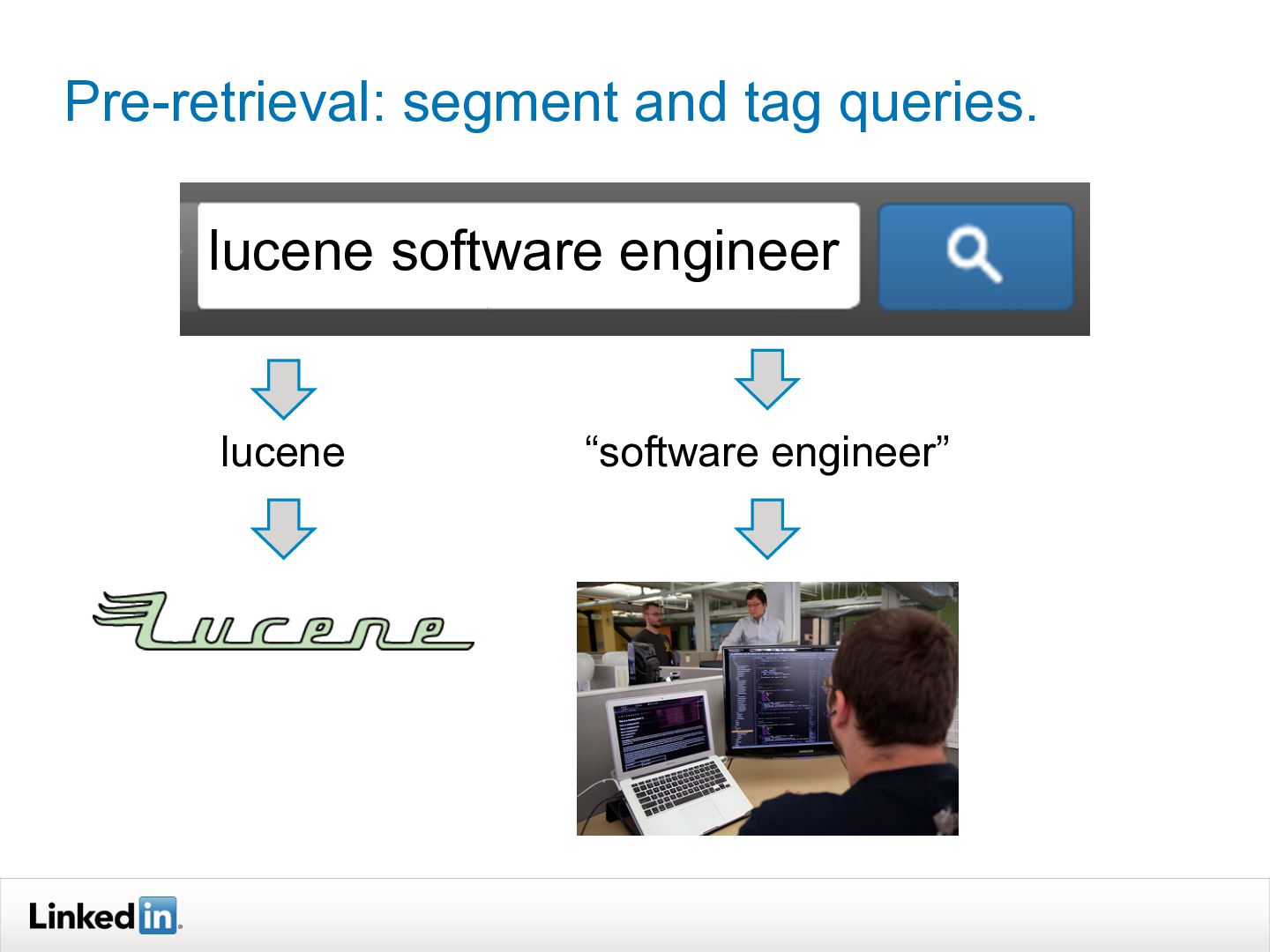
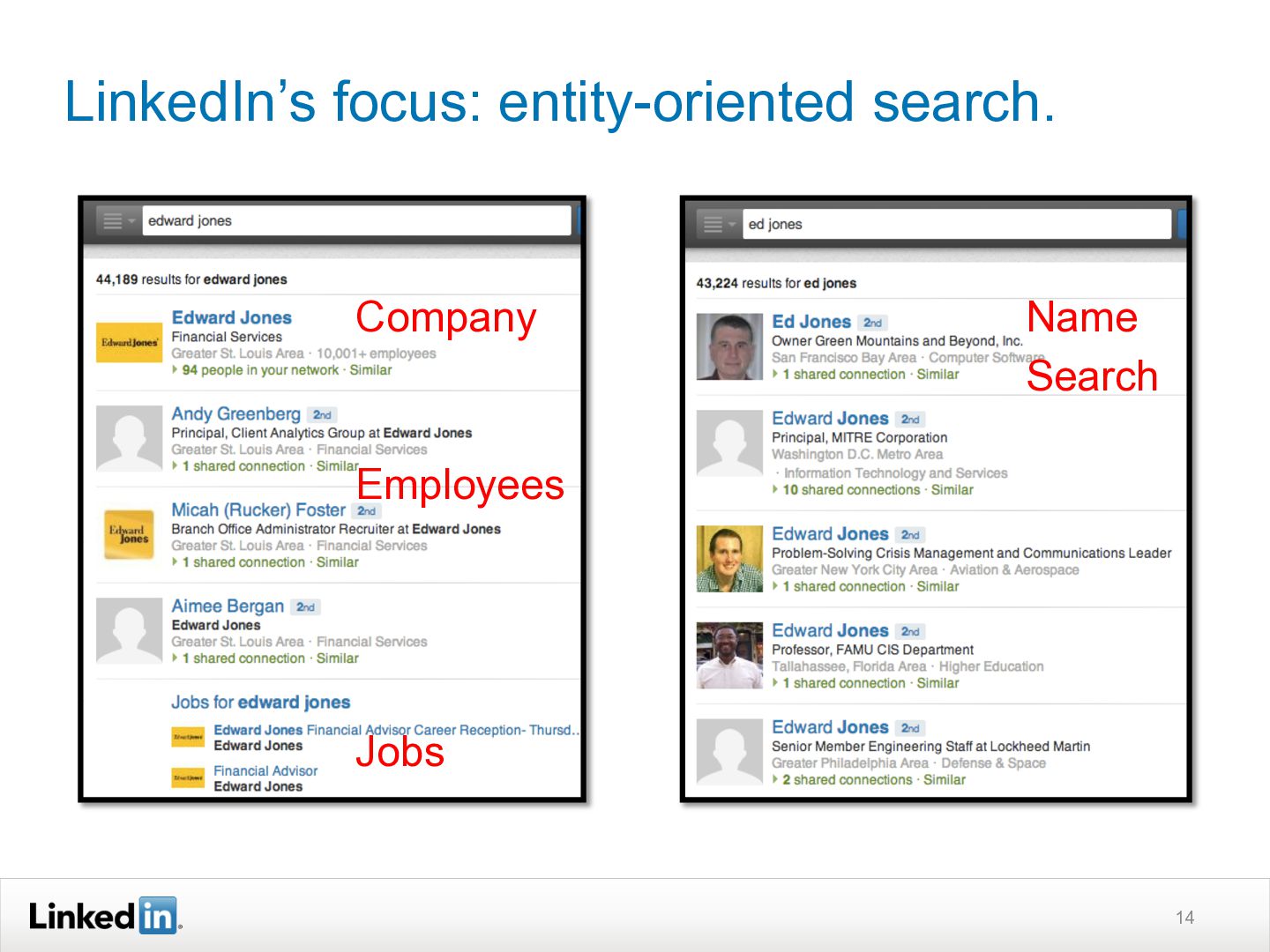
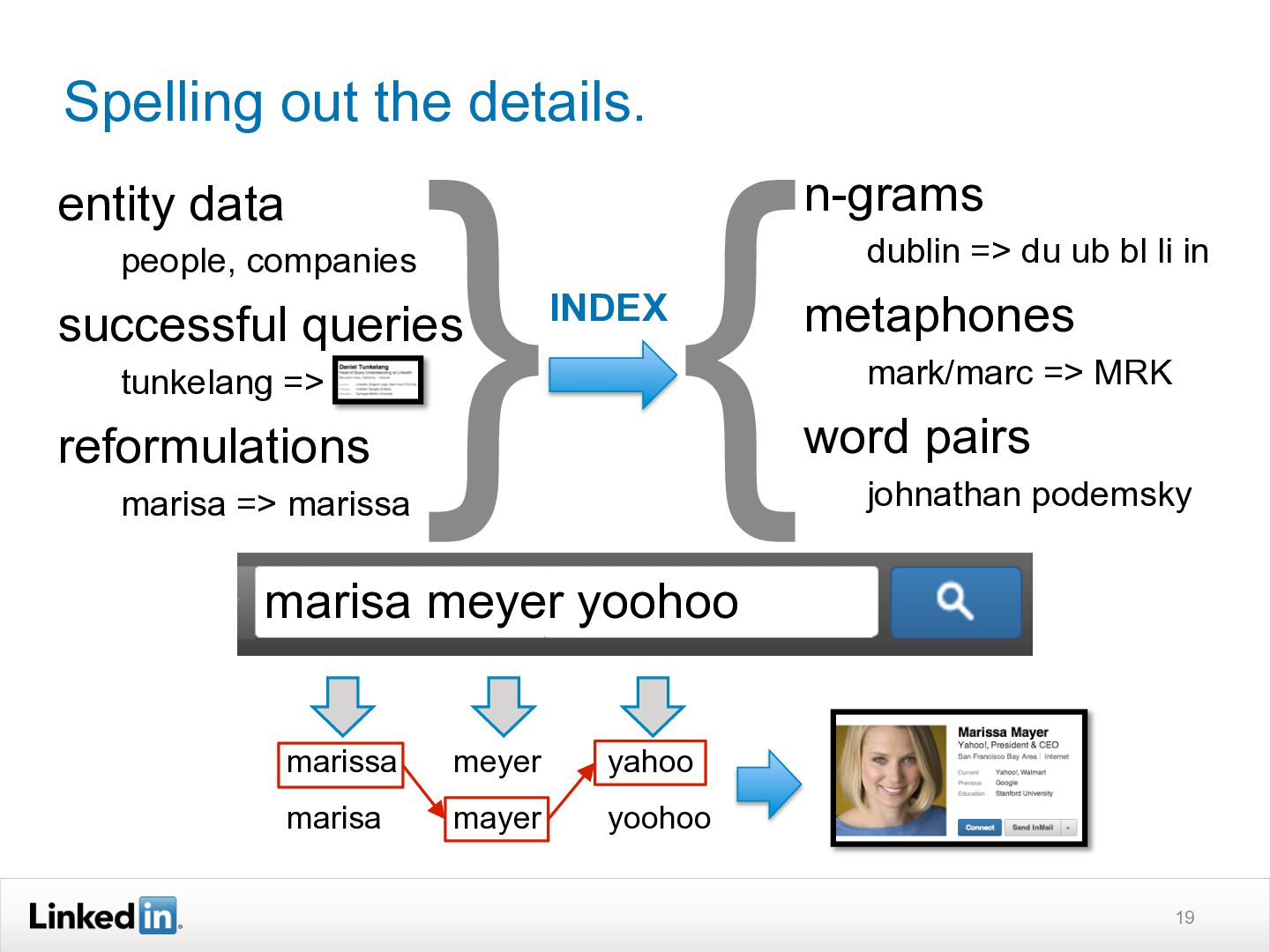
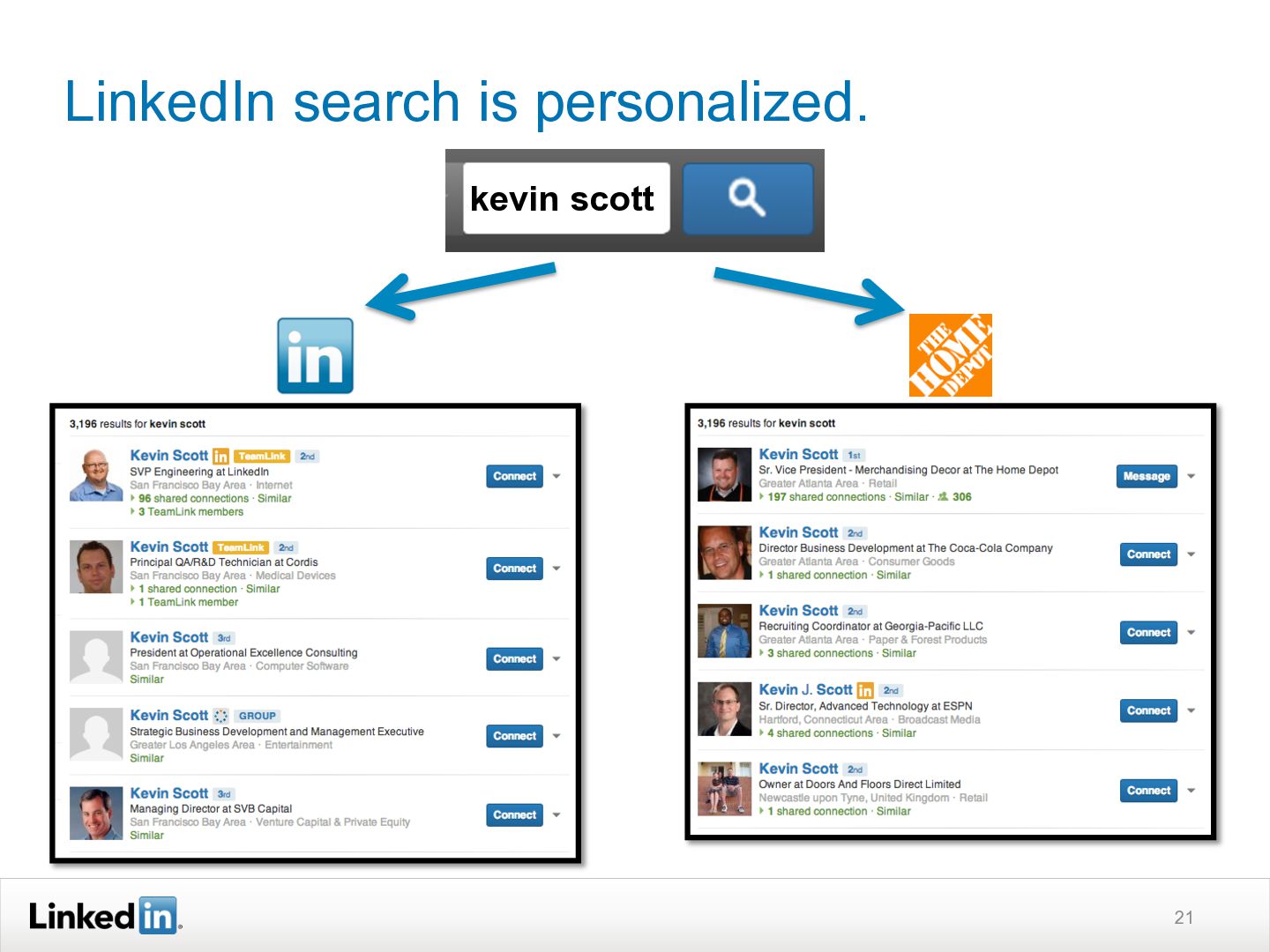
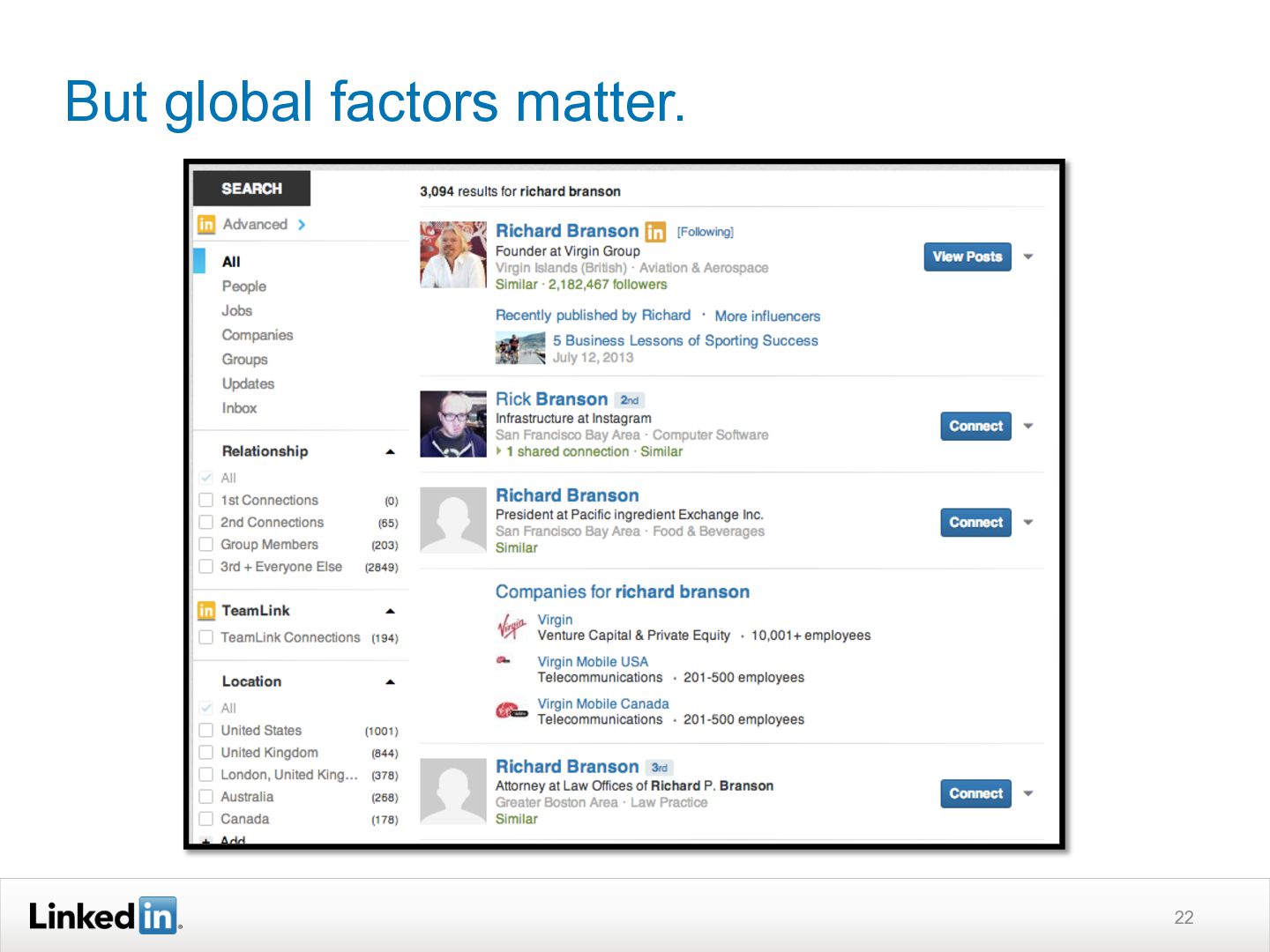
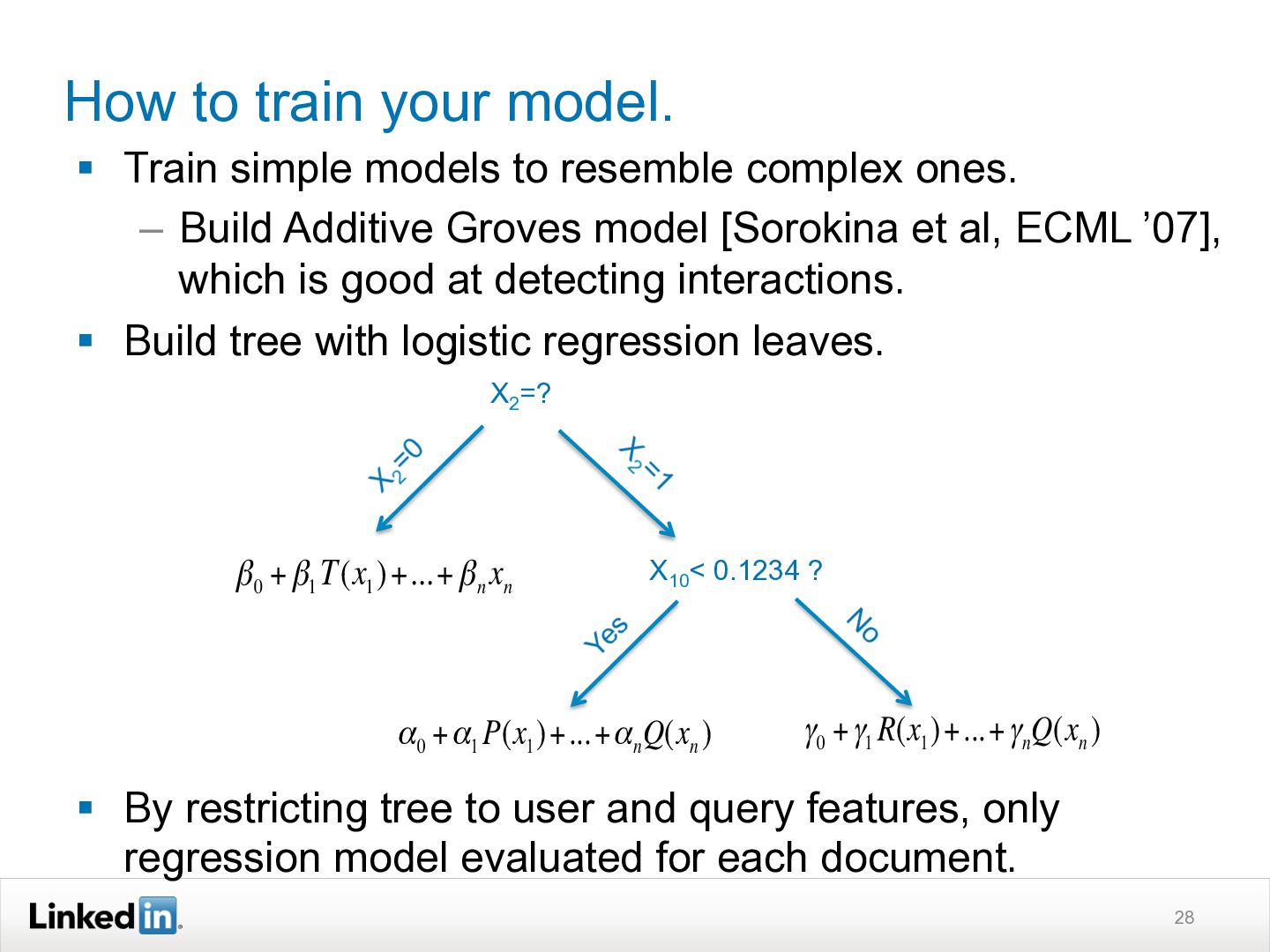
This ACM SIGIR 2013 Industry Track presentation discusses how LinkedIn's search functionality works. It explains how LinkedIn search is personalized based on a user's profile and network. Query understanding involves tagging queries to determine entity types like people, companies, or skills. Ranking is also personalized using machine learning models trained on search logs to determine relevance for a specific user's query. The system aims to provide both globally and personally relevant results, as about two-thirds of clicks come from out of a user's network.
{kind=link}
{kind=link}
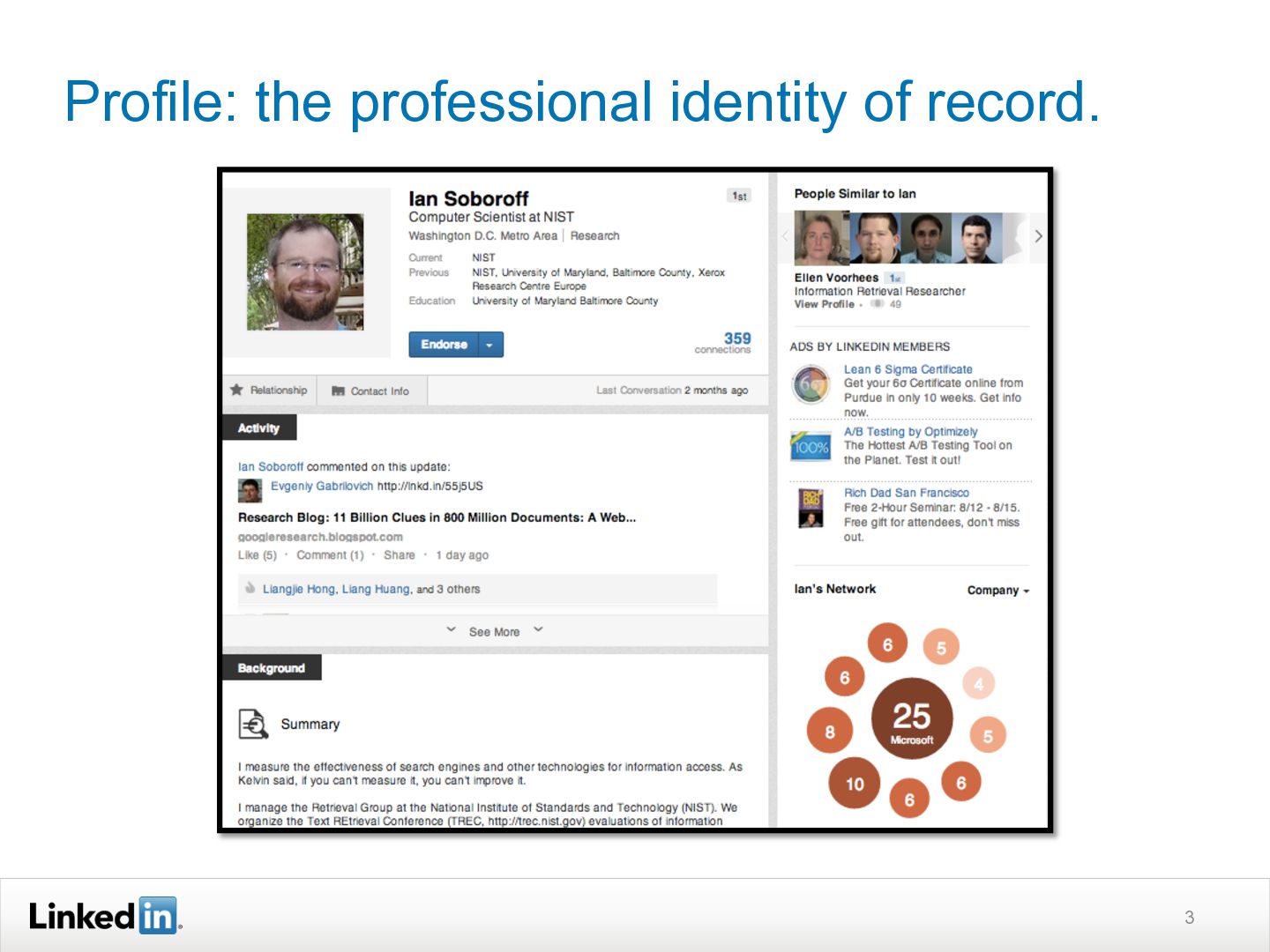{kind=link}
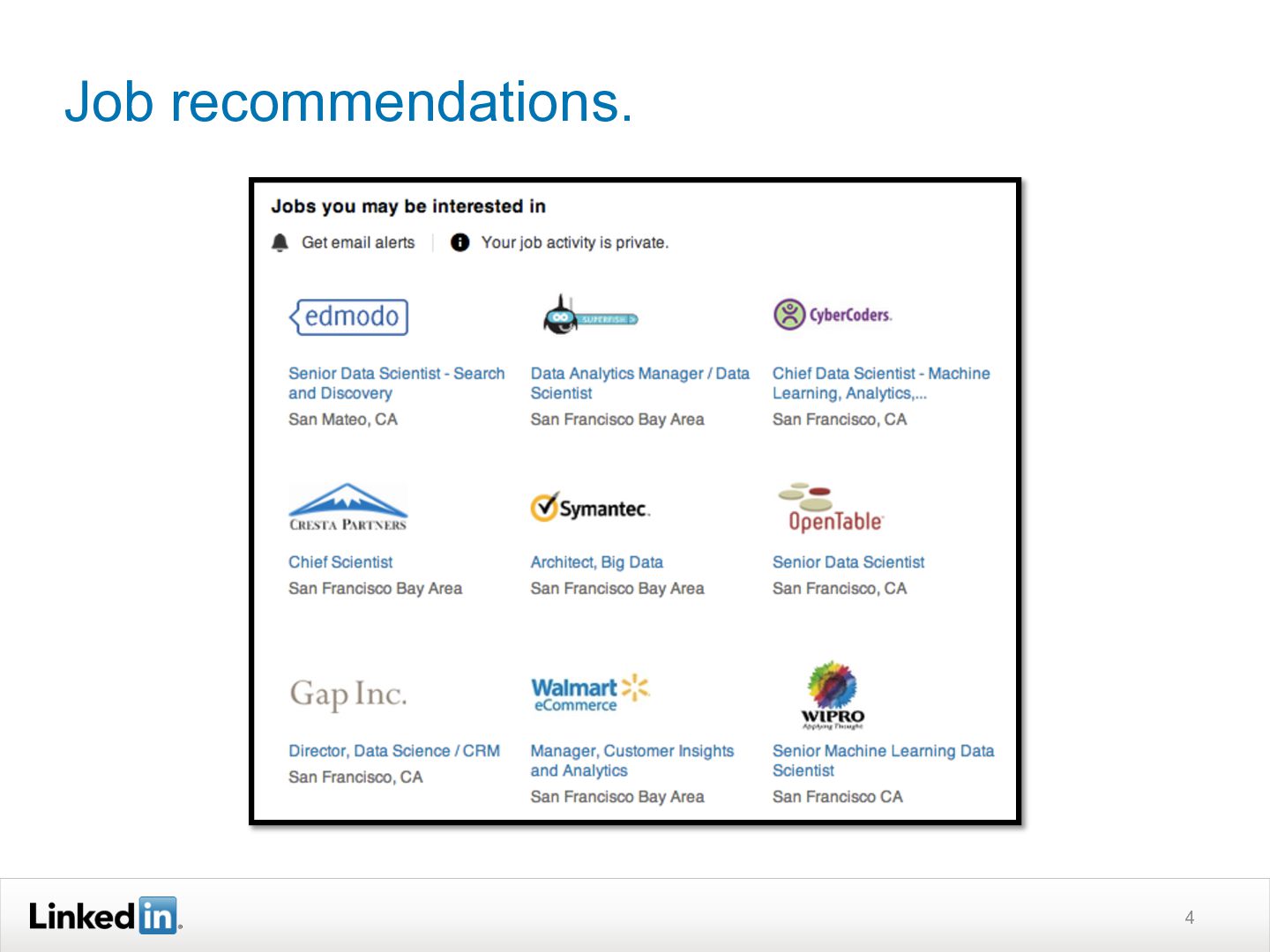{kind=link}
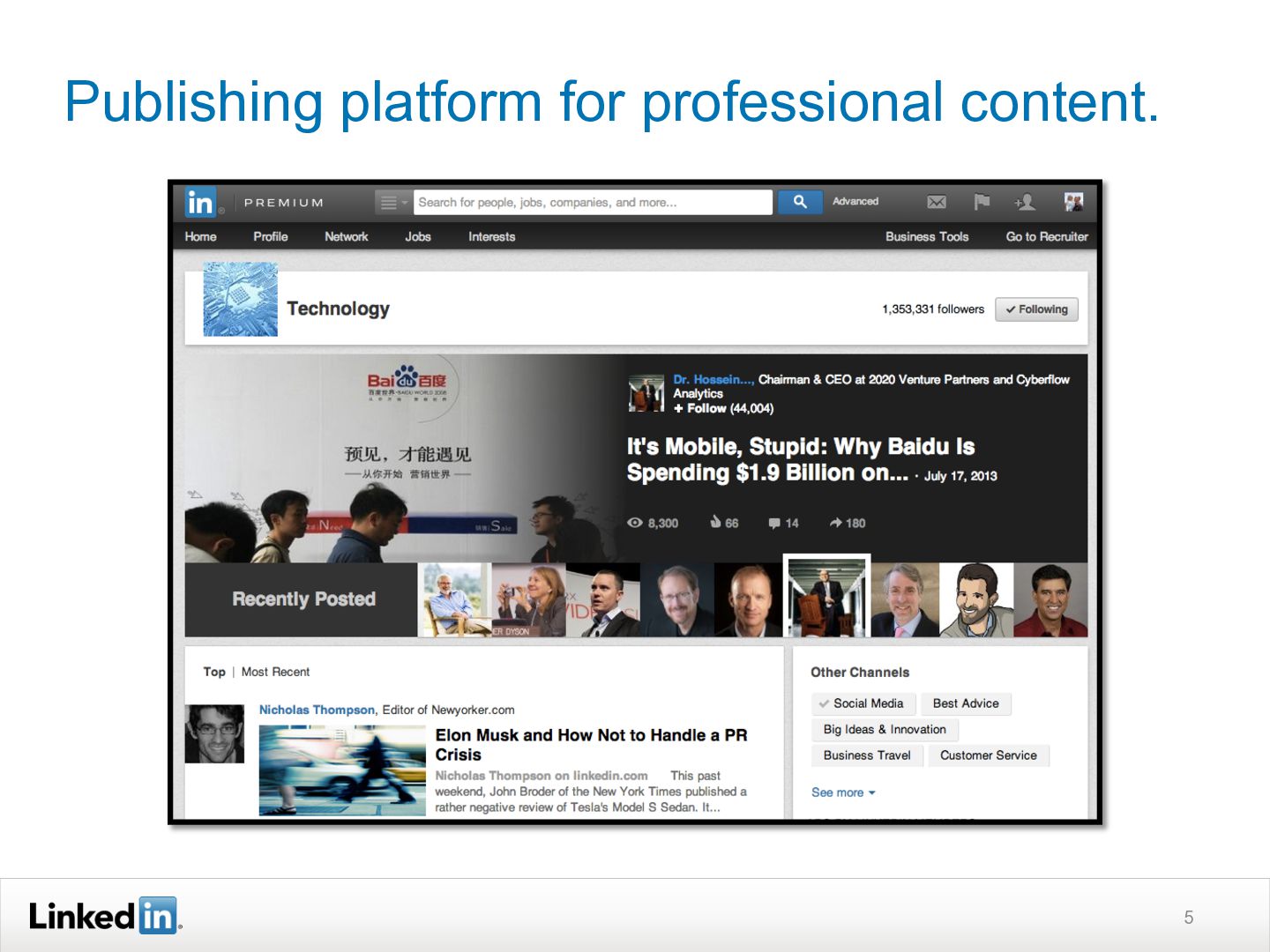{kind=link}
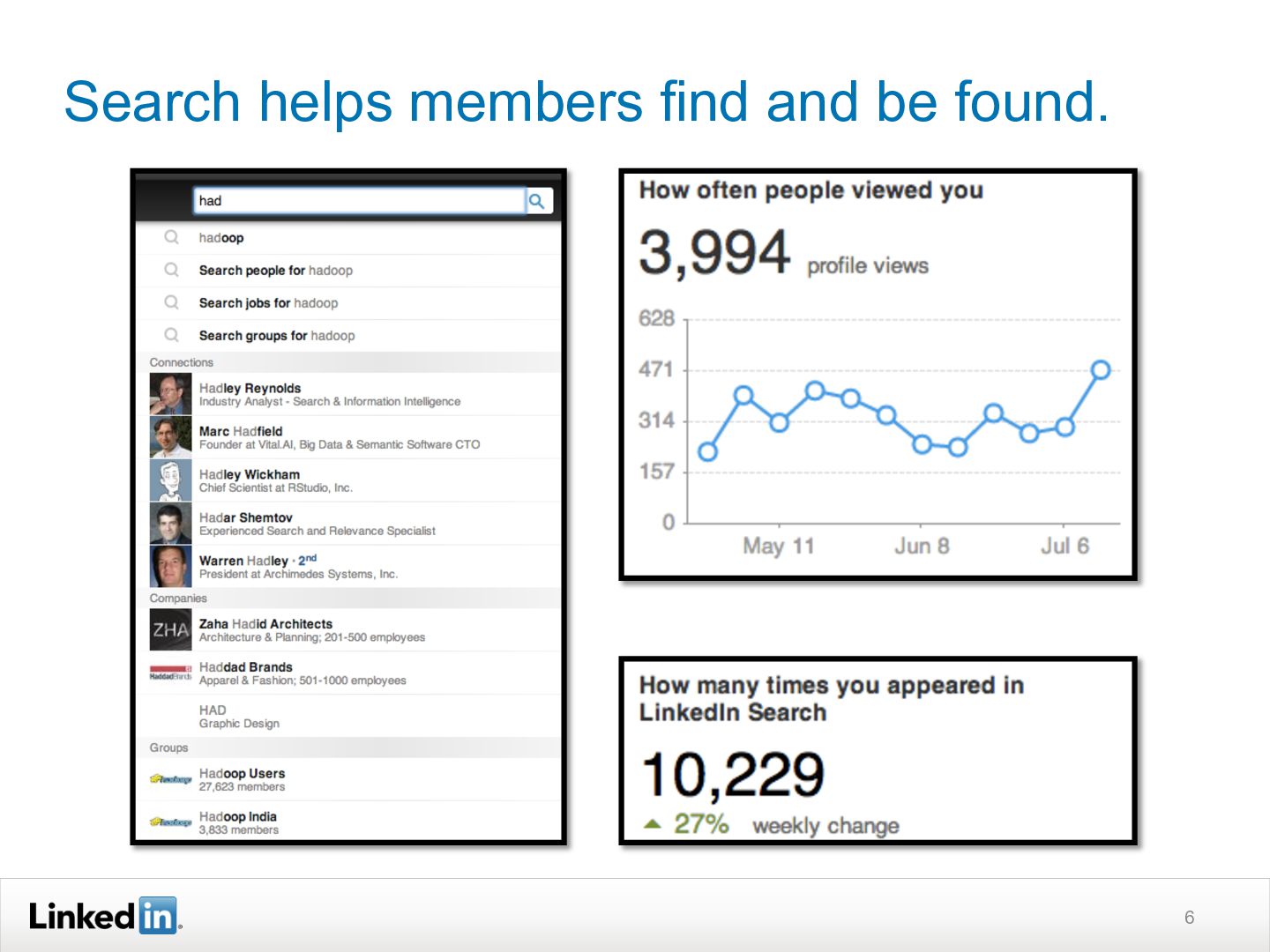{kind=link}
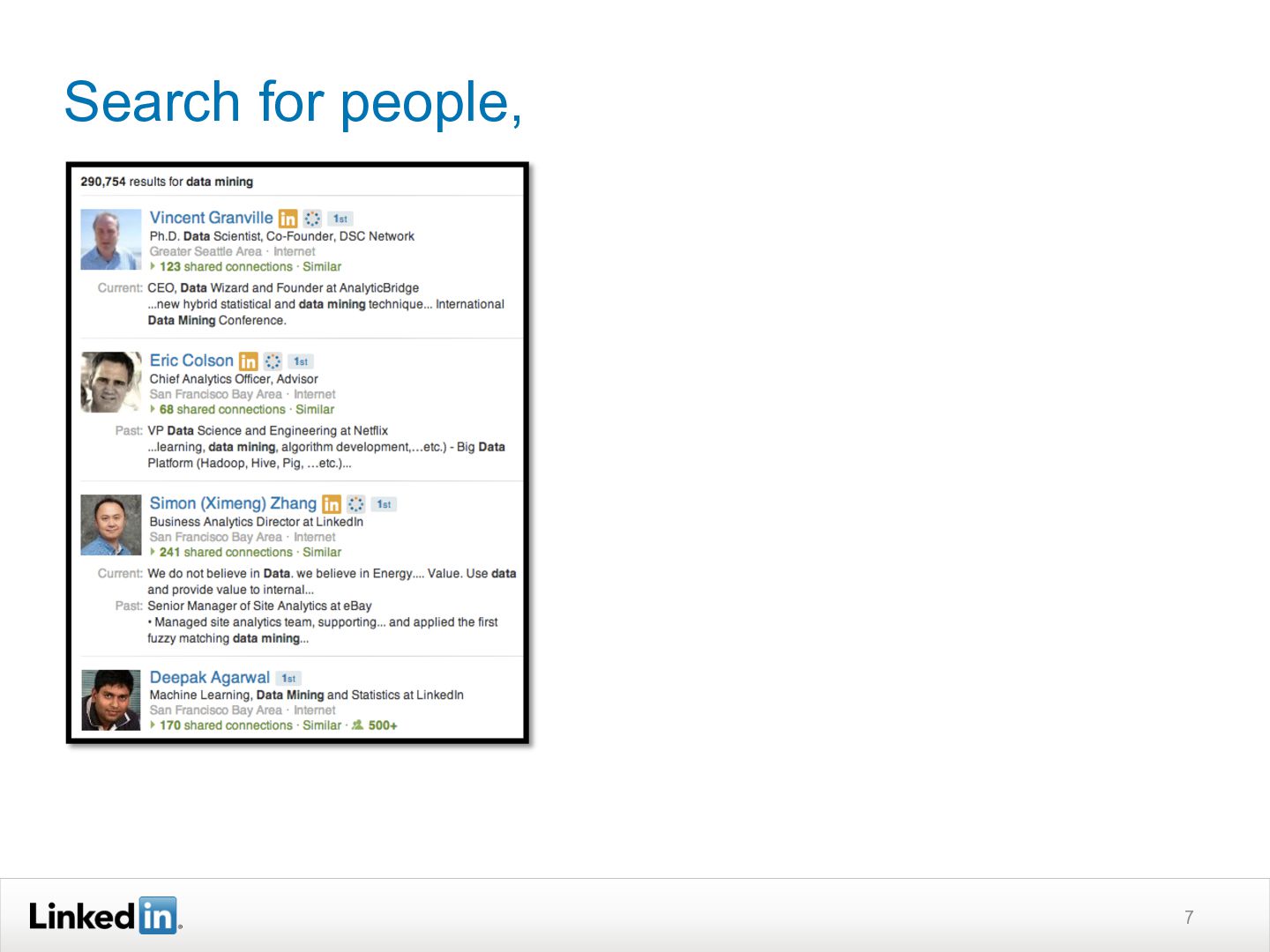{kind=link}
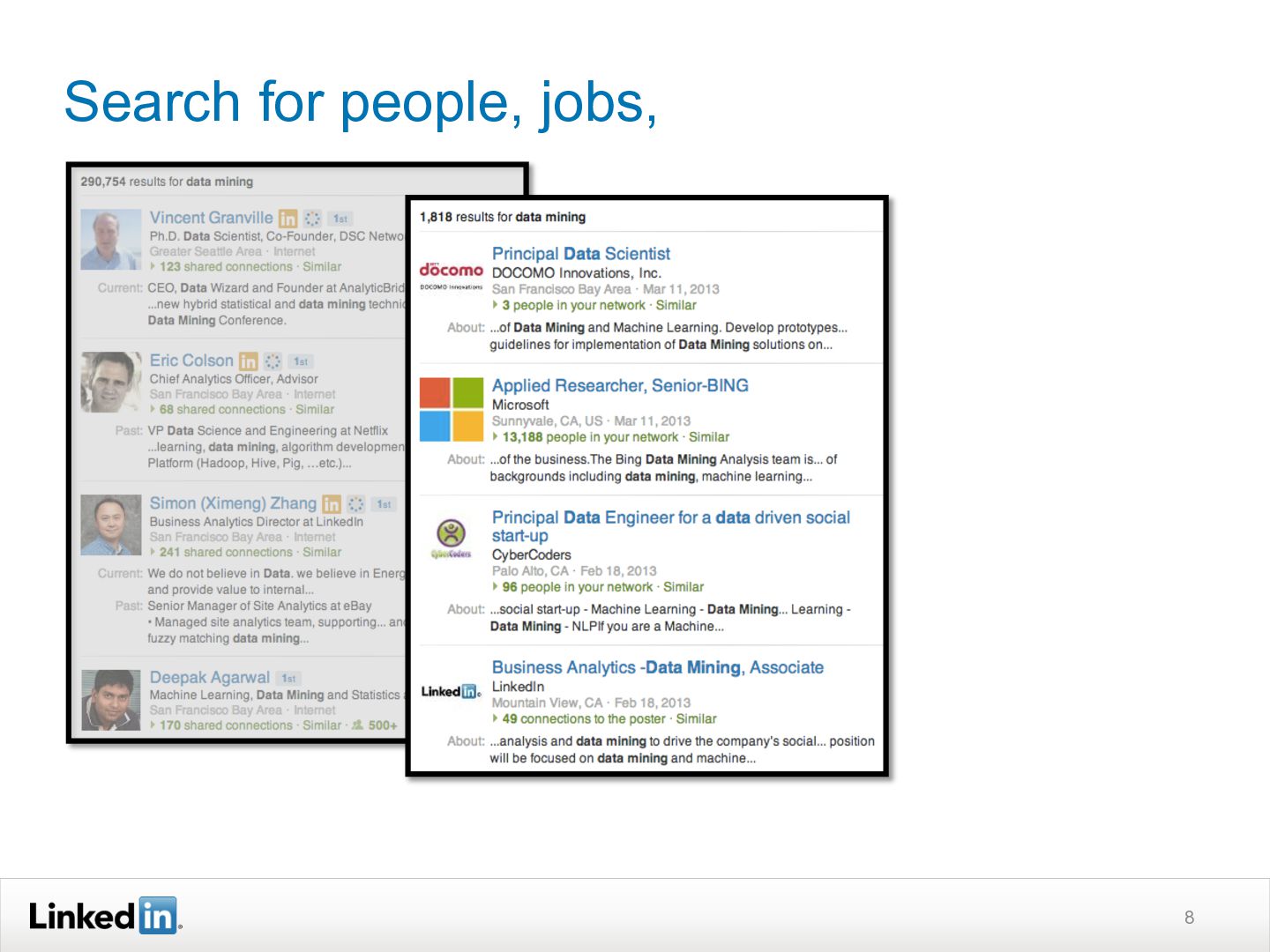{kind=link}
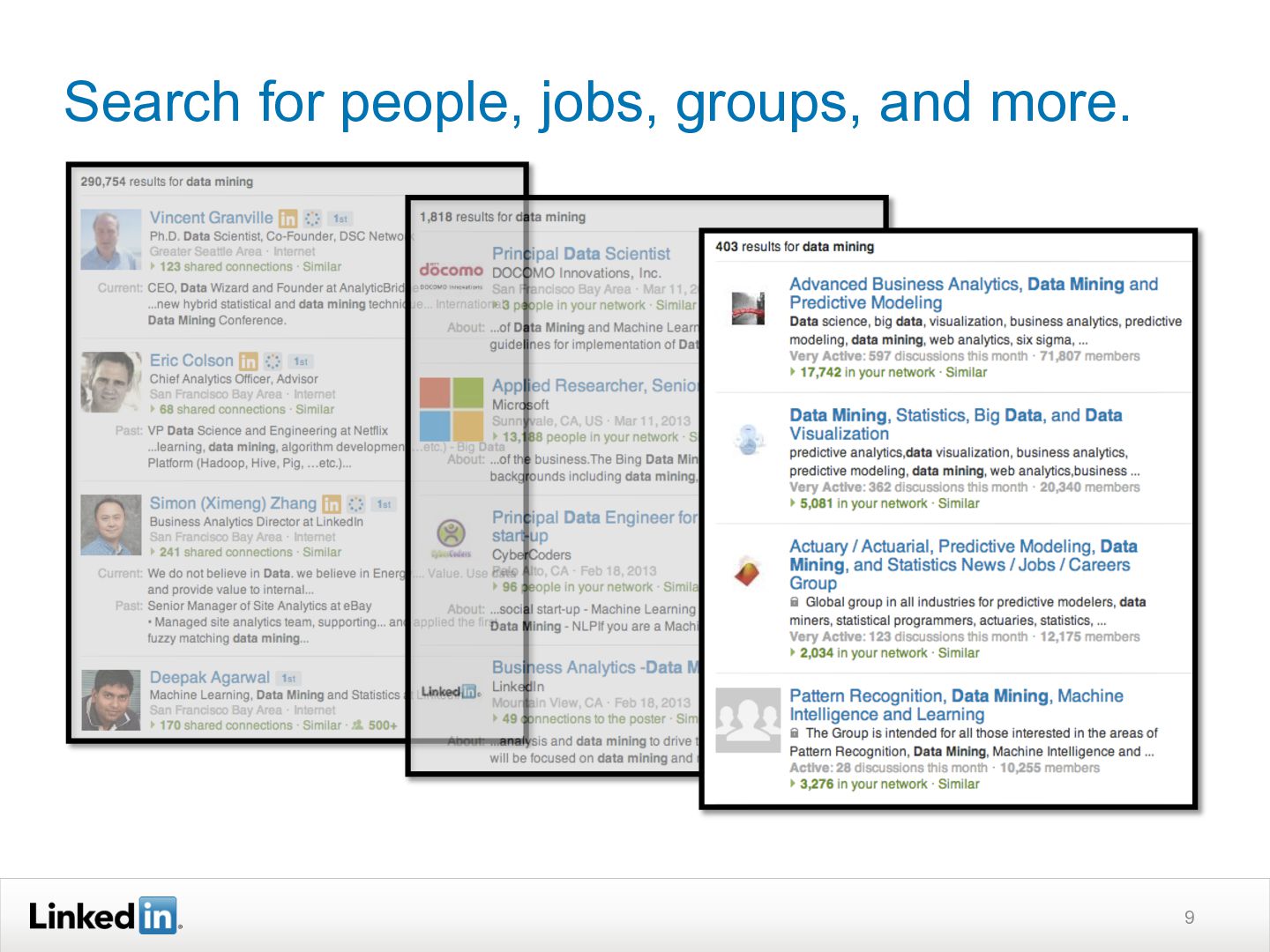{kind=link}
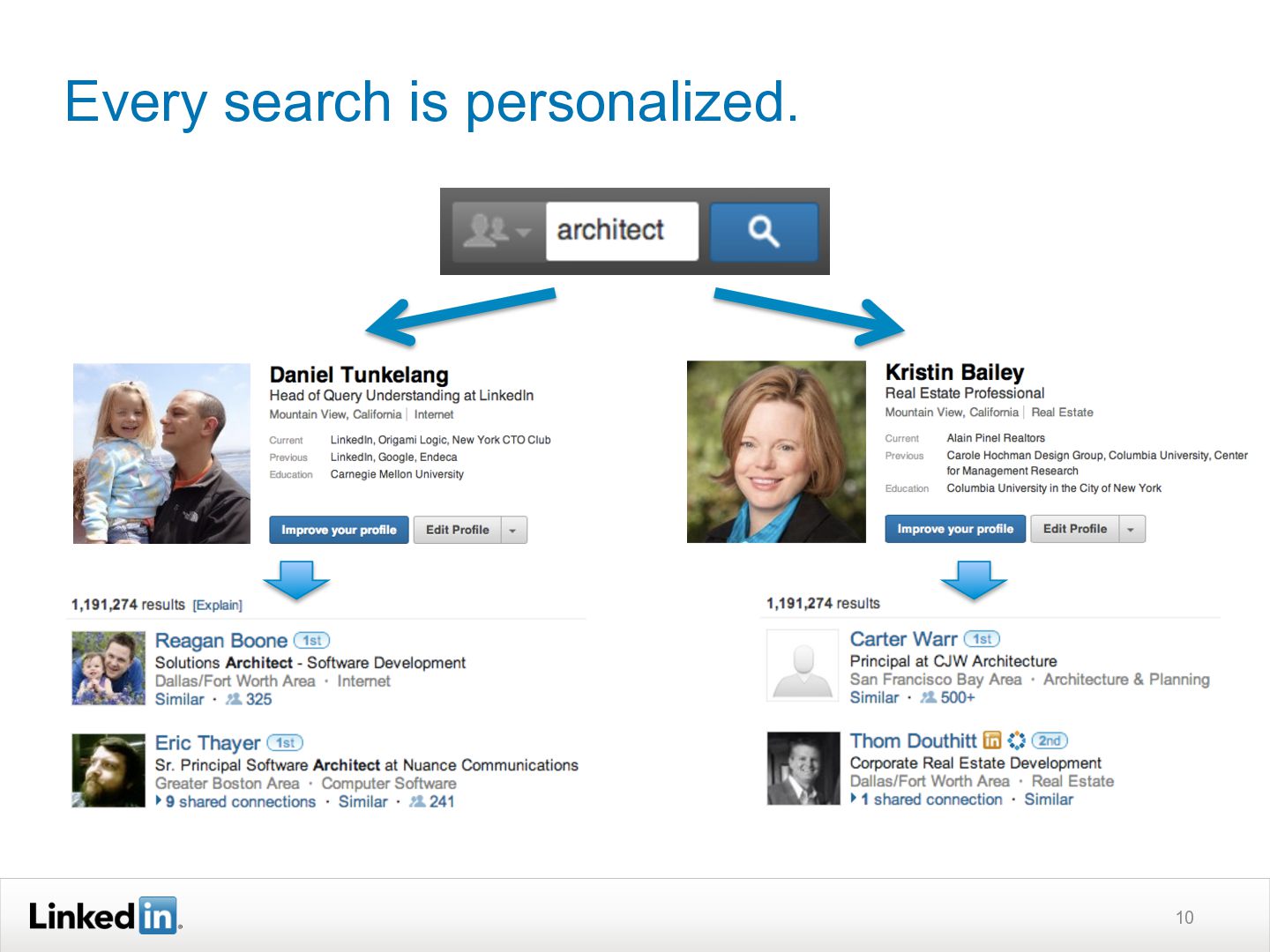{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}