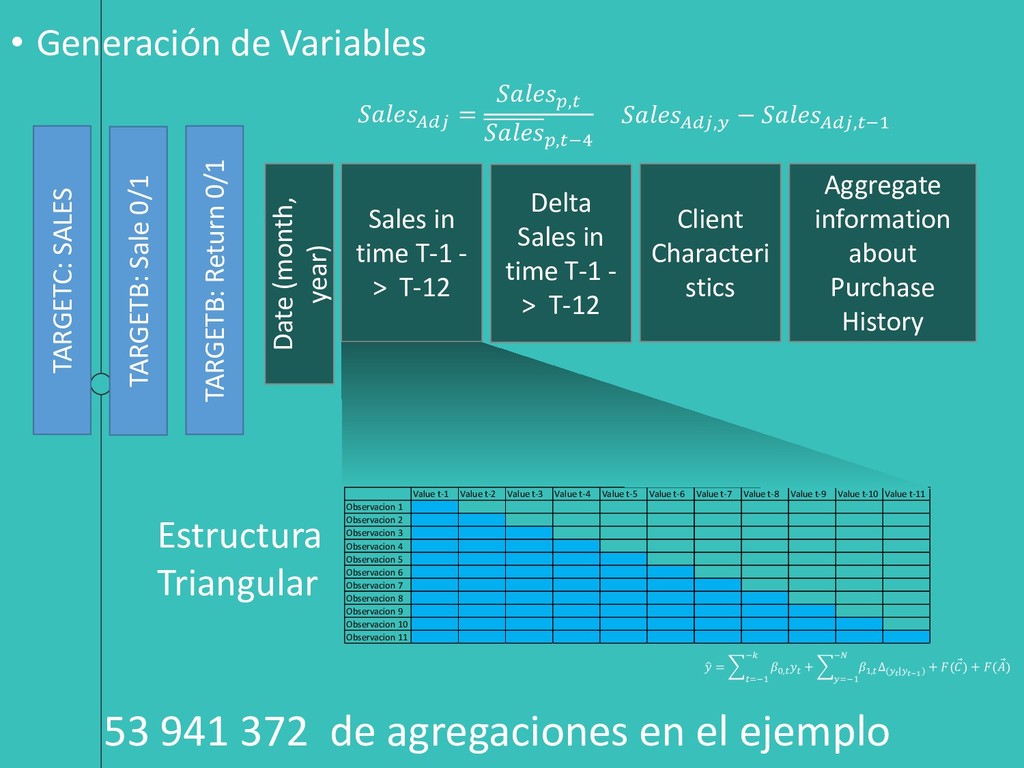
+ =−1 − 1, ∆(|−1) + ( Ԧ ) + ( Ԧ ) TARGETC: SALES TARGETB: Sale 0/1 TARGETB: Return 0/1 Sales in time T-1 - > T-12 Delta Sales in time T-1 - > T-12 Client Characteri stics Aggregate information about Purchase History Date (month, year) Value t-1 Value t-2 Value t-3 Value t-4 Value t-5 Value t-6 Value t-7 Value t-8 Value t-9 Value t-10 Value t-11 Observacion 1 Observacion 2 Observacion 3 Observacion 4 Observacion 5 Observacion 6 Observacion 7 Observacion 8 Observacion 9 Observacion 10 Observacion 11 Estructura Triangular = , ,−4 , − ,−1 53 941 372 de agregaciones en el ejemplo
se puede especificar manualmente cuales usar.. Selección de variables 01 Reto Hay que corer varios miles de modelos para poder parametrizar evitando el sobreajuste Parametrización 02 Reto Los problemas de Data Mining tienen un porcentaje bajo de target… que requieren millones de registros para poder ajustar un modelo decente. Cantidad de Obs. 03 Reto • Modelamiento • Si falta un elemento… es selección de modelos, no modelamiento Learning and Validation Datasets (T) K-Fold Cross Validation Test Dataset (T) Back-Test Dataset (T+1)
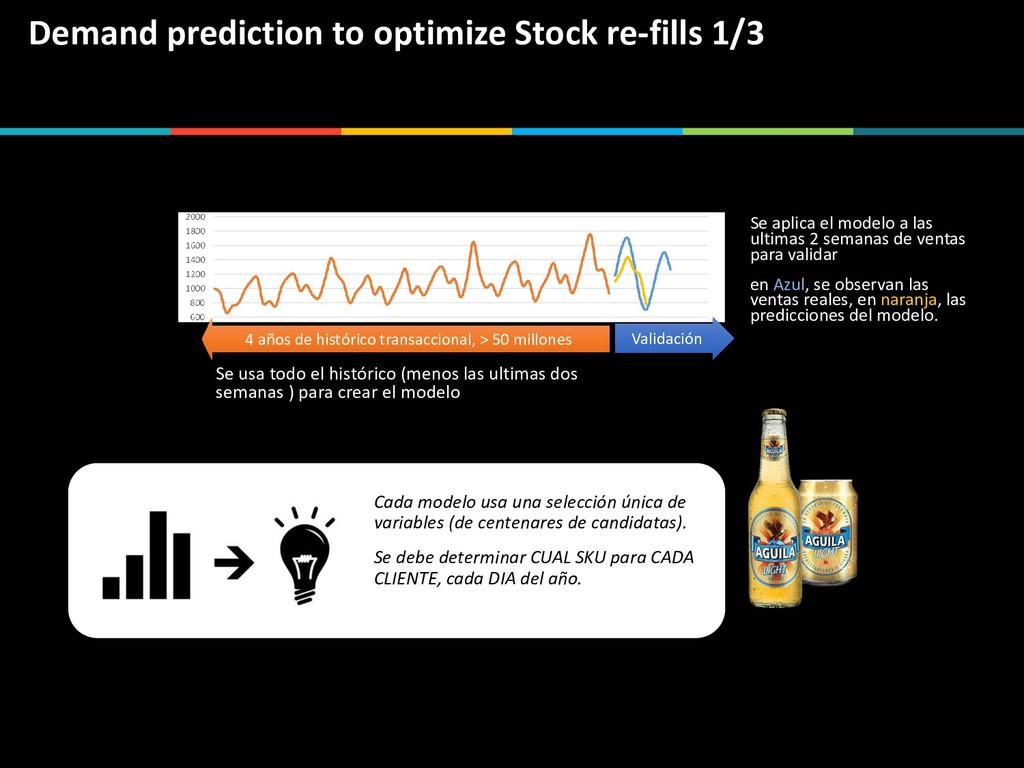
modelo a las ultimas 2 semanas de ventas para validar en Azul, se observan las ventas reales, en naranja, las predicciones del modelo. 4 años de histórico transaccional, > 50 millones Validación Se usa todo el histórico (menos las ultimas dos semanas ) para crear el modelo Cada modelo usa una selección única de variables (de centenares de candidatas). Se debe determinar CUAL SKU para CADA CLIENTE, cada DIA del año.
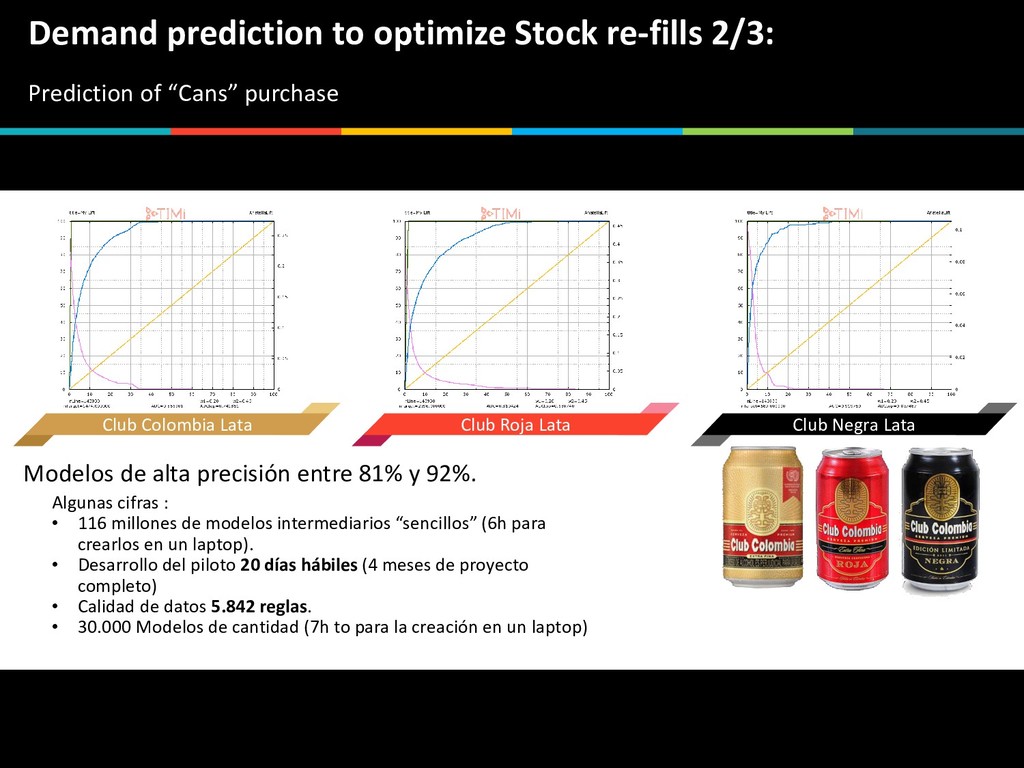
purchase 13 Club Colombia Lata Modelos de alta precisión entre 81% y 92%. Algunas cifras : • 116 millones de modelos intermediarios “sencillos” (6h para crearlos en un laptop). • Desarrollo del piloto 20 días hábiles (4 meses de proyecto completo) • Calidad de datos 5.842 reglas. • 30.000 Modelos de cantidad (7h to para la creación en un laptop) Club Roja Lata Club Negra Lata
Cada día, se sabe cual tienda comprara cual producto. Podemos pegar esos modelos con los modelos de cantidad para estimar las necesidades de producción. El scoring se hace en una fracción de segundos (+/- 2.400.000 scores por segundo) y se integra automáticamente a Qlik, Tableau, u otro sistema de DB/BI.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}