Lecture slides for Lecture 13 of the Saint Louis University Course Quantitative Analysis: Applied Inferential Statistics. These slides cover the topics related to the basics of multiple regression and the creation of formatted regression tables.
no problem set. Please focus on the final project! Lab 11 is due next Monday - there will be no problem set. Please focus on the final project! 1. FRONT MATTER ANNOUNCEMENTS All peer reviews are due today!
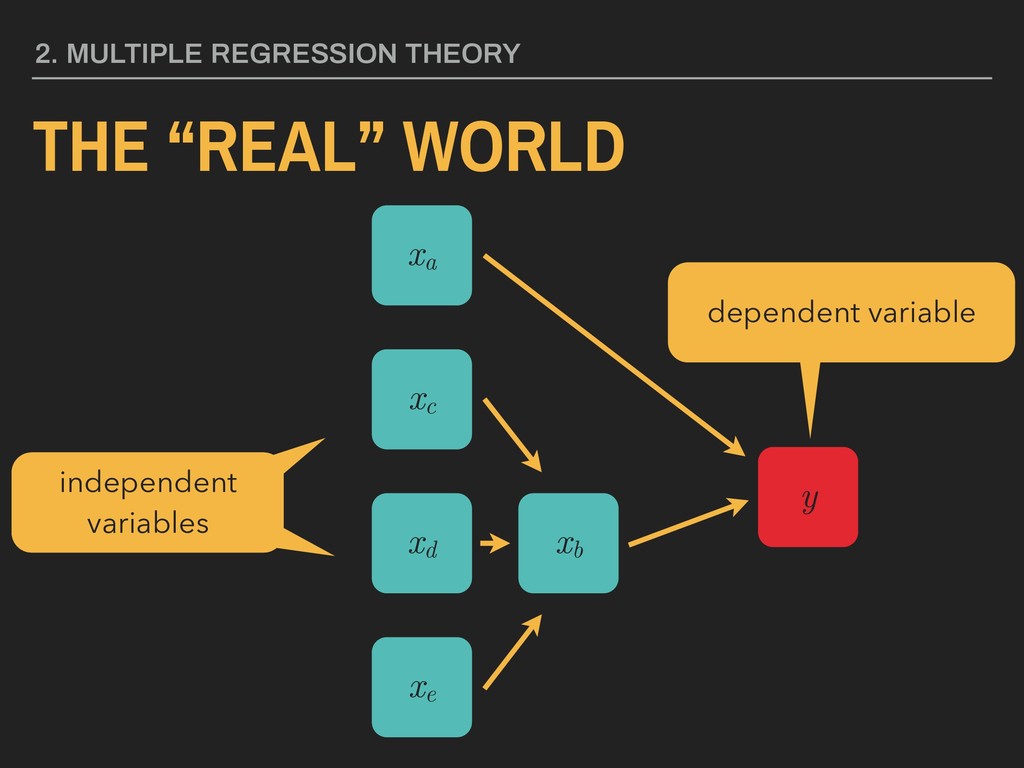
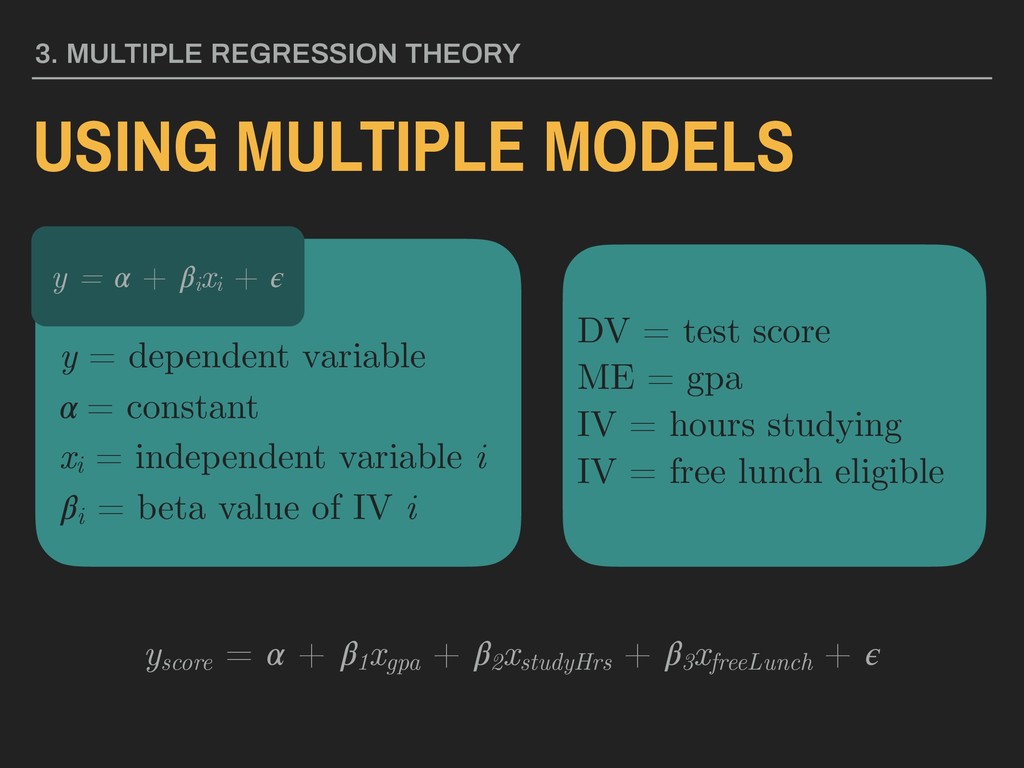
= constant xi = independent variable i i = beta value of IV i DV = test score ME = gpa IV = hours studying IV = free lunch eligible y = + i xi + yscore = + 1 xgpa + 2 xstudyHrs + 3 xfreeLunch +
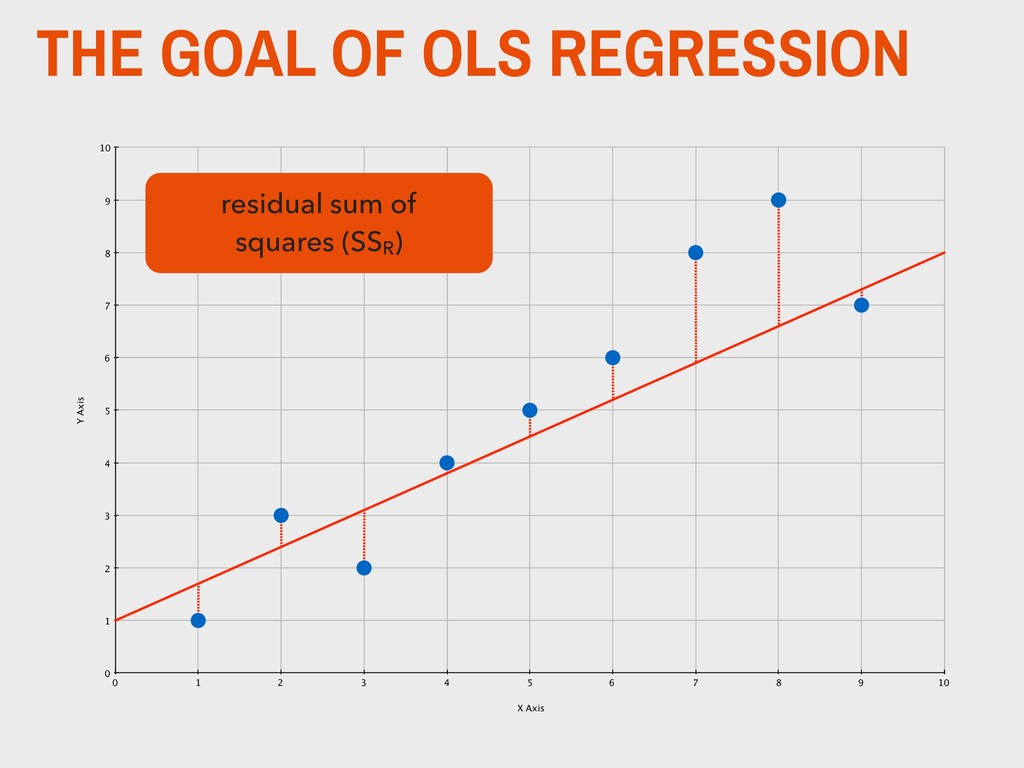
Pr(>|t|) (Intercept) 68.7166 5.7262 12.000 1.81e-15 *** gpa 6.1242 0.0811 1.531 0.0009 *** studyHrs -1.17074 0.28129 -4.162 0.000148 *** freeLunch -7.8843 3.7484 -2.103 0.0412 * --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 9.728 on 43 degrees of freedom Multiple R-squared: 0.433, Adjusted R-squared: 0.3935 F-statistic: 10.95 on 3 and 43 DF, p-value: 1.811e-05 3. MULTIPLE REGRESSION THEORY The standard error is an indicator of amount of uncertainty in the estimate, representing the amount of variation present across observations. It is also used to find t.
Pr(>|t|) (Intercept) 68.7166 5.7262 12.000 1.81e-15 *** gpa 6.1242 0.0811 1.531 0.0009 *** studyHrs -1.17074 0.28129 -4.162 0.000148 *** freeLunch -7.8843 3.7484 -2.103 0.0412 * --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 9.728 on 43 degrees of freedom Multiple R-squared: 0.433, Adjusted R-squared: 0.3935 F-statistic: 10.95 on 3 and 43 DF, p-value: 1.811e-05 3. MULTIPLE REGRESSION THEORY These are based on calculations of the total sum of squares and the residual sum of squared error.
68.7166 5.7262 12.000 1.81e-15 *** gpa 6.1242 0.0811 1.531 0.0009 *** studyHrs -1.17074 0.28129 -4.162 0.000148 *** freeLunch -7.8843 3.7484 -2.103 0.0412 * --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 9.728 on 43 degrees of freedom Multiple R-squared: 0.433, Adjusted R-squared: 0.3935 F-statistic: 10.95 on 3 and 43 DF, p-value: 1.811e-05 3. MULTIPLE REGRESSION THEORY Evaluation of the null hypothesis that all the betas are equal to zero. It is a measure of the reliability of the model.
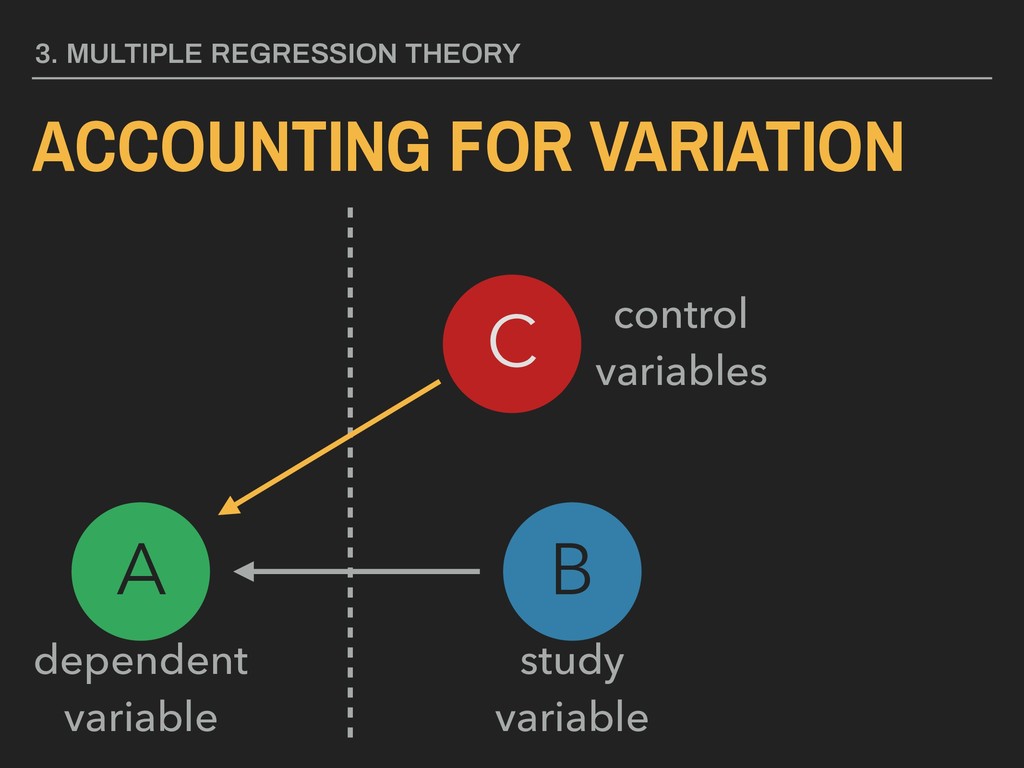
8.03926404 4.2876193 studyHours 3.06346803 0.5734902 freeLunch -15.43865689 -1.3300016 3. MULTIPLE REGRESSION THEORY These are measures of the accuracy of each beta estimate. If they include zero, the estimate will not be statistically significant.
variable = constant xi = independent variable i i = beta value of IV i DV = test score ME = gpa IV = hours studying IV = free lunch eligible y = + i xi + yscore = + 1 xgpa + 2 xstudyHrs + 3 xfreeLunch +
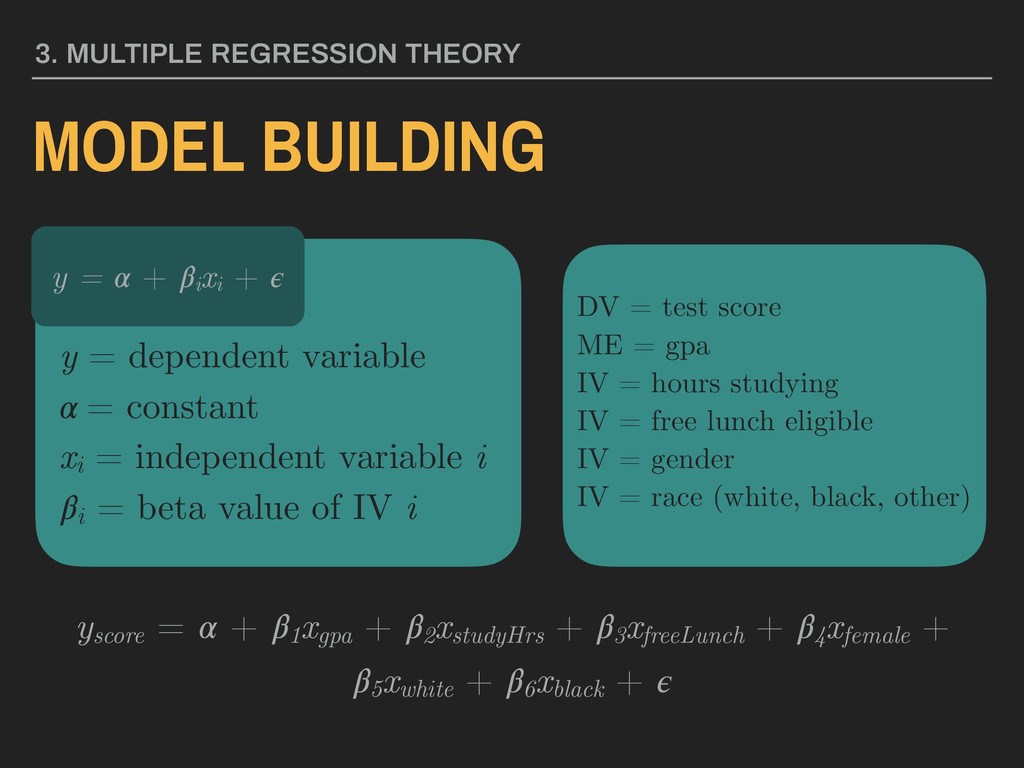
= constant xi = independent variable i i = beta value of IV i DV = test score ME = gpa IV = hours studying IV = free lunch eligible IV = gender IV = race (white, black, other) y = + i xi + yscore = + 1 xgpa + 2 xstudyHrs + 3 xfreeLunch + 4 xfemale + 5 xwhite + 6 xblack +
1 xgpa + 2 xstudyHrs + 3 xfreeLunch + yscore = + 1 xgpa + Model 1, Main Effects: Model 2, Main effect + other educational measures : yscore = + 1 xgpa + 2 xstudyHrs + 3 xfreeLunch + 4 xfemale + 5 xwhite + 6 xblack + Model 3, Full Model: We can also use AIC and BIC “information criterion” values, which should decrease.
where: • y is the dependent variable • x1, x2, x3 are the in dependent variables ▸ dataFrame is the data source (can be a tibble) All functions in this section are available in stats Included in base distributions of R 3. MULTIPLE REGRESSION IN R OLS MODEL Parameters: lm(y ~ x1+x2+x3, data = dataFrame) f(x)
where: • y is the dependent variable • x1, x2, and x3 are the independent variables ▸ dataFrame is the data source (can be a tibble) 3. MULTIPLE REGRESSION IN R OLS MODEL Parameters: lm(y ~ x1+x2+x3, data = dataFrame) f(x)
data = dataFrame) Using the hwy, cyl and displ variables from ggplot2’s mpg data: > model <- lm(hwy ~ displ+cyl, data = autoData) Save model output into an object for reference later. Output is stored as a list, and contains far more data than what is printed. f(x)
x1+x2+x3, data = dataFrame) Using the hwy, cyl and displ variables from ggplot2’s mpg data: > model <- lm(hwy ~ displ, data = autoData) > model2 <- lm(hwy ~ displ+cyl, data = autoData) Name each model object clearly! f(x)
models ▸ “table title” is a title for your regression table All functions in this section are from stargazer Download via CRAN 4. REGRESSION TABLES BASIC REGRESSION TABLE Parameters: stargazer(models, title = "table title") f(x)
models ▸ “table title” is a title for your regression table 4. REGRESSION TABLES BASIC REGRESSION TABLE Parameters: stargazer(models, title = "table title") f(x)
title") Using the hwy, cyl and displ variables from ggplot2’s mpg data: > model <- lm(hwy ~ displ+cyl, data = mpg) > stargazer(model, title = "basic regression table") <<<<< OUTPUT OMITTED >>>>> This will return LaTeX output by default. We’ll convert this to a Word document once the table is fully prepared. f(x)
- there will be no problem set. Please focus on the final project! Lab 11 is due next Monday - there will be no problem set. Please focus on the final project! All peer reviews are due today!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}