This 2020 presentation to the Wikimedia Foundation elaborates on the intricacies of search processes, emphasizing the importance of metrics, models, and methods for effective search engine functionality. Key insights include the distinction between known-item and exploratory searches, the need for understanding user intent, and the iterative nature of the search process. The presentation also highlights the importance of optimizing query performance and leveraging successful searcher behavior to enhance overall user experience.
![MMM, Search! Daniel Tunkelang [email protected] Presented to Wikimedia Foundation on](https://files.speakerdeck.com/presentations/55d88839ba904b7aba893be00a591197/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
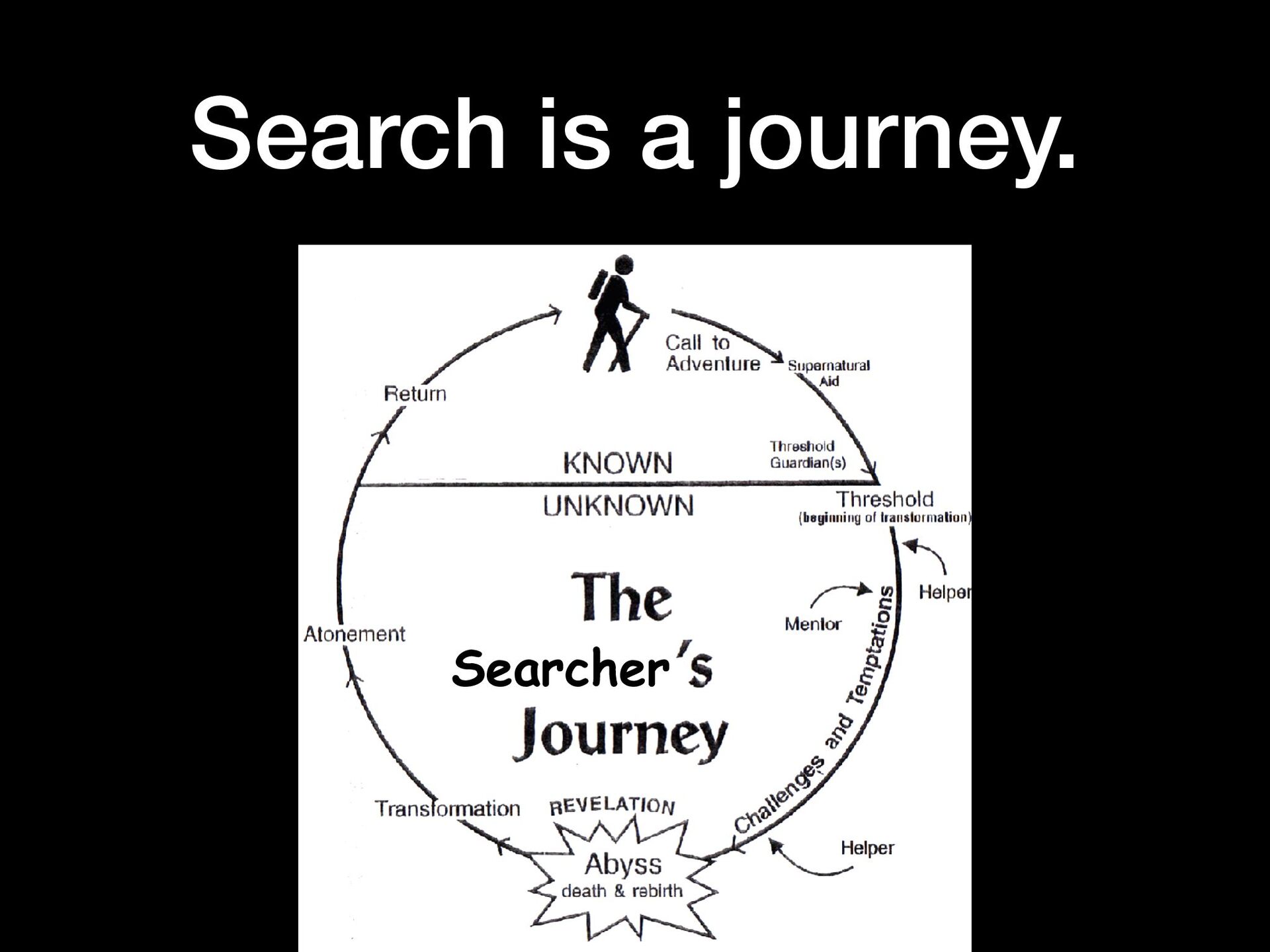{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
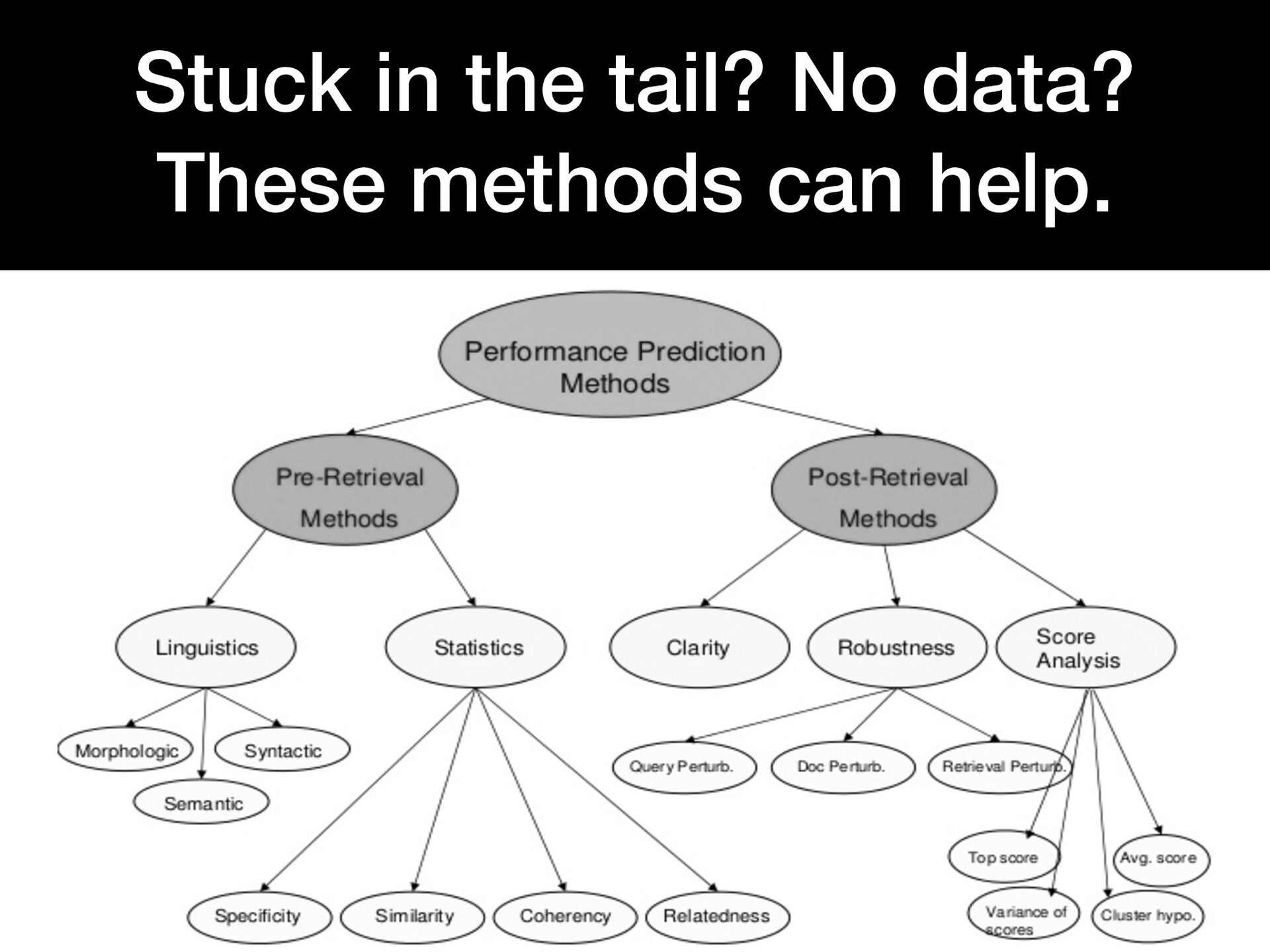{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}