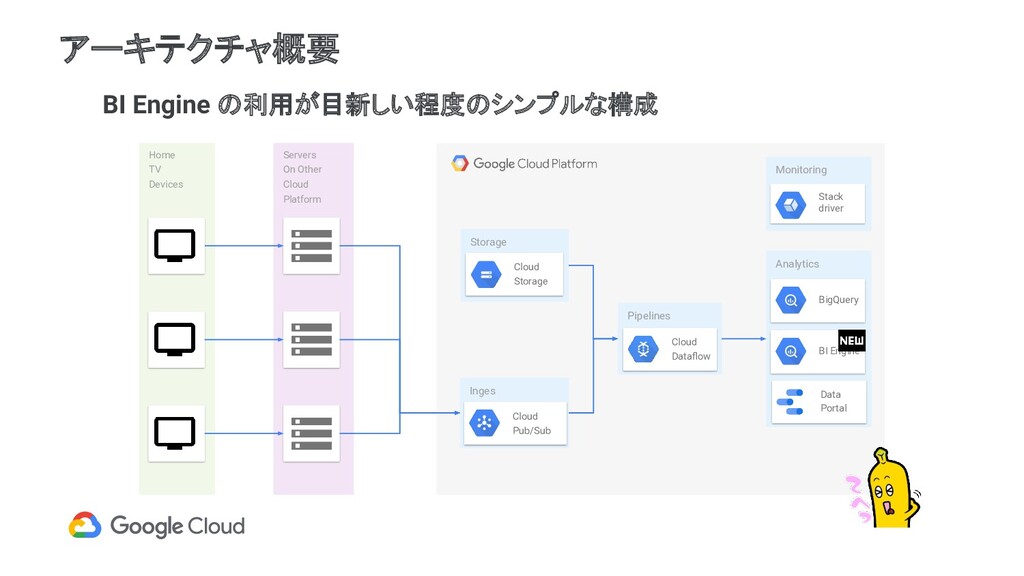
連携が容易) BigQuery Transfer で他 Google サービスのログを取り込み、一元管理可能 Google の開発注力具合(明らかな BigQuery 推し、今後のアップデートが期待できる) ・Data Portal 無料!(他社BIツールだとダッシュボード表示するには閲覧者分だけライセンス費が必要) ・Pub/Sub、Cloud Dataflow (Apache Beam) スケーラブル、フルマネージド、 Google サービスとの連携が容易、移植容易性 Google ソリューションのメリット
SDK for Java を利用 ・進行中のストリーミングパイプラインを停止せずに更新 24 x 365 モニタリングしないので不要だが、可能なら対応したい ・出力先テーブル名の動的設定( DynamicDestinations 機能) 番組ごとの TV ID テーブルをリアルタイムに作成したい BigQuery Data Portal Cloud Dataflow Cloud Pub/Sub fluentd
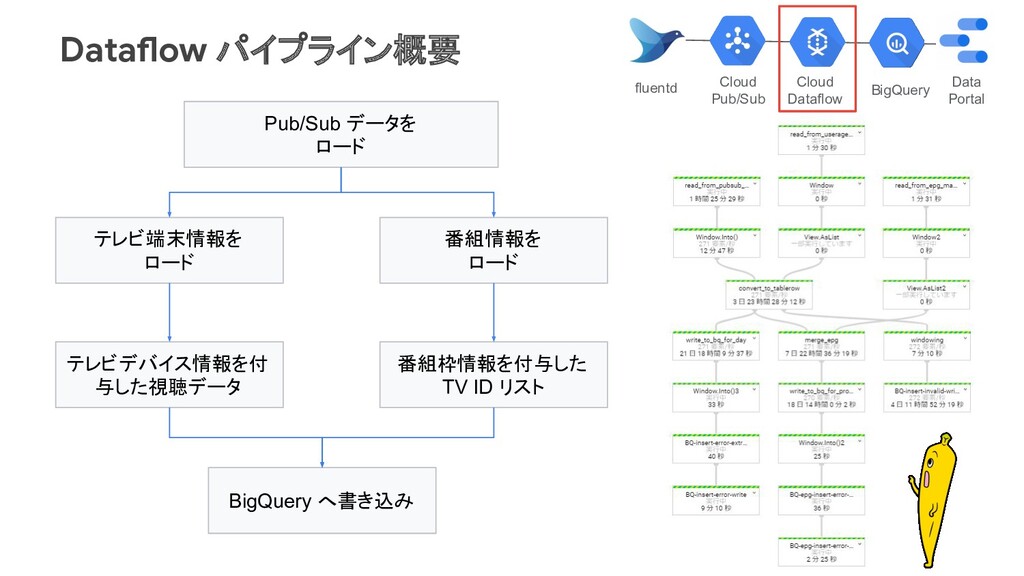
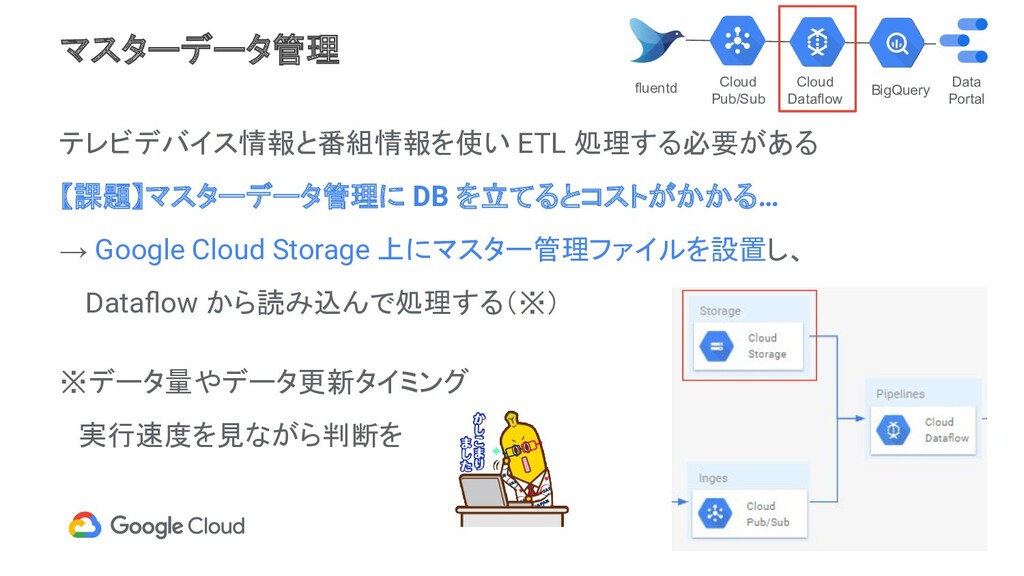
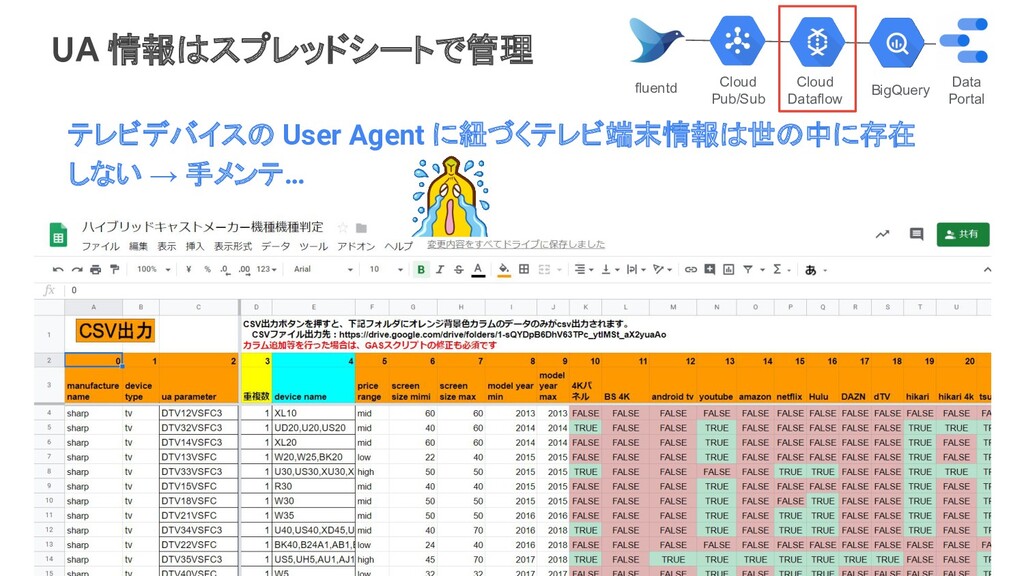
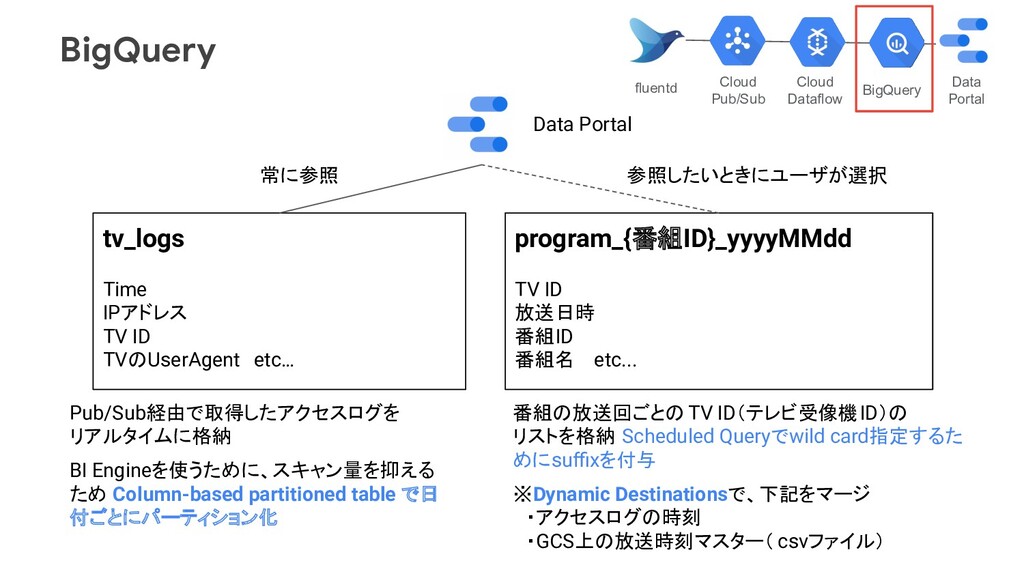
付ごとにパーティション化 番組の放送回ごとの TV ID(テレビ受像機ID)の リストを格納 Scheduled Queryでwild card指定するた めにsuffixを付与 ※Dynamic Destinationsで、下記をマージ ・アクセスログの時刻 ・GCS上の放送時刻マスター( csvファイル) tv_logs Time IPアドレス TV ID TVのUserAgent etc… program_{番組ID}_yyyyMMdd TV ID 放送日時 番組ID 番組名 etc... 常に参照 参照したいときにユーザが選択 Data Portal BigQuery Data Portal Cloud Dataflow Cloud Pub/Sub fluentd
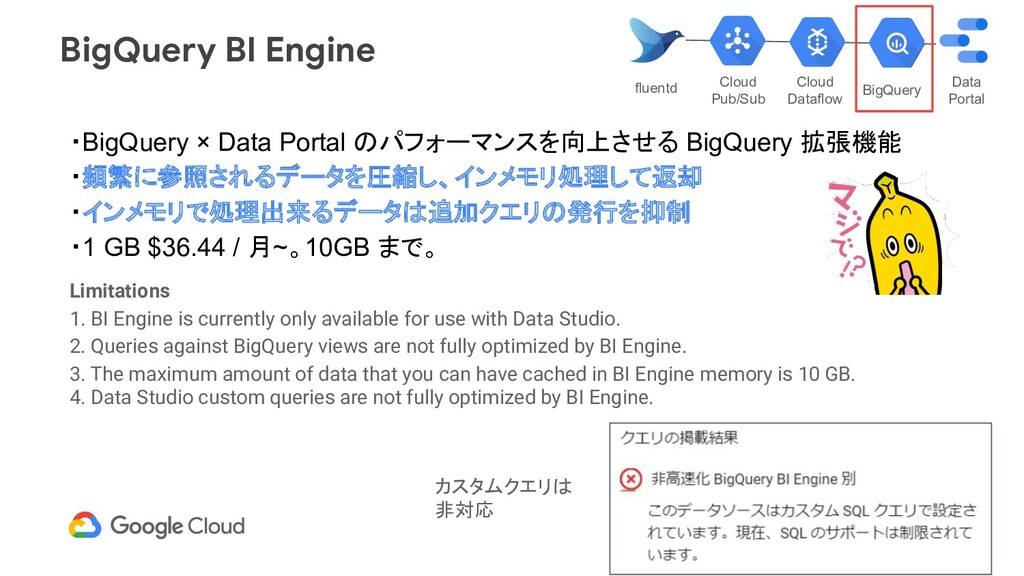
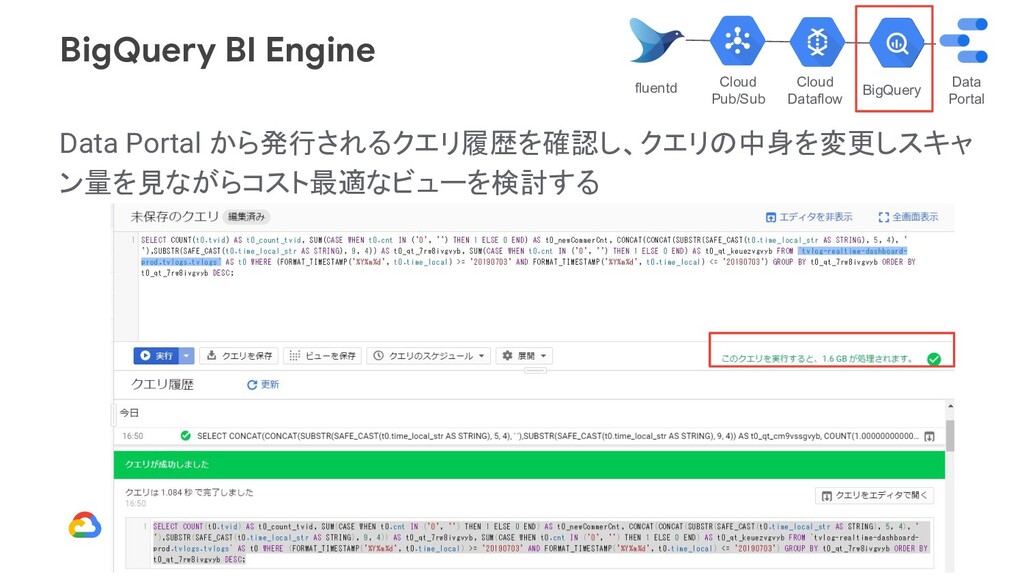
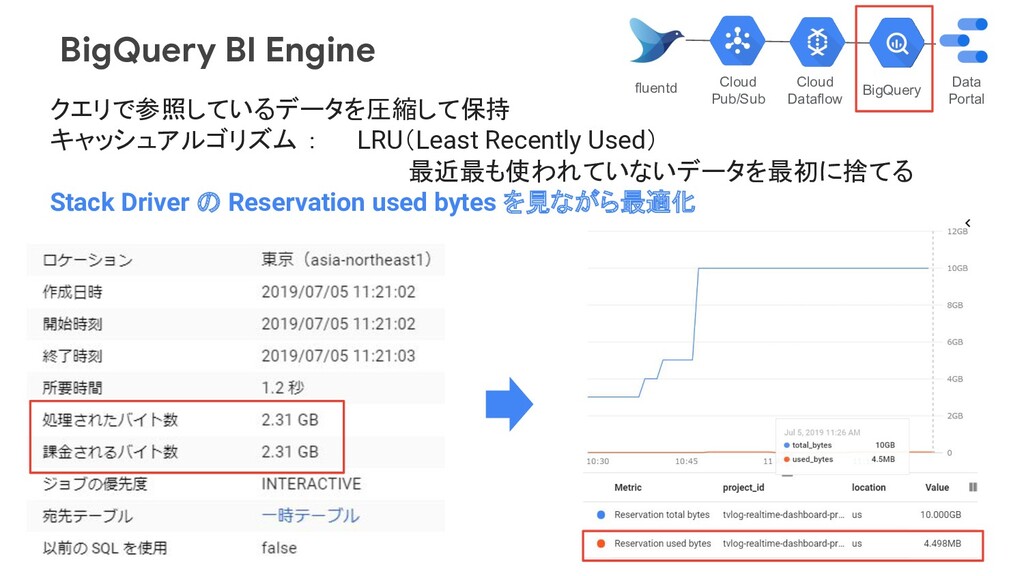
・頻繁に参照されるデータを圧縮し、インメモリ処理して返却 ・インメモリで処理出来るデータは追加クエリの発行を抑制 ・1 GB $36.44 / 月~。10GB まで。 Limitations 1. BI Engine is currently only available for use with Data Studio. 2. Queries against BigQuery views are not fully optimized by BI Engine. 3. The maximum amount of data that you can have cached in BI Engine memory is 10 GB. 4. Data Studio custom queries are not fully optimized by BI Engine. カスタムクエリは 非対応 BigQuery Data Portal Cloud Dataflow Cloud Pub/Sub fluentd
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
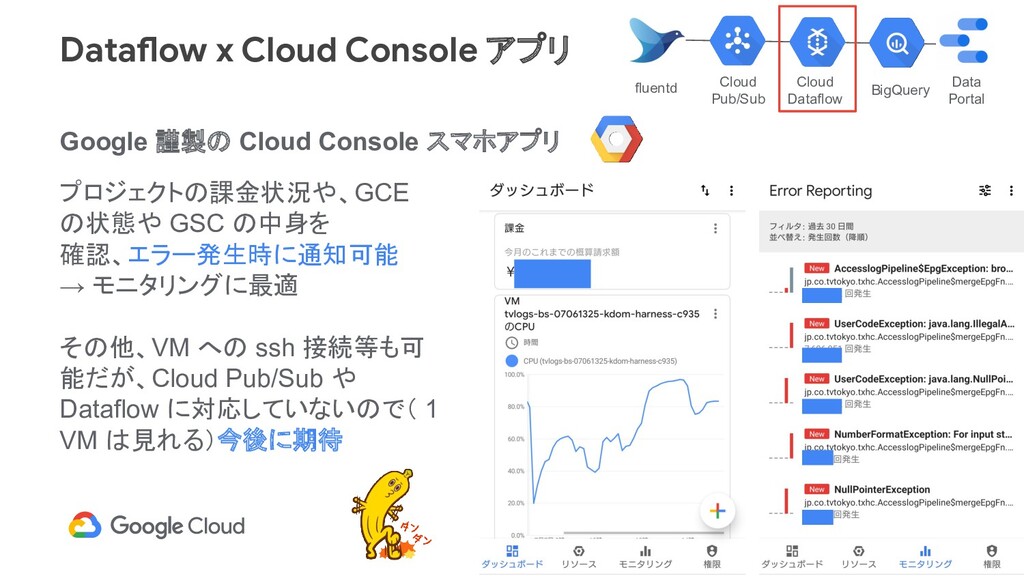{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}